
基于多任务学习和注意力机制的双分支深度换脸检测方法*
2022-10-28 03:27蒲文博孔维华
电讯技术 2022年10期
胡 靖,蒲文博,孔维华
(成都信息工程大学 计算机学院,成都 610225)
0 引 言
随着深度学习和神经网络的快速发展,面部图像篡改已经成为一项简单的任务。最近,一种被称为深度换脸(Deepfake) 的技术引起了广泛的关注。它能合成另一个身份的人脸,并替换原视频中目标人的脸,同时保留原始的面部表情、光照以及位置信息。这种技术生成的换脸视频能达到肉眼难以区分的视觉效果。由于人脸与身份识别密切相关,深度换脸视频可能会被恶意地滥用而威胁公众的隐私安全。此外,随着抖音、微信等社交媒体的快速发展,这种伪造视频可以被迅速而广泛地传播。
为了应对深度换脸视频给隐私安全带来的威胁,大量研究人员投入到深度换脸检测技术研究中。最近提出的深度换脸检测方法大体上可以分为两类:图像(帧)检测方法和视频检测方法。图像(帧)检测方法又可以进一步分为基于卷积神经网络(Convolutional Neural Network,CNN)的分类方法和基于自编码器的伪造区域定位方法。基于CNN的分类方法通常将深度换脸检测视为二分类问题,使用CNN络进行特征图提取,以获得有利于网络判别图像是否为换脸图像的隐含信息。伪造区域定位方法侧重于将篡改的区域暴露出来。与图像检测任务不同,视频检测任务侧重于对整个视频的判断。
为了解决现存方法的缺陷,本文基于多任务学习策略[1],提出了一种双分支深度换脸检测网络。该网络结合了视频检测方法和图像检测方法的特点,将两种方法视为同一网络的不同任务,使得网络能对视频进行综合判断的同时检测每帧的伪造情况。此外,通过引入卷积注意力模块(Convolutional Block Attention Module,CBAM)[2]和时序学习模块模型,拥有对特征图的局部通道信息和局部空间信息的注意能力,以及提取时序不连续信息的能力。实验结果表明,在公开数据集Celeb-DF[3]和 FaceForensics++[4]上,所提方法在视频检测任务和帧检测任务中都具有优秀的准确率(Accuracy,ACC)和ROC(Receiver Operating Characteristic)曲线下面积(Area under ROC Curve,AUC)。此外,该方法在面对不同光照、人脸朝向、视频质量的换脸视频时表现出了良好的鲁棒性。
1 卷积注意力模块
