
一种基于深度强化学习的测向基线布阵技术*
2022-10-28 03:28朱子翰
电讯技术 2022年10期
胡 超,朱子翰
(中国西南电子技术研究所,成都 610036)
0 引 言
在无线电测向定位任务中,测向天线阵的阵列布局是影响测向定位效果的关键因素,必须在侦察任务系统的总体设计中统筹考虑,在充分有效发挥测向效能的基础上综合优化设计。传统的布阵方式是测向设计师根据经验评估天线阵元位置得到测向阵列,再用测向算法对阵列的测向指标进行评估,当指标不满足要求时,继续修改阵列,反复工作以获得符合指标要求的阵列。这种方式经过一定的精力投入可以设计出符合要求的阵列,但却费时费力,而且布阵效果极大依赖于设计人员的测向经验和专业素养,且能力不可复制,并且有些非标准阵列设计条件苛刻,状态空间复杂,即使有丰富测向经验的设计者也可能难以设计出符合要求的阵列。
强化学习(Reinforcement Learning,RL)作为机器学习的一种重要手段,研究的是智能体与环境交互完成决策模型的学习,实现环境状态到最佳动作的映射。深度强化学习(Deep Reinforcement Learning,DRL)是将深度学习与强化学习结合起来从而实现感知到动作的端对端学习的一种全新的算法,可应用于机器人、游戏博弈、优化与调度、仿真模拟、自然语言处理等领域,且在多个人机对抗竞赛中连续夺魁[1-3],在特定场景应用中完全具备代替“人”的能力。
为解决传统测向布阵方法中存在的耗时耗力且严重依赖于人工经验的现状,本文设计了一种基于深度强化学习的测向基线布阵算法,既满足相关干涉仪一维测向,也适配相关干涉仪二维测向。设计布阵智能体模拟人工设计测向基线,通过设定阵列类型、测向频段、测向方位、基线空间约束、测向阵元数量等布阵条件,由智能体反复试错,最终获得符合指标的最优测向阵列。其布阵过程采用机器自主+人在回路的方式,经过高性能计算机的优化加速,可大大提高布阵效率,提升测向质量,进一步解放人力资源。
