
应用透明的超算多层存储加速技术研究
2022-12-13 13:51何晓斌高洁肖伟陈起刘鑫陈左宁
计算机工程 2022年12期
何晓斌,高洁,肖伟,陈起,刘鑫,陈左宁
(1.国家并行计算机工程技术研究中心,北京 100080;2.清华大学 计算机科学与技术系,北京 100084;3.中国工程院,北京 100088)
0 概述
当前高性能计算已经迈入E 级时代,随着传统超算与AI 的不断融合,超算应用领域不断扩大,应用产生的数据量也呈爆发性增长[1-3]。为此,主流高性能计算系统均构建了多层存储体系,主要包括全局文件系统(Global File System,GFS)、突发缓冲存储(Burst Buffer,BB)[4]、节点高速存储层等,其中GFS 主要使用大容量磁盘构建,BB 一般使用NVMe SSD 构建。此外,近年来利用非易失性随机访问存储器(Non-Volatile Random Access Memory,NVRAM)、非易失性双列存储模块(Non-Volatile Dual In-line Memory Module,NVDIMM)等高速存储介质构建节点高速存储层也成为研究热点[5]。最新发布的美国Frontier 超算部署了三层存储[6],包括计算节点本地高速存储、全局共享的SSD 存储和全局共享的磁盘存储,合计存储容量高达760 PB,数据读带宽达75 TB/s,数据写带宽达35 TB/s;日本超级计算机富岳[7]部署了两层存储,包括计算节点共享的SSD 存储系统,容量达16 PB,带宽达10 TB/s,此外还基于磁盘构建了容量达100 PB 的全局文件系统。存储层次的不断增加,虽然提升了存储系统的总体性能,但是目前多层存储系统的构建缺乏统一标准,特别是BB 层与计算节点本地存储层,为了发挥硬件介质的性能优势,其软件设计与传统存储软件存在显著差异,无法与传统文件系统形成统一名字空间,如GekkoFS[8]、UnifyFS[9]、CROSS[10]、Datawarp[11]、BeeOND[12-13]等文件系统均基于BB 构建了独立的文件系统空间,需要应用修改数据访问路径,往往会导致额外的数据管理负担。正是由于以上原因,导致存储加速系统的利用率普遍不高[14]。业界针对以上问题研发了多款软件,如Elevator[15]、Unistor[16]、Hermes[17]等,但是此类软件或者针对特定的上层I/O 库(例如HDF5 等),或者无法支持多层异构存储介质,难以适用于下一代国产超算存储系统。
为解决多层存储架构无法实现统一名字空间访问的问题,本文提出对应用透明的加速技术。针对计算节点NVDIMM 等高速存储层设计透明的块级数据读写缓存机制,提出支持数据顺序读和跨步读的预读算法,实现NVDIMM 层与BB 层统一名字空间管理;针对BB 层设计文件级的数据缓存机制,提出缓存副本的一致性管理方法,实现BB 层与传统GFS 层统一名字空间管理。最终,基于神威E 级原型验证系统对这2 种缓存技术进行测试。
1 相关工作
当前,随着超算算力的高速增长,为支撑超算应用的数据访问需求,超算存储系统一般使用分层存储架构构建,主要包括大容量全局文件系统、高性能Burst Buffer 以及计算节点本地高速NVDIMM 等层次[6-7,18-19],其架构如图1 所示。