近年来,注意力机制在深度学习中得到了广泛研究与应用。例如,张宇等人[5]提出了一种融入注意力机制的动作识别方法,通过引入注意力机制,模型更专注于重要信息,从而降低了模型过拟合的风险。注意力机制受人类视觉神经的启发,通过引入注意力权重,调整网络对不同信息的关注度,使网络注意关键信息而忽略非关键信息,提升网络的效率。换脸检测工作中,合成人脸周围不一致信息是模型判断图像是否伪造的关键。然而这种关键信息往往只占极少部分,因此将注意力机制引入深度换脸检测,能提升模型对该信息的注意能力。
卷积注意力模块[2]包含通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)两个部分,其中CAM如图1所示。
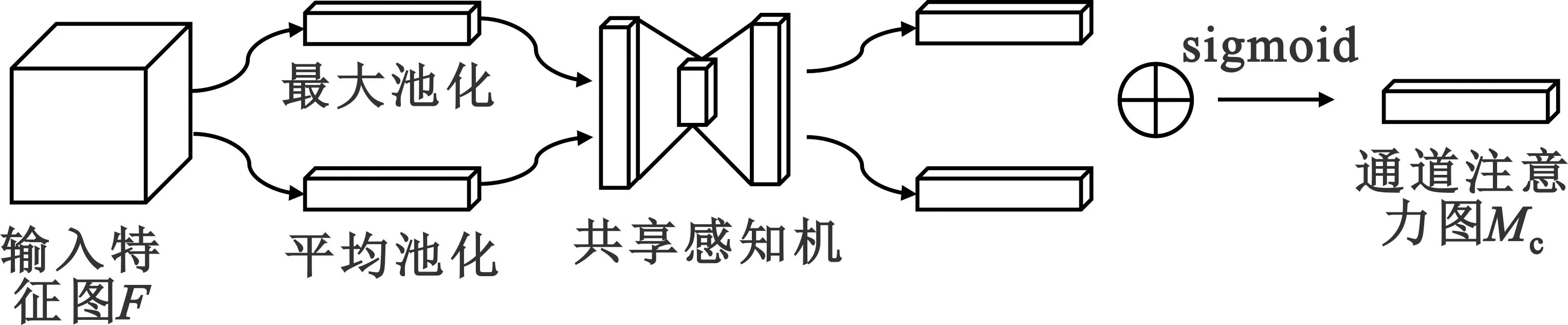
图1 通道注意力模块示意图
通道注意力模块的具体工作流程如下:
设卷积网络中卷积层输出特征图F∈H×W×C。CAM以该特征图为输入,特征图分别经过两个基于通道维度的全局最大池化层和全局平均池化层,得到两个特征向量1×1×c和1×1×c。这两个特征向量随后会分别进入一个共享的两层感知机中,该感知机第一层神经元个数为c/r,第二层神经元个数为c,其中r为压缩率。经过感知机输出的两个特征向量会进行对应元素相加,相加的特征向量再经过sigmoid激活函数处理,以输出最终的通道注意力图Mc。该特征图最终会和输入特征图F相乘,这样输入特征图F的不同通道便被赋予了可学习权重。简单地,通道注意力图可以表示为
(1)
式中:σ为sigmoid激活函数,W0和W1分别为共享感知机的两层参数。
空间注意力模块如图2所示。
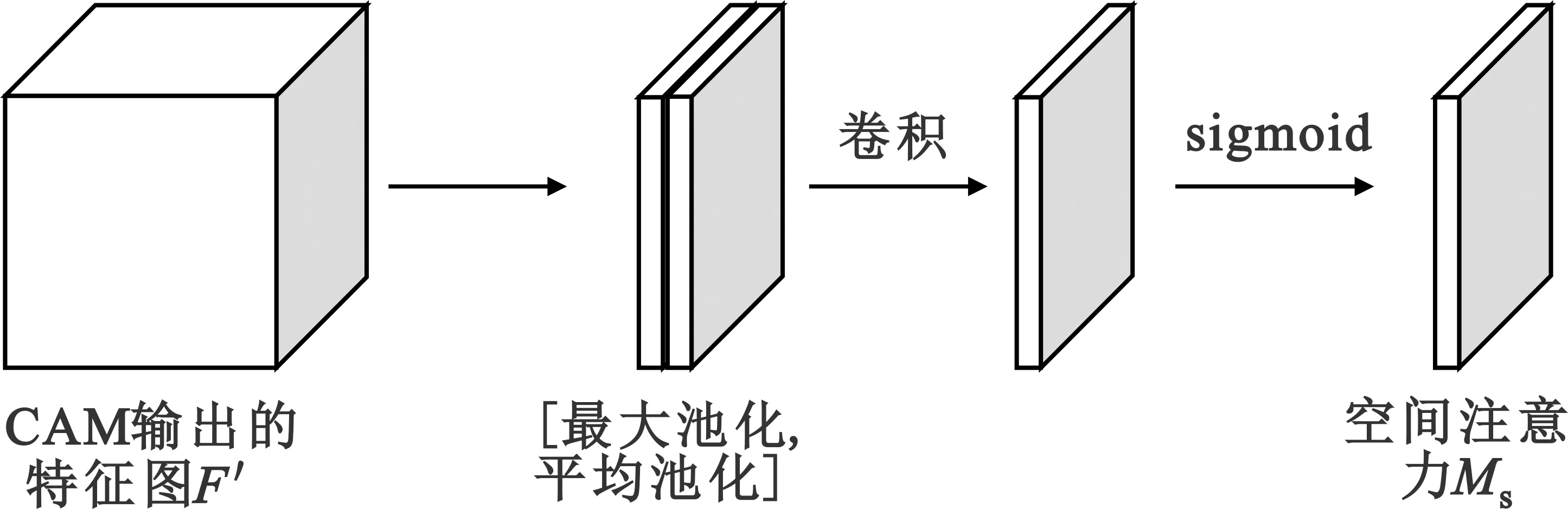
图2 空间注意力模块示意图
空间注意力模块的具体工作流程如下:
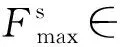
(2)
式中:σ为sigmoid激活函数,Cov对应卷积操作。
2 双分支深度换脸检测网络
双分支深度换脸检测网络架构如图3所示。Dlib[6]人脸识别库会将原视频中的每帧人脸提取出,作为网络的输入数据。基于CBMA的ResNet50[7]会逐帧提取空间信息。在注意力机制的帮助下,会筛选出有助于判断的关键信息。每帧的空间信息会被输入到时序学习模块,用于提取帧间不连续信息。融合了空间信息和时序信息的特征图会输入至帧检测分支和视频检测分支中。帧检测分支会输出每帧的检测结果,而视频检测分支会输出整个视频的检测结果。

图3 算法网络架构
2.1 基于CBAM的ResNet50