1 基于DDPG的测向基线布阵方法
1.1 智能布阵思想
在传统的测向布阵问题中,存在确定阵元数量、阵列类型、布阵频率、布阵方位、空间尺寸等约束条件,如果能遍历阵列的所有空间布局,理论上是可以找到最优测向基线的,但是传统的搜索算法受巨大搜索空间影响,无法在给定时间内做出决策响应。
在强化学习方法中,智能体可通过与环境的相互作用来学习。一般地,将强化学习问题描述为在有限状态、有限动作集合的环境中,最大化智能体获得的累积折扣回报。因此,强化学习通常被建模为马尔科夫决策过程(Markov Decision Process,MDP)[4]。MDP模型是一个五元组(S,A,P,R,γ),主要含义如下:S为状态空间,即环境状态组成的有限集合;A为动作空间,即所有可能动作组成的有限集合;P为状态转移概率;R为执行动作后的奖励回报;γ为折扣累积奖励,表示在每个时间步长之后,环境反馈给智能体相应的折扣回报。
本文采用深度强化学习的布阵方法是将传统的布阵要素量化为智能网络模型算法适配的数据输入,利用智能体去学习和探索布阵经验,智能体每移动一次阵列的坐标,环境反馈一个奖励(依据当前阵列的测向精度和测向模糊性),以此来指导智能体的学习过程,其设计流程如图1所示。
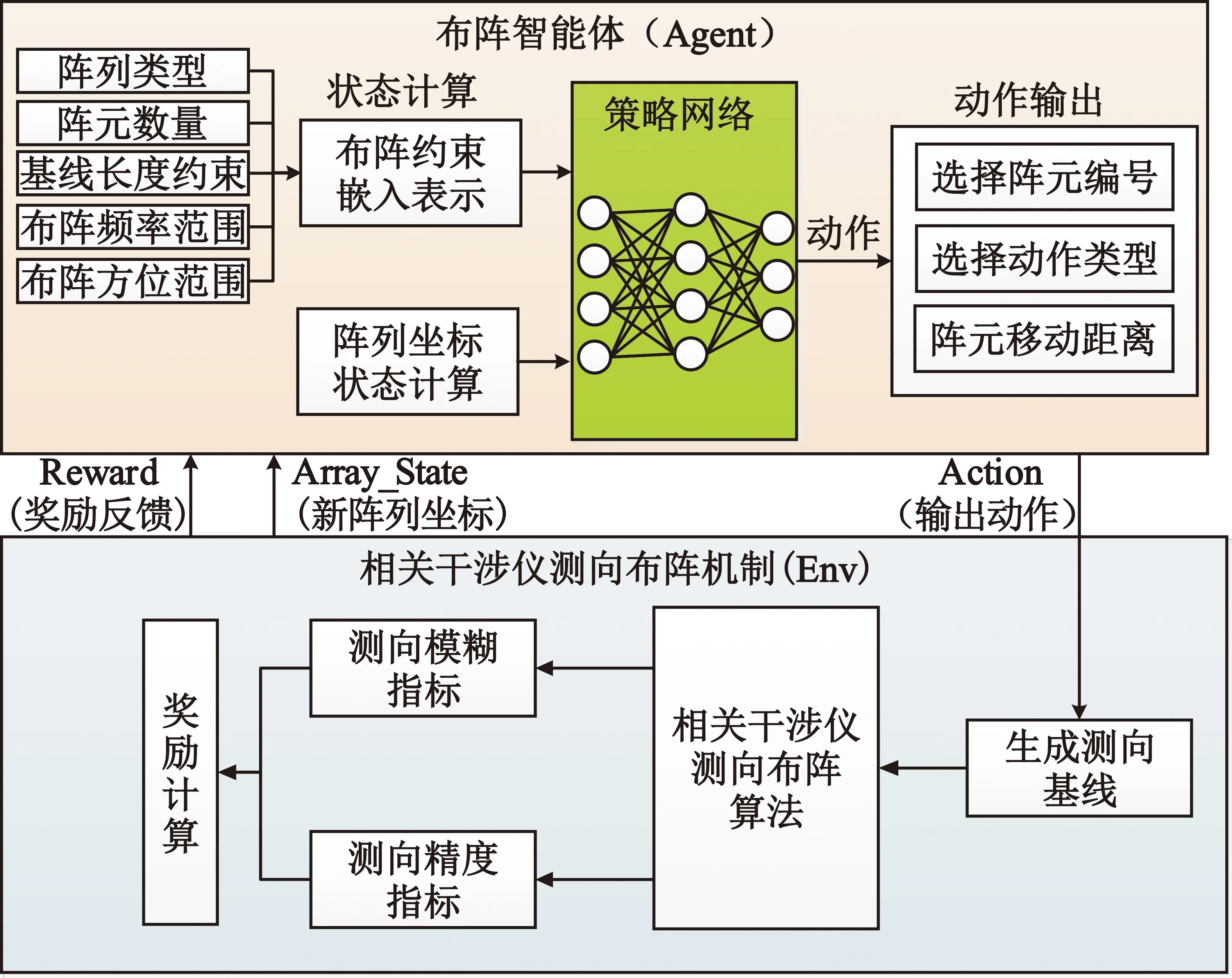
图1 基于深度强化学习的测向布阵方法原理图
