
一种基于LSTM物流资源需求预测模型
2022-11-24 02:29胡艳娟潘雷霆
长春工业大学学报 2022年3期
胡艳娟,胡 伟,潘雷霆
(长春工业大学 机电工程学院, 吉林 长春 130012)
0 引 言
在云制造环境下物流资源配置得到了优化,企业实现了信息、资源共享,这对物流企业也提出了新的挑战。物流企业为了增强整体实力和竞争力,需要有效解决供需双方不断变化的需求。
物流运输过程的供需双方为了防止缺货而人为地增加安全库存。同时,物流配送服务中产生的服务成本以及配送时路况变化的影响也是不容忽视的。这些问题累加到一定程度将会导致牛鞭效应的产生,为了预防这一情况,需要对物流需求进行预测。
在云制造平台上,汇集了大量的物流资源与服务,并实现了物流资源信息共享。物流资源调度过程中,云制造平台通过对客户未来需求进行预测,并结合用户所需服务容量评估平台内物流资源提供方的服务能力。这种模式下,用户可以根据自身需求,以租赁的方式从云平台获取对应的资源与服务。因此,云制造模式下的物流资源需求预测方法需要考虑客户需求信息多变性、物流任务时序的不确定性和物流服务的其他性质,使得物品属性与物流资源属性相匹配。
物流企业大多采用经验预测法和传统预测法[1]预测所需的物流资源。但是,经验预测法过于主观、缺乏科学依据,对客户需求进行长期预测时,存在较大的误差。传统预测法在处理离散型数据时,难以取得理想的预测效果。此外,传统需求预测方法很少考虑到需求量和相关影响因素的内在影响关系。近年来,众多学者对深度学习理论在资源需求预测方面进行了深入研究。
文中在云制造环境下采用一种基于LSTM框架的需求预测模型,该模型与其他预测模型相比,能够更好地利用平台闲置的物流资源,实现物流资源信息精准预测。
1 国内外相关工作研究现状
物流运输过程中受时间变化、突发事件等非线性因素影响,单一物流需求预测模型的预测效果差,难以满足物流管理的实际要求。为解决上述问题,国内外学者纷纷对物流资源需求预测进行研究。