
动态聚合权重的隐私保护联邦学习框架
2022-11-19 06:09应作斌方一晨张怡文
网络与信息安全学报 2022年5期
应作斌,方一晨,张怡文
动态聚合权重的隐私保护联邦学习框架
应作斌1,方一晨1,张怡文2
(1. 澳门城市大学,中国 澳门 999078;2. 安徽新华学院,安徽 合肥 230000)
在非可信中心服务器下的隐私保护联邦学习框架中,存在以下两个问题。①在中心服务器上聚合分布式学习模型时使用固定的权重,通常是每个参与方的数据集大小。然而,不同参与方具有非独立同分布的数据,设置固定聚合权重会使全局模型的效用无法达到最优。②现有框架建立在中心服务器是诚实的假定下,没有考虑中央服务器不可信导致的参与方的数据隐私泄露问题。为了解决上述问题,基于比较流行的DP-FedAvg算法,提出了一种非可信中心服务器下的动态聚合权重的隐私保护联邦学习DP-DFL框架,其设定了一种动态的模型聚合权重,该方法从不同参与方的数据中直接学习联邦学习中的模型聚合权重,从而适用于非独立同分布的数据环境。此外,在本地模型隐私保护阶段注入噪声进行模型参数的隐私保护,满足不可信中心服务器的设定,从而降低本地参与方模型参数上传中的隐私泄露风险。在数据集CIFAR-10上的实验证明,DP-DFL框架不仅提供本地隐私保证,同时可以实现更高的准确率,相较DP-FedAvg算法模型的平均准确率提高了2.09%。
联邦学习;差分隐私;动态聚合权重;非独立同分布数据
0 引言
随着大数据的兴起与发展,机器学习在计算机视觉、医疗、金融、电信、无人驾驶等领域广泛应用[1]。传统的机器学习是由一个服务商从各个参与用户处收集数据进行统一的模型训练,因此会直接将原始数据泄露给第三方服务商。而这类数据中可能包含敏感类信息,如医疗健康信息(个人生理特征、既往病史、基因序列等)、文本邮件、交易记录、资产数据、行踪轨迹等[2-3]。
在满足数据融合需求的条件下,解决数据孤岛难题,同时保障包含敏感信息的数据共享中的隐私安全,联邦学习技术应运而生。联邦学习最早在2016年由Google公司提出,是一种分布式的机器学习框架,其核心机制是多个数据持有方(个人、企业、机构)在参与协同训练时,仅在中间过程中交换模型参数,无须直接共享原始数据,从而避免原始敏感信息的泄露[4-6]。联邦学习在一定程度上有效保护了原始数据直接泄露给第三方[7-9],但随着对联邦学习的深入研究,其自身框架存在的安全问题被挖掘出来[10-12]。首先,联邦学习存在一个中心服务器,中心服务器接收来自所有本地参与方客户端的模型参数,Nicolas等[13]发现,一个不可信的中心服务器可以通过共享的参数(如梯度)还原原始的数据集。