
基于双视图故障特征提取的列控车载设备故障诊断方法
2022-12-02 11:49上官伟邢玉龙蔡伯根
铁道学报 2022年11期
彭 聪,上官伟,2,邢玉龙,蔡伯根,2
(1.北京交通大学 电子信息工程学院, 北京 100044;2.北京交通大学 轨道交通控制与安全国家重点实验室,北京 100044)
我国《中长期铁路规划网》(2016—2030)中规划了“八纵八横”的高速铁路网,“交通强国”战略引领我国高速铁路发展进入新的阶段,更高的效率、更优越的系统性能对高速列车的运行安全提出了更加严苛的要求。
列车运行控制系统是高速铁路系统的核心组成,车载设备是保障列车运行控制系统功能正常实现的必不可少的部分。车载设备组成部件众多,结构复杂,且各单元之间信息交互频繁,快速、高效地实现车载设备的故障诊断对保证列车运行安全具有重大意义。
故障诊断是确定故障位置及类型的过程。故障诊断算法可以分为基于知识的方法、基于模型的算法、基于信号的方法和基于数据驱动的方法[1-2]。鉴于车载设备的复杂性,近年来,利用数据挖掘技术基于数据驱动对车载设备文本数据进行故障特征提取,进而实现对车载设备的故障诊断成为当前车载设备故障诊断的研究方向。文献[3]使用属性简约后的车载设备故障数据训练贝叶斯算法,以此构建分类模型,实现车载设备的故障诊断。文献[4]利用铁路维护部门的故障文本数据,改进主题模型进行故障特征提取,使用支持向量机对故障模式进行分类,实现车载设备的故障诊断。文献[5]利用卷积神经网络实现车载日志内部特征提取,结合代价敏感学习的随机森林算法对不均衡数据进行处理,对所提取特征进行分类,实现车载设备故障诊断。文献[6]提出一种贝叶斯网络与粗糙集模型约简技术相融合的故障诊断方法。文献[7]针对文本数据的不规则性,使用主题模型进行特征提取,采用贝叶斯网络算法实现车载设备的故障诊断。文献[8]使用主题模型对日志数据的语义特征进行特征提取,采用基于粒子群优化的支持向量机对日志文本的故障进行分类,实现车载设备的故障诊断。文献[9]以车载设备中应答器信息接收模块BTM故障文本数据作为样本,提出一种基于粗糙集和改进布谷鸟搜索算法优化神经网络的列控车载设备故障诊断方法。上述方法在一定程度上可以实现车载设备的故障诊断,但也存在一定的弊端,主要体现在:故障特征提取的过程没有考虑实际情况中出现的故障模式分布不平衡问题;大多数研究均采用浅层模型对故障特征进行特征提取,忽略了语序、句序对故障特征提取的影响,对故障特征提取不充分,使得分类器的性能下降,降低了故障诊断的精度。
为此,本文在对车载设备故障文本数据进行分析,以及总结目前故障特征提取过程中存在问题的基础上,提出一种基于双视图故障特征提取的列控系统车载设备故障诊断方法。首先在两个不同的视图下分别对故障文本数据进行故障特征提取;然后利用PCA技术[10]对两者进行融合,得到可以用于学习的PCA特征集合;最后将该特征集合注入极端梯度提升[11](eXtreme Gradient Boosting,XGBoost)分类器进行训练,对不平衡的故障模式进行分类,从而实现车载设备的故障诊断。该方法不仅解决了故障模式分布不平衡问题,也解决了故障特征提取不充分问题,同时通过PCA技术对级联后故障特征集合进行降维,还解决了故障特征维度高问题。相比于传统的故障特征提取方法,本文方法可以充分准确地提取故障特征,在提高分类器分类性能的同时也提高了故障诊断的分类精度。
1 车载设备故障数据分析
目前CTCS-3级列控系统的车载设备主要有300T、300S和300H三种类型,其中300T型车载设备应用于武广客专、哈大客专、京石武客专等多条线路,应用范围广,因此本文选取300T型车载设备作为研究对象。
在列车运行过程中,车载设备会产生大量运行日志数据,故障类型繁杂,归结起来分为三类:硬件故障、软件故障和外部环境干扰故障[12]。为了有效记录系统运行的状态数据,专门在车载设备中开辟了非易失存储区,用于记录系统的运行状态。对于300T型车载设备,其故障数据主要为AE-Log文件,记录列车在运行过程中车载设备的启机成功、测试完成等重要进程事件,以及测试失败、系统异常等故障事件。
