
基于SmoteTomek和GBDT算法的不平衡数据违约预测
2022-11-08 11:14杨冰清赵金虎
宿州学院学报 2022年10期
杨冰清,高 珊,赵金虎
阜阳师范大学数学与统计学院,安徽阜阳,236037
在“互联网+”“金融赋能”等模式背景下,互联网金融得到了前所未有的快速发展。但是在飞速发展的同时,一些风险问题也不断随之而来。例如:贷款人存在经营不当,导致还款能力降低;贷款人还款意愿的不佳,导致贷款者的违约风险攀升。合理控制贷款坏账率,建立个人贷款违约风险预测模型,构建良性可循环金融体系对于金融业各机构来说具有重要且现实的意义。
在大数据时代,传统的计量方法已经无法满足海量数据的需求,机器学习方法以其较高的精度和较低的时间损耗在众多领域都取得了显著的成效。由于金融贷款用户数据往往具有较大的数据体量、较高的数据特征以及样本的非均衡、非线性等特点,传统的Logistic回归等方法已不再满足数据的宏观假设。方匡南等[1]将Lasso引用入logistic模型,旨通过Lasso进行特征选择,保留对模型重要的变量,提高计算的效率。近几年借助于机器学习的发展,一些学者将机器学习算法应用到违约风险预测研究中,如陈诗一[2]、Hajek等[3]证实了发展机器学习方法的预测准确度比Logistic模型有明显的改善。Hajek等[3]通过对比k-means、SVM和随机森林方法对贷款违约进行评估,最终结果表明随机森林优于其他方法。
传统的贷款违约模型往往是基于平衡分布假设建立,但违约数据具有典型的分布不平衡特征,如果忽略该特征则建立出来的模型会发生偏移,导致模型预警能力减弱,而机器学习在一定程度上减弱传统方法所要求的样本数据正态性的这一问题[4]。
解决数据分布不平衡问题可以从两方面着手,算法方面和数据方面。算法方面是指加强分类算法对不平衡数据中薄弱数据的倾向性,大致可分为代价敏感学习和集成学习。代价敏感学习是指通过对较少数据类别的样本增加模型预测错误的权重,从而改善类别的分布不同造成的模型偏移。集成学习是指结合多个分类器的结果进行预测,从而获得比单一分类器更全面、更精确的预测结果。相关论文通常是在Boosting算法和Bagging算法的基础上做一些改进,如多分类代价敏感AdaBoost算法[5],加入Smote思想的Bagging算法[6]。