其次,参与联邦学习的不可靠参与方客户端可以轻松并且合法得到中间参数从而推断出其他参与方的模型参数,进而通过模型参数获取用户数据[14]。参与方客户端也可以通过构建恶意的数据集诱导其他参与方暴露更多含有敏感信息的原始数据。此外,其他的第三方攻击者可以通过发布的模型进行模型重构演练从而还原原始数据集收集敏感信息[15]。
对于联邦学习算法的隐私保护问题,需要一个严格的、有原则的框架来加强数据隐私。以差分隐私为代表的数据扰动方法作为成熟的隐私保护技术已广泛运用于联邦学习[16-23]。已有在联邦学习的框架上引入差分隐私从而保护用户数据的研究,McMahan等[24]提出了DP-FedAvg(differentially private-federated averaging)算法。DP-FedAvg在联邦学习模型参数共享算法FedAvg[4]的基础上,引入了差分隐私,是第一个通过应用高斯机制来保证联邦学习中用户级差分隐私的算法。DP-FedAvg算法主要有两个阶段:①参与方使用本地数据集训练模型;②中心服务器收集并聚合模型,通过加权平均获得全局模型并注入高斯噪声。然而,DP-FedAvg算法存在以下两个问题。
1) 在中心服务器中全局模型的聚合权重通常由用户端的数据样本量决定,这种设计假定数据在不同客户端之间是同分布的,但在现实世界中,无法知道不同参与方的数据分布类型,即不同参与方之间很可能是非独立同分布的数据(non-iid,non-independent and identically distributed data)。采用此种聚合方法导致模型的效用和适用能力不足。
2) DP-FedAvg算法建立在中心服务器是诚实的假定下,然而中心可以接收到来自所有本地参与方的模型参数信息,一旦中心服务器不可信,它能利用本地参与方的模型参数倒推数据的分布特征,甚至倒推出具体的训练集数据,导致本地参与方的数据隐私泄露,甚至出于利益相关将本地参与方的数据售卖给其他第三方,进一步导致本地参与方的数据隐私大规模泄露。
针对以上问题,本文提出了一种基于非可信中心服务器设定下的动态聚合权重的隐私保护联邦学习(DP-DFL,differentially private- dynamic federated learning)框架,主要贡献总结如下。
1) 构建了一种动态的模型聚合权重的方法,该方法可以从数据中直接学习联邦学习中的模型聚合权重,进一步实现更好的性能和不同数据分布类型的通用。
