
基于微服务架构的负载均衡优化算法及实现
2022-11-10 05:27经成,谢军
南昌大学学报(理科版) 2022年4期
经 成,谢 军
(南昌大学数学与计算机学院,江西 南昌 330031)
随着互联网急速发展,IT行业日新月异,系统架构的发展也在与时俱进,当用户量以几何指数飞速增长,曾经流行很久的单体架构[1]已经很难应对和处理日益增长的软件复杂性。传统的单体架构也很难支撑如今庞大的数据量,当同时访问人数达到一定数额,服务器就会出现响应缓慢,交互失败等问题,甚至可能会出现服务器宕机等情况。基于这种现状,微服务架构风格应运而生,微服务架构核心是面向服务,重点是模块划分,服务之间正确高效调用。微服务架构通常都是集群的形式,但当服务端机器从一台提升为集群形式,其承载的访问量得到很大程度的提升时,系统的复杂程度也随之提升,此时产生了一个新的问题,客户端带着请求访问服务端,由于服务端是一个大的集群组,请求需要知道自己该到哪个具体的机器上调取服务,这就需要让系统设计者设计一套可用合理的负载均衡算法,负载均衡存在的意义就是让请求基于该算法能够知道去哪台机器获取资源。如果负载均衡算法高效可用,就可以大幅度提升系统提供服务的能力。
传统负载均衡算法包括静态负载均衡算法和动态负载均衡算法,静态负载均衡有无法获取服务器实时负载的不足,动态负载均衡算法会给服务器端带来负担。本文针对传统负载均衡算法存在的不足,设计了基于最低并发负载算法的动态权重负载算法。最低并发负载算法[2]面对瞬时的流量冲击时会出现算法降级演变为轮询算法从而导致算法失效的情况。本算法通过计算磁盘利用率的方差来衡量系统整体负载的稳定度,当磁盘利用率的方差在一个合适的范围,算法根据服务器节点的性能计算得出系统节点的权重,当最低并发算法失效,算法升级为动态权重算法,权重大的节点被选中的概率也会更大。
1 负载均衡优化策略和实现方式
负载均衡算法有很多种,从系统角度可以分为同构系统下的负载均衡算法和异构系统下的负载均衡算法;从算法种类角度可以分为静态负载均衡算法和动态负载均衡算法。其中静态负载均衡算法实现简单,系统资源消耗小,很适合同构系统集群的环境。
随机算法负载均衡器通过随机函数生成一个随机数用于选择后台的集群节点,选择的机器无法预测,即满载服务器还是存在被选中的可能性,所以这种算法的负载效果比较差。
在随机算法中,如果每台机器的性能差异较大,则会严重影响负载均衡效率和集群提供服务的能力,因此在随机算法的基础上,负载均衡器为每个可用的服务器节点加上了权重,权重大的节点更大概率被选中,在这种算法中,可以很好地应对机器性能不会大幅度改变的异构系统,但是若是节点性能受到负载状况的影响,则这种算法效果也不理想。
在同构系统中,静态负载均衡算法[3]有着很好的负载效果,但是若是需要实时监测机器负载的异构系统下,由于静态负载均衡算法无法自适应动态调整,所以静态负载均衡算法有很大的局限性。此时异构系统下的区域分解算法和动态负载均衡算法就能满足异构系统对于负载性能的要求。
异构系统下的简易化区域分解算法是将计算域分解为若干子域,分别求解再进行综合的一种计算方法。此种方法分解了计算过程,加快了计算速度,使总体解更符合实际,并有利于采用并行计算,加快运算速度。在异构系统下,由于每个系统的独特性,因此我们不能归一化处理机器状态,假设系统有N个处理机,这N个处理机完成一个时间步的时间为Ti,则处理机平均计算时间Ta,Ta的计算公式如1.1所示。