杨建成[2]分析了ARIMA与SVM的优缺点,并在此基础上提出了基于ARIMA-SVM的物流需求预测模型,该模型可有效提高物流需求预测精度;牛思佳等[3]提出利用熵权法和灰色预测法相结合,对北京大兴机场航空物流吞吐量进行预测,得出在未来5年内机场货邮吞吐量预测值,但是这种方法在处理较大数据时缺少鲁棒性,其模型在进行大数据和长期预测时缺乏长效性和扩展能力;Kohestani V R等[4]采用随机森林和 Keras回归神经网络算法对食品需求量进行预测,实验表明,采用随机森林算法模型的性能优于人工神经网络模型的性能。深度学习是一种模仿人类大脑来认识数据模式的学习算法[5]。在处理非结构化数据(如图像、文本、语音等)方面体现出极为优越的性能。如Zhuo Q Z[6]等提出的有长短时记忆(LSTM)神经网络模型;刘明宇等[7]提出门控循环单元(GRU);Zhao X等[8]提出神经网络模型和栈式自编码(SAE)神经网络模型等优化模型参数,不断逼近理想参数值,优化模型整体性能;Altche F等[9]提出使用长短期记忆(LSTM)网络能够有效处理关于时间序列的相关问题。也有学者发现其他深度学习的方法,如量子生成对抗网络[10](QGANs),它是利用量子信息原理把输入特征映射到输出分类,Wang G等[11]将其改进提出了前馈神经网络(FNN)等,这些方法都可以运用到物流资源需求预测中。
在其他领域中,深度学习方法在需求预测方面也有一定的借鉴意义。 戴稳等[12]为了预测铣刀磨损损耗程度,简化了传统信号处理过程,并提出基于堆叠稀疏自动编码网络与卷积神经网络的两种预测模型,实验验证了其模型具有更好的效率与更优的精度;张阳等[13]提出一种改进小波包分析和长短时记忆神经网络组合(IWPA-LSTM)的短时交通流预测方法,来克服交通流在不稳定状态下,较短时间内交通流预测精度不高、过分依赖大量的历史数据等缺陷。
2 建立物流资源需求预测模型
2.1 模型描述
云制造环境下物流资源调度系统如图1 所示。
图1中,云平台根据获取需求方的历史物流需求数据及其相关数据(a),利用自身强大的计算能力将这些数据转化为多个物流任务,形成任务池(b),并考虑到极端天气(雨、雪等)和交通堵塞等影响物流需求因素。把这些物流任务及其影响因素代入到物流资源预测模型(c)。