
基于BiLSTM和改进注意力机制的高铁车载设备故障诊断
2022-12-02 11:49赵小强丁艳华范亮亮
铁道学报 2022年11期
魏 伟,赵小强,3,丁艳华,范亮亮
(1.兰州理工大学 电气工程与信息工程学院,甘肃 兰州 730050;2.甘肃省工业过程先进控制重点实验室,甘肃 兰州 730050;3.兰州理工大学 国家级电气与控制工程实验室教学中心,甘肃 兰州 730050;4.中国铁路兰州局集团有限公司 高铁基础设施维修段,甘肃 兰州 730050;5.中国铁路兰州局集团有限公司 兰州电务段,甘肃 兰州 730050)
车载设备作为列车运行控制系统的核心组成部分,掌控着列车运行的速度、距离等要素,是保障列车运行安全的关键。文献[1]表明,目前列控车载设备故障诊断主要依靠人工经验判断,已不能满足大流量、高密度的运输需求。因此,运用智能故障诊断技术,及时准确地查找列控车载设备故障成为各学者研究的热点。
故障诊断是对设备异常工作状态进行检测、隔离、识别的过程。早期学者运用基于知识表示的方法定性完成铁路信号设备故障诊断。文献[2]根据故障类型和特征,基于电路原理逻辑和专家经验知识建立专家系统,实现车站信号控制设备故障的分析与诊断。文献[3]针对故障树分析法(Fault Tree Analysis, FTA)的动态失效问题,建立动态FTA模型,并采用分层迭代法优化运算,提高了车载ATP设备可靠性分析的精度。文献[4]将案例推理技术引入车载设备故障诊断,以历史案例完全表达为依据,采用分层引索策略克服了案例检索效率低的问题。这类以专家系统为代表的知识表示故障诊断方法,存在专家知识难以完全收集,建立的知识库不易更新,推理规则过多等问题。
近年来,机器学习和深度学习在故障诊断领域得到了广泛应用。文献[5]基于粗糙集理论简约故障特征,利用贝叶斯网络决策和推理完成车载故障诊断。文献[6]针对贝叶斯网络先验知识不足的缺点,综合运用模糊数学理论建立了一个多属性指标下故障态势的模糊贝叶斯决策模型,但贝叶斯网络需要假设故障属性之间相互独立,这在实际中难以满足。文献[7]采用独热表示方式获得故障现象与故障原因之间的映射,基于DBN完成车载故障诊断。文献[8]建立故障诊断决策表,运用GA优化BP完成车载故障诊断。文献[9]基于粗糙集和PSO算法优化BP,实现车载应答器信息接收模块故障诊断。文献[10]基于Apriori算法时间序列数据进行简约,构建LSTM模型完成车载测速测距单元故障诊断。基于神经网络的故障诊断方法需要将故障数据预处理成适合输入的格式,需要投入大量人工和时间成本,同时也难免造成原始数据中有用信息的丢失。
在大数据的时代背景下,基于数据驱动的故障诊断方法成为研究的主流。车载设备故障数据包括两种:自然语言形式的人工故障记录和安全计算机生成的AElog文件。文献[11]以人工故障记录为依据, 利用pLSA主题模型对故障追踪表进行语义特征提取,搭建贝叶斯网络完成故障诊断。文献[12]提出一种融合语义特征的两级故障特征提取方法,将χ2统计提取的词义特征与LDA提取的语义特征融合,分级完成车载设备故障诊断,但由于车载故障数据均为短文本,故利用LDA提取文本主题效果并不理想。文献[13]以困惑度为指标评价了不同主题个数的LDA模型,通过融合不同的主题特征空间,提出一种多粒度的LDA故障诊断方法,能有效提取短文本主题特征,但主题模型属于无监督模型,文本特征的提取具有较大的随意性,不利于故障文本分类。针对以上问题,文献[14]依据现场先验知识,采用Labeled-LDA主题模型提取故障文本特征,并用PSO优化SVM完成故障分类,该模型预设标签与主题对应,提高了故障诊断的精度,但不能识别ATP设备误报信息。