2) 假定中心服务器不可信,设计了一种新的协议,参与方客户端在本地模型隐私保护阶段使用噪声进行模型参数的隐私保护,从而降低本地参与方模型参数上传中的隐私泄露风险。
3) 验证了所提算法的效率,在数据集CIFAR-10上采用两种卷积神经网络模型进行实验,结果显示,DP-DFL在有效保证本地隐私的条件下,平均准确率相比DP-FedAvg算法提高了2.09%。
1 相关工作
越来越多的工作研究联邦学习背景下的隐私保护,将DP约束引入联邦学习模型共享是其中一种主要的研究。Geyer[25]等提出了一种算法,中心服务器将高斯机制注入每一轮迭代后的权重矩阵中,将单个客户的贡献隐藏在聚合中。
McMahan[24]等也提出了类似的想法,DP-FedAvg算法和DP-FedSGD算法扩展了FedAvg和FedSGD。FedAvg[4]算法和FedSGD[4]算法是联邦学习中的经典算法,中心服务器聚合每一轮迭代本地参与方客户端的最优梯度更新,FedAvg算法与FedSGD算法相比,前者在本地参与方客户端进行多轮迭代。DP-FedAvg算法和DP-FedSGD算法则是在每一轮的模型更新中加入扰动。以上算法在共享模型参数时通常假定不同参与方的数据具有相同分布,在异质环境下,DP-FedAvg算法和DP-FedSGD算法存在不稳定性和收敛的问题。
除此之外,非独立同分布数据上的联邦学习问题引起了人们的关注。在非DP环境下,Wang[26]提出了一种归一化的平均方法,在保持异质数据用户端快速收敛的同时,消除了目标的不一致性。Zheng[27]等在共享参数平均化阶段引入了基于注意力的加权平均法,以针对异质数据。在DP环境下,Hu[28]等针对数据异质性问题,提出了一种个性化的FL-DP方法,但此方法只针对线性模型。现有工作通常是在非DP环境下,考虑模型的统计数据或基本分布进行聚合,对客户数据进行基于梯度的优化,直接学习聚集权重的研究较少。联邦学习中DP约束条件下数据异质环境问题的研究尚且不足,尤其是针对神经网络模型及数据类型为图片的原始数据。为了解决数据异质性这一问题,在DP约束条件下的联邦学习中,本文引入了一种为联邦学习寻找最佳聚合权重的自动化方法。通过使用Dirichlet分布[29-30]对权重进行建模,将聚合权重由原来的依据客户端数据集大小优化为依据不同参与方的数据分布和模型的训练进度。
上述研究通常假定中心服务器是诚实的,然而实际中,中心服务器可能是“诚实但好奇”或是“恶意”的。Zhao[31]等考虑了DP-FedSGD算法在“诚实但好奇”的中心服务器条件下的联邦学习隐私保护。Li[32]等认为服务器是“诚实而好奇”的,但没有确保用户的端到端隐私。本文基于DP-FedAvg算法,并且假设中心服务器状态为非可信,设定中心服务器处于两种状态中的“诚实但好奇”这一状态,本地参与方客户端在将参数发送给中心服务器前需要进行扰动保护。相关工作比较如表1所示。
