
基于SELC模型的新闻文本分类方法
2022-11-24 02:29侯秀萍郑肇谦
长春工业大学学报 2022年3期
秦 硕,郑 虹,侯秀萍,郑肇谦
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
网络新闻的用户规模达到6.86亿人,占网民总体的80.3%。如何对这些庞杂的网络新闻数据进行高效的分类和管理,用户又该如何快速地获取自己感兴趣的新闻,已然成为亟待解决的问题。对新闻文本分类任务可以解决上述问题。
传统的文本分类方法不能自提取特征,需要人工提取特征。深度学习作为当下人工智能领域最热门前沿的技术,在自然语言处理中具有广泛应用,使用深度学习方法的文本分类不仅能够解决传统机器学习不能处理语义层面的问题,而且能够解决当数据量较大时分类效率低下等问题,是一个极其重要的研究课题,因此,使用深度学习的方法对文本分类进行研究在理论和应用上都有重要意义。
在数据预处理阶段,一般对长文本信息分类时采用截断式方法,这种方法无法确保截取后的文本还具有原文本的语义。深度学习中的循环神经网络(RNN)[1]和卷积神经网络(CNN)[2]在文本分类领域有广泛的应用。但是RNN模型存在梯度爆炸和梯度消失的问题,CNN模型在处理中文文本信息的时候,训练和处理时间较长。目前,比较流行的预训练模型有ALBert、Transformer和Bert等,但是这些预训练模型是基于字的隐藏,对于中文词语形式的语义表征不够完整。
为解决上述问题,文中先将长文本进行文本摘要,将摘要后的新闻文本送入ERNIE预训练模型[3],再结合双向LSTM和Attention机制[4]与CNN模型的方法。
1 相关工作