在此过程中,相关干涉仪测向布阵算法主要包括对测向基线进行相位差建库,施加相位差误差,再对该阵列进行测试,得出测向精度和测向模糊指标,并根据测向指标计算得到奖励值。
整个布阵过程是一个“机器自主+人在回路”的工作模式,由机器训练迭代输出符合条件且测向精度最优的前三组测向阵列,然后由设计师根据实际需求将三组测向阵列或者测向精度最优的测向阵列输入到工程论证中所用的相关干涉仪测向分析软件中对测向的性能进行评估,并输出评估报告。
1.2 决策网络设计
针对测向基线布阵任务的特点,智能体在决策时需要考虑布阵的约束条件和当前的阵列坐标信息。本方案智能体策略网络的结构主要依赖于编码器-解码器的Transformer,其中编码器部分将时间序列上的测向阵列坐标作为输入,而解码器部分以自回归的方式预测下一时刻可以移动的阵元编号,解码器使用注意力机制与编码器连接。通过这种方式,解码器可以学习在做出预测之前“关注”时间序列历史值中最有用的部分。智能布阵的策略网络结构如图2所示,策略网络将阵列坐标、阵元数量、空间尺寸约束、阵列类型等特征量作为输入,通过Transformer网络中的注意机制提取阵元之间的实体关系状态特征信息,再将实体状态信息经过多个全连接网络输出状态价值、阵元编号类选择、动作类型和阵元移动距离等决策要素。
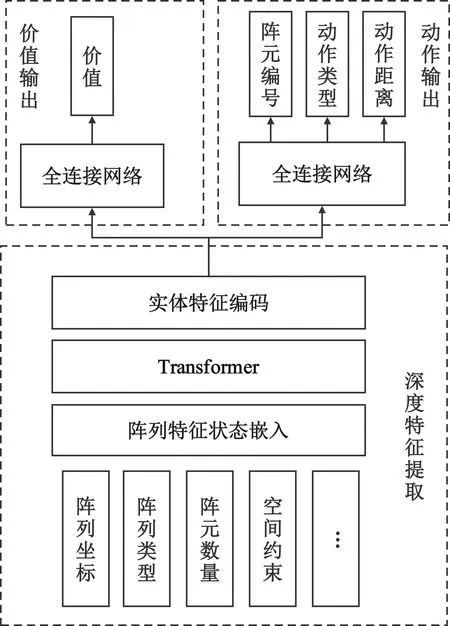
图2 智能测向阵列基线布阵决策网络设计
1.3 深度确定性策略梯度算法
在本文中测向基线的布阵是根据当前的布阵环境和策略输出具体的动作值,且阵元的移动距离是连续确定性策略动作,因此,本文采用深度确定性策略梯度强化学习算法。