数据方面是指通过重抽样改变数据集分布不平衡现状,具体可以采用过采样和欠采样,分别增加少数量类别样本和减少多数量类别样本。数据方面原理简单且易操作,但过采样可能导致数据量过多,从而造成过拟合;而欠采样可能出现数据量较少,模型拟合欠佳,从而出现欠拟合。因此,如何得到一个有较低时间损耗并且有较高精度的违约模型,已经是众多学者近年来研究的重点。
1 理论与方法
1.1 Boosting算法
Boosting算法是道德对不同样本集获取相应样本子集,利用弱分类器算法在该样本子集上训练基分类器,这样训练n次后就得到n个基分类器;再利用框架算法将这n个基分类器进行加权融合,生成最后的结果分类器。其思想通过将更大的权重分配给错误分类的样本,并降低正确分类样本的权重,从而使得算法能针对错误分类样本进行下一轮分类。然后将每次训练集上的精度作为每个基分类器的权重进行加权,将加权投票的结果作为最终分类器的结果。其核心目的是将原本准确率不高的弱分类器通过集成的方法得到准确率较高的强分类器模型。
1.2 Adaboost算法
Adaboosts分类算法是Schapire和Freund在1996年提出的算法。并且,Schapire针对不同的分类问题先后提出了多种变形的Adaboost算法。该算法在训练过程中,首先为所有样本子集赋予相同的权重,并构造基分类器,且每次基分类器的构造中都会根据训练结果更新样本中的权重,从而使得迭代后的分类器能重点学习分类错误的样本,最终通过投票法得到多次迭代汇总的强分类器。
1.3 XGboost算法
XGboost是一种基于梯度提升决策树改进的算法,最大的特点是构造能并行运算的增强树。XGboost在迭代过程中同时使用一阶导数和二阶导数,并且加入正则项,通过对模型偏差和模型复杂程度之间的权衡,调整正则化系数,达到在特征选择的同时避免模型过拟合。
1.4 GBDT算法
梯度提升树(gradient boosting decision tree)算法,是由Friedman提出的一种基于boosting的算法。它是一种由多棵决策树组成的迭代算法,最终结果依据多棵树的结果。其中GBDT和Adaboost的不同之处是选择对模型调整的策略不同。
1.5 数据采样方法
对于数据不平衡问题可以通过采样方法来提高模型的效果。采样方法可分为过采样(oversampling)、欠采样(undersampling)以及过采样和欠采样结合的方法。
