
手势识别关键技术研究
2022-10-24 02:06陈雅茜张代玮何志伟
西南民族大学学报(自然科学版) 2022年5期
陈雅茜,吴 非,张代玮,何志伟
(1.西南民族大学计算机科学与工程学院,四川 成都 610041;2.四川大学锦江学院,四川 眉山 620860)
在日常生活中,肢体语言是我们沟通交流中不可或缺的重要方式,很多沟通交流信息我们可以通过一些特定的手部姿势和躯体动作表达出来[2],从而达到简化沟通的目的.基于肢体语言的交互与传统键鼠交互不同,它摆脱了设备的束缚,让交互从屏幕扩展到3D空间,具有方便、高效等特点.
目前体感技术已经在游戏、医疗、教育等众多领域中得到了非常广泛的应用[3],基于体感技术的人机交互应用正不断地出现在人们的视野中.体感技术所涉及的学科和技术种类偏多,本文重点对手势识别进行研究,最后根据目前存在的一些不足,进行了分析和讨论,为未来研究方向提供思路.
1 关键技术
手势识别的主要步骤如图1所示,开始是通过摄像头获取RGB原始图像,然后在获取到的图像中进行手势分割,得到手部区域.接着在此基础上进行手势分析,分析手势特征,最后通过识别算法实现手势识别.在此流程中,手势分割以及手势识别是整体研究的关键点.
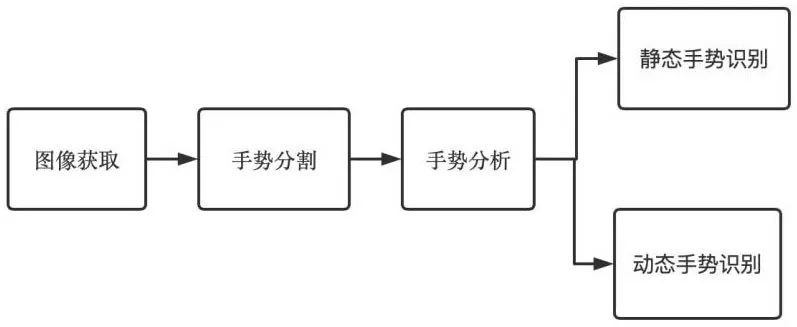
图1 手势识别的基本步骤Fig.1 Basic steps of gesture recognition
1.1 手势分割
手势分割的最终目的是采用一系列分割算法从图像中有效地分割出手部区域,将手势作为前景与背景进行分离.在手势识别过程中,手势分割是不可或缺的重要步骤,分割效果的优劣程度直接影响手势识别的效果[4].手势分割示例如图2.

图2 手势分割示例结果Fig.2 Gesture segmentation example results
目前,手势分割的常用方法主要分为以下两类:
1)基于肤色的手势分割方法
肤色是手势最基本的特征之一,肤色特征比较固定,跟手势动作无关,并且肤色检测的运算量较小,适用于快速的手势分割,同时也便于和其他算法相结合提高分割效果,因此基于肤色的手势分割方法具有较大的研究价值.
基于肤色的手势分割方法需要选择合适的颜色空间并建立合适的肤色模型,利用肤色与背景之间的区别完成手势分割的任务.目前常用于建立肤色模型的颜色空间包括RGB空间、HSV空间、YCbCr空间等[5].如果手势图像背景为单一且覆盖面积广与背景颜色相似,则可以选择HSV颜色空间.如果手势图像背景复杂,颜色区域较小且分散,则可以选择YCbCr颜色空间,该颜色空间下肤色聚类效果好,抗光照影响能力较强.
Shu等人[9]第一步先采用优化后的卡尔曼滤波器来预判手的位置,以降低相似肤色的影响,再采用TSL肤色模型完成手势区域分割.严秋锋等人[10]选用椭圆肤色模型,先采用色彩均衡化处理输入图像,再根据亮度将图像进行分段化,为降低光照的干扰,在高亮区延长模型的长短轴,以提高分割准确率.潘丹丹等人[11]选择YCbCr颜色空间并建立高斯模型,为提高模型的检测率,采用提高亮度阈值化,联合手势几何特征的方法,最终完成手势分割.黄沛昱,黄岭等人[11]在YCbCr空间下提出基于肤色质心与边缘自生长的分割算法,通过利用手势区域的质心降低后续计算量,再利用边缘自生长算法补全因光线不均匀,阈值选择不当等原因造成的局部断裂的边缘,最终更加快速准确地分割出手势图像.
