
基于部分迁移学习的皮肤病图像分类
2022-12-04 12:06陈明海贺建峰
生物医学工程与临床 2022年3期
陈明海,贺建峰
皮肤癌是一种比较常见的癌症。数据表明全球每年有大约300万例皮肤癌发生,每3例癌症患者中就有1例是皮肤癌患者[1]。皮肤病的早期发现可以让患者得到及时治疗并避免病情的进一步恶化,还可以降低致死率[2]。有些皮肤病,比如黑色素瘤(melanoma,MEL)和黑色素细胞痣(melanocytic nevi,NV),从表面看非常相似,医生在诊断这类疾病时极易混淆[3]。另外,医生在诊断疾病时还有可能受到一些非主观因素的影响,比如眼疲劳等,对患者造成误诊[4]。
为了解决上述问题,研究人员利用数字图像处理技术辅助医生诊断。Celebi ME等[5]采用基于阈值分割算法对MEL图像进行分割,然后从分割的病变区域中选取病兆特征,并训练支持向量机(support vector machine,SVM)分类器对MEL进行识别,实验证明该方法有较好的效果。Ganster H等[6]和She Z等[7]采用皮肤病诊断常用的ABCD(asymmetry,border,color,diameter)准则对皮肤病图像提取特征,从恶性MEL中检测出良性病变,诊断精确度达到85%~91%。以上这些方法在提取图像特征过程中,存在着过程复杂、特征提取不够精细的不足。
近年来,随着深度学习技术的发展,研究人员把深度学习技术应用到皮肤病的辅助诊断中。Yu L等[8]采用了一种深度卷积神经网络对MEL进行识别,利用残差网络处理过拟合和模型退化问题,设计了一种全卷积残差网络对图像进行分类,精确度平均达到85.5%。Codella N等[9]采用了稀疏编码、深度学习和SVM相结合的方法对3类皮肤病图像进行分类,分类精度达到了93.1%。以上方法均用到了深度学习的方法,但是一般的深度神经网络对训练模型用的数据集都有着严格要求,比如数据集要足够大、数据样本要有标注等,这对一些数据量较小或者无标注的数据集,在训练时很难达到相应的效果。正是因为上述原因,研究人员采用了训练神经网络时对数据集没有以上严格要求的迁移学习[10]方法。Esteva A等[11]采用迁移学习方法,在网络模型Inception V3的基础上微调,然后对网络模型进行端到端训练,对3类皮肤病进行分类。分类精度达到了71.2%。Brinker TJ等[12]分别在网络模型VGG16和GoogleNet基础上进行迁移学习对皮肤病分类,分类精度分别达到了79.7%和81.5%。董青青[13]在网络模型DenseNet基础上进行二次迁移学习,对ISIC2017数据集进行分类,分类精确度达到了85.15%。Honsny KM等[14]在网络模型AlexNet基础上迁移学习,对ISIC2018数据集进行分类,其精确度、灵敏度、特异度及准确度分别达到了98.7%、95.6%、99.27%和95.06%。以上传统迁移学习方法都是在已有网络模型基础上进行微调来迁移,所利用网络模型的预训练参数是在与皮肤病数据集相似度很低的数据集上训练得到的,很容易把不相关的特征迁移到目标域上,导致负迁移现象的产生,从而降低了训练网络模型的性能。
