
分布式子空间局部链接随机向量函数链接网络
2022-11-23 05:30于万国袁镇濠陈佳琪何玉林
深圳大学学报(理工版) 2022年6期
于万国,袁镇濠,陈佳琪,何玉林
1)河北民族师范学院数学与计算机科学学院,河北承德 067000;2)深圳大学计算机与软件学院,广东深圳 518060;3)人工智能与数字经济广东省实验室(深圳),广东深圳 518107
分类是机器学习领域的重要分支,神经网络模型在处理分类问题方面有着非常优异的性能表现.其中,应用了随机化技术的神经网络模型由于不需要反向传播计算模型参数,训练速度极快,深受学者们的关注.如今,基于随机化技术的神经网络已经发展出了几种代表性结构,如随机向量函数链接(random vector functional link,RVFL)网络[1-3]、基于随机权重的前馈神经网络[4]、极限学习机(extreme learning machines,ELM)[5-7]和局部链接的极限学习机(extreme learning machine with local connections,ELM-LC)[8]等.RVFL网络结构简单、训练速度快且性能表现佳,而ELM-LC模型作为ELM模型的一种变体,将输入层节点和隐藏层节点的全链接改为局部链接,获得了更好的泛化能力.受到ELM-LC思想的启发,通过将无策略的局部链接方法改进为有理论支撑和有策略的局部链接方法,子空间局部链接RVFL(RVFL with subspace-based local connections,RVFL-SLC)网络[9]突破了RVFL网络模型的限制,获得了比RVFL网络、ELM和ELM-LC模型更高的测试精度.
Apache Spark是Apache软件基金会的一个热门开源项目,是一个支持多语言的通用内存并行计算框架,具有快速运行、简单易用、高度通用等特点.Spark应用程序由单个驱动器进程和多个执行器进程组成,其中驱动器进程是Spark应用程序的核心,主要进行任务的分发和任务信息的维护等,而执行器进程主要负责实际的计算工作并在完成后通知驱动器进程.Spark框架的优异特性吸引了越来越多的研究者从Hadoop框架转向Spark框架,对于需要进行大量迭代计算的机器学习任务而言,基于内存的Spark框架无疑比需要借用硬盘中转的Hadoop框架更加快速[10].当前出现的并行随机权网络算法主要包括下面两类:
1)分布式ELM.为解决大数据背景下模型训练速度过慢的问题,学者们提出了很多精彩的解决方案.SUN等[11]基于分层对等网络(peer to peer,P2P)提出一种在线ELM集成分类框架.不同于以P2P为切入点的算法改进,XIN等[12]通过对ELM算法本身进行分析,发现矩阵求广义逆的过程可被分解且其本身计算开销很大,进而提出一种基于mapReduce框架的新型分布式极限学习机.CHEN等[13]从数据集在集群中的分布式特性出发,提出基于mapReduce的分布式算法,使用不同的分布式数据块单独训练ELM,并将隐藏层权重进行组合,最终得到一个完整的单隐藏层前馈神经网络.邓万宇等[14]提出一种基于Spark框架的ELM并行算法,利用Spark平台特有的弹性分布式数据集(resilient distributed dataset,RDD)数据结构来封装ELM训练过程中的多个矩阵,并在实现过程中利用RDD对应的多个应用程序界面(application program interface,API)实现ELM的隐藏层输出矩阵求解和输出矩阵求解并行化,提高了训练速度的同时还获得了和单机训练ELM模型同等的精度.杨敏等[15]提出基于Spark平台的自适应差分进化极限学习机,针对差分进化算法的种群划分机制进行并行化加速,将每个子种群封装为RDD数据结构的某个分区,利用RDD可并行计算的特性,让每个分区进行独立并行进化,期间不断用子种群中最优的个体替换最差个体,实现并行优化多个子种群,最终达到提高训练速度的目的.