(1.1)
集群系统所有机器最大处理时间为Tmax,即为处理机并行处理一个任务所要耗费的时间,计算公式如1.2所示。
Tmax=max{Ti}(0≤i≤N-1)
(1.2)
由以上步骤可得负载均衡函数,IB为负载均衡临界值,计算公式如1.3所示。
(1.3)
公式1.3为简易化的负载均衡平衡函数,显然,IB等于零时系统负载近似达到平衡,大于零时,系统负载处于失衡状态。
在上文中我们简单讨论了区域分解算法下的系统负载状况,由于粒度较粗再加上现实环境中,系统负载还要受各种因素的干扰。因此在实际环境中,这种算法的应用场景极其有限。所以在实际环境中,我们往往选择动态负载均衡算法。下面是常见的动态负载均衡算法。
1.最短预期延时算法是期望最小化每个任务的预期延时直到任务完成的算法,服务器Si的预期延时公式如1.4。
(1.4)
其中,C(Si)表示服务器Si的当前连接数,W(Si)表示服务器Si的权重。当服务器Sm满足公式1.5时,新的连接请求将会被调度到Sm上。
(C(Sm)+1)/W(Sm))=min{(C(Si)+1)/W(Si)}(i=0,1,2,…,n-1)
(1.5)
最短预期延时算法[4]考虑了连接的预期成本,不是以当前连接数作为成本,而是以当前连接数加1作为成本,这样就极大提高了算法的效率。最短预期延时调度算法希望在请求少的时候将请求尽可能转发到性能高的服务器上,这种调度算法不再考虑非活动连接。这种算法有一定缺陷,在请求量比较少的时候,某个权重下的节点可能一个请求都没有轮到。而权重大的节点却轮到了比较多的请求。
2.最低并发策略(BestAvailableRule)是一种动态、智能的负载均衡算法,主要是根据节点的当前连接数来决定将请求发送至哪个节点。当服务器集群性能平均,每台服务器提供服务的能力相差不大时,我们往往采用RoundRobinRule负载策略,即轮询策略,但是现实情况中,服务器性能有好有坏,性能不均匀,轮询算法就显得极其不合理,不合理的负载均衡算法会极大影响服务端提供服务的效率和能力。最低并发策略就很好地考虑服务器端性能,并发数是其衡量的重要指标,该策略会将请求转发至并发数最小的服务器,这种策略对服务器有很好的保护功能。
2 加入动态权重的BestAvailableRule改进算法
上文提及的BestAvailableRule[5]算法可以一定程度上解决因服务器性能不均导致负载不平衡的问题。但是当并发高到一种程度,服务器可能会出现服务降级,服务响应时间延长等问题,BestAvailableRule策略一定程度地维护了服务器集群的整体性能,该策略的流程图如下所示:
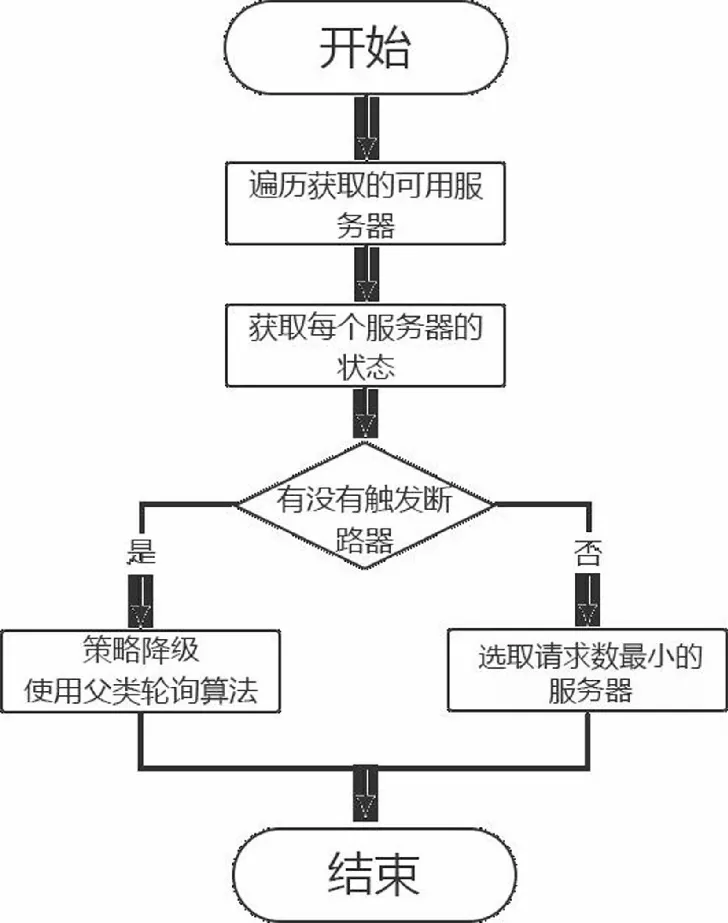
图1 BestAvailableRule负载策略流程图Figure 1 Flow chart of BestAvailableRule load policy
