
基于量子免疫克隆BP算法的软件缺陷预测模型
2022-10-24 02:06:54吴克奇崔梦天
西南民族大学学报(自然科学版) 2022年5期
姜 玥,王 帅,吴克奇,谢 琪,崔梦天
(西南民族大学计算机系统国家民委重点实验室,四川 成都 610041)
软件在开发过程中不可避免地会产生各种缺陷问题.因此,软件质量问题也愈发重要.如何设计出高质量、可靠的软件产品成为当下业界的重要研究问题.软件缺陷的分布是不均衡的,因此,软件缺陷预测技术对于快速开发软件和提高软件系统的质量具有重要意义.文献[1]提出了基于朴素贝叶斯(NB)的软件缺陷预测模型.文献[2]整合了SVM和粒子群优化算法,建立软件缺陷预测模型.文献[3]利用优化的PSO算法调整BP神经网络.文献[4]提出了将改进的多种群量子遗传算法用于优化BP神经网络,建立网络流量预测模型.文献[5]提出了QPSO-BP的GNSS高程转换方法.文献[6]提出了基于优化问题的量子遗传算法.文献[7]采用量子粒子群算法优化BP神经网络,应用于软件缺陷预测.以上各种方法都在对标准BP神经网络的优化改进,避免在实际应用中BP神经网络算法的不足.为了避免标准BP神经网络算法在软件缺陷预测中,学习能力有限,准确率和精确率不理想,易陷入局部最优,本文提出将量子免疫克隆算法和标准BP神经网络算法结合,应用于软件缺陷预测中,取得了较好的学习效果.
1 免疫算法
免疫算法(Immune Algorithm,IA)的大致算法思路如下[8]:1)分析待求解问题,通过透彻的分析获得该问题的基本特征信息;2)处理该特征信息,把该特征信息经过必需的步骤转化为用来解析回答待求解问题的方案;3)将此方案已确定的规则转变为免疫算子进行操作.其中,人工免疫算法解决问题重点关注以下三部分:
1)抗原识别和初抗体的产生.根据待解决问题的基本特点,设计适合的编码规则,并按照该编码规则生成初抗体种群.
2)抗体评估.分别采用合适的计算公式计算抗体适应度和抗体浓度,据此评价抗体的质量,从中选出优势抗体,更新淘汰劣势抗体.
3)克隆选择.采用免疫选择,克隆变异和种群更新等免疫算子来模仿生物机体免疫应答中的操作,得出基于免疫系统的克隆选择原理的种群进化方法,从而达到对目标问题的寻优搜索.
2 量子免疫算法
量子免疫算法(Quantum Immune Algorithm,QIA)是将量子计算理论与一般的人工免疫算法相结合而提出的一种新型概率进化算法[9].该算法将量子计算的高效并行性引入传统免疫算法中,使其抗体种群多样性得到保障的同时,提高收敛速度,得到全局最优解;采用量子比特的概率幅对抗体进行量子编码,使抗体处于叠加状态.同时,将抗体通过量子旋转门和量子非门进行克隆变异操作,使抗体种群得到优化.
混沌现象是自然界中广泛存在的一种非线性现象,其具有随机性的同时又兼具内在规律.计算量子旋转门旋转角大小时,利用混沌系统原理,本文创新性地引入混沌优化系统中广泛应用的Logistic映射:

其中,μ是混沌吸引子,取值范围为[0,4],当μ=4时,系统进入混沌状体,产生混沌变量△n,其值在[0,1]区间内,△0取值范围在(0,1)的任意数值.
由此定义旋转角大小为:

其中,θ0调节因子,由查询表获得;△由式(1)得到;t为当前进化代数,T为总进化代数.在克隆更新时,抗体的适应度与最优抗体适应度差别越大,则旋转门的角度越大,其大小会随着搜索的进行而缩小.
3 软件缺陷预测模型的建立
3.1 量子免疫克隆算法
量子免疫克隆算法(Quantum Immune Clonal Algorithm,QIC)中,设量子抗体种群Q(t)={q1t,q2t,...,qnt},n为抗体种群大小,t为算法进化次数,qit为第i个量子编码抗体,m为量子抗体比特的长度[12].