2)分布式RVFL.SCARDAPANE等[16]提出使用分散平均共识策略的分布式RVFL算法,能够免除中央代理的协调得到一个通用的学习器模型.随后,SCARDAPANE等[17]又提出基于乘法器交替方向方法的RVFL算法,解决了每个模式在多个代理中都用时的分布式学习问题.ROSATO等[18]提出一种基于有限精度算术的RVFL神经网络在线学习算法,并通过实验证明这是一种基于递归算法的有效分布式方案.ZHAO等[19]基于交替方向乘子法(alternating direction method of multipliers,ADMM)提出一种全新的分布式RVFL,通过ADMM将全局问题分解为多个小的局部问题来实现并行化,从而达到加速算法运行速度的目的.XIE等[20]基于ADMM分布式RVFL网络提出采用流形正则化的分布式半监督学习算法,进一步扩大了分布式RVFL的适用范围.
与上述分布式ELM和RVFL分类模型一样,RVFL-SLC模型也必须将数据全部载入内存再进行计算才能完成训练.然而,单机的内存十分有限,这意味着RVFL-SLC模型虽然可在中小数据集上很好地工作,但在大规模数据集上的训练速度难以被接受.更糟糕的是,当数据集超过一定规模后,单机内存将无法装载全部数据集,导致无法进行模型训练.为解决RVFL-SLC模型在大数据背景下训练效率低和泛化能力差的问题,本研究提出一种基于Spark框架和随机样本划分技术的分布式RVFL-SLC(distributed RVFL-SLC,DRVFL-SLC)模型,并在8个大规模数据集上获得了比单机版本更佳的精度和更快的训练速度.通过分析加速比、可扩展性以及规模增长性3个衡量分布式算法性能的指标,验证了该模型的可行性和有效性.
1 预备知识
1.1 随机样本划分
随机样本划分(random sample partition,RSP)是一种适用于大数据的分析模型,主要原理是利用与大数据的分布保持概率分布一致性的小数据块(RSP数据块)来估计大数据的统计特征[21].在RSP模型中,大数据被分为多个RSP数据块,因此在执行分类或者回归任务时,不需对整个大数据进行运算,而只需对部分RSP数据块进行处理就可获得较准确的结果,从而大大减少了模型的计算量同时降低了对资源的要求,这在数据量剧增的今天有很强的实用性.
1.2 Spark平台
首款流行的mapReduce框架利用多次map和reduce组合操作完成对大数据计算任务的求解,用户需将目标任务分解为多个map和reduce操作.但实际中并非所有操作都能被很好地分解,这给使用者带了不便.此外,mapReduce框架在运行过程中需借助磁盘作为中介,这无疑带来了很多不必要的磁盘读写,延缓了任务的执行.加州大学伯克利分校开发了一个基于内存计算的分布式框架Spark.基于内存计算设计的Spark比mapReduce更适用于迭代任务,因为迭代任务往往会有大量数据需被重复使用,将数据缓存于内存中会更便于多次重复读取,减少无谓的磁盘读写,使任务完成更快速,如一些常见的机器学习算法就更适合使用Spark框架而非mapReduce框架[22].Spark框架自带的一系列接口也可让任务的设计不再拘泥于map和reduce操作,使用者可更加灵活和高效地利用读框架.
1.3 分布式文件系统
Spark的文件存储系统采用Hadoop分布式文件系统(Hadoop distributed file system,HDFS).HDFS因具有容错性高、对硬件要求低且可保证较高的数据访问吞吐量而流行[23].HDFS的设计基于master/slave结构,master角色由namenode担任,主要存储metadata,包括文件系统内部的命名空间、client对文件的访问权限以及保存文件的副本数、块数和存储的位置等.datanode作为HDFS设计中的slave角色,主要任务是完成client的读写文件操作和保存文件及其副本操作.每个文件会按照配置进行切块,然后被namenode分配到相同或者不同的datanode中保存.为保证系统的容错性,每个文件都会有相应的副本,配合心跳机制,通过datanode周期性发送心跳包给namenode以表明其工作状态是否良好,使文件能够在部分datanode出现错误(如宕机)时,依然可正常读写.client在访问文件时,需与namenode进行交互以获取相应文件信息,而具体文件的读写操作则需和datanode进行交互.