随着深度学习的广泛推广,Xu J等[5]使用带有缓存机制的LSTM捕获长期情绪信息。2015年,CNN模型在Zhang X等[6]研究下用于文本分类任务,主要提出一种字符级卷积网络模型。Yann L C等[7]使用卷积神经网络进行文本分类任务,实验表明分类质量显著提升,这表明卷积神经网络在情感分类任务中是有效的。2017 年,谷歌提出了 Transformer 框架[8],将文本之间的相关性进行建模,自注意力机制在encoder和decoder阶段计算出输入部分的表征,捕获各词直接关系,被广泛应用于各种预训练模型。2018 年,Devlin J等[9]提出基于深度双向Transformer 的预训练模型 BERT,Bert是先随机掩盖部分信息,然后通过上下文预测方式实现强大的语义表征。雷景生等[10]提出一种ERNIE_BIGRU的中文文本分类方法,并在新闻公开数据集取得了不错的分类效果。这些前人的工作表面预训练模型与神经网络模型的结合,效果非常不错,在特征提取和语义的完整性上展现了优秀的效果。
文中提出的文本分类模型是在现有的预训练模型与神经网络结合的模型基础上进行改进,解决了长文本截断式可能破坏语义的完整性和全局特征问题,在一定程度上能够对文本的特征语义进行理解,具有出色的文本特征表示和建模能力。在新闻文本分类任务上准确率有所提高。
2 SELC模型
针对传统的新闻文本分类任务方法的不足,文中目的是提供一种既能用于大规模的文本分类,也能用于精准地进行提取特征算法。SELC新闻文本分类模型的主要构成如图1所示。
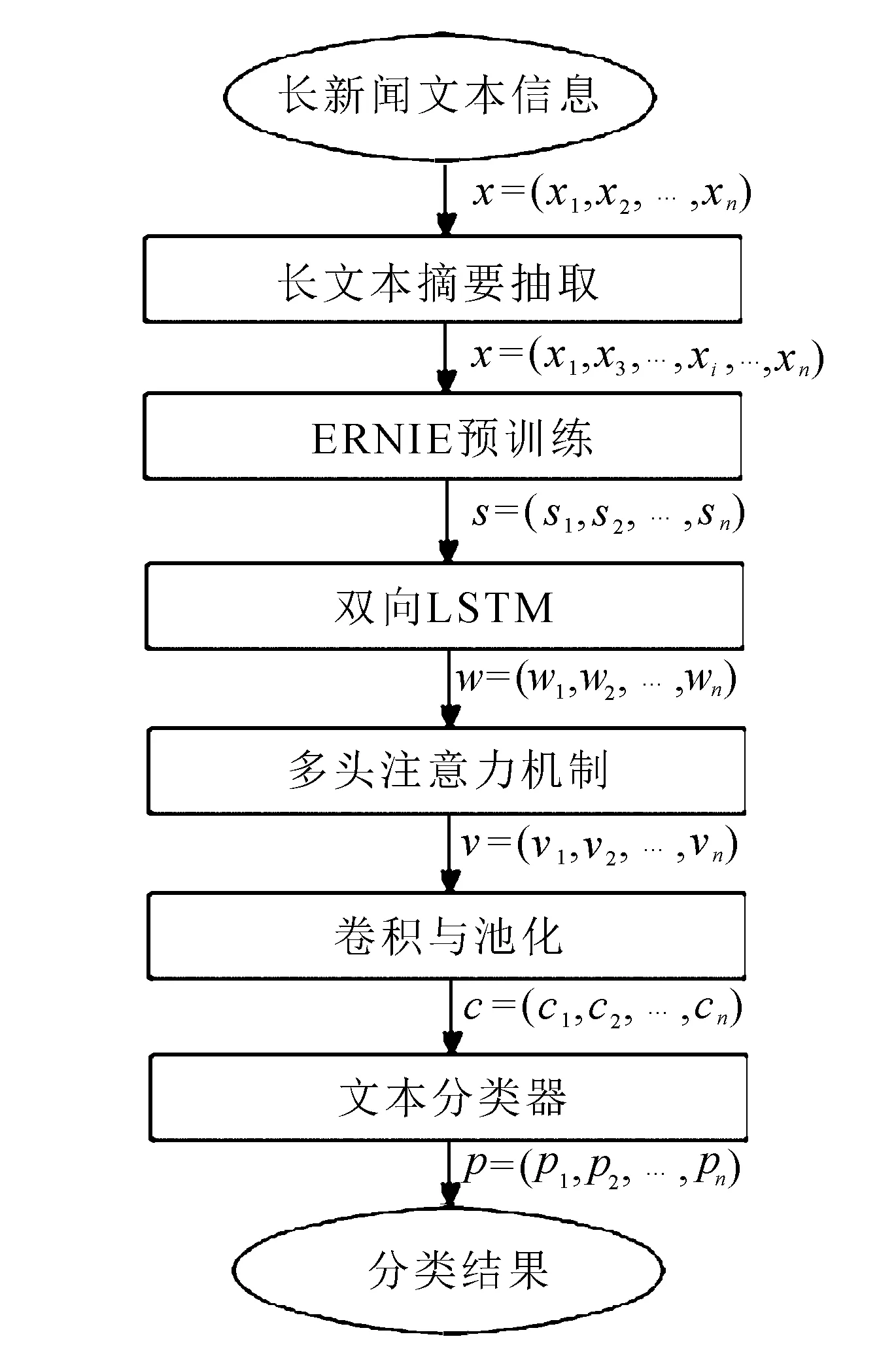
图1 SELC模型流程图
其中:x={x1,x2,…,xn}表示新闻文本的输入序列;x={x1,x3,…,xi,…,xn}与输入有所不同,表示摘要抽取后的文本序列;s={s1,s2,…,sn}表示经过预训练后的序列;w={w1,w2,…,wn}表示经过双向LSTM后的特征提取向量;v={v1,v2,…,vn}表示注入Attention后的权重矩阵;c={c1,c2,…,cn}是经过卷积与池化后的特征向量;p={p1,p2,…,pn}表示经过softmax分类器后的分类结果。
