
基于高光谱成像和卷积神经网络的‘库尔勒’香梨黑斑病潜育期诊断研究
2022-11-21 12:09胡泽轩王文秀赵丹阳马倩云孙剑锋
河北农业大学学报 2022年5期
胡泽轩,王文秀,张 凡,2,赵丹阳,马倩云,孙剑锋
(1.河北农业大学 食品科技学院,河北 保定 071000;2. 塔里木大学 现代农业工程重点实验室,新疆 阿尔罕 843300)
‘库尔勒’香梨具有皮薄酥脆、风味独特等优点,深受消费者喜爱[1],然而在贮藏过程中,香梨果实容易受到链格孢属真菌Alternaria alternata的侵染导致黑斑病[2]。目前对梨采后病害的诊断主要依靠人工识别,但由于潜育期果实表面无明显变化,且人工识别受到主观因素的影响较大,因此误判率较高,这些误判的果实在贮藏期间不仅自身会腐败变质,还会影响附近的健康果实,最终导致大面积病害的发生[3-4],造成严重的经济损失。因此建立客观、快速、准确的香梨黑斑病潜育期检测方法是十分必要的。
高光谱成像(Hyperspectral imaging,HSI)技术能够同时获取样品的光谱信息和图像信息,实现“图谱合一”,具有分辨率高、波段较多等优点[5]。目前已有部分学者利用该技术实现了水果表面病害的识别[6-8],证明了其在水果病害检测领域具有良好的应用前景。但现有研究大多针对样品的显性病征进行识别,在深度挖掘样品内部信息,实现病害潜育期的准确识别方面缺少系统性研究。在利用HSI 技术对水果病害进行诊断识别时,需要结合适当的化学计量学方法,目前应用较为广泛的分类模型算法包括最小二乘支持向量机(Least squaressupport vector machines,LS-SVM)、K 最邻近法(K-nearest neighbor,KNN)、随机森林算法(Random forest,RF),等[9]。近年来深度学习算法因其自主学习能力强,可以处理大批量样本数据而备受关注[10],其中卷积神经网络(Convolutional neural network,CNN)作为1 种深度学习算法,可以直接利用原始图像,从大批量样本中提取出样品的特征信息,避免了复杂的特征提取过程,且该过程是自动进行的,避免了因主观因素产生的实验误差[11]。此外,CNN 对数据预处理的要求较低,甚至不对数据进行预处理即可对光谱信号进行分析,对操作人员的专业性要求较低。CNN 还能进行非线性建模处理,有较强的的泛化能力[10]。鉴于CNN 能够充分挖掘高光谱图像中的深度特征信息,将其与HSI 技术结合,有望实现对‘库尔勒’香梨潜育期病害样品的识别。
