
融合注意力机制的深度学习推荐模型
2022-10-24 02:07:06蔡利平周绪川戴涵宇
西南民族大学学报(自然科学版) 2022年5期
于 蒙,蔡利平,周绪川,戴涵宇
(西南民族大学计算机系统国家民委重点实验室,四川 成都 610041)
近年来,网络应用尤其是移动应用的快速发展[1],使得人们能够方便地浏览大量的网络信息资源,如何为用户从海量的信息资源中推荐符合其需求的资源(如商品、电影、书籍等)成了目前研究者们关注的问题之一,推荐系统可以有效地对信息进行过滤和筛选,帮助用户以个性化的方式来检索符合其需求的信息资源,缓解信息过载(Information overload)[2]的问题.推荐技术经过不断的发展和更新,已在电影、音乐、电子商务、社交网络等领域广泛应用.协同过滤算法(Collaborative filtering,CF)被提出后,推荐系统逐渐成为一个新的研究热点,同时也面临着数据稀疏问题(用户对推荐项目的评分数量太少)和冷启动问题(新的推荐项目和新用户无评分数据).
深度学习(Deep learning,DL)是具备识别、分析、计算的机器学习算法,为缓解数据稀疏和冷启动问题带来了新的机遇,2015年以来,该算法已经在语义挖掘、人脸识别、语音识别等领域广泛应用,深度学习模型的逐渐成熟为推荐系统的发展带来了新的机遇.2016年,ACM推荐系统年会上Song等人[3]指出将深度学习和推荐系统融合作为推荐系统未来研究的重点,国内外的学者们和研究机构针对这一研究热点展开了深刻探讨.2017年以来机器学习方向的顶级会议(如:ICML、NIPS、COLT等)中有关深度学习的个性化推荐的相关文章逐年增加.2019年,文献[4]的研究认为深度学习能够从数据中自动学习特征的不同层次表达和抽象,是解决传统推荐技术出现的冷启动、数据稀疏等问题的有效策略.利用注意力机制针对电影海报信息进行提取,提出了一种结合多源信息的深度推荐模型.在最后进行了实验设计与分析,证明该推荐模型在推荐效果方面的优越性和有效性.
1 相关工作
目前研究大部分研究都更关注在电影预告片[5]或情节概要[6]的分类上,电影海报是体现电影内容和感情色彩的重要形式,往往通过海报中局部的某个细节信息就能判断出电影的可能类型,电影海报能直接影响到用户对电影的第一印象.因此,对电影海报信息特征提取的程度决定了推荐效果.文献[7]采用RAKEL集成的方法,使用Naive-Bayes、C4.5决策树和k近邻作为分类器,并使用Dominant Colors、GIST和Classemes方法从电影海报中提取用于分类的低层特征.在之后研究中,Ivasic-Kos等人[8]从海报中提取了颜色、边缘和纹理等特征,并且还把海报中的人脸数量也被用作分类的额外特征.此外,利用向量空间模型[9]提取了摘要的文本特征,其中使用的支持向量机(support vector machine,SVM)是根据海报和概要的特点进行的分类,但是此研究中类别的数量仅有4个,没有进行多标签分类.这种方法具有比神经网络计算简单、训练容易的优点,但仅限于对低层特征颜色进行评估,并不能真正反映出海报中的高层特征.为了解决此类问题,一些研究开始采用深度学习模型对海报中的更深层次的特征进行提取.对于电影海报的处理,大部分研究是对VGG、ResNet模型调参再输出分类结果,判断预测准确度.在国外研究中,Barney等人[10]测试了几种分类方法,包括k-近邻、一个改进的ResNet-34 CNN和一个具有自定义架构的CNN.尽管他们的评估范围很广,但用于训练他们的神经网络的损失函数不能补偿其他电影类别中海报数量不足情况,这可能会导致他们的预测错误.Chu等人[11]设计了一个复杂的结构,将CNN和一个YOLO对象识别器结合起来进行分类.尽管这是一个多标记分类问题,但它们模型中的最终全连接层的输出是通过softmax函数激活的.为了在之后能够获得多标签输出,输出向量中的每个标签被赋予不同的阈值,并且每个类别的阈值通过一个单独的算法来选择,使得训练过程中输出的预测向量与真实值向量之间的距离最小,这种设计可能导致性能下降,因此,在电影海报处理过程中,仍存在一些问题导致分类效果不佳和提取出的特征向量语义不丰富的问题.