过采样顾名思义就是从少数样本的类别中通过采样方式获得样本,再将采样的样本添加到原数据集中。Smote方法是过采样方法的典型代表,其核心是对少数类样本通过插值法产生额外的样本用于训练。具体地,是对少数类别的样本,找到离它最近的k的样本集合S,并在两者之间的连线上,利用随机函数产生随机数合成的新样本,从而增加少数样本的数量。
欠采样的思想和过采样有相似之处,就是从多数类的样本中随机剔除一定的样本。如NearMiss算法的核心是从多数类样本中根据采样的比例仅保留最具代表性的样本用于训练。其过程是选择每个多数类样本距离最小k个少数类样本,计算两者的平均距离,保留平均距离最小的多数类样本,从而实现降采样。
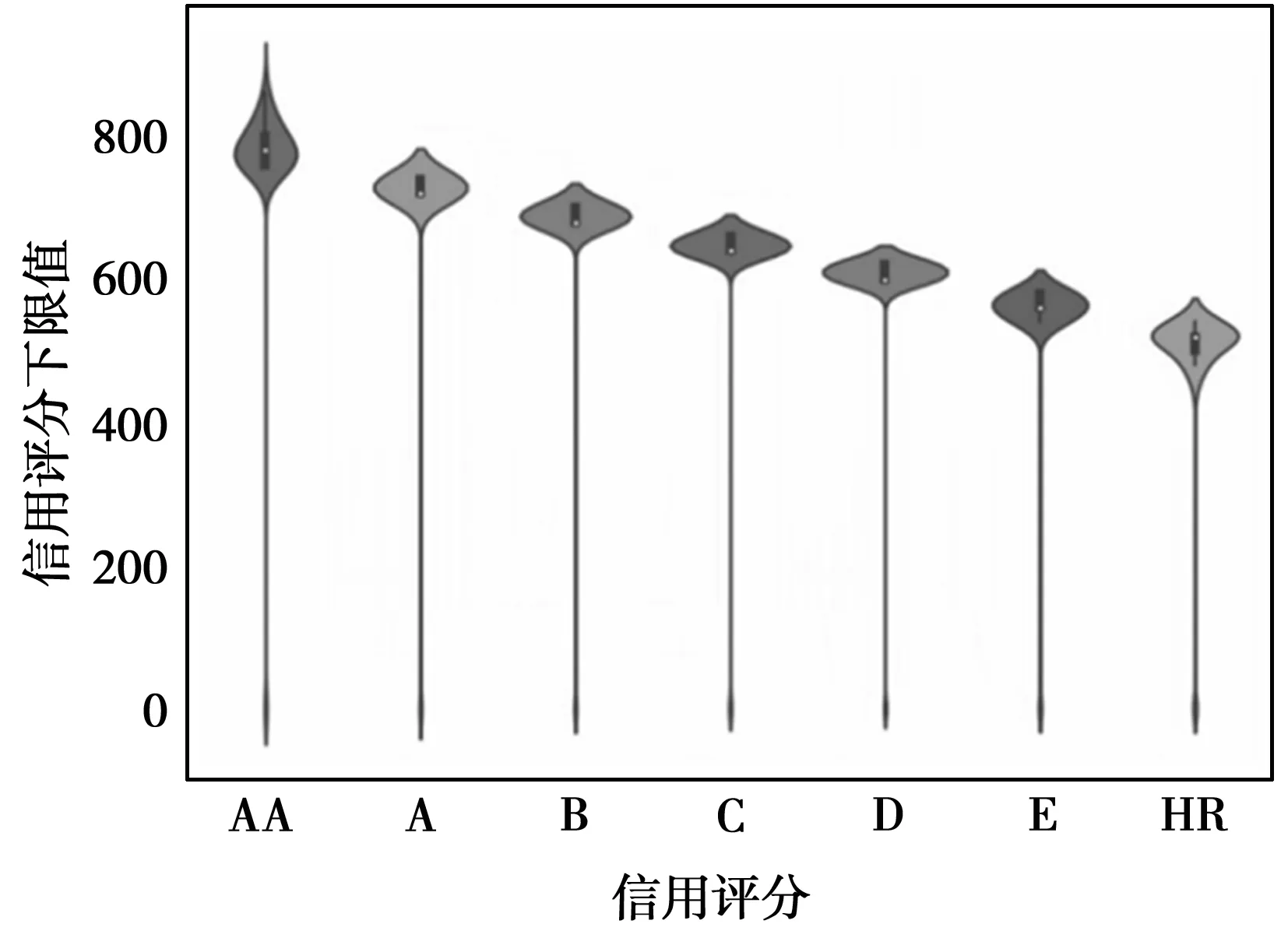
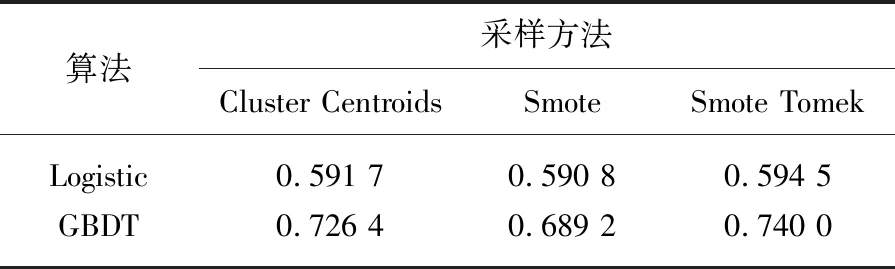
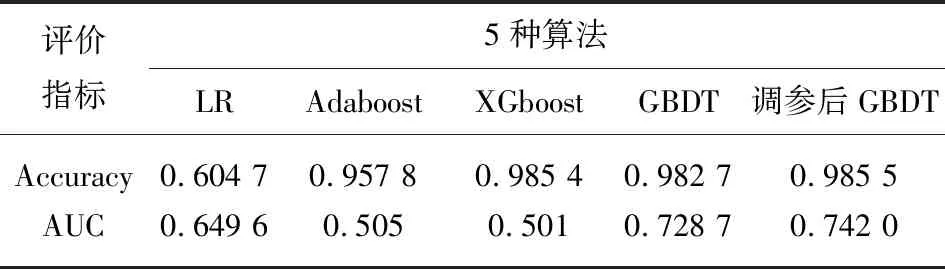
Tomek算法是由Tomek Link[7]提出的,其算法思想为:样本n和样本m来自两个不同类别,若不存在另一个样本x,使得d(n,x) 图1 Tomek Link对 对于普通分类问题可以采用正确率(Accuracy)衡量分类模型的性能。对于当前问题来说,正确率表示真实违约预测也违约,真实不违约预测也不违约,这两种样本之和与总样本的比例,比例越高表示预测正确的占比越大。 但由于研究的问题属于典型的样本类别不平衡问题,如果仅通过正确率(Accuracy)作为衡量指标,则会出现对模型错误的评估。在不平衡数据中,ROC曲线是公认的一种全面衡量分类器性能的评价准则[8]。AUC是ROC曲线下的面积,在基于ROC的标量型度量下保留了ROC的众多优点[9]。ROC曲线的横坐标为假正类率(False positive rate,FPR),即错误分类的负样本个数占负样本总数的比例,纵坐标为真正类率(True positive rate,TPR),即正确分类的正样本个数占正样本总数的比例。AUC越大代表分类器的分类性能越好,模型性能越好。 P2P网络借贷来源于P2P小额借贷,P2P小额借贷是一种将非常小额度的资金聚集起来借贷给资金需求人群的一种商业模式。