深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)是连续控制领域经典的强化学习算法[5],是DQN(Deep Q-learning Network)[6]在处理连续动作空间的一个扩充。Deep表示采用了深度神经网络;Deterministic表示输出的是一个确定性的动作,可以用于连续动作的输出;Policy Gradient表示该算法用的是策略网络,但DDPG是单步更新方式,即每一个step更新一次 Policy 网络[6]。DDPG借鉴了DQN的目标网络和经验回放技巧,让算法训练更稳定,更容易拟合。相比DQN网络,DDPG具有更泛化的表达能力,需要采样的数据少,算法效率高。算法架构如图3所示。
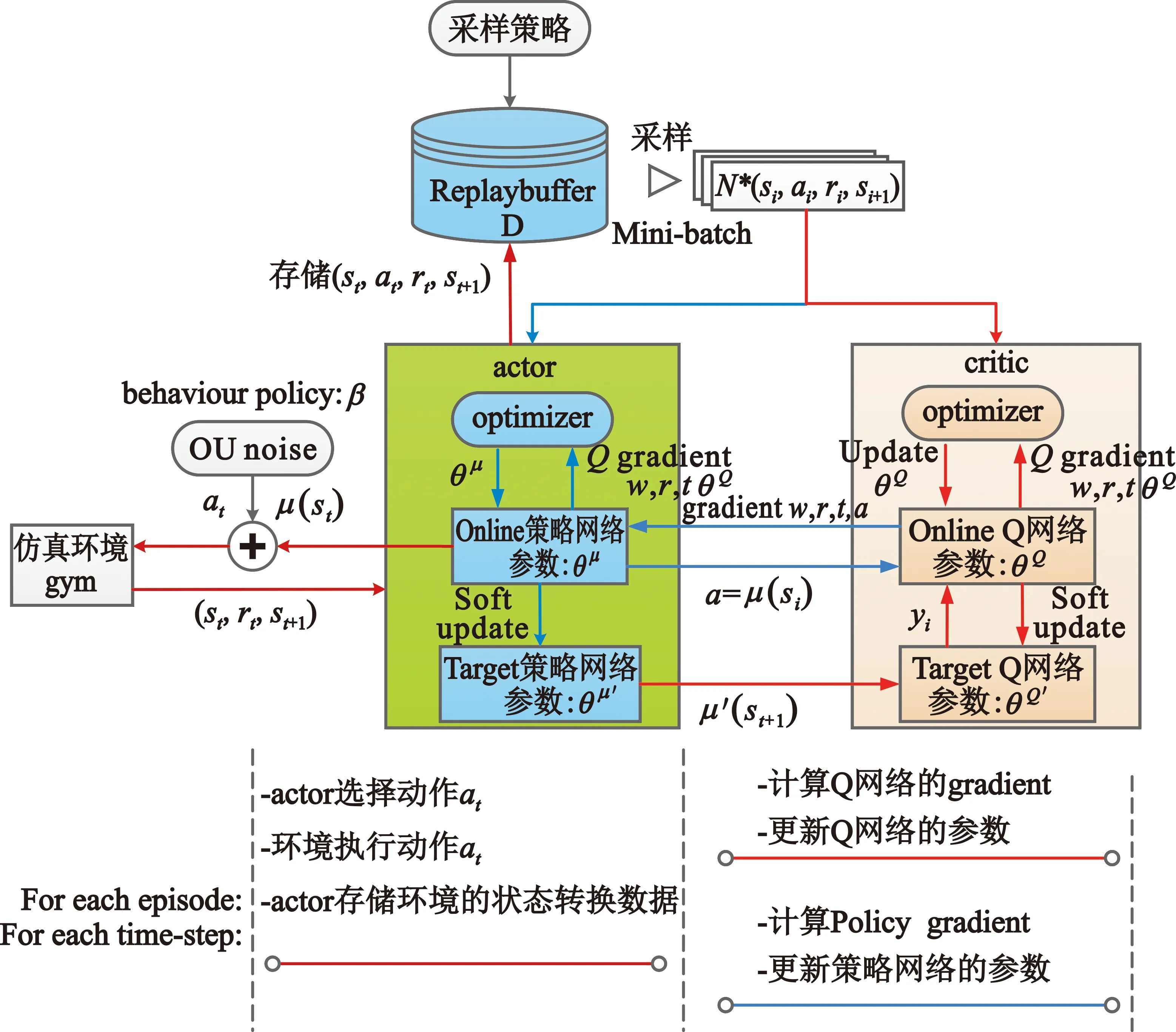
图3 DDPG算法架构图[5]
1.4 状态空间设计
阵列的状态空间主要包含阵列的固有属性特征和阵元的状态特征,如表1所示。

表1 状态空间表达
1.5 动作空间设计
在布阵过程中,动作的主要对象是对目标阵元的操作,主要包含离散输出和连续动作两种,离散动作包含选择阵元编号和动作类型,连续动作主要输出阵元的移动距离值,如图4所示。
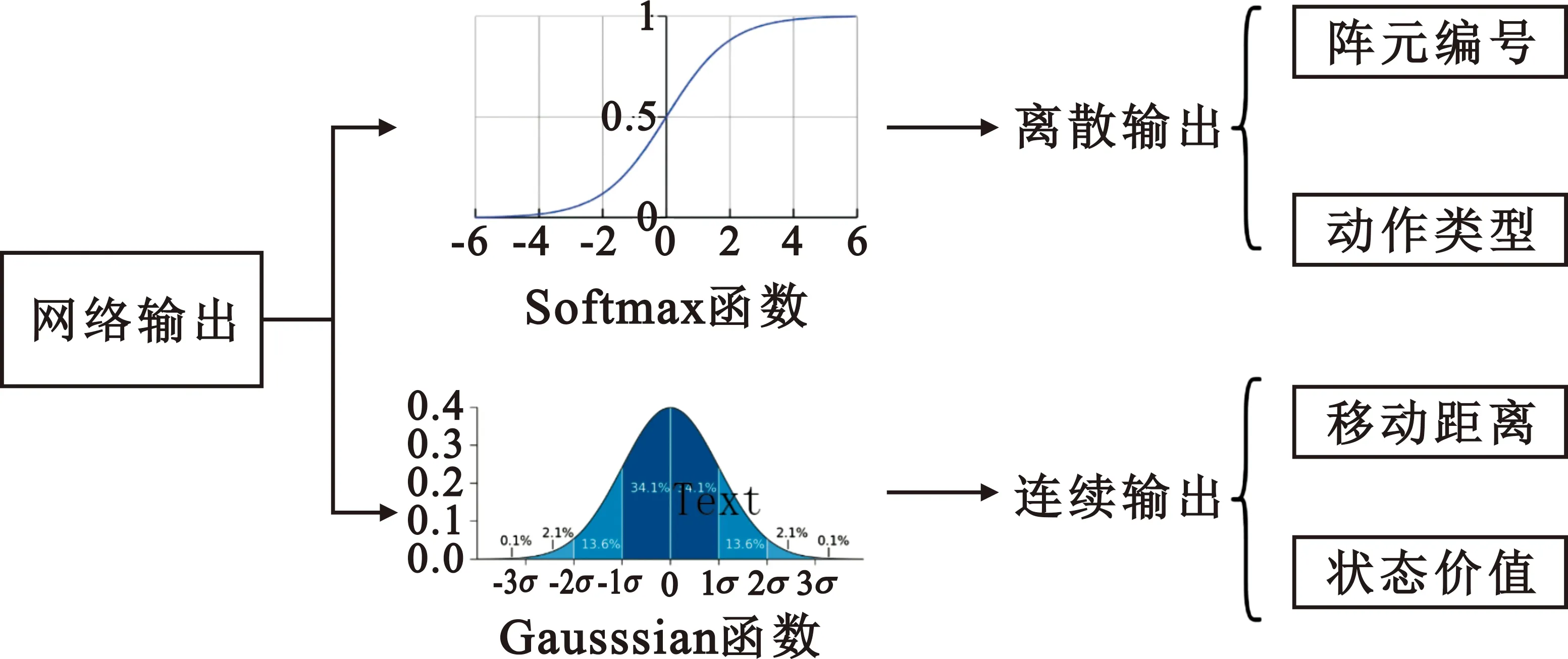
图4 策略输出类型概念图
策略网络的动作空间输出如表2所示。
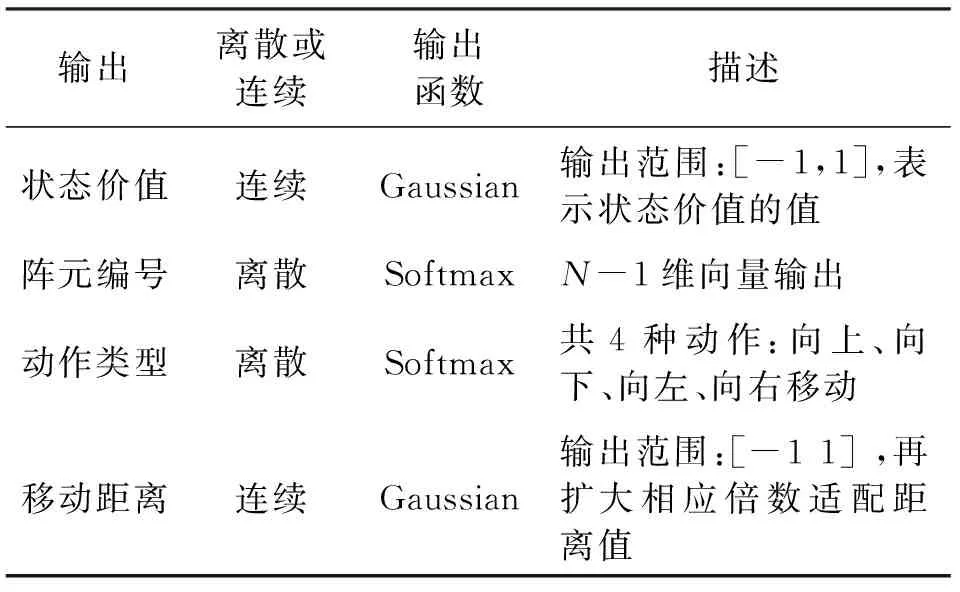
表2 动作空间表达
离散数据采用Softmax函数进行描述,公式如下:
(1)
以动作类型为例,一共有Left、Right、Up、Down 4种动作类型,输出为x1、x2、x3、x4,则概率如表3所示。

表3 动作概率输出表达
连续数据采用高斯函数进行描述,公式如下:
(2)