通过上述BestAvailableRule负载策略流程图和源码可知,BestAvailableRule策略关键在于找取并发数最小的服务器,这种算法性能会随着并发量极速升高而降低,当并发量很高时,BestAvailableRule算法策略性能将会下降,慢慢趋近于轮询算法[6],该算法策略平均响应时间随着并发量的提升如下图所示,归纳该图数据我们可以知道,当我们定义的并发连接数小于全部的服务器并发连接数时,此时就没有最优的可用服务,这个时候该算法会发生性能下滑,并演变成轮询负载均衡算法。因此本文在最小并发策略的基础上加入了权重,改进了该算法,利用动态权重来让负载均衡策略在高并发场景下仍然可以高效平稳地运行。
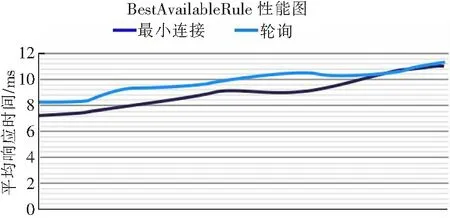
开发用户量/个图2 BestAvailableRule性能图Figure 2 BestAvailabilityRule performance diagram
一般来说,磁盘空间使用率是反映负载节点存储空间剩余容纳量的最直观表现,也是提供服务的子节点负载能力的关键衡量标准。通过磁盘利用率,我们可以分析出节点的空间使用情况和当前存储空间下的负载能力。磁盘空间利用率是影响负载均衡的重要因素。可以用公式2.1表示磁盘空间利用率,其中Pi表示编号为i的节点的磁盘利用率。
(2.1)
其中,Pi是第i个节点的磁盘使用率[7],DUi是第i个节点磁盘已经使用的内存空间,单位通常是GB,DTi是第i个节点磁盘的总容量,单位通常也是GB,在同构型分布式系统下,每个磁盘的DT即磁盘总容量一般来说是一样的,但是在异构系统下,DT一般来说是不一样的,因此,不能把机器的磁盘总容量作为衡量机器负载能力的标准。
可以由公式2.1得出的磁盘利用率作为基准计算出节点磁盘利用率的方差DX,计算公式如2.2所示。
(2.2)
其中,DX是磁盘利用率的方差,Pa是集群系统下机器的平均磁盘利用率,系统有N台服务器。DX可以衡量系统整体负载的稳定度,当DX值越大,系统子节点磁盘利用率的离散程度就越大,此时系统整体处于失衡状态,当DX值越小,系统子节点磁盘利用率的离散程度[8]就越小,此时系统稳定性相对而言就较强。系统磁盘平均利用率Pa计算公式如2.3所示。
(2.3)
系统磁盘平均利用率Pa可以大概衡量系统磁盘空间的使用状况,但是可能会出现系统机器性能不平均[9]这种状况,因此磁盘平均利用率只能作为参考因子而不能作为影响系统负载的关键因素。dm是系统各节点相对于磁盘平均利用率的最大差值即最大相对偏差值,当最大相对偏差值在一个合理的范围内,平均磁盘利用率才具有较强的可参考性[10],最大相对偏差dm计算公式如公式2.4所示。
dm=max{|pi-pa|i=0,1,2,…,N}
(2.4)
除了服务器的磁盘空间使用离散度外,服务器的其他性能指标也是重要衡量标准。
若是要计算出服务器端的权重,服务器的性能指标是其重要参考依据[11],当上文中的磁盘利用率的方差在正常范围内,即系统处于相对平衡状态[12]。当系统失衡时,断路器被触发。已知系统有N台服务器,令Si表示服务器集群中第i个服务器,A表示服务器的CPU主频,B表示内存,C表示带宽,计算第i个性能的服务器的性能指标X(Si)为:
(2.5)
下面Au,Bu,Cu分别表示目标服务器上的CPU利用率,内存利用率和带宽利用率,计算第i个服务器的负载为L(Si):
L(Si)=αAui+βBui+γCui
(2.6)
其中α,β,γ是影响因子系数且满足α+β+γ=1。