针对上述问题,本研究以不同染病程度‘库尔勒’香梨为研究对象,基于高光谱成像技术和卷积神经网络,构建‘库尔勒’香梨黑斑病潜育期快速诊断识别方法。此外,还利用LS-SVM、KNN、RF等常规算法构建模型,进一步对比验证CNN 模型的分类效果。研究结果可为库尔勒香梨黑斑病的无损、实时、准确检测提供参考。
1 材料与方法
1.1 试验样品制备
实验选用大小形状均匀,表面无病害的‘库尔勒’香梨样品共计172 个。为了获得发病样品,首先选择自然发病的香梨果实,从染病区域分离纯化得到病原菌后,将其制备成菌悬液,接种到健康果实中。为了获得不同发病程度的样品,每天接种17 个样品,持续10 d,最终得到124 个接种病原菌的果实和48个健康果实。在培养过程中记录每个样品上病斑的直径,并根据病斑面积与果实面积的比率,参考表1 的标准[12]将样品分为健康、潜育期、轻度发病、重度发病4 个等级。
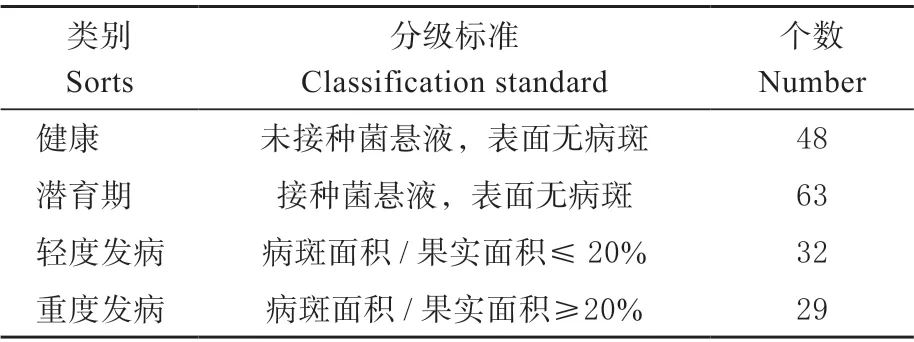
表1 ‘库尔勒’香梨分级标准Table 1 Classification standard of korla fragrant pear
1.2 高光谱成像系统及图像采集
实验所用高光谱成像系统主要由CCD 相机、2个卤素光源、位移平台、步进电机和计算机组成。经过前期重复试验,位移平台速度、相机与样品间距离、相机曝光时间分别设置为9.74 mm/s、500 mm、8.50 ms。采集样品时,将样品的病变区域向上,按照3 行×3 列的方式摆放在位移平台上,利用线扫描的方式采集样品的高光谱图像。在图像采集过程中,由于暗电流和不同透镜对光的敏感程度不同,需对采集到的高光谱图像进行黑白校正处理。
1.3 光谱信息提取
在提取光谱信息前,对采集到的图像进行分割,得到单个样品的高光谱图像。感兴趣区域的选择在高光谱数据分析中十分重要,能够直接影响模型的准确率和性能。本研究通过阈值分割法选取整个香梨样品作为感兴趣区域,并利用ENVI 5.3 计算出所有像素点的平均光谱作为样品的光谱信息。
1.4 数据增强
由于卷积神经网络中参数量十分庞大,需要大量有标签的样本对模型进行训练[13]。因此本研究参照专利[14]的方法对172 组原始数据进行30倍扩增处理。经过数据增强,共得到5 160 条包含不同染病阶段样品的光谱数据,分别包括健康样品1 440 条、潜育期样品1 890 条、轻度染病样品960 条、重度染病样品870 条。
1.5 光谱预处理