将这些预测结果和原先等待的物流任务汇集起来形成新的任务池(d),评估该任务池中物流任务所需的物流服务容量和类型,同时,评估云制造平台上闲置的物流服务,根据不同的物流服务特征来划分物流服务类型,并融合到平台的资源池(e)中。根据资源池中的物流服务类型与任务池中的物流任务,按照时间顺序进行对应(f),实现物流资源实时调度(g)。然而,在物流资源智能调度过程中,到达云平台中物流任务的类型、时间等都具有不可预测性。所以,需要对所需的物流资源进行预测,以满足即将到达云平台的物流任务所需要的物流服务。另外,在云制造环境下,除了需要预测即将达到的物流任务,并及时提供需求方所需的物流服务,还需要充分考虑与物流资源需求量相关因素的内在关联,并选择所需要预测的目标和采用合适的算法。
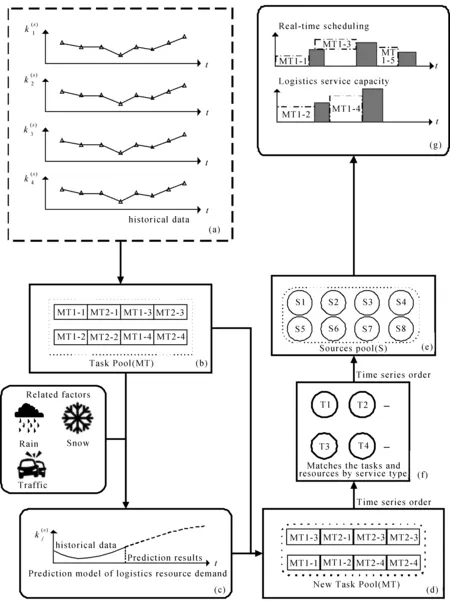
图1 云制造平台中物流资源调度系统
与传统的机器学习相比,基于长短期记忆网络(LSTM)建立的模型面对复杂多变的环境,仍然可以有效预测物流需求。而且LSTM模型还能有效避免RNN模型在预测过程中出现梯度消失与梯度爆炸的现象。它包含输入层、隐藏层和输出层,同时,层与层之间连接方式是全连接的,且序列数据将随时间步长递增。
2.2 影响物流需求预测的因素
影响需求变化的因素主要为三类:需求方所需服务类型发生变化、市场行情对需求的扰动、极端天气和不可抗拒灾害。文中记录5种影响因素判断指标,分别是客户满意度、市场期望值和雨、雪、交通事故的记录次数,并对其进行归一化处理[14],将其转化为监督问题。
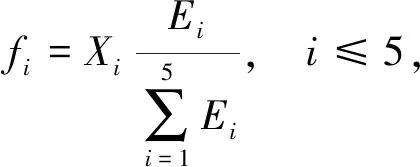
(1)
式中:Xi----评估结果i;
Ei----相对重要程度i。
2.3 预测目标
预测目标是预测即将达到任务所需的物流资源需求量(见图1)。根据周期性到达平台的配送需求历史数据,预测接下来配送服务需求量,据此产生虚拟需求量补充到调度模块的决策队列中。可以通过使用上一个时间步长t0的需求量z0作为输入,预测当前时间步长t1的需求量z1作为输出来实现。
