
基于调频连续波雷达的多维信息特征融合人体姿势识别方法
2022-10-29 03:36冯心欣李文龙郑海峰
电子与信息学报 2022年10期
冯心欣 李文龙 何 兆 郑海峰
(福州大学物理与信息工程学院 福建省媒体信息智能处理与无线传输重点实验室 福州 350108)
1 引言
在人机交互的发展过程当中,人体姿势识别是其中关键技术之一[1]。人体姿势识别技术在智能家居、运动分析、游戏娱乐等各类范畴均有运用[2]。
基于视觉的姿势识别技术发展成熟[3–6],但是图像质量易受环境光照干扰,且目标在被障碍物或者其他对象所遮挡等不利条件下识别率相对较低。更重要的是,基于视觉的人体姿势识别需要采集用户的图像信息,存在暴露用户信息、泄露用户隐私等安全隐患。基于无线感知技术的姿势识别方法是指通过电波、磁声波等普适无线信号对人和环境进行非接触式感知的技术,是目前应用前沿的一种人体姿势识别技术[7]。由于无线信号的特性,该方法可以有效克服图像的光照、障碍物干扰等因素的影响。而调频连续波技术因其测距范围广、测量准确率高等特点而受到广泛的关注[8]。文献[9]介绍了调频连续波(Frequency Modulated Continuous Wave, FMCW)雷达目标角度、速度和距离估计的原理与方法。文献[10]通过对FMCW雷达信息进行时频分析得到手势目标的距离、多普勒及角度多维参数,使用卷积神经网络及特征串联融合方法进行手势识别。文献[11]通过将毫米波雷达的2维数据时间-范围、时间-多普勒和距离-多普勒特征联合拓展为3维数据模型然后进行人体运动的识别。文献[12]提出利用图像训练一个教师网络来指导FMCW信号生成人体关节点热图以进行人体姿势的识别。文献[13]提出了利用射频信号进行3D人体姿势估计的方法,该方法利用了射频信号对人体的各个部位进行跟踪和定位,再结合神经网络的方法来进行人体姿势识别。多模态研究是人工智能的一个新兴领域,多模态数据融合是该领域的主要研究问题之一。多模态数据融合是将多个单模态表示整合为一个紧凑的多模态表示的过程[14]。文献[15]使用级联特征作为输入,并组合特征联合模型,从而消除了模态中存在的时间依赖性,实现多模态情感分析任务。文献[16]为每个单模态特征建立单独的模型,然后使用多数投票或加权平均等方法将输出整合在一起进行最终的决策。为了充分考虑每个模态内部的信息和跨模态之间的相互作用关系,文献[17]利用张量的表示方式,基于张量外积对多模态特征进行融合,充分利用多模态特征之间的相关性。文献[18]在文献[17]的基础上,引入张量分解的概念,进一步提出了低秩多模态融合网络,以减少网络大量参数。文献[19]结合对抗网络概念提出域对抗神经网络(Domain-Adversarial Neural Network, DANN),通过让网络学习到的特征具有域不变性,达到域自适应的效果,让网络适应不同环境下的数据。
然而,现有的基于FMCW雷达信号对人体姿势的感知方法存在以下问题。第一,对多维信息的利用不够充分,只是进行了简单的拼接融合或者维度拓展;第二,由于实际应用中,背景环境是复杂多变的,但这些方法并未考虑到实际环境的多样复杂性对系统性能的影响。针对以上工作和问题,本文提出一种基于多维信息融合的FMCW雷达人体姿势识别方法,本方法使用3维快速傅里叶变换、具有噪声的基于密度的聚类算法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)及Hampel滤波算法对FMCW雷达信号进行分析得到有效的多维信息,然后通过低秩多模态融合网络对多维信息进行融合,并结合对抗网络的概念使用域鉴别器进一步获得与环境无关的特征,最终通过分类器获得分类结果。本文方法由于对融合网络和域鉴别器的设计,在保证识别精度的同时,实现了对环境的强鲁棒性。