本文提出了融入混合注意力机制的残差网络模型(ARN)对电影海报特征进行学习,其不仅对Res-Net50进行改进,并且设计高效的注意力模块,设计的ARN有两个用途,第一是通过针对一部电影对应多个电影类型的多标签情况,以电影海报分类准确率的提升来证明ARN在电影海报处理方面具有更好的效果,能够提取到带有更丰富含义的特征向量;第二是通过去掉ARN模型的全连接层中的最后一层,将提取出来的海报的特征向量融入推荐模型中,能够为推荐算法提供更多的初始信息,达到进一步提高推荐算法的准确度的目的.
1.1 基于注意力机制的推荐
近年来,注意力机制的神经网络能够去自动关注图像中重要的区域,给其分配更大的权重,因此,注意力机制在图像识别任务中广泛使用.在2017年,Momenta团队提出的SENet注意力模块[12],此模块能够与多种神经网络结合,在ILSVRC竞赛中取得了图像识别任务的冠军.该模型主要是能够自动地学习到在通道域上的特征信息,通过对不同重要程度的通道分配不同的权重,去增强对提升识别效果有用的部分.1.2 ResNet随着深度网络的发展,人们想通过增加网络模型的深度去提高训练的效果,但人们发现,随着深度的增加,深度神经网络很难训练,甚至准确性还开始下降.那么为了解决这一问题,ResNet[13]应运而生.在ILSVRC 2015和COCO 2015的比赛中,ResNet都以很大的优势获胜.ResNet主要特点在于残差网络结构的引用,残差块能够学习真实输出的残差.
2 海报信息特征提取
目前对电影海报特征处理的方式从传统的基于像素灰度的算法转变为了基于深度网络模型进行特征提取和分类的方式.然而,对电影海报特征提取的深度模型普遍存在以下问题:深度神经网络训练特征的过程仅仅是将海报输入到卷积层中通过映射的方式再逐一传递到下一层中,忽略了训练过程中对权重高的局部区域的关注,导致最终提取出来特征缺乏精细化的表示能力,进而影响提取出来的海报特征.本文重点是解决当前电影海报特征提取过程中如何着重关注到带有更丰富的含义且权重较高的局部区域.
2.1 改进的注意力机制模块
注意力模块主要目的是增强电影海报影响力大的区域权重,从而大大增强神经网络对于局部重点区域的判别,提高海报分类和特征提取的性能.其主要流程是将卷积神经网络中的各层中提取出来的海报特征图作为原始特征图,然后在不同维度方向上学习出针对海报不同区域的不同的权重值,将这些学习到的权重值与原始特征图融合后,替代原始的特征图,进而得到表征性更强的特征,分为2个模块:通道注意力模块和空间注意力模块.