1.4 RDD
RDD是为了让使用者可显式保存中间结果到内存中、控制数据集分区数以优化并行效率,以及拥有完善成熟接口的一种抽象的数据集表达方式[24].RDD提出了基于粗粒度的转换而非细粒度的转换方式,具体来说就是通过记录一系列transformation操作来生成或复现新的RDD,而非通过记录真实的数据变动来改动数据集,此设计使得RDD拥有了高容错性和高效率.在出现错误时,RDD只需重现已记录的transformation操作即可.
2 DRVFL-SLC的并行化设计
DRVFL-SLC算法的并行化设计分为并行化训练模型和并行化测试模型两部分.并行化训练模型主要是通过将大规模数据集划分为多个和大规模数据集保持统计意义上分布一致的小数据集,然后利用RDD的分区并行计算特性,将大数据集作为1个RDD,每个小数据集作为该RDD的1个分区,使RDD的分区数等于集成器的个数,从而对RDD使用mapPartitions转换算子创建多个任务进行集成器的并行训练.并行化测试模型主要有3种方法.
1)在执行器节点中训练得到最优模型后,在同一个任务中进行测试.这种方法有3个问题:①需将测试集以广播变量的形式传送到所有节点中,而广播将测试数据集从驱动器节点通过网络发送到各个执行器节点中,让集群中所有节点都拥有测试数据集的只读副本,而非每个执行任务都进行1次测试数据集的传送.这意味着需大量的网络读写操作来完成测试数据集的广播,然而大数据背景下的测试数据集十分庞大,这无疑会导致因为传输耗时过长而变相降低算法效率的缺陷.②这种方法因在单机上用整个测试数据集对单个模型进行测试,当数据集达到一定规模时,单机的内存将因无法容纳整个测试数据集导致测试无法完成.③进行模型测试时,并行的测试任务数仅为集成器数量,同时每个任务都使用整个测试数据集进行测试,结果令所有矩阵运算都集中在少数任务里,此时其他的内核没有分配到任务,因此形成了少数内核在运行,其他内核空转的情况,最终导致无法充分发挥多核系统的优势.
2)在多个执行器节点并行训练模型结束后,通过collect算子将模型收集到驱动器节点中进行集中测试.这种方法也有3个问题:①与第1种方法一样,测试是在一个节点中进行,但该方法还需同时把模型都保存在内存中,单机内存限制了算法的通用性;②该方法同样没有很好地利用多核系统的优势,仅在单机上进行大规模的矩阵运算,导致算法效率大幅降低;③该方法需将多个最优模型进行汇总,而汇总多个最优模型的本质是通过网络将模型所有相关的参数传输到驱动器节点中然后重新组合,这将导致不可接受的传输耗时.
3)在多个执行器节点并行训练模型结束后,将模型收集到驱动器节点中,然后以广播变量的形式将多个最优模型的只读副本传输到集群中所有节点,最后在多个节点中以并行方式进行模型的测试,这也是DRVFL-SLC最终采用的方法.这种方法解决了上述许多问题.首先,这种方法避免了将庞大的测试数据集进行广播,减少了极为耗时的大量网络传输.其次,这种方法采用了并行的方式进行模型的测试.在将测试数据集上传HDFS后,虽然有了默认的分区数,但为了最大化并行效率,需调用repartition算子对测试数据集重新分区.Spark的RDD进行宽依赖转换时需进行洗牌操作,这会增加时间消耗,但也带来可任意控制并行度和最大程度利用多核系统性能优势的好处.例如,在不考虑硬件的情况下,假设集成器个数为100,若训练后直接进行模型测试,则会有100个任务同时参与测试;若将测试数据集重新分区为1000个,则有1000个任务同时进行测试,效率提升10倍.另一方面,由于测试数据集被分为1000份,将100个大矩阵运算分为1000个小矩阵运算,极大地提升了测试速度.这种方法虽有诸多优点,但还需解决如何高效地将模型汇总到驱动器节点中的问题.