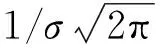
1.6 奖励函数设计
奖励函数的设计是研究强化学习中非常重要的设置,它决定了强化学习算法的收敛速度和程度,是引导智能体学习的关键因素。在本文中,测向布阵的最终目标是在约束条件下,得到一组符合测向精度且无模糊的最优测向精度的阵列。奖励设计如表4所示。

表4 奖励汇总表达
为了适度激发布阵智能体对于状态空间的探索,设计好奇心奖励函数,根据当前已经探索状态空间与当前未探索的状态空间对探索未知状态的智能体进行奖励。
2 实验设计与结果分析
2.1 仿真环境建模
本文的仿真环境采用OpenAI团队针对强化学习实验开发的开源平台Gym,利用rendering模块中的画图函数进行图形绘制,以便于直观展示阵元的空间部署信息。布阵建模时,主要考虑生成两个引擎——图像引擎和动作引擎:图像引擎render(),用来显示测向基线中的天线阵元的空间位置;动作引擎step(),在建模背景环境中扮演物理引擎的角色,即每次通过动作引擎来移动阵元位置。
2.2 实验硬件平台
本文实验开展硬件配置如表5所示。

表5 实验平台与配置
2.3 实验流程设计
在布阵训练过程中,网络收敛的速度与阵列类型、阵元数量、布阵频率范围有着直接关系。
某项目拟设计侦测天线,要求测向天线阵实现全方位测向,同时具备水平测向和俯仰测向能力(即具备二维测向能力),布阵需求和参数设置如表6所示。
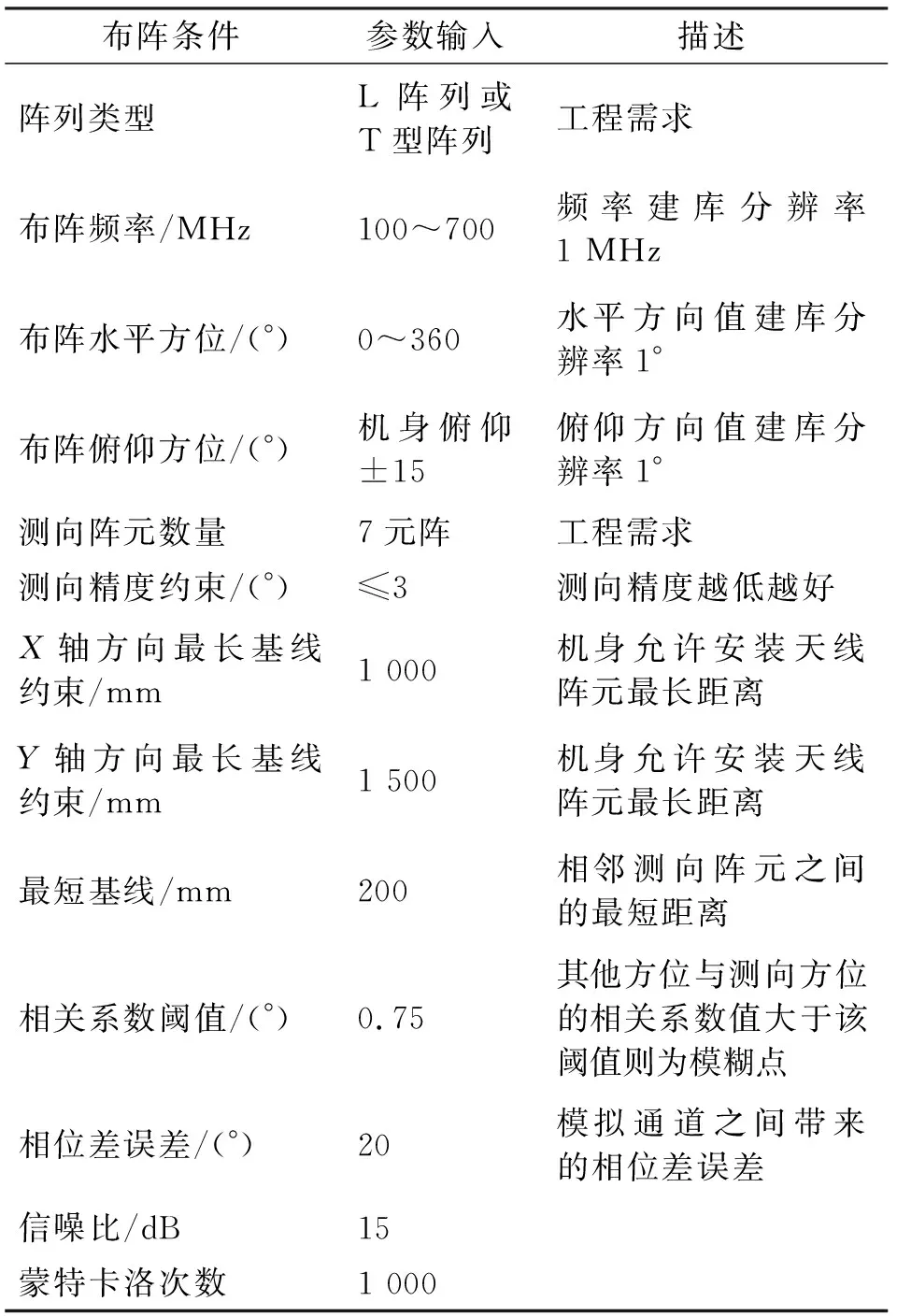
表6 布阵需求和实验参数设置
2.4 实验结果分析