2 系统算法
本文提出基于多维信息特征融合的FMCW雷达人体姿势识别系统,主要包括FMCW雷达数据处理、数据集构建及深度学习模型设计部分。首先,根据FMCW雷达原理对原始数据进行快速傅里叶变换得到距离、速度及角度参数。其次,利用DBSCAN聚类、Hampel滤波以及线性插值的方法获取最终的数据集。最后,搭建深度学习模型框架进行姿势识别。
2.1 FMCW雷达数据处理
FMCW雷达是一种调频连续波雷达,它传输一种频率随时间递增的信号。FMCW信号经过目标反射回来后与发射的信号进行混合,得到的信号称为中频信号。FMCW雷达在某个时间点采集到的回波信号,经过数字信号采样后变成数字信号。采样后的数据形状是一个2维矩阵,分别为快时间维度和慢时间维度,采样的数据点对应快时间维度,慢时间维度对应时间。对于多接收天线雷达,采样后的数据可以排列成一个3维矩阵,即采样点数、调频脉冲数以及接收天线数。
在快时间维度对数据进行快速傅里叶变换(Fast Fourier Transform, FFT),并且为了防止频谱泄漏,需要对每一列数据添加海明窗,得到距离-FFT图。然后在慢时间维度上每一行做采样点数的快速傅里叶变换,得到距离-多普勒图。将距离-多普勒图中位于不同接收天线但索引相同的值取出并进行补零,然后进行180点的快速傅里叶变换处理,得到角度-FFT图,从而构建成3维的距离-多普勒-角度图,其中3个维度分别对应距离、速度及角度。
3维快速傅里叶变换将数据从时域变换到频域,然后通过峰值搜索检测出峰值位置(x,y,z),其中x对应距离维,y对应速度维,z对应角度维。当物体运动时,回波信号和发射信号之间有时延τ,而回波时延可以通过差拍频率fb得到,这是因为差拍频率与回波时延呈线性关系。但由于物体的运动,差拍频率包含了多普勒频移,测距时需要减去多普勒频移fd,差拍频率为
其中,fs是采样频率,NRFFT是距离维度的FFT点数。多普勒频率为
其中, c为光速,k是调频连续波信号频率随时间的变化率,λ是雷达初始频率波长,L是接收天线间的 距离。
2.2 数据集构建
雷达探测到的距离及角度信息是相对于雷达而言的,因此经过简单的坐标变换可以获得目标以雷达为原点的位置坐标信息。在实际环境中,雷达所探测到的信息不仅包含雷达前方有效的目标姿势信息,同时也包含了雷达前方的各种无效的静态或动态目标信息。DBSCAN聚类算法将聚类定义为高密度的连续区域,能够将数据中不同类型的数据聚类成不同形态的簇[20]。由于人体运动的轨迹具有一定的连续性和规律性,在同一场景中,不同目标在执行动作时所产生的运动轨迹具有不同的密度区域,因此通过DBSCAN聚类算法能够将雷达探测到的所有目标的位置坐标信息根据密度的差异聚类成不同形态的簇,从而去除无关目标的轨迹信息,保留所需的人体目标运动信息,进而保留对应的距离、速度及角度参数。
本文以50帧数据为观测时长,在时间上分别对距离、速度和角度参数进行积累,从而得到距离-时间图(Distance-Time Map, DTM)、速度-时间图(Velocity-Time Map, VTM)以及角度-时间图的数据集。但由于硬件噪声的原因,不同的数据集中可能存在异常点,本文采用Hampel滤波排除异常点。Hampel滤波是指将信号中特定的信号点滤除出去,从而抑制干扰,即对于数据集中的每个样本,选取该样本的左右各3个样本组成窗口,同时求出这6个样本的中值,确定窗口中的值与中值的偏差,并且将偏差的中值乘以用户定义的阈值,然后根据该值判断样本点是否离群。如果窗口中的某个样本为离群值,则用样本中值替换掉该样本的值。
