
基于优化SVM和BP神经网络检测双孢蘑菇早期病害
2022-11-29 03:09:52陈子涵温志强
福建农林大学学报(自然科学版) 2022年6期
黄 亮, 魏 萱,2,3, 陈子涵, 温志强
(1.福建农林大学机电工程学院,福建 福州 350002;2.福建农林大学食品学院,福建 福州 350002;3.福建省农业信息感知技术重点实验室,福建 福州 350002;4.福建水利电力职业技术学院,福建 永安 366000;5.福建农林大学生命科学学院,福建 福州 350002)
双孢蘑菇(Agaricusbisporus)又名白蘑菇、洋蘑菇,是伞菌目(Agaricales)蘑菇属(Agaricus)食用菌.双孢蘑菇含有丰富的氨基酸、核苷酸、超氧化物歧化酶、胰蛋白酶等,蛋白质含量高达42%,具有较高的食用价值和医药价值[1-2].有害疣孢霉菌(MycogoneperniciosaMagn.)属于子囊菌门(Ascomytota)盘菌亚门(Pezizomycotina),在20~28 ℃时生长较快[3].双孢蘑菇被疣孢霉菌侵染引起的疣孢霉病,又称褐腐病、白腐病,轻度侵染后其表面会形成褐色斑点和白色菌丝,重度侵染可能会形成畸形菇,且不同生长发育阶段感染症状的差异明显[4].
多酚氧化酶(polyphenol oxidase,PPO)又称儿茶酚氧化酶,是一种存在于植物、食用菌中的金属蛋白酶.它能够引起果蔬酶促褐变,从而影响果蔬的外观品质和口感风味[5].PPO也能作为一种参与黑色素细胞形成的氧化还原酶,它能抑制黑色素的沉积,从而避免色斑、褐斑等疾病的产生[6].相反,黑色素可以治疗白化病等疾病,故防御活性酶可能与食用菌病害存在一定联系.已有许多专家研究了果蔬防御活性酶与真菌病害的相关性,指出防御酶对大麦抗病起到一定作用[7].传统的疣孢霉菌检测方法有柯赫氏法则致病性检验、核糖体转录间隔区(rDNA-ITS)序列分析[8],这些分子生物学技术方法往往会破坏样本的外部品质和内部结构.因此,采用无损、快速的高光谱成像技术检测样本的品质尤为重要.
近年来光谱成像技术已经大量运用到水果[9]、蔬菜[10]、食用菌[11]等检测中,具有检测范围广、精度高等优点.马淏等[12]基于光谱技术对双孢蘑菇的新鲜度进行分级检测,结果表明,结合粒子群算法(particle swarm optimization,PSO)和海姆优化算法(seagull optimization algorithm,SOA)极限学习机(extreme learning machine,ELM)检测模型精度较高,预测精度分别为92.5%、94%.Yang et al[13]采用反向传播神经网络(back propagation, BP),构建了不同生育期杏鲍菇MSC-CARS-BP菌丝体检测模型,不同生育期菌丝体检测结果准确率均为99.67%.Xiao et al[14]基于高光谱技术预测渗透脱水中双孢蘑菇的可溶性固形物(Soluble Solids Content,SSC)含量,结果表明经过正交信号校正(orthogonal signal correction,OSC)的支持向量机(support vector machine,SVM)模型预测集R2p为0.883,且OSC-CARS-SVM预测模型的精度最佳.Mollazade[15]基于高光谱成像技术对4种褐变双孢蘑菇进行了分类,其中经过竞争自适应加权算法(competitive adaptive reweighted sampling,CARS)后的偏最小二乘回归(partial least squares regression,PLSR)模型的校正集和预测集的分类准确率分别为80.6%、80.3%,并将全光谱点的主成分分析(principal components analysis,PCA)图与常规红、绿、蓝(red,green,blue, RGB)成像波段分类图进行了比较.