P2P借贷是指不需要以银行等传统金融机构为中介,借贷双方直接通过网络平台交易的无担保借贷。借款人可以以低于银行贷款利息的方式快捷方便借到钱;放款人可以获得高于银行存款的利息。目前国内出现了宜信、拍拍贷、人人贷等网络借贷平台,国外则有Prosper、Lending Club平台。 基于以上借贷模式,文本采用Lending Club平台数据开展违约预测研究,该平台是目前美国交易量最大的P2P平台,占据美国P2P市场份额的65%,在行业内具有较强的权威性和实际意义。部分重要特征如表1所示。 表1 部分重要特征数据变量解释 经过检查数据的缺失情况,发现数据“信用评级”特征的缺失率≥70%,决定删除该特征;对于其他缺失率<70%的特征,其定量特征用均值填充,定性特征用众数填充。由于数据存在不同的量纲,所以我们采用Z-score进行标准化: 采用过采样方法往往会产生噪声数据,造成数据冗余,模型出现过拟合。而欠采样方法可能会出现一些重要的样本被错误剔除,导致模型拟合效果欠佳。因此,采用过采样和欠采样结合的方法,即SmoteTomek方法(表2)。其过程是通过Smote算法生成少数类样本,但为避免生成的数据质量差,形成数据重叠,在Smote算法之后,通过欠采样技术进行数据清洗,剔除冗余数据[10] 表2 样本数详情表 数据填充和清洗后,可以进行探索性数据分析,以查看数据可视化特征之间的关系。如图2所示,“客户月收入”越高,其“风险评分”越高。因为客户月收入的高低会直接影响其偿债能力。银行对月收入越高的客户风险评价越好。 图2 风险评分和月收入柱状图 图3反映了客户“信用等级”与“信用评分下线值”呈现正相关性。信用评分下限值是对客户偿债信誉的度量,一般由官方评级机构提供。客户的信用评分下限值越低,信用等级越低。因此,本文根据随机森林法选取前15个最重要的特征作为后续模型的输入特征。 图3 信用等级和信用评分下限小提琴图 在原始不平衡样本中,正样本占总样本的1.5%,我们采用三种采样方法,分别是欠采样(ClusterCentroids方法)、 过采样(Smote方法)和上下采样结合的方法(SmoteTomek方法),将其转变为平衡样本,即正负样本1∶1。用AUC作为衡量采样方法优劣情况的指标,如表3所示,在同一数据集上采用了三种不同采样方法,并使用了传统Logistic回归方法和GBDT机器学习方法这两种不同算法进行对比研究。