此类方法在环境背景,光照条件较好的情况下,可以得到比较好的手势分割效果.对硬件要求也不高,没有较大的运算量.但现实情况存在各种因素,如检测背景复杂、光照过暗过强、光源色彩干扰等,这些影响因素都可能导致检测出的肤色不均匀,甚至是色彩偏移等情况,都会降低手势分割的分割效果.
2)基于深度学习的手势分割方法
随着深度学习的发展,越来越多的学者开始使用基于深度学习的方法代替传统基于肤色的方法来解决手势分割问题.基于深度学习的分割方法从输入图像中提取手势区域,关键在于卷积神经网络模型.Kim等人[12]提出了Network-in-Network的网络结构,该模型共包含4个卷积层和8个感知模块,主体是基于GoogleNet初始模块优化而来.Roy等人[13]提出一个分段检测的方法.为了确定手势的初始位置在第一阶段采用RCNN和Faster-RCNN目标检测模型.为降低手势位置定位的错误率,在第二阶段使用皮肤检测器提取肤色像素,以此提高识别准确率.Minhas等人[14]将手部肤色分割问题类比成语义像素分割问题,提出了SSS-Net(皮肤语义分割网络),该网络能够提取多尺度上下文信息,还能细化分割结果,提升分割精度.Amirhossein等人[15]提出了HGR-Net网络,采用双路网络,先进行语义分割,再对分割后的图像进行判定.该网络的手势分割准确率较高,且手势边缘清晰.张晓俊,李长勇等人[16]提出多特征融合的手势分割算法,其核心思想是融合肤色聚类特征结合深度学习网络对多种手势特征进行提取和训练,最终完成手势分割,算法平均识别度很高,具有很强的鲁棒性.
此类方法根据神经网络模型学习到的特征,能较准确地提取手部区域,并且在光照不均匀、复杂背景、类肤色区域等因素影响下,也能有效地完成提取.但在有些情况下,对于非训练集的测试样本,网络模型泛化能力较弱,手势分割效果不理想.
1.2 手势识别
手势识别中有两个关键的概念:手形与手势.手形属于静态手势,即用手的一个特定模样形状表示一个语义,手势则是以手在时间与空间上连续的轨迹表示一个语义,即动态手势.
1.2.1 静态手势识别
静态手势识别中最早提出的识别方法为模板匹配法[17].此方法是将输入图像与图像库模板进行比较,并计算相似度再进行分类.此方法的关键在于手势模板库的构建(示例如图3所示)与输入图像的处理.输入图像经过手势分割分离出手势区域,再通过图像二值化处理,凸显图像特征[18],再提取手势特征,最后通过模板匹配法识别手势.如图4所示.此方法在数据量不大的样本上,识别速度很快,抗光照干扰能力较强,但识别精度不高.

图3 部分手势模板库示例Fig.3 Examples of some gesture template libraries

图4 模板匹配示例Fig.4 Template matching example
静态手势识别也常采用基于几何特征的识别方法[19],几何特征主要为手指个数、手指夹角和手指间距等特征.但因为每个个体都存在差异,即使是相同的手势在上述几何特征中也会存在较大的变化,所以基于单几何特征的手势识别精度较低.为了提升该方法的分类精度,许多研究者考虑多特征融合,以结合多个几何特征进行识别.王艳、曹洁等人[20-21]通过结合手势指尖个数以及Hu不变矩特征,对特征距离进行加权并融合来识别手势.该方法通过多特征融合,虽然比单一手势特征方法识别率高,但却存在特征量增多,计算量增大的问题.张辉,邓继周等人[22]相继提出在结合多特征融合算法的情况下,分两层处理识别任务.提高识别率的同时,也降低了多特征融合带来的数据量增大、计算量增大的问题.此类方法在简单桌面背景和简单手势情况下,具有计算简单,识别速度快的优点.