图1 超算分层存储架构Fig.1 Tiered storage architecture of supercomputing
大容量全局文件系统一般基于磁盘存储构建,具有容量大、数据全局共享、可靠性高、兼容标准接口、聚合带宽较低等特点,如Lustre[20-21]、BeeGFS[12]等;而高性能BB 存储系统一般基于SSD 构建,性能相比全局文件系统更高,具备一定的数据共享机制,但是目前这一类系统往往不能完整支持POSIX 接口,应用使用时不仅需要修改路径,而且还需要定制数据从GFS 导入至BB(stage-in)以及从BB导出至GFS(stage-out)的管理流程,如GekkoFS[8]、DAOS[22]、UnifyFS[9]、HadaFS[23]、Datawarp[11]等;计算节点本地的NVDIMM 存储性能更接近内存,但是容量较小,仅可作为临时性局部存储空间,这类存储介质一般通过块接口使用[24-25],难以适用于通用的I/O 流程[26]。
分层存储通过更多层次高速硬件的部署提升了存储系统的基础性能,然而却带来了统一名字空间的问题,如何对应用隐藏多层次存储系统的复杂性,透明提升应用数据访问的效率成为业界关注的难题[14,27]。Elevator提出了一种针对Burst Buffer 的透明缓存机制,可实现BB 与GFS 的透明整合,但是这种机制只能运行在HDF5 库内部,存在适应性问题[15];Unistor 在Elevator 的基础上实现了对通用场景下BB 的加速机制支持,但是无法支持NVDIMM存储环境[16];IBM 在Summit 中分别提出了面向计算节点本地SSD 的块和文件级缓存机制,但是仅支持透明的写缓存[28];LPCC 基于Lustre 文件系统实现了BB 与GFS 的数据缓存[20],但是其要求BB 中的数据必须写回GFS 以支持数据共享,数据共享效率较低;Hermes 提出多级存储融合使用的方法,但是其缓存管理和分配机制需要统计大量I/O 事件信息,在大规模超算中存在扩展性差的问题[17]。
神威E 级原型验证系统是我国面向E 级超算关键技术挑战构建的验证平台[29],配置了全局文件系统、BB 存储系统,并且具备利用节点内存进行I/O 加速的基础。该系统中的全局文件系统基于Lustre+LWFS 构建,与神威·太湖之光全局存储相似[19];BB存储系统基于全新研制的HadaFS 构建,该系统实现了用户层、松耦合的文件访问语义。面向下一代超算的I/O 挑战,本文针对NVDIMM 的块访问和BB 的文件访问优势分别提出不同的数据缓存机制,从而支持多层存储加速的统一名字空间,实现对应用透明的I/O 加速。相关技术在神威E 级原型验证系统中进行部署,为神威下一代超算存储系统的研发提供参考。
2 透明存储加速技术的设计
为解决当前超算多层存储异构软件堆叠带来的多种名字空间统一的问题,本文提出面向下一代超算的透明存储加速技术,如图2 所示,该技术嵌入在超算多层存储软件栈中,支持POSIX 标准的文件读写接口,主要包括基于NVDIMM 的块级缓存和基于BB 的文件级缓存两个方面。基于NVDIMM 的块级缓存以计算节点高速NVDIMM 存储介质为基础,通过NVDIMM 高速块访问协议实现对传统文件数据块的缓存;基于BB 的文件级缓存通过文件级的动态数据迁移,解决BB 层与全局文件系统无法实现名字空间统一的问题。

图2 面向下一代超算的透明存储加速技术架构Fig.2 Transparent storage acceleration technology architecture for next-generation supercomputing
2.1 基于NVDIMM 的块级缓存
基于NVDIMM 的块级缓存运行在超算BB 层存储之上,针对计算节点本地读写的数据流进行加速,其利用计算节点NVDIMM 实现对文件的数据块级缓存,原理如图3 所示。NVDIMM 层块级缓存功能作为一个独立模块嵌入超算存储客户端内部,自动截获应用文件读写的数据块地址、大小等信息,并为存储客户端提供块级写数据缓存和数据预读功能。