2.1 文本摘要抽取
针对长文本信息的文本分类时间过长问题,提出了文本摘要生成后输入的预处理办法,减少了模型的训练时间和算法的时间复杂度。采用抽取摘要生成方法,既保证了摘要在语法和事实的正确性,充分还原了原文,又表达出文章最主要的含义。
文中采用的摘要技术是Textrank算法[11]。这种算法受到网页排名算法Pagerank的启发,将文章的关键词、关键句进行排名,TextRank算法将文本中的句子对于网页,为每个句子之间的关联性作为权重,进行重要性评价。其基本思想是将文档看作一个句子的网络,在网络中的链接表示句子与句子之间关系。其算法为:
WS(Vi)=(1-d)+

(1)
式中:In(Vi)----包含Vi所指向的点;
Out(Vj)----所有点的子集;
Wji----将Out(Vj)所指向的数目记录下来;
Vi----除j外的点;
d----阻尼系数,有些类似目标函数中的正则项,加入后使整个计算更平滑,一般取0.85。
换句话说,根据两个句子之间的内容重复程度计算他们之间的相似度,构建以句子为节点,相似度为边权值的带全图结构,最后将规定数量排名最高的句子构成摘要。 因此,TextRank算法的抽取本质在于将文本中的关键词和关键句从文章中提取出来。
2.2 ERNIE预训练模型
ERNIE是在Google提出的Bert模型基础上改进的预训练模型。ERNIE也利用Transformer的多层自注意力双向建模能力对词、实体等语义单元的表示更加完整[12]。但是,Bert模型对于中文词法信息的缺失问题没有进行专门的建模,而ERNIE通过对训练数据中的中文结构、语法结构、词法表达等信息进行统一建模,通用语义表示能力有了极大的增强。ERNIE模型结构如图2所示。
