
基于语料库的《孟子》译本对比研究
2022-11-21 02:58◎周央
今古文创 2022年44期
◎周 央
(河北工业大学 天津 300400)
《孟子》记录了战国时期儒家代表人物孟子的言行,这部儒家经典体现了中国的传统文化。研究《孟子》英译本有助于全面系统地传播儒家文化(杨伯峻,1999)。诸多翻译家如柯大卫(David Collie)、理雅各(James Legge)、伦纳德·赖发洛(Leonard A.Lyall)和刘殿爵(D.C.Lau)等皆对《孟子》进行了翻译。基于众多《孟子》译本,翻译界的研究成果层出不穷,研究角度也不断更新。然而,目前翻译界对《孟子》英译本的研究以主观分析为主,缺乏有力的客观数据的支持。本文旨在使用语料库技术和自然语言处理(NLP)技术,借助Python提供数据分析,基于类符/形符比、词频排序、语篇相似性度量、词云图等多个指标对《孟子》的三个代表性译本进行对比分析。
一、文献综述
(一)《孟子》英译本研究
当下,《孟子》的翻译版本众多,翻译界也不断尝试从各种角度对其进行研究。在中国知网(CNKI)文献检索可视化平台中,笔者以“《孟子》英译本”作为关键词进行检索,其共现矩阵分析结果显示:在所查询到的48篇相关论文的主题词统计中,“《孟子》”和“比较研究”两个词条的共现数字最大,为6;其主要主题分布图显示,这一主题词下的研究方向集中在典籍英译、读者接受、比较研究、生态翻译学等。对以上文献进行分类整理后发现,目前以《孟子》英译为主题的研究具有以下几个特点:①以《孟子》英译为主题的研究已经有一定成果,译学界对此类研究有一定关注度;②近些年译学界不断尝试从各种角度对《孟子》英译本进行研究。早期译学界主要从典籍英译的视角分析译本,后来衍生出跨学科的研究方向,出现了语料库技术等诸多研究角度。相应的翻译策略也随之产生,研究方法也不断更新——从早先的主观分析逐渐转向客观指标分析等。③得益于《孟子》的诸多译本,许多研究者仍关注多译本对比研究。在上述57篇对于《孟子》的译本研究中,多译本对比研究位列主题分布项前五。
(二)语料库与《孟子》英译本研究
从检索结果来看,基于语料库的《孟子》译本对比研究相关文章仅3篇,其中仅1篇是关于《孟子》译本的对比分析。
孙婷婷(2013)基于语料库,以大卫·亨顿(David Hinton)所翻译的《孟子》英译本为对象,对主语省略句这一语法现象进行了研究。作者对六类主语省略句的原文及译文进行统计分析后指出,尽管主语省略在《孟子》原文及其英译本中都存在,但是原文中的主语省略句数量远远超出于其英译本。
金紫薇(2014)将语料库和普通语言学相结合,即结合语言系统内和系统外证据,对《孟子》一书中有待商榷的若干词语释义做出解释与论证。