早期双孢蘑菇(原基期至小菇期)菌盖上的菌丝细小,很难提取到疣孢霉菌进行病害判别.又由于疣孢霉菌入侵双孢蘑菇后,会合成大量PPO来抵制病菌的侵害[16].故PPO与疣孢霉病可能存在某种相关性.目前利用高光谱成像技术预测双孢蘑菇早期PPO的研究较少,对双孢蘑菇疣孢霉病判别鲜有研究.因此,本研究先提取与PPO相关的特征光谱,然后进一步筛选光谱特征判别双孢蘑菇的早期病害,旨在为食用菌早期病害判别提供一种新方法,为进一步开发早期双孢蘑菇病害的快速无损鉴别设备提供参考.
1 材料与方法
1.1 样本的培养与接菌
试验材料为福建省农业科学院食用菌研究所提供的W192型双孢蘑菇菌菌种、My.p0012型疣孢霉菌菌种.以小麦播种的方式将菌种播撒在栽培料中混合均匀,采用无菌食用菌栽培袋以400 g·袋-1的标准分装;将双孢蘑菇放入22 ℃、90%相对湿度、无光照条件的人工气候培养箱中培养;当菌丝大约生长到栽培料的2/3时覆土,覆土高度约3 cm.覆土后适当调高环境温度并进行轻喷,以利于菌丝爬土.待覆土后10 d左右,温度调低至20 ℃,观察双孢蘑菇出菇情况.培养期间每天通风2次,每次1 h[17].
采用孢子悬浮液接种双孢蘑菇.先将疣孢霉菌放入马铃薯葡萄糖琼脂(potato dextrose agar,PDA)中培养7 d,再用无菌水冲洗PDA活化疣孢霉菌孢子,并用血球计数板检测疣孢霉菌孢子悬液浓度,其值为(1.0±0.4)×105个·mL-1.然后在2/3覆土层的表面均匀喷洒5 mL疣孢霉菌孢子悬液接菌[18].
1.2 防御酶活性值的测定
选用苏州科铭生物技术有限公司生产的试剂盒测定指标值,测定方法参考文献[19].PPO的特征波段光密度用酶标仪测定,计算PPO活性值.酶标仪(SpectraMax®Plus 384)配备高精度光栅型单色器和温度控制器,波长可调节至190~1 000 nm,步进1 nm,带宽2 nm.
1.3 高光谱图像的获取
高光谱成像系统主要包括ImSpector V10E光谱仪、OLE 23型成像镜头、2个150 W光纤卤素灯、电控升降台和计算机等[20].采用HSI Analyzer软件进行白板校正、图像存储等.设置合理的曝光时间等参数以避免信息饱和以及图像失真,调整后物镜高度为350 mm,CCD相机曝光时间为0.13 s,相机推扫移动速度为2.20 m·s-1.为了消除传感器暗电流、光线不均匀等产生的影响,对高光谱图像进行黑白校正:
(1)
式中:I0表示校正后的高光谱图像;A表示白板图像;B表示黑板图像;IC表示原始高光谱图像.
采集原基期、菇蕾期、幼菇期和小菇期的染病双孢蘑菇高光谱图像以实现早期检测.接种后0~7 d为原基期,8~9 d为菇蕾期,10~11 d为幼菇期,11~12 d为小菇期,各个生长周期为2 d左右.原基期普遍呈白色米粒状;菇蕾期则为黄豆大小,且菌柄、菌盖已成雏形;幼菇期、小菇期的菌盖分别呈盖半球状、扁盖半球状.小菇期后的病害特征较为明显,菌盖表面会出现褐变等患病症状,故可将接种后7~11 d的样本认定为早期.每个周期健康和染病双孢蘑菇的数量各50个.以每个图像菌盖周围部分区域为感兴趣区域(region of interest,ROI),采用新区域叠加所有样本的数据提取区域,提取形状有椭圆形、矩形、八边形等.最终得到4×2×50个高光谱图像的ROI光谱数据.
1.4 特征波长的优选方法
CARS采用自适应重加权采样(adaptive reweighted sampling,ARS)和指数衰减函数(exponential decay function,EDF)来建立多个PLSR模型,从而筛选出极值回归系数,然后利用十字交叉算法优选出均方误差较小的PLS模型[21].连续投影算法(successive projections algorithm,SPA)通过引入最小化变量解决矢量空间的共线性来选择最优变量,从而提高建模效率.SPA先对所有光谱波段进行投影分析,然后将相对较大的投影向量值作为特征波长,从全波段范围内筛选出无关信息量最少的一组光谱信息来建立多元回归模型.所筛选的变量不仅共线性较小,而且避免了光谱波段的共线性和信息重叠,提高了建模精度[22].