将以上布阵条件输入测向布阵网络进行训练迭代,网络模型每迭代一次都会输出当前设计测向阵列的阵列坐标、测向模糊性、测向精度等评估结果。当训练步长达到设定值时结束训练,训练时长3.7 h,训练结果曲线如图5所示。值得注意的是,因为实验是以训练迭代步长episodes和是否收敛作为训练结束标识,所以在这个过程中布阵智能体可能没有对测向阵列的所有状态空间进行探索,因此该技术的输出结果是局部最优的。
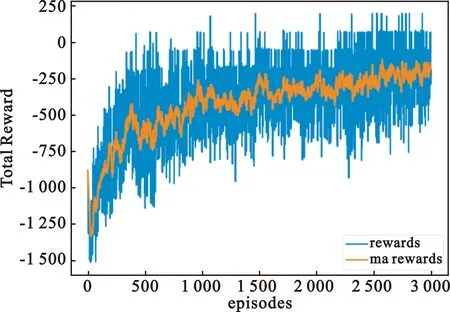
图5 线阵训练迭代结果曲线
从训练过程中输出的多个无测向模糊阵列中,输出测向精度排名前三的3组测向阵列,如表7所示。
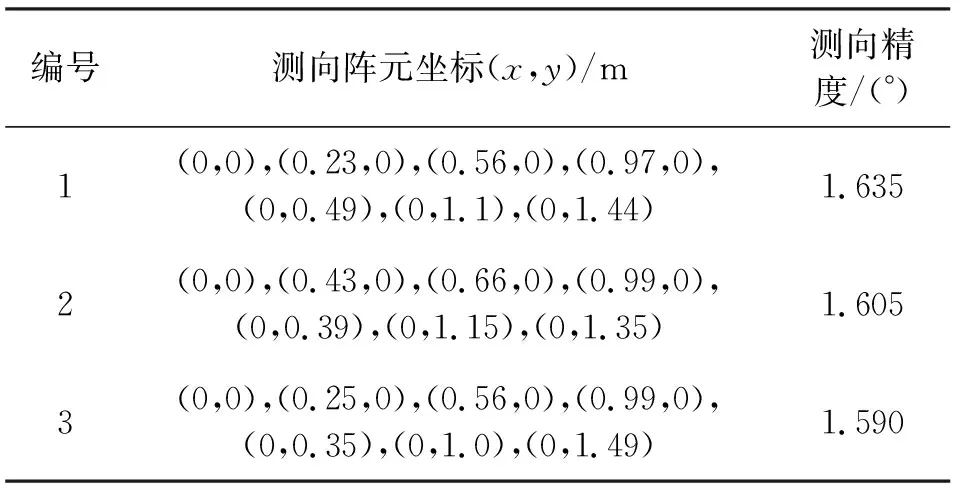
表7 训练迭代生成的测向阵列
采用测向精度最优的第三个阵列(编号3)作为评估对象,其阵列布局如图6所示。
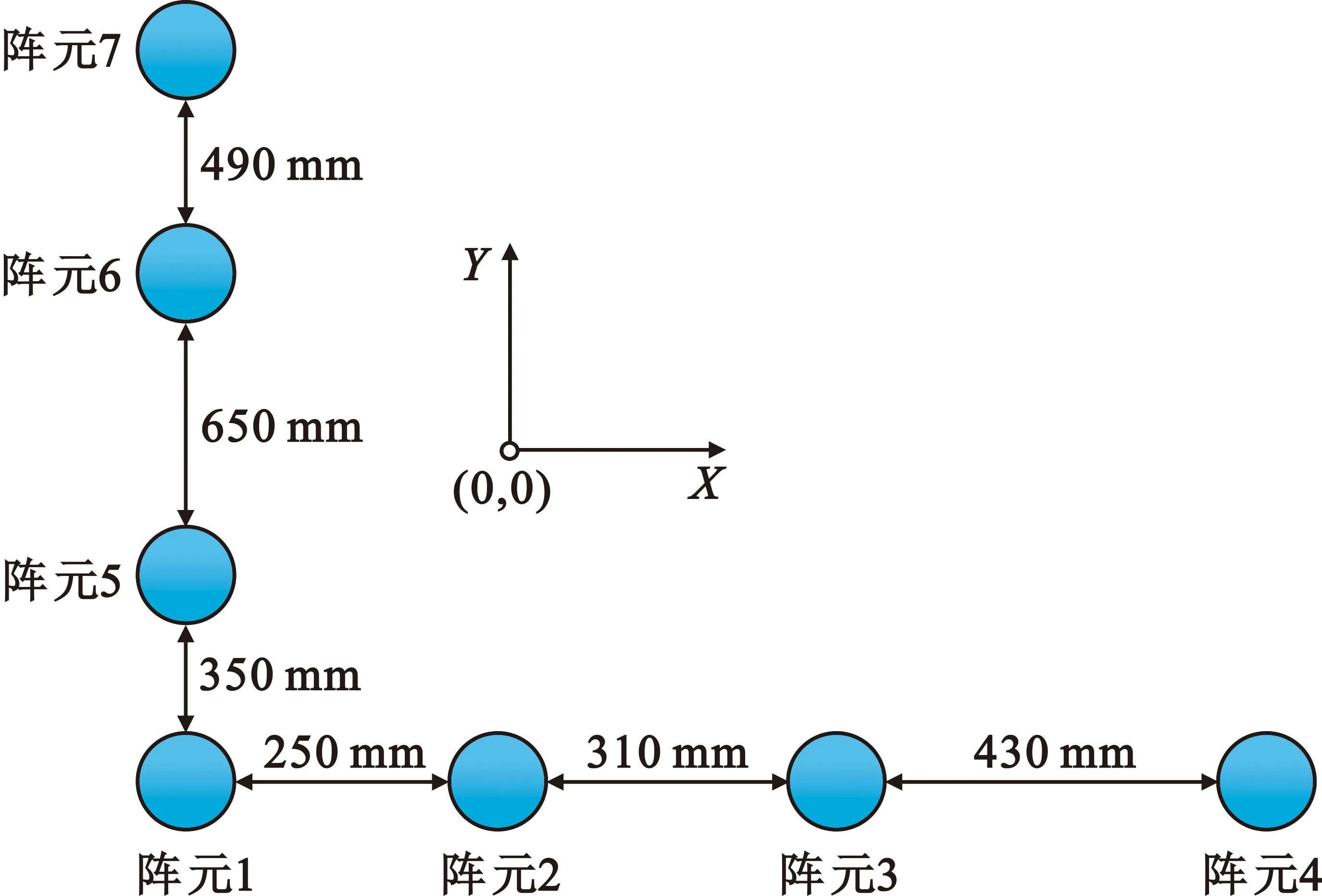
图6 布阵基线示意图
采用相关干涉仪测向分析软件对该阵列的布阵效果进行验证测试,分别统计该测向阵列在俯仰角-15°、5°、0°、5°、15°时,水平全方位(0°~360°)的测向精度,测试评估结果如表8所示。
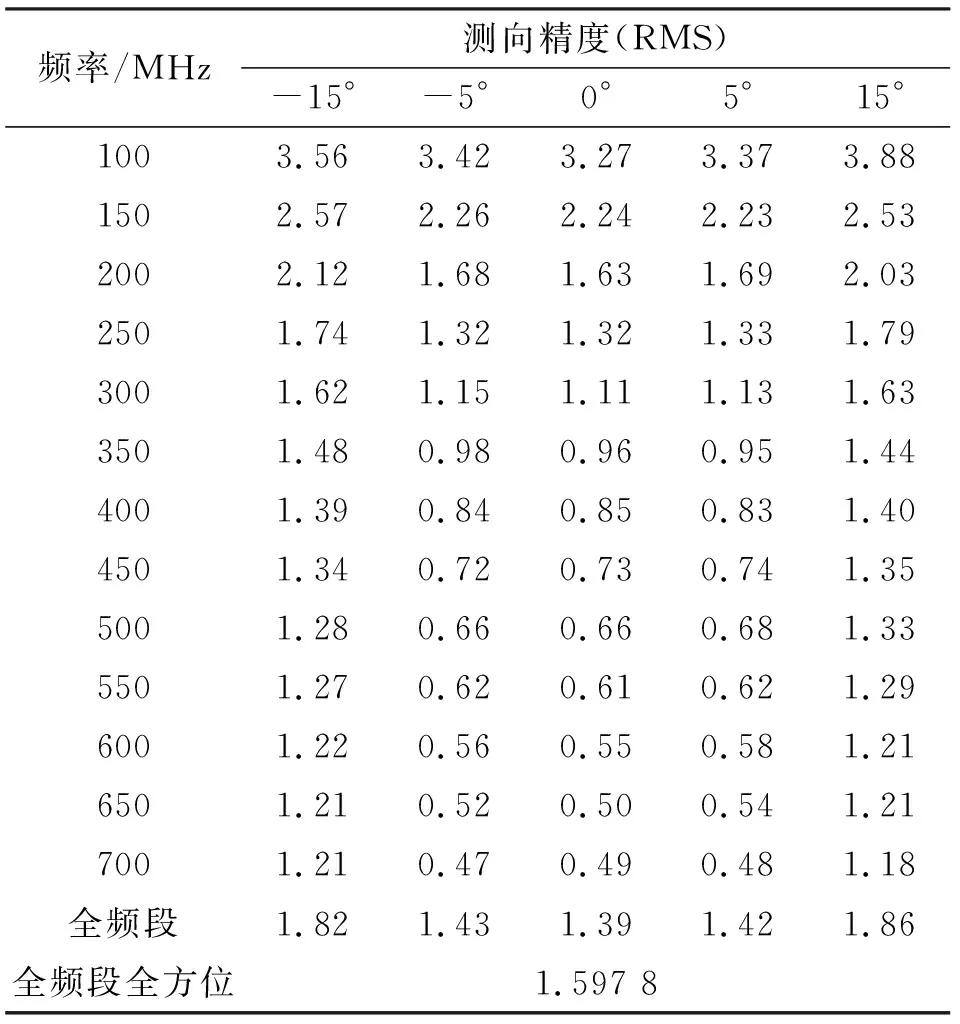
表8 测向阵列在不同俯仰角时的测向精度评估结果
从表8中可以看出,该阵列在全频段全方位的测向精度≤1.597 8°,优于测向指标3°。画出该测向阵列在俯仰角为0°,频点为100 MHz、400 MHz、700 MHz时水平全方位的测向曲线,对测向阵列的模糊指标进行验证评估,如图7所示。
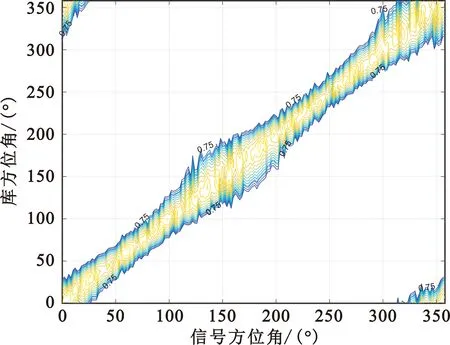
(a)100 MHz时水平全方位测向曲线