采用单步预测方式对预测系统中的模型进行训练,设定1 h为一个单位时间步长,用过去三个时间单位步长的样本数据zm、zm+1、zm+2预测当下一个单位时间步长的样本数据zm+3。采用标签编码方式对样本数据按时序进行编码,输出时也按照时序输出预测的数据,并标记标签,即:
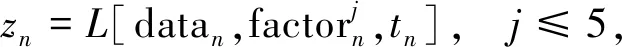
(2)
Γ(z0,z1,z2,z3,…,zn)≈Outn,
(3)
式中:datan----n时刻需求数据;
j----影响需求预测因素的类型;
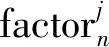
tm----m时刻的时间步长。
z0,z1,z2,z3,…,zn----分别为样本在0~n时刻输入的序列样本;
Outn----样本在0~n时刻输出标签。
2.4 激活函数和损失函数
模型权重参数求解采用常见的梯度下降法,通过迭代逼近求取权重参数最佳值。文中采用sigmoid函数f(z)和tanh函数g(z)作为预测模型训练的激活函数[15],即:
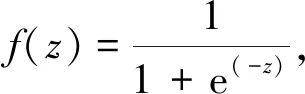
(4)
g(z)=2f(2z)-1。
(5)
采用均方根误差和平均绝对误差作为预测模型训练的损失函数,并采用RMSE优化算法和MAE优化算法作为线索寻求最优参数来评价模型的性能水平。优化器则选用Adam[16]优化器进行梯度优化,使得模型准确率不断提高,即:
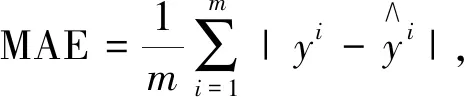
(6)
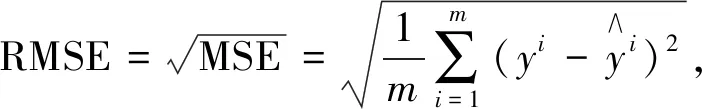
(7)
式中:m----迭代次数;
yi----实际值;
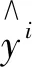
2.5 数据来源
文中数据来源于南方某个物流公司的物流需求数据[17],对数据进行整合后,对其进行脱敏、归一化处理。处理后的需求数据样本一共有9 000个,按照配送服务完成时间为基准,并以小时为单位统计。将数据样本分为训练组和测试组。其中,训练组的样本数据数量为8 775个,测试组的样本数据数量为225个。
3 物流资源需求预测模型仿真
