
基于暗光环境下光条纹去糊的车牌识别
2022-12-10 10:46赵靖华孙宏宇刘靓葳
吉林大学学报(信息科学版) 2022年5期
李 亮, 鲁 铮, 赵靖华, 孙宏宇, 刘靓葳,2
(1. 吉林师范大学 计算机学院, 吉林 四平 136000; 2. 长春金融高等专科学校 信息技术学院, 长春 130028)
0 引 言
为更好地对车辆进行管理, 提高出行效率和实现交通畅通, 因此对交通进行智能化管理非常必要, 而对车牌识别是实现交通智能化管理的一项关键技术[1]。目前车牌识别的传统方法主要包括车牌定位、 字符分割、 字符识别[2]等步骤。由于字符分割易产生误差影响识别准确率, 因此为优化车牌识别过程, 提高车牌识别的准确性, 定位后直接识别车牌可以有效地解决车牌分割产生的误差等问题。在车牌识别领域中, 从传统的视觉处理方法到目前基于人工智能的算法, 识别效果得到了增强。对车牌定位, Muhammad等[3]提出了一种前景极性检测模型, 能较为精准地确定车牌位置。Zou等[4]基于车牌的字符特征, 提出了一种能激活字符的区域特征鲁棒车牌识别模型。Wang等[5]提出了一种轻量化的车牌定位与识别方法。与传统检测算法相比, 多任务并行处理提高了检测精度和速度。Wang等[6]提出了一种基于小波变换和垂直边缘匹配的车牌识别算法。目前比较成熟的车牌识别算法有基于模板匹配、 机器学习和深度学习[7]3种算法。Li等[8]提出了一种通过单个网络联合可以同时定位车牌和识别字母的深度神经网络, 有效地避免了中间误差的积累, 加快了处理速度。 Pustokhina等[9]提出了一种有效的基于深度学习的VLPR(Vehicle License Plate Recognition)模型, 使用基于最优K-means聚类的分割和基于卷积神经网络(CNN: Convolutional Neural Network)的识别, 在一定程度上具有比其他比较方法更有效的性能。Qin等[10]提出了一种轻量级的、 统一的深度神经网络和高效准确的框架解决车牌检测和识别任务。Zherzdev等[11]提出了由轻量级卷积神经网络组成的LPRNet车牌识别系统。
从上述文献可以看出, 随着车牌识别技术应用越来越广泛, 在人们享受车牌识别技术便利的同时, 但也无法避免车牌识别过程中的诸多困难。由于白天和夜间的街道环境有所不同, 因此在白天, 摄像头可以较清晰的拍摄车牌照片; 而在夜间, 许多关键位置都存在光线不足的问题, 如铁路交叉口、 窄桥或长桥、 隧道等。因此, 由于亮度不足和微弱的对比度使夜间车辆识别比较困难。在真实场景中, 高速公路监控是车牌识别系统的重要应用之一, 它经常捕获包含快速移动车辆的图像。这些车辆图像通常是小物体图像, 在1 920×1 080像素的图像上, 车牌字符的尺寸是119×38 mm左右, 仅占整个图像的0.2%。由于车辆的高速移动, 使捕获清晰车牌图像的成功率降低, 增加了识别难度。因此, 对车牌进行图像增强等操作显得尤为重要。