1.2.2 动态手势识别
由于动态手势本身的多义性以及时空差异性,动态手势识别一直是一项极富挑战的课题.在识别动态手势的过程中,需要考虑空间上下文结合时序分析,先确定手势起始与最终位置[9],再通过手势分析提取的特征点结合时序连续图像进行拆分并逐帧分析.动态手势识别常用算法大概可以分为三种:基于状态图转移的算法,基于统计学的算法和基于深度学习的算法.
基于状态图转移的方法中,HMM(Hidden Markov Model,隐马尔可夫模型)是典型方法,它是时间序列的概率模型,对连续时序信号的处理有较好的表现,所以也广泛应用于动态手势识别领域.Chen等人[23]采用HMM来识别连续输入手势,构建了可以识别20种不同手势的系统,平均识别率在90%以上.Elmezain等人[24]利用HMM构建了实时识别孤立手势和0-9阿拉伯数字的应用系统,平均识别率分别达98.6%和94.29%.Hazmoune等人[25]在KNN(K-Nearest Neighbor,K邻近算法)结构中嵌入HMM,对阿拉伯数字进行识别,结果表明该融合方法有效.
基于统计学习的方法常用有SVM(Support Vector Machine,支持向量机)和KNN.Chen等人[26]利用Leap motion捕捉动作运动轨迹信息结合SVM算法对36个数字以及字母的手势进行识别,并获得了较高的识别率.Yu等人[27]研究了多特征融合识别技术,采用SVM算法的同时,结合高斯金字塔光流算法提取并处理动作轨迹特征,最后在决策层融合信息得到最终识别结果,实验表明,融合方法有效、识别率较高.Likhitha等人[28]提出一种基于皮肤颜色模型的数据库驱动手势识别方案,方案最后利用PCA(Principal Components Analysis,主成分分析)、KNN和SVM进行手势识别.实验表明在机器人领域中可以有效应用.
随着深度学习的不断发展,神经网络也逐渐进入研究者的视野.它学习和适应能力强,在多个热门研究领域中已广泛应用,在动态手势识别领域也深受研究者喜好.常用的神经网络包括CNN(Convolutional Neural Networks,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)、DNN(Deep Neural Networks,深度神经网络)和LSTM(Long Short-Term Memory,长短期记忆网络).Singh[29]使用3D-CNN网络处理ISL(Indian Sign Language,印度手语),实验表明该网络模型在准确率和精确率方面都有不错表现.Ye等人[30]提出了一种混合模型,3DRCNN(3D循环卷积神经网络)用于识别ASL(美国手语).通过多模态特征融合,3DRCNN集成了3DCNN和FC-RNN,其中3DCNN捕捉学习运动特征,FC-RNN捕捉学习时间特征.实验表明融合有效,提升了识别精度.
基于状态图转移和统计学的手势识别方法,能训练的样本量不大,无法应对较大的数据集,因此无法广泛使用.目前被广泛应用的是基于深度学习的手势识别方法.因为神经网络对样本特征有着很强的学习能力且对数据集有着很强的适应性.但在部分研究中为提取更多的手势特征,实现较高的识别率,需要设计堆叠更多的网络层.最终增加了运算量和硬件要求,难以保证手势识别的实时性.
动态手势识别常用方法对比如表1所示.

表1 动态手势识别常用方法对比Table 1 Comparison of common methods for dynamic gesture recognition
2 存在问题及展望
手势识别技术是一个很热门的领域,具有很大的发展前景,目前还存在以下问题亟需解决.
2.1 提高数据采集的有效性
目前,普通摄像头在采集数据时常会受限于环境光照、拍摄角度、图像分辨率、复杂背景等各种综合因素的影响,而无法有效地采集手势及姿态的各种信息,进而影响识别效果.对此可以选用深度相机(如Microsoft的Kinect设备和Leap的Leap Motion)来采集数据,深度相机又称3D相机,该相机能检测出拍摄空间的景深距离,采集深度信息,在光照不好的情况下也能完成采集工作,还能提供人体骨骼信息,可以在一定程度上降低数据采集任务的复杂度.