3.1 不同算法下物流资源需求预测模型
ARIMA(p,q,d)模型[18]由三部分组成:AR(p)表示p阶自回归模型;d为差分阶数,记作I(d);q阶移动平均模型,记作MA(q)。虽然ARIMA预测模型简单,不需要依靠其他外界因素的数据也可以精准预测。但是,他要求数据的时间序列是稳定的,且具有线性关系,而物流需求预测需要考虑到多重影响因素。
RNN神经网络在处理时间序列问题时,具有良好的效果。然而,RNN神经网络模型随着时间轴传递会出现梯度消失和梯度爆炸的现象,在处理长周期的时间序列问题时,RNN模型会显得力不从心。因此,需引入LSTM神经网络结构,并训练LSTM的相关算法。
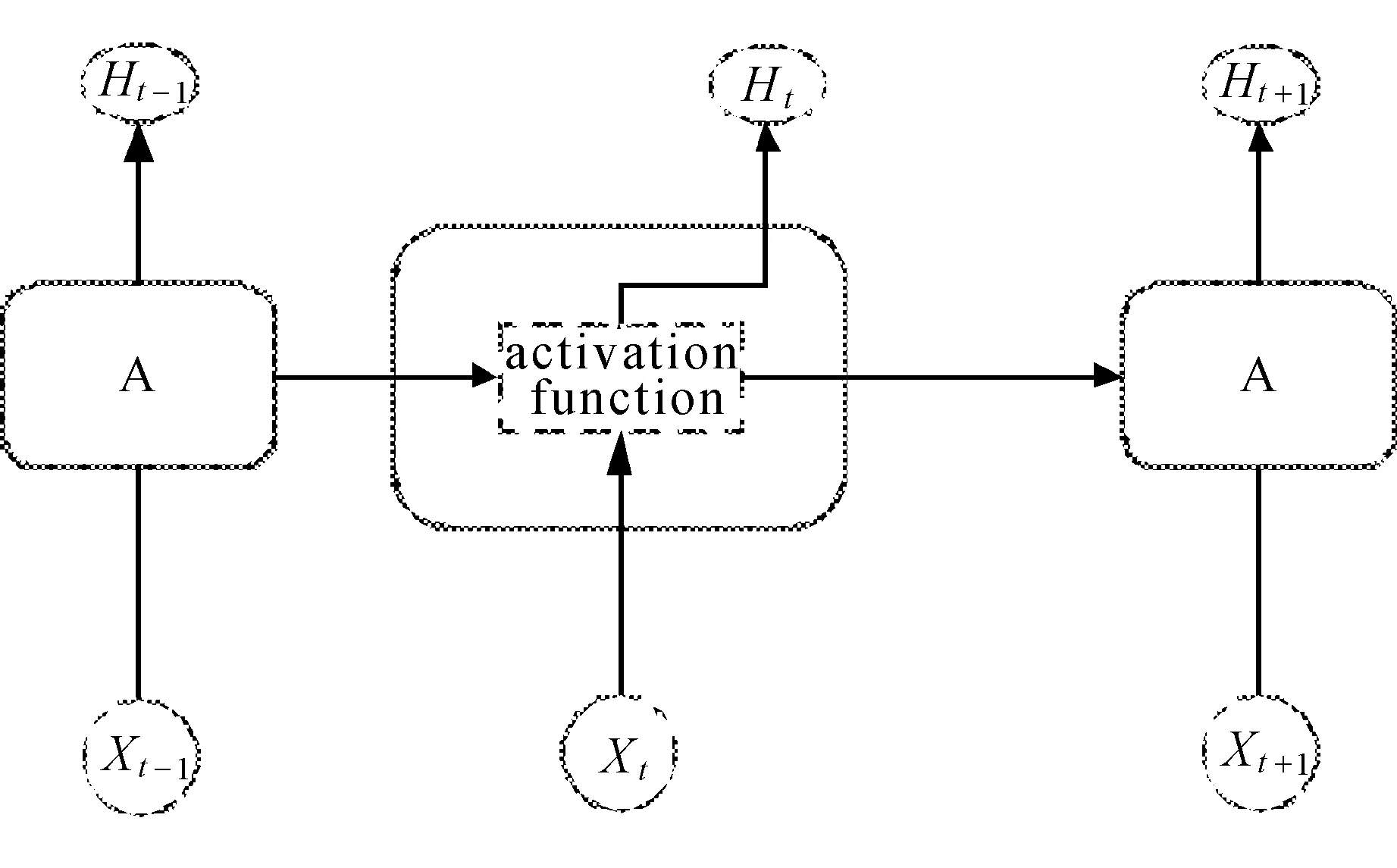
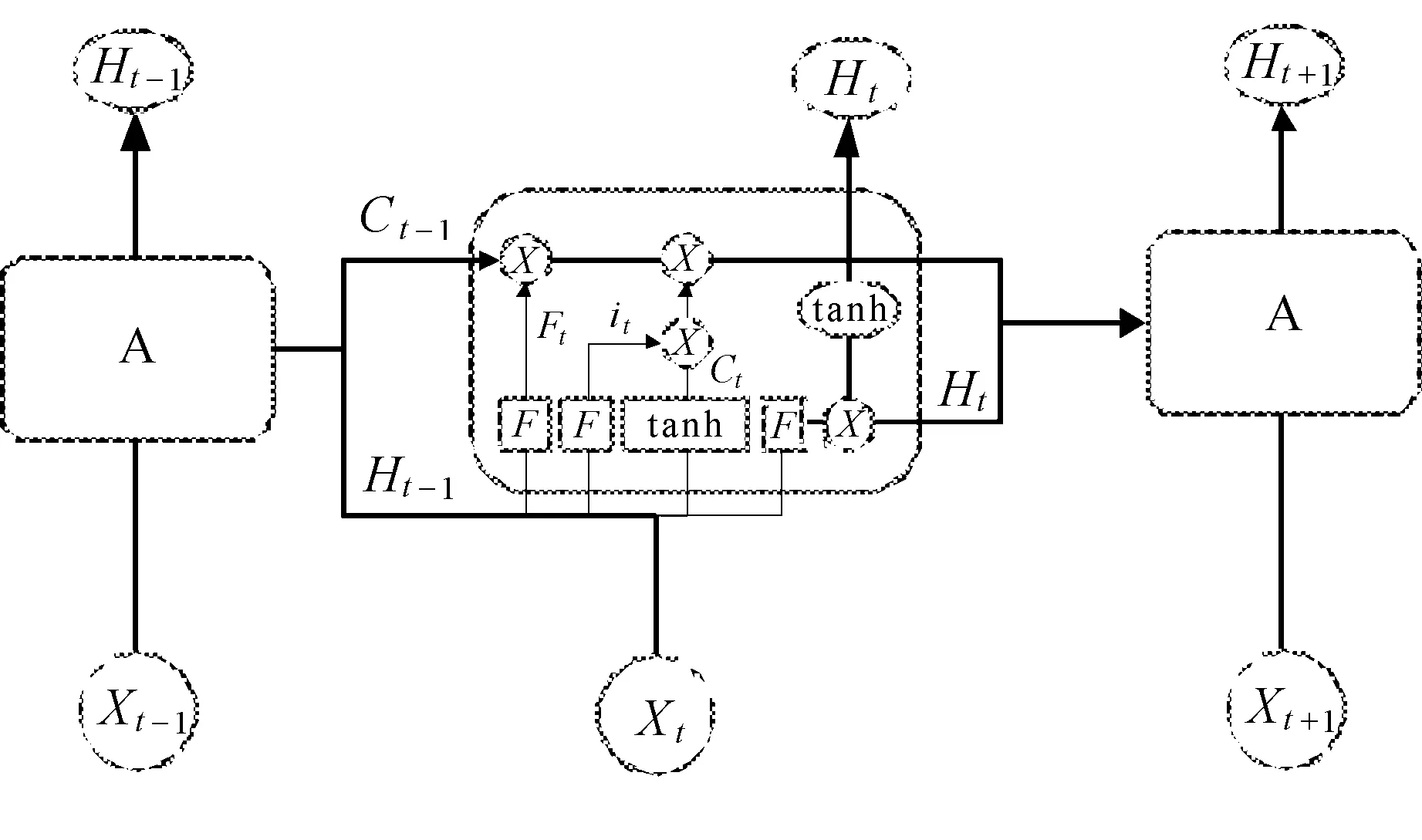
RNN神经网络和 LSTM神经网络结构如图2所示。
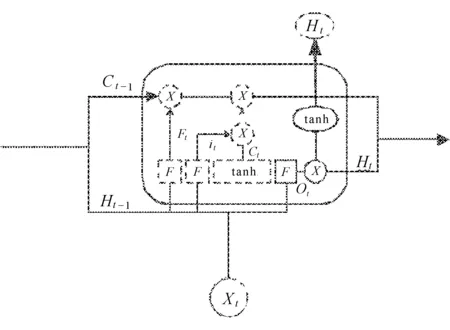
相比RNN只有一个传递状态Ht,LSTM则有两个传输状态:Ct(cell state)和Ht(hidden state)。LSTM是通过一种“门”结构来达到对传递信息保护和控制目的。这三个门分别为输入门、遗忘门和输出门。
RNN神经网络和 LSTM神经网络结构如图3所示。
遗忘门对于上一个节点传送的数据信息进行选择性记忆。主要通过忘记函数Ft读取上一隐藏状态Ht-1和这一阶段输入xt,控制上一状态Ct-1。其中,Ct-1的数值介于0到1之间。1表示“完全保留”,0表示“完全舍弃”,见图3(a)。
Ft=Φ(Wf·[Ht-1,xt]+bf),
(8)
式中:Φ----sigmoid函数;
Wf----遗忘门的权重矩阵;
bf----遗忘门的偏置项。
(a) RNN
(b) LSTM
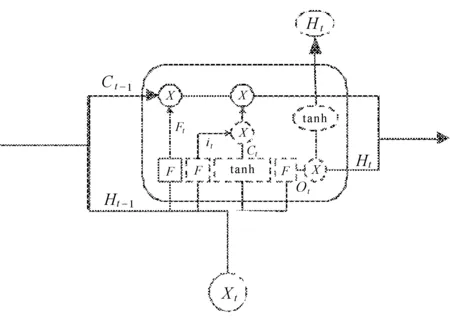
(a) 遗忘门
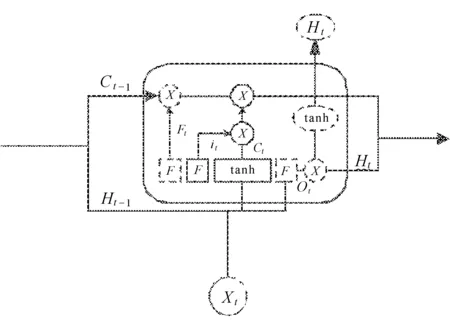
(b) 输入门
(c) 输出门