在图像增强方面, Fu等[12]使用DerainNet的深层网络架构去除单个图像中的雨纹, 将输入的雨图像分解为基本层和细节层, 进行图像增强, 提高视觉效果。Hu等[13]采用CNN提出了一种新的具有端到端策略的神经网络架构, 在去噪和保持颜色和纹理的真实性方面有明显的质量优势。Kin等[14]提出了LLNet处理低照度的方法, 基于深度自动编码器的方法识别低亮度图像的信号特征, 从变暗和有噪声的训练样本中自适应地增强和去噪。由于LLNet应用于实际场景下的彩色图像时会产生大量冗余参数, 为此王万良等[15]提出卷积自编码器网络的图像增强方法, 将LLNet方法中的低光处理模块与网络训练进行衔接, 采用卷积网络代替传统自编码器的编码和解码方式, 使网络训练更加高效。Di等[16]提出了一种基于端到端的深度学习架构直接识别车牌, 通过将剩余误差网络、 多尺度网络、 回归网络和分类网络混合的深度架构, 在复杂的环境中得到了很好的识别精度。由于车牌识别场景对算法的特殊要求, 在保证实时性的前提下, 需要一种尽可能提高图像质量的预处理算法。Jin等[17]提出了一种基于雾霾环境下的车牌识别方法, 利用大气光值的局部估计的暗通道先验算法对图像进行初步去模糊, 通过一个卷积增强的超级卷积神经网络完成图像的超分辨率。段宾等[18]提出了一种基于优化卷积生成对抗网络的模糊车牌图像生成和基于深度可分离卷积网络与双向长短时记忆的轻量级车牌识别方法。Wen等[19]提出了一种基于改进的Bernsen算法与高斯滤波器相结合的阴影去除技术和字符识别算法, 并提出了一种适用于低分辨率图像的车牌识别算法。Svoboda等[20]利用盲解卷积算法对模糊图像的锐化图像进行反求, 将字符错误率降低, 提供了更高的重建质量。Zhe等[21]提出利用光条纹进行图像去糊, 使用光条纹作为模糊核估计的去模糊框架, 适用于大部分的暗光场景, 将图像去糊算法应用于车牌识别领域中。虽然这些算法都对车牌图像进行了增强, 但由于拍摄场景的复杂性, 其在弱光低照度条件下的字符识别效果仍然不理想。所以, 笔者针对暗光环境下车牌识别困难的问题, 对文献[21]中的算法进行了改进, 提出了一种基于暗光环境下的车牌识别方法。
1 图像光条纹去糊技术
笔者通过对传统的方法步骤进行描述和分析, 提出了针对改进运动模糊模型的光条纹去糊方法。
1.1 传统光条纹去糊方法
1.1.1 寻找最佳的光条纹补丁
光条纹检测为检测模糊图像中的光条纹进行核估计, 首先检测一组候选图像块, 检测包含用于内核估计的光条纹图像块。通过以下3个步骤实现: 1) 检测一组可能包含亮条纹的候选图像块; 2) 使用基于功率谱的度量选择与底层模糊核最相似的光条纹; 3) 使用所选择的光条纹寻找最佳光条纹补丁, 用于内核估计。从候选光条纹片中仔细找到一个最像底层模糊核心, 在输入图像中近似得到模糊核的功率[22], 通过定义一个基于功率谱的度量标准选择最佳光条纹。自然图像的幂律分布为
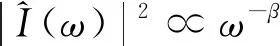
(1)