2.2 肢体遮挡问题
在正常交互过程中,难免会出现肢体遮挡的情况,其中包括自遮挡和外物遮挡.如果识别过程中出现这种情况,那么最终的识别率将会大幅度降低,所以研究肢体遮挡修复算法对手势识别技术应用的推广具有积极作用.对此,Facebook团队采用Megatrack类似的方法[31],构建3D手部模型,结合动作的时间连续性,模拟手部的形状变化,使得跟踪效果更为逼真,具体效果如图5所示.目前这只是一项前瞻性的研究,距离实用还有很长的距离,需要更深入的研究.
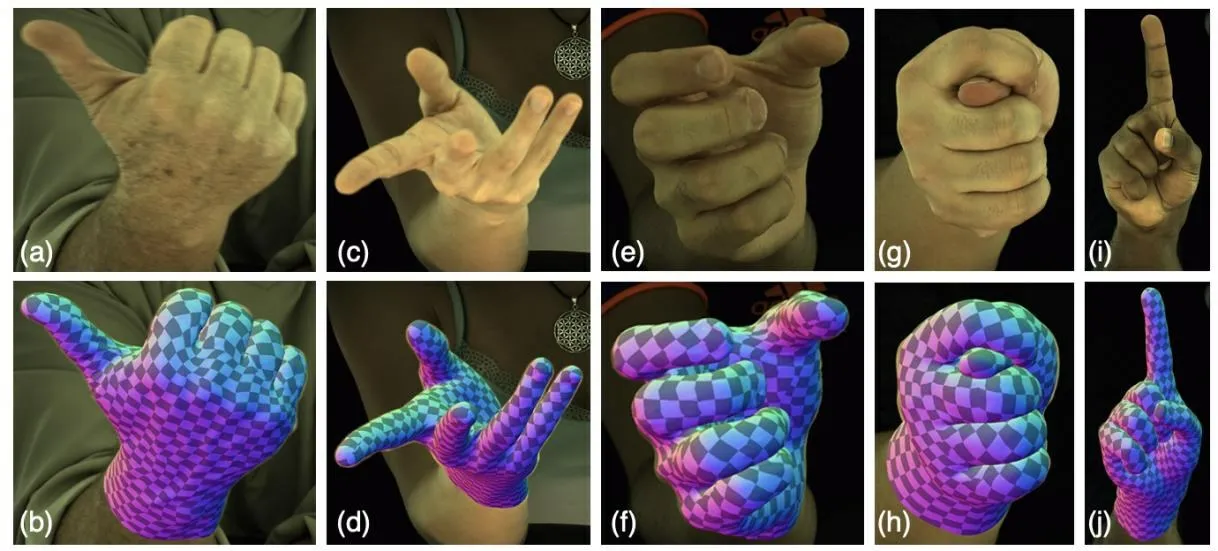
图5 Facebook构建的3D手部模型Fig.5 3D hand model built by Facebook
2.3 提高识别的准确性与实时性
基于手势识别技术的人机交互要想广泛应用于社会生活中,其准确性与实时性都必须要有所提高,以满足正常交互需求.目前针对单个识别算法的研究与优化,短时间都很难再有较大的突破.对此,部分研究者们走上了算法融合的道路,通过了解掌握各种算法的优缺点并将其融合.实验表明,在相同的数据集上,融合算法的识别效果往往会比单个算法识别效果好.例如CNN与BLSTM的结合,利用CNN处理空间特征,BLSTM处理时间特征,最后将两者结合起来,提升识别准确率.诸如此类的例子还有很多,所以通过算法融合来提高识别的准确性与实时性是值得研究的.
基于手势识别技术的人机交互是新时代人机交互中更为自然的交互方式,是一个极有研究潜力的热点方向.希望更多的研究者加入到这一领域来,使其得到更快速的发展.
猜你喜欢
文学港(2021年12期)2021-02-28
疯狂英语·新悦读(2020年4期)2020-06-18
好孩子画报(2020年3期)2020-05-14
计算机工程(2020年3期)2020-03-19
小天使·四年级语数英综合(2019年9期)2019-11-09
红领巾·萌芽(2019年9期)2019-10-09
中国听力语言康复科学杂志(2019年3期)2019-06-24
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年3期)2018-06-13
小学阅读指南·低年级版(2017年6期)2017-06-12