人工故障记录不具有时间序列特性,车载安全计算机自动生成的AElog文件可按时间顺序记录列车的运行状态,电务人员结合列车历史、未来的运行状态,能对当前时刻的故障做出更准确的判断。但AElog文件属于非结构数据,冗余信息较多,语义特征不易提取,常作为间接数据用于统计分析[3,5-7],未得到充分利用。文献[15]通过Word2vec模型将AElog文件转化为词向量,以句子为单位输入LSTM-BP级联模型,完成车载设备故障诊断,通过分析故障数据之间时序关系,并结合列车历史运行状态完成故障诊断,提高了关机误报等非故障信息的诊断精度,但Word2vec模型存在语义歧义问题,且LSTM仅考虑列车故障前的运行状态,而在实际中列车故障后的运行状态对故障分析同样重要。
为此,本文采用加权的变压器双向编码表示(Weighted BERT, wBERT)实现文本向量化表示,并基于双向长短期记忆(Bidirectional Long Short Term Memory, BiLSTM)和改进注意力机制(Improved Attention Mechanism, IAtt),提出wBERT-BiLSTM-IAtt车载设备故障诊断模型。首先,由BERT得到包含上下文语义信息的词向量,并以各词的TF-IDF值为权重加权求和得到句向量,相较于传统BERT直接求和得到句向量的方法,wBERT能准确地表示出句子语义,可为后续文本分类任务提供更好的数据基础;然后,以句向量为单位输入BiLSTM,与传统LSTM仅考虑单方向的时序关系不同,BiLSTM能分析列车故障时刻前后的运行状态,充分捕获具有时序特性的故障特征;最后,以高维的故障特征作为改进注意力机制层的输入,分析故障文本与各句子之间的权重关系,增加重点句子的关注度,忽略冗余句子的影响,解决短文本语义表达模糊问题,进一步提高故障文本分类的正确率。
1 算法研究
1.1 车载设备结构及故障数据
车载设备、地面设备、GSM-R通信网络构成了规模庞大、结构复杂的列车运行控制系统。其中,车载设备主要有300T、300S、300H、200H、200C等5种型号,本文以300T型车载设备为例进行分析。300T型车载设备结构见图1,采用C2/C3级一体化的分布式设计,主要包括列车超速防护单元(ATPCU)、C2控制单元(C2CU)、应答器信息接收模块(BTM)、测速测距单元(SDU)、轨道电路信息读取模块(TCR)、安全输入输出单元(VDX)、安全无线传输系统(STU-V)、司法记录单元(JRU)、人机界面单元(DMI)等,各个部分通过Profibus和车辆MVB双总线连接,实现列车运行的动态速度和目标距离控制[1]。

图1 300T型车载设备结构
列车运行过程中,ATPCU自动生成记录列车运行状态的AElog文件,每个AElog文件包含250条状态信息,这些信息以“堆栈”的形式存储,阅读时需要按时间顺序从后往前读。AElog文件截图(部分)见图2。

图2 AElog文件截图(部分)
由图2可见,AElog文件记录了故障发生的时间、文件名、任务号、故障码、故障语句等信息,故障分析时,主要依据故障语句做出故障诊断。故障语句由英文短句描述,例如“Radio service lost”和“Network resource not available”表示网络资源不可用造成车地通信中断故障。从模式识别角度看,基于AElog文件的车载设备故障诊断,就是依据故障语句识别文本语义完成文本分类的过程,主要存在以下难点:
(1)故障数据冗余。AElog文件属于半结构化数据,含杂着大量冗余信息,这些信息对语义特征提取无任何作用,需通过数据预处理删除。
(2)故障信息误报。ATP设备在系统断电前后或者检修作业期间会记录部分模块故障的信息,这些故障信息多由人为操作造成,而设备本身并无故障。
(3)故障特征复杂。AElog文本中的故障语句存在一词多义或多词一义的情况。若将故障语句比作故障特征,即存在多个特征表征一种故障或者一种故障表现不同故障特征的情况。比如:故障语句“radio service lost”“No network connection available”“No station registrated”“RD Connection ACK timeout”均表示无线通信相关故障。
综上所述,基于文本挖掘的车载设备故障诊断不是简单的文本信息检索过程,需要深度挖掘文本语义,综合上下文信息才能做出准确的故障判断。
1.2 BERT
文本向量化表示是处理自然语言任务的第一步,有学者从潜在语义角度出发,提出了LSA、LDA等主题模型,将原始高维特征词空间映射到低维潜在主题空间以获得文本层面的语义信息,然而这些模型缺乏对短句和词语等低层语义表示,不善于处理短文本。2013年Mikolov提出Word2vec模型[16],从“词”粒度层面进行文本信息提取,更精细地表达文本语义,但Word2vec模型忽略了词与上下文的关系,存在一词多义的问题。2018年ELMo模型被提出,该模型可结合语境为每个单词创建与上下文关联的词向量,克服了Word2vec模型的缺点[17],但是其文本特征提取能力有限。
2018年谷歌AI团队集成各语言模型的优点提出了BERT模型,该模型采用具有双向信息流的Transformer编码器[18],能够同时完成遮蔽语言建模和下一句话预测两个无监督任务[19],可为每个单词根据上下文语义灵活选择词向量,消除了语义表示歧义问题,在各项自然语言处理任务中取得了领先效果。BERT模型结构见图3。图3中,Wn为原始词向量;On为训练后融合全局语义信息的词向量;Trm为Transformer编码器。
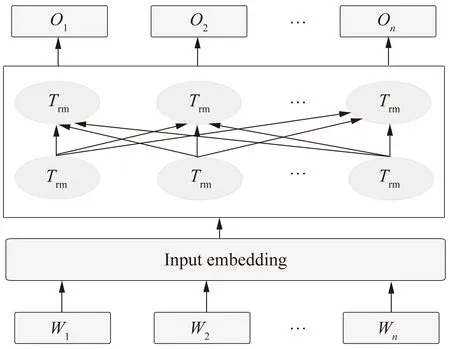
图3 BERT模型结构
1.3 LSTM与BiLSTM
LSTM由Hochreiter等[20]于1997年提出,该模型具有学习长依赖性数据特征的能力,同时克服了循环神经网络(Rrecurrent Neural Network, RNN)训练过程中梯度消失和梯度爆炸的问题,广泛用于各领域故障诊断任务[21-23]。LSTM单元结构见图4。

图4 LSTM单元结构
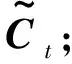
LSTM训练过程如下:
ft=σ(Wfxt+Ufht-1+bf)
(1)
it=σ(Wixt+Uiht-1+bi)
(2)
ot=σ(Woxt+Uoht-1+bo)
(3)
(4)
(5)
ht=ottanh(Ct)
(6)
式中:ft、it、ot分别为遗忘门、输入门、输出门当前时刻的输出;Wf、Wi、Wo分别为遗忘门、输入门、输出门当前时刻网络输入xt的权值矩阵;Uf、Ui、Uo分别遗忘门、输入门、输出门t-1时刻隐藏层输出ht-1的权值矩阵;bf、bi、bo分别为遗忘门、输入门、输出门的偏置值。