输入门对上一个节点传送的数据信息进行选择性记忆。主要是对输入xt进行选择记忆。首先,输入门中的sigmoid层决定哪些信息需要更新;再通过tanh层生成一个向量,也就是备选的用来更新的内容it。
it=Φ(Wi·[Ht-1,xt]+bi),
(9)
式中:Wi----输入权重矩阵;
bi----输入门的偏置项;
it----输入函数。
其次,我们把这两部分联合起来,更新Ct的状态,将旧状态Ct-1更新为Ct、Ct-1与Ft相乘,丢弃掉确定不需要的信息。t中tanh激活函数将内容归一化至-1到1之间;接着加上itt,即新的候选值,并根据我们决定更新每个状态的程度进行变化,见图3(b)。
(10)
Ct=Ct-1Ft+ict,
(11)
输出门ot首先需要运行一个sigmoid函数确定将要输出的部分。通过tanh函数进行处理,将数值范围控制在-1到1之间,并将它和sigmoid门的输出相乘,见图3(c)。
ot=Φ(Wo·[Ht-1,xt]+bo),
(12)
Ht=ot*tanh(Ct),
(13)
式中:Wo----输出权重矩阵;
bo----输出门偏置项。
3.2 LSTM神经网络训练流程
文中采用LSTM 神经网络的训练流程,如图4所示。
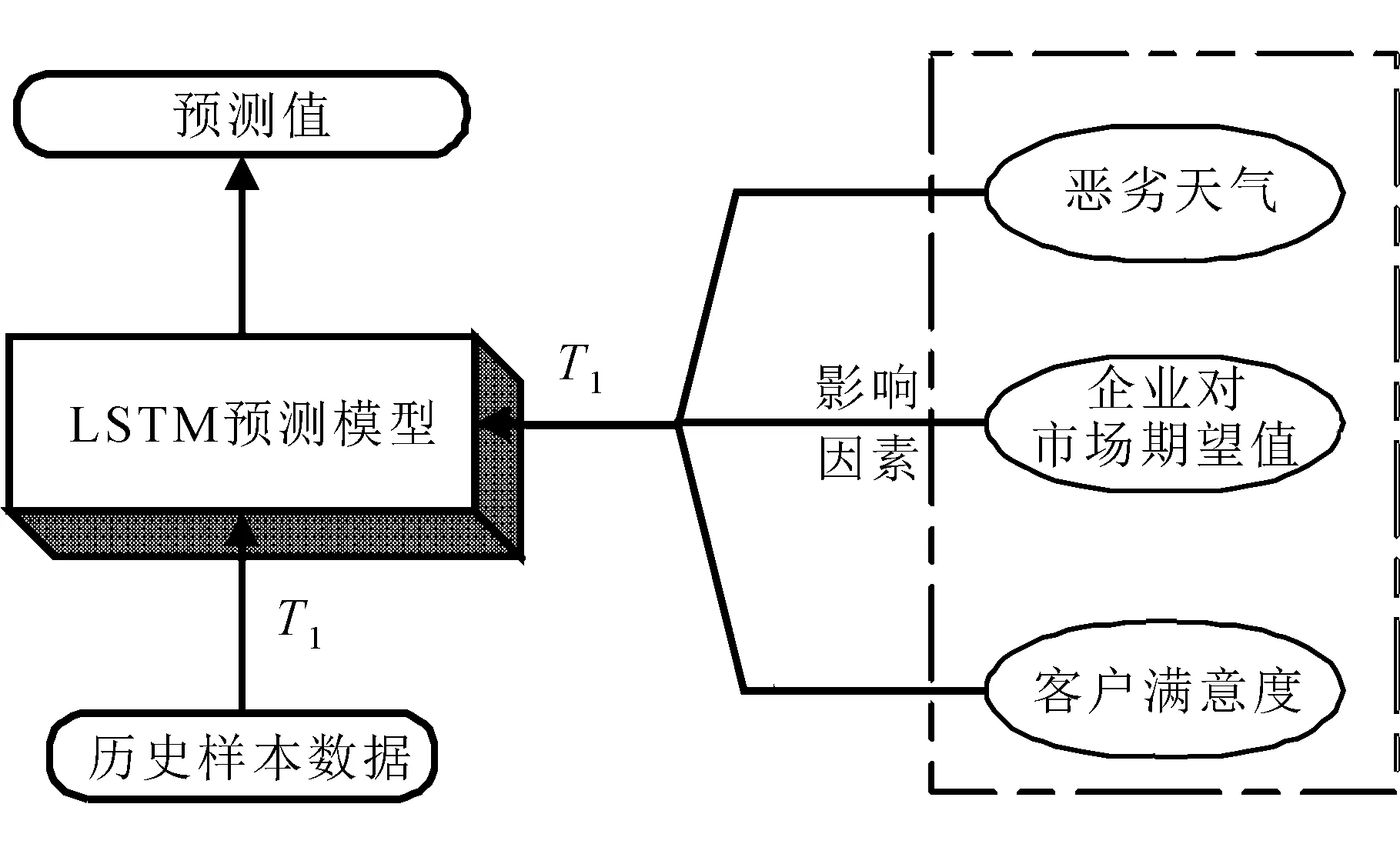
图4 LSTM神经网络的训练流程
输入:各个时刻(T1,T2,T3,…,Tn)的配送点需求量和导致配送异常的影响因素异常值。
1)创建LSTM神经网络。
2)输入T1、T2时刻配送点需求量和导致配送异常的影响因素常值。
3)将T1、T2时刻数据进行训练,输出训练后的期望值。
4)输入T2、T3时刻配送点需求量和导致配送异常的影响因素异常值。
5)将T2、T3时刻数据进行训练,输出训练后的期望值。
6)直至完成对Tn-1时刻数据训练,输出最后一个期望值Tn。
7)LSTM神经网络训练完成。
输出:LSTM神经网络训练后的结果。
3.3 实验与仿真结果
实验配置见表1。

表1 实验环境配置
采用Tensorflow[19]深度学习框架,编程语言版本为Python3.7,在anaconda环境下建立物流资源需求预测模型。为了避免过拟合情况出现,将物流资源数据样本分为训练组和测试组,并评估测试组的数据。训练数据是模型不断调整权重的集合,测试数据是用于测试模型性能。