1.5 预测及判别模型
SVM是一种典型的二分类有监督学习算法.SVM通过采用序列最小优化法(sequential minimal optimization, SMO)来不断迭代出2个最合适的拉格朗日算子α,从而确认最终模型.在本研究中采用Sigmoid核函数来线性划分数据集.
ELM与单隐含层前馈神经网络(single hidden layer feed-forward neural network,SLFN)相似.与反向传播的神经网络不同,ELM随机选取输入层权重和隐含层偏置,输出层权重由最小化训练误差项和输出层权重范数的正则项构成,具有学习速度快、训练参数少、泛化能力强等特点[23].
BP神经网络具有正、反向传播的特点,是目前应用最广的多层前馈神经网络之一.其结构主要由输入层、隐含层和输出层构成,每层网络的神经元节点数由实际问题确定.BP神经网络迭代训练时首先进行正向传播,输入层的每个神经元通过权值连接隐含层的每个节点,将隐含层每个节点的输入值带入激活函数(sigmoid)中可得到每个节点的输出值,sigmoid函数的导数能很好地逼近非线性关系,并将值控制在0~1.每个隐含层节点输出值又通过权值连接到每个输出层的神经元.然后计算输出值与实际值的误差,将误差带入反向传播中,不断更新网络层之间的连接权值和隐含层、输出层的阈值,直到输出误差达到最小[24].本研究的关键算法步骤表示如下:
Oy=sigmoid(x×u+hy)
(2)
Oz=sigmoid(y×v+hz)
(3)
(4)
(5)
(6)
(7)
(8)
式中,Oy、OZ分别为隐含层、输出层节点的输出值,x、y分别为输入层、隐含层神经元节点值,u、v分别为输入层与隐含层之间的权值、隐含层与输出层之间的权值,hy、hz分别为隐含层、输出层的阈值.Ix、Iy、Iz分别为输入层、隐含层、输出层的输入节点值.δ为输出值与实际值的误差.σ′为sigmoid函数的导数.
式(4)、(6)、(8)中的LRA、LRB、LRC为学习率.式(2)、(3)分别是正向传播中隐含层、输出层的网络节点输出公式,式(5)为损失函数的计算公式,式(4)、(6)、(7)、(8)分别是反向传播中权值、阈值的更新公式.
1.6 粒子群优化算法
PSO的基本思想是共享群体中个体的信息来寻求适应度函数的最优解.群体中每个粒子有且仅有速度和位置2个属性[25].若计算适应度函数最小值,将个体极小值赋予全局最优解;反之,将个体极大值赋予全局最优解.然后将当前全局最优位置和个体历史最优位置带入式(9)~(10)中迭代速度、位置,最后根据目标函数问题性质更新全局最优位置解.
(9)
(10)
式中,ω为惯性因子,取值范围为0.8~0.2.其值越大,全局寻优能力越强,局部寻优能力越弱.Vj为第j个粒子的速度,Xj为第j个粒子的位置.C1和C2为学习率.Pbest为个体极值,Gbest为全局最优解.将个体的位置带入目标函数求得个体极值,然后根据目标函数最优解性质将个体极值(Pbest)赋予全局最优解(Gbest).
采用PSO优化支持向量机算法的步骤为:(1)归一化数据集,初始化粒子群的速度、位置;(2)将核宽度(g)和惩罚参数(c)分别作为粒子的位置(X1,X2),并带入式(9)、(10)迭代更新速度、位置,计算粒子的个体最优值和群体极值;(3)若满足终止条件,将获得的最优参数c、g带入SVM模型中迭代训练;(4)若不满足终止条件,重复更新粒子的速度、位置,寻找当前个体最优极值,直至满足条件,输出c、g.