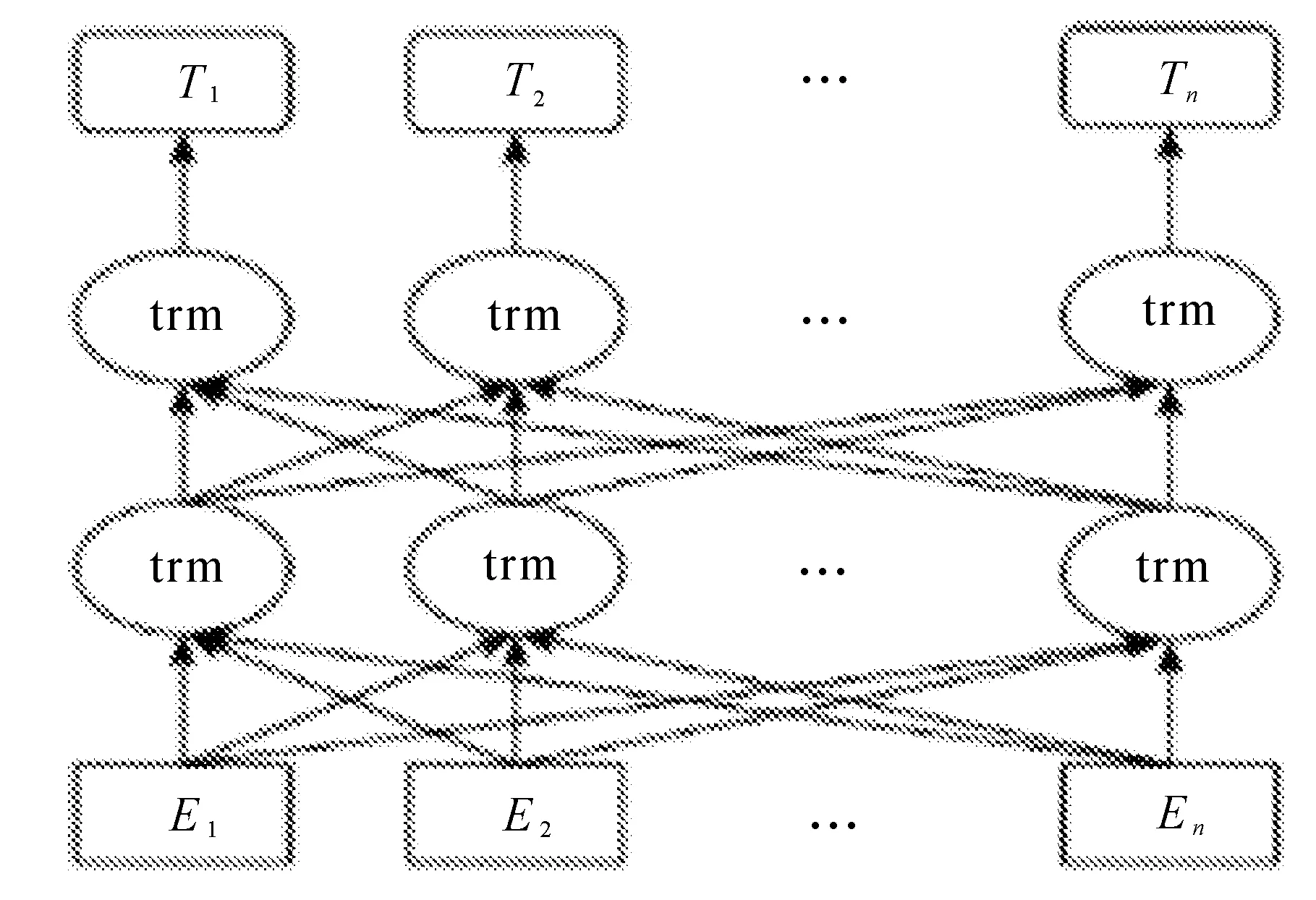
图2 ERNIE模型结构
由图2可知,输入向量是embedding后的向量表示;其中trm表示ERNIE模型联合调节所有层Transformer完成预训练双向表示,每个Transformer输出表示和Transformer的自注意力层公式表示为:
LayerNorm(x+Sublayer(x)),
(2)
(3)
ERNIE模型输出部分包括了文本上下文向量信息表示,并且输出部分的词向量都将整个序列的文本向量信息包含在内。
此外,由于ERNIE预训练模型对中文的歧义问题处理较好,可以作为Embedding词嵌入层获取词向量表示。通过学习后,得到一组新的词嵌入表示,该组词的展示具有丰富的语义信息,便于模型下一阶段。
2.3 双向LSTM层
LSTM是RNN模型的改进,解决了RNN模型长期依赖和梯度爆炸的关键问题,LSTM可以学习长期依赖信息。LSTM的关键就是细胞状态,细胞状态类似于传送带,直接在整个链上运行,并加入了遗忘门、输入门和输出门。
遗忘门是控制上一层细胞状态,通过sigmoid激活函数后保留或去除上一层细胞状态的内容;输入门是将当前序列位置的输入确定需要更新的信息更新状态;输出门是用细胞状态保存的内容确定输入的内容。而我们有时预测可能需要前面若干输入和后面若干输入共同决定,因此提出双向循环神经网络。双向LSTM结构如图3所示。
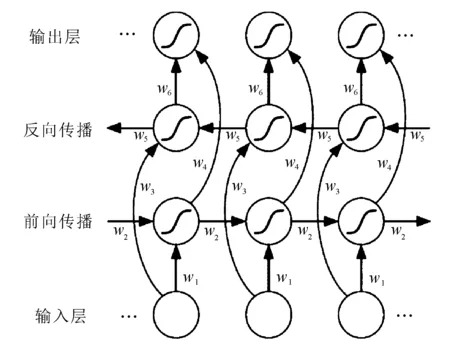
图3 双向LSTM模型结构
前向传播和反向传播共同连接输出层,其中包含了共享权重w1~w6。每个结合前向传播和反向传播相应时刻的输出结果得到最终的输出,其表达式为:
ht=f(w1xt+w2ht-1),
(4)
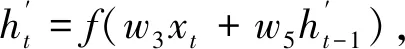
(5)