基于CBAM[2]模块的ResNet50[7]具体实现如图4所示:

图4 整合CBAM模块的ResNet50的流程示意图
(1)在ResNet50中第一层7×7卷积层后分别加入通道注意力模块和空间注意力模块,赋予模型对图像低层特征的注意能力;
(2)在ResNet50最后一层卷积层后,平均池化层(avg pool)前加入通道注意力和空间注意力模块,赋予模型对图像高层特征的注意能力;
(3)移除ResNet50原本的最后一层全连接层,使ResNet提取的特征向量直接输入至下层时序学习模块中。这样ResNet50就有两层CBAM模块,能分别赋予模型对图像低层特征和高层特征的注意能力。
设输入的视频大小为n×h×w×3,其中,n为输入视频帧数,h和w为每帧图像的高和宽,通过基于CBAM的ResNet50模块提取的输出特征向量大小为n×2 048。
相比CBAM原文在ResNet50的每个ResBlock中加入CBAM模块的方法,本文方法使ResNet50拥有注意能力的同时降低了网络参数,提高了模型的信息提取效率。
2.2 时序学习模块
时序学习模块在深度换脸检测中扮演了重要角色。本文中,时序学习模块由三层门控循环单元(Gated Recurrent Unit,GRU)[8]网络构成,具体结构如图5所示。时序学习模块接收来自上层ResNet50输出的每帧的特征向量,由于模块中每层GRU网络包含256个神经元,因此模块输出大小为n×256的包含时序信息的特征图,其中n为输入帧数。
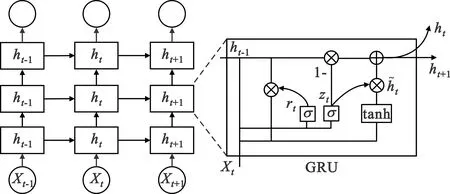
图5 时序学习模块结构图
2.3 视频检测分支和帧检测分支
时序学习模块提取的特征图会被同时传递到视频检测分支和帧检测分支中。如图3所示,在视频检测分支中包含了一个平均池化层和全连接层。平均池化层接收来自时序学习模块的特征图,产生大小为16×16的特征图,特征图被展平成一维特征向量,该特征向量大小为256。视频检测分支中的全连接层接收该特征向量,输出模型对整个视频的判断结果。与此同时,帧检测分支中的一个共享的全连接层会接收来自每一帧的特征向量,每个特征向量大小均为256,并对每一帧是否为换脸帧做出最终判断。平均池化层能综合所有帧的特征信息,输出固定大小的特征图,视频检测分支中的全连接层便使用该特征图输出对整个视频的预测结果。此外,平均池化使输出的特征图与视频帧长度无关,因此本文方法能处理不同长度的视频。
2.4 目标函数

Lv=EVi~X[-ln(Fv(Vi)yi)],