2.2 通道注意力模块
通道注意力模块的设计主要是以SENet模块为基础搭建的.首先在此定义从卷积层中的某层提取出来的海报原始特征图为.其中W×H表示特征图F在空间维度上的大小,C表示特征图F在通道域上的维度.对在SENet通道注意力模块的基础上进行改进,选择一种性能更高效的通道注意力模块,其模块的结构图如图1所示:
由图1可知,在该通道注意力模块首先采用多尺度池化的方式,分别使用平均池化和最大池化的方式,将原始特征图F在空间维度上降维为两个大小为1×1×C的和其中FA是平局池化的到的特征图,FM是全局池化得到的特征图.这里采用两路池化的方式,相比SE模块是为了能够在空间维度上提取到带有更多信息的特征图.然后分别把这两个池化的结果输入到两个1×1的卷积层f和f′中,去学得共享卷积层后的重新分配的权重后得到的特征和.最后将X1和X2对应元素加和并通过sigmoid函数合并后映射,生成该通道注意力模块在空间域上的注意力权重,再将其与原始特征图F按照点乘的方式得到新的注意力特征图F,去替换原始特征图F
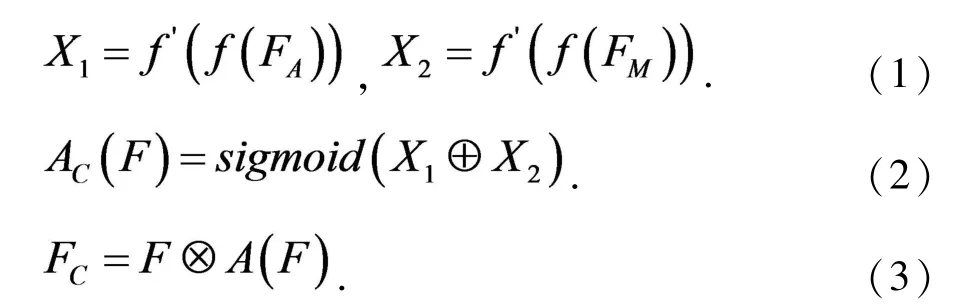
2.3 空间注意力模块
设计的空间注意力模块的过程如下,如图2所示:
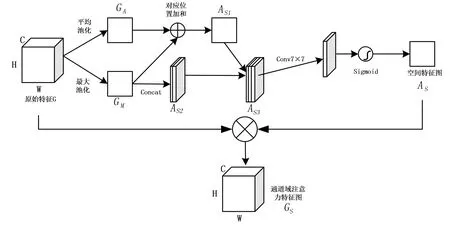
图2 改进的空间注意力模块Fig.2 Modified spatial attention module
1)采用多尺度池化的方式,分别使用平均池化和最大池化的方式,将原始特征图G∈RW*H*C在通道维度降维,得到两个大小为H*W*1的GA∈RH*W*1和GM∈RH*W*1.
2)将GA和GM并行处理.其中,GA沿着通道维度方向进行求和得到特征图As1∈RH*W*1,GM将两个池化结果沿着通道维度方向进行连接操作(concatenation)拼接得到特征图As2∈RH*W*1,并通过concatenation的方式沿着通道维度将As1和As2组合得到As3∈RH*W*1.
3)使用一个7×7的卷积核f对As3卷积,将维度压缩为H*W*1,并通过Sigmoid函数激活,生成该空间注意力模块在通道域上的注意力权重As∈RH*W*1,再将其与原始特征图G按照点乘的方式得到新的注意力特征图Gs∈RH*W*C,去替换原始特征图G.
4)由于Gs是在G的基础上,在空间域上学习过权重分配得到的,那么用Gs来替换G能够加强在空间域上对海报的关键局部特征的识别能力.对空间域上注意力模块的添加注意力机制,其模块结构如图3所示:

图3 混合注意力模块Fig.3 Hybrid attention module
2.4 混合注意力模块
将上述两个改进后的注意力模块串联起来得到 一个混合注意力模块,该模块能同时从通道维度和空间维度上学习到整体的特征权重,进一步提升对海报的关键局部特征的识别能力.其混合注意力模块结构如图4所示.