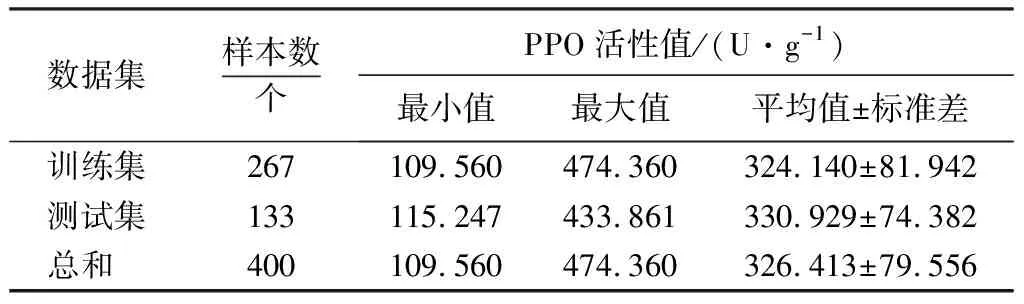
表1 400个样本的PPO活性真实值统计结果Table 1 Statistics of PPO values of 400 A. bisporus samples
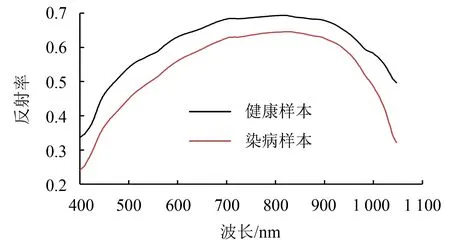
图1 健康、染病双孢蘑菇高光谱平均光谱曲线Fig.1 Average hyperspectral curve of healthy and infected A. bisporus
2 结果与分析
2.1 光谱数据与样本
采用柯尔莫哥洛夫-斯摩洛夫(kolmogorov-smirnov,KS)算法[26]将400个样本PPO活性值按2∶1的比例分为训练集和测试集,统计结果如表1所示.训练集、测试集的PPO值范围分别为109.560~474.360 U·g-1、115.247~433.861 U·g-1.测试集指标范围在训练集内,数据划分合理.健康、染病双孢蘑菇所有时期的平均光谱曲线如图1所示.健康、染病双孢蘑菇的平均光谱曲线变化相似.相对于表面有褐斑、霉菌的染病双孢蘑菇,健康双孢蘑菇表面光滑、白净,总体光谱反射率较高.去除首位噪声,选取450~1 000 nm高光谱波长范围(307个波段)进行研究.
2.2 基于PPO特征波段的活性值预测
2.2.1 竞争自适应加权算法优选波段 采用CARS法对所有样本全波段(307个波段)进行PPO活性值特征波段的选取.如图2a所示,设定采样次数N=50,随着采样次数的增加,曲线斜率不断减小,表明从“粗选”到“细选”过程中高光谱波段数由原来的307个减少至24个.如图2b所示,当采样次数为26次时均方误差最小,其值为39.采样次数从26次增加到50次的过程中,均方误差不断地增大或减小,表明与PPO敏感的特征波段被剔除或保留.为了建立稳定的预测模型,选取均方误差最小时采样次数所对应的特征波段数.即当采样数为26次时,提取到了与双孢蘑菇PPO活性值敏感的24个特征波段.特征波段依次为540.8、542.6、549.5、565.2、566.9、570.4、579.1、616.0、617.7、619.5、621.3、644.2、656.7、658.4、764.5、801.0、802.9、810.2、823.1、908.4、925.3、942.2、949.7、980.0 nm.