(3)
(4)
L=α1·Lv+a2·Lf。
(5)
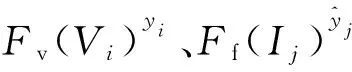
3 实验与分析
3.1 数据集
Celeb-DF(v2)[3]是2020年提出的大规模数据集,用于评估换脸检测方法。该数据集包含 590个真实视频和5 639个换脸视频。换脸视频由59位不同性别、年龄和种族的名人的公开可用的YouTube视频生成。值得注意的是,Celeb-DF数据分布不平衡,其中换脸视频显著多于真实视频,为模型的正确判别提出了挑战。
FaceForensics++[4]包含从 YouTube 抓取的1 000个真实视频和使用四种换脸算法生成的4 000个造假视频,每个算法生成的换脸视频数量为1 000。本文使用深度换脸合成的版本,故该数据为平衡数据集。除此以外,FaceForensics++包含了从三个质量从高到低的版本,分为raw、c23、c40。
3.2 实验设置
3.2.1 数据集准备
由于原数据集为纯视频数据,需要先对这些视频进行预处理,步骤如下:
首先,使用Dlib[6]库中的人脸检测器对数据集的每个视频中的每一帧进行人脸检测并提取。然后,将提取的人脸调整为64 pixel×64 pixel,并使用 ImageNet的均值和标准差对人脸图像进行归一化。由于Celeb-DF数据集中视频的平均帧数约为300,因此,为了加速网络训练,实验中的输入视频的长度统一设置为300。如果视频少于300 帧,则重复其最后一帧以达到300帧。这一方法借鉴了自然语言处理中常用的post-padding方法。但需要注意的是,本文方法在真实应用环境中可以接收并处理任意长度的视频。
3.2.2 对比方法
实验比较了五种图像检测方法和三种视频检测方法,分别为DSP-FWA[9](在FWA的基础上加入了空间金字塔池化以应对不同输入尺寸换脸图像)、Meso4[10](通过捕获深换脸图像的介观特征以判断图像是否为Deepfake合成)、MesoInception4[10](在Meso4基础上结合Inception模块的改进网络)、Xception[4](使用常用的卷积神经网络XceptionNet提取Deepfake图像的空间域信息)、Capsule[11](以VGG19为基础,基于胶囊网络结构检测换脸视频帧)、ResNet50+LSTM[12](包含了以ResNet50作为提取空间域信息的卷积网络和LSTM作为提取时序信息的循环神经网络)、ResNet50+GRU(ResNet50+LSTM的变体,使用和本文方法相同的GRU网络替换LSTM网络)、Inception3D[13](通过3D卷积网络同时提取伪造视频的空间信息和时序信息,以判断换脸视频是否伪造)。