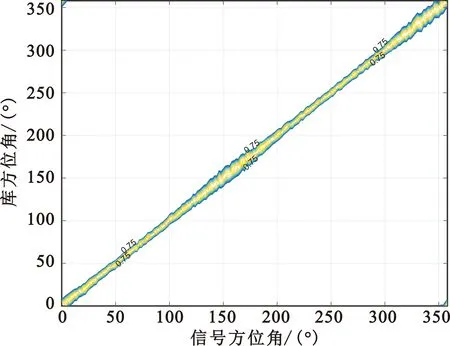
(b)400 MHz时水平全方位测向曲线
(c)700 MHz时水平全方位测向曲线图7 测向阵列在部分频点全方位的测向曲线
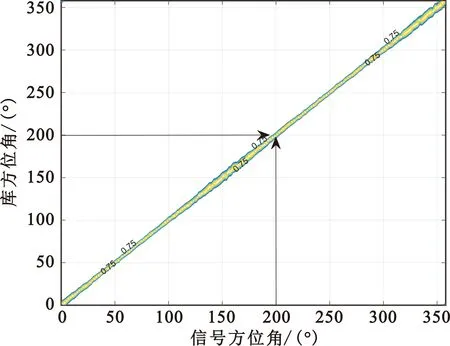
从图7中可以看出,信号方位角与库方位角做测向相关算法后,相关系数大于0.75的值均分布在相关峰附近。以图7(c)测向阵列在700 MHz、水平全方位的测向曲线为例,信号方位角在200°时,与库中所有方位做复相关运算后,相关系数大于0.75的值都集中在库方位200°左右,与其他方位的相关系数无大于0.75的点,即该阵列在700 MHz测向时全方位无测向模糊点。以此类推,验证得到该测向阵列在全频段全方位均无测向模糊。综上,该阵列的测向指标均符合布阵需求,可进一步作为工程实现参考阵列。
为进一步探索本文方法在实际使用中的增量,特请在工程项目中具有丰富经验的3位测向设计师A、B、C参与布阵论证工作。
以表6所述的相关参数作为布阵需求,让3位设计师同时开展布阵论证工作,为控制变量,特要求3位老师在上班有效时间段全力以赴该论证工作,直到输出结果为止。试验结果如表9所示,值得注意的是,表中的布阵耗时代表该设计师参与阵列基线设计的有效时间。
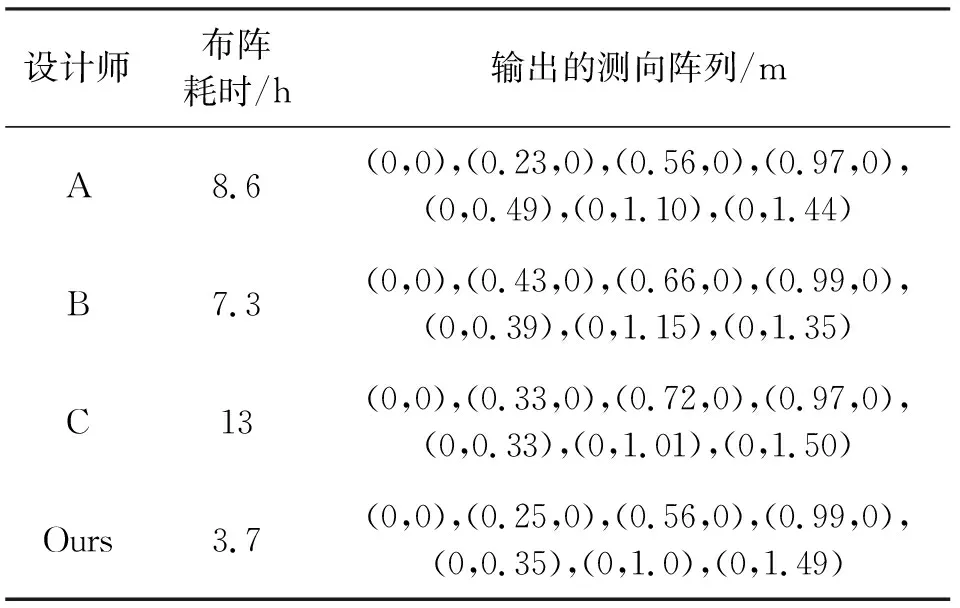
表9 测向设计师布阵结果
分别采用相关干涉仪测向分析软件基于表9的测试条件,对表8中各设计师的输出测向阵列在全频段、水平全方位(俯仰角为0°)的测向精度和测向模糊指标进行评估,评估结果如表10所示。
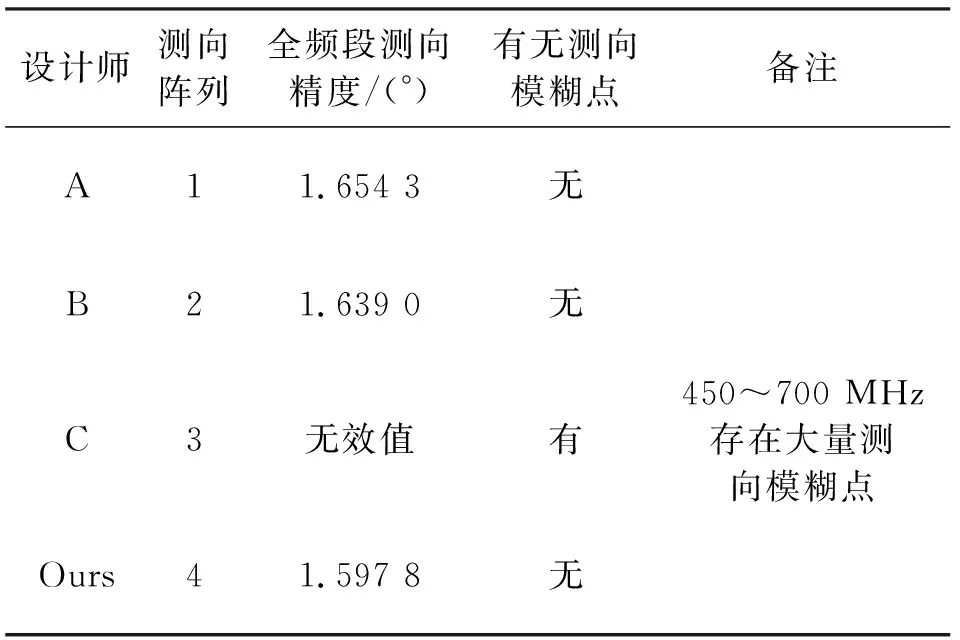