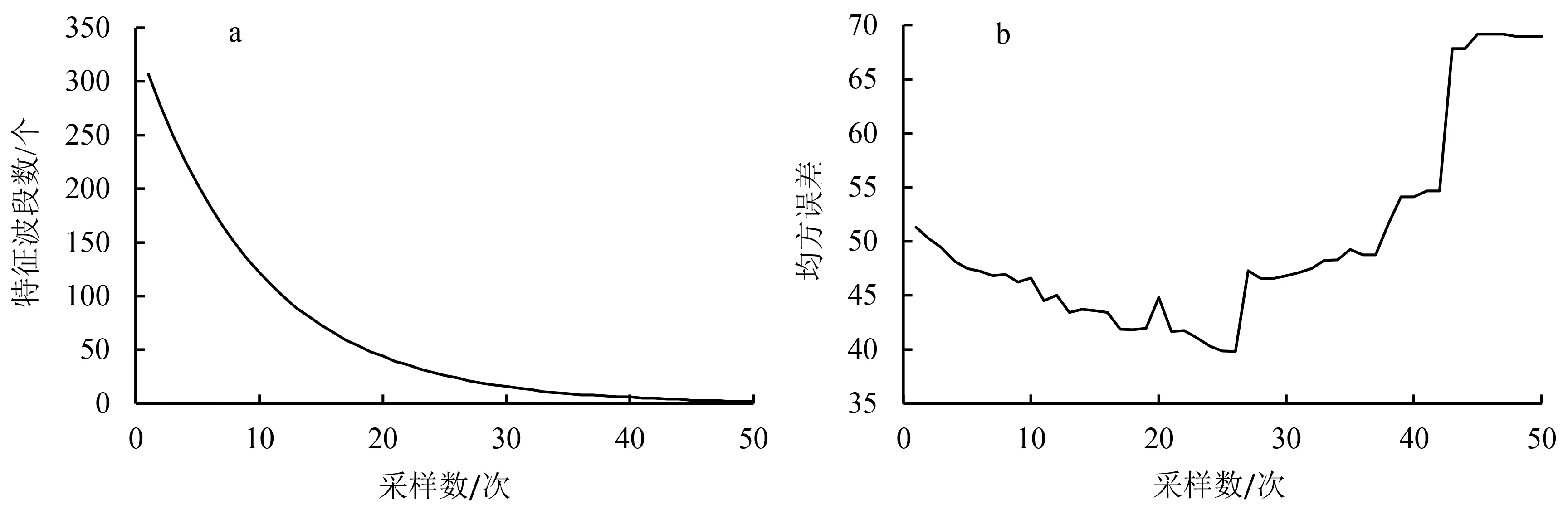
a:光谱波段数变化过程;b:均方误差变化过程.图2 CARS算法优选波段过程图Fig.2 Optimization of spectral bands by CARS algorithm
2.2.2 连续投影算法优选波段 采用SPA对所有样本全波段(307个波段)进行PPO活性值特征波段的选取,选取过程如图3所示.图3a表示随着模型内变量的引入,均方误差的变化过程.当引入10个变量时,均方误差最小.图3b表示各个波段的反射率.最终提取到了10个特征波段,依次为499.4、566.9、653.1、726.5、823.1、910.3、929.0、962.9、995.2、1 000.9 nm.
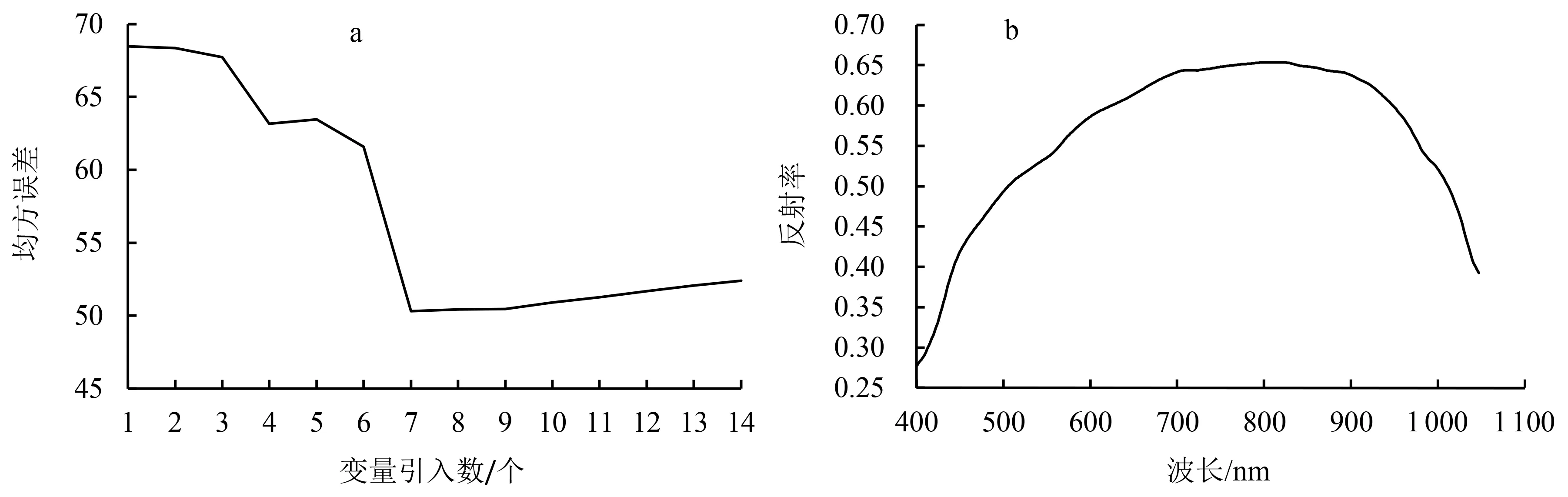
a:均方误差变化过程;b:波段筛选过程.图3 SPA算法优选波段过程图Fig.3 Optimization of spectral bands by SPA algorithm
分别将经过SPA、CARS提取的特征波段带入PLSR模型中预测PPO活性值.SPA-PLSR模型的训练集的相关系数(Rc)和均方误差(RMSEC)分别为0.921、0.303,测试集的Rp、RMSEP分别为0.917、0.349.CARS-PLSR模型训练集的Rc、RMSEC分别为0.923、0.306,测试集的Rp、RMSEP分别为0.904、0.340.
2.3 光谱反射率与疣孢霉病的相关性
本研究所提取的高光谱信息位于发病区域,可采用所提取特征信息对双孢蘑菇的染病情况进行判别.为了在对PPO敏感的波段中选取对病害敏感的特征波段,拟采用逐步回归法和相关性分析在经过CARS所提取的24个特征波段中筛选出与染病相关的光谱波段.
首先筛选出对染病情况贡献最大的特征波段建立回归模型,然后逐步加入剩余特征波段,最后在加入波段的过程中及时剔除不显著和共线性的特征波段,共建立8个回归模型.对染病情况贡献最大的566.9 nm波段最先被引入第1个回归模型,其次566.9、656.7 nm波段被引入第2个回归模型.以此类推,最后有8个特征波段按贡献率依次被引入第8个回归模型中,引入波段的顺序为566.9、656.7、617.7、658.4、801.0、980.0、908.4和942.2 nm波段.引入标准为F检验概率小于0.05.各回归模型的统计参数如表2所示.