提取到的光谱信息中,除了包含样品本身的信息外,还有一些无关信息如噪声和背景等,对模型的精度产生一定影响[15]。本研究首先利用Savizkg-Golag 5 点平滑消除随机噪声,并对比分析了标准正态变量变换(Standard normal variable transformation,SNV)、一阶导数(First derivative,FD)、二阶导数(Second derivative,SD)及其组合使用对建模结果的影响[16]。
1.6 模型建立及评价
利用Kennard-stone(K-S)算法将预处理后的数据按3 ∶1 的比例划分为校正集和预测集,其中校正集中有3 870 个样品,预测集中有1 290 个样品。
1.6.1 基于常规算法的模型建立 采用了LS-SVM,KNN,RF 3 种常规算法建立分类模型。其中LSSVM 是传统支持向量机的改进和推广,以结构风险最小化为原则,避免了求解二次规划问题;KNN 通过度量特征空间中样本之间的相似性,获得距离目标点最近的k个点,并根据少数服从多数的分类决策规则,确定目标点的分类,本研究k选定为3;RF 是1 种机器学习中常用的决策树算法,效率更高,且不易产生过拟合现象,本研究中随机树数量为500。
1.6.2 基于卷积神经网络的模型建立 CNN 是1 类包含卷积计算且具有深度结构的前馈神经网络,主要由输入层、卷积层、池化层、全连接层和输出层组成(图1),是深度学习的代表算法之一。在建立CNN 模型前,将预处理后的一维光谱数据转变为二维数据,以增强CNN 模型深度挖掘光谱数据中特征信息的能力,最后将人工标记的标签作为输出变量建立CNN 模型。由于网络在向前传输的过程中,每一层卷积的卷积核随机产生,因此最后1 层卷积层的特征输出不相同,需要对整个网络模型不断迭代,根据网络的预测值与标签值之间的损失优化训练过程中的随机量,最终达到模型拟合,并保存最优的模型参数。本研究采用交叉熵损失函数作为模型更新的衡量指标。
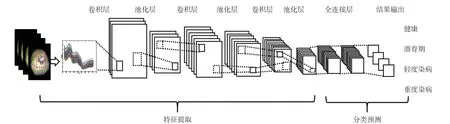
图1 卷积神经网络结构示意图Fig. 1 Structure diagram of convolutional neural network
(1)网络结构的优化
在构建CNN 模型时,不同的网络结构会对模型的分类效果产生影响,因此需对网络结构进行优化。本实验将卷积层数量设置为1、2、3,全连接层数量设置为1、2、3,在此基础上进行不同层数间的组合,最终设计了9 种不同的网络结构,并对这些结构进行训练,通过对比不同网络结构模型的分类效果,确定最优网络结构,此时模型的学习率设置为0.000 1。