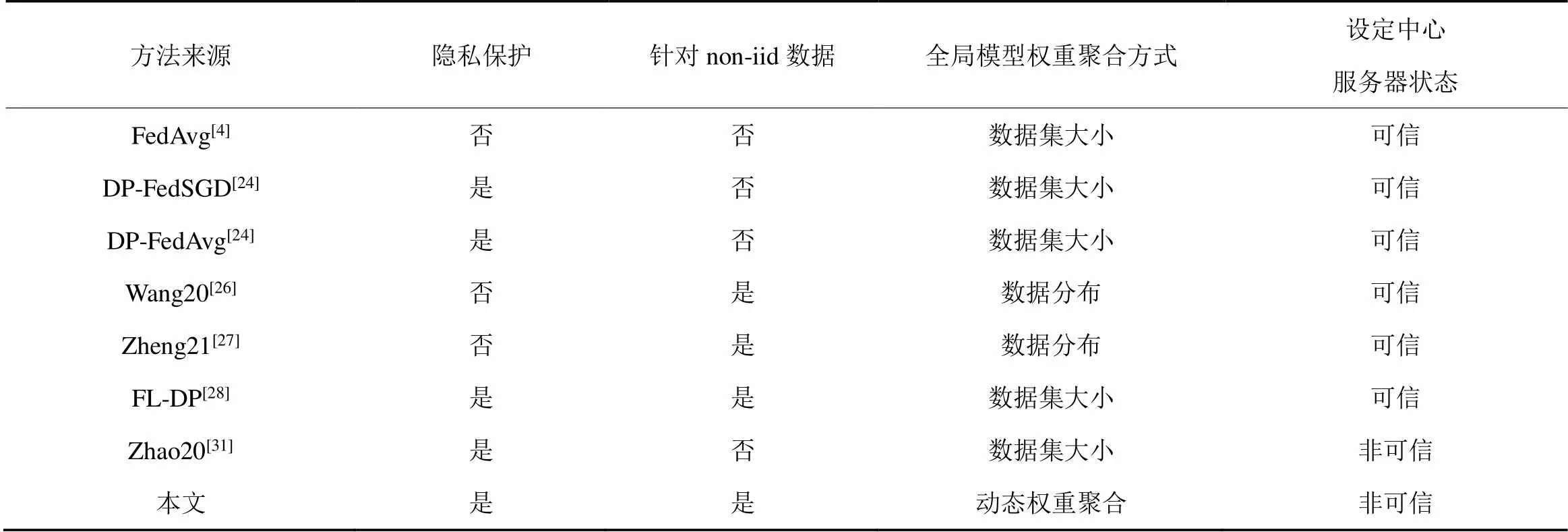
表1 相关工作比较
2 基本定义
2.1 联邦学习
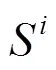

2.2 差分隐私
定义1 严格差分隐私

传统的DP基于最严格的假设,即攻击者拥有除了某一条信息以外的所有其他信息,但在现实中这类攻击者是十分少见的。严格差分隐私在隐私性的保护方面十分严格,影响了数据在使用过程中的可用性,在实际应用中主要使用含有松弛机制的差分隐私定义。带有松弛机制的差分隐私与传统差分隐私相比,引入了一个松弛项。
定义2 松弛差分隐私
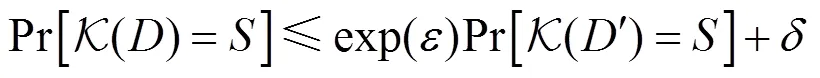
2.3 高斯机制
差分隐私通常通过添加噪声的方式来扰动数据,具体实现机制有高斯机制、指数机制、拉普拉斯机制。其中,拉普拉斯机制仅针对传统的差分隐私,而高斯机制可以满足松弛的本地差分隐私。
定义3 全局敏感度
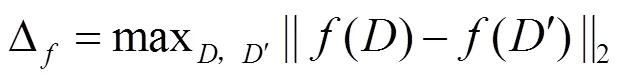
定义4 高斯噪声机制
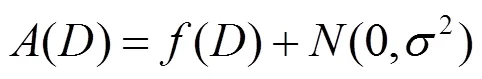
2.4 差分隐私随机梯度下降法
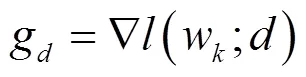
得到梯度后对梯度进行裁剪,即

3 方案实现
3.1 方案概述
本文提出了一种基于非可信中心服务器设定下的动态聚合权重的隐私保护联邦学习框架,流程如图1所示。

图1 DP-DFL流程
Figure 1 The illustration of DP-DFL
DP-DFL框架的完整流程为:①部分本地参与方客户端从中心服务下载全局模型参数和聚合权重参数;②本地参与方客户端在本地训练模型和更新权重,并将DP隐私保护,即采用DPSGD方法添加噪声后的模型更新和动态权重算法更新后的聚合权重上传给中心服务器;③中心服务器接受本地参与方客户端的模型更新和聚合权重更新,生成新的全局模型并进行DP隐私保护添加噪声;④重复上述每一轮迭代,直至达到设定的迭代轮数或期望的模型精确度。
3.2 动态聚合权重算法

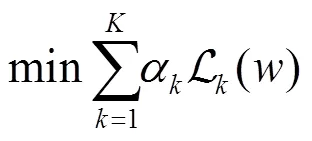
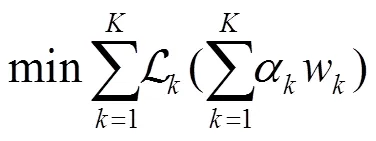