为减少在传统迁移学习方法中存在的负迁移现象,笔者提出了一种基于部分迁移学习[15]的皮肤病图像分类方法。
1 材料与方法
1.1 实验材料
1.1.1 实验环境
该实验的环境配置如下:CPU i7;内存64 GB;GPU GeForce RTX2080Ti;显存11 GB。操作系 统Windows10 Professional;深度学习框架PyTorch 1.2。
1.1.2 实验数据集
实验采用的数据集是由国际皮肤成像协会(International Skin Imaging Collaboration,ISIC)提 供 的ISIC2018和ISIC2019数据集。ISIC2018数据集光化角化病(actinic keratoses,AKIEC)图像327幅,良性角化病(benign keratosis-like lesions,BKL)图像1 099幅,基底细胞癌(basal cell carcinoma,BCC)图像514幅,皮肤纤维瘤(dermatofibroma,DF)图像115幅,MEL图像1 113幅,NV图像6 705幅,血管病变(vascular lesions,VASC)图像142幅,鳞状细胞癌(squamous cell carcinoma,SCC)图像0幅,合计10 015幅。ISIC2019数据集AKIEC图像867幅,BKL图像2 624幅,BCC图像3 323幅,DF图像239幅,MEL图像4 522幅,NV图 像12 875幅,VASC图 像253幅,SCC图 像628幅,合计25 331幅。
数据集ISIC2018和ISIC2019共有的图像类别有7类,前者的类别是后者类别的真子集,符合部分迁移学习对源域和目标域数据样本类别数目的要求。根据部分迁移学习对源域和目标域数据集的要求,把包含8类图像的ISIC2019数据集作为源域数据集,把包含7类图像的ISIC2018数据集作为目标域数据集。
从两个数据集中每个类别的数量上可以看出,类别之间图像数量存在严重不平衡的情况。比如ISIC2018数据集中NV类包含6 705幅图像,而DF类仅有115幅图像。类别之间图像数量的不平衡会降低神经网络的分类性能。为了解决图像类别之间数据不平衡的问题,采用对数据集扩增的方法。数据扩增主要是通过对图像进行翻转及0°~355°的随机旋转等几何变换来实现。在对ISIC2019数据集扩增的时候,考虑到NV类有12 875幅图像,已经有足够的图像数量用于训练,无需再进行扩增。其余类别均扩增到10 000幅左右。在对ISIC2018数据集扩增的时候,是对所有的类别都进行了扩增,每一类别扩增后的图像均达到10 000幅左右。
1.2 方法
1.2.1 问题的提出