随着蘑菇染病日的延长,贡献较低的特征波段样本内水分的流失会导致其吸收峰发生偏移,616.0、619.5、621.3 nm波段可能是水分特征波段617 nm发生偏移所致.此外双孢蘑菇在培养、接菌后,其内部物质含量会发生改变,802.9、810.2、823.1 nm可能是维C特征波段801、810、821 nm发生位置偏移所致.540.8、542.6和549.5 nm附近的吸收峰可能与双孢蘑菇内PPO分子中的O-H二级倍频(540 nm)、C-H二级倍频(543 nm)有关,565.2 nm附近的吸收峰可能与其C-H四级倍频(566 nm)有关[27].从表3可知,随着特征波段的引入,各回归模型的复测定系数(R)逐渐变大.回归模型8的R为0.891,表明所筛选的8个特征波段与染病判别的拟合度最大,R上标的a~h分别表示各个模型被引入特征波段的光密度,a表示第1个引入的波段光密度,h表示被引入的8个波段光密度.其回归模型8的决定系数(R2)为0.793,表示8个波段的光密度能解释双孢蘑菇染病情况的79%,其染病情况的21%由其他变量来解释.

表2 染病判别回归模型的统计参数Table 2 Statistical parameters for regression analysis of infection recognition model

表3 特征波段与染病情况的显著性分析结果1)Table 3 Significance analysis results of characteristic bands and infection
将经过逐步回归筛选出的特征波段与经过SPA筛选出的特征波段结合,采用皮尔曼相关系数对疣孢霉病进行显著性分析(表3).从表3可知,929.0 nm波段与染病情况在0.05水平上有显著相关性,其他光谱波段都在0.01水平上具有极显著相关性,且449.4 nm波段与染病情况呈负相关.
