
基于多先验约束和一致性正则的半监督图像去雾算法
2022-10-29 03:29苏延召崔智高蔡艳平李艾华
电子与信息学报 2022年10期
苏延召 何 川 崔智高 姜 柯 蔡艳平 李艾华
(火箭军工程大学作战保障学院 西安 710025)
1 引言
在雾、霾等恶劣天气条件下,视觉传感器产生的图像将出现模糊、对比度下降等明显退化现象,进而导致目标检测、语义分割等高层视觉任务性能严重下降[1]。因此,在智能交通、无人驾驶等诸多应用领域,图像去雾不仅要提高去雾图像的视觉质量,同时还需保证高层视觉任务模型在雾霾等恶劣环境中的性能[2]。
由于雾霾图像成像过程非常复杂,研究中常采用文献[3]提出的简化物理模型对雾霾图像形成进行描述。为估计该模型参数(大气透射率和全局光照)进而得到复原图像,许多研究提出利用统计先验如暗通道、颜色衰减以及颜色线等对模型中的透射率参数进行估计[4–6]。然而由于这些先验并不适用于所有场景,因而其去雾结果容易出现过度增强、伪影、颜色偏差等现象。近年来,大量基于深度学习的去雾算法被提出。文献[7]和文献[8]分别利用边缘约束的多尺度网络和结合先验设计的网络估计大气散射模型的透射率参数,取得了较好的去雾效果。但上述方法均采用传统方法估计场景光照信息,容易出现颜色漂移等问题。Zhang等人[9]同时利用两个神经网络分别估计透射率与大气光照参数,进而获得清晰图像。由于简化模型并不能完全描述复杂雾霾场景,因此该方法容易受参数估计噪声干扰,对真实雾霾场景适应性不高。
为解决上述问题,研究人员提出直接通过端到端网络学习将雾霾图像映射为清晰图像[10]。文献[11]和文献[12]分别提出基于多尺度boosting机制和基于注意力机制融合多尺度特征的去雾模型,可直接恢复清晰结果。然而,由于没有图像退化机理模型约束,上述方法不仅需要大量合成样本进行训练,并且容易出现过拟合现象,在真实雾霾场景中性能下降明显。Su等人[13]提出利用传统先验去雾结果引导条件生成对抗网络的去雾方法,进而提升合成样本训练模型在真实场景中的去雾效果。Li等人[14]提出了同时在合成与真实雾霾图像上训练的半监督去雾算法,结果表明该方法在真实场景具有较好的去雾性能。Shao等人[15]将真实雾霾与合成雾霾图像视作不同的域进行相互转化,提出了基于领域自适应的图像去雾算法。Chen等人[16]利用多种先验知识作为约束条件,对合成样本上训练的去雾模型进行迁移学习,有效提高了真实场景去雾结果的视觉质量以及高层视觉任务性能。
受上述方法启发,本文提出基于多先验约束和一致性正则的半监督图像去雾算法。与文献[14]不同,本文采用多种局部正确的先验去雾结果作为监督约束,能够更好地恢复出场景结构信息;与文献[15]不同,本文无需针对不同雾霾场景进行领域适应,并且取得更好的结果;与文献[16]不同,本文进一步利用多雾霾图像及多先验去雾随机增强对局部正确去雾结果进行一致性约束,较好地克服了先验去雾结果差异以及所含噪声的干扰,并且同样可以适应多种已有端到端的去雾网络结构。
2 本文算法
2.1 算法原理
本文提出的基于多先验约束和一致性正则的半监督图像去雾算法,其总体框架如图1所示。


图1 本文算法总体框架示意图

2.2 去雾网络结构
在许多图像增强与复原研究中,编码器-解码器网络是最为常见的一种形式[17,18]。受文献[19]启发,本文在去雾网络结构设计上采用基本的编码器-残差-解码器结构,具体设计如表1所示。在编码器部分,有雾图像首先通过由一个卷积核大小为7,步长为1的卷积模块进行初始特征提取,然后再利用3个连续下采样卷积块(卷积核大小为4,步长为2)将图像特征分辨率减小为原来的1/8。为增强去雾网络的特征表征能力,本文采用连续16个残差块作为特征变换模块以学习雾霾特征与清晰图像特征之间的变换关系。解码器与编码器在结构上保持对称,在对解码器特征进行2倍上采样(除去最后一个卷积层)后通过跳连接与编码器特征相连,然后再通过两个3×3卷积对叠加特征进行处理,进而逐步恢复出清晰图像。