3 DRVFL-SLC的具体实现
本研究针对RVFL-SLC提出一种新的优化方案DRVFL-SLC,解决了传输模型耗时过长的痛点,进一步提升了RVFL-SLC的性能.RVFL-SLC主要有3个参数需要确定,其中,输入层权重矩阵和隐藏层节点的偏置都通过生成符合给定概率分布的随机数赋值,而输出层权重矩阵通过计算得到.有了这3个参数,就可以重构模型并得到对应的预测值.输入层权重矩阵的维度与数据集的属性数、属性子空间个数以及每个属性子空间的隐藏层节点数有关;输出层权重矩阵的维度与数据集的类别数、属性子空间个数以及每个属性子空间的隐藏层节点数有关;隐藏层节点的偏置的维度与样本数、属性子空间个数以及每个属性子空间的隐藏层节点数有关.当处理大数据有监督学习问题时,由于隐藏层节点的偏置的维度与样本数有关联性,隐藏层节点偏置的维度是影响传输时长的最大因素.分析RVFLSLC不难发现,隐藏层节点的偏置的每一行都是相同的.因此,传输隐藏层节点的偏置时,仅需传输第1行,然后在真正进行模型测试时根据第1行重新生成隐藏层节点的偏置.本研究通过此针对性优化,消除了所有模型传输到驱动器节点的传输量与样本数的相关性,令传输量只与数据集的属性数、属性子空间个数、每个属性子空间的隐藏层节点数,以及数据集的类别数相关.在处理大数据有监督学习问题时,样本数远大于其他参数,所以这样的优化可显著提升分布式算法的执行效率.
分布式环境下DRVFL-SLC算法的实现步骤如图1至图3.算法在Spark上的实现细节简要描述为:

图1 DRVFL-SLC算法的具体实现步骤(算法1)Fig.1 DRVFL-SLC algorithm procedure.

图2 单个RVFL-SLC模型的训练算法(算法2)Fig.2 Training algorithm of single RVFL-SLC model.

图3 多个RVFL-SLC模型的测试算法(算法3)Fig.3 Testing algorithm of multiple RVFL-SLC models.
1)在驱动器节点中以RDD形式读取多个RSP数据块,并将全部RSP数据块进行组合得到TrainRDD,数据块数量等于RDD分区数且等于集成器的个数;
2)对TrainRDD调用mapPartitions转换算子,每个分区在各自的任务里进行单个RVFL-SLC的训练,对结果RDD调用collect执行算子,待模型训练完毕后将多个最优模型收集到驱动器节点备用;
3)在驱动器节点中以RDD形式读取整个测试数据集得到TestRDD,再针对TestRDD调用repartition操作,将TestRDD的分区数调整到适合的大小以便提升并行测试的效率;
4)对TestRDD调用mapPartitions转换算子,每个分区在各自的任务里进行多个最优模型的测试,得到投票集成的预测结果后,调用collect执行算子并将结果收集到驱动器节点中以计算预测精度.
4 实验验证与结果分析
4.1 实验环境及数据
本实验环境是Spark集群且使用YARN调度器.其中,集群中拥有6个节点,每个节点的配置均相同.节点拥有2 Tbyte大小的外存,128 Gbyte的内存,12核的CPU(Intel(R)Xeon(R)CPU E5-2630 v2@2.60 GHz).集群主要使用的软件有Spark2.4.0+cdh6.3.1、HDFS3.0.0+cdh6.3.1、YARN3.0.0+cdh6.3.1和JDK1.8等,操作系统为Ubuntu 18.04.3 LTS.Spark集群包括1个master主节点和5个worker数据节点(主节点也是数据节点).实验选用8个仿真数据集进行训练和测试,编号1#—8#,特征数皆为7,类别数依次为3、5、6、7、7、7、3和3,样本数量依次为2×106、2×106、2×106、1×106、15×105、2×106、1×107和5×107个.其中,训练和测试数据集占比分别为70%和30%.这些数据集可以在百度盘“DRVFL-SLC数据集文件夹”(https://pan.baidu.com/s/1bNiuC7JuxDH8PzbuGUOHIQ)使用提取码k98x下载.