在进行数据处理的过程中可能导致原本数据样本的丢失,从而导致数据缺乏完整性。考虑到FMCW雷达在实际测量的过程中每一帧的时间极为短暂并且人体目标的运动速度比较均匀,因此,可以采用数据重构的方式进行线性插值,即以丢失时刻的前一未丢失时刻的值代替丢失时刻的值。
由于人体在执行动作的过程中,人体的运动幅度比较大,从而导致了角度-时间数据集效果不佳。所以在本文主要采用DTM数据集和VTM数据集。DTM数据集与VTM数据集存在很大的差异,为了使深度学习模型更快收敛,对数据集采取归一化处理
2.3 深度学习模块
本文提出一种多维参数域自适应网络(Distance-Velocity-Environment-Independent-Net, DV-EINet),对DTM和VTM数据进行融合并提取出与环境无关的特征,从而对环境噪声进行消除。该网络由4个部分组成:特征提取器、特征融合器、活动识别器和域鉴别器,如图1。
2.3.1 模型输入
本文模型的输入使用的是不同环境下采集的人体姿势数据。将数据分为源域数据和目标域数据两部分,其中源域数据是有姿势标签的姿势数据,而目标域数据是无姿势标签的姿势数据,并且每一个数据均有其相应的环境标签,具体的实验数据配置可见本文3.1节的描述。模型的输出为目标域数据的预测姿势标签。
2.3.2 特征提取器
本文使用卷积神经网络提取每个分支网络的特征,由于DTM和VTM描述的是目标的距离和速度的变化信息,相对于正常光学图像有效信息占比较少,使用两个2D卷积层和1个池化层对DTM和VTM进行特征提取。假设各个分支网络的输出分别为ZDTM和ZVTM。卷积神经网络(Convolutional Neural Network, CNN)的参数集为λDTM和λVTM,输入数据集为XDTM和XVTM,则提取的特征可以表示为
2.3.3 特征融合器
为了更好地利用多维度特征之间的各种相互关系,可以借助张量的表示方法,通过创建高阶张量来捕捉各个特征所包含的信息,但高阶张量构建将带来更大的计算成本。因此,本文采用低秩多模态融合网络(Low-rank Multimodal Fusion network,LMF)[18],如图2所示,该网络通过张量分解提出低阶的张量融合网络,减少计算成本。
2.3.4 活动识别器
活动识别器由两个全连接层组成,使用softmax层获取特征提取器的概率。对于已标记的数据,可以使用交叉熵函数Ly来计算预测结果与事实之间的损失
2.3.5 域鉴别器
在本文中主要考虑不同环境下人体姿势的识别,由于在不同的环境下采集到的数据具有一定差异性,且这些差异性都与特定的环境因素有关,以至于特征提取器所提取的特征也包含了与特定环境相关的特征,因此需要对特征进一步消除环境干扰。
3 实验分析与讨论
3.1 实验数据