图3 NVDIMM 块级缓存的工作原理Fig.3 Principle of NVDIMM block-level cache
NVDIMM 块级缓存模块在NVDIMM 介质中以文件为单位分别维护了读写两个先进先出(FIFO)队列,此外还包括数据一致性控制、数据异步写引擎和数据预读引擎等部分。应用进程产生的文件操作如读(read)、写(write)、刷新(flush)、获取状态(stat)等将按照时间顺序依次进入队列,并由数据一致性控制部件决定是否立即向上层应用返回成功。对于写操作,若NVDIMM 中事先设定的缓存窗口没有溢出,则设置为异步操作,否则设置为同步操作。异步操作意味着该写请求的数据块将被缓存至NVDIMM,同时客户端将立即向应用返回写成功,而同步操作意味着客户端需要等待该请求刷新至BB 层文件系统后才能向应用返回结果。写操作缓存的数据块由数据异步写引擎负责刷新至BB 层文件系统中。
对于读操作,系统将尽可能多地预读数据块并缓存在读数据队列中,以减少从服务端直接读数据的次数。数据读引擎根据读缓存队列中缓存的数据块大小和偏移位置决定预读数据起始位置和大小,目前有可探测顺序(Sequential)读和跨步(Stride)读两种模式,对于随机读默认按照顺序读的方式预取数据,数据预取块大小为事先设定的大数据块,以提升命中概率。数据预读算法如算法1 所示。
算法1数据预读算法
输入最近两次读请求q1(offset,size)、q2(offset,size),以及记录的跨步偏移量stride_offset
输出预读的数据块请求q_preread(offset,size)


NVDIMM 块缓存模块收到应用读数据请求后,将在文件预读数据块列表中查找对应的数据块,具体算法如算法2 所示。此外,为了保证缓存的利用率,缓存块搜索的过程也需要同步进行缓存块清理,以实现后续更多数据的预读。
算法2预读数据块的搜索和管理算法
输入已经预读的数据块(offset,size,buffer)组成的顺序列表list,以及应用的读请求rq(offset,size)
输出命中返回hitbuf,以及剩余未命中部分的left_offset和left_size;未命中返回NULL

高性能计算应用数据读写类型较为单一,几乎不存在多进程对同一文件同一区域进行可覆盖写以及读写交叉的应用场景,因此,NVDIMM 块级缓存对读、写队列分开处理,且不支持对同一文件进行缓存写与预读。读写一致性模块对于请求队列中的数据一致性进行检查,发现对同一文件同时进行缓存写与预读的I/O行为后将对该文件强制禁用写缓存和预读功能。
由于NVDIMM 是一种非易失的存储介质,因此基于NVDIMM 的块缓存机制理论上具备节点故障后恢复数据的能力,为此,读写一致性处理部件在数据写入的同时还保留了文件数据块缓存的日志,以在节点故障恢复后快速恢复数据,同时由于底层文件系统存储了文件的真实大小和访问时间,因此故障状态下应用可根据文件大小、访问时间等检索受影响的文件,以在应用层做出补救。对于读缓存,由于本身不涉及数据一致性问题,因此无需特殊处理。
NVDIMM 层块级缓存支持两种管理方式:一种是用户通过环境变量设置加速目录和缓存窗口大小,该模块自动为目录中文件读写的全流程进行NVDIMM 缓存;另一种是应用通过标准的ioctl 接口以文件为单位进行缓存的动态开关,实现对数据缓存更加精确的控制。
2.2 基于BB 的文件级缓存
基于BB 的文件级缓存模块运行在超算存储服务端,对上兼容POSIX 接口,也作为NVDIMM 块级缓存数据导出和预读的支撑平台,对下访问GFS 和BB 文件系统,支持BB 与GFS 统一名字空间,应用的所有目录操作均由GFS 完成,而对文件数据访问,则提供写缓存和预加载两种策略。在写缓存策略中,应用产生的数据默认写入BB 中,系统将在收到close 操作后将数据由BB 迁移至GFS;而在预加载策略中,文件将在首次读或者收到用户预加载命令后,将文件由GFS 预加载至BB。图4 以文件预加载为例子,说明了文件级透明缓存的流程。

图4 BB 文件级缓存的文件预加载流程Fig.4 Procedure of file proload in BB file-level cache
BB 与GFS 之间的文件迁移完成后,同一个文件在GFS 和BB 中存在两个副本。对于写缓存策略,BB 中的副本在迁移完成后数据将被删除或者设置为只读权限,而对于预加载策略,BB 中的副本只有读权限,文件缓存管理利用一个K-V 库监控存储副本信息,并由缓存文件的属性检查和更新模块监控管理BB 中只读副本与GFS 中副本的属性变化,一旦发现GFS 中的数据被更改或者BB中副本的存储时间超过预设时间,则BB中的只读副本将被删除,从而减少文件副本占用的BB空间,具体原理如图5 所示。