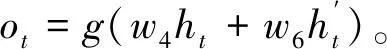
(6)
双向LSTM神经网络结构模型对文本特征提取效率和性能要优于单个LSTM结构模型。
2.4 多头自注意力机制
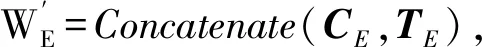
多头注意力机制可以简单有效地对上下文依赖关系进行抽象,并捕获句法和语义特征。其中WE作为Q,K,V一般框架下的标准Attention。其计算过程为
Anention(Q,K,V)=softmax(fatt(Q,K))V,
(7)
式中:fatt----概率对齐函数。
采用Scaled Dot Product,其中,
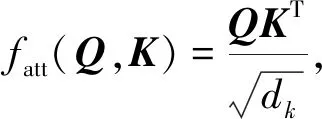
(8)
式中:dk----矩阵的维度。
在多头注意力机制中,输入特征通过不同的权值矩阵被线性映射到不同的信息子空间,并在每个子空间完成相同的注意力计算,以对文本潜在结构和语义进行充分提取,其中第i头注意力计算过程为
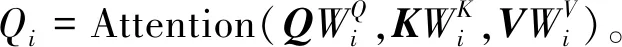
(9)
最后将各个head进行合并,产生多头自注意力机制的输出,设注意力的头数为m头。
则WE经过多头注意力计算得到
MHS(Q,K,V)=Concat(O1,O2,O3,…,Om),
(10)
H=MHS Att(WE,WE,WE)。
(11)
2.5 卷积与池化
新闻文本信息经过以上处理后得到新的语义向量以及权重分配,利用卷积和池化再进一步特征提优,其中卷积输出计算过程为
zi=f(F⊙Hij+l-1+b),
(12)
式中:f----激活函数Relu;
F----滤波器;
b----偏置项;
l----滑动窗口大小;
Hij+l-1----由多头注意力机制组成的特征矩阵。
Zi作为第i个卷积核的输出,计算过程为
Zi=Concatenate(z1,z2,z3,…,zn-l+1)。
