
基于PCANet和SVM的病变眼底图像检测算法
2022-10-18 04:02杨得国马兰萍
江西师范大学学报(自然科学版) 2022年4期
杨得国,马兰萍,聂 毓
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
0 引言
糖尿病是由胰岛素不足或对胰岛素的抵抗所造成的一种葡萄糖代谢紊乱而导致高血糖的疾病.这会使糖尿病性视网膜病变患者的眼睛产生病变.
糖尿病性视网膜病变眼底图像检测可以看作一个二分类问题.有监督分类器的SVM为医学图像分类任务提供了一种通用且有效的检测方法,但它们需要大量带标签的数据,并且训练过程复杂、耗时.无监督的主成分分析网络(PCANet)虽然不需要进行标签训练,但不能提供较高的分类精度.为了在训练数据集较小的情况下实现医学图像的准确分类,本文采用PCANet和SVM相结合的模型,通过对彩色眼底图像视网膜渗出物检测,区分得到含渗出的病变图像和正常眼底图像.
1 SVM分类器
支持向量机(support vector machine,SVM)是一种二分类模型,其基本模型是在特征空间中定义的间隔最大的线性分类器,间隔最大使它不同于感知机[1].简单来说,SVM就是在多维空间中将数据单元表示出来,并对该空间进行分割的算法.
把实例的特征向量(以2维为例)映射为空间中的某些点,如图1中的实心点是一类,空心点是另一类.SVM的目标是制作1条线来更好地区分这2种类型的点,这样,即使出现了新的点,也能做出很好的对点分类.
支持向量机基于以下2个思想:边缘最大化和非线性核分类.假设一个由L标记的训练样本组成的训练集D={X,Y},x=(x1,x2,…,xl),Y=(y1,y2,…,yl),其中xi∈Rn,yi∈{-1,1},i=1,2,…,l.SVM模型分类的目的是从数据到标签获得一个分类器f:xi→yi(i=1,2,…,l).在机器学习中,分类函数的复杂性极大地影响了算法的性能.因此,在一般情况下,高度复杂的函数可以较好地拟合训练数据.若训练数据在特征空间中是线性可分的,则得到决策函数:
f(x)=wTΦ(x)+b,
其中w为权重向量,b为偏差,对于L标记的样本,yif(xi)≥1.对未标记的数据x,若f(x)>0,则数据被分类到class1,若f(x)<0,则数据被分类到class-1.
若分类问题在特征空间中不是线性可分的,则通过求解软边距优化问题得到最优分离超平面:
其中c是正则化参数,它决定了模型复杂度和分类误差的权重,ξi是xi的松弛变量,ξi≥0,i=1,…,l.上述问题的对偶优化问题为
这里K(xi,xj)是一个核函数,K(xi,xj)=Φ(xi)·Φ(xj),任何满足Mercers定理的函数都可以作为核函数,如高斯函数K(xi,xj)=exp(-‖xi-xj‖2/
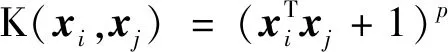
2 基于PCANet和SVM的病变眼底图像检测方法
2.1 糖尿病性视网膜病变眼底图像检测算法流程
预处理后的视网膜图像数据集先通过主成分分析网络(PCANet)进行特征提取.在该结构中,PCA学习2阶段的滤波器组,然后使用二值哈希和直方图对特征向量进行聚类,并将其作为输入,通过SVM分类器进行分类[2](见图2).

图2 糖尿病性视网膜病变眼底图像检测算法流程框图
2.2 眼底图像预处理
2.2.1 糖尿病性视网膜数据集 本文使用的数据分别来自DIARETDB1和E-Ophtha.DIARETDB1是糖尿病性视网膜病变数据库,该数据集包含89幅大小为1 500×1 152的眼底图像.所有图像均由数字眼底相机拍摄,视场为50°.渗出液的注释由4位独立专家手工完成并进行评估.其中45幅有渗出物,44幅无渗出物.E-Ophtha数据集包含47幅含有渗出物眼底图像以及35幅健康图像,图像分辨率为1 400×960~2 544×1 696.眼底图像的视野范围为35°~50°.表1给出了在每个数据集中图像的数量和分辨率.

表1 数据集
2.2.2 去除冗余背景 在本文的眼底图数据中,图像的格式并不统一,很多图像都是长方形.由于部分视网膜受拍摄设备的影响,所以图像会存在黑色边框.为了便于后续的分类,在进行图像预处理时,将图像裁剪为格式512×512的正方形,根据每幅图像背景的色度和中心色度,自动定位眼球位置,去除多余黑色边框(见图3).