本实验使用的FMCW雷达是德州仪器(Texas Instruments, TI)公司的IWR1642BOOST毫米波雷达开发板。实验使用了4个接收天线以及2个发射天线,FMCW雷达的参数设置为数据帧长为50帧,每帧调频脉冲数为128,每个脉冲的采样点数为64,工作频率范围在77~78 GHz,带宽约为1.50 GHz。为了体现环境的复杂性,实验数据在4种不同的环境下进行采集,包括了走廊、会议室、实验室及空旷的房间。本实验一共邀请了4名实验者(2男2女)在4种环境下实施站立、坐下、行走以及挥拳这4种姿势,每一种姿势在每一个环境下都采集了100个样本。实验共收集了8组人——环境相对应的姿势数据集,对应于8个不同的域。将这8组姿势数据集中的4组划分为源域数据(包含2个实验者在2个环境下采集的有姿势标签的数据),4组划分为目标域数据(包含2个实验者在2个环境下采集的无姿势标签的数据),并规定源域和目标域数据的环境是不同的,最终共得到800个源域数据样本和800个目标域数据样本。
3.2 实验平台
本文的实验平台框架如图3所示,主要由FMCW毫米波雷达、PC端、边缘计算平台所构成。FMCW毫米波雷达用于姿势数据的采集;PC端对采集到的数据使用算法进行处理并生成DTM和VTM数据,生成的数据通过局域网实时传送给边缘计算平台;边缘计算平台使用深度学习网络模型进行姿势识别。本文使用Jetson Nano作为边缘计算平台,该边缘计算平台上搭载的是预先离线训练好的深度学习网络模型,本文后续的实验均是基于该实验平台所实现的。
3.3 数据处理实验结果与分析
为了验证DBSCAN聚类、Hampel滤波和线性插值对数据的处理效果,在有无关人员走动的实际环境下进行数据的采集工作。比如实验者在执行向雷达靠近的行走动作时,实验者后面有无关的人员走过。在聚类实验中,DBSCAN的实验效果如图4。
其中,紫色是干扰的行走人员轨迹,绿色是实验所需的行走数据,黑色是其他静态物体信息。从图4可以看出即使在有人员干扰的情况下,使用DBSCAN聚类算法可以保留所需的人体姿势数据并消除分散的噪声点。聚类主要去除的无关静态和动态物体干扰,实验数据处理过程中有可能产生的数据丢失和数据异常仍然存在,本文使用Hampel滤波去除距离-时间和速度-时间图中残留的干扰噪声,处理结果如图5所示。
从图5可以看出Hampel滤波有效去除了信号的跳跃噪声点,从而获得更加平滑的数据,而线性插值对数据进行了重构,使得距离-时间和速度-时间图数据更加完整。
在经过数据处理后,最终得到的人体姿势数据DTM和VTM图以及对应数据在Jetson Nano边缘计算平台上的识别结果如图6所示。
3.4 深度学习网络实验结果与分析
为了验证多维参数数据集相比于单参数数据集的优势,设计一个单参数DV-EI-Net网络,即将多维参数DV-EI-Net网络的输入改为单输入,删除特征融合器,输入经过特征提取器后直接进入活动识别器和域鉴别器。单参数DV-EI-Net网络的具体配置为:特征提取器包含2层卷积层,将卷积核大小设置为5×5,每个卷积层后都有一个激活函数及最大池化层,且池化层大小为2×2;活动识别器和域鉴别器都包含2层全连接层,最后都是使用Softmax层获取活动和域的概率向量。表1给出了单参数网络分别在DTM和VTM数据集上进行单独训练后的识别精度。在总体情况下,对于在VTM数据集上的精度要比DTM数据集高3.5%~4.5%,这说明速度信息相比于距离信息而言,对于人体姿势的表征能力要更好。
将DTM和VTM数据集加载到多维参数DV-EI-Net网络。其中多维参数网络DV-EI-Net的网络配置与单参数网络一样,但该网络的输入是多维参数数据集DTM和VTM。在测试数据集上对多维参数DVEI-Net网络进行测试,得到表2所示的姿势识别混淆矩阵。为了验证多维参数的融合方法对网络性能的提升,本文使用简单串联特征融合方法FADD=[ZDTM,ZVTM]T与LMF融合方法进行比较,通过表3和表1可知,基于多维数据融合的方法明显比单参数网络的精度来的高,这说明充分融合多维数据能够带来更多的潜在信息。而基于LMF的融合方法比串联特征融合方法精度要高4%左右,这表明基于LMF特征融合方法挖掘到了更多的多维参数特征之间的相互关系。从表3还可知,在有域鉴别器的情况下,基于串联融合方式的精度提升了2.5%,而基于LMF融合方式的精度可达91.5%,相比于无域鉴别器的情况提升了5%,这说明域鉴别器的存在可以有效消除复杂环境的干扰,从而获得了与环境无关的特征,进一步提升了系统精度。