BiLSTM由正、反向两个LSTM构成,二者参数独立,共享网络输入,训练得到正、反向两个隐藏层输出,合并后即为当前时刻网络输出,因此BiLSTM可以同时从两个方向上获取时序信息,理论上更利于挖掘更深层的文本语义信息。
1.4 注意力机制
注意力机制最早应用于图像处理领域[24],可提高模型对图像重点目标区域的关注度。后来,Bahdanau等[25]将注意力机制与RNN结合应用于机器翻译任务,证明了注意力机制在自然语言处理任务中的有效性。近年,注意力机制在故障诊断领域也得到广泛关注。文献[26]基于Inception-CNN模型完成滚动轴承故障分类任务,在CNN提取故障特征后加入注意力机制,权衡不同特征的重要程度,提高模型分类的精度。文献[27]将注意力机制和多尺度网络引入高速列车EPR电缆故障诊断,分析了PRPD谱图在不同通道域的权值分配,实验表明,引入注意力机制得到了更低损失函数值和更高模型正确率。可见,在故障诊断任务中引入注意力机制的本质在于从复杂的故障特征中筛选重要信息,过滤或弱化冗杂信息,以提高故障诊断精度。
2 基于BiLSTM和改进注意力机制的车载故障诊断模型
本文提出的wBERT-BiLSTM-IAtt车载设备故障诊断模型见图5。首先将AElog文件预处理成统一格式,基于wBERT得到句向量;再以句向量为单位输入BiLSTM提取文本语义信息,引入改进注意力机制层调整不同句子的权重;最后输入Softmax分类器完成故障分类。
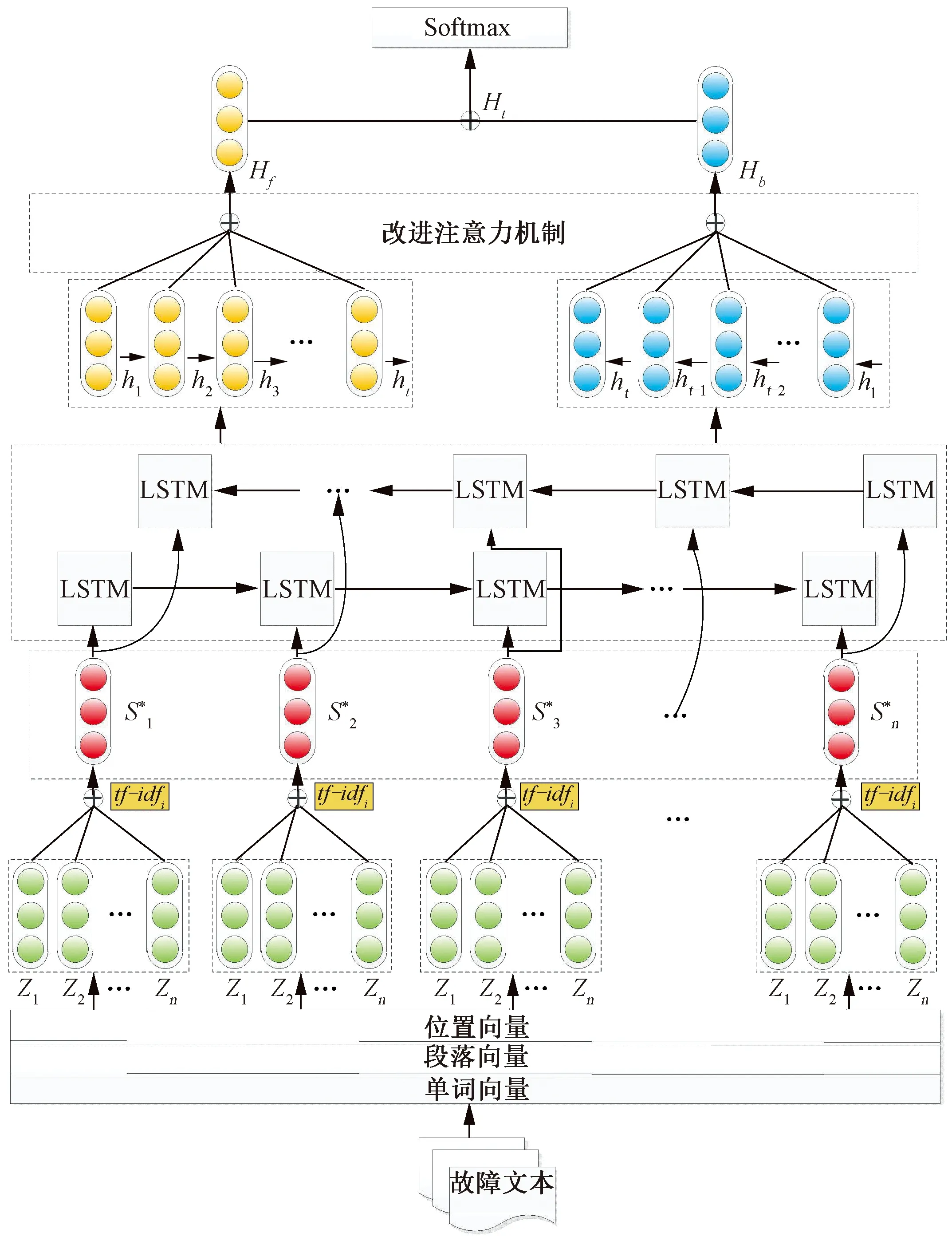
图5 wBERT-BiLSTM-IAtt车载设备故障诊断模型
2.1 文本向量化表示
与传统文本分类数据集不同,AElog文件属于半结构化数据,含有大量冗余信息,在人工分析数据时,仅依据关键的3~5条故障语句即可做出故障判断。因此,需要对故障数据进行清洗和整理,删除冗余信息,仅保留故障语句,并完成故障类别标注,该过程由Python正则表达式自动匹配实现。
2.1.1 词向量表示层
AElog文件中故障语句s={w1,w2,…,wn}由n个单词wi组成,1≤i≤n。经BERT模型训练得到3种向量:单词向量pwi、段落向量psi、位置向量ppi,分别表示单词的语义信息、所在段落信息、词序信息。使用时结合语境,选择适当的3种向量求和得到最终词向量Zi,即
Zi=pwi⊕psi⊕ppi
(7)
由式(7)可见,相较于传统词向量工具,由BERT生成的词向量Zi包含了更多的参数,文本语义表示更加准确。
2.1.2 句向量表示层
词向量不仅能够表示单词的语义特征,而且可以采用词向量相加减的方式表示句子或文本的语义特征[16],因此,句向量Si可由句子中各单词对应的词向量Zi累加求和得到,即
(8)
但是AElog文件中故障语句短,组成文本的特征词少,句子语义不易表示。另外,由词向量累加求和得到句向量的方法,忽略了不同单词对句子语义的不同影响,易造成语义丢失。为此本文提出wBERT文本向量化方法,即由BERT生成词向量后,以各单词词频为权重,通过加权求和的方式得到句向量,以此调整句子中不同单词的权重,突出重点单词对句子语义的贡献度,可最大程度保留句子的原始语义。
词频-逆文本频率(Term Frequency-Inverse Document Frequency, TF-IDF)是一种评估单词对于一个文本集中某一类文本重要程度的统计方法,由词频tf和逆向文件频率idf组成,计算式为