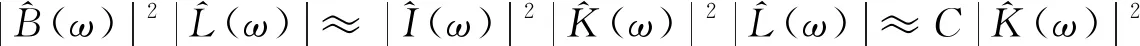
(2)
在空间域中, 有B⊗B*L≈C(K⊗K), 其中⊗为相关算子。因此, 将指标定义为
d(P,B)=minC‖B⊗B*L-C(P⊗P)‖2
(3)

1.1.2 亮条纹的模糊核估计
利用光条纹帮助去模糊弱光图像, 通过对光条纹及其底层光源进行建模, 并将它们作为优化框架中估计模糊核的约束条件。传统的线性运动模糊模型被公式化为B=K*I+N, 其中,B为模糊图像,I为潜在的清晰图像,K为模糊核,N为传感器噪声, *为卷积算子。将观察到的图像B中的像素分成BP,Br,BS3个互补的集合。每个B*分配一个二进制掩码M*, 则B*=M*B。将输入图像引入一个更精确的模糊模型, 如下

(4)

Pi=K*Di+N
(5)
于是, 式(4)中的第1行变为

(6)
利用上述模型, 寻找最能描述观察到的图像和检测到的光条纹的最佳K,Di和I。通过优化能量函数K,Di和I修复和更新
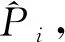
更新Di函数, 对每个选定的光条纹补丁, 估计其原始的非模糊光源。将Di建模为两个参数ti和ri的函数, 这两个参数分别表示强度值和半径。推导出这一步的能量函数
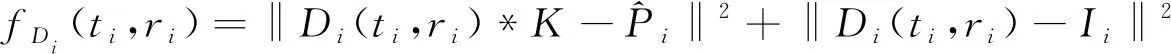
(8)
其中Ii为潜像I中覆盖与Pi相同像素的补丁。对一组离散的ti和ri值进行采样, 找出使fDi(ti,ri)最小的最佳值。更新I函数, 使用模糊核K和光源Di优化能量函数更新潜像I

(9)
其中第3项是Levin等[24]提出的稀疏先验项, 通过IRLS(Iterative Reweighed Least Squares)方法解方程(9)。
1.2 改进亮条纹的模糊核估计
针对光条纹检测问题, 对传统方法的检测光条纹步骤进行改进, 虽然笔者阐述了一种使用光条纹的均匀模糊模型的去模糊算法, 但在实际中, 相机抖动会导致空间变化的模糊效果, 产生不同的模糊形状。为此笔者将通过改进算法扩展到非均匀图像去模糊。简单的传统线性运动模糊模型公式不足以对光条纹的行为进行建模。通过检测到的光条纹, 可以向所有几何非均匀模糊模型添加内核约束, 以局部和稳健的方式计算潜像的初始估计。相机运动被表示为运动密度函数(MDF: Medium Density Fiberboard), 由于相机在每个姿态下所用的曝光时间很少, 称这个比例为相机姿态的密度。这些密度形成了一个运动密度函数, 空间变化的模糊核是直接从中密度函数得到, 由该函数可以直接确定图像上任何点的模糊核。所有相机姿态的中密度函数在相机姿态空间的离散位置上形成一个列向量, 改进后的线性运动模糊模型为

(10)

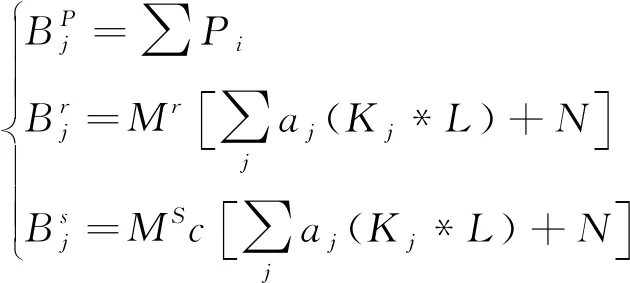
(11)
Pi=Kj*Di+N
(12)
于是, 式(11)中的第1行变成

(13)
利用上述模型, 改进Kj,Di和L能量函数。通过采用广泛使用的交替优化方法实现, 给定3个变量的初始值, 每次固定其中两个, 并优化余下的一个。式(7)改进为
对Kj进行更新, 第3项是边缘提取不可避免地受到饱和区域和光条纹的影响, 检测到的光条纹用于约束调整相机运动的权重估计, 用共轭梯度下降法最小化上述方程。利用在相应位置使用j推断的局部模糊核更新Di。第4项是Kj上的先验, 由(13)导出。更新Di函数

(15)
其中Li为潜像L中覆盖与Pi相同像素的补丁。补丁通常很小, 强度很高, 因此通过采样的方式找出使fDi(ti,ri)达到最小的最佳值。更新L函数

(16)
其中第1项对应式(15)中的第2项。第2项是从模糊模型中导出的数据项。第3项是稀疏先验项,α=0.8,φ为正则项的权重, 此处设φ=0.005。通过给小梯度分配线性惩罚, 给大梯度分配二次惩罚, 并近似自然图像的梯度分布先验。
2 改进光条纹去糊方法的试验评估
针对夜间车牌识别, 传统的光条纹去糊方法, 工作流程如图1所示。经过光条纹提取、 带光条纹的核估计等步骤, 光条纹的提取步骤存在问题, 检测到的最佳光条纹出现在车辆的后视镜上, 会对车牌去糊结果造成影响。光条纹去糊系统由光条纹提取和核估计组成。通过对低照度图像的光条纹提取, 选取最佳的光条纹作为模糊核进行估计, 具体效果如图1所示。