表10 各设计师测向布阵基线测向结果评估
由表10可以看出,在4组测向阵列中,本文方法设计出来的阵列测向精度最优,且无测向模糊,证明了本文方法的实用性。由C设计的测向阵列3在450~700 MHz频段内测向时全方位存在大量模糊点,在工程实施时无法应用于测向任务,以500 MHz测向曲线为例,如图8所示。
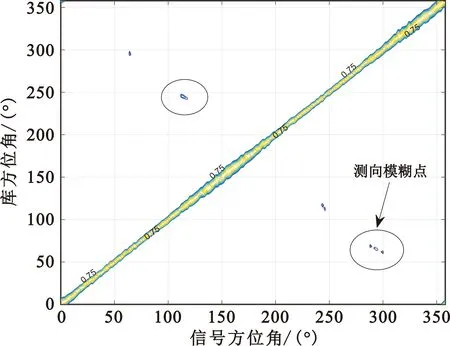
图8 测向阵列3在500 MHz水平全方位测向曲线
3 结 论
本文针对当前相关干涉仪测向提出了一种基于深度强化学习的测向基线布阵技术,通过Gym仿真建模环境构建布阵场景、DDPG深度强化学习算法构建布阵智能体,以强化学习反复试错的机制模拟人工布阵的过程,并通过实验证明了本文方法的科学性和有效性。
智能布阵过程采用机器自主+人在回路的形式,通过设计师输入布阵条件,机器训练迭代输出阵列结果,再由设计师对阵列结果进行测试验证,整个过程大大降低了人参与的程度,且不依赖于设计师的测向经验,任何有测向布阵需求的设计师都可以使用该技术,因此该方法具有实用性和普适性。
猜你喜欢
幼儿100(2022年37期)2022-10-24
一重技术(2021年5期)2022-01-18
导航定位学报(2021年5期)2021-10-13
家庭影院技术(2020年11期)2020-12-28
导航定位学报(2019年2期)2019-06-06
舰船电子对抗(2019年6期)2019-04-27
电子制作(2018年11期)2018-08-04
作文大王·中高年级(2018年5期)2018-06-20
华人时刊(2016年16期)2016-04-05
中国科技术语(2012年5期)2012-12-28