迁移学习方法中有一个源域和一个目标域。目前大部分迁移学习算法假设源域和目标域有着相同的标签空间,但实际应用中这样的条件很难达到,更多的情况是目标域的标签空间是源域标签空间的子集。通常需要把一个模型从一个大规模数据集(e.g.ImageNet)迁移到一个小规模数据集(e.g.Caltech256)上。假设源域目标域其中表示源域Ds中的数据样本表示对应的类别;ns表示源域Ds中带有标签的样本数目表示目标域Dt中的数据样本;nt表示目标域Dt中无标签的样本数目。假设源域和目标域数据样本类别数目分别是Cs和Ct。在实验提出的部分迁移学习应用场景中,二者存在如下关系:Cs>Ct。源域和目标域中数据样本分别有着不同的概率分布p和q。在传统的迁移学习中有p≠q,但是在部分迁移学习中更进一步,有着这里pCt表示源域中属于目标域的数据样本类别的概率分布。笔者的目标是设计一个深度神经网络,不但能够学习可迁移的特征,而且可以让那些仅属于源域的数据在迁移过程中造成的负迁移现象降到最低。
在传统的迁移学习中,一个主要的挑战是目标域数据无标注,加之源域和目标域数据样本有着不同的概率分布,因此在源域上训练好的分类器不能直接用到目标域上。在部分迁移学习中,存在的另一个更加困难的问题是甚至不知道源域中哪一部分数据样本和目标域数据样本有着共同的标签空间。以上存在的问题导致的结果是:①仅存于源域中的数据样本在整个迁移过程中导致负迁移的发生,从而影响整个迁移的性能;②减小源域中和目标域属于共同类别数据样本的分布差异成为迁移学习的关键。为避免上述结果对网络最终分类性能的影响,实验采用了通过选择性对抗网络实现的部分迁移学习方法。
1.2.2 域对抗网络
域对抗网络[16]通过提取可迁移的特征减少源域和目标域的分布差异,这种方法被成功地应用到迁移学习当中。对抗学习过程是一个双人游戏。第一个游戏者是域判别器Gd,域判别器负责分辨数据样本是来自源域还是目标域。第二个游戏者是特征提取器Gf,特征提取器负责提取源域和目标域的特征迷惑域判别器。为了提取域不变特征f,通过最大化域判别器Gd的损失学习特征提取器Gf的参数θf,同时,通过最小化域判别器Gd的损失学习域判别器参数θd。另外,也要让标签预测器Gy的损失最小化。最终,域对抗网络[16]的目标函数如(1)式所示:
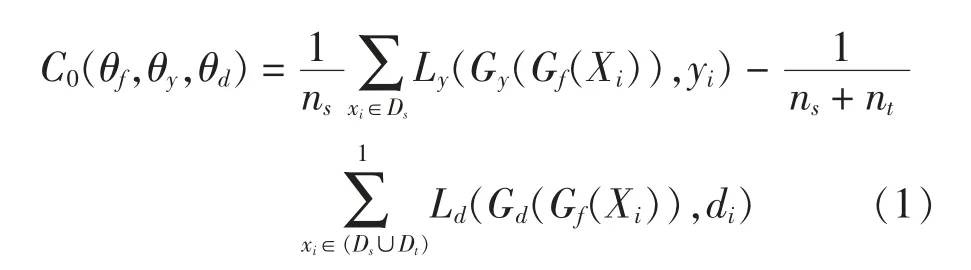
公式(1)中:λ是实现上述目标的调和参数。模型训练收敛后,将会由参数得到函数(1)的一个鞍点,如(2)式所示:
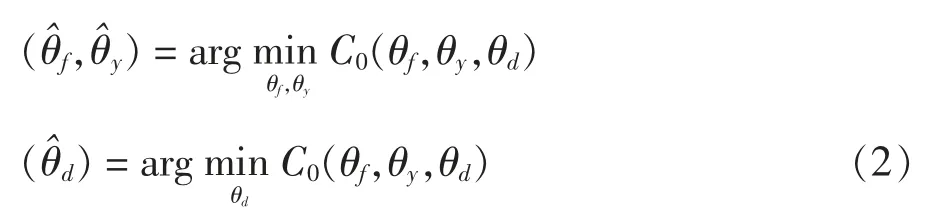
域对抗网络在传统的迁移学习中,在源域和目标域标签空间相同,即Cs=Ct的条件下有着很好的性能。
1.2.3 选择性对抗网络
