
迁移学习辅助基于机器学习的传输质量评估
2022-12-17 09:05王家馨
光通信研究 2022年6期
王家馨
(南京邮电大学 电子与光学工程学院、柔性电子(未来技术)学院,南京 210023)
0 引 言
近年来,机器学习(Machine Learning,ML)评估方法在光通信领域拥有广泛的研究,迁移学习(Transfer Learning,TL)已被证明是一种有效的知识转移方法,但只有少数研究提出使用TL来预测与传输质量(Quality of Transmission,QoT)相关的各种指标(例如,误码率(Bit Error Ratio,BER)和Q因子)[1]。在文献[2]中,采用一种基于人工神经网络(Artificial Neural Network,ANN)的TL框架来预测实时混合线路速率光学系统中的Q因子。结果表明,应用知识迁移来准确预测目标领域的QoT,只需少量训练样本来微调权重。文献[3]提出基于卷积神经网络(Convolution Neural Network,CNN)深度TL的多损伤诊断技术,减少了95%以上的训练时间且具有99.88%的准确率。文献[4]提出深度神经网络(Deep Neural Network,DNN)与TL相结合,对多域光网络进行QoT预测。结果表明,该方法可以显著降低估计精度新任务所需的训练数据量。
以上研究工作发现,神经网络是TL的研究热点,但神经网络性能不易解释,缺失利用传统ML算法方面的研究;其次,TL在光纤链路QoT评估上的研究较少。因此,提出新的思路,使用直接TL与TL并微调参数两种方法在相关光通信系统中进行仿真分析并比较,验证TL并微调的基于ML的QoT多分类器在相关光纤通信系统的优势,其中ML算法使用传统ML和神经网络。
1 模型构建及多分类器介绍
系统A采用的光纤通信系统模型:在网络线性拓扑中,假设使用9个信道、信道间隔为50 GHz的波分复用链路,码元速率为32 GBaud,噪声带宽为32 GHz的偏振复用相干未补偿系统[5]。拓扑采用色散无补偿的标准单模光纤(光纤损耗系数为0.22 dB/km,非线性系数为1.3 1/(W·km),色散系数为21 ps2/km ),构成等跨度的透明传输同质链路,每个跨度的损耗全部由光纤损耗组成,掺铒光纤放大器(Erbium-doped Fiber Amplifier,EDFA)以相同跨距均匀放在链路上。EDFA完全弥补上一个跨度的损耗,噪声指数为5 dB,EDFA增益由光纤损耗系数决定。节点由具有波长选择开关(Wavelength Selection Switch,WSS)技术的可重构光分插复用器构成。光纤链路结构如图1所示。
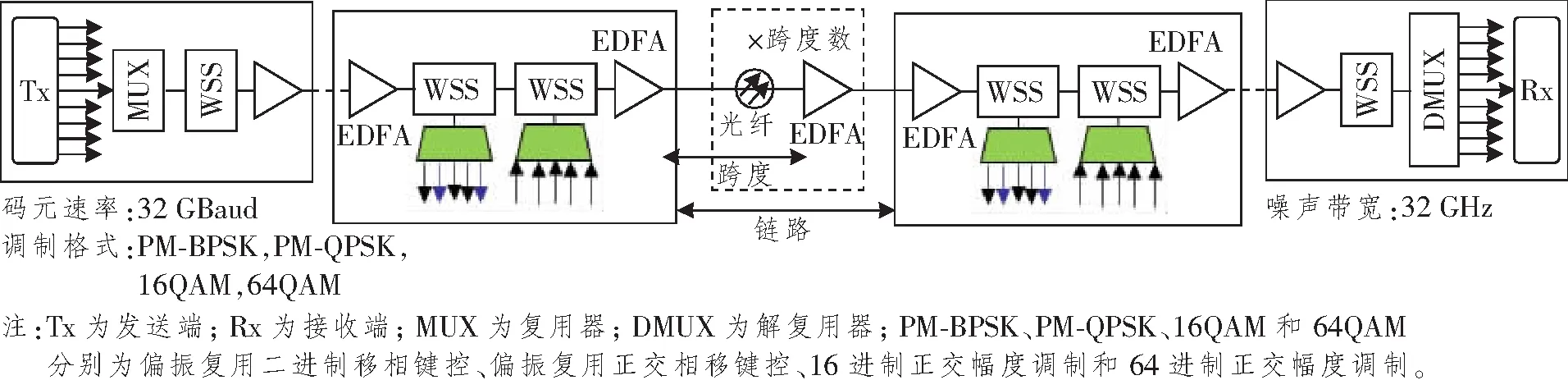
图1 光纤链路结构图Figure 1 The structure diagram of optical fiber link