(2)学习率值的优化
在确定最优网络结构后,需要对CNN 模型的一些超参数进行优化[17],其中学习率作为最重要的超参数,能够加快模型收敛,避免陷入局部最优的局面,因此选择对学习率进行优化。基于最优网络结构,分别将学习率设置为0.000 1、0.001、0.01、0.000 5、0.005,其它参数的设置如表2 所示。
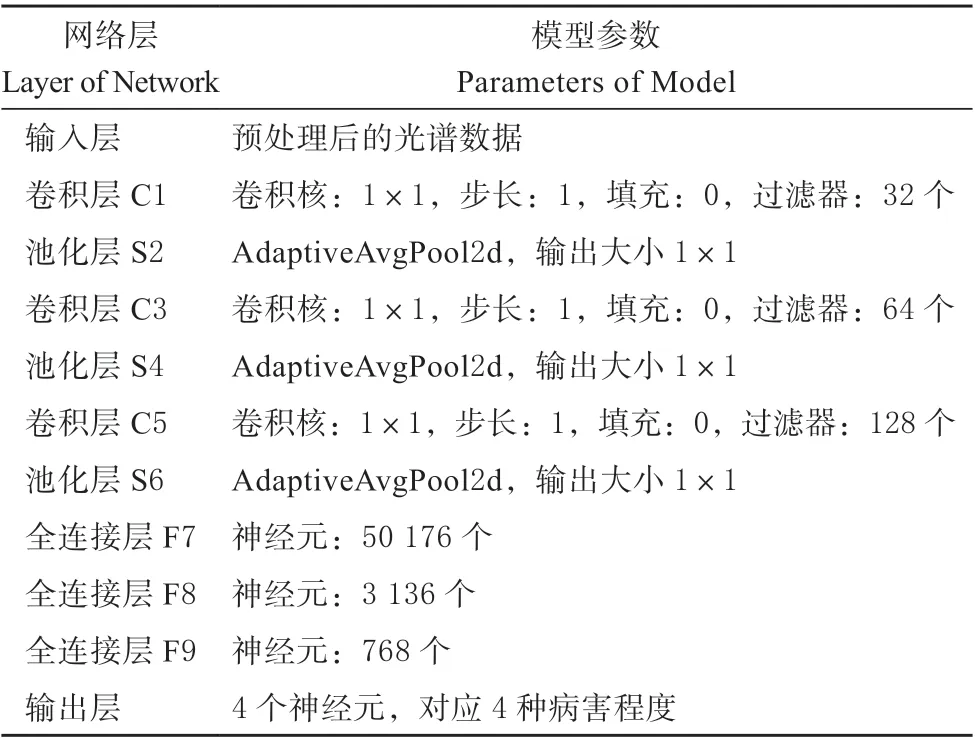
表2 CNN 模型参数Table 2 Parameters of CNN model
1.6.3 模型评价 以准确率(%)为评价指标,常规算法建模分析在Matlab2014a 中完成,CNN 建模分析在PyCharm Community Edition 2022.1中完成。
2 结果与讨论
2.1 ‘库尔勒’香梨样品分析
不同病害程度的香梨样品如图2 所示。在潜育期,链格孢菌在香梨果实内部不断增殖,但与健康果实相比,外观无明显变化;随着侵染时间的增加,接种区域附近表皮组织开始坏死,形成肉眼可见的黑褐色圆形病斑;在侵染后期,病原菌逐步扩散到周围健康区域,病斑区域加大,同时病斑区域会产生少量液体沉淀,可能是随着侵染时间延长,果实表面的蜡质层及果实细胞壁组成的防御性结构被破坏,细胞内各种酶活性降低,病原菌更容易入侵所致[18]。本研究采用注射器接种链格孢菌悬液的方式模拟制备黑斑病样品,较大程度地接近自然发病样品,使所建立的模型具有较高的实际应用价值。同时,利用游标卡尺测量病斑直径,并计算出病斑面积与果实面积的比率,参照表1 标准对不同染病等级的样品进行分类,减小了人为误差,使研究结果更精确。
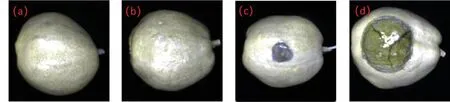
图2 不同染病程度的库尔勒香梨Fig.2 ‘Korla’ fragrant pear at different infection degrees
2.2 原始光谱信息及预处理
不同染病程度样品的平均光谱如图3(a)所示,随着染病程度的加深,样品反射率整体呈下降趋势。980、1 210、1 450 nm 处的吸收峰较为明显,其中980 nm 的吸收峰与O-H 的2 级倍频伸缩振动有关[19];1 210 nm 处的吸收峰与C-H 伸缩的3 级倍频有关;1 450 nm 处的吸收峰与O-H 伸缩的1级倍频有关。