(9)
(10)

由此,得
(11)
以式(11)为权重,代入式(8)得到wBERT的句向量为
(12)
2.2 故障特征提取层
本文选择BiLSTM作为特征提取层,构造2个LSTM,从正、反两个方向捕获前后句子之间的依赖关系,挖掘AElog文件深层的语义。故障文本T={S1,S2,…,Sm}中包含m个故障语句Si,分别输入正、反向LSTM,按照式(1)~式(6)训练后得到
(13)
(14)
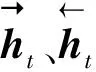
(15)
2.3 改进的注意力机制层
为进一步提高重点故障语句对AElog文本的重要性,在故障特征提取层后引入注意力机制层。传统做法是将BiLSTM正、反向输出合并后作为注意力机制层的输入[28],这种接入方式忽略了正、反向LSTM获取的特征受注意力机制的不同影响。为此,本文改进注意力机制的接入模式,如图5所示,分别将正、反向LSTM获取的特征单独作为注意力机制层的输入,并分配独立的参数进行训练,然后将加权后的正、反向LSTM输出合并,获得最终特征表示。改进注意力机制层计算过程为
(16)
(17)
(18)
2.4 分类层
将故障特征向量Ht输入Softmax分类器,得到待分类故障文本的结果输出为
y=Softmax(WsHt+bs)
(19)
式中:y为实际故障类别;Ws为权重矩阵;bs为偏置。本文采用反向传播算法(Back propagation, BP)迭代更新参数,使用交叉熵损失函数优化网络,即
(20)

3 实验结果及分析
3.1 数据集与评价指标
本文收集某局集团有限公司电务段自2017年1月至2019年12月300T型车载设备AElog文件作为实验数据。首先依时间顺序与人工故障记录对比,确认AElog文件故障类型,然后从中选取800条典型的故障数据预处理后完成故障标注,形成实验数据集。参照文献[12, 14]车载设备故障分类方式,将不常发生的故障类型合并为一类,并忽略司机误操作等人为原因造成的故障,整理后的车载设备故障分类见表1。

表1 车载设备故障分类
车载设备故障诊断为多分类问题,引入正确率Accuracy、准确率P、召回率R,以及准确率与召回率的调和平均数F1值等多个指标评价模型为
(21)
(22)
(23)
(24)
式中:TP为标签i且被分到标签i类的故障数;TN为非标签i且被分到非标签i类的故障数;FP为非标签i被分到标签i类的故障数;FN为标签i被分到非标签i类的故障数。
3.2 实验分析
3.2.1 参数设置
本次实验基于TensorFlow2.0深度学习框架完成,将数据集按8∶2分为训练集和测试集;Word2vec词向量维度为150,BERT采用Google预训练后的XLM-R[Large]模型;CNN采用一维卷积网络,设置3个大小为2,3,4的卷积窗口[29];LSTM的输入层节点数、词向量维度与BiLSTM的一致,隐藏层节点数为64,隐藏层后设Dropout层丢弃概率为0.5防止过拟合,注意力机制层节点数为64;模型训练使用Adam,学习率为0.001,批次训练为50,迭代次数为20;SVM采用LIVSVM工具包,设置类型为C-SVC;核函数采用径向基函数,惩罚因子为10,核函数控制因子为0.01。
3.2.2 词向量工具对比实验