系统模型B与A不同的部分是信道间隔,信道带宽与码元速率相同,为32 GHz(奈奎斯特-波分复用);系统模型C与A不同的部分是信道带宽为64 GHz,选择大于系统A的带宽值[6-7]。
1.1 链路系统参数设置
根据文献[5]、[6]和[8]设置链路参数,如表1所示。为系统相关,实现TL,则3个系统链路参数的取值是相交的,有相同部分。
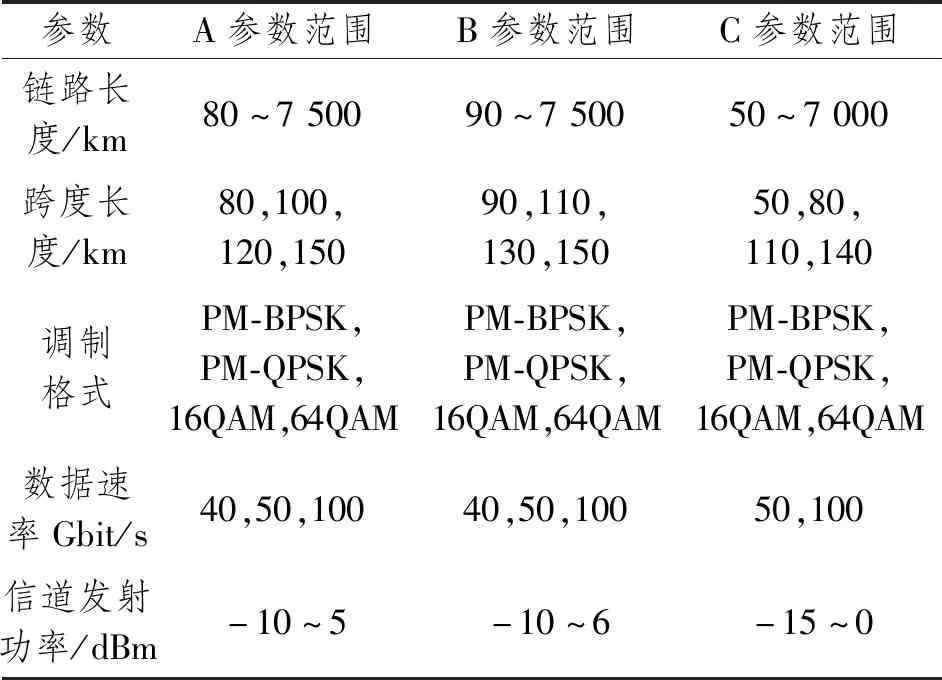
表1 A、B和C链路参数设置Table 1 A, B and C link parameter settings
1.2 获取数据
根据文献[4],确定数据集的特征为链路长度、跨度长度、调制格式、数据速率和信道发射功率,QoT指标为BER[9],即数据集标签,并使用文献[5]和[10]中的QoT评估公式,在Matlab2020a软件平台构建QoT评估公式,获得初始数据集A、B和C。
根据国际电信联盟电信标准分局(International Telecommunication Union-Telecommunication Sector,ITU-T)G.975.1建议的前向纠错标准,BER阈值设置为4×10-3。对于多分类器而言,设置两个阈值,分别为4×10-3和4×10-5。BER=4×10-3时QoT及格,符合基本链路QoT要求;BER=4×10-5时误码更少,QoT精度更高。将BER<4×10-5、4×10-5
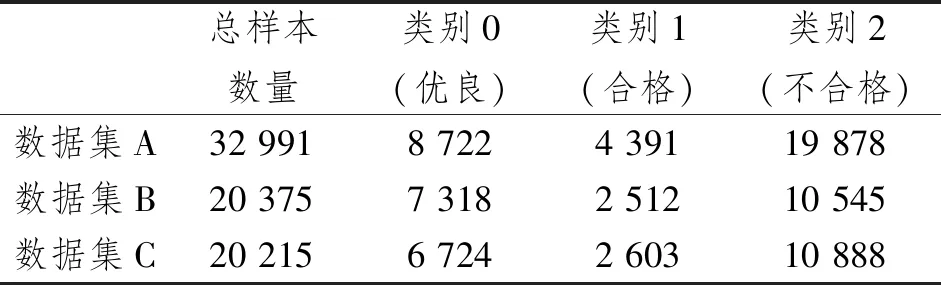
表2 数据集内容Table 2 Dataset content
1.3 ML多分类器介绍
1.3.1 ML算法简介
(1) 传统ML算法
支持向量机(Support Vector Machine,SVM)是监督ML算法,通过一对多或一对一的策略实现多分类。SVM的优点是泛化能力强,过拟合概率小,分类准确率高,中小型数据集使用其频率高[11-12]。
随机森林是多个决策树的集成,是使用bagging方法的代表之一,能够执行分类和回归任务[13-14]。在随机森林对陌生样本进行预测时,集成的所有决策树对其进行预测,会得到很多预测结果。分类时,对预测结果采用投票法,而回归时采用平均法。
(2) 神经网络
ANN由一列相互关联的人工神经元以拓扑结构的形式连接组成一个数学或计算模型,这些神经元有能力从经验数据中进行学习,以此模拟人类神经网络的功能和结构[14-15]。
DNN与ANN不一样的部分是隐藏层的数量,除了一层输出层,还包含两层以上的隐藏层,是一种典型的深度学习模型,能够实现逼近某个函数[15]。
1.3.2 多分类器介绍
多分类器结构如图2~3所示。TL选择基于参数的迁移方式,即源域A系统和目标域B和C系统共享模型参数。数据集A、B和C相关,则可进行微调技术。