健康梨的反射率与潜育期梨的反射率接近,这可能是由于侵染早期,病原菌数量较少,并未大量消耗样品中的水分、糖分等,同时由于植物表皮蜡质层和植物组织细胞壁的防御作用,使得梨果实发生的变化较小。同种发病程度的样品光谱强度有所不同,可能是由于样品中原始叶绿素含量不同,此外由于叶绿素不稳定,在贮藏过程中会分解,也会导致吸收峰强度不同[20]。采用不同方法预处理后的光谱如图3(b)~(h)所示。导数处理使隐藏在原始光谱较宽吸收频带中的特征峰(如1 130 nm 和1 390 nm 处)得到了增强,;SNV 处理后的光谱与原始光谱趋势一致,但有效减少了样品间因光散射引起的误差。将导数处理与SNV 结合,可以有效增强样品特征峰的强度,同时减小光散射引起的误差,FD+SNV、SNV+FD 和SD+SNV、SNV+SD 处理分别与FD、SD 的总体趋势相同,但在数值上有明显差异。
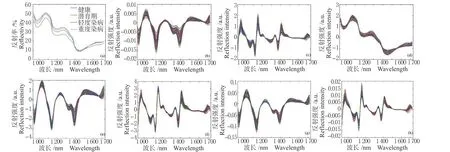
图3 不同病害程度样品的原始光谱及预处理光谱Fig. 3 Original and pretreated spectra of pear samples at different disease degrees
2.3 基于常规算法的建模结果分析
分别将健康、潜育期、轻度染病、重度染病香梨样品赋予类别标签0、1、2、3,基于全部波段,分别利用LS-SVM、KNN、RF 3 种算法进行建模分析,结果如表3 所示。可以发现,基于预处理光谱的建模结果均优于原始光谱建模结果,表明适当的预处理方法能够有效减少噪声和背景的干扰,同时消除散射的影响,对保留光谱中的有效信息、提高模型的鲁棒性有着十分重要的意义。对比不同算法的建模结果可知,LS-SVM 模型的分类效果最好,且FD+SNV 预处理后模型准确率最高,验证集准确率为87.75%;而利用KNN 和RF 建模时,同样是FD+SNV 处理后模型结果最优,验证集准确率分别为87.21%、85.35%,表明FD+SNV 能够更好地消除光谱中无关信息的影响。
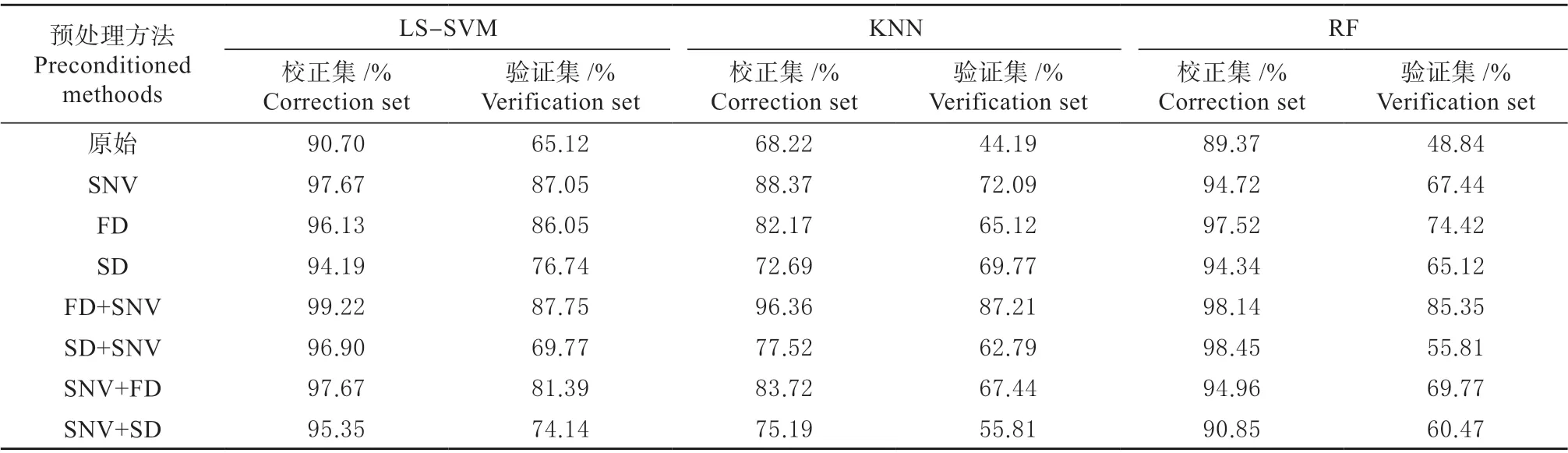
表3 不同分类模型判别准确率比较Table 3 Comparison of discrimination accuracy of different models