结果显示,基于两种算法的采样对比实验,都展现出SmoteTomek采样法能使得模型获得更高的AUC值,即模型性能更好,计算成本更低。 表3 基于两种算法的3种采样方法AUC值 依据以上研究结果,本文提出基于SmoteTomek-GBDT违约评估方法。研究选取4种在违约评估研究中经常使用的机器学习算法:Logistic、Adaboost、XGboost、GBDT。对这四种算法,都采用通过SmoteTomek采样的相同数据集作为训练数据集。 采用网格搜索作为超参数优化的方法,对GBDT模型中的参数进行调整(调参后GBDT算法),分别是决策树数量(n_estimators)、树的最大深度(max_depth)、内部节点所需最小样本数(min_samples_split),其他参数使用sklearn库默认的数值。参数优化空间如表4所示。 表4 调参后GBDT算法的参数空间 表5 实验结果 为衡量调参后GBDT算法的性能,表5对比了上述5种算法的两个评价指标。由表5可得,调参后的GBDT有最高的AUC值和Accuracy值。调参后的GBDT比LR在模型性能方面提升14.2%,正确率方面提升62.9%;比Adaboost在模型性能方面提升46.9%,正确率方面提升2.9%;比XGboost在性能方面提升48.1%,正确率方面提升0.01%;比没有调参的GBDT在性能方面提升1.83%,正确率方面提升0.285%。综上所述,对于不平衡数据,通过调整数据采样方法(选择SmoteTomek采样法),可以使数据有更好的估计精度。这里是选择SmoteTomek采样和GBDT算法相结合的方式,通过网格搜索法进行参数调整,最终模型在模型性能和正确率方面都得到更好的提升。 文本以国外著名的prosper金融科技公司的平台数据为研究对象,运用预处理、可视化探索分析、SmoteTomek算法构建违约预测模型。基于数据的严重不平衡特征,对比三种数据采样方法,在两种不同算法下的性能表现。经过对比发现采用欠采样和过采样结合的方法能更好地避免样本不平衡给模型带来的扰动。然后基于SmoteTomk采样方法,构建了SmoteTomek-GBDT模型,经过实验对比发现,该模型较单分类器模型Logistic、多分类器模型(Adaboost、XGboost)在测试数据集有更好的估计精度。 