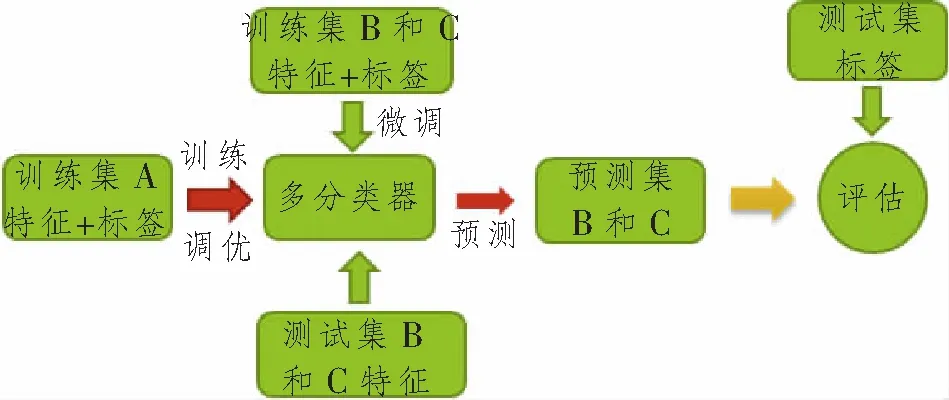
图2 迁移+微调分类器结构图Figure 2 The structure diagram of migration and fine-tuning classifier
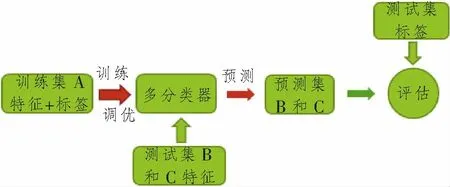
图3 直接迁移分类器结构图Figure 3 The structure diagram of direct migration classifier
微调技术将训练集B和C输入由训练集A训练好的ML多分类器中,在预先训练好的多分类器的模型参数基础上,由于系统相关,更快获得拟合系统B和C的模型参数。SVM模型对决策函数的权重和偏置进行微调,随机森林对节点特征和特征阈值进行微调,神经网络对神经元的权重和偏置进行微调。直接TL将训练集A训练好的ML多分类器,直接用于系统B和C,输入测试集B和C对模型进行评估。
2 仿真结果分析
以A系统为源域,B和C系统为目标域。算法进行超参数调优,使用系统A数据集以最优超参数的算法训练得到多分类器,使用B和C系统的数据测试评估并比较直接TL和TL并微调两种方式下的多分类器分类性能。
2.1 未微调的多分类器性能分析
多分类器在系统B中的多分类性能指标分数总结如表3所示,ANN和DNN均运行30次取均值。Kappa为统计学中评估一致性的一种方法,可用于衡量分类精度;F1_macro为F1分数的宏平均计算方式,取值范围为0~1,是评估多分类性能的指标[16]。
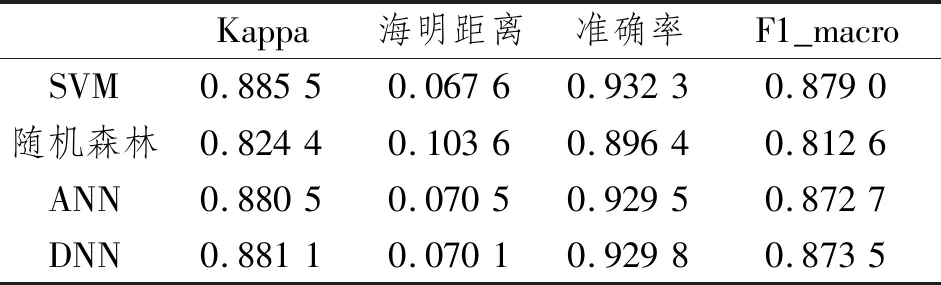
表3 系统B的多分类性能指标分数Table 3 Multi-classification performances of system B
表3记录了系统B中的多分类性能指标分数,SVM、ANN和DNN准确率在 0.92以上,Kappa和F1_macro关注样本较少的类别,分数在0.87以上。随机森林三者分数均最低,分别为0.896 4、0.812 6和0.824 4。海明距离,分数越低性能越好,SVM、ANN和DNN值相近。随机森林比前3种分类器分数大一个精度。
综上,4种性能指标分数,基于训练集A的ML多分类器整体对系统B的QoT分类精度较高,但4种分类器的准确率都比F1_macro和Kappa高,所以没有经过微调的多分类器对数据集B中样本数量较少的类别分类能力一般,其中SVM性能最好。
多分类器在系统C中的多分类性能指标分数总结如表4所示,ANN和DNN均运行30次取均值。
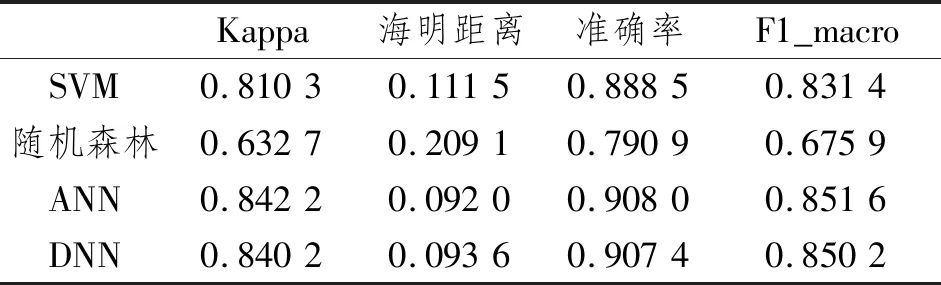
表4 系统C的多分类性能指标分数Table 4 Multi-classification performances of system C
