
一种半监督对抗鲁棒模型无关元学习方法
2022-12-13 13:52胡彬王晓军张雷
计算机工程 2022年12期
胡彬,王晓军,张雷
(1.南京邮电大学 计算机学院,南京 210023;2.南京邮电大学 物联网学院,南京 210023)
0 概述
近年来,深度学习技术利用大数据在图像分类、语音识别等领域取得显著成果,这些技术需要大量带标注的高质量数据,但在某些现实场景中,有些类别只有少量数据或少量标注样本数据。少样本学习(Few-Shot Learning,FSL)[1]的目标是设计一个只需少量样例就可以快速认知新任务的模型,但是,基于梯度下降的优化算法在被应用于少样本学习时会失效,可能的原因有[2]:少样本学习问题的训练数据量较小,在模型训练中参数更新次数受到限制,传统基于梯度优化的算法(如ADAM[3]、Adagrad[4]等)无法在这种情况下寻找到最优参数;对于每个数据集,网络参数必须从随机初始化开始,这严重影响了网络优化速度。为缓解上述问题,文献[5]总结了基于模型微调[6]、基于数据增强[7-9]和基于迁移学习[10-12]的三类方法。其中,迁移学习的主要思想是利用旧知识来学习新知识,并将已经学会的知识很快地迁移到一个新的领域中。迁移学习由于只需源领域和目标领域存在一定关联,就能实现知识在不同领域之间的迁移,因此成为目前主流的应用选择之一。
元学习(Meta-Learning)是基于迁移学习的一种解决方案,其目的是“学会学习”(Learning to Learn)[13]。元学习希望从大量相似的小任务中学习一些元知识,并使用这些元知识来指导模型快速适应新任务。一些元学习算法在少样本学习中取得了较好的效果,如FINN等[14]在2017 年提出的模型无关元学习(Model-Agnostic Meta-Learning,MAML)算 法。MAML 算法以神经网络为基础模型,在大量相似任务中进行元学习,以找到对各任务都较为通用的初始化参数,MAML 训练出的模型也被称为元模型。当新任务来临时,仅用少量标注训练样本微调元模型,便可让损失函数快速收敛,以使模型适应新的学习任务。MAML 不仅可以用来解决少样本分类问题,还可用于强化学习、回归等问题。但是,GOLDBLUM等[15]发现MAML 等元学习器的对抗鲁棒性较弱,很容易受到对抗样本的影响,尤其是一些恶意设计的对抗扰动,能够让自动驾驶失效[16],让目标检测或人脸识别系统失灵等[17],如果系统无法应对,会造成极大危害。
YIN等[18]发现将干净样本与对抗样本简单混合后,采用MAML 训练元模型时该模型并不能有效工作,于是提出对抗元学习(Adversarial Meta-Learner,ADML)算法。ADML 的关键思想是利用干净样本与对抗样本之间的相关性,使任务训练和元更新相互对抗,以改善模型鲁棒性,但是,这种交替训练网络的方式,使得ADML 的训练代价昂贵。在另一项工作中,GOLDBLUM等[15]将对抗训练与MAML 相结合,提出对抗性查询(Adversarial Querying,AQ)算法,在训练时使用快速梯度符号方法(Fast Gradient Sign Method,FGSM)[19]生成对抗样本,测试时使用投影梯度下降(Projected Gradient Descent Attack,PGD)算法[20]生成对抗样本。然而,AQ 仅在有监督下工作,对于如何利用未标注样本则没有进一步研究。
WANG等[21]提出鲁棒增强模型无关元学习(Robustness-promoting MAML,R-MAML)算法,将AQ 考虑为R-MAML 的一种特殊情况,其半监督版本R-MAML-TRADES 将额外的未标注数据引入元学习以提升元模型的对抗鲁棒性。但是,REN等[22]认为将未标注数据引入元学习中,应当考虑两种场景:一是每个任务中的未标注样本与同一任务的已标注样本具有相同的类分布;二是该任务中的部分未标注样本不属于训练集中任何一类,未标注数据包含了在标注训练集中未见过的类。
R-MAML-TRADES 在引入未标注样本时,隐式地假设每个未标注样本与当前任务中的已标注样本属于同一组类,即场景A,这种假设在现实场景中难以成立。REN等[22]针对上述两种场景,扩展原型网络(Prototypical Networks)算法[23],提出掩码软聚类(Masked soft K-Means)算法,将未见过类未标注样本作为干扰项剔除,但其没有考虑元学习器的对抗鲁棒问题。
本文针对模型无关元学习算法与半监督对抗元学习存在的不足,提出一种半监督对抗鲁棒模型无关元学习(semi-supervised Adversarially Robust Model-Agnostic Meta-Learning,semi-ARMAML)算法进行模型训练,该模型仅使用少量标注数据训练迭代即可快速适应新任务。具体地,本文提出一种有效的对抗鲁棒正则化元学习方法,在微调过程与元更新过程的目标函数中均引入对抗鲁棒正则项,以提高元学习器的对抗鲁棒性能。在元更新过程的目标函数中引入基于信息熵的任务无偏正则项,从而缓解元模型在训练过程中出现过拟合的问题。在元更新过程的目标函数中还使用未标记的集合来计算对抗鲁棒正则化项,并允许未标注数据包含标注训练集中未见过的类,以获得更为通用且对抗鲁棒的元模型。
1 semi-ARMAML 算法
本文semi-ARMAML 算法的目标是采用半监督学习与对抗训练的方式来训练一个模型,该模型仅使用少量标注数据训练迭代即可快速适应新任务,并且还拥有较高的对抗鲁棒性能,在半监督场景B下同样适用。
1.1 问题定义
假设任务Ti是一个从任务分布p(T)中取样的NwayK-shot 分类任务,每个任务数据集中共有N个类别,每个类别只有K个标注样本。任务Ti被划分为支撑集(support set)和查询集(query set)。为简单起见,将元模型表示为由θ参数化的函数fθ(x),其将输入样本x映射到离散标签y∈{1,2,…,N}上。
数据集D来自一个任务分布p(T),其类别被划分为3 个类别集合,分别为训练集类集合Ctrain、未见过类集合Cunseen与测试集类集合Ctest,3 个类集合不相交。将数据集D也划分为3 个集合,分别为训练集Dtrain={(x,y)|x∈D,y∈Ctrain}、未见过类训练集Dunseen={(x,y)|x∈D,y∈Cunseen} 与测试集Dtest={(x,y)|x∈D,y∈Ctest}。为构建任务Ti的训练集,首先从Ctrain中抽取包含N类的子集,然后再从数据集Dtrain中抽取支撑集与查询集包含来自中每个类别的K个样本包含来自相同N类且不属于的样本。
semi-ARMAML 的元训练过程与MAML 相似,也采用双层学习过程,即任务微调过程(内循环)与元更新过程(外循环)。内循环得到任务的最优参数,外循环将内循环期间得到的模型组合起来,形成一个更通用的元模型。