王英强(2020)基于刘殿爵和理雅各《孟子》译本对比语料库,从词汇、句式和语篇层面,以及译本词汇丰富度、平均词长和语篇可读性角度对两译本进行翻译风格对比研究。
在语料库翻译对比研究领域已有诸多论文,但这些论文往往基于主观分析,没有客观数据作为支撑,从而无法全面揭示译本的复杂特征。本文借助编程语言Python,增加类符/形符比、词频排序、语篇相似性度量、词云图等指标,来对不同译本的特色进行更加客观具体的描述。
二、Python文本分析
(一)英译本来源
本文以《孟子》三个英译本为对比研究对象,数据来源于对理雅各、赖发洛、刘殿爵三个英文译本的分析。具体信息如表1所示。
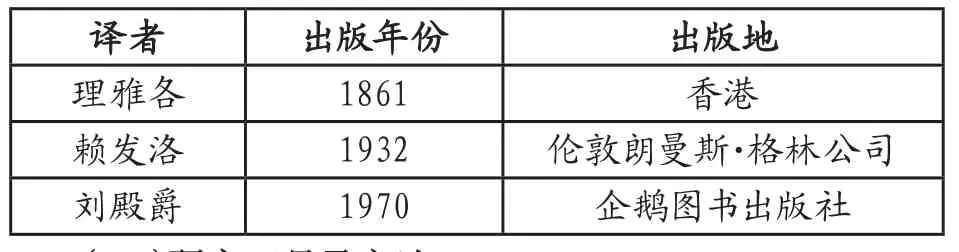
表1 译本出版信息
(二)研究工具及方法
本文以文本分析为主线,调用Python相应的库和模块,实现语料库技术和自然语言处理(NLP)技术在译本对比分析中的应用。文本分析是NLP要完成的重要任务,而Python及其第三方库(常用的几个第三方库包括:NLTK、 Pattern、 gensim、 TextBlob 和 spaCy)可以帮助解决文本分析中的具体问题;文本处理与理解、文本分类、文本相似度计算等都是常见的文本分析类型。本文采用的指标包括:类符/形符比、词频排序、语篇相似性度量、词云图。
(三)词汇丰富度对比
《孟子》三个译本中各自词汇的丰富程度可以通过文本词汇的类符/形符比表示,用以说明词汇变化和丰富程度。使用Python调用相应的库和模块对数据进行处理,《孟子》三个译本中各自的类符/形符比的结果如表2所示。
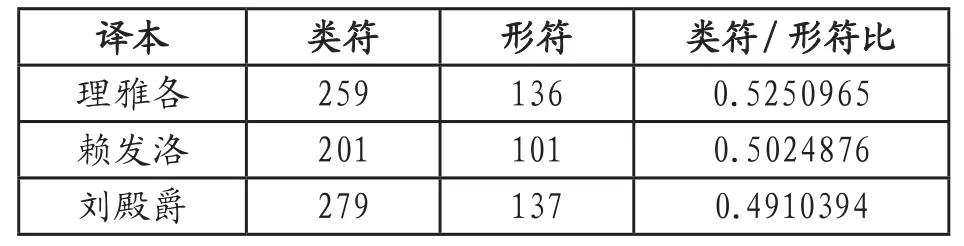
表2 译本词汇丰富度
由表2可知,理雅各译本的类符处于中等位置,形符处于中等位置;赖发洛译本类符位置靠后、形符位置也靠后;刘殿爵译本形符位置靠前。但我们从类符/形符比这一栏中可以看到,理雅各译本的指标明显高于其他两个译本。我们结合译本中的句子分析,理雅各译本的平均句长指标高,译本词汇丰富度较高,用词变化性较大。而在这三个译本中,赖发洛译本平均句长指标低,译本整体词汇丰富度较低,用词变化性较小。
(四)采用高频词对比
清除停用词后高频词出现的频次可以反映《孟子》三个不同译本间的主题相似度。使用Python调用相应的库和模块来对数据进行处理,继而分别对《孟子》三个译本中排名前七的高频词的出现频次进行统计,结果如下。为直观呈现数据,相同高频词用黑体标注。
由表3所示,相较其他译本而言,理雅各译本高频词独特,主题突出;排名第二的是刘殿爵译本。由此可以看出,理雅各译本和刘殿爵译本的主题突出,用词独特性较高。究其原因,翻译方法和策略的不同是其中一条。赖发洛译本和刘殿爵译本的高频词比较相似,两个译本甚至使用了许多重复词语,这表明赖发洛译本和刘殿爵两个译本主题相类似。