由以上推导过程,我们得出权重计算公式,T表示总连接数,ti表示第i个服务器的连接数,计算得出的权重为W(Si)为
(2.7)
前文介绍的最小并发算法会有很大的瓶颈,本文为服务器列表加入动态权重,让客户端更加智能的选取最符合性能的服务器。
在BestAvailableRule算法中,当设定的并发数小于每一个服务器的请求数时,算法策略失效,本算法的核心是当BestAvailableRule算法失效时,算法升级到动态权重负载均衡算法,动态权重负载均衡算法的核心是在客户端中引入权重,将权重作为选择服务器的标准。
由上述计算得出的权重公式,我们可得集群中N台服务器的权重之和Wt,使用式2.8计算。
(2.8)
经过上述计算得到了服务器的权重之和,相加之后相当于各机器在总权重上各占了相应的一段比例。由权重和可得随机权重Wr,使用式2.9计算。
Wr=σWt(0<σ<1)
(2.9)
其中σ是随机系数。若随机权重满足式2.10,说明第(i+1)台机器被选中。
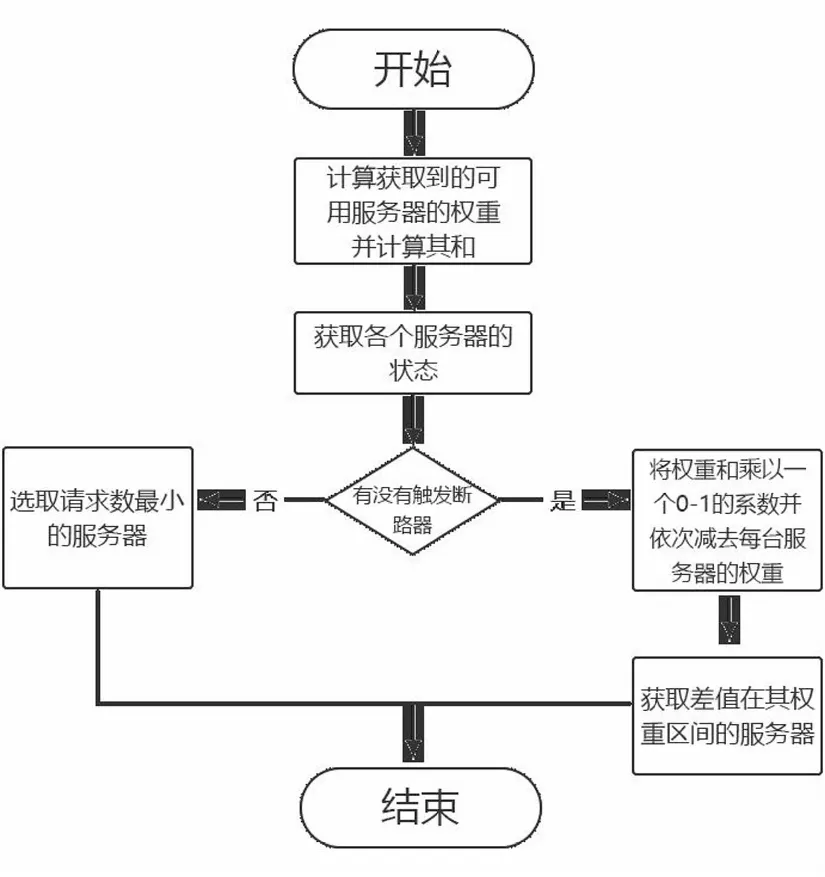
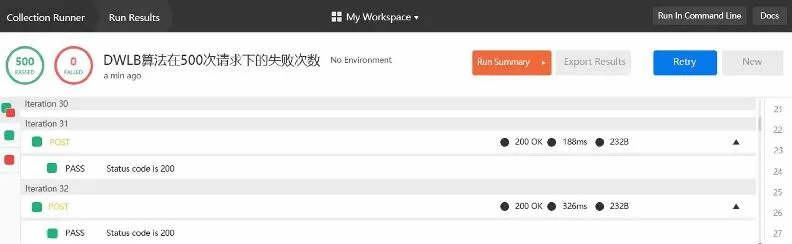
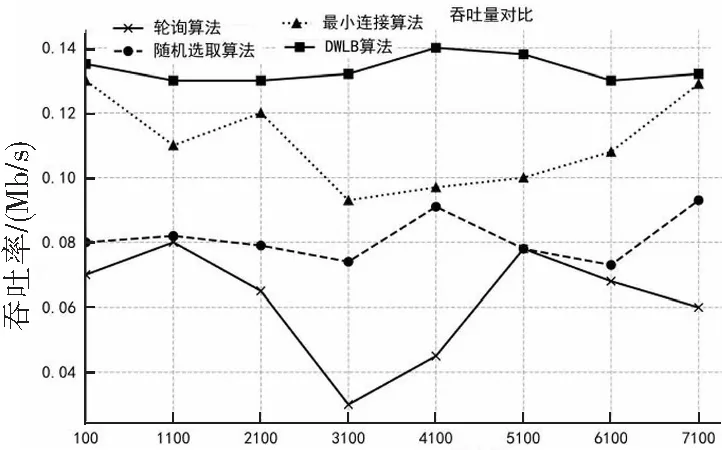
W(Si) (2.10) 其中i=0时权重为0,即W(S0)=0。 算法示意图如图3: 图3 动态权重负载均衡算法示意图Figure 3 Schematic diagram of dynamic weight load balancing algorithm 由上图可知,服务器权重越高,在线段上的占的长度越长,被随机数选中的概率越大。该算法完整的流程图如下图所示: 图4 动态权重算法流程图Figure 4 Flow chart of dynamic weight algorithm 通过以上流程图可知,优化后的算法首先接收到用户的请求,根据用户请求内容分析出功能所属的微服务链,根据微服务链确定该链上的微服务类型以及他们的依赖关系,再借助微服务链中的数据传输信息[13],负载均衡器对系统中的实例进行遍历计算,寻找出所得代价最小的实例组合。当并发量在一定范围内,算法的逻辑是选取最小并发处理机,当并发量提高时,算法智能的提升为动态权重负载均衡算法[14]。算法维持了逻辑的完整性和严谨性,当遇到请求的大量冲击时,本算法也能维持其高可用性。 本次测试目的将验证本文所提出的负载均衡算法的可用性,为了验证这个算法,本实验将在高并发的实验环境下分别测试轮询算法,随机选取算法,最小连接算法和本文提出的DWLB算法下系统的性能指标。 本实验利用压力测试工具siege和Postman模拟了100,500,1000,1500,2000,3000,4000,5000等不同请求数量的并发场景,分别对比了Ribbon自带的轮询调度算法、随机选取算法、最小连接算法以及本文提出的DWLB算法,选择了平均响应时间、吞吐率和失败次数这三个指标作为算法评估指标。 这里以DWLB算法在500次请求下的失败次数为例,经过测试工具Postman设置请求数量进行测试,测试结果如下图所示,总共发起了500次请求,请求失败的次数为0,这可以初步验证本算法的高稳定性。 