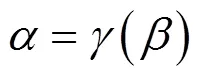
算法1给出了动态聚合权重算法的描述。
算法1 动态聚合权重算法
9) end for
3.3 DP-DFL框架
表2列出了DP-DFL框架相关符号和定义。

表2 符号和定义
算法2给出了DP-DFL的描述。DP-DFL框架分为中心服务器端和参与方客户端。在参与方客户端,主要使用DP-SGD进行模型的训练和参数的隐私保护,具体步骤如下。
步骤4 (第4行):裁剪梯度,限制单个数据对整体的影响。
算法2 DP-DFL
中心服务器
11) end
6) end for

4 实验与结果
4.1 实验环境设置
实验环境:操作系统为Windows 10,CPU为InterCore i5-5250U,基于框架为TensorFlow2.0,开发环境为Anaconda3、Python3.8.0、Pycharm、CUDA Toolkit 10.0。
数据集:CIFAR-10数据集共用60 000幅图片,每幅照片均为32×32的彩色照片,每个像素点包含R、G、B这3个数值,数值范围为0~255,照片可以划分为10种不同的类别。其中,50 000幅图片划为训练集,10 000幅图片划为测试集。
4.2 结果分析
(1)non-iid结果分析
本文实验使用两个常用的图像分类问题CNN模型Resnet18和VGG16。Resnet18网络分为4层,每层有两个模块组成,第一层由两个普通的残差块组成,其他3层由一个普通的残差块和下采样的卷积块组成。VGG16网络中,主要有13层卷积层以及3层全连接层,其中卷积层和全连接层使用ReLU函数作为激活函数。为了模拟异质数据的环境,对数据进行non-iid操作,本文实验使用Zheng等[27]的方法对数据集进行划分。

图2是模型设定为Resnet18时的实验结果,其中,图2(a)挑选每轮参与训练的本轮训练的参与方的概率为0.2,图2(b)概率为0.5。根据迭代10次后的模型最终准确率,DP-DFL优于DP-FedAvg,图2(a)中DP-DFL准确率为68.81%,高于DP-FedAvg的2.19%,图2(b)中DP-DFL准确率为78.56%,高于DP-FedAvg的2.42%。图3是模型设定为VGG16时的实验结果,其中图3(a)挑选每轮参与训练的本轮训练参与方的概率为0.2,图3(b)概率为0.5。根据迭代10次后的模型最终准确率,DP-DFL优于DP-FedAvg,图3(a)中DP-DFL准确率为81.37%,高于DP-FedAvg的2.36%,图3(b)中DP-DFL准确率为88.21%,高于DP-FedAvg的1.39%。