分别采用Word2vec、ELMo、BERT,以及本文提出的wBERT实现文本向量化,并基于BiLSTM完成车载设备故障诊断,对比不同词向量工具对模型性能的影响。基于不同词向量工具的实验结果对比见表2。由表2可见,各模型都获得了80%以上的故障诊断正确率,说明从词级层面提取文本特征在短文本向量化方面取得了不错的效果;ELMo是一种动态词向量模型,具有多义词的识别能力,正确率较Word2vec提高了2.5%;BERT采用Tranformer编码器,文本信息提取能力优于ELMo,正确率达到了89.5%;本文提出的wBERT模型进一步提升了重点词权重,同时降低冗余词的影响,获得了最高的故障诊断正确率,达到90.6%。

表2 基于不同词向量工具的实验结果 %
3.2.3 故障特征提取层对比实验
基于wBERT实现文本向量化,将句向量输入4种不同的神经网络模型完成车载故障诊断,对比不同故障特征提取层对模型性能的影响。基于不同故障特征提取层的实验结果对比见表3。由表3可见,相较于CNN,LSTM、BiLSTM、BiGRU更利于分析具有时序特性的故障数据,它们能结合上下文提取语义信息,因此,CNN模型正确率低于其他3种模型;LSTM仅从单方向考虑句子之间的关系,即上文语义信息,而AElog文件分析时需结合上下文语义信息才能做出更准确的判断,特别在判断误报信息时,如果仅考虑列车故障前的运行状态,容易把误报记录判断为故障;BiLSTM和BiGRU弥补了单向LSTM的缺点,从两个时序方向提取文本特征,综合上下文语义信息对故障文本做出判断,提升了模型学习能力,正确率得到提高。

表3 基于不同故障特征提取层的实验结果 %
LSTM、BiLSTM、BiGRU 3种模型的正确率、损失值随网络迭代次数增加的变化过程见图6。从图6(a)明显看出,BiGRU与BiLSTM均得到较高的正确率和低的损失值;BiGRU是BiLSTM的改进[30],将LSTM中遗忘门、输入门、输出门简化为更新门和重置门,因此,BiGRU参数少于BiLSTM。从图6(b)看出,BiGRU能够更快收敛,损失值下降快于BiLSTM,但是迭代10次左右时两者均获得90%左右的正确率,BiLSTM略高。考虑列控车载设备故障诊断需要具备较高的可靠性,故本文选择BiLSTM为故障特征提取层。
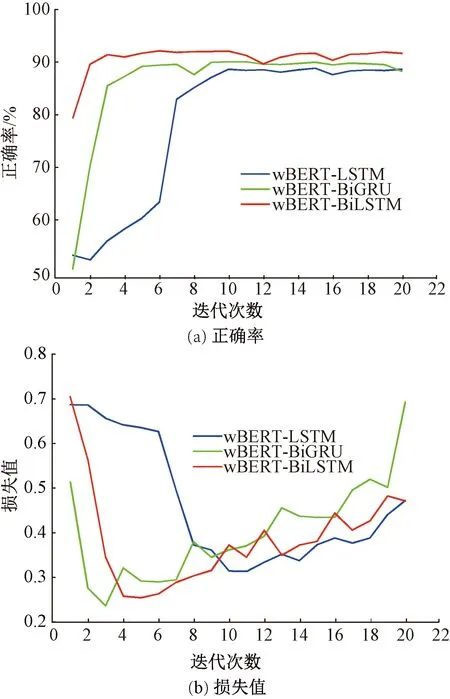
图6 3种模型正确率、损失值随迭代次数增加的变化过程
3.2.4 注意力机制层对模型性能的影响
为验证引入注意力机制的必要性,本文构建wBERT-BiLSTM、wBERT-BiLSTM-Att、wBERT-BiLSTM-IAtt 3种模型进行对比实验。基于不同模型的实验结果对比见表4。

表4 基于不同模型的实验结果 %
注意力机制层可以有效识别重点句子对文本语义的影响,从表4看出,接入注意力机制层正确率提升了2%以上。本文提出改进注意力机制层,独立分配正、反向LSTM输出特征的权重,进一步加持了BiLSTM故障特征提取的效果,故障诊断正确率提升了3%左右。
AElog文件经过改进的注意力机制层后各句子权重分配可视化效果见图7。该故障类别为“BTM端口无效”,经过改进注意力机制层后,关键故障语句“Balise Port1 invalid”和 “StatusPort notvaild in BTM1”被分配了更多的权重,说明得到模型更多的关注,提高了AElog文件的可分性。

图7 改进注意力机制层输出特征可视化效果
3.2.5 基线模型实验对比
本文基于加权BERT实现文本信息表示,并结合双向长短期记忆网络和改进的注意机制,提出wBERT-BiLSTM-IAtt车载故障诊断模型,为进一步说明该模型的性能,与其他模型进行对比实验。