表4记录了系统C中的多分类性能指标分数,SVM、ANN和DNN的准确率均在0.88以上,F1_macro和Kappa系数的分数皆在0.80以上,其中ANN和DNN分数相近。随机森林三者分数均最低,分别为0.790 9、0.675 9和0.632 7。ANN和DNN的海明距离分数差距为0.001 6。随机森林和SVM比ANN和DNN分数大一个精度。结合4个指标来分析,ANN和DNN在系统C中的QoT分类能力与SVM相比较强,分类精度较高。SVM的分类精度中等,随机森林对系统C的分类能力较差。
比较4种分类器的准确率、F1_macro和Kappa系数,SVM、ANN和DNN的准确率比F1_macro和Kappa系数高0.05~0.06,随机森林的准确率比F1_macro和Kappa系数高0.12~0.16。结果表明,没有经过微调的多分类器对数据集C中样本数量较少的类别分类能力一般。
综上,基于训练集A的ML分类器对系统C的分类能力总体尚优,其中ANN和DNN总体性能好。随机森林对系统C的分类能力较差,不适合用于系统C。与系统B性能相比,系统C的性能分数均低。4种分类器对系统B的分类能力明显好于系统C,这说明系统B与系统A的相关性更强。
2.2 微调的多分类器性能分析
多分类器在系统B中的多分类性能指标分数总结如表5所示,ANN和DNN均运行30次取均值。
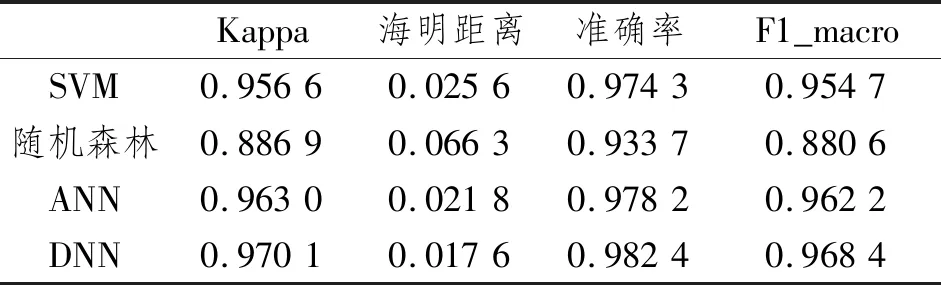
表5 系统B的多分类性能指标分数Table 5 Multi-classification performances of system B
表5记录了系统B中的多分类性能指标分数,SVM、ANN和DNN的准确率、F1_macro和Kappa系数三者分数皆在0.95以上。随机森林三者分数均最低,分别为0.933 7、0.880 6和0.886 9,分数也均在0.88以上。所有分类器的海明距离精度级别都在0.01。结合4个指标分析,经过微调后的ANN和DNN在系统B中的QoT分类能力较SVM强,分类精度很高。SVM的分类精度也很高,随机森林对系统C的分类能力也高。
测试集的大小对性能影响可忽略不计,与表3数据相比,经过微调的4种分类器分类质量明显提高,表3中,SVM、ANN和DNN的F1_macro和Kappa系数的数值都处于0.88左右,随机森林在0.82左右。经过微调,表4中SVM、ANN和DNN的F1_macro和Kappa系数数值都处于0.95以上,提升了0.07分,进步显著。随机森林在0.88左右,提高了0.06分,提高了随机森林对系统B的分类能力。
综上,得到经过微调的基于ML多分类器对系统B的分类能力提高甚多,分类精度高。DNN的性能最好,性能分数最佳。
多分类器在系统C中的多分类性能指标分数总结如表6所示,ANN和DNN均运行30次取均值。

表6 系统C的多分类性能指标分数Table 6 Multi-classification performances of system C