2.4 PSO算法优化及BP判别模型的建立
将筛选出的12个与染病相关的高光谱波段分别带入ELM、SVM、PSO-SVM和BP神经网络中进行建模比较分析.
从图4可知,设置迭代次数为100,种群规模为30,采用8折交叉验证来优化参数.为了平衡寻优能力,惯性权重w设为1.以核宽度和惩罚参数为目标函数的输入变量进行迭代,优化后的惩罚参数、核宽度分别为78.149、0.01,然后将最优解带入SVM计算双孢蘑菇的正确判别率.
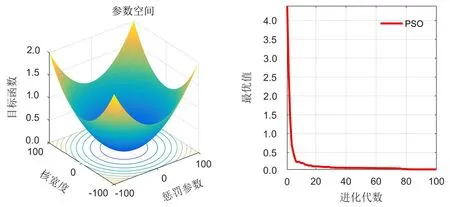
图4 PSO优化后的适应度函数值变化图Fig.4 Changes on fitting values after PSO optimization
在图5的3组学习率下的误差走势图中,迭代次数设为500,反向传播更新权值、阈值后,均方误差不断降低.学习率A=0.1,学习率B=0.1时,学习率较小,曲线很平滑,收敛速度较慢.A=0.5,B=0.6时,学习率适当增加后,收敛速度较第1组有所降低,曲线较平滑.A=0.8,B=0.9时,学习率快到上限时,收敛速度未发生明显改变,但曲线发散,迭代过程不稳定.输入层节点数为光谱波段数(12个),输出层节点数为输出类型数(2个).隐含层节点数可由下列3个经验公式计算:
(11)
m=log2n
(12)
(13)
式中,m、n、l分别是隐含层、输入层、输出层的节点数,α为1~10的常数.
从式(11)可得到隐含层节点数范围为4.7~13.7,从式(12)可得到隐含层节点数为3.6,从式(13)可得到隐含层节点数为4.9.隐含层节点数分别取式(12)、(13)的值以及式(11)的最大值.迭代后均方误差的变化趋势如图6所示,当m=4时,在迭代次数200次以内误差曲线较为发散,大于200次迭代次数误差趋向平稳.当m=5时,迭代次数在250次以内误差曲线较平滑,迭代次数大于250次曲线较为发散;且与m=4相比较,收敛后的均方误差较大.当m=14时,迭代过程中误差曲线较为平滑,且与m=4,m=5相比较,收敛后的均方误差有所减小.当m=40时,迭代2次达到过拟合的状态,训练模型停止.
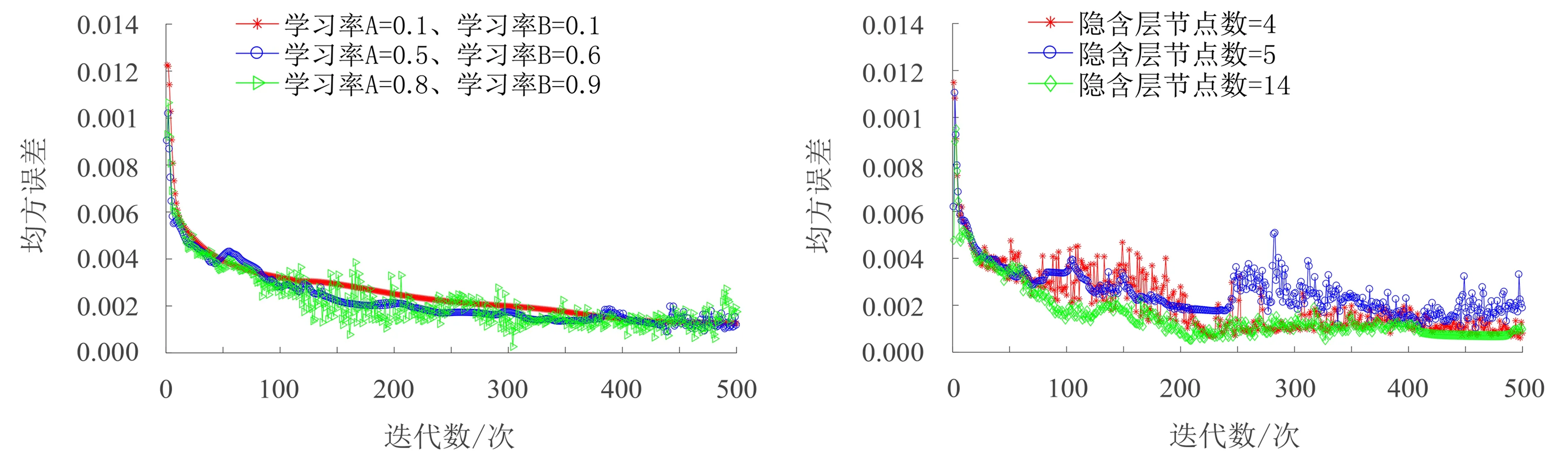
图5 不同学习率下的BP网络误差图Fig.5 Error diagram of BP network under different learning rates
表4为6种模型的建模效果,PSO-SVM、BP1、BP2测试集健康识别率最高,其值为93.333%,BP2测试集染病识别率、总体识别率最高,其值分别为95.890%、94.737%.