4.2 实验结果及分析
本研究从3个方面对DRVFL-SLC算法进行分析.首先,在6个不同的百万级大规模数据集上比较RVFL-SLC算法和DRVFL-SLC算法各自的预测精度;其次,在8个不同的百万级大规模数据集上对比分布式RVFL算法和DRVFL-SLC算法的预测精度;最后,通过在数据集的大小为10万级的原始数据集、5倍于原始数据集、10倍于原始数据集、15倍于原始数据集和20倍于原始数据集上,计算加速比、可扩展性以及规模增长性3个常用的衡量并行算法优劣的指标,对DRVFL-SLC算法进行评价.其中,正则化因子λ=0.001;通过选用一块小数据集进行交叉验证,获得隐藏层节点个数L和随机化权重区间的最优值;独立重复试验次数I=10;集成器个数应与数据集规模成正比,一般设置每个集成器负责的数据集占总数据集的1/10,本研究设集成器个数为110.
图4对比了在6个不同的百万级大规模数据集(数据集1#—6#)上,在单机上使用大数据集训练单个RVFL-SLC模型和将大数据集分块后训练多个模型并集成的DRVFL-SLC算法各自的预测精度.对于不同的数据集通过交叉验证法选出最优的参数对后进行训练.由图4可见,直接在单机上对整个数据集训练RVFL-SLC模型获得的预测精度,均比将大数据集分块后训练多个模型的集成结果要差.其中,RVFL-SLC模型学习曲线的阴影部分对应I次测试的“平均值±标准差”区域.

图4 在1#—6#数据集(对应图(a)—(f))上RVFL-SLC和DRVFL-SLC的测试精度Fig.4 The testing accuracies of RVFL-SLC blue curve and DRVFL-SLC red curve on datasets 1#—6#((a)-(f))respectively.
图5对比了在8个不同的百万级大规模数据集(数据集1#—8#)上,分布式RVFL算法和DRVFLSLC算法的预测精度.由图5可知,对于同样的集群和同样的数据集,分布式RVFL算法的预测精度均比DRVFL-SLC算法的低.其中,RVFL和RVFLSLC模型学习曲线的阴影部分对应I次测试的“平均值±标准差”区域.
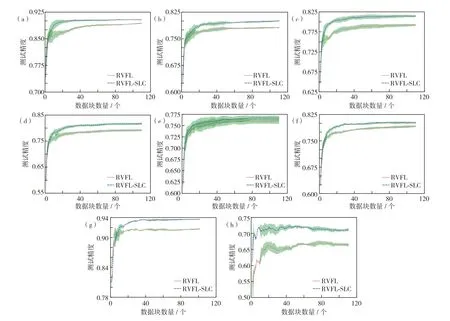
图5 在1#—8#数据集(对应图(a)—(h))上的并行RVFL和DRVFL-SLC的测试精度Fig.5 The testing accuracies of RVFL red curve and DRVFL-SLC blue curve on datasets 1#—6#((a)-(h))respectively.
图6展示了基于加速比(Speedup)、可扩展性(Scaleup)和规模增长性(Sizeup)评估DRVFL-SLC算法并行表现.

图6 DRVFL-SLC算法的并行效果 (a)加速比;(b)可扩展性;(c)规模增长性Fig.6 The parallel performances of DRVFL-SLC.(a)Speedup,(b)Scaleup,and(c)Sizeup.