图3 去除冗余背景图
2.2.3 通道分离 在眼底图像中,绿色通道常用于分析眼底和结构.如图4所示,绿色通道的细节特征比其他2个通道更清晰.因此,采用绿色通道作为渗出物检测的基本输入特征.
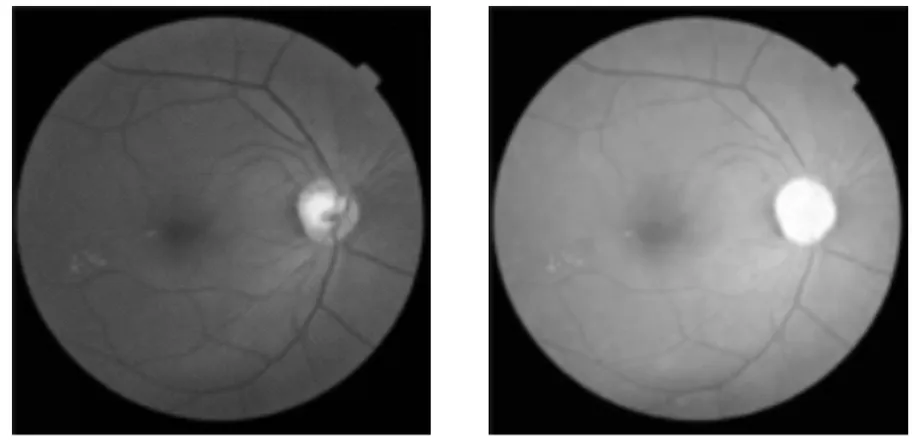
(a)RGB图像 (b)红色通道

(c)绿色通道 (d)蓝色通道
2.2.4 图像直方图均衡化 直方图均衡化(HE)是对比度增强最简单、应用最广泛的方法之一,直方图表示每个强度值对应的像素数,它表示具有特定强度的像素出现的概率,并提供有关图像全局外观的信息.在HE方法中,像素在整个动态强度范围内均匀分布.HE方法有2种类型:全局HE法和局部HE法.全局HE法根据整个图像的灰度内容,利用变换函数修改像素;而局部HE法是通过使用直方图强度统计来考虑领域内像素的均衡化[3].原始图像以正方形或矩形领域的形式划分为多个子块.在每个位置求出各领域内的点的直方图,并获得直方图均衡化或直方图规格变换函数.在重复这些步骤后,最终通过合并获得结果图像.图5表示绿色通道直方图变化.
2.2.5 主要血管分割 视网膜眼底图像血管检测是唯一可直接观察到的血液循环系统,也是糖尿病、动脉硬化症等临床诊断的依据,受到众多研究者的关注.在以往的研究中,虽然有许多血管的检测方法,但由于小血管与其周围区域的对比太低,所以这样可能会错误地判断了渗出物的位置.因此,本文对主要血管进行分割,血管图如图6所示.
M.A. Palomera-Perez等[4]利用结合图像特征值的多尺度方法提取血管,通过将原始图像I(x,y)与尺度为s的高斯核函数G(x,y)的2阶导数进行卷积,从而得到在图像中每个像素的Hessian矩阵.对于所得到的Hessian矩阵,分别进行特征向量和特征值的计算.
L(x,y)=I(x,y)⊗G(x,y),
其中G(x,y)=e(-x2-y2)/(2s2)/(2πs2),s是尺度参数,⊗是卷积符号.
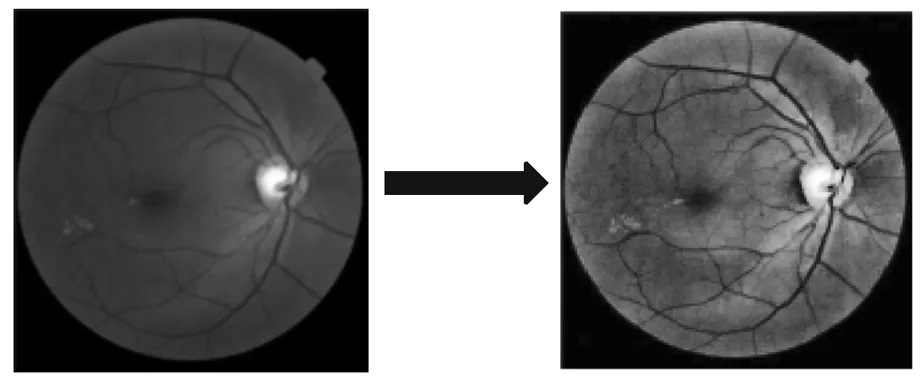
(a)绿色通道 (b)HE
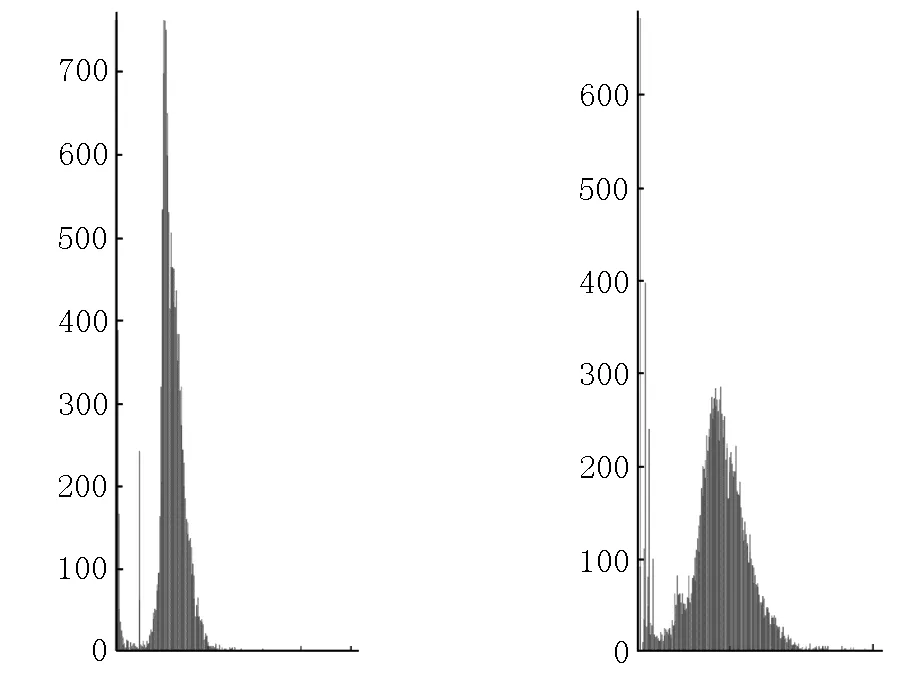
(c)绿色通道直方图 (d)增强后的直方图
计算强度图像的Hessian矩阵的特征值分别为
λ+=(Lxx+Lyy+α)/2,λ-=(Lxx+Lyy-α)/2,
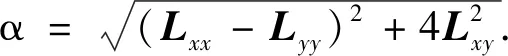
计算特征值的局部最大值为
λmax=maxs(λ+(s)/s).