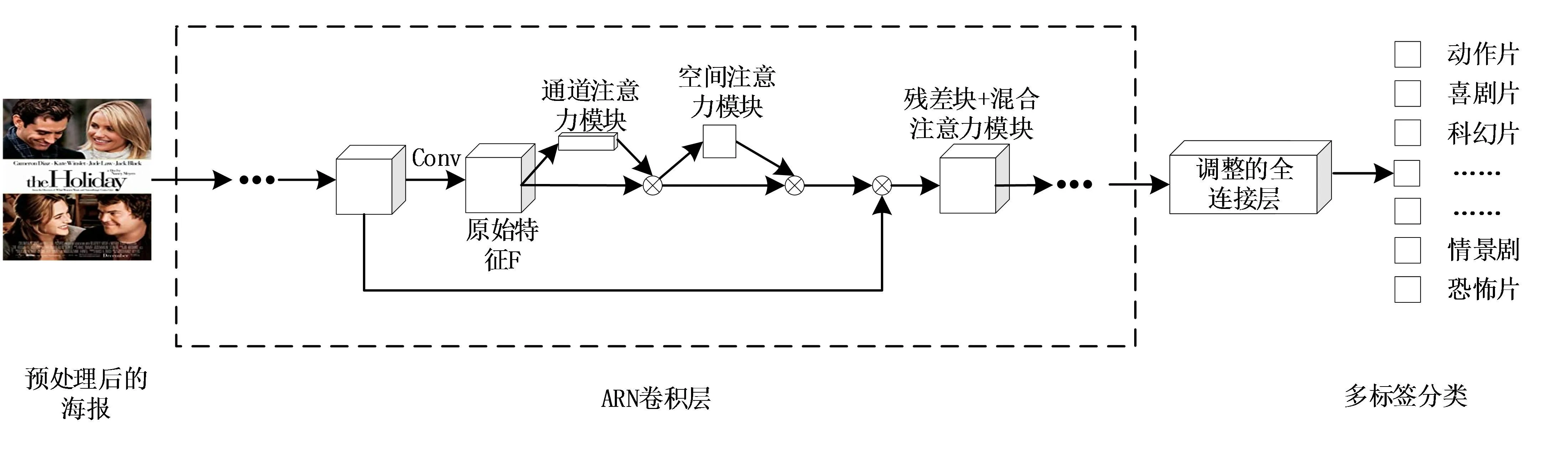
图4 ARN网络模型Fig.4 ARN network modle
由上图可以看出,混合注意力模块首先将原始特征图F输入到改进的通道注意力模块中得到通道注意力特征图FC,再将FC输入到改进的空间注意力模块得到空间注意力特征图FS,同时这个FS就是该混合模型最终想要的兼顾通道维度和空间维度的注意力特征图.
2.5 融入混合注意力机制的残差网络模型(ARN)
将上文设计的混合注意力模型与ResNet50结合,设计了ARN网络模型,主要是用来证明ARN在电影海报处理方面与传统的海报处理方法相比具有更好的效果.
ARN模型首先将预处理好的海报送入网络中,从各卷积层中提取出特征图,将其送入混合注意力模块分别学习中通道域和空间域中带注意力的特征图,之后再通过将其按照多标签分类的策略,输入到改进后的全连接层中,用sigmoid函数去独立预测每个类别的概率.ARN网络模型结构如图5所示,模型首先对电影海报数据进行处理;接着针对电影海报局部细节特点,将混合注意力机制模块融入改进后的Res-Net50网络模型中,让其能够在重要的局部信息处分配更大的学习权重;最后针对电影海报的多标签分类任务设计分类器和损失函数,达到分类效果,提高预测电影类型的准确率.
图5 NeuralCF模型Fig.5 NeuralCF Model
ARN模型结构主要是由混合注意力模块和Res-Net50组成,并将混合注意力模块嵌入到ResNet中的每一个残差块中.为了去控制网络的输出,就需要利用损失函数的作用,用预测值与输出值计算出来的损失值大小去判断模型性能的好坏.针对电影海报多标签分类任务,由于本文选用的多标签分类方法是Binary Relevance,因此将ResNet50模型使用的softmax层改为sigmoid层,并将损失函数从交叉损失熵改为二分类交叉熵(binary cross-entropy)作为训练过程的损失函数,其过程先单独计算每个电影类型的损失值,再根据每一种类型计算出来的损失值加和求平均,其损失函数表示如下.