由于AE-Log文件中的故障数据是以文本形式进行存储,无法直接对其进行分析诊断,因此需要对故障数据进行预处理。故障数据预处理是指对故障文本数据进行标准化和规范化处理,使之转换成计算机可以识别的形式,以供后续进行特征提取。预处理操作主要包括删除特殊字符、单词规范化、分词等。其中,单词规范化是将单词小写化、提取词干;分词是利用英文中的空格和标点符号作为分隔符来得到单词;删除特殊字符是对除英文字符、数字之外的其他字符进行过滤筛选。
目前,从300T型车载设备AE-Log文件中提取的故障特征存在以下问题:
(1)故障模式分布不平衡。通过对车载设备故障模式的统计,发现某一类故障数量(大类)要远远大于另一类故障数量(小类),使用这样的不平衡数据集进行故障诊断,分类器容易将小类别故障类型误诊为大类别故障类型,使分类性能下降。
(2)故障特征提取不充分。传统的特征提取模式忽略了故障文本数据语序对其特征集合的影响,故障特征提取不充分,使得特征集合的质量降低,在一定程度上使分类器性能下降。
(3)故障特征维度高。故障文本数据中包含大量语料,对该语料库进行单词规范化、删除特殊字符、去除停用词后得到的特征集合维度高,使用大多数学习算法对高维特征集合进行学习会占用大量的时间、空间资源。
针对上述问题,本文提出一种双视图故障特征提取方法,在语义和语序两个视图下对故障文本数据进行特征提取。在语义视图下,提出改进的互信息(Improved Mutual Information,IMI)特征提取方法实现不平衡数据集下的特征提取,得到IMI特征;同时增加类别比重因子用于调整大类故障模式和小类故障模式的特征权重,解决不平衡数据集对分类器性能造成的影响。类别比重因子包括平均类词频和倒转类别频率两部分。在语序视图下,使用句向量的分布记忆模型(Distributed Memory Model of Paragraph Vectors,PV-DM)实现故障特征的充分提取,得到PV-DM特征。相较于传统的特征提取方法,本文方法考虑了语序和句序对故障特征提取的影响,能够充分提取故障文本数据中的故障特征,解决特征提取不充分问题。然后,利用PCA技术对IMI特征和PV-DM特征进行融合,将两者转化为线性不相关的PCA特征,解决故障文本数据维度高的问题。双视图故障特征提取方法流程见图1。

图1 双视图故障特征提取方法流程
2 双视图故障特征提取
2.1 语义视图
在语义视图下,基于IMI的特征提取方法通过增加类别比重因子δ来改变原有的特征空间,提高小类故障的权重,减少大类故障的权重。在δ中,考虑到高频特征很可能与最终诊断的总体性能相关,因此特征在故障文本数据中出现的频率TF可以用做特征选择的一个因素;IMI方法的目的是希望更准确地对大、小类故障模式加以区分,而不同的特征对类别的区分能力存在一定的差异,出现在小类中的词条显然具有较好的区分类别的能力,因此倒转类别频率ICF可以作为特征选择的另一个因素;类比于常用于文本加权的TF-IDF[13]方法,将TF与ICF的乘积作为类别比重因子δ。
2.1.1 互信息
互信息经常用来衡量特征之间相互依赖的程度,是信息论中的重要概念[14]。对于给定的类别c和特征ti,它们之间的互信息MI(ti,c)定义为
(1)
式中:P(ti∩c)为故障文本语句中特征ti与类别c同时出现的概率,即类别c中包含特征ti的概率;P(ti)为特征在整个故障文本语句中出现的概率;P(c)为类别c出现的概率。互信息值越大,表明特征所带来的信息量也就越大。当互信息达到最大值时,该特征即为判定类别归属的最佳特征。
设{c1,c2,…,cm}为故障文本数据集中m类故障的集合,则特征ti与故障文本数据集的互信息MI(ti)为
(2)
进行特征选择时,对每个特征计算其与故障文本数据集的互信息值并进行排序,选取前τ个互信息值最高的特征作为最终的特征集合。
2.1.2 基于IMI的故障特征提取方法
由互信息定义分析可知,互信息具有以下不足:
(1)仅考虑了特征在某类以及整个数据集中的文档频率,忽略了词频因素,从而倾向于选择低频特征,会造成更具有代表性、与类别依存关系更强的特征项被过滤掉。