在部分迁移学习中,没有了上述域对抗网络中的Cs=Ct的条件,目标域的标签空间是源域标签空间的子集,即Cs⊂Ct,因此如果再匹配整个源域的概率分布p和目标域的概率分布q,将会因为仅存于源域中的数据样本的存在而造成负迁移现象的产生。为了降低负迁移现象的产生,在进行域对抗适应的过程中必须过滤掉那些仅存于源域中的数据样本。
为了匹配源域和目标域不同的标签空间,需要把(1)式中的域判别器Gd划分为Cs个类级别的域判别器,k=1,…,Cs,每一个判别器负责匹配源域与目标域中的第k类数据样本(图1)。

图1 部分迁移学习的选择性对抗网络结构Fig.1 Selective adversarial network structure diagram of partial transfer learning
因为目标域数据样本无标注,所以在模型训练期间,目标域的标签空间是不可访问的。这样就很难决定哪一个域判别器(k=1,…,Cs)负责对目标域的数据样本进行判别。但是,观察到标签预测器yi=Gy(Xi)对于每一个数据样本的输出是在整个源域标签空间上的概率分布。这个概率正好能说明Xi属于Cs类中某一类的概率。因此,就用作为每一个数据样本Xi被分配到Cs个域判别器的概率。每一个数据样本被分配到不同的判别器可以通过(3)式所示的概率权重域判别器损失来实现。
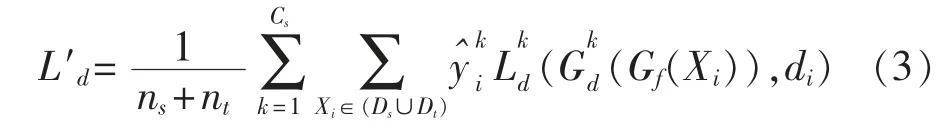
在(3)式中:是第k个域判别器;是其交叉熵损失;di是数据样本的域标签。与(1)式中单个判别器的域对抗网络相比,实验提出的算法可以实现更加细粒度的域适应,让每一个样本点只与自己相关的域判别器进行匹配。这种细粒度的域适应有三个优点:①避免了硬性的把每个数据样本指派给一个域判别器,这种硬性的指派对目标域来讲是不准确的;②通过过滤掉不相关类别的数据样本,减少了负迁移;③概率权重域判别器分配不同的损失给不同的域判别器,使得不同的判别器学习到不同的参数,促进了每个数据样本的正向迁移。
除了上述样本级别的权重机制,实验还采用了类级别的权重方法来进一步地降低仅存在于源域中的数据类别样本造成的负迁移。注意到只有负责对目标域类别进行判别的判别器对促进正向迁移是有效的,其他的判别器在迁移过程中只会带来噪声,降低正向迁移的性能。因此需要降低那些仅负责判别只存在于源域中的数据样本类别的判别器的权重。因为目标域的数据样本属于仅存于源域中的那部分数据样本类别的可能性较小,所以可以降低那些仅负责只存于源域中数据样本类别判断的判别器的权重,如(4)式所示。

尽管(4)式中的域判别器可以通过降低仅存在于源域中的数据造成的负迁移现象实现了选择性地迁移相关知识,但是这些判别器主要依靠的是概率=Gy(Xi)。因此进一步地利用促进类间低密度分离的熵最小化原则[17]来改进标签预测器Gy。通过最小化数据样本Xi在目标域Dt上的概率的条件熵来实现上述要求,如(5)式所示。
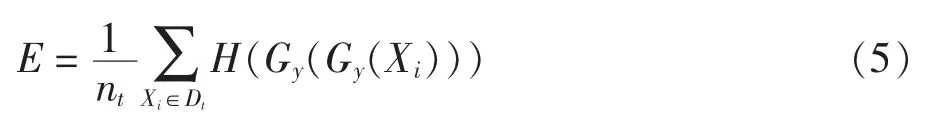
综上所述,选择性对抗网络最终的目标函数如(6)式所示。
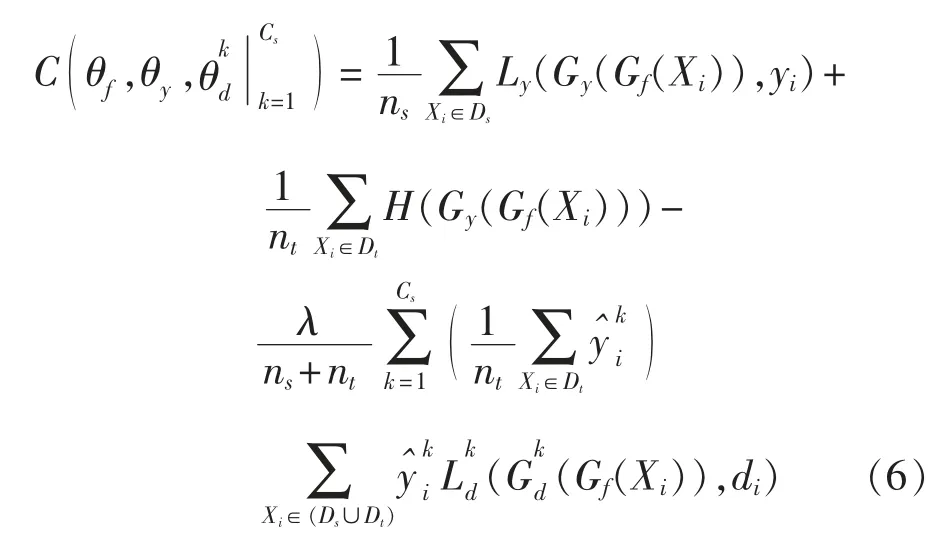