图6 血管图
计算图像中每个像素处的2阶偏导数.阈值化处理每个点的最小特征值形成的图像,得到完整的血管结构.在多尺度图像分析中,图像被转换成一组派生图像,每一组图像代表原始图像(但在不同的尺度上).
2.2.6 视盘分割 视盘的定位与分割在许多计算机辅助诊断中起着重要的作用,本文将采用一种无监督视盘的定位和分割方法.视盘是视网膜眼底图像中一个比较明亮的部分,与其他图像有较高的对比度.因此,它比其他区域更能吸引人类的注意力.从显著性检测来看,它也比其他区域更显著.因此,使用最显著的像素来定位视盘,并使用显著值分割视盘.
首先,为眼底图像I生成显著性图S(见图7).自然场景图像的显著性检测方法有很多,但大多数显著性检测方法所采用的中心偏置先验在眼底图像中并不有效.同时,与复杂的自然场景相比,视网膜眼底图像中的内容是固定的.因此,简单的基于全局对比度的显著性检测方法就足以使视盘均匀突出、边界清晰[5].因此,可采用调频区域检测方法来生成视网膜眼底图像的显著性图.

(a)原始图像 (b)原始图像上的视盘区域 (c)检测到的视盘轮廓

(d)显著性图 (e)显著性图像上的视盘区域 (f)显著性图像上检测到的视盘区域
给定图像I,本文通过以下方法计算视场中每个像素的显著性值,计算方法为
S(x,y)=‖Iμ-Iwhc(x,y)‖,
其中Iμ是视场像素的平均颜色特征向量.采用Lab色彩空间,Iwhc(x,y)为原始图像高斯模糊版本所对应的图像像素向量值,‖·‖为L2范数.
为了减少渗出区等明亮区域的不利影响,不直接对显著性图进行阈值处理,而是先根据显著性图中最显著的区域定位视盘,然后通过阈值化将视盘从一个小窗口中分割出来,最后,对视盘中的空洞进行填充,根据分割区域的面积来判断得到的图像是否为视盘.若分割的区域太大或者太小,则就将其归类为背景区域,否则将它看作视盘.
2.3 PCANet和SVM结合的分类检测模型
将PCANet技术作为一种深度学习的方法,通过3个阶段对眼底图像渗出物特征进行特征向量提取,再利用SVM对数据集中的图像进行分类,模型结构如图8所示.
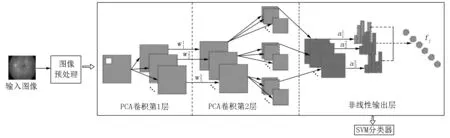
图8 模型结构图
2.3.1 PCANet特征提取 与经典的特征提取方法相比,基于深度学习的特征提取方法最大的优势之一是灵活性和分辨率,因为可以将更高层次的特征运用到多个层次的表示中,以提取图像特征的判别信息.PCANet技术为提取图像中的大部分信息提供了可靠的解决方法,可被用于更大范围的模式识别系统.与其他深度学习技术相比(如卷积神经网络(CNN)和深度信念网络(deep belief net,DBN)),PCANet方法具有更多的优点,非常适合纹理分析且更为简单.
PCANet可以看作是一个简单的卷积神经网络,它包括3个阶段,第1阶段和第2阶段是PCANet卷积滤波器,第3个阶段是二值哈希(生成非线性输出)和直方图.

第1个阶段.首先,在每个输入图像的每个像素周围进行一次k1×k2的块采样.然后,对于图像Ii,可以得到该输入图像所有重叠或非重叠的采样块,并对每