上述对比方法均为开源方法。为了保证实验的公平性,上述对比方法均使用本文预处理的数据集重新训练。如果上述方法提供最优模型,则加载最优模型作为预训练模型并在本文数据集上微调,以确保各对比方法取得最优性能。
3.2.3 评价指标
实验中使用ACC和AUC作为评价指标。ACC的计算方式为
(6)
式中:TP为正例预测正确的个数,FP为负例预测错误的个数,TN为负例预测正确的个数,FN为正例预测错误的个数。
AUC的计算方式为
(7)
式中:posNum为正样本数,negNum为负样本数,则分母表示为正负样本总的组合数;predpos表示模型对正样的预测结果,predneg为模型对负样本的预测结果,分子则表示正样本大于负样本的组合数,含义为分别随机从数据集中抽取一个样本,正样本的预测值大于负样本的概率。
3.2.4 实现细节
本文方法使用PyTorch实现。实验环境为搭载了四张NVIDIA Tesla P100 GPU的服务器。本文方法训练迭代20次,批处理(batch size)大小为16,学习率设置为1×10-4。为平衡视频检测损失和帧检测损失的影响,使网络的两个分支的检测能力相近,公式(5)中α1和α2设置为 1。
为了保证实验的公平性,对比方法尽可能使用与本文方法相同的实验设置。例如,为了保证对比方法使用的GPU显存与本文方法相同,对于图像检测方法,它们的批处理大小设置为3 000;对于视频检测方法,它们的批处理大小设置为16。
3.3 性能结果与比较
3.3.1 Celeb-DF上的结果
表1给出了本文方法和对比方法在Celeb-DF数据集上的ACC和AUC结果,可以看出本文方法在视频检测任务和帧检测任务都取得了优于对比方法的成绩。在视频检测任务中本文方法取得了0.97的ACC和0.96的AUC,在帧检测任务中本文方法取得了0.95的ACC和0.95的AUC。Celeb-DF是一个不平衡的数据集,其中换脸视频与真实视频比例为7∶1。相比其他基于CNN网络的图像检测方法,例如Meso4,本文模型能有效提取空间信息和帧间时序信息,通过融合空间域和时序信息的方式有效提升模型的检测性能。因此,相比于图像检测方法这种单一的信息提取方法,本文方法能在不平衡数据集中做出更准确的判断。与本文方法相似,视频检测方法融合了空间域和时序信息,但由于本文方法在视频检测方法基础上引入双分支结构,在联合损失函数的同时优化下网络的两个分支得到互相增强,因此取得了更优秀的视频检测结果。此外,本文方法引入了注意力机制,增强了对关键信息的捕捉能力。