伴随着近些年国内也陆续出现的该类借贷平台,如宜信、拍拍贷等,互联网金融市场在运作方式和监管机制上存在一定漏洞,风险管控也一直是金融市场难以避开的话题。为此,结合该现象和金融行业的发展状况,为推进互联网金融发展,提出以下三个方面的建议。 第一,加强P2P网络借贷平台的准入标准和破产清算管理,建立合理的第三方存管体系,从源头上提高P2P网贷平台的良性开端,维护金融秩序的良性发展,避免恶性竞争、卷款跑路等现象的存在。 第二,基于数据分析、大数据、人工智能科技的发展,通过网络技术建立透明的经营管理平台、智能化的运营测算体系、精确的借贷双方实时评级平台和强大的网络安全环境。对借贷平台的上中下游,通过人工智能算法等前沿技术,为互联网金融赋予良性发展的持久动力。 第三,借鉴国外监管法律制度、信息披露制度、资金存管制度,落实法律监管主体,避免权责不清;在风险披露和信息安全中寻求平衡,避免投资人、融资人和平台之间信息不对称局面;加强对平台资金存管制度的管理,避免平台出现非法经营、挪用资金或者卷款跑路等风险。加强平台的监管,使其在由内而外隔断非法经营的风险和隐患。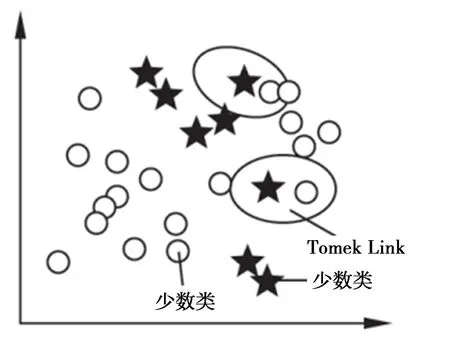
1.6 分类效果评价指标
2 数据准备
2.1 数据来源
2.2 数据预处理
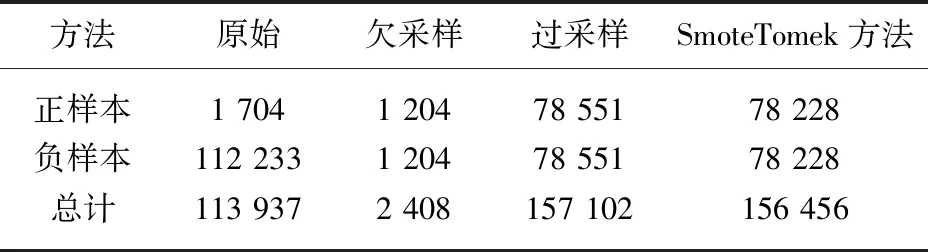
2.3 SmoteTomek方法数据采样
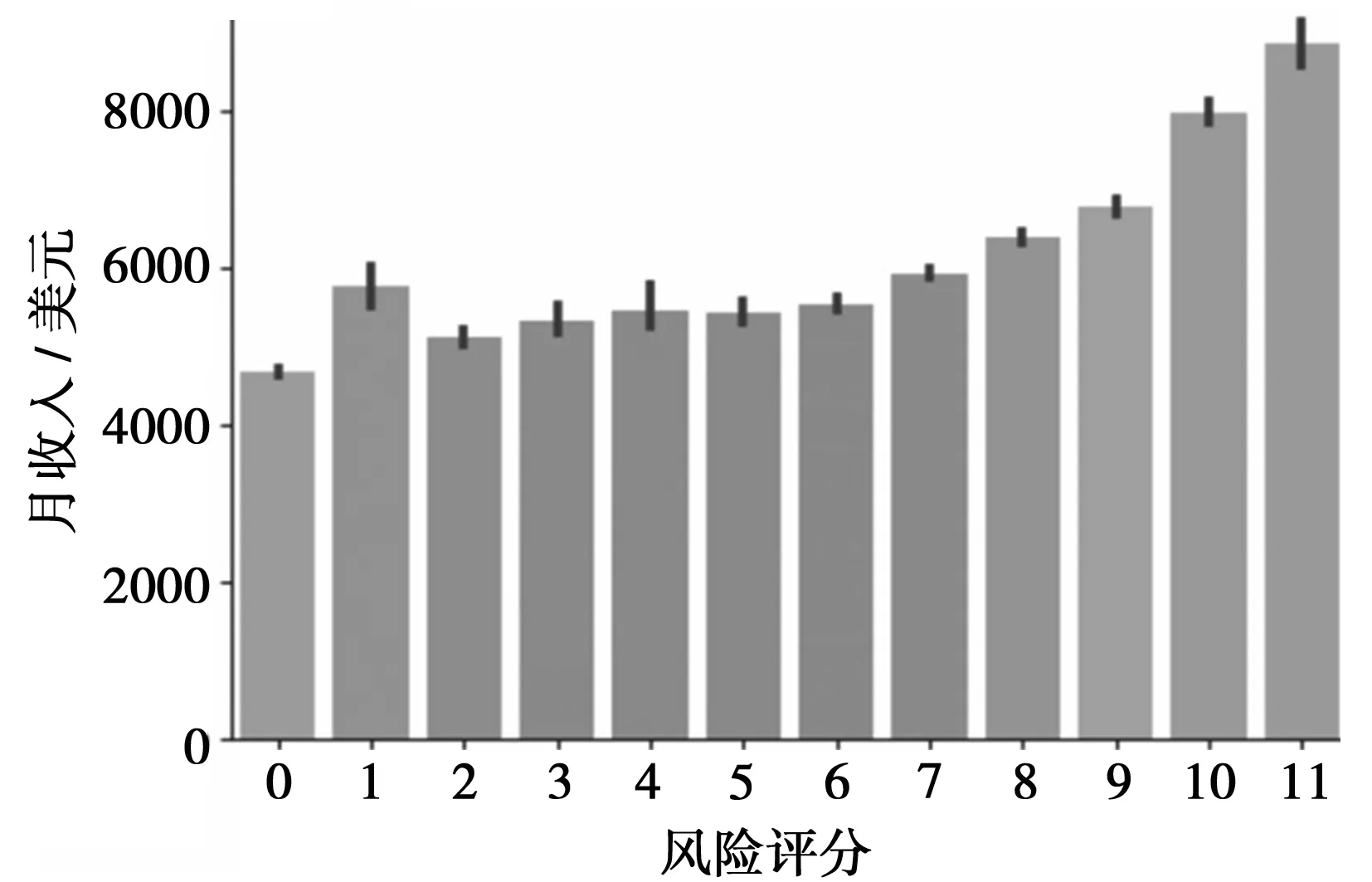
2.4 数据探索性分析与特征选择
3 实验结果及分析

4 结论与建议
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
电子产品世界(2022年4期)2022-04-21
今日农业(2021年19期)2022-01-12
计算机系统应用(2021年2期)2021-02-23
软件(2018年1期)2018-02-05
电子技术与软件工程(2017年14期)2017-09-08
领导决策信息(2017年13期)2017-06-21
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
商界(2015年9期)2015-10-15