经过通道注意力模块能够得到通道注意力特征图Fc,再经过空间注意力模块能够得到空间注意力特征图Gs,此时的特征图也是混合注意力特征图.接下来再通过与残差块的直接映射部分对应元素相加(addition)操作得到,通过ReLu激活函数,就能够得到此残差块的输出值为:

继续在ARN上反复地做这样的操作,最终将对于ARN网络提取出的电影海报特征可以表示为:
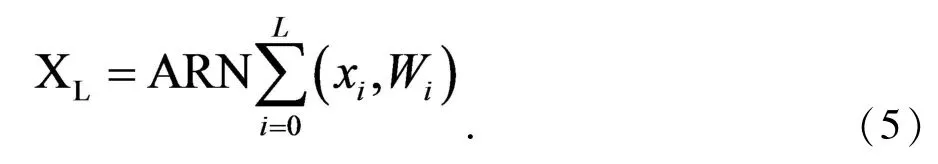
其中XL表示最终提取到的海报特征向量,L表示融入混合注意力模块的残差块的累加次数,Wi表示每个残差模块的权重矩阵.
3 融合多源信息的深度推荐模型
本节设计的结合多源信息的深度推荐模型,主要将深度学习技术中学习和提取特征的能力结合到推荐模型中,针对不同类型的用户、电影数据信息采用专门的网络模型将低纬稀疏的特征转变为高维稠密的特征,再将提取出来的用户、电影特征向量采用非线性的手段去得到它们的交互信息,实现更准确的预测.最后再利用神经同过滤模型NeuralCF的思想,将用户特征向量和电影特征向量通过MLP的方式,去解决仅仅使用矩阵分解中的简单的内积操作导致学习性能不足的问题,达到理想的推荐效果.
在本节设计的结合多源信息的深度推荐模型使用来进行评分预测任务,因此利用逐点损失,使得预测出来评分值与真实评分值误差最小,选用的损失函数的目标公式如(6):
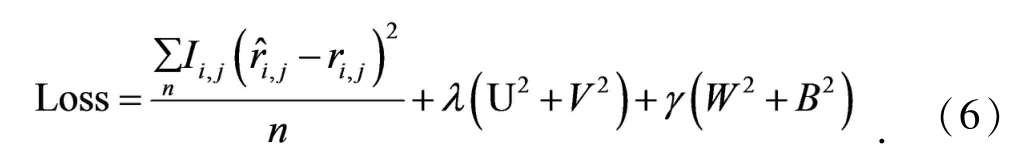
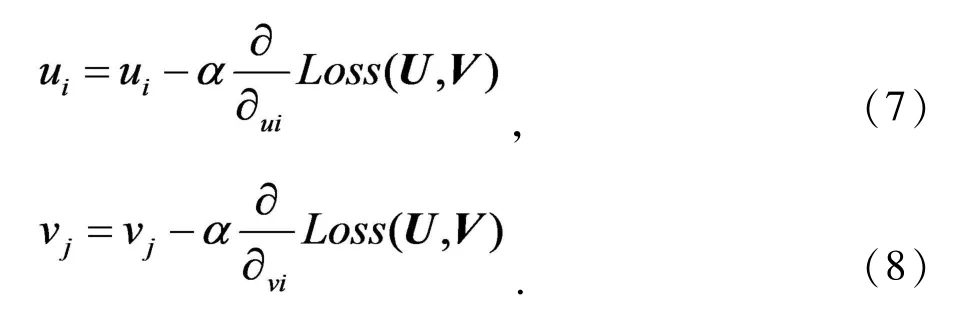
最后通过反向传播算法,使U或者V固定,交替更新变量,就能够求解到Loss的局部最优.结合多源信息的深度推荐模型的描述为:

算法1 结合多源信息的深度推荐模型Input:用户信息、电影信息Output:推荐模型的预测值images/BZ_87_724_1487_768_1539.png1初始化W、b;提取用户属性信息images/BZ_87_879_1547_914_1594.png、电影属性信息images/BZ_87_230_1602_264_1650.png;通过ARN训练电影海报信息XL;2通过结合多源信息的深度推荐模型将电影属性信息images/BZ_87_230_1703_264_1751.png直接映射为用户特征向量U,再将U、V通过MLP进行特征融合得到预测值.3通过公式(6)计算损失函数.5重复步骤3、4,直到算法收敛.6输出推荐模型的预测值images/BZ_87_708_1896_749_1945.png.