图5 BB 层缓存文件副本的管理流程Fig.5 Management procedure of cache file copies in BB layer
BB 层文件级缓存支持用户通过特定的工具以目录为单位设置缓存管理策略,包括数据迁移的触发条件、副本在BB 中的留存时间等,系统将以目录为单位按照策略进行缓存文件的自动管理,缓存文件管理的过程对应用I/O 过程透明。
3 测试与结果分析
3.1 测试环境
神威系列超算是具有世界影响力的超算平台[30-31],神威E 级原型验证系统是神威面向E 级时代超算技术研制的验证系统,部署于国家超级计算济南中心,其基于国产SW26010Pro 处理器构建[32],每个处理器包含6 个核组,可支持6 路I/O 并发进程,节点之间使用神威网络互连[29],单节点上网带宽达到400 Gb/s以上,可用于I/O的网络带宽超过200 Gb/s。神威E 级原型验证系统的存储系统符合图1 所示的超算存储架构,其中数据转发节点配置了双路服务器CPU,单节点网络带宽为200 Gb/s,并部署了两块NVMe SSD(单块容量为3.2 TB)以构建突发缓冲存储(BB)。全局存储方面利用Lustre 构建了全局文件系统(GFS),利用LWFS 实现了全局文件系统的数据转发。在本文的测试中,由于NVDIMM 硬件针对国产处理器环境的适配仍在实验阶段,因此使用节点DRAM 内存模拟NVDIMM 构建块级缓存。
3.2 测试方法
本文使用IOR Benchmark[33]在神威原型验证系统中测试存储加速技术使用后的带宽变化情况。IOR 测试进程运行在计算节点中,每个测试进程通过本文提出的加速技术读写独立的文件。测试在不修改应用程序数据访问路径的前提下进行,分别测试加速技术启用和不启用时的性能,以对比本文所提技术的透明加速效果。此外,还使用超算典型应用对本文提出的加速技术进行测试。
3.3 测试结果分析
3.3.1 计算节点NVDIMM 块级缓存的测试
NVDIMM 块缓存机制运行在存储系统客户端,由于在高性能应用运行时,NVDIMM 可能有SWAP 空间、应用直接存储数据等多种其他用途,同时为了测试NVDIMM 缓存机制在缓存溢出时的加速效果,选择16 MB 缓存窗口进行测试(单节点4 进程运行时占据的内存为64 MB,考虑常用的国产NVDIMM 单根大小为16 GB,占比为1/256),对比技术为未使用NVDIMM 块缓存的BB 文件系统HadaFS 的常规读写机制,内存刷新和预读块大小为1 MB,选择128 KB 块顺序读写和8 KB 块随机读写两种典型模式,128 KB 块顺序读写单进程数据量为1 GB,8 KB 块随机读写单进程数据量为80 MB,由于NVDIMM 块缓存机制仅作用在客户端,因此测试中服务端固定为一个转发节点。
缓存窗口大小为16 MB 时128 KB 顺序读写带宽的测试结果如图6 所示。随着测试进程数的不断增加,块缓存机制实现了读写带宽的加速。对于写操作:当1、4、16 进程时,块缓存模式写带宽增幅超过40%;当进程超过64 个时,写带宽增幅逐渐降低;当1 024 个进程并发时,增幅为12%;不同进程规模下的平均增幅为36%。出现这种现象的主要原因在于块缓存机制启用后虽然数据写入本地缓存,但是由于缓存窗口大小的限制,并未实现完全的缓存命中。以64 进程为例,写缓存命中率为89%,一旦写缓存未命中,则该请求必须等待缓存队列清空后才能向应用返回,因此影响了性能。此外,测试中计算了文件的close 时间,由于写文件完成后的close 操作需要刷新元数据等信息,因此耗时较长,也一定程度影响了写缓存的总体效果。对于读操作:由于数据预读的块大小为1 MB,128 KB 块读写时缓存命中率最高为87.5%,命中率低于写操作,因此测试的不同进程规模下的平均增幅更小,为27%;随着进程数的不断增加,加速幅度降低的主要原因在于底层存储的性能已经达到峰值,因此每个计算节点端可见的缓存刷新或者预读的速率降低,从而导致缓存命中率降低。