(1)TF-IDF-SVM。TF-IDF是一种基于词频的文本特征提取方法,原理简单、运行速度快,提取文本特征后利用SVM完成文本分类,是最简单的文本分类模型,以此作为基线模型。
(2)Labeled-LDA-PSO-SVM。文献[14]克服LDA模型主题分散的缺点,结合专家经验预设主题标签,从隐语义层面提取文本信息,采用PSO算法优化SVM完成多故障分类。
(3)Word2vec-LSTM-BP-BR。文献[15]采用Word2vec提取文本语义特征,基于LSTM从时间序列角度分析,利用BR优化BP,完成故障分类。
不同模型下各类别故障的诊断结果见表5。

表5 基于不同模型车载故障诊断结果 %
由表5可见:
(1)TF-IDF-SVM模型基于词频对文本分类,不能有效解决一词多义问题,语义信息丢失严重,正常类故障诊断准确率仅为68.98%,说明受冗余信息影响故障特征不明显的AElog文件被划分为正常类别,整体诊断精度仅为72.62%。
(2)文献[14]改进主题模型,从文本层面提取语义信息,各类别结果得到了提升,故障诊断精度达到81.5%;但未考虑故障数据之间的时序特性,不能准确识别误报信息,正常类故障诊断准确率为79.8%;另外,各类别仍有提升空间,说明主题模型的短文本特征提取效果不够理想。
(3)文献[15]基于Word2vec生成词向量,采用LSTM结合上文故障语句判断故障,正确率达到89.37%;值得注意的是,正常类诊断准确率相对于文献[14]方法增加了7%左右,说明LSTM有效增加了误报信息的诊断准确率。
(4)本文模型从文本向量化方法、故障特征提取和故障文本分类三个方面优化,提高了各类别诊断的准确率、召回率、F1值,故障诊断正确率为93.75%,优于其他模型,说明了本文模型的有效性。
4 结论
(1)本文结合TF-IDF和BERT提出wBERT文本向量化方法,通过加权求和的方式得到AElog文件中故障语句的向量化表示,然后将句向量输入BiLSTM提取故障特征,再接入改进的注意力机制层调整不同句子的权重,最后利用Softmax对故障文本分类,实现了车载设备故障诊断。
(2)为了验证模型合理性,与Word2vec、ELMo、BERT对比了文本向量化效果,与CNN、LSTM、BiGRU对比了故障特征提取性能,同时验证了引入改进注意力机制的必要性。
(3)为进一步说明本文模型的有效性,基于真实故障数据,与其他文献提出的车载故障模型进行对比,实验结果表明,本文模型在准确率、召回率、F1值三方面均取得了最优的结果,可为电务人员车载故障诊断与设备维护提供有力指导。
下一步研究工作将基于BERT生成不同维度的词向量,验证词向量维度对实验结果的影响,并收集更多数据,尝试解决在不均衡样本下的车载故障诊断问题。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
中华养生保健(2020年7期)2020-11-16
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2020年8期)2020-02-06
汽车维修与保养(2019年3期)2019-06-19
中国公共安全(2017年11期)2017-02-06
中国修辞(2017年0期)2017-01-31
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