图1 光条纹去糊实现效果Fig.1 Light streak deblurring effect
图2是笔者提出改进的光条纹去糊试验效果, 通过图2b和图3a对比可看出, 改进光条纹线性运动模糊模型, 在提取光条纹中能更精确的定位到光条纹的位置, 得到更准确的最佳光条纹。
改进后的去糊结果如图3b所示, 通过对比图2b和图3b的去糊结果可看出, 改进前的方法对所选择的输入块敏感, 并对检测到的非饱和光条纹表现良好, 但对其他手动选择的图像块无效。对饱和像素, 笔者的方法提出的优化方案生成更高质量的去模糊图像。

图2 改进后的光条纹去糊试验效果Fig.2 The effect of the improved light streak deblurring test
通过对其他暗光车牌图像进行改进前后的图像恢复实验, 进一步验证试验效果, 对比结果如图3所示, 可看出改进后的图像具有更好的对比度和清晰度。
改进后的光条纹去糊算法能从视觉质量的角度更准确地估计核和去模糊图像。现有方法在弱光图像上表现不佳, 这是由于核估计识别的突出边缘数量不足。而改进后的算法能估计更精确的模糊核, 生成更清晰的去模糊图像。

图3 改进前和改进后的图像去糊结果Fig.3 Image deblurring results before and after improvement
3 整体的车牌识别方法及车牌数据集实现效果
笔者的车牌识别方法分为2部分: 车牌定位和车牌识别。由于字符分割会影响识别率, 为消除误差和减少处理时间, 采用免分割的车牌识别方法。
3.1 整体的车牌识别方法
笔者针对低照度环境下识别困难等问题, 提出了一种端到端的车牌识别研究方法。该算法利用改进的运动模糊模型将重点研究光条纹去糊模块, 并利用相机密度函数进行对模糊核进一步估计, 得到更准确的光条纹位置。笔者将此算法改进并应用于车牌识别领域中, 其车牌识别步骤如图4所示。首先, 将暗光下车牌图像送入光条纹去糊模块, 通过对光条纹提取、 光条纹内核估计进行去糊操作, 为后面的定位识别做准备; 然后, 将增强后的图片送入统一的定位识别框架进行训练与识别。

图4 暗光下光条纹去糊的车牌识别步骤Fig.4 The steps of license plate recognition with light streak de-paste under dark light

图5 U-Net网络车牌定位示例Fig.5 U-Net network license plate location example
在车牌定位阶段采用U-Net[25]网络进行定位, 示例如图5所示。在矫正中加入了矫正函数, 该函数通过cv2对车牌图像区域进行边缘检测, 获取车牌区域的边缘坐标和最小外接矩形4个端点坐标, 再计算出和最小外接矩形4个端点最近的点即为平行四边形车牌的4个端点, 从而实现车牌的定位和矫正。通过计算坐标点到上下两条边的距离, 并添加了权重, 经过调整权重设置为0.975倍的点线距离, 0.025点到端点距离时整体效果较佳, 最终效果如图6所示。车牌识别方法采用CNN[26]网络结构, 具体结构如图7所示。