表1 本文图像去雾网络结构详细设计表(数字表示图像序号)
2.3 合成雾霾图像去雾
通过合成雾霾图像能够学习雾霾图像与清晰图像之间的映射函数。以JS表示真实场景清晰图像,IS表示合成雾霾图像,fθ(·)表示去雾网络,则利用合成雾霾图像对fθ(·)进行训练,可将输出结果与真实图像之间的偏差表示为

其中,φ(·)表示损失函数。常用的图像处理损失函数包括L1, L2损失,但这两种类型损失将每个像素视为独立变量,并没有充分考虑图像的局部相似性。因此,本文采用负结构相似性函数(Structural SIMilarity, SSIM)[20]作为损失函数,φ(·)可表示为式(2):
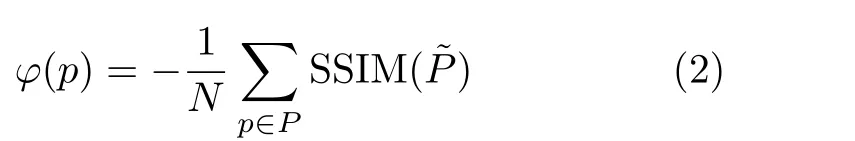
其中,N表示图像总像素,SSIM(P˜)表示区域P的结构相似性指标,P˜表示该区域的中心点。通过计算损失函数值,并将梯度反传进而对fθ(·)的参数θ进行更新。
2.4 真实雾霾图像去雾
由于合成雾霾图像与真实雾霾图像之间存在较大差异,且真实雾霾图像缺乏像素级对应的参考真值,难以直接进行监督学习。为此本文引入多种先验去雾结果对真实场景进行监督,并通过多张真实雾霾图像随机混合与多先验混合输出的一致性对多种先验知识的差异与缺陷进行正则,以提高真实场景去雾效果。
2.4.1 多先验去雾结果监督
传统去雾方法虽然不适用于所有场景,但具有较好的泛化应用能力。如图2所示,传统先验去雾结果在一定程度上已经能够恢复出真实雾霾场景的结构信息,但不同先验知识的侧重点不同,其恢复结果也存在明显差异。


图2 不同先验去雾方法处理结果对比

2.4.2 混合雾霾图像一致性正则

2.5 总体损失函数
由于本文方法通过参数共享的方式,同时对合成样本与真实雾霾图像进行训练,因此网络训练时其总体损失函数包括合成样本的监督损失、真实雾霾图像的半监督损失以及一致性损失3部分,具体如式(6)所示。

3 实验结果与分析
3.1 实验设置
为有效验证所提方法,本文从广泛使用的图像去雾训练数据集RESIDE[26]中随机抽取合成雾霾图像以及真实场景的雾霾图像对去雾网络进行训练。RESIDE数据集中包括了室内与室外的合成数据集(ITS和OTS)以及真实雾霾图像数据集(URHI),具体训练时本文分别从ITS和OTS中各抽取1000对合成样本,从URHI中抽取2000张真实雾霾图像。同时,对于真实雾霾图像以文献[21](简写为BDCP)和文献[22](简写为NLD)的两种先验去雾方法为例,对其进行去雾,从而得到4000对真实雾霾图像训练样本。
网络训练时采用Adam优化器进行优化,初始学习率为0.0002,每隔5轮训练进行线性衰减,总计训练30轮。每次训练时输入合成样本、真实样本以及混合真实样本,相当于样本批量大小为4。总体损失函数中的权重超参数λ1,λ2,λ3根据经验分别设置为1, 0.4, 0.4。
算法测试时,本文分别选取RESIDE中的SOTS、合成数据集HAZERD[27]、真实场景的IHAZE[28], OHAZE[29], BeDDE数据集[30]以及部分传统真实雾霾场景对图像去雾效果进行验证,并与现有代表性算法BDCP[21],NLD[22], MSBDN[12],SED[14], DAAD[15], PSD[16]进行对比分析。此外,为进一步验证图像去雾对高层视觉任务性能提升能力,本文还在RESIDE的RTTS数据集上进行目标检测任务性能测试。实验对比分析时,对图像去雾结果评价采用常见的SSIM, PSNR(Peak Signal to Noise Ratio)以及文献[30]提出的VI(Visibility Index),RI(Realness Index)指标进行分析,而目标检测任务则采用平均准确率(Average Precision,AP)和总体平均准确率(mean of Average Precision,mAP)指标进行结果对比。最后,在HAZERD和RTTS数据集上对算法的不同关键部件设计进行消融实验验证。
3.2 实验结果
3.2.1 图像去雾实验
(1)定性实验结果
图3和图4分别显示了本文算法在合成数据集及真实场景中与现有代表性算法的定性实验对比结果。