(13)
池化操作,通过第i个卷积核计算获取的文本特征作为池化层的输入,对获取的特征进一步筛选,得到更重要的特征。使用最大池化操作,Pi为第i个卷积核池化后的结果,计算如下:
Pi=max(z1,z2,z3,…,zn-l+1)。
(14)
最后获得经过池化和卷积的向量P,其中r为卷积核的数量,将池化后最终得到的特征向量作为全连接层的输入,再利用最后一层的softmax分类器进行文本所属类别的概率计算,完成文本分类任务。其中σ是用来预测文本的类别,函数argmax计算导致概率值最大的文本类别标签,其公式为:
σ=Linear(P),
(16)
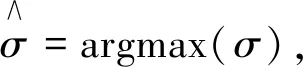
(17)

函数argmax计算导致概率值最大的文本类别标签。
3 实验及结果分析
3.1 实验环境
实验在CentOS 7.9 环境下运行,使用显卡NVIDIA TITAN XP,内存32 G,编程语言选择Python 3.7,使用的深度学习框架为Pytorch 1.8.1,编译器使用Pycharm。
3.2 数据集介绍
新闻数据集由来自新浪网等大型新闻网站爬取20 000条网络上真实的新闻文本,数据集包含新闻标题和内容信息,并且分为10个新闻类别的数据集。为了保证数据集质量,爬取时每个类别均为2 000条数据,分布均衡,数据集不存在长尾分布。将两个数据集分别整体划分为8∶1,作为训练集、测试集,使用清华大学提供的THUCNews新闻文本分类数据集中的验证集作为验证文中算法验证集。
3.3 实验设计
实验通过上文介绍的模型进行对比验证,共设置了5组对比实验,分别是根据前人提出的模型与文中所提算法模型对比,为了使模型能表现出自身最佳的分类性能,参数设置见表1。
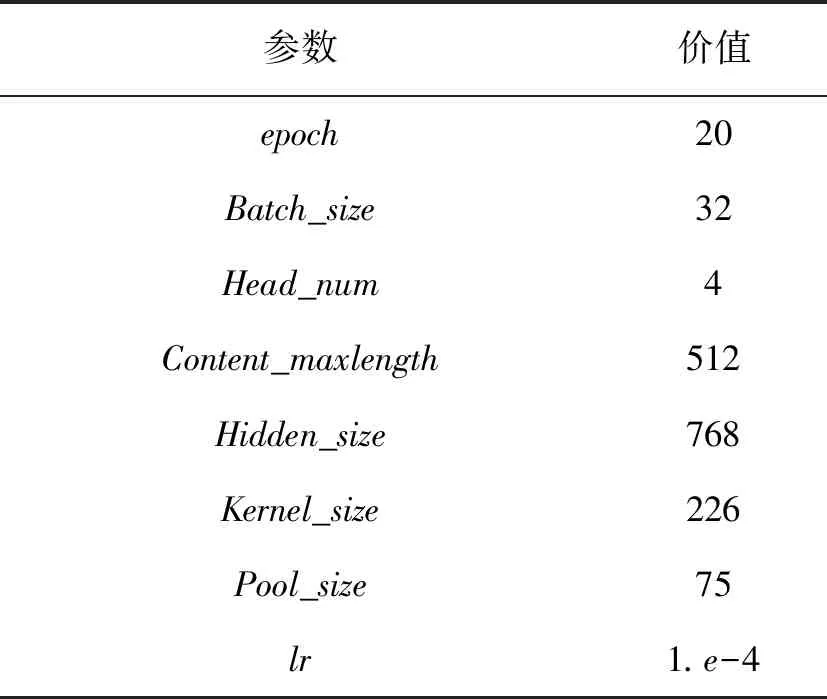