QIC的算法步骤如下,流程图如图1所示.
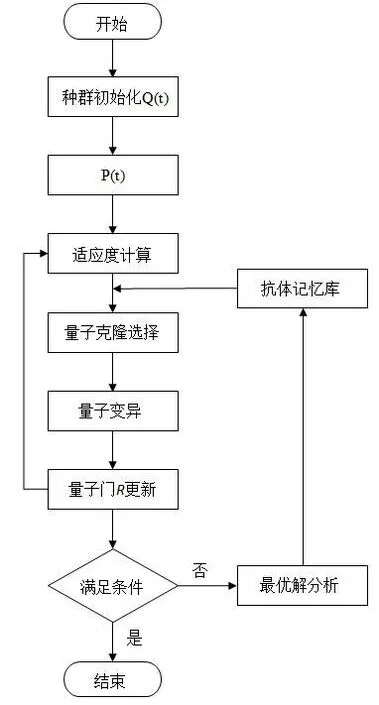
图1 量子免疫克隆算法流程图Fig.1 Flow chart of quantum immune clonal algorithm
1)初始化量子抗体种群,将n个抗体的2*m*n个概率幅均初始化为1/Sqrt(2),即每个抗体均以概率1/Sqrt(2m)处于所有可能状态的叠加态中,生成并初始化第一代量子种群Q(t),其中Sqrt为开根号函数.
2)对第一代抗体逐一测量,得到对应的确定解.观察Q(t)的状态生成二进制解集P(t)={p1t,p2t,...pmt},其中每个解pjt均(j=1,2,...,m)为二进制串,长度位m,其值由量子比特幅度|αit|2或|βit|2(i=1,2,...,m)计算所得,二进制的构成是产生随机数R[1,0],若R>|αit|2,取1;,否则取0;
3)计算解P(t)的适应度,获得当前最优解.
4)根据适应度值,对优势抗体进行量子克隆选择.
5)量子非门对抗体进行变异操作.
6)将抗体群通过量子旋转门进行更新进化操作.将二进制解集P(t)与当前最优解抗体进行比较,并使用量子旋转门R更新抗体群Q(t).
7)转(2),并且选择P(t)中的当前最优解,如果该抗体解比当下最优解更优,则更新记忆库,将其加入到记忆库中,来代替记忆库中原来的抗体,t=t+1,当满足条件或达到最大进化代数时,算法结束.
3.2 软件缺陷预测模型
本文采用量子免疫克隆BP神经网络算法(Quantum Immune Clonal Algorithm Based on BP,QICBP)[10],建立软件缺陷预测模型(SDPM-QICBP).该模型主要包括三部分:①对待预测的数据集进行预处理,使用归一法进行处理,提升算法效率;②执行量子免疫克隆算法,在全局范围内搜索,获取最优值并使用该值对BP神经网络的权值和阈值进行优化;③将处理后的数据集分为学习样本与测试样本,利用所提出的软件缺陷预测模型进行训练和测试.QICBP算法步骤如下,SDPM-QICBP的流程图如图2所示.

图2 SDPM-QICBP模型流程图Fig.2 Flow chart of SDPM-QICBP model
1)构建BP神经网络,规定输入输出.对MDP数据集进行预处理,获得学习样本与测试样本.
2)随机产生初始种群Q(t),对BP神经网络的权值和阈值编码.
3)根据数据集确定适应度函数,计算适应度值,评估输出值.
4)将BP神经网络的输出进行解空间变换,得到初始种群的全局最优解.
5)将种群中的抗体的概率幅通过量子旋转门进行遗传操作(克隆选择和变异),实现种群更新.
6)若误差或者进化次数满足进化要求,则转7),否则转3).
7)解码QIC算法搜索的最优解,用于BP神经网络初始权向量.
8)训练BP神经网络,直至满足需要.