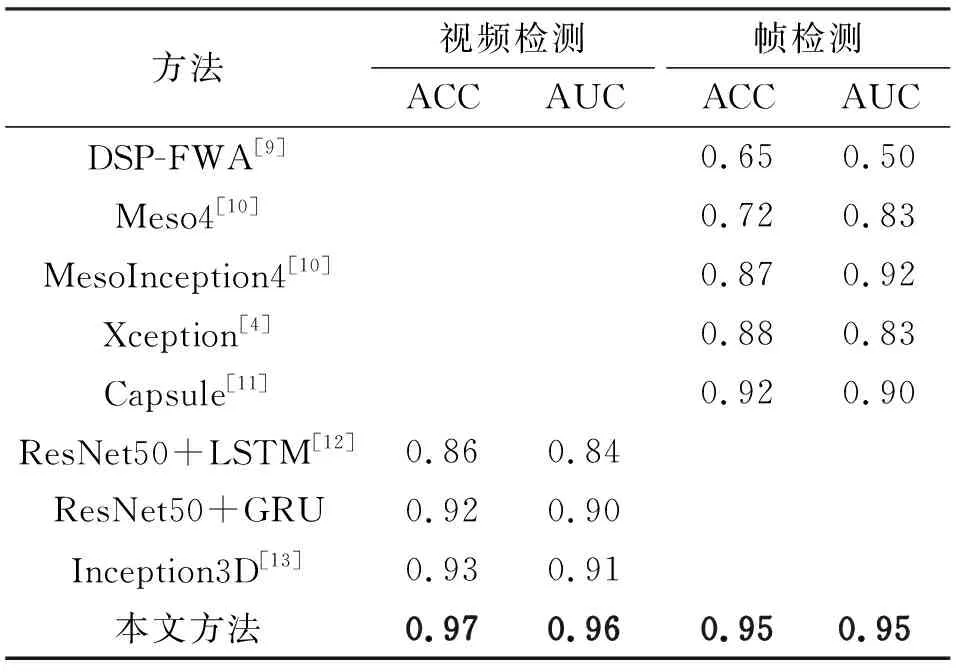
表1 各方法在Celeb-DF数据集上的性能对比
3.3.2 FaceForensics++ 的结果
表2给出了本文方法和对比方法在 FaceForensics++ 中等质量数据集c23上的性能对比结果。本文方法在视频检测任务上取得了0.95和0.95的 ACC 和 AUC,在帧检测任务上取得了0.94和0.94 ACC和AUC,无论是在视频检测任务还是帧检测任务上都优于对比方法——这和在Celeb-DF上的测试结果基本一致。
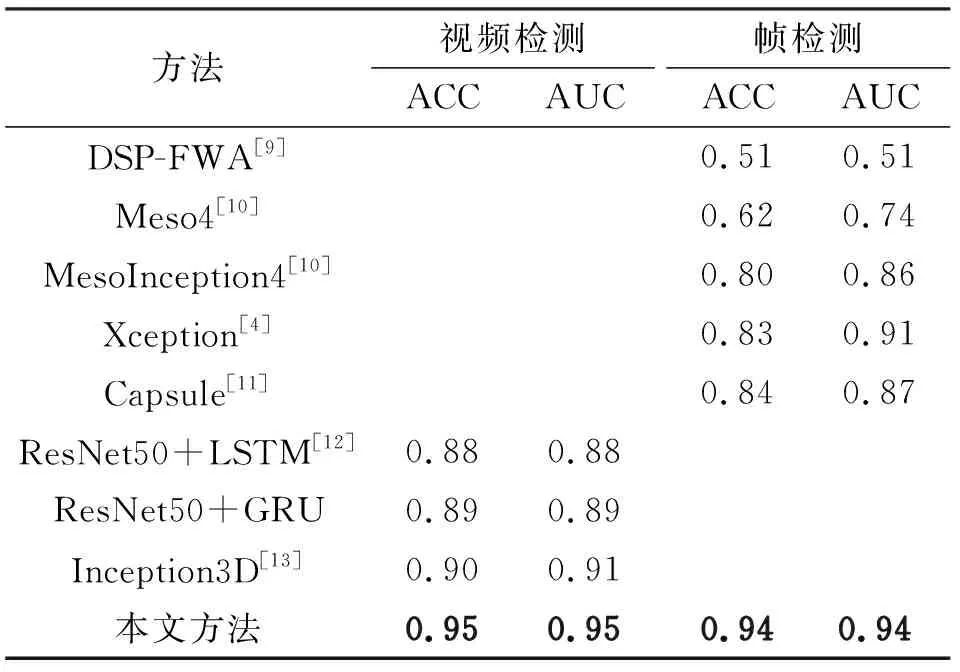
表2 在FaceForensics++ c23上的性能对比结果
本文方法创新设计了双分支网络结构,能融合视频的空间域不连续信息和帧间不连续信息,加之注意力机制的引入,模型能注意换脸视频的局部信息,有效提升模了型对换脸视频的检测能力。
此外,实验使用Grad-CAM[14]图像来展示本文模型在空间域上的检测方式。Grad-CAM通过展示模型对输入图像的注意力区域来解释模型在空间域的决策方式。图6给出了模型在FaceForensics++数据集上输出的Grad-CAM可视化图像,图中前两列分别为来自FaceForensics++的换脸图像和模型输出的Grad-CAM图像,后两列分别为来自FaceForensics++的真实图像和模型输出的Grad-CAM图像。从图6中可以得出,红色的注意力区域主要集中在人脸与其背景之间的边界区域。这表明本文方法通过检测换脸视频帧中的合成人脸与周围环境的不连续特征判断是否为换脸合成。

图6 本文方法在FaceForensics++上的Grad-CAM图像
3.4 消融实验
本实验通过对在Celeb-DF数据集上进行消融实验来研究提出的模型的多任务结构以及各个模块的作用。为了验证CBAM模块引入给模型带来的性能提升,实验去除了CBAM模块,用ResNet50以代替,记为“-CBAM”。为了验证帧检测分支带来的性能提升,在“-CBAM”此基础上,去除帧检测分支,记为“-CBAM,-FP”,该模型与对比方法“ResNet50+GRU”相同。为了验证视频检测分支带来的性能提升,实验在“-CBAM”基础上移除视频检测分支,留下ResNet50、时序学习模块和帧检测分支,记为“-CBAM,-VP”。为了验证时序学习模块和帧间不连续信息在深度换脸检测中的作用,在“-CBAM,-VP”基础上又移除时序学习模块(TM),记为“-CBAM,-TM,-VP”。