其中:λ是一个超参数,在上述的联合优化问题中用来调和两个目标。整个优化的问题的目标就是找到满足(7)式的参数(k=1,2,…,Cs)。

选择性对抗网络通过过滤掉仅存于源域的数据样本类别成功地实现了部分迁移学习,同时在共享标签空间Ct上最大化地匹配数据分布pCt和q,从而更加促进了正向迁移。
1.2.4 实验与分析
1.2.4.1 网络模型的训练 在PyTorch深度学习框架中应用实验提出的方法来训练网络模型。因为实验的目标是对包含7类皮肤病图像的ISIC2018数据集进行分类。实验采用ResNet网络模型作为基础网络模型,对最后的全连接层和分类层进行微调,并采用ResNet在大型数据集ImageNet上训练的参数作为预训练参数。对于选择性对抗网络,实验微调了所有的特征层、分类层和对抗层。因为这些网络都是从头开始训练,所以把这些层的学习率设置为其他层的10倍。因为所用数据集不同的图像类别之间存在严重的数量不平衡现象,注意到Focal Loss损失函数[18]主要用来解决样本比例严重失衡的问题,因此在计算每个类别判别器的损失时,用Focal Loss代替了交叉熵损失函数。
1.2.4.2 图像分类实验 针对实验提出的部分迁移学习皮肤病图像分类算法,做了两组实验。①在部分迁移学习时,采用类级别的域判别器过滤掉仅存于源域中的数据样本类别。单个类级别域判别器的损失函数采用交叉熵损失函数;提取特征时采用ResNet作为基础网络模型,并针对要分类的目标数据集ISIC2018对ResNet进行微调(实验1)。②在实验1的基础上,把单个类级别域判别器的损失函数替换为Focal Loss损失函数;提取特征时针对要分类的目标数据集ISIC2018对ResNet网络模型进行微调(实验2)。并与Honsny KM等[14]结果进行对比。
1.2.4.3 评价指标 实验采用了图像分类中常用的4种评价指标对实验结果进行评价。这4种评价指标分别是精确度(accuracy)、灵敏度(sensitivity)、特异度(specificity)、准确度(precision)。


其中:tp、fp、fn、tn分别表示真阳性(true positive)、假阳性(false positive)、假阴性(false negative)、真阴性(true negative)的数目。
2 结果
2.1 ResNet网络模型与Honsny KM结果比较
第1组实验的结果中,精确度、灵敏度、特异度及准确度分别是99.13%、96.99%、99.45%和97.12%;第2组实验结果中上述指标分别是99.24%、97.73%、99.56%和97.32%。实验结果与Honsny KM等[14]结果对比,数值接近。见表1。
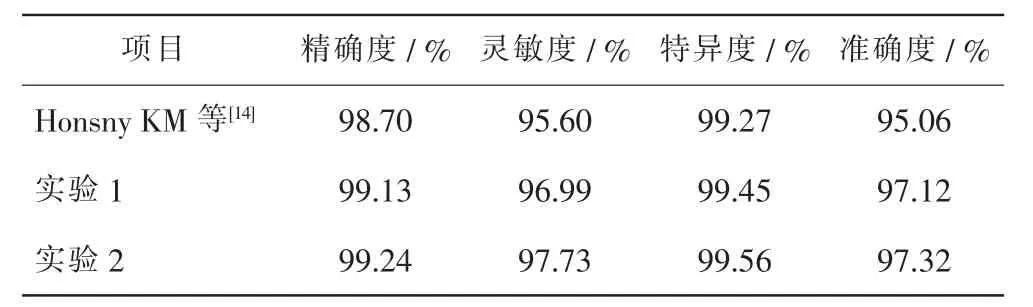