1.2 对抗鲁棒正则项
对抗鲁棒性本质上是要求模型对于输入的微小扰动应有一个稳定的输出,这表现为最小化扰动样本和干净样本的预测概率分布之间的差异,因此,semi-ARMAML 在任务微调过程和元更新过程中同时引入对抗性鲁棒正则化方法。

其中:={(x,xadv)|x∈D}是数据集D对应的对抗样本集;E为g(x,xadv;θ)的期望;θ为模型参数;g(x,xadv;θ)根据样本是否带标注进行处理,对于标注样本,g(x,xadv;θ)测量xadv的预测概率分布和真实概率分布之间的差异,即fθ对xadv的预测值和x的真实标签y之间的交叉熵,对于未标注样本,借鉴虚拟对抗训练(Virtual Adversarial Training,VAT)[24],g(x,xadv;θ)测量fθ对xadv的预测值和x的虚拟标签fθ(x)之间的均方误差。该损失函数的目的是希望参数模型fθ(xadv)逼近真实分布,使得元模型对输入足够平滑,降低模型对输入扰动的敏感性,平滑决策边界,提升模型在对抗样本上的识别率。
1.3 任务无偏熵正则项
为了防止元模型fθ在某些训练任务中过拟合,本文采用基于信息熵实现的任务无偏正则项entmax-min[25],计算如下:

1.4 算法描述
1.4.1 任务微调过程
在任务微调期间,根据梯度及步长α微调每个任务{Ti}0≤i≤m,更新特定于该任务的最优参数

1.4.2 元更新过程

由于与Ti中已标注样本类别不一致,因此本文使用“通用”的初始化参数θ进行预测,而不使用依赖特定于当前任务Ti的最优参数。R()和R(,θ)的作用与内循环中对抗鲁棒正则项类似,不仅将样本映射到其目标分类,而且使元模型在对抗样本集上具有相似的表现。
semi-ARMAML 期望模型fθ以相等的概率预测新任务中的样本标签,采用式(3)计算上的entmax-min,以缓解模型在训练数据上的过拟合问题,找到更通用的初始化参数。semi-ARMAML 的伪代码如算法1 所示。
算法1semi-ARMAML 算法

2 实验结果与分析
2.1 实验设置
实验选用MiniImageNet 和CIFAR-FS 数据集测试算法性能,MiniImageNet 是ImageNet 的一个精缩版本,2 个图像数据集的概况如表1 所示。
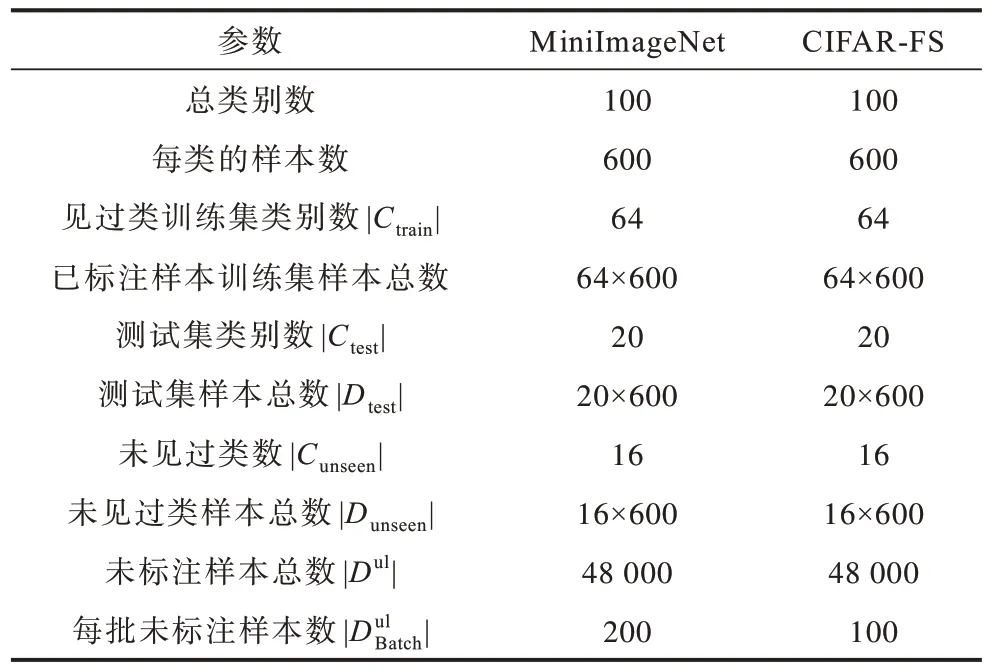
表1 数据集信息Table 1 Datasets information
本文分别为2 个数据集从100 个类中预留16 个类数据作为未见过类数据。在MiniImageNet 数据集实验中,从ImageNet 数据集中为每个训练类挑选600 个未标注数据,并将图片调整为84×84×3 大小;在CIFAR-FS 数据集实验中,从STL-10 数据集中为每个训练类挑选600 个未标注数据,将图片调整为32×32×3 大小。在任务微调过程中,设置梯度更新次数S=5,α=0.02;在元更新过程中,查询集中设置每类15 个样本,梯度步长设置为β=0.001。在元训练过程中使用FGSM 生成对抗样本集,元测试过程中使用10 步PGD 生成对抗样本集。
如不特别说明,λe取值为1,semi-ARMAML 实验均在半监督场景B 下进行,训练运行纪元数epoch=60 000。在MiniImageNet 数据集实验中,训练时ϵ=2,元测试时ϵ=2,λout1=8,λout2=8,λin=1;在CIFAR-FS 数据集实验中,训练时ϵ=2,元测试时ϵ=8,λout1=10,λout2=10,λin=1。
2.2 评价指标
本文测试semi-ARMAML 的以下特性:
1)可以同时有效识别对抗样本和干净样本。
2)在半监督场景下,能够进一步提升模型的对抗鲁棒性,而在未标注样本中混入未见过类数据时,分类性能不会受到较大影响。
为评价模型性能,分别测试标准正确率(Standard Accuracy,SA)和鲁棒正确率(Robustness Accuracy,RA)。SA 表示在干净样本数据集上的模型性能,RA 表示在对抗样本数据集上的模型对抗鲁棒性能。
2.3 对抗鲁棒正则项对算法性能的影响
首先分析鲁棒正则项对算法性能是否产生正面影响。在表2 中:out 表示仅在元更新时加入正则项,训练任务的微调过程与新任务适应过程都不加入正则项,即λin=0;in+out 表示在新任务适应与训练任务的微调过程都加入正则项,即λin=1。λout1、λout2均设置为1,最优结果加粗标注。