消融实验结果如表3所示,“-CBAM”模型在视频检测任务上取得了0.95的ACC,0.95的AUC;在帧检测任务上取得了0.94的ACC,0.93的AUC。可以发现,相比本文模型,CBAM模块在图像检测任务带来了2%的AUC提升,在视频检测任务带来了1%的AUC提升。CBAM能提供模型在空间域和在通道方向的注意力学习能力,使模型能关注对决策有用的关键信息,例如换脸图像的不一致区域,以提高模型的性能。模型“-CBAM,-FP”在视频检测取得了0.92的ACC和0.90的AUC,相比“CBAM”视频检测AUC成绩下降了5%;模型“-CBAM,-VP”在帧检测任务取得了0.93的ACC和0.91的AUC,相比“-CBAM”,帧检测AUC成绩降低了2%。上述两个实验说明,本文提出的双分支网络得益于多任务学习的特殊优化方式,相比传统的单任务模型有更好的效果,两个任务在提出的联合损失的优化下,能力得到互相加强。模型“-CBAM,-TM,-VP”在帧检测任务取得了0.75的ACC和0.68的AUC。这种模型就是常见的使用CNN网络进行换脸图像检测的模型,其CNN网络为ResNet50,由表可知,相较于“-CBAM,-VP”,时序模块的加入使得模型AUC提高了0.23,充分证明了时序信息在换脸检测工作中的重要作用。
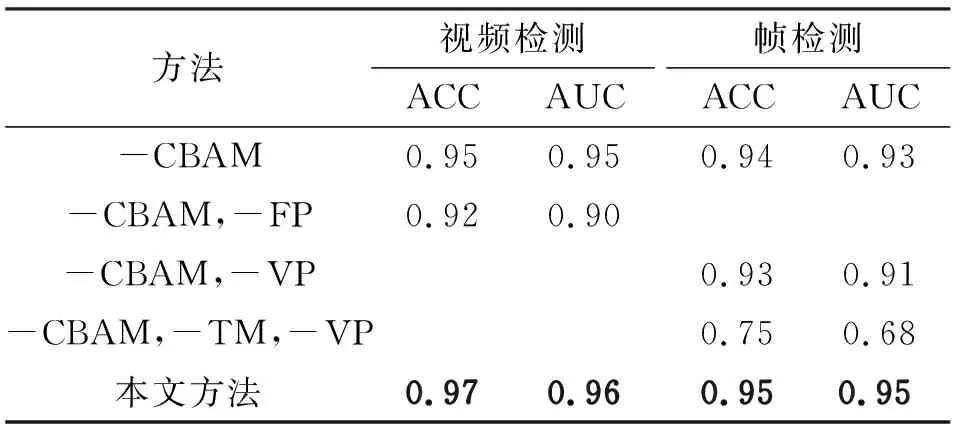
表3 各方法在Celeb-DF上的消融实验结果
3.5 模型鲁棒性分析
在实际应用中,视频传播前都会采用视频压缩算法以减少视频的冗余信息。然而,视频的压缩程度会对检测模型的性能有着显著的影响。为了验证本文方法在面对低质量视频时的鲁棒性,对比了和其他方法面对FaceForensics++低质量数据集 c40的性能,结果如表4所示。对比表2的结果可知,虽然本文模型在视频检测任务和帧检测任务中都有一定的性能下降,但仍在两个检测任务中都取得了0.92的AUC,远高于其他模型在c40上的性能。该实验充分证明了本文方法在面对低质量压缩视频时的鲁棒性。
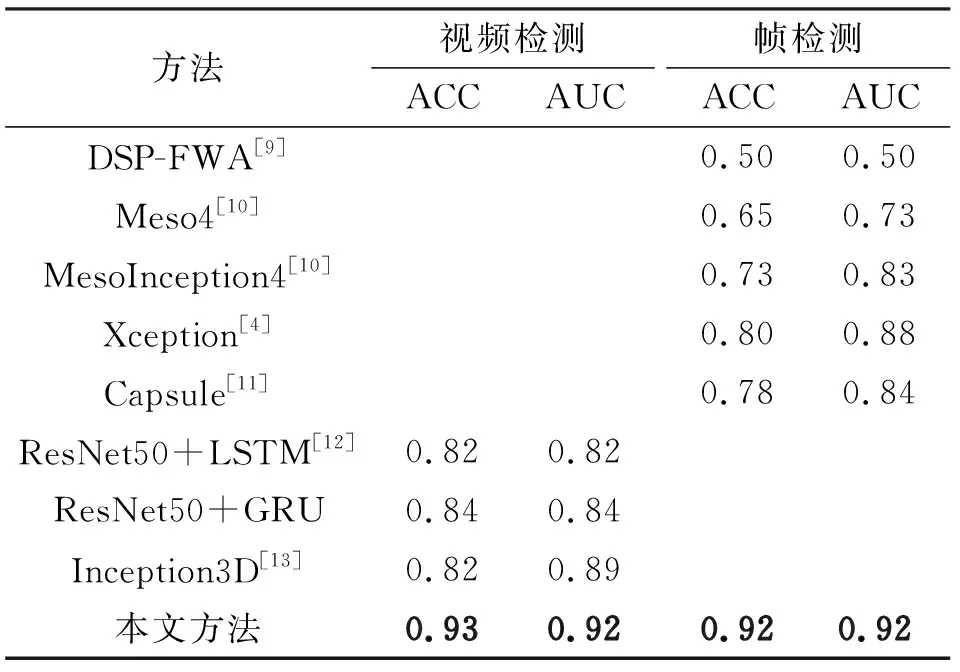
表4 各方法在FaceForensics++ c40上的性能对比