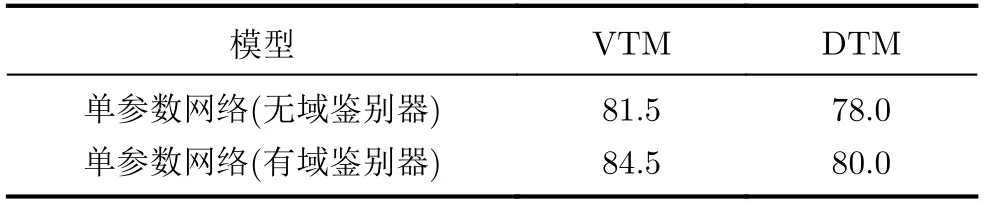
表1 DV-EI-Net单参数网络目标域分类精度(%)
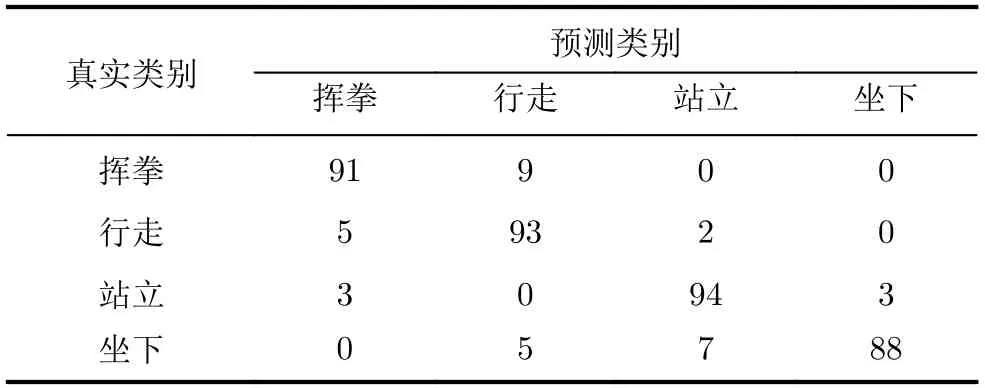
表2 姿势分类混淆矩阵(%)
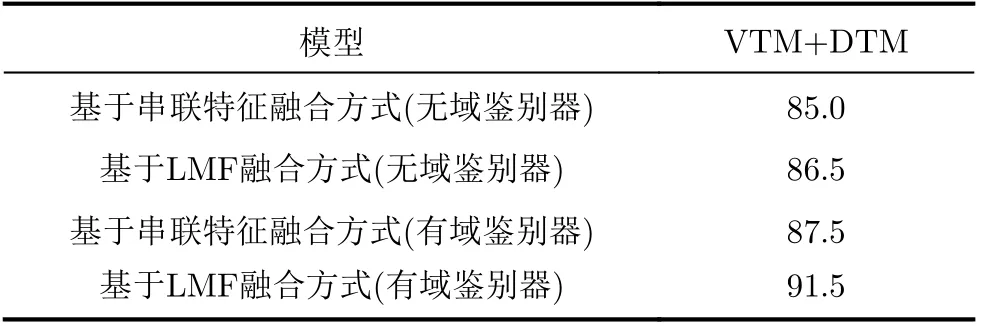
表3 DV-EI-Net多参数网络目标域分类精度(%)
为了验证本文完整的DV-EI-Net多参数网络的性能,表4给出了本文方法与其他方法准确率的比较。其中,对比算法CNN[21]和视觉几何群网络(Visual Geometry Group network 16, VGG16)[22]为单参数网络,距离多普勒角度-时间网络(Range Doppler Angle-Time, RDA-T)[10]为多参数网络。具体来说,RDA-T利用简化版VGG16网络和特征串联的方式对手势进行分类;CNN网络利用多普勒谱图做输入,通过10层的卷积神经网络对手势进行分类;VGG16是在图像分类上效果显著的网络结构。同时,本文在上述3个算法中进一步增加了域鉴别器结构,参与对比实验。为了比较公平,上述算法的输入均采用相同的DTM, VTM数据集,其中单参数网络只使用对人体姿势表征能力更好的VTM数据集。通过表4可知,无论是单参数网络还是多参数网络,相比于源域精度,在无标签的目标域下精度都有着一定程度的下降,且下降精度最大达到7.5%。加入域鉴别器后,下降精度减小为最多4%,这说明了域鉴别器具有通用性和有效性,不仅适用于本文所提出的网络结构,也可应用于其他姿势识别算法。从总体上看,本文所提出的方法在有姿势标签的源域数据下精度可达94.0%,并且在目标域精度也可以达到91.5%,相比于RDA-T[10]多参数网络提高3.0%,对比其他单参数网络算法则具有更加显著的优势。
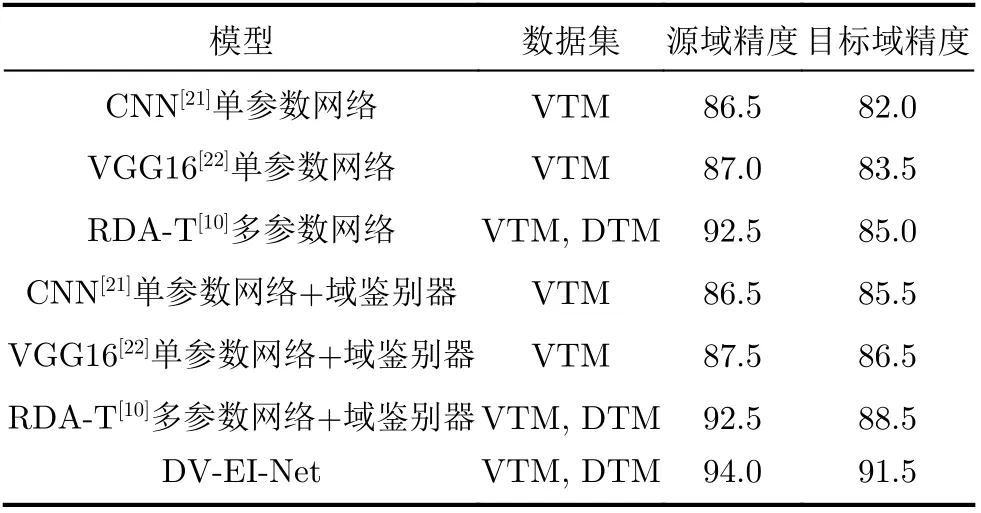
表4 本文方法与其他方法平均精度的比较(%)
4 结论
本文提出一种基于FMCW雷达信号的人体姿势识别方法,本方法利用FMCW雷达信号的多维信息,并关注复杂环境背景的处理。通过对FMCW雷达信号的有效算法分析,如3维FFT变换、DBSCAN聚类算法等,获得准确的目标距离、速度及角度参数,并进一步通过Hampel滤波和线性插值方法构造出VTM和DTM数据集。然后搭建了基于LMF融合网络和域自适应网络对多维参数数据集进行有效融合并提取与环境无关的特征。通过最终实验表明,本文方法对于复杂的目标域环境下的人体姿势的识别精度可达91.5%。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
电子制作(2019年15期)2019-08-27
航天电子对抗(2019年4期)2019-06-02
小学生学习指导(低年级)(2018年12期)2018-12-29
学校教育研究(2017年30期)2017-08-13
小学生导刊(高年级)(2016年11期)2016-11-14