图3 本文方法与现有代表性方法在合成数据集上的去雾处理结果对比

图4 本文方法与现有代表性方法在真实场景中的去雾处理结果对比
从图3可以看到传统先验去雾方法存在过度增强或去雾不充分的问题,如图3(a)中BDCP方法结果在地面出现明显的颜色偏差,而图3(b)中传统方法在柜子以及墙体等位置均出现了明显的颜色失真。基于深度学习的方法在大量数据驱动下能够较好地恢复室内图像如图3(a)和图3(b)中MSBDN和DAAD的处理结果。相比较于侧重解决真实雾霾场景的SED, PSD等方法,本文方法能够得到视觉质量更好的去雾图像。在室外场景的去雾结果中,传统方法能够更好地处理场景中远处雾霾比较严重的区域,但其去雾结果在色调和亮度等方面出现了明显偏差(如图3(c)和图3(d)所示)。MSBDN方法对场景中雾比较浓的区域复原效果不佳,存在明显的雾霾残留。引入真实雾霾图像作为训练样本SED, DAAD以及PSD方法具有一定的远景区域去雾能力,但其去雾结果仍然存在较多雾霾残留(如图3(d)所示)。相比之下,本文方法能够有效去除参考图像中存在的部分雾霾(如图3(c)所示),并且在亮度、色调等方面没有明显偏差。图3(e)和图3(f)展示了7种去雾方法在合成数据集HazeRD中的去雾结果。从结果中可以发现,传统方法能够适应多种雾霾场景,但其突出问题仍然是容易过度增强,如图3(f)中NLD去雾结果。如图3(e)所示,除了PSD方法外,本文方法与MSBDN, SED, DAAD方法均取得了较好的去雾效果(如场景中的草地部分,色差相对较小)。图3(f)中测试图像的雾霾程度比较严重,导致SED算法去雾结果存在明显的雾霾残留和伪影区域,本文方法与DAAD方法对高楼附近的雾霾区域具有一定的复原能力,能够提升其清晰度。综合对比分析,本文方法能够减少传统方法过度去雾的影响,并且能够泛化到不同合成场景。
图4为不同方法在真实场景中的图像去雾结果对比示意。从图中可以发现传统方法BDCP和NLD虽然能够恢复场景结构信息,但其去雾图像呈现明显的过度增强。如图4(a)—图4(f)所示,BDCP方法其去雾图像整体偏亮,而NLD方法的去雾结果则相对较暗。相比之下,MSBDN方法在真实场景中其去雾图像存在明显残留,如图4(b)中树林区域和图4(f)中远景区。SED方法利用了先验知识与真实场景数据进行训练,其去雾结果明显好于MSBDN。但如图4(a)、图4(b)所示,由于暗通道先验的约束会导致图像整体偏暗,在树林局部区域以及火车头附近其亮度存在明显区别,此外在图中还可以发现较多的雾霾残留。DAAD方法和PSD方法的去雾结果相对比较自然。与PSD方法相比,DAAD方法去雾相对比较彻底,但面对不同真实场景时,部分结果(如图4(c)和图4(d)所示)也出现了明显的颜色漂移。不同于上述方法,本文方法的去雾结果在视觉效果上更贴近于真实场景,去雾效果明显优于其他方法,说明本文方法能够较好克服局部正确先验去雾结果存在的不足与多种先验知识之间差异,并且能够较好地泛化到不同的真实雾霾场景。
(2)定量实验结果
为了进一步对所提算法性能进行验证,本文分别在合成数据集与真实场景雾霾图像数据集上进行了定量实验对比分析。表2为不同方法在合成与真实图像数据上的定量对比结果,其中所选择的评价指标值越大,说明去雾图像质量越好。
从表2可以看到,在合成数据集SOTS上,总体性能最好的是深度学习算法MSBDN,本文方法排在第3位,与基于领域适应的DAAD方法和半监督方法SED基本相当。其主要原因在于MSBDN方法采用了大量成对合成样本进行训练,并且对网络结构进行精心设计,而本文方法只使用了2000对合成样本与4000对真实场景雾霾图像对常规的编码器与解码器网络进行优化训练。但在合成数据集HAZERD上,本文方法的SSIM指标最优,PSNR指标排名第2。与MSBDN, PSD, BDCP, NLD等方法相比,本文方法具有更好的泛化能力。对于IHAZE, OHAZE以及BeDDE等真实场景雾霾测试数据,本文方法同样在VI, SSIM等指标上优于MSBDN, PSD以及SED方法,与典型代表算法DAAD基本相当,但本文方法在VI以及SSIM指标上略微优于DAAD。上述定量分析结果进一步验证了本文方法对真实雾霾场景的有效性。