(2)当互信息值为负数时,说明该特征在当前类别中很少或者不出现,而在其他类别中出现,这样的特征项对类别的正确判断具有重要作用。而式(2)采用累加求和的方式将正相关和负相关的作用进行中和,会影响特征集合的选择,特别是在数据集不平衡的情况下,小类故障的分类精度会受到很大影响。
(3)由于数据集故障模式分布不平衡,而互信息度量特征的信息量是在假定数据集类别分布相对均匀的情况下进行的,因此,如果不对互信息进行改进,对于小类故障而言,诊断效果会大幅度下降。
本文通过增加类别比重因子δ来解决上述问题,δ包含TF和ICF两部分。
某一特征ti在数据集中出现的频率TFti为
(3)
式中:nti为特征ti出现的次数;N为特征总数。TFti反映了该特征在故障文本数据集中的分布情况,出现该特征的次数越多,TF越大,意味着该特征的区分能力就越差。同时考虑到TF是特征在数据集中出现的频率,不能很好地体现特征在某一类中出现的频率,因此进一步使用类词频TFC表示特征在某一类中出现的频率,定义为
(4)
对式(4)取平均后得到平均类词频ATFC为
(5)
式中:nti,cj为特征ti在类cj中出现的次数;m为故障类别总数。特征ti在类cj中出现的次数越多,在其他类中出现的次数越少,ATFC越大,说明该特征更能代表该类。
倒转类别频率ICF可以用来衡量特征对类别的重要程度,计算式为
(6)
式中:|{j:ti∈cj}|为包含特征ti的类别数量。特征ti的ICF反映了该特征在整个类别中的分布情况,出现该特征的类别数越少,ICF越大,该特征的区分类别能力就越好。在计算中,为避免ICF为0,对式(6)进行加1处理。处理后的ICF为
(7)
将特征的ATFC与ICF相乘作为类别比重因子δ,δ值越大,说明特征在该类别中出现的频率越高,与该类别的关系更为密切,特征的区别能力越好,该特征能更好地代表该类别。δ计算式为
δti=ATFCti×ICFti
(8)
在互信息计算过程中,会出现上述式(2)中出现的正负相关相互抵消的问题,对此在求解特征ti与类别c之间的互信息值时,做绝对值处理。
综上所述,本文提出特征ti改进的互信息IMI(ti)计算式为
(9)
基于改进的互信息故障特征提取方法流程如下:
Step1初始化故障文本数据D,故障模式集合C,集合D中元素数ND,集合C中元素数m,生成的IMI特征集合维度τ。
Step2对于D中每一条文本数据Di,1≤i≤ND,去除特殊字符、小写化、分词后得到词集合,合并所有词集合并去重后得到特征词集合Ω。
Step3对于特征词集合Ω中的每一个特征ti,故障模式集合C中每一个类别cj,根据式(1)计算ti和cj的互信息值MI(ti,cj),根据式(4)、式(5)计算特征词ti的ATFCti,根据式(7)计算特征词ti的ICFti。

Step5根据式(9)计算特征词ti的IMI(ti),IMI(ti)从大到小依次排序,选取前τ个IMI(ti)作为特征集合FD输出,FD={t1,t2,…,tτ}。
Step6利用特征集合FD,采用One-Hot编码的方式对ti进行编码,得到特征表示向量wi。
Step7输出IMI特征矩阵FIMI=[w1w2…wτ]T。
2.2 语序视图
2.2.1 PV-DM模型
PV-DM模型是一种神经网络模型,可以将故障文本数据映射成为一个结构化向量。相比于传统的特征提取方法,PV-DM模型考虑了语序对文本特征提取的影响,能够更准确地表达故障特征。
词嵌入是一种将文本中的词汇转化为数值向量的方法,由于文本不能被计算机直接识别,因此在数据处理中生成词向量就显得异常的重要。Word2Vec[15]是一种常见的词嵌入方法,以大型的文本语料为输入,生成词汇的对应向量空间。Doc2vec[16]在Word2vec 的基础上增加了一个特征向量,并将这个特征向量看作是一个表示当前文档中其余部分信息或者主题信息的向量。PV-DM模型是Doc2vec两种模型中的一种,通过给定上下文来预测目标特征。PV-DM模型结构见图2。

图2 PV-DM模型结构