图6 16 MB 缓存窗口时128 KB 块的顺序读写性能Fig.6 Sequential read/write performance of a 128 KB block when the cache window is set to 16 MB
缓存窗口大小为16 MB 时8 KB 随机读写带宽如图7 所示。随着测试进程数的增加,8 KB 随机读写的带宽不断增加,相对HadaFS 常规操作的性能增幅变化与128 KB 块大小顺序读写带宽增幅变化规律相似,在64 进程规模下读写带宽分别提升19%和39%,不同进程规模下的平均增幅分别为20% 和37%。虽然8 KB 随机场景下NVDIMM 缓存机制难以准确预测出读请求的偏移量,但是由于缓存窗口相对于8 KB 块大小比例较高,因此提前读入的数据量大,一定程度上增加了缓存命中的概率,由此保证了读带宽相比未使用缓存机制有所提升。
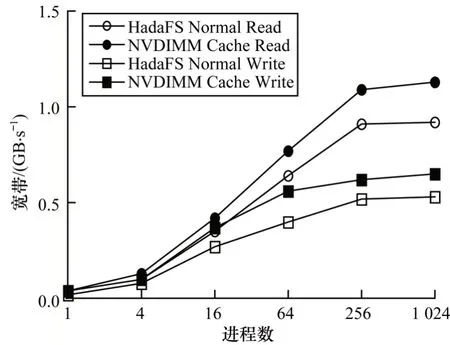
图7 16 MB 缓存窗口8 KB 块的随机读写性能Fig.7 Random read/write performance of an 8 KB block when the cache window is set to 16 MB
固定进程数为1 024,数据块大小为128 KB,每个进程顺序读写1 GB 数据,并按照4 倍比例逐渐增加缓存窗口和数据预读块,测试得到的带宽数据归一化后如图8 所示。随着缓存窗口的不断增大,写缓存命中率不断提升,因此写带宽加速比也不断增加,一旦缓存窗口大小超过写入的数据总量,写缓存的命中率达到100%,写带宽达到峰值,1 GB 窗口下写带宽相比16 MB提升达到10 倍以上。随着缓存窗口、预读数据块大小的不断增加,读带宽也呈现增加趋势,但是增加幅度相对缓慢,这是由于预读数据块大小始终没有超过文件大小。固定测试的进程规模,单进程以8 KB 块随机读写80 MB 数据,在增加缓存窗口时呈现出完全相同的规律,且加速效果更加明显,此处不再赘述。

图8 增加缓存窗口时128 KB 块的顺序读写性能Fig.8 Sequential read/write performance of a 128 KB block when increasing cache window size
以上测试表明,未来随着NVDIMM 等新型存储介质的大规模应用,对于文件大小在NVDIMM 缓存空间内的应用,块缓存机制有望大幅提升应用的数据读写性能,对于那些文件大小超过缓存空间的应用,该机制也具有一定的加速效果。
3.3.2 基于BB 的文件级缓存测试
基于Burst Buffer 的文件级缓存机制运行在BB节点上,负责实现BB 存储的HadaFS 文件系统与底层全局文件系统(GFS)之间的数据统一管理和透明加速。测试使用IOR 程序,分别测试128 KB 顺序读写和8 KB 随机读写两种模式,对比技术为使用磁盘构建的GFS。测试中关闭了计算节点NVDIMM 缓存,测试程序运行在计算节点,分别测试1、16、256、1 024、4 096、8 192 进程规模,128 KB 块顺序读写测试每个进程读写数据量为1 GB,8 KB 块随机读写测试每个进程读写数据量为80 MB,服务端运行在8个转发节点,每个转发节点包含2个NVMe SSD,对比本文提出的BB 级文件缓存功能打开和关闭(相当于使用底层GFS 进行数据读写)时的聚合带宽变化,以测试加速效果。
128 KB 块顺序读写性能如图9 所示。随着进程规模的不断增加,GFS 模式和BB 文件级缓存模式均实现了性能增长,最终在8 192 进程规模下BB 文件级缓存模式的读写带宽相比GFS 提升90%和147%,不同测试规模读写带宽的平均增幅分别为55%和141%。BB 文件级缓存机制使用后,由于BB 文件级缓存空间达到51.2 TB,远大于测试程序产生的数据量,确保了测试中读写数据均实现缓存命中,测试程序产生的文件全部通过SSD 读写,因此,测试程序实际使用的带宽即为BB 层HadaFS 的峰值带宽。事实上,当前几乎所有主流超算在设计时,其BB 层缓存空间基本都能满足应用突发数据的多次写入,可基本保证突发数据的缓存能通过BB 层的要求,提升系统总体I/O 性能。