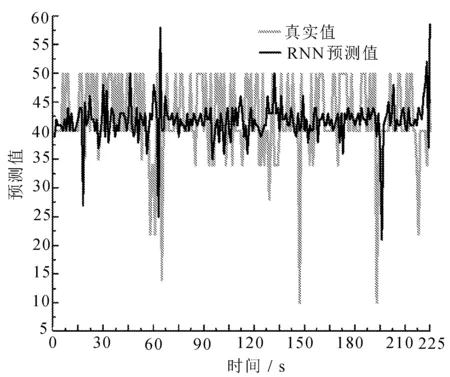
ARIMA模型的参数p、q、d值分别设置为5,1,0。LSTM预测模型和RNN预测模型参数设置相同,输入节点个数设置为50,输出1个节点,迭代次数为1 000次,批处理参数为64,实验次数为100次。最终得到未来225 d的物流需求量的预测值,如图5所示。
其中,图5表示LSTM、RNN与ARIMA三种网络模型预测值和真实值的比较。由于图像不具备较好的观测效果,故针对预测结果进行卡方拟合检验[20]。首先分别假设LSTM、RNN与ARIMA三种网络预测结果不符合真实值;然后,分别将LSTM、RNN与ARIMA三种网络的预测值代入下式
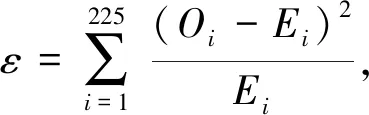
(14)
式中:ε----卡方拟合检验的观测值;
Oi----预测值;
Ei----真实值。
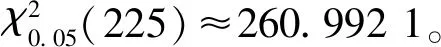
LSTM与RNN方法相比,LSTM物流资源预测模型比RNN物流资源预测模型的误差值要小,而且在运算过程中表现出更好的迭代效果。
训练组曲线和测试组曲线对比如图6所示。

(a) LSTM
(b) RNN

(c) ARIMA
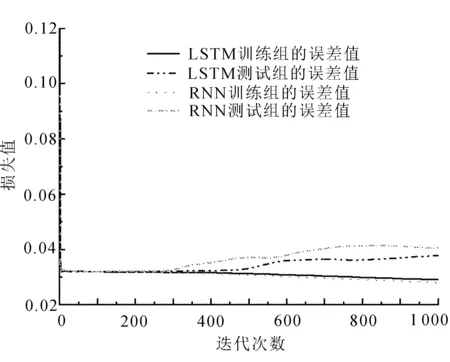
图6 训练组曲线和测试组曲线对比
在模型训练方面,LSTM训练组曲线和RNN训练组曲线几乎重合,收敛性一致。而在模型测试方面,相同迭代次数下LSTM测试组损失值明显小于RNN测试组损失值,故有更好的迭代效果。
为了不同方法构建的模型之间的精准度。对这些预测模型进行仿真。根据仿真结果可以发现,采用LSTM预测模型,其预测结果明显好于采用RNN和ARIMA预测模型的预测结果。
不同算法下的预测值见表2。
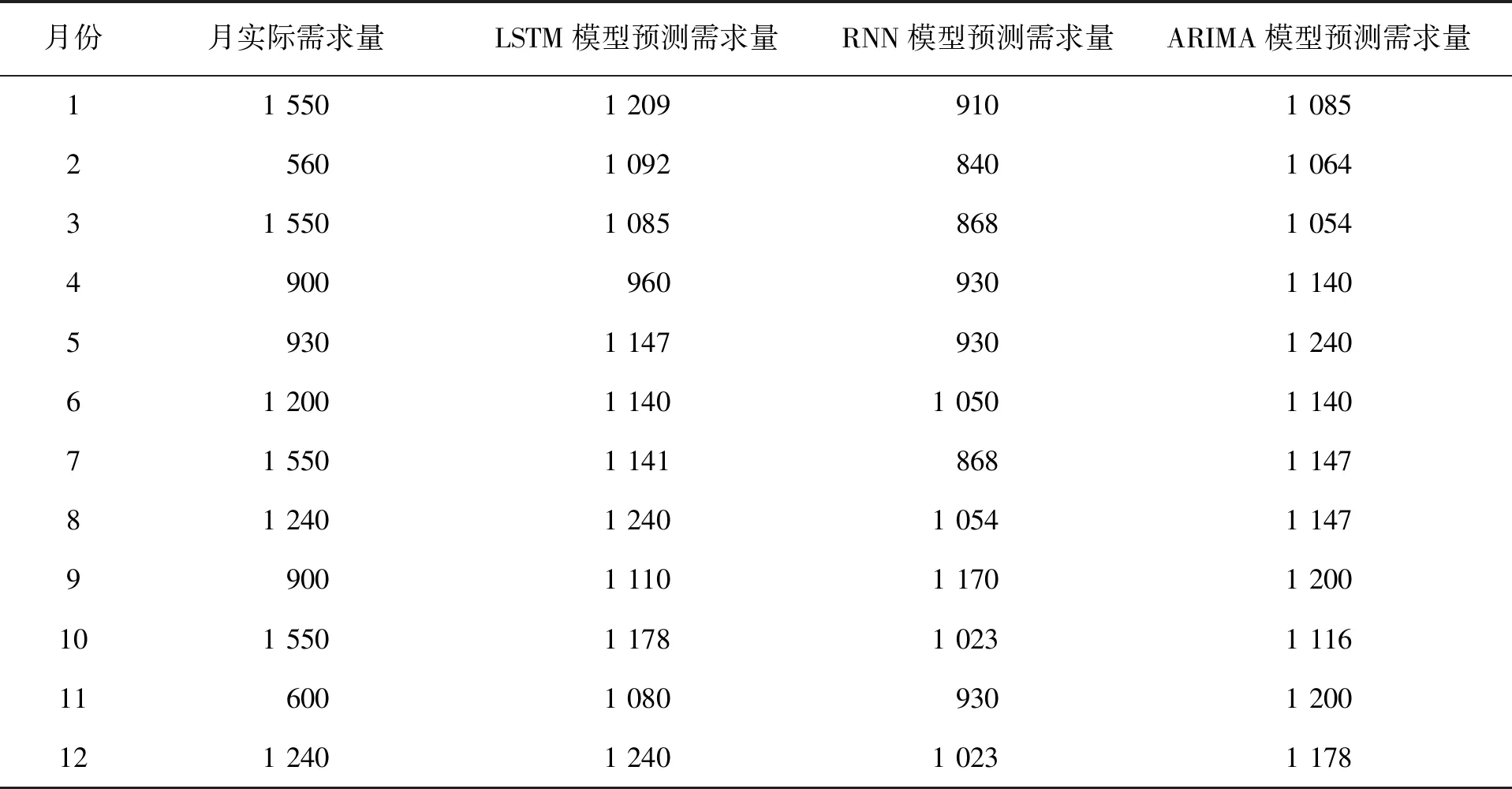
表2 不同算法下的预测值表