算法1(QICBP):基于量子免疫克隆BP算法(Quantum Immune Clonal Algorithm Based on BP,QICBP)输入:样本数据集输出:分类集步骤:1.Normalize(Input_train); //归一化输入数据2.Normalize(Output_train); //归一化输出数据3.CreatBP; //构建神经网络4.t=0;5.Initialzie; //初始化种群6.ChromeCode; //种群编码7.Compute_Fitness; //抗体适应度评估8.KeepBestIndividual; //保留最优抗体9.While(MinErr<ε||t<T) //种群更新10.{t=t+1;11.ChromeCode 12.Compute_Fitness;13.Update; //通过量子门更新种群14.KeepBestIndividual;15.}16.x=Zbest;17.TrainBP; //训练BP神经网络
算法1中,input_train、output_train是训练输入、输出原始数据,ε为误差阈值,T为总进化代数,Zbest为最优参数.
命题1算法1的时间复杂度为O(N2+MN2),其中N为种群大小,三层神经元数量分别为N1,N2和N3,样本数为M.
证明:寻找最优抗体的过程是双重循环,两层循环分别扫描N次.因此,量子克隆寻优的时间复杂度为O(N2).
对三层BP神经网络,设每层神经元数量分别为N1,N2和N3,则M个样本的前馈计算时间复杂度是O(M*(N1*N2+N2*N3))=O(MN2).
综上,算法1的时间复杂度为O(N2+MN2).
4 实验与性能分析
为了验证和比较算法的性能和有效性,将SDPMQICBP模型和传统方法的实际运行效果进行了实验和讨论,采用了Windows10操作系统,Visual Studio2019.
实验采用NASA提供的MDP软件缺陷基础数据集[11],其含有13个子数据集,每一个都来源于实际开发项目,大部分采用C/C++语言编写.MDP数据集拥有良好的真实性,可以清晰地描述软件系统内部的软件缺陷信息,且已有多个机构对其进行了软件缺陷分析和预测等相关信息.数据集的每条记录作为一个样本.数据集部分信息如表1所示.由表1知,KC4数据集记录过少,因此,实验选择其他12个子数据集.学习样本集和测试样本集记录数为1∶1,学习样本随机选择[12].
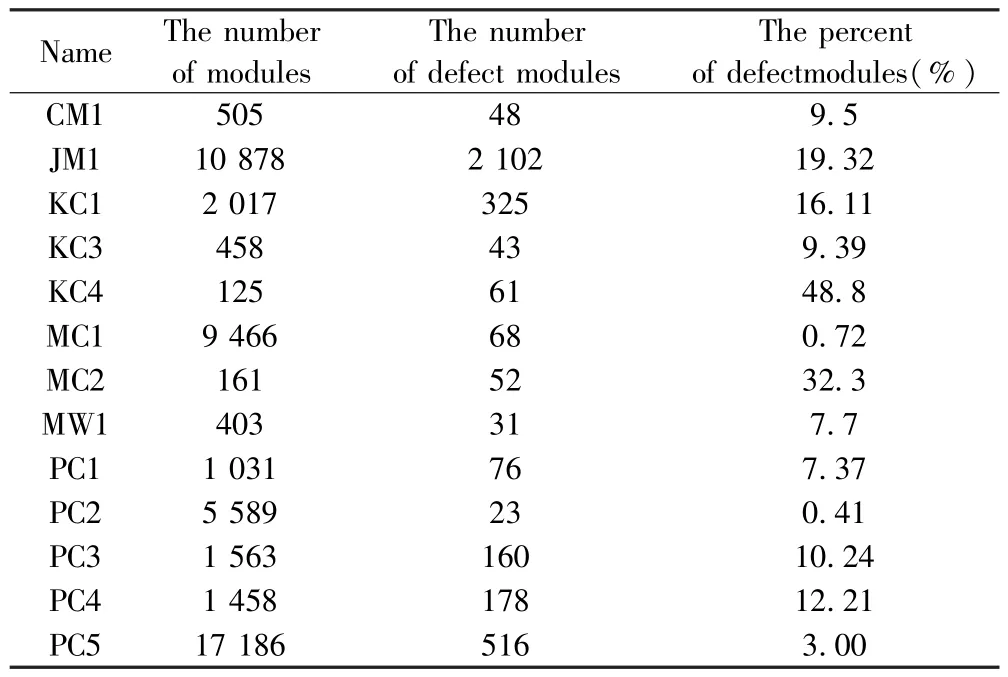
表1 实验数据集Table 1 Experimental dataset
4.1 评估指标
本实验的性能评估采用准确率和精确率,以上指标是从混淆矩阵中推导出来的[13-15],混淆矩阵如表2所示.