表1 两组实验结果与Honsny KM结果对比Tab.1 Comparison of results between 2 experimental groups and Honsny KM
2.2 混淆矩阵评价结果
混淆矩阵是评价图像分类结果的一个常用方法,实验1与实验2从混淆矩阵中可以清楚地看出每一类图像的分类结果基本相似。见图2。
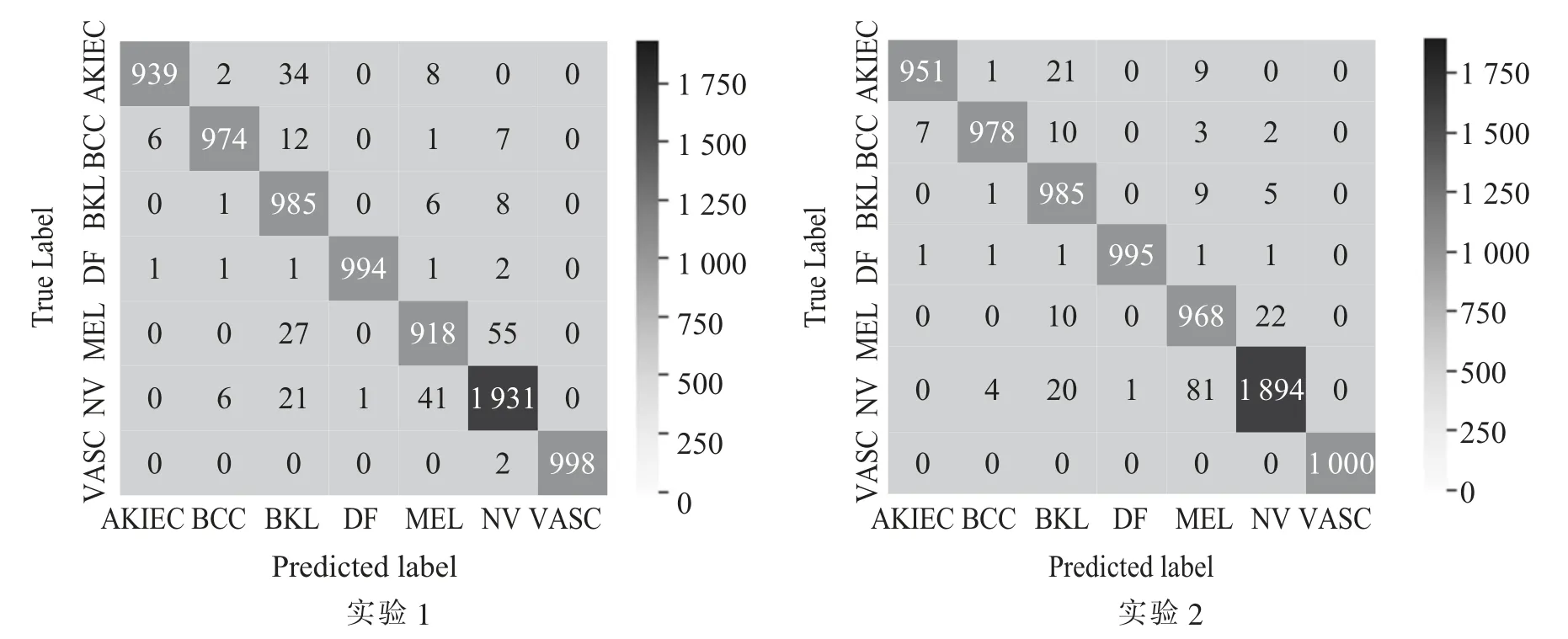
图2 实验1和实验2混淆矩阵Fig.2 Confusion matrix graph of experiment No.1 and experiment No.2
3 讨论
传统迁移学习把已有网络模型学习到的知识迁移到新的领域中加以利用,可以节省新模型的训练时间,但是在迁移过程中极易造成负迁移现象的产生。笔者通过引入选择性对抗网络进行部分迁移,降低了负迁移现象的产生,提高了图像的分类精度。实验中特征提取时采用ResNet网络模型,使得提取的特征更加丰富,但是比采用层次浅的网络训练时间会长一些。从实验结果可以看出,4项指标均比传统迁移学习方法有了显著提高。
从实验结果来看,采用实验提出的部分迁移学习方法,因为规避了传统迁移学习方法中容易出现的负迁移现象,降低了负迁移对网络性能的影响;又通过降低仅存于源域数据的判别器的权重促进了正向迁移,实验结果相比Honsny KM等[14]采用的传统迁移学习方法有明显的提升。另外,提取图像特征的时候,在ResNet的基础上进行迁移,并且采用了ResNet的预训练参数。因为ResNet是在ImageNet数据集上训练的模型,ImageNet数据集中每类图像的数量相对比较均衡,而笔者实验采用的数据集都存在着严重的图像类别之间数量的严重失衡的问题,所以实验采用了Focal Loss损失函数,从实验结果看,相比采用图像分类常用的交叉熵损失函数也有着一定的改善。如何降低迁移学习中的负迁移现象和如何通过少样本训练出精度高的网络模型依然值得深入研究。
4 结论
笔者提出的基于部分迁移学习的皮肤病图像分类算法降低了传统迁移学习算法中极易出现的负迁移现象,同时通过最大化地匹配源域和目标域共享标签空间促进了正向迁移。实验表明,该方法优于传统的迁移学习方法。一个值得注意的问题是,目前在对皮肤病分类实验中,采用数据集中的皮肤病图像大部分来自欧洲及北美的白种人[19],为了提高分类器的泛化能力,还需要针对不同种族人群的皮肤病图像进行深入研究。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
计算机技术与发展(2020年11期)2020-12-04
少儿画王(3-6岁)(2020年4期)2020-09-13
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
青年文学家(2015年29期)2016-05-09
西南学林(2011年0期)2011-11-12
微型计算机(2009年4期)2009-12-23