图7展示了模型应对来自Celeb-DF测试集的不同换脸视频样例的预测结果,其中包含了模型对不同视频不同光照、相同视频不同人脸朝向位置的检测结果。从图7(a)可得出,虽然本文方法在面对暗光场景时检测性能会有些许下降,但仍都给出正确的判断(预测概率均大于0.5),显示了模型对不同光照环境的鲁棒性。此外,图7(b)展示了模型面对相同视频不同人脸朝向的预测结果,证实了模型对不同人脸位置检测能力相同。

图7 模型在不同光照和人脸朝向对换脸图像的预测结果
为了展示环境物遮挡对模型的影响,使用了常用的数据增强方法Cutout[15]对来自Celeb-DF测试集中的换脸视频的每一帧使用随机位置的20 pixel×20 pixel的黑色方块进行遮挡,以模拟环境物体对人脸信息的遮挡。图8给出了本文方法对同一换脸视频在有遮挡和无遮挡时的预测概率,其中预测值大于0.5则表明模型判断为换脸视频帧,值越大表明模型越确定其为换脸视频帧。图8表明,当有环境在遮挡时,模型预测结果会有一定的下降,尽管如此,模型仍对这些视频帧仍做出了正确判别。该实验证实了本文方法对环境遮挡情况的鲁棒性。

图8 模型在有遮挡和无遮挡时对换脸视频的预测概率对比
4 结束语
本文提出了一种基于多任务学习和注意力机制的双分支深度换脸视频检测网络模型,克服了当前图像检测任务和视频检测任务的缺陷,在检测视频是否为伪造的同时能逐帧判断视频帧是否为深度换脸技术合成。此外,本文通过引入卷积注意模块和时序学习模块,检测每帧的局部空间的不连续信息和帧间时序不连续信息。在两个主流的公开数据集上的实验表明,本文方法在帧检测任务和视频检测任务中取得了优秀的成绩。而且,本文方法具有更好的泛化能力,在面对不同光照条件、不同人脸朝向以及低视频质量时表现出了良好的鲁棒性。
如今深度换脸检测仍面临着大量的挑战,例如,当模型在面对真实世界广泛存在的真假视频分布不平衡的数据时,换脸检测算法性能会有显著下降,因此,深度换脸中的不平衡学习将是后续研究的重点。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小雪花·成长指南(2022年1期)2022-04-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
计算机系统应用(2021年10期)2022-01-06
意林·作文素材(2021年23期)2021-01-22
甘肃教育(2020年22期)2020-04-13
学生天地(2019年28期)2019-08-25
第二课堂(课外活动版)(2016年2期)2016-10-21