为了更直观地观察FD+SNV 处理后模型的分类效果,利用混淆矩阵对分类结果进行了分析(图4)。在混淆矩阵中,对角线上的数字代表分类正确的数量,其他数字代表分类错误的样品,颜色越浅,代表模型预测该类别的数量越多。从图中可以看出,模型对健康和潜育期样品的分类效果较差,但能够较好地识别出轻度染病样品和重度染病样品。对于健康和潜育期样品而言,LS-SVM 模型相较于其他2 种模型的分类准确率更高,为85.69%,大量样品被误判可能是由于健康与潜育期样品外观无明显差异,且常规算法无法挖掘光谱中深层的特征信息。对于轻度和重度染病样品而言,3 种算法的建模结果较为相似,其中RF 模型的分类准确率更高,有16 个轻度染病样品被误判为潜育期样品,1 个被误判为重度染病样品,可能是由于部分样品相较于其他轻度染病样品而言,发病不明显,光谱中的特征信息与潜育期样品接近,常规模型无法准确识别造成的,此外个体间差异也会导致误判;有18 个重度染病样品被误判为轻度染病样品,可能是由于这部分样品相较于其它重度染病样品,发病程度较低,光谱中的特征信息与轻度染病样品相似造成的。

图4 不同分类模型的混淆矩阵Fig. 4 Confusion matrix of different classification models
2.4 基于CNN 建模结果分析
2.4.1 网络结构优化的结果分析 通过上述分析可得,基于FD+SNV 预处理的建模结果优于其他方法,因此利用FD+SNV 预处理光谱进行卷积神经网络建模。在模型建立前,需要对卷积神经网络的结构进行优化,结果如图5 所示。
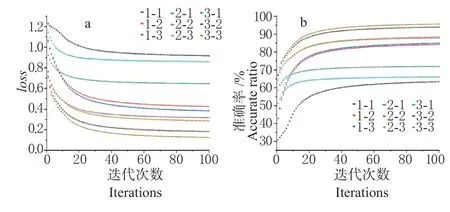
图5 卷积神经网络结构优化Fig. 5 Optimization of convolutional neural network structure
随迭代次数的增加,loss值逐渐降低,校正集的准确率逐渐提高,当迭代次数为70 次时,模型分类效果的变化趋于平稳并逐步达到最大值。采用不同卷积层数和全连接层数,模型的损失率和准确率也会有较大差异,当卷积层数为3,全连接层数为3时,模型的效果最好,对验证集样品的分类准确率达93.19%。
2.4.2 学习率优化的结果分析 基于上述最优网络结构,设置了5 组不同学习率进行建模处理,结果如图6 所示。可以看出随着迭代次数增加,loss值不断降低,校正集的准确率不断提高,当迭代次数为70 次时,模型分类效果的变化趋于平稳并逐步到达最大值。此外,当学习率为0.000 5 时,loss值最低,校正集的准确率最高,将验证集数据代入模型中,分类准确率为99.70%。
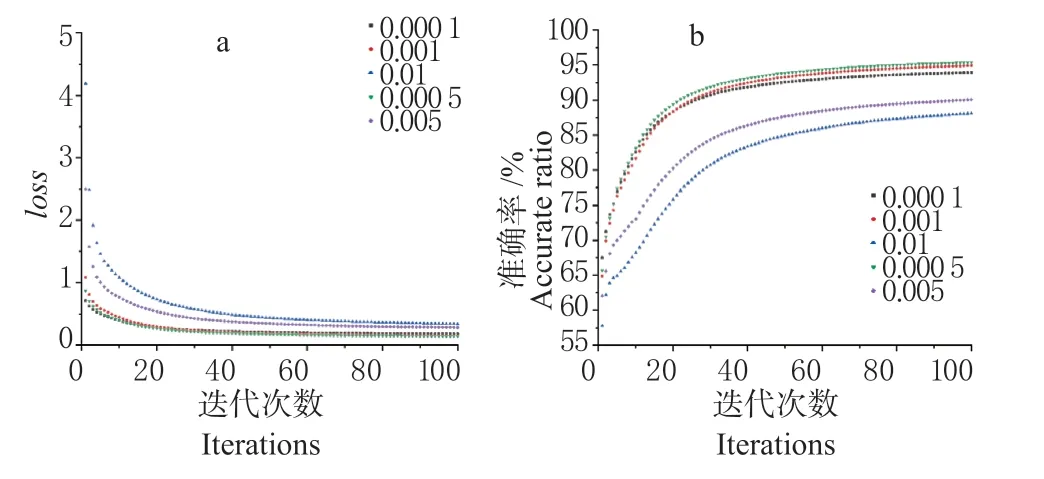