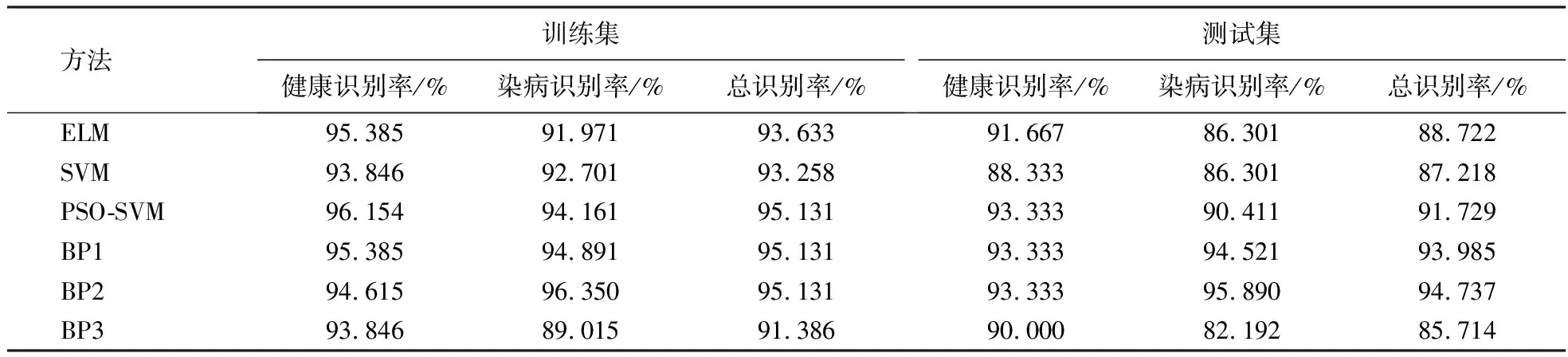
表4 6种模型的建模效果Table 4 Modeling effects of 6 models
3 小结
本文采用粒子群算法优化支持向量机和BP神经网络检测双孢蘑菇的早期品质.所建立的PPO预测模型SPA-PLSR精度最高,其RP、RMSEP分别为0.917、0.348.在所提取的特征波段中有8个被引入到回归模型中,决定系数可达78.6%.所建立的BP模型对双孢蘑菇病害的判别率最高,总体判别率可达94.74%.结果表明,优化后的机器学习模型可较好地实现双孢蘑菇外部品质的判别.
猜你喜欢
青年文学家(2022年13期)2022-07-06 02:16:00
安阳师范学院学报(2018年5期)2018-11-21 06:43:48
现代食品(2018年4期)2018-02-18 15:50:01
食用菌(2017年3期)2017-05-24 06:52:18
诗选刊(2016年9期)2016-11-26 13:47:43
妇女之友(2016年9期)2016-11-07 19:39:58
西藏科技(2016年8期)2016-09-26 09:00:59
作文周刊·小学一年级版(2016年1期)2016-08-12 12:57:15
文理导航·科普童话(2015年2期)2015-06-16 16:42:04
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:33