图2 Resnet18实验结果
Figure2 The experimental result of Resnet18
根据结果显示,无论训练模型选择Resnet18或VGG16,无论每轮迭代选取的本地参与方客户端数量为2或5,DP-DFL在保障本地隐私的条件下,不仅模型精度没有受损,相较DP-FedAvg算法的模型准确率平均提高了2.09%。
差分隐私以损失部分准确率来达到隐私保护的效果。将DP-DFL框架与其他两个非DP环境下的联邦学习方法相比,模型准确率也未受到很大的影响。
(2)iid结果分析
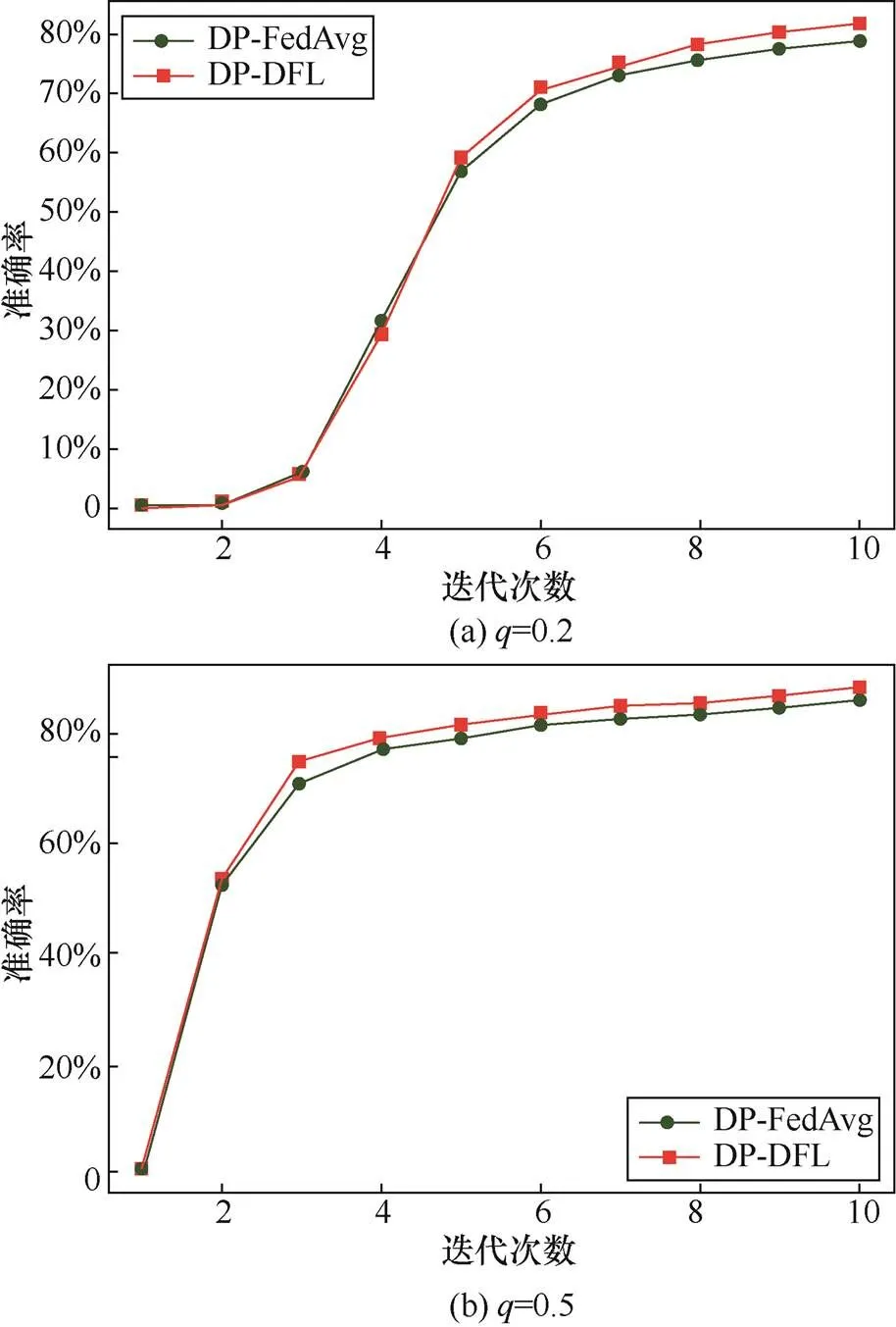
图3 VGG16实验结果
Figure 3 The experimental result of VGG16

图4是iid环境下的实验结果,其中图4(a)挑选每轮参与训练的本轮训练的参与方的概率为0.2,图4(b)概率为0.5。结果表明,在同分布情况下,DP-DFL收敛速度虽然慢于DP-FedAvg,但在第10次全局迭代左右,两者准确率已经达到相似水平。DP-DFL在同分布数据情况下仍可以保持良好的性能表现。
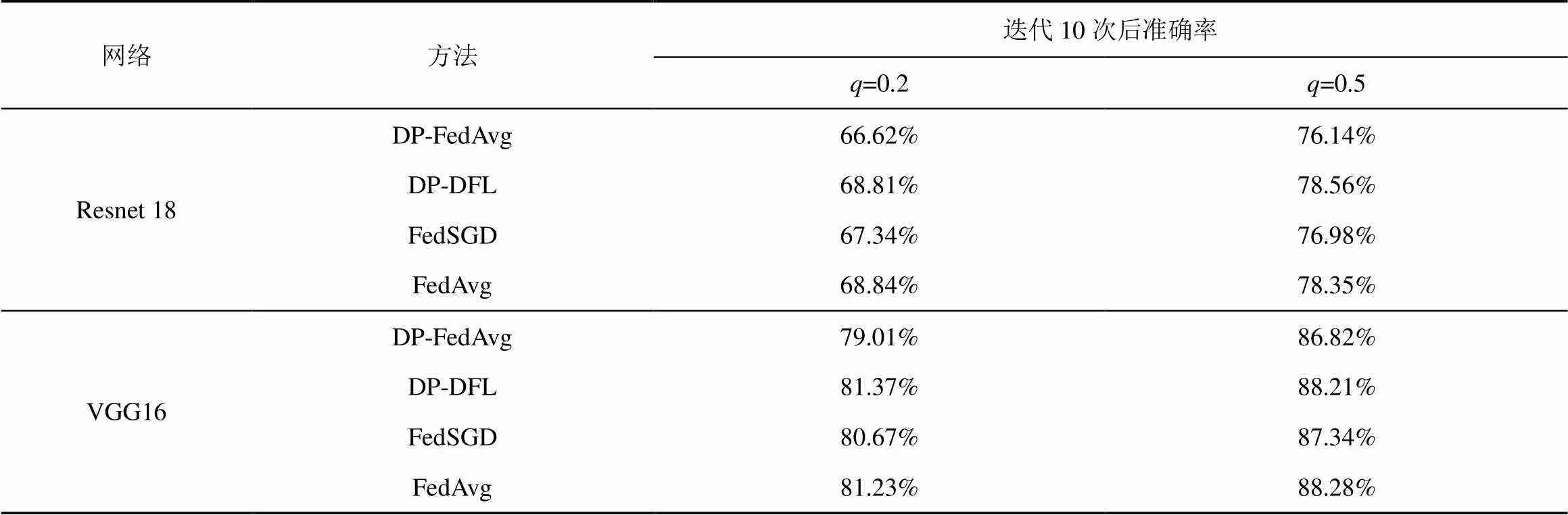
表3 实验结果
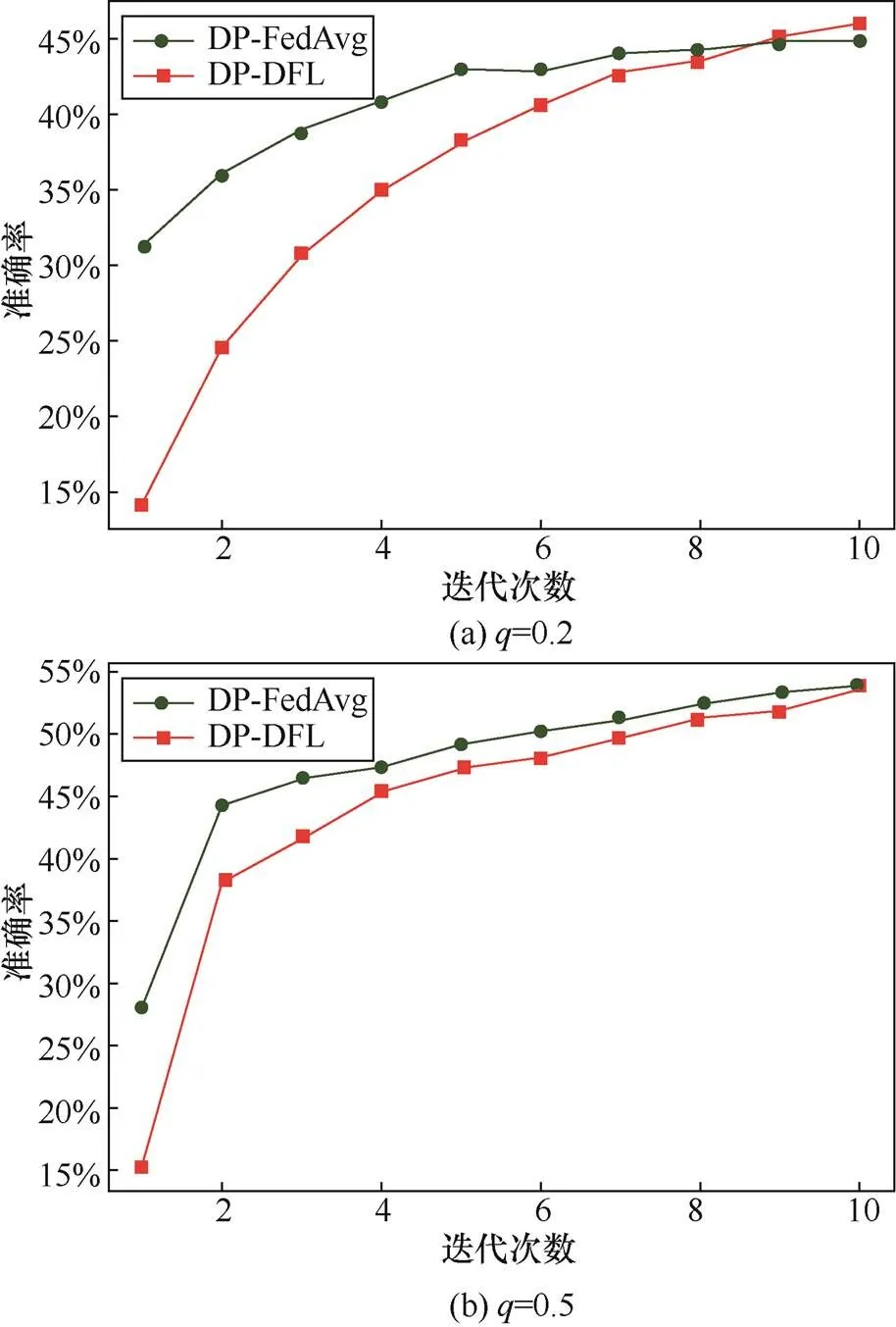
图4 iid环境下的实验结果
Figure 4 The experimental result of iid
5 结束语
针对现有联邦学习全局模型聚合时,不同参与方客户端拥有非独立同分布的数据类型造成模型全局模型效用和适用性效果不高,以及中心服务器不可信的问题,本文提出了一种DP-DFL框架。该框架在本地参与方模型训练阶段引入了DP-SGD以保证本地模型参数的隐私不会被不可信第三方窃取,同时,在本地模型参数聚合阶段设计了一种新的动态模型聚合权重的方法。实验验证,DP-DFL不仅进一步保证了用户隐私,而且模型精度优于DP-FedAvg算法。未来的工作将研究更复杂的聚合操作,同时可以模拟现实真实攻击,寻找效用和隐私保护均衡更优的方法。
[1] LI T, SAHU A K, TALWALKAR A, et al. Federated learning: challenges, methods, and future directions[J]. IEEE Signal Processing Magazine, 2020, 37(3): 50-60.