Speedup指标用于计算当数据集大小不变,只增加机器个数时,算法可提供的计算加速效率.若该指标随着机器个数的增加保持线性增长或趋于线性,则说明测试算法可很好地并行化从而提高计算速度.但在实践中很难获得真正的线性增长,因为机器数越多,意味着通过网络传输的数据就越多,此时网络读写的耗时占算法总耗时的比例就越高.此外,调度程序的策略、每个节点的运行情况,以及硬件设备的差异都会影响算法的耗时,所以多数情况下呈现近似线性增长的趋势.为获取DRVFLSLC算法的Speedup性能,分别在1核、并行5核、10核、15核和20核的条件下对算法耗时进行测量,数据集的大小为10万级的原始数据集和分别5倍、10倍、15倍、20倍于原始数据集,结果如图6(a).由图6(a)可见,随着核数增加,DRVFL-SLC算法的Speedup逐渐增加;随着数据集大小的增加,DRVFL-SLC算法的Speedup曲线逐渐趋于近似线性.可见,增大数据集的规模和增加计算的核数都可提高DRVFL-SLC算法的Speedup.
Scaleup指标用于计算当数据集规模随着集群规模增大时,算法对于数据集大小的适应性.若指标随着参与计算的并行核数增多而降低,则意味着测试算法对于数据集的大小拥有良好的适应性,可很好地提高大数据的并行计算速度.为测量DRVFL-SLC算法的Scaleup,分别在1核及原始数据集大小、5核及5倍于原始数据集大小、10核及10倍于原始数据集大小、15核及15倍于原始数据集大小和20核及20倍于原始数据集大小的条件下运行算法,结果如图3(b).由图3(b)所示,随着数据集和核数的同时增大,Scaleup逐渐减少且其减速越来越小,表明DRVFL-SLC算法拥有良好的适应数据集大小变化的能力.
Sizeup指标用于计算当集群规模不变时,数据集规模成倍数增加所花费的时间与原始数据集花费时间的比例.为测量DRVFL-SLC算法的Sizeup,分别在1核和并行5核、10核、15核、20核的条件下训练数据集大小为10万级的原始数据集和分别5倍、10倍、15倍、20倍于原始数据集,结果如图3(c).由图3(c)可见,核数越高的曲线,其斜率越小,说明多核环境能够更好地加快算法的计算速度.
结语
RVFL-SLC算法能解决回归及分类问题,并通过实验证明比RVFL、ELM、ELM-LC等算法的泛化性能更好,但如今数据集规模日益膨胀,训练速度日渐成为RVFL-SLC算法的瓶颈.本研究通过分解RVFL-SLC算法的运行步骤,同时结合Spark并行计算框架和随机样本划分技术,设计并实现了DRVFL-SLC算法,提高了大规模数据背景下RVFL-SLC算法的计算速度.通过实验从3个方面对DRVFL-SLC算法的性能进行了评估.结果表明,DRVFL-SLC算法在预测精度上比单机上串行运行的RVFL-SLC算法更高.此外,DRVFL-SLC算法的运行效率也比串行的RVFL-SLC算法高出了数倍,并且高出的倍数随着数据集规模的增大而增大,从而证明了DRVFL-SLC算法的有效性和可行性.未来将进一步改进DRVFL-SLC算法,提高其对计算机资源的利用效率,同时由于Spark的版本在持续更新,继续推出更高性能的Spark优化DRVFL-SLC算法.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
北华大学学报(自然科学版)(2021年3期)2021-07-13
物联网技术(2020年12期)2021-01-27
电脑爱好者(2020年6期)2020-05-26
科学与财富(2018年30期)2018-12-28
北京航空航天大学学报(2017年5期)2017-11-23
汽车零部件(2017年4期)2017-07-12
计算机应用(2016年9期)2016-11-01
体育科技(2016年2期)2016-02-28
中国石油石化(2013年5期)2013-05-03