以故障文本数据中某一文本{ω1,ω2,ω3,ω4,ω5}={bsa,permanent,error,inactive,btm1}为例(见图2),在训练过程中,该文本的段落ID=2且保持不变,用段落向量DMj表示,j为该文本在整个数据集中的位置,文本中的每个特征共享该段落向量。同时文本中每个特征通过One-Hot编码的方式映射为一个独立的特征向量Wi,i为该特征在文本中的位置。将段落向量DMj与相邻的特征向量{Wi+1,Wi-1}求和得到一个矩阵,用来预测Wi。在给定上下文和DMj的条件下,PV-DM模型的目标是预测中心特征最大平均似然估计,即
(10)
式中:T为文本长度;k为上下文窗口长度。
本文利用Softmax函数[17]完成预测任务为
(11)
每个yi都为输出特征i的非标准化对数概率,即
y=b+Uh(ωt-k,…,ωt+k;W+DM)
(12)
式中:U、b为Softmax的参数;h由段落向量DM与特征向量W求和构成,两者使用反向传播算法[18]获得随机梯度进行训练。每一步的随机梯度下降,都是在任意一个随机段落里使用采样的方式获得上下文信息,通过PV-DM模型计算梯度误差并更新相应的参数。通过这样的训练方式,能够将具有关联的词映射到向量空间中相似的位置上,解决序列中词与词序之间的关联问题。
2.2.2 基于PV-DM模型的故障特征提取方法
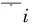
(13)
式中:Wi,e为第e轮训练过程中第i个文本被映射成的特征向量;η为迭代次数。
基于PV-DM模型的故障特征提取方法流程如下:
Step1初始化故障文本数据D,集合D中元素总数ND,迭代次数η,上下文窗口长度k,生成的PV-DM特征维度ρ。
Step2对于D中每一条文本数据Di,1≤i≤ND,去除特殊字符、小写化、分词后得到词集合。
Step3根据式(10)~式(12),利用随机梯度下降方法训练词集合,其中上下文窗口长度设置为k。
Step4重复训练η次,得到η个特征词向量集合{Wi,1,Wi,2,…,Wi,η}。

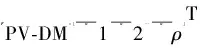
2.3 PCA特征融合
2.3.1 PCA
PCA是一种用来对高维特征降维的技术,对于pm维特征矩阵Fpm=[f1f2…fpm]T,通过PCA技术可以将其降维后形成pn维PCA特征矩阵,pn Step1对所有的特征进行中心化处理,用每一列数值减去每列均值,得到矩阵X,求矩阵X的协方差矩阵R。 (14) Step2利用Rx=λx求协方差矩阵R的特征值λ和特征向量x。 2.3.2 PCA特征融合 Step1初始化FIMI、FPV-DM,以及PCA特征维度γ。 Step3根据式(14)计算F的协方差矩阵R,并计算协方差矩阵R的特征值λ和特征向量x。 选用铁路运营部门收集的300T型车载设备故障文本数据作为数据集。通过对故障文本数据的统计,发现车载设备在不同故障模式之间具有明显的不平衡性。具体的故障模式及样本比例见表1。 表1 故障模式及样本比例 由表1可见,FM1和FM2占据的比例较大,属于大类别故障;相对的其他故障类型所占比例较小,属于小类别故障。其中,FM1与FM4的样本比例接近8∶1;FM1与FM5的样本比例达到7∶1。样本分布的不均衡性在进行诊断分类时易将小类别样本错误地诊断为大类别的故障类型,对于大类别的准确率影响较小,但是会大大降低小类别的准确率,从而影响分类器的性能。 为了全面衡量本文方法的有效性,基于准确率P和召回率R两个指标,将准确率与召回率的调和平均数F1作为度量车载设备故障诊断的最终评价指标。 (15) (16) (17) 式中:TP为正确分类的正样本;FP为分类为负样本的正样本;FN为分类为正样本的负样本。 为了验证本文提出的双视图文本特征提取方法的有效性,使用本文建立的数据集,以XGBoost作为诊断模型,以F1值作为评价指标,分别采用基于卡方分布[19](Chi-squared Distribution, CHI)、TF-IDF、MI、IMI、PV-DM模型,以及本文提出的故障特征提取方法进行对比实验。使用不同故障特征提取方法分类器不同类别的混淆矩阵见图3。 