表6记录了系统C中的多分类性能指标分数,SVM、ANN和DNN的准确率、F1_macro和Kappa系数三者分数皆在0.95以上。随机森林分数三者均最低,分别为0.951 6、0.917 4和0.916 2,分数也均在0.91以上。ANN的分数与DNN相近。ANN和SVM的海明距离分数差距微小,为0.006左右,DNN最小,随机森林分数最大,所有分类器的海明距离都在0.01级别的精度。结合4个指标来分析,经过微调后4种分类器对系统C的QoT分类能力增强,分类精度显著变高。
同样,与表4相比,微调后的4种分类器性能指标分数大幅度提高。表4中,SVM、ANN和DNN的F1_macro和Kappa系数的数值都处于0.84左右,随机森林分数在0.66左右。经过微调,表6中SVM、ANN和DNN的F1_macro和Kappa系数的数值都处于0.95以上,提升0.11分。随机森林分数在0.91左右,提高了0.25分,数量较少的样本分类能力明显提高。
综上,得到微调后的分类器性能都比未微调的分类器性能提高很多,提升了系统C的分类精度,减少了样本不均衡影响。随机森林的变化非常大,这是由于随机森林依赖数据以进行特征和特征阈值的选择,若是不进行微调,则需要目标域与源域的系统相关性强,生成的随机森林相关性也强,否则直接迁移不能实现较好的分类, 微调后所有指标分数都得到改善。
2.3 比较结果
比较系统B和系统C在直接TL和TL并微调的两种方式下得到的多分类性能分数,得出结论,TL结合微调能够极大改善分类器的性能,减少对系统间相关性的依赖。传统ML分类器的分类质量不逊于神经网络,且其算法复杂度较低,性能原因更容易解释分析。因此,传统ML对于TL是一个有效选择。
3 结束语
本文提出直接TL和TL并微调两种方法去解决ML光纤链路QoT评估器训练复杂的问题,构造的4种ML链路QoT多分类器的直接迁移指标分数在0.63以上,TL并微调在0.88以上,与其他研究结果相比,从新的思路验证了TL辅助并进行微调的多分类器实现少样本高精度评估相关通信系统的链路QoT,传统ML多分类性能优秀且易解释,对光纤链路QoT评估具有很好的实现意义。未来可以引入更多TL和ML相关的技术,进一步提升评估光纤链路的效率。
猜你喜欢
乐器(2021年1期)2021-09-10
石油沥青(2021年1期)2021-04-13
空间科学学报(2020年4期)2020-04-22
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
考试周刊(2017年7期)2017-02-06
制冷技术(2016年4期)2016-08-21
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
中国工程咨询(2011年12期)2011-02-13