图6 卷积神经网络学习率优化Fig. 6 Optimization of convolution neural network learning rate
为了更直观地表明卷积神经网络对不同发病程度样品的分类效果,利用混淆矩阵对结果进行分析,如图7 所示。
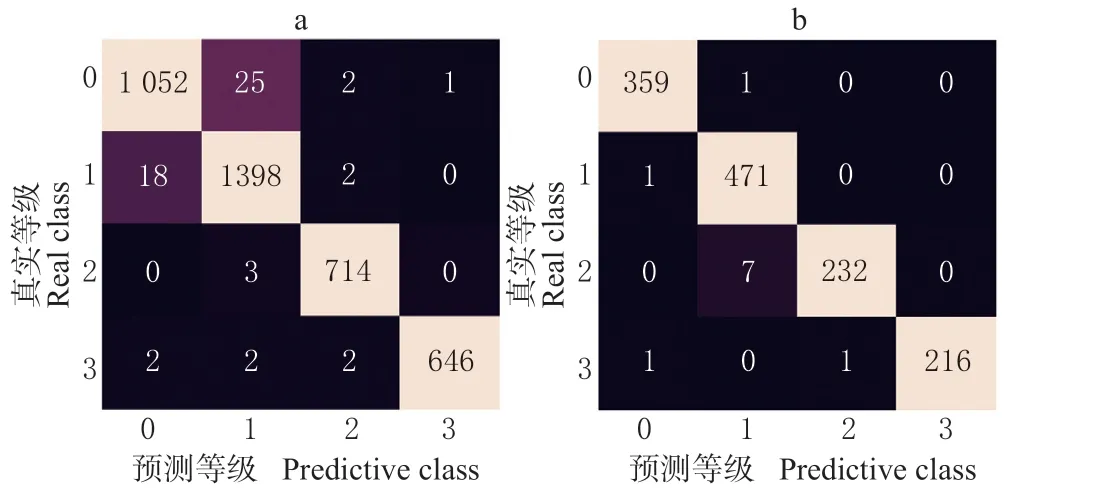
图7 卷积神经网络的混淆矩阵Fig. 7 Confusion matrix of convolutional neural network
相比常规算法,CNN 模型可以较好地实现对健康和潜育期样品的识别,准确率为99.76%,对于轻度染病样品,有7 个样品被误判为潜育期样品,1个样品被误判为重度染病样品,可能是由于样品在染病初期,染病部位的特征不够明显,光谱曲线与潜育期样品相似所导致,此外,个体间差异也可能导致误判。模型对轻度染病和重度染病样品的识别率分别为96.67%和99.08%,可能是由于重度发病的样品表面病斑面积更大,更易识别。综上所述,基于FD+SNV 预处理建立CNN 模型,能够有效实现对库尔勒香梨黑斑病潜育期样品的识别。
3 结论
本研究基于高光谱成像技术结合CNN,实现了对‘库尔勒’香梨黑斑病潜育期的识别。首先通过对比不同预处理方式建立的21 种常规分类模型对样品的分类效果,确定最适预处理方法为FD+SNV,最优常规分类模型为LS-SVM。基于FD+SNV 处理光谱建立了CNN 模型,通过对网络结构和学习率进行优化,确定了当卷积层数为3,全连接层数为3,学习率为0.000 5 时,CNN 模型的分类效果最好。与常规模型对比分析,CNN 的整体分类准确率为99.70%,对潜育期样品的分类准确率为99.76%,分类效果均有明显地提高。综上所述,CNN 模型能够对光谱数据的深层信息进行挖掘,提高了对‘库尔勒’香梨黑斑病潜育期样品的分类精度,可为‘库尔勒’香梨黑斑病无损快速检测技术的发展提供1 种新方法。
猜你喜欢
今日农业(2022年16期)2022-09-22
青年文学家(2022年13期)2022-07-06
温州大学学报(自然科学版)(2022年2期)2022-05-30
数学物理学报(2019年5期)2019-11-29
烟台果树(2019年1期)2019-01-28
安阳师范学院学报(2018年5期)2018-11-21
制导与引信(2017年3期)2017-11-02
中国三峡(2017年4期)2017-06-06
诗选刊(2016年9期)2016-11-26
工业设计(2016年11期)2016-04-16