表1 实验的超参数表
3.4 评价指标
目前,在自然语言处理领域的评价指标多种多样,但针对文本分类的评价标准一般使用准确率P、召回率R和F1值,具体计算公式如下:
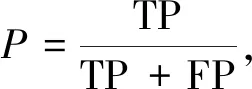
(18)
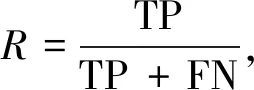
(19)
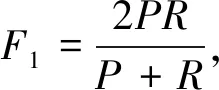
(20)
式中:TP----实际值与预测值都为正时的数据量;
FP----预测值为正,实际值为负时的数据量;
FN----实际值与预测值都为负的数据量。
由式(20)可知,F1值是P与R共同决定的。
3.5 实验结果与分析
为了验证本方法对新闻文本分类方法的有效性,在同等条件下,文中提出的SELC模型准确率优于其他中文文本分类的基线模型,在前人的模型与文中模型相同设备,数据集、参数设置相同的条件先进行对比实验。CNN_BASE,BERT_CNN,ERNIE_BiGRU_CNN,ERNIR_CNN等文本分类模型,本模型在验证集上的损失值和准确率对比其他模型稍有进步。不同模型在新闻文本分类验证集上的准确率与损失值见表2。
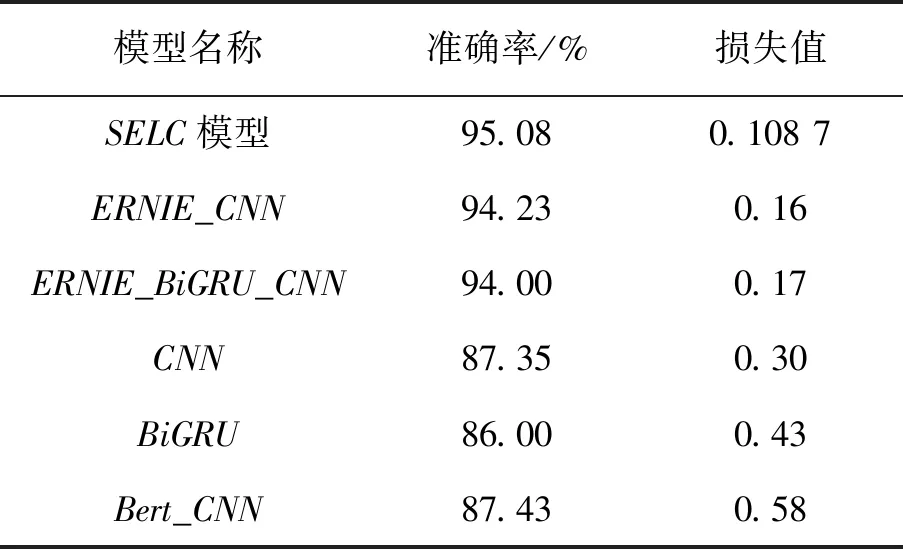
表2 不同模型的准确率及损失值
使用验证集对经过20个epoch 后的训练模型进行验证,分别得到 10 个类别的准确率、召回率和F1值。对10个类别的3个评价指标分别取平均值,得到不同模型在每一轮的训练情况。最后将训练好的模型通过测试集进行测试,得到结果见表3。

表3 不同模型的不同评价指标
验证集的准确率对比图如图4所示。
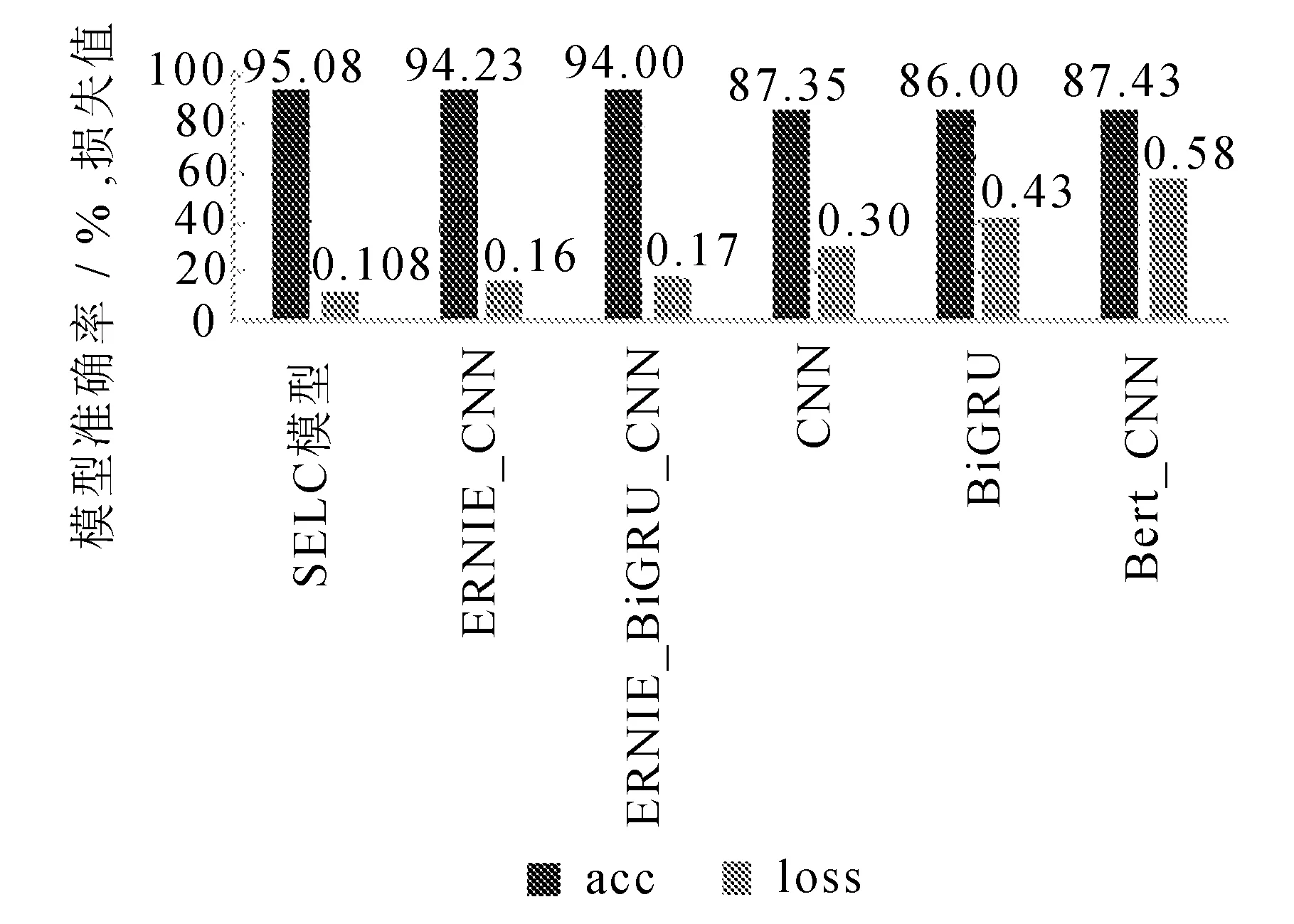
图4 验证集的准确率对比图