[2] XU X H, PENG H, SUN L C, et al. Fedmood: federated learning on mobile health data for mood detection[J]. arXiv preprint arXiv:2102.09342, 2021.
[3] CHE SICONG, PENG H, SUN L C, et al. Federated multiview learning for private medical data integration and analysis[J]. arXiv preprint arXiv:2105.01603, 2021.
[4] MC-MAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial Intelligence and Statistics. 2017: 1273-1282.
[5] LIU Z, GUO J, YANG W, et al. Privacy-preserving aggregation in federated learning: a survey[J]. arXiv preprint arXiv: 2203.17005, 2022.
[6] RAMASWAMY S, THAKKAR O, MATHEWS R, et al. Training production language models without memorizing user data[J]. arXiv preprint arXiv:2009.10031, 2020.
[7] LI Z, SHARMA V, MOHANTY S P. Preserving data privacy via federated learning: challenges and solutions[J]. IEEE Consumer Electronics Magazine, 2020, 9(3): 8-16.
[8] LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[J]. Proceedings of Machine Learning and Systems, 2020, 2: 429-450.
[9] 陈前昕, 毕仁万, 林劼, 等. 支持多数不规则用户的隐私保护联邦学习框架[J]. 网络与信息安全学报, 2022, 8(1): 139-150.
CHEN Q X, BI R W, LIN J, et al. Privacy-preserving federated learning framework with irregular-majority users[J]. Chinese Journal of Network and Information Security, 2022, 8(1): 139-150.
[10] 刘艺璇, 陈红, 刘宇涵, 等. 联邦学习中的隐私保护技术[J]. 软件学报, 2021, 33(3): 1057-1092.
LIU Y X, CHEN H, LIU Y H, et al. Privacy-preserving techniques in Federated Learning[J]. Journal of Software, 2022, 33(3): 1057−1092.
[11] 王腾, 霍峥, 黄亚鑫, 等. 联邦学习中的隐私保护技术研究综述[J].计算机应用, 2022.
WANG T, HUO Z, HUANG Y X, et al. Survey of privacy-preserving technologies in federated learning [J]. Journal of Computer Applications,2022.
[12] FIGURNOV M, MOHAMED S, MNIH A. Implicit repara-meterization gradients[C]//Advances in Neural Information Processing Systems. 2018: 441-452.
[13] PAPERNOT N, ABADI M, ERLINGSSON U F, et al. Semi-supervised knowledge transfer for deep learning from private training data[C]//ICLR. 2017.
[14] SONG C, RISTENPART T, SHMATIKOV V. Machine learning models that remember too much[C]//2017 ACM SIGSAC Conf. on Computer and Communications Security. 2017: 587-601.
[15] SHOKRI R, STRONATI M, SONG C, et al. Membership inference attacks against machine learning models[C]//2017 IEEE Symposium on Security and Privacy (SP). 2017: 3-18.
[16] KIM M, GÜNLÜ O, SCHAEFER R F. Federated learning with local differential privacy: Trade-offs between privacy, utility, and communication[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2021: 2650-2654.
[17] SUN L, QIAN J, CHEN X. LDP-FL: practical private aggregation in federated learning with local differential privacy[J]. arXiv preprint arXiv:2007.15789, 2020.
[18] ABADI M, CHU A, GOODFELLOW I, et al. Deep learning with differential privacy[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. 2016: 308-318.
[19] MIRONOV I, TALWAR K, ZHANG L. R'enyi differential privacy of the sampled gaussian mechanism[J]. arXiv preprint arXiv:1908.10530, 2019.
[20] SUN L, LYU L. Federated model distillation with noise-free differential privacy[J]. arXiv preprint arXiv:2009.05537, 2020.
[21] NAGAR A, TRAN C, FIORETTO F. Privacy-preserving and accountable multi-agent learning[C]//AAMAS Conference proceedings. 2021.
[22] DAI Z, LOW B K H, JAILLET P. Differentially private federated Bayesian optimization with distributed exploration[J]. Advances in Neural Information Processing Systems, 2021, 34.