图6 矫正前后对比图Fig.6 Before and after correction comparison chart
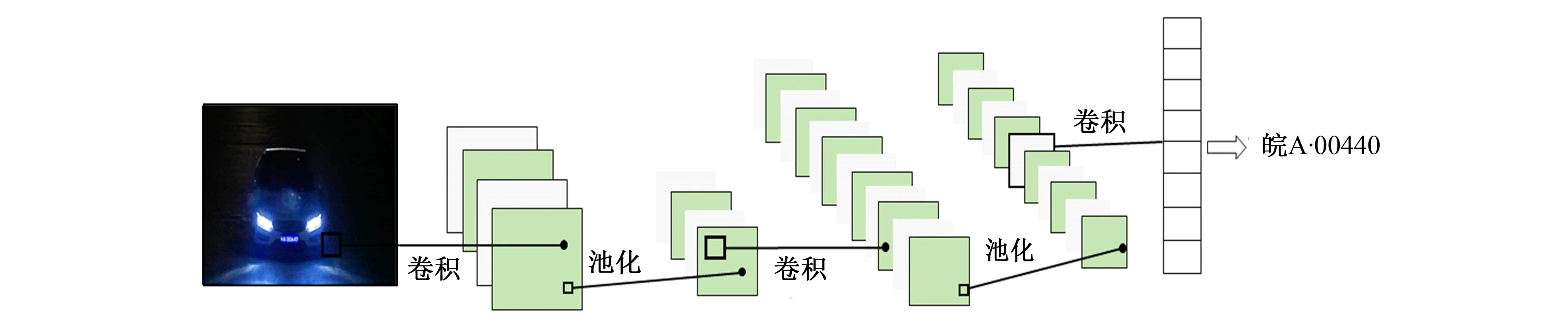
图7 CNN网络结构Fig.7 CNN network structure
3.2 车牌数据集的试验分析
通过对比图像质量评价指标峰值信噪比(PSNR: Peak Signal to Noise Ratio)、 平均模糊核相似度[27-30]和识别准确率, 进行3组实验, 进而达到更精准的试验结果。实验环境为Intel(R) Core(TM) i7-6700 CPU@3.40 GHz处理器, Windows10操作系统, 在Python3.7和Matlab 2019a中实现。通过将暗光数据集添加运动模糊, 对比不同算法在模糊程度不同数据集下的峰值信噪比和核相似度, 最后对比车牌字符识别的准确率, 证明该算法的可行性。
对真实数据集图片进行运动模糊处理, 通过变换运动模糊核的矩阵参数调节运动模糊程度(degree), 参数越高模糊程度越大。采用PSNR的指标评价图像质量, PSNR是最广泛使用的评价图像质量的客观标准, 是一种全参考的图像质量评价指标。其值越高, 图像失真越小, 图像增强效果越好。将直方图均衡算法(HE: Histogram Equalization)、 粒子群(PSO: Particle Swarm Optimization)、 Retinex与笔者所提算法的峰值信噪比进行比较, 通过对数据集添加不同模糊程度的参数, 比较各算法的PSNR。从图8可以看出, Retinex方法的PSNR值随模糊程度的增加, 在模糊程度20之后会出现增长。HE方法的PSNR值对模糊程度不敏感。PSO方法与Retinex方法表现类似, 只不过在模糊程度20之后, PSNR值增长的幅度有限。笔者提出的方法PSNR值整体都要高于其他方法, 并且在模糊程度20时最低, 在30时达到最高。表明笔者所提算法能在增强图像同时较好地抑制噪声干扰。
通过对模糊程度为20的数据集进行核相似性的定量比较和定量评估, 对比不同算法之间的平均模糊核相似度, 即描述了估计核和基本核之间的相似度。如表1所示, 作为有效利用光条纹的结果, 所提出的算法在去模糊弱光图像方面优于现有方法。