通过图4模型准确率和损失值对比结果可以看出,在预训练后的向量加入双向LSTM、多头自注意力机制的卷积神经网络对文本分类任务的准确率有明显提升,在1%左右,并且损失值下降0.5。
从以上实验结果数据可以看出,本模型与其他模型在同等实验条件下要比之前学者提出的模型效果在新闻文本分类任务中有不错的提升,由此说明,在长文本分类时,将文本摘要化对原文本的语义信息没有很大变化,可以将摘要后输入代替截断式输入,ERNIE预训练模型在中文数据集中有不错的表现。
在三种评价指标方面,文中模型在准确率方面提升并不是很大,仅有0.03,召回率有所增长,表明ERNIE预训练模型对中文语义信息捕捉更明显,由于F1值受到准确率和召回率共同影响,所以F1值也有所增长,由此推知,文中模型在文本分类任务中比之前文献所设计的模型分类效果更好,更加具有优势。
4 总结与展望
设计的模型是应用于新闻文本分类任务的模型,其创新点在于将传统的截断式输入改进为摘要后输入模型,这样极大地减少了模型训练时间,并有效地减少了时间复杂度;将ERNIE预训练模型应用到文本中,利用ERNIE对中文可以通过多任务学习逐步建立和学习预训练任务,并能生成更准确的语义词向量表示,在中文应用有不俗的表现,再融合双向LSTM、多头自注意力机制和卷积神经网络的新闻文本分类模型。在相同的实验环境下进行了大量对比实验,实验显示,提出SELC模型的分类效果优于其他模型。
虽然本模型在准确率和评价指标上取得了不错的成绩,并在数据集中展现了优秀的分类效果,但是也存在不足,如本模型在抽取阶段的工作并不完美,还存在对于文本的语义特征丢失的情况,对于新闻中的热词新词判别错误等。因此,接下来的工作是要对摘要提取阶段的工作进行研究,使得文中提出的模型准确率进一步提高。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
电视技术(2014年19期)2014-03-11