图5 DWLB算法在500次下失败次数实验结果Figure 5 Experimental results of failure times of DWLB algorithm under 500 times 总的实验结果如表1所示,展示了不同算法在不同请求数量下的性能数据。其中吞吐率单位是兆每秒(Mb/s),响应时间单位是秒(s),失败次数单位是1,为了显示简洁,依次用A、B、C、D代替轮询算法、随机选取算法、最小连接算法、DWLB算法,用1、2、3代替吞吐率、响应时间、失败次数,例如用B3表示最小连接算法下的失败次数。 表1 各个算法在不同并发量下的性能指标Table 1 Performance indexes of each algorithm under different concurrency 将上述数据以图表展现出来,如图6、图7、图8所示分别表示吞吐率、响应时间和失败次数的折线图: 并发数图6 吞吐率对比Figure 6 Comparison of throughput rates 并发数图7 请求响应时间对比Figure 7 Comparison of request response time 并发数图8 请求失败次数对比Figure 8 Comparison of number of failed requests 以上实验从系统吞吐率、请求响应时间、请求失败次数三个性能指标得出了不同算法在不同请求数量级下的响应情况。 吞吐率是指服务器在单位时间内可以处理并发请求数量[15],从图6中可以看出这4种算法浮动比较平稳,没有一个比较稳定的吞吐率峰值点,但是DWLB算法因为获取了不同服务器实时的健康状况[16],因此在吞吐率这个性能指标,DWLB算法明显比其他算法表现优秀。 请求响应时间是指服务器对处理请求花费的时间[17],从图7可以看出,轮询算法和随机算法因为其算法复杂度较为简单,所以响应时间很短,DWLB算法因为其算法复杂,运算量大,所以响应时间比其他算法久点,但是差距不大,在可接受范围之内,这说明DWLB算法不会给服务器带来过多额外的负担。 失败次数是指服务器端没有给出正确响应的请求的次数[18],由图8可知,轮询算法下的失败次数比较均衡[19],因为每个服务器得到请求的机会都是一致的,随机选取算法因为带有一定的偶然性,所以造成折线图波动较大[20],最小连接算法因为优先把请求给空闲服务器,响应时间较短,DWLB算法因为从多个维度计算了服务器的性能,能够最大程度地提高请求的处理正确度,所以失败次数显著优于其他算法,这也验证了本文提出算法的高性能。 DWLB算法虽然在响应时间稍逊于其他算法,但是在吞吐率和失败次数性能明显优于其他算法,并且响应时间跟其他算法的差距也在接受范围之内,因此经过实验证明,本文提出的负载均衡算法具有高可行性。
3 实验设计



4 结语
猜你喜欢
矿山安全信息(2022年11期)2022-11-26
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2019年2期)2019-10-30
中学生数理化(高中版.高考理化)(2019年6期)2019-06-22
人大建设(2018年5期)2018-08-16
妇女生活(2018年7期)2018-07-14
证券市场红周刊(2018年3期)2018-05-14
智富时代(2018年1期)2018-03-26