表3 三个译本高频词比较
(五)译本相似度对比
本研究使用Python调用相应的库和模块,对于三个译本的总体相似度进行了统计分析,数值差距越小相似度越高。结果如表4所示。

表4 译本总体相似度
结果显示,理雅各译本同赖发洛译本和刘殿爵译本的差异性都较大,赖发洛译本与刘殿爵译本相似度较高。这一结果与表3的结果也基本吻合。
(六)词云图对比
相较于高频词对比,词云图可以更加直观地展示主题词出现的频次。使用Python调用相应的库和模块,得到《孟子》三个译本的词云图。字体大小和单词位置内外分别代表主题词出现的频次高低。以下三张图为三个译本的词云展示。

图1 理译本图

图2 赖译本图

图3 刘译本图
通过《孟子》三个译本的词云图可以看出,在理雅各、赖发洛和刘殿爵三人各自的译本中,除停用词以外的具有实际意义的词汇有着不同的体现,但在总体上保持了字体大小和单词位置内外的一致。从这一结果可以看出,理雅各、赖发洛和刘殿爵都做到了忠实于原始材料,凸显出原文的中心思想。词云图中字体大小和单词位置内外与上述表格中呈现的数据相吻合,是对上述结论很好的验证。
三、讨论
基于本文对《孟子》英译本的对比研究,可以得出以下推断:
整体看来,三个译本中,理雅各译本的词汇丰富度较高,用词变化性较大。究其原因,理雅各译本由十九世纪的书面语体英文写成,洋溢着浓厚的学术气息。赖发洛译本整体词汇丰富度较低,用词变化性较小。究其原因,赖发洛始终把普通读者的接受能力放在首要考虑的位置,以激发他们的阅读兴趣和方便他们理解为己任,因而译本更显通俗性。而刘殿爵的《孟子》英译本词汇丰富度适中,是学术性和通俗性的完美结合(刘单平,2011)。
三个译本中,理雅各译本的高频词最独特,可以说明译者在翻译《孟子》时,不仅把握住了原文的主旨和思想,而且依据不同的翻译原则,选择了不同的翻译方法和策略。理雅各在翻译时,“一直关注对原文的忠实,而非行文的雅致。他每治一经,必先广泛搜集历代评注,详加对比、分析,在此基础上做出自己的判断。”(王辉,2003)
同其他译本相比,理雅各译本中高频词的相似度较低,说明译者依据不同的翻译原则,选择了不同的翻译方法和策略来翻译特定高频词如书名和地名等。
在词云维度上,理雅各、赖发洛和刘殿爵三位译者的《孟子》英译本的差别不大,都做到了忠实于原文。
四、结语
本文基于理雅各、赖发洛、刘殿爵三位译者的《孟子》英译本,使用程序设计语言Python,基于语料库,从词汇丰富度、主题词、文本相似度和词云四个维度出发,通过类符/形符比、词频排序、语篇相似性度量和词云图四个指标分析了这些译本的相似点与不同之处。三个译本中理雅各译本词汇丰富度高;赖发洛、刘殿爵译本词汇丰富度较低。从译本的高频词对比角度而言,理雅各译本高频词与其他两个译本的重合率较低,独特性最高;赖发洛译本与其他两个译本的重合率较高,高频词独特性最低。从主题词角度而言,赖发洛、刘殿爵译本主题词相似性高,理雅各译本主题词差异性大。从词云角度而言,三个译本呈现较为一致的结果。本文使用Python调用相应的库和模块,利用客观数据对《孟子》的三个译本进行了对比研究。以往的译本对比分析大都以主观分析为依据,相比较而言,本文增添了以客观数据为基础的指标分析,角度更为新颖,结论更加有力,同时也有利于其他学者继续使用Python进行语料库方面的译本对比研究。
猜你喜欢
西南科技大学学报(哲学社会科学版)(2022年1期)2022-11-21
小康(2022年7期)2022-03-10
小康(2022年7期)2022-03-10
新体育(2022年3期)2022-03-03
文萃报·周五版(2021年14期)2021-06-08
小康(2021年7期)2021-03-15
小康(2021年7期)2021-03-15
红楼梦学刊(2019年5期)2019-04-13
红楼梦学刊(2019年2期)2019-04-12
海峡姐妹(2018年9期)2018-10-17