表2 图像去雾定量实验结果对比(红色表示第1,绿色表示第2,蓝色表示第3)
3.2.2 雾霾图像目标检测实验
本文在图像去雾视觉质量实验对比的基础上,进一步分析对比了7种去雾方法对雾霾图像目标检测任务性能的提升能力。参照文献[16]和文献[14],本文采用YOLO V3[31]作为目标检测器,在RTTS数据集上将7种去雾方法处理之后的图像送入目标检测器,并对人(person)、自行车(bicycle)、摩托车(motorbike)、小汽车(car)以及公交车(bus)5类目标的检测精度进行对比,其结果如表3所示。
从表3结果可以看到,传统方法对图像进行去雾之后,其目标检测结果准确率反而低于未进行去雾的检测结果,其可能原因是传统方法通常会过度增强雾霾图像,在提升视觉质量的同时也放大了噪声,甚至破坏了图像的局部空间结构。基于深度学习的去雾方法通常能够提升目标检测准确率,但从表3可以看到提升的比例并不高,单纯基于数据驱动的MSBDN方法仅能提升0.27%。在所有方法中,本文方法对目标检测准确率的提升最为明显,达到1.28%,PSD方法排名第2,能够提升0.69%。综合前文结果可以发现,虽然PSD方法的视觉质量定量指标不高,但对于目标检测任务却有较好提升,超过了DAAD与SED方法,说明对于高层视觉任务图像的视觉质量不一定是影响其性能的关键。
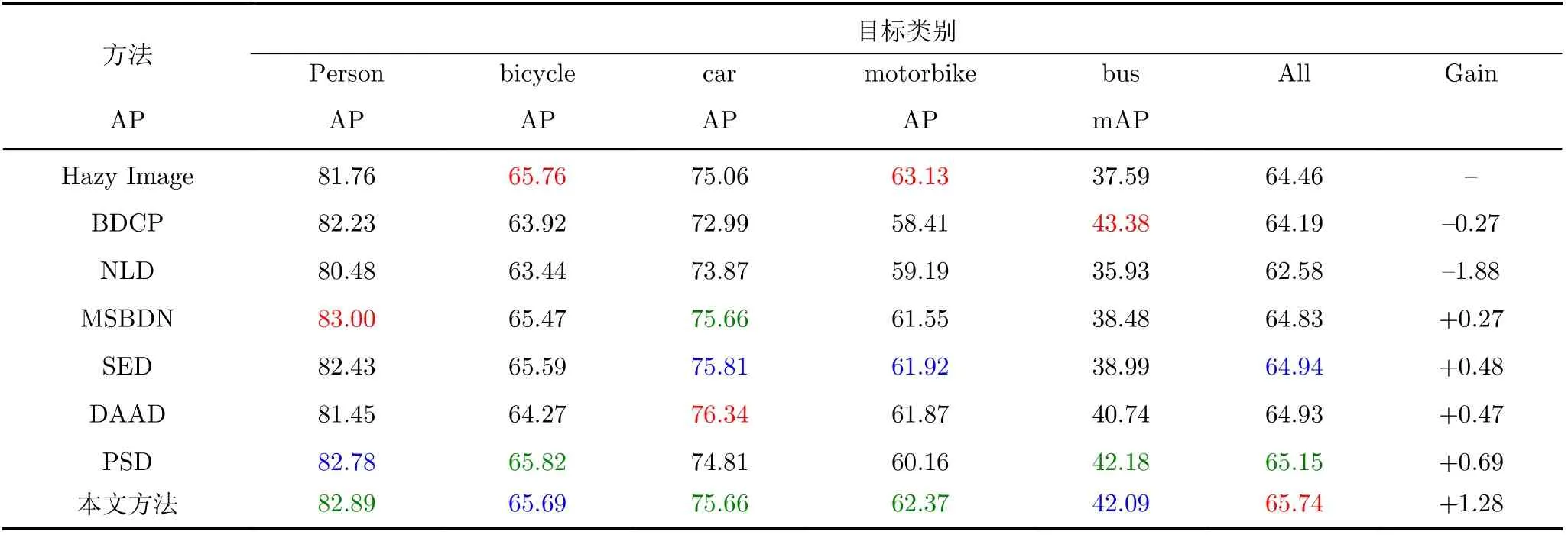
表3 雾霾图像目标检测实验结果对比(红色表示第1,绿色表示第2,蓝色表示第3)
3.2.3 消融实验
为了充分说明设计提出方法的有效性,本文在BeDDE和RTTS两个真实数据集上分别对不同的变体方法进行图像增强以及雾霾场景目标检测消融实验分析。实验对比包括一个基准去雾网络和4类变体:(1)基准方法:利用表1的去雾网络作为基准进行监督学习,即不利用真实场景雾霾图像进行训练;(2)变体1:在基准方法基础上结合真实雾霾图像进行半监督学习,但不引入先验去雾结果,只是通过真实图像去雾随机拼接进行一致性约束;(3)变体2:在变体1的基础上,引入一种先验去雾结果(如文献[21])进行监督,同时保留一致性约束;(4)变体3:变体2的基础上将先验去雾方法替换为文献[22]的方法;(5)变体4:在变体3的基础上进一步引入两种先验去雾结果进行监督,不采用一致性正则;(6)按照本文所提方法进行训练。消融实验结果如表4所示。从表中结果可以看到,变体1能够提升去雾网络的泛化性能以及目标检测任务性能,表明加入真实场景雾霾图像进行一致性正则训练对去雾有益。变体2和变体3的实验结果表明,引入先验去雾图像作为监督标签后,对比原始先验去雾结果不论在图像视觉质量还是对于高层视觉任务提升上均有提高,说明结合数据学习与先验知识进行去雾能够取得更好的去雾效果。在此基础上,变体4的结果表明通过结合两种先验去雾方法能够进一步增强图像去雾性能,说明通过数据驱动能够自动从多种先验去雾结果学习其共性特征,从而更好地适应真实去雾场景。本文方法在变体4的基础上进一步利用一致性约束方式对两种先验之间的差异进行正则,增强了去雾模型训练的稳定性,并能够微弱提升去雾网络的性能。