表2 对抗鲁棒正则项对算法性能的影响Table 2 Influence of adversarial robust regularization term on algorithm performance %
从表2 可以看出,尽管在微调阶段加入正则项会增加一定的计算代价,但是除了5-way 1-shot 的RA 性能没有提高外,其余实验的SA 与RA 均有一定程度的提高,因为在任务适应阶段加入对抗正则项有助于找到更为鲁棒的模型参数θ′i,使得元模型更新时也能兼顾对抗鲁棒性。在后续实验中,均采用in+out 方式。
2.4 算法性能比较
为了进行算法性能比较,将MAML、ADML 和RMAML-TRADES 作为对比算法。MAML、ADML 只能采用已标注样本进行有监督训练,为了便于比较,semi-ARMAML 中设置λout2为0(记 为semi-ARMAML(supervised)),从而支持有监督方法。R-MAMLTRADES 仅支持半监督场景A,为保证公平,semi-ARMAML 与R-MAML-TRADES 实验数据设置相同,未标注样本数为38 400,均为见过的类。所有算法的标注样本集设置相同。
不同元学习算法的实验结果如表3、表4 所示,实验超参数设置如表5所示。表3、表4显示MAML在2个数据集上几乎没有对抗鲁棒性,但是在干净样本下正确率最高,其他算法的SA 均有所下降,对抗鲁棒性相比MAML 有明显提升。对比对抗元学习的几种算法,semi-ARMAML 在RA 上的性能均为最高,而SA 由于对抗训练而不可避免地有所降低。在所有的有监督方法中,semi-ARMAML(supervised)的RA 均优于其他有监督算法,这主要是由于引入了任务无偏的熵正则项,使得新任务与训练任务之间的关联度降低,提高了模型对新任务的泛化性。在半监督场景下,由于未标注样本的引入,尤其在CIFAR-FS 数据集上,本文算法有效提高了模型的对抗鲁棒性能。尽管R-MAMLTRADES 的SA 相比其他对抗元学习算法有一定优势,但是RA 并不占优。semi-ARMAML 支持未标注样本与当前任务标注样本不一致的情况,适应性更广,其RA均优于其他算法,这说明对未标注样本信息的利用可增强模型的对抗鲁棒性。

表3 MiniImageNet 数据集上SA/RA 性能对比分析Table 3 Comparative analysis of SA/RA performance on MiniImageNet dataset %

表4 CIFAR-FS 数据集上SA/RA 性能对比分析Table 4 Comparative analysis of SA/RA performance on CIFAR-FS dataset %