从表2中清晰看出,LSTM物流需求预测模型的预测效果更加显著。因此,采用LSTM神经网络建立物流需求预测模型效果最好。
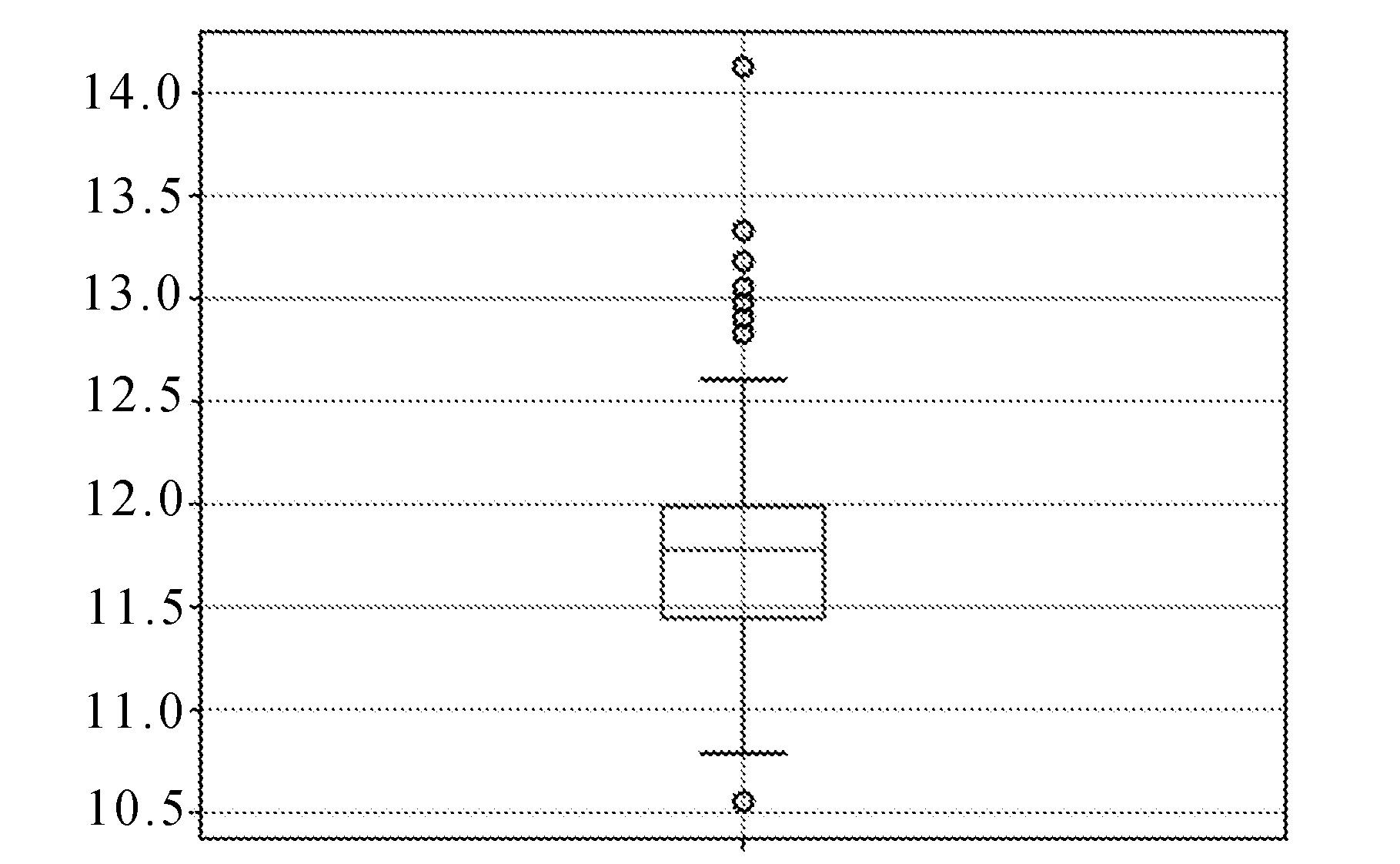
由于误差评价指标常常采用均方根误差(RMSE)和平均绝对误差(MAE)两种,文中也针对其优劣进行了比较实验。性能评测如图7所示。
(a) RMSE
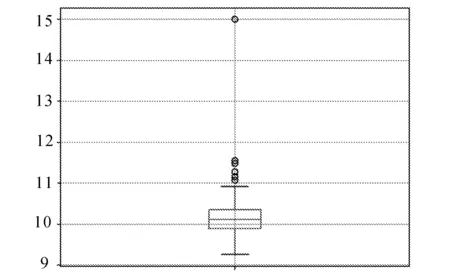
(b) MAE
从图7可以看出,模型采用MAE损失函数的误差值10.212,而采用RMSE损失函数的误差值11.724,说明采用MAE损失函数更能反映预测值误差的实际情况。模型在不同时期的性能评测见表3。
从表3可以看出,使用MAE损失函数的平均误差值小于RMSE。此外,分别对不同比例的样本数据进行神经网络训练,其结果仍然是MAE的误差值小于RMSE的误差值。因此,采用MAE损失函数的预测模型,预测精度更高,其预测需求量更加接近实际需求量。
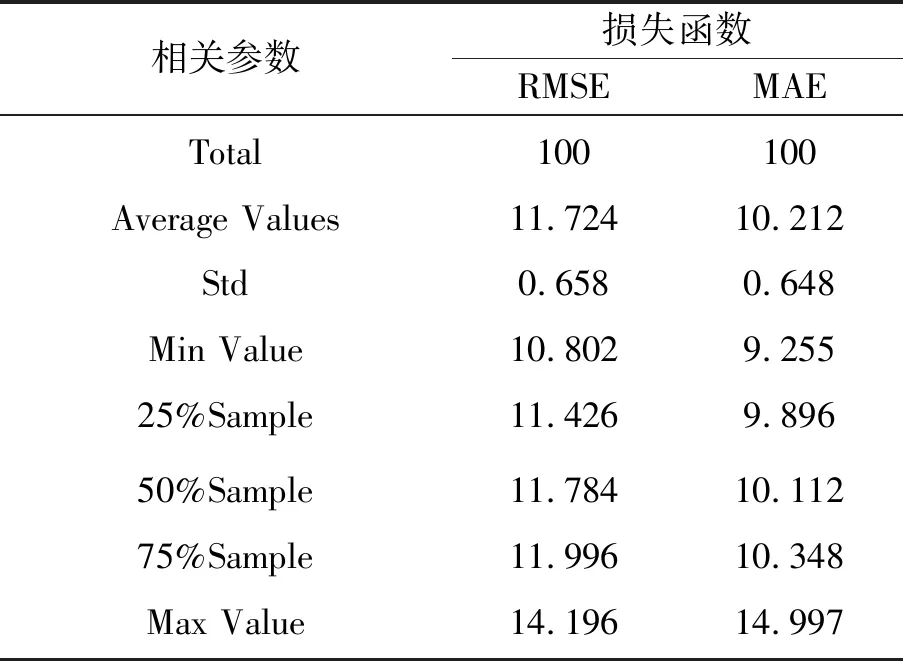
表3 性能评测表
4 结 语
研究了云制造环境下物流资源需求预测问题,首先,在云制造环境下需要评估即将进行的任务所需服务容量,提前将要到达的任务安排好合适的服务窗口。其次,针对物流任务所需服务容量的不确定性这一问题提出的基于LSTM物流资源需求预测模型可以在多重因素影响下准确预测客户需求,为合理调整调度方案提供科学依据。最后,分别采用多种评价指标反映预测值误差情况,在对物流资源需求预测时,MAE损失函数有更好的表现。
猜你喜欢
数学大王·中高年级(2021年6期)2021-09-27
当代水产(2020年2期)2020-03-17
电子制作(2019年19期)2019-11-23
自动化学报(2017年1期)2017-03-11
现代工业经济和信息化(2016年1期)2016-05-17
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
橡胶科技(2015年3期)2015-02-26
湖南农业科学(2014年8期)2014-02-27