图3 各种故障特征提取方法下不同类别的混淆矩阵 由图3(a)~图3(d)可见,对于小类别故障模式FM4、FM5而言,分类器更倾向于将其分类成大类别故障FM1、FM2,这是数据集不均衡导致的。未添加特征类别因子时,在特征空间中更能代表FM4、FM5的故障特征占比小,往往会被传统特征提取方法所忽略,使得FM4、FM5的分类精度降低。从图3(e)中可以看出,添加了类别比重因子后,FM4、FM5的分类精度得到了大幅度提高,但是FM1、FM2的召回率反而下降,这是FM1、FM2故障特征提取不充分导致的,增加类别比重因子后,特征空间中FM4、FM5的故障特征占比变大,FM1与FM2之间故障特征的差异变小,分类器无法很好地对两者进行区分,使得FM1、FM2的召回率下降。本文提出的双视图故障特征提取方法混淆矩阵见图3(f),在小类别分类精度和大类别召回率上都取得了很好的效果。 各种故障特征提取方法下的分类器分类精度见图4。由图4可见,对于小类别故障模式FM4,采用CHI、TD-IDF、MI的故障特征提取方法后的分类精度分别为66.7%、66.7%、55.6%;对于FM5,采用CHI、TD-IDF、MI的故障特征提取方法后的分类精度分别为30.0%、40.0%、30.0%;增加类别比重因子后,小类别故障模式特征空间增大,基于IMI的特征提取方法对于小类别故障模式FM4、FM5的分类精度升高,分别为77.8%、60.0%;将IMI与PV-DM模型融合后的基于双视图文本特征提取方法,对于小类别故障模式FM4、FM5的分类精度分别为88.9%、80.0%,相比较于基于IMI特征提取方法,分别增加了11.1%和20.0%。 图4 各种故障特征提取方法下的分类器分类精度 各种故障特征提取方法下分类器性能对比见表2。从表2中可以看出,相比较于基于MI的故障特征提取方法,基于IMI的故障特征提取方法下的分类器分类精度虽然总体提升了1.3%,但是其召回率下降了3.8%,使得最终评价指标F1值反而下降了0.031,这是由于对大类别故障模式特征提取不充分导致的。在没有添加类别比重因子时,由于故障模式的不均衡性,能代表小类故障模式的故障特征没有被提取出来,故障模式的差异主要体现在大类故障模式之间,大类别故障模式的召回率会升高;在增加类别比重因子后,小类别故障模式特征空间趋近于大类别故障模式特征空间,能代表小类别故障模式的故障特征被充分提取,大类别故障模式特征之间的差异变小,召回率下降,使得最终评价指标F1反而下降。因此,本文在IMI基础上增加基于PV-DM的模型,并对两者进行融合。融合后的故障特征提取方法得到的分类器分类精度为99.2%,召回率为98.8%,F1为0.988,相比于IMI和PV-DM而言,分类精度分别增加了1.8%、4.1%,召回率分别增加了8.7%、4.7%,最终评价指标F1分别增加了0.063、0.037,证明了融合后的双视图故障特征提取方法的有效性。 表2 各种故障特征提取方法下分类器性能对比 (1)针对实际应用中列控系统车载设备故障诊断领域面临的故障文本数据维度高、故障模式分布不平衡、故障特征提取不充分三大问题,提出双视图文本特征提取方法。首先利用基于IMI的特征提取方法在语义视图下解决了故障模式分布不平衡问题;其次利用PV-DM模型在语序视图下对故障文本数据充分提取,解决了故障特征提取不充分的问题;最后利用PCA方法对通过两个视图得到的特征集合进行融合,解决了故障文本数据维度高的问题。 (2)以铁路运营部门收集的300T型车载设备运行日志数据为例,采用XGBoost作为分类器,F1作为评价指标,对本文提出方法的有效性进行实验验证。实验结果表明,本文提出的基于双视图文本特征提取方法,其分类器性能优于基于传统的特征提取方法(如IMI和PV-DM),评价指标F1分别增加了0.063、0.037,证明了本文提出方法的有效性。
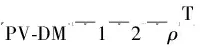

3 实验验证及结果分析
3.1 数据集及评价指标

3.2 实验结果



4 结论
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