表5 不同数据集下semi-ARMAML 的超参数设置Table 5 Hyper parameter setting of semi-ARMAML under different datasets
综上,使用semi-ARMAML 训练得到的初始化参数θ一方面对各任务的变化敏感,另一方面对任务中的样本扰动噪声有更高的容忍度,使得元模型的对抗鲁棒性大幅提高。
2.5 正则项系数对算法性能的影响
表6所示为系数λout1和λe在CIFAR-FS 数据集上对semi-ARMAML 算法性能的影响。为了分析任务无偏正则项entmax-min对模型性能的影响,本文设置λout1=20、λe=0和λout1=20、λe=1 两组对比实验,两组实验中的其他参数设置相同。结果表明,尽管entmax-min正则项的引入使模型损失一定的SA,但会明显提升RA 性能,这是因为entmax-min降低了元模型与训练任务之间的相关性,缓解了过拟合问题,能在新任务中更好地适应对抗样本。表6 结果还显示,当引入正则项时(λout1>0),算法的SA与RA性能明显优于λout1=0时的算法性能,且随着λout1逐渐增大,RA 性能提高,SA 性能略微降低,这表明对抗鲁棒正则项系数λout1对模型的对抗鲁棒性能起主导作用,通过调整目标损失函数中的λout1系数,可使模型同时兼顾干净样本准确度和对抗鲁棒性。

表6 正则项系数对算法性能的影响分析Table 6 Analysis of the influence of regularization coefficients on algorithm performance
2.6 未见过类的未标注样本对算法性能的影响
在2.4 节的实验中,为保证公平,实验数据集均使用见过类的未标注数据集,本节进一步研究未见过类对算法性能的影响。
表7展示了未见过类样本数量对模型性能的影响。未标注样本Dul中已见过类样本数与上文中设置相同,为32 000,其余为额外追加的与训练集类别不相交的9 600 个未见过类样本。从表7 可以看出,当引入干扰项,即Dunseen≠∅时,semi-ARMAML 的RA 性能有所损失,但是,RA 即使在最坏情况下相比表3、表4 中其他算法的RA 也仍然具有优势,而且由于训练样本增加,semi-ARMAML 的SA 在大部分情况下会比未增加未见过类样本时有所提升。

表7 未见过类样本数量对算法性能的影响分析Table 7 Analysis of the influence of number of unseen class samples on algorithm performance
2.7 算法时间代价对比
表8 基于CIFAR-FS 数据集对比不同算法的时间代价,ADML、R-MAML-TRADES 和本文semi-ARMAML 这3 种算法是双层优化过程,且为保证公平,使用相同的对抗样本生成算法。

表8 CIFAR-FS 数据集上的时间代价Table 8 Time cost on CIFAR-FS dataset
在表8 中:Time 表示500 轮的训练时间,ADML使用干净样本与对抗样本交替训练网络,训练时间代价最高,R-MAML-TRADES 和semi-ARMAML 算法整体时间代价相差不大,本文算法略优;Fin steps表示在元测试时使模型达到稳定性能所需的微调步数,由于semi-ARMAML 在新任务的任务微调过程中也加入了对抗鲁棒正则项,使其能够更好地微调模型参数,更快地适应新任务,因此仅需2 步梯度下降就能达到稳定性能。
3 结束语
本文针对半监督对抗元学习问题,提出一种对抗鲁棒模型无关元学习方法。该方法在元训练过程中同时使用标注样本与未标注样本进行训练,即使不知道未标注样本的类别信息,也能在大量相似任务中训练元模型,使其能够快速适应新任务。同时,在损失函数中加入对抗鲁棒正则项与任务无偏熵正则项,提升模型的对抗鲁棒性,缓解元模型在训练任务时的过拟合问题。在2 个基准数据集上的实验结果表明,相较其他对抗元学习方法,该方法在干净样本上的正确率仅有微小降低,但获得了更高的对抗鲁棒性能,且对含未标注样本的真实场景适应性更好。下一步将在学习过程中探究如何利用未标注样本中占比更大的未见过类样本,进一步提高模型的泛化性与对抗鲁棒性。
猜你喜欢
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
科技研究·理论版(2021年22期)2021-04-18
农业机械学报(2020年2期)2020-03-09
北京航空航天大学学报(2019年9期)2019-10-26
中华建设(2019年7期)2019-08-27
自动化学报(2019年6期)2019-07-23
上海师范大学学报·自然科学版(2018年3期)2018-05-14
自动化学报(2017年4期)2017-06-15