[23] ANDREW G, THAKKAR O, MCMAHAN B, et al. Differentially private learning with adaptive clipping[J]. Advances in Neural Information Processing Systems, 2021, 34.
[24] MC-MAHAN H B, RAMAGE D, TALWAR K, et al. Learning differentially private recurrent language models[C]//arXiv preprint arXiv:1710.06963, 2017.
[25] GEYER R C, KLEIN T, NABI M. Differentially private federated learning: a client level perspective[J]. arXiv preprint arXiv:1712.07557, 2017.
[26] WANG J Y, LIU Q H, LIANG H, et al. Tackling the objective inconsistency problem in heterogeneous federated optimization[C]// NeurIPS. 2020.
[27] ZHENG Q, CHEN S, LONG Q, et al. Federated f-differential privacy[C]//International Conference on Artificial Intelligence and Statistics. 2021: 2251-2259.
[28] HU R, GUO Y X, LI H N, et al. Personalized federated learning with differential privacy[J]. IEEE Internet of Things Journal, 7(10):9530–9539, 2020.
[29] CHEN X N, WANG R C, CHENG M H, et al. Drnas: dirichlet neural architecture search[J]. arXiv preprint arXiv:2006.10355, 2020.
[30] XIA Y, YANG D, LI W, et al. Auto-FedAvg: learnable federated averaging for multi-institutional medical image segmentation[J]. arXiv preprint arXiv:2104.10195, 2021.
[31] ZHAO Y, ZHAO J, YANG M, et al. Local differential privacy-based federated learning for internet of things[J].IEEE Internet of Things Journal,2022,8(11):8836-8853.
[32] LI Y W, CHANG T H, CHI C Y. Secure federated averaging algorithm with differential privacy[C]//2020 IEEE 30th International Workshopon Machine Learning for Signal Processing (MLSP), 2020: 1-6.
Privacy-preserving federated learning framework with dynamic weight aggregation
YING Zuobin1, FANG Yichen1, ZHANG Yiwen2
1. City University of Macau, Macau 999078, China 2. Anhui Xinhua University, Hefei 230000, China
There are two problems with the privacy-preserving federal learning framework under an unreliable central server.① A fixed weight, typically the size of each participant’s dataset, is used when aggregating distributed learning models on the central server. However, different participants have non-independent and homogeneously distributed data, then setting fixed aggregation weights would prevent the global model from achieving optimal utility. ② Existing frameworks are built on the assumption that the central server is honest, and do not consider the problem of data privacy leakage of participants due to the untrustworthiness of the central server. To address the above issues, based on the popular DP-FedAvg algorithm, a privacy-preserving federated learning DP-DFL algorithm for dynamic weight aggregation under a non-trusted central server was proposed which set a dynamic model aggregation weight. The proposed algorithm learned the model aggregation weight in federated learning directly from the data of different participants, and thus it is applicable to non-independent homogeneously distributed data environment. In addition, the privacy of model parameters was protected using noise in the local model privacy protection phase, which satisfied the untrustworthy central server setting and thus reduced the risk of privacy leakage in the upload of model parameters from local participants. Experiments on dataset CIFAR-10 demonstrate that the DP-DFL algorithm not only provides local privacy guarantees, but also achieves higher accuracy rates with an average accuracy improvement of 2.09% compared to the DP-FedAvg algorithm models.
federated learning, differential privacy, dynamic aggregationweight, non-independent and identically distributeddata
TP393
A
10.11959/j.issn.2096−109x.2022069
2022−04−09;
2022−09−06
方一晨,fyc980601@163.com
澳门科学技术发展基金(0038/2022/A)
General R&D Subsidy Program Fund Macau (0038/2022/A)
应作斌, 方一晨, 张怡文. 动态聚合权重的隐私保护联邦学习框架[J]. 网络与信息安全学报, 2022, 8(5): 56-65.
Format: YING Z B, FANG Y C, ZHANG Y W. Privacy-preserving federated learning framework with dynamic weight aggregation [J]. Chinese Journal of Network and Information Security, 2022, 8(5): 56-65.
应作斌(1982−),男,安徽芜湖人,澳门城市大学助理教授,主要研究方向为区块链、联邦学习。

方一晨(1998−),女,浙江湖州人,澳门城市大学硕士生,主要研究方向为差分隐私、联邦学习。
张怡文(1980−),女,安徽阜阳人,安徽新华学院教授,主要研究方向为数据挖掘、联邦学习。

猜你喜欢
计算机研究与发展(2022年10期)2022-10-14
新世纪智能(数学备考)(2021年5期)2021-07-28
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
中国房地产·学术版(2016年7期)2016-10-21
专利代理(2016年1期)2016-05-17
项目管理技术(2016年10期)2016-05-17
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
四川生理科学杂志(2014年2期)2014-02-28