表4 消融实验结果对比
3.2.4 其他场景去雾霾测试
本文方法虽然在城市场景中进行训练,但对于其他图像退化场景如水下雾霾图像以及沙尘天气不加微调也能进行增强,得到视觉效果较好的清晰图像,其结果如图5所示[32]。从图5可以看到,本文方法能够较好地克服水下以及沙尘天气的退化图像导致的模糊、对比度下降等问题,但从结果中也可以看出,对于水下以及沙尘天气导致的颜色偏差,本文方法无法有效恢复出对应的清晰颜色。因此对于特殊的退化场景还需要针对性建模和训练,从而消除恶劣环境导致的颜色差异。

图5 本文方法在其他场景去雾霾结果
3.2.5 算法运行时间分析
本文通过统一的测试环境对5种基于深度学习的去雾方法的运行时间进行验证分析。测试采用SOTS 500张室内图像去雾,以其平均时间作为每种去雾方法的运行时间。测试对比结果如表5所示,从表中可以看到本文算法运行时间低于MSBDN,PSD以及DAAD 3种代表性算法,对于620×460大小的图片处理时间约为0.028 s,且本文所提算法性能与上述方法基本相当,因而从整体上看本文所提方法在实际应用中具有一定优势。

表5 5种去雾方法运行时间对比(s)
4 结论
本文以提升真实雾霾场景中的图像去雾及高层视觉任务性能为目标,提出了一种基于多先验约束和一致性正则的半监督图像去雾算法。本文方法的主要贡献如下:(1)提出利用去雾网络参数共享的方式分别对合成图像与真实雾霾图像进行训练,并通过多种先验去雾结果与一致性正则增强了网络对真实雾霾图像的去雾效果;(2)提出一种利用局部正确的多先验去雾结果半监督方法,通过数据驱动的方式自动学习多种先验去雾的共性优点,从而较好地恢复雾霾图像的结构信息,增强去雾模型在真实场景中的泛化能力;(3)提出一种基于随机混合增强的一致性正则方法,能够消除多种先验去雾结果的偏差以及去雾噪声的影响,提升图像去雾质量。实验结果表明,本文方法能够有效提高真实场景图像去雾视觉效果以及高层视觉任务性能,具有较强的泛化能力。后续还将进一步研究将图像去雾作为高层视觉任务的预处理步骤,其增强结果对高层视觉任务提升不明显的问题,以解决恶劣天气条件下通用视觉模型应用瓶颈。
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
汽车实用技术(2022年9期)2022-05-20
教学考试(高考物理)(2021年5期)2021-11-08
客联(2021年9期)2021-11-07
历史教学问题(2021年4期)2021-11-05
海外文摘·艺术(2020年22期)2020-11-18
矿山测量(2020年2期)2020-05-17
小型微型计算机系统(2018年6期)2018-07-04
计算机系统应用(2017年10期)2017-10-20
北京航空航天大学学报(2017年10期)2017-04-20