图9 BB 文件级缓存128 KB 块顺序读写性能Fig.9 Sequential read/write performance of a 128 KB block in BB layer file-level cache
文件级缓存8 KB 块随机读写性能如图10 所示,随着进程数的不断增加,8 KB 块随机读写带宽的变化规律与128 KB 顺序写相似。8 192 进程时8 KB 随机写带宽提升240%,随机读带宽提升220%,不同测试规模下读写带宽的平均增幅分别为163% 和209%,主要原因在于BB 基于SSD 构建,其小块随机读写性能相对于基于磁盘构建的GFS 更具优势。

图10 BB 文件级缓存8 KB 随机读写性能Fig.10 Random read/write performance of an 8 KB block in BB layer file-level cache
3.3.3 实际应用测试
本文提出的透明存储加速机制在神威E 级原型验证系统部署后,为多道应用课题提供了数据加速服务,典型的包括WRF[34]、H5bench[35]等。
WRF 是一种经典的区域数字天气预报系统,通过单进程写出数据。使用本文提出的块级数据缓存技术后,WRF 写数据I/O 带宽提升50%。H5bench 是一种多个进程写同一个文件的经典程序,模拟了VPIC 应用的I/O 流程,需要进行大量数据的读写。使用基于BB 的文件级缓存后,H5bench 性能变化如图11 所示。可以看出:使用BB 文件级缓存后,H5bench 的写性能相比GFS 平均提升3.6 倍,读性能提升1.3 倍,这是由于H5bench 是典型的多进程读写同一文件的应用场景,GFS 在这种场景下由于需要维护严格数据一致性,因此性能开销较大;此外,BB文件缓存的H5bench 最高写带宽为图9 中BB 峰值性能的一半,而读性能达到图9 中BB 所能实现的最高读带宽,原因在于H5bench 是多个进程写同一个文件,在底层BB 端也面临着多个进程写同一个文件的场景,因此性能不如每个进程写独立的文件,由于多个进程读同一个文件时NVMe SSD 底层文件系统缓存作用明显,因此能实现较高读性能。

图11 H5bench 的读写性能Fig.11 Read/write performance of H5bench
4 结束语
E 级时代超算利用不同的存储介质构建了大容量、高性能的多层存储系统,虽然一定程度上满足了应用对于存储容量和性能的需求,但是由于多层存储异构软件使用方式上的差异,难以实现统一名字空间管理和对应用透明的缓存机制。本文针对这一问题提出基于NVDIMM 的块级缓存和基于Burst Buffer 的文件级缓存机制,并在神威E 级原型验证系统中进行部署和测试。测试结果表明,本文提出的技术可以实现应用透明的存储加速。下一步将继续研究多层存储面向应用的资源协调与分配机制,实现多应用共享的存储加速资源动态管理。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
哈尔滨轴承(2020年2期)2020-11-06
中国外汇(2019年20期)2019-11-25
中国外汇(2019年8期)2019-07-13
发明与创新·大科技(2019年12期)2019-03-17
金桥(2018年4期)2018-09-26
中国教育信息化(2015年12期)2015-08-24
中国卫生(2014年5期)2014-11-10
民主与科学(2014年3期)2014-02-28