4 实验验证
4.1 评价指标
本文使用均方误差RMSE作为评判推荐模型指标的好坏,判断推荐模型的评分的拟合能力,RMSE值越小表示预测值和真实值之间偏差越小即模型的推荐效果越好,其公式如(22)所示,其中表示模型中用户i对电影j的预测评分,ri,j表示用户i对电影j的真实评分,N表示测试集中所有用户i对电影j已评过分的集合:
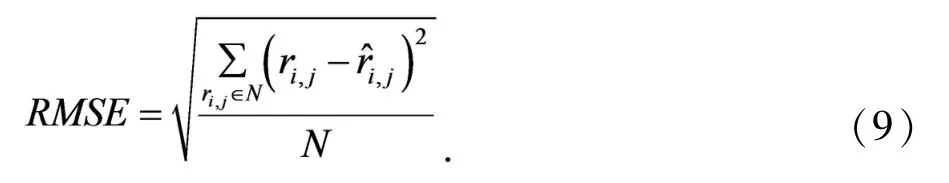
4.2 数据集与实验环境
4.2.1 数据集
本文首先对各种能够获取电影海报的网站进行了浏览,国内的各种视频网站中海报大小各有不同,国外的IMDB提供的电影海报的大小为182×268像素,虽然各种网站海报的像素大小有一定的区别,但是这不影响对于海报的使用,但由于国内的一些视频网站中的一些电影存在版权问题,若使用来自多个网站上的不同海报数据,则会存在因数据格式不同而导致海报不方便处理的问题.因此本文使用的是IMDB资料库提供的电影海报图像.本实验中使用了kaggle上公开的IMDB的数据集,其中部分数据如图6所示,其中包括了IMDB ID,标题,类别以及下载电影海报的链接等.
图6 IMDB部分数据格式Fig.6 IMDB partial data format
电影海报数据是按照MovieLens数据集中的电影数据通过爬虫工具收集到与电影对应的海报信息,数据集中的links.csv中有IMDB网站中海报的下载链接和标识符.其中movieId是对应每个电影的标签号,imdbId即为每部电影所在的链接地址.例如:电影标签号为1的电影是,则海报所在页面的链接地址为http://www.imdb.com/title/tt0114709/.为了对爬取的海报进行训练,需要对爬取的海报进行处理,使之能够与其对应的MovieID相匹配,对电影海报进行重命名.如图7所示.

图7 电影海报数据Fig.7 Movie poster data
同时,由于电影海报的多标签的特性,在这里采用Binary-Relevance分类的方式,利用独热编码将多分类标签转化为二进制值的向量.将一个电影多标签分类问题转化成m个二元分类.若电影属于某一类别,则值为1,否则为0,最后再针对每一列电影类别分别进行训练,提取对应特征向量.处理后的数据如图8所示.
图8 Binary Relevance分类的部分结果Fig.8 Some results of Binary Relevance classification
4.2.2 环境配置
实验是在编程环境为python3.5实现的推荐模型效果,深度学习计算框架为TensorFlow 1.3,系统为64位Windows10,具体的实验环境如表1所示:

表1 具体实验环境Table 1 Specific experimental environment
4.3 实验对比和分析
为了验证结合多源信息的深度推荐模型的预测的准确性,本节选取以下中模型作为基线模型进行对比实验.
1)MLP:此模型是NeuralCF模型中的一种形式,它采用了多层神经网络的形式,去替代用户、项目特征向量之前通过简单内积的组合方式,实验证明了MLP在数据集上表现出来的比较好的推荐效果.
2)CDL:此模型是协同深度学习模型,其特点在于能够提取文本信息中深层含义,将概率分解模型与深度模型结合起来,能够起到很好的推荐效果.
3)ConvMF:此模型被称作卷积矩阵因子分解模型,其模型在推荐效果中能够起到比较好的效果.其特点是将用来提取文本特征的CNN[14]用概率的思想融入到了PMF中,很好地处理了因为文本稀疏而导致的预测效果欠佳的问题.