表1 不同算法的平均核相似度
实验数据均来自当地真实场景抓拍图片, 在桥下抓拍了500张图片, 在车牌定位识别阶段选取了CCPD数据集中33 000张车牌图片进行模型训练, 选取100张暗光场景抓拍图片进行测试。为验证笔者提出的基于暗光环境下光条纹去糊的车牌识别方法的有效性, 将笔者所提方法与未去糊的车牌识别方法、 传统车牌识别OpenCV方法进行对比验证, 通过将数据集添加10~40的运动模糊参数, 对比各算法的识别率。结果如图9所示, 在运动模糊参数为10~20时, 各算法的识别率多数可以超过80%, 但在运动模糊参数为30~40时, 各算法的识别率都不理想。通过结果对比, 在运动模糊参数为10时, 改进后的去糊方法比OpenCV方法识别率提升了22.6%, 运动模糊参数为20时, 识别率提升了30.3%, 运动模糊参数为30时, 识别率提升了65.9%, 运动模糊参数为40时, 识别率提升了55.2%。可以看出笔者所提方法的车牌识别率优于其他对比算法。
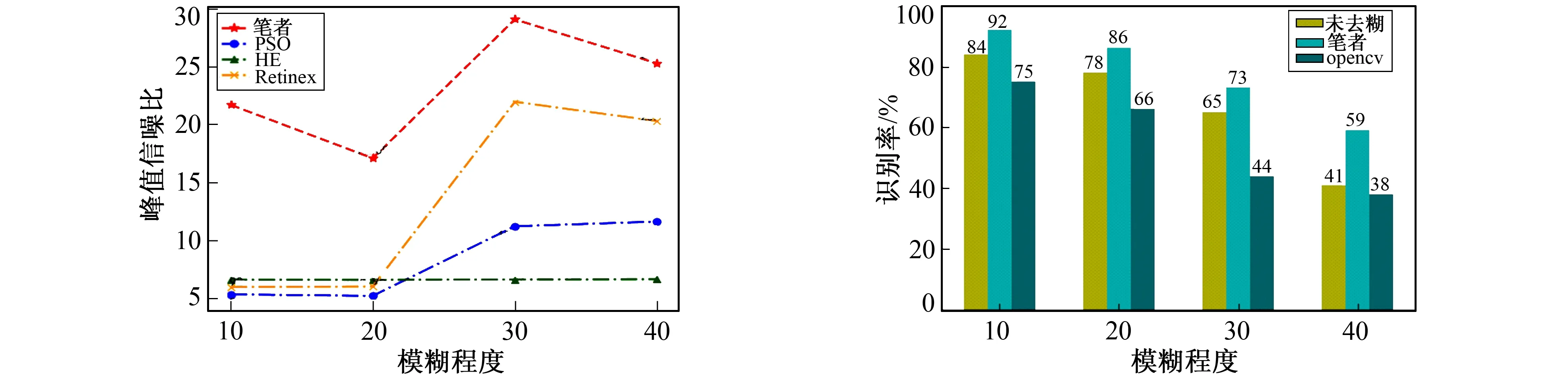
图8 各算法峰值信噪比对比 图9 各算法识别率对比 Fig.8 Comparison of peak signal-to-noise ratio by algorithm Fig.9 Comparison of recognition rates by algorithm
4 结 语
针对暗光环境下车牌图片识别效果差, 高速运动下车牌图片模糊等问题, 导致难以提高车牌识别准确率, 笔者提出了基于暗光环境下光条纹去糊的识别方法。实验采用抓拍数据集, 将所提算法与直方图均衡算法(HE)、 粒子群(PSO)、 Retinex图像增强算法的峰值信噪比进行比较。实验结果表明, 相比于其他图像增强算法, 笔者算法具有很好的鲁棒性, 能在进行增强图像的同时较好地抑制噪声干扰。将笔者所提算法与未去糊识别算法、 传统OpenCV算法进行对比, 实验结果表明, 笔者提出的方法相比于其他识别算法具有一定的优越性, 在不同模糊程度的数据集上都有较好表现, 去糊前后的识别率在模糊程度至少提高了22.6%。在一定程度上解决了由于暗光环境下字符识别准确率低等问题, 具有广泛的应用场景。
猜你喜欢
家教世界·创新阅读(2020年8期)2020-08-13
当代美术家(2020年6期)2020-05-10
小福尔摩斯(2019年2期)2019-09-10
电子制作(2019年12期)2019-07-16
小学生必读(低年级版)(2019年9期)2019-04-13
小学生必读(低年级版)(2019年10期)2019-04-13
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
娃娃画报(2014年9期)2014-10-15
环球时报(2009-03-03)2009-03-03