表2 混淆矩阵Table 2 Confusion matrix
为了方便描述,定义了以下指标.
定义1设TP,FP,FN和TN分别为表4所示.
①(准确率)设Acc为准确率,则

②(精确率)设Pre为精确率,则

4.2 实验结果分析
对数据集采用归一化方法进行处理,将标准BP神经网络算法,朴素贝叶斯(Navie Bayes,NB)和QICBP算法建立的软件缺陷预测模型进行对比,分类预测结果如表3所示,标准BP神经网络算法和QICBP算法迭代次数如表4所示.

表3 算法预测结果Table 3 The prediction results among BP,NB and QICBP

表4 算法迭代次数Table 4 The number of iteration between BP and QICBP
由表3知,SDPM-QICBP模型预测的准确性达到75%以上,其中PC2的预测正确率达到95%,表明SDPM-QICBP模型具有较好的学习效果.以子数据集CM1为例,QICBP预测的准确率达到80%且精确度达到88%,而采用标准BP算法与NB算法后的分类准确率仅为74%和75%.QICBP算法的性能优于标准BP算法与NB算法,即QICBP算法对软件缺陷的预测能力比标准BP算法与NB算法更强,说明QICBP算法有效.在观察分析其他子数据集的实验结果,也可得到同样的结论.
实验结果的精确率对比说明QICBP算法的最优解具有全局最优性,这是其他两个传统算法所不具备的.本文算法在大部分数据集下,其准确率和精确度均优于其他两个传统算法.
由表1知,子数据集MC2共352条记录,相对较少,但实验准确率也达到83%,这表明在样本数量较少的情况下,QICBP算法依然具有强的稳健性,获得较优的预测性能.
但是,子数据集KC1、PC1等极少数几个的实验结果中,QICBP算法的准确率和精确度并未同时提高,这是由于该预测模型在学习和预处理过程中样本中正误模块数量的差异造成.
由表4知,QICBP算法和标准BP算法相比,迭代次数降低11%以上,表明OICBP算法在先对进入BP神经网络的数据精选后,会明显缩短迭代次数,找到最优解,说明该算法能有效地改善标准BP神经网络算法用于软件缺陷预测.
5 结论
传统算法在软件缺陷预测上存在着学习能力不足,不能很好地保留优势抗体,性能指标易陷入局部最优.本文将QIC算法引入到BP神经网络算法中,发挥免疫的抗体优势,利用QIC算法对进入BP神经网络的参数精选,设计了QICBP算法;将该算法应用到软件缺陷预测中,设计了SDPM-QICBP模型,取得到较好的结果.
下一步的工作,将在本文的基础上,将基因表达式编程算法引入到BP神经网络算法中[16],扩大数据集范围,使之在软件缺陷预测上取得更好的性能.
猜你喜欢
青少年科技博览(中学版)(2023年3期)2023-05-11 07:36:58
今日农业(2022年15期)2022-09-20 06:54:16
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
小学科学(学生版)(2020年1期)2020-01-19 06:02:08
科学大众(中学)(2019年2期)2019-04-08 02:26:40
红土地(2018年7期)2018-09-26 03:07:38
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
西安工程大学学报(2016年6期)2017-01-15 14:08:28
电脑与电信(2014年10期)2014-03-13 08:18:44