为了验证融入多源信息的有效性,这里使用本文模型与仅使用用户、电影的交互信息进行对比,测试在不同的迭代次数在数据集ML-100k、ML-1m下对实验结果的影响.结合多源信息的本文模型,epoch的次数与RMSE的关系,如表2所示:

表2 epoch对RMSE的影响(融入多源信息)Table 2 The influence of epoch on RMSE(integrating multi-source information)
仅使用评分信息的模型,epoch的次数与RMSE的关系,如表3所示.通过表中看出,在相同数据集下,随着迭代次数的增多,RMSE的值会逐渐减少,并且达到一定的次数后,RMSE会趋于稳定,这说明了在保证了预测准确率的前提下,随着迭代次数增多,会导致模型耗时过久,效率低下.从表中还能看出,在迭代次数相同的情况下,本文结合多源信息特点推荐模型的RMSE的值始终要低于仅使用用户电影的评分信息的单一模型,预测的值越接近真实值,证明了本模型中结合多源信息的有效性.

表3 epoch对RMSE的影响(未融入多源信息)Table 3 The influence of epoch on RMSE(without multi-source information)
在数据集MovieLens-1M中,随机划分为不同比例的数据集对本文的深度推荐模型和以上基线模型进行对比.这里设置提取出来的用户、电影向量维度为200.通过设置不同训练集比例,分别为20%、40%、60%、80%在数据集上随机抽取数据作为训练集.在这四个比例的分配中,本文所提出的模型一直优于其他三个基线模型,并且随着数据量的增多,推荐的效果也越来越好,说明本文的推荐模型在融入多模信息后的推荐能力有了一定的提升.
由图9可以得知,随着训练集规模越大,实验中得到的推荐模型的准确度就越高,每个算法的RMSE都在减小.选取80%的训练数据列可以看到,本文模型相比MLP有7.3%的提升,相比CDL有4.7%的提升,相比ConvMF有1%的提升.本文提出的结合多源信息的深度推荐模型,与三个基准模型相比,在不同的训练比例中,都能够达到一个最好的推荐效果,说明即使在数据量比较稀少、训练不充分的情况下,本文的模型也能较好地提取到用户、电影特征向量,达到推荐目的.

图9 各模型在ML-1M不同比例的训练集比较Fig.9 Comparison of training sets with different proportions of each model in ML-1M
接下来实验将数据集分类成80%训练集以及20%对比测试集,同时为了验证算法的有效性,将本文模型与MLP、CDL、ConvMF在数据集ML-100k、ML-1m中进行对比实验,实验结果如表4所示.

表4 各模型在不同数据集上的对比Table 4 Comparison of Models on Different Datasets
上表可看出,本文的推荐模型与三个基准模型相比,在ML-100k、ML-1m数据集中的精度都能有较为理想的提升.在ML-100K上RMSE值下降了6.6%,这说明预测值和真实值之间的误差有所下降,推荐效果得到了提升.同样在ML-1m数据集上RMSE值下降了7.3%.因此,本文模型在ML-1m上的精度提升了6.6%,而在ML-100k上推荐精度提升了7%,说明当数据集的稀疏度越小,表现出的推荐效果越好.
通过以上实验证明了本文提出的融入多源信息的电影深度推荐模型,为不同数据类型设计的数据处理模块以及将多源信息与深度神经网络模型结合的方式,能够充分地提取和处理出用户、电影中内容更准确、更丰富的特征矩阵,一定程度上缓解了数据集的稀疏性的问题,提升了深度推荐模型的推荐性能.
5 总结
本文针对多源数据信息分别设计不同的处理模型.提出了融入注意力模块的残差网络模型(ARN)来处理电影海报,分别对通道域和空间域的注意力模块进行改进,并融合成为混合注意模块;接着将混合注意力模块融入改进后的ResNet50中,设计了ARN网络模型.设计了一种结合多源信息的深度推荐模型.通过与MLP、CDL、ConvMF在数据集ML-100k、ML-1m上的性能指标的对比实验,通过均方误差RMSE能够证明了模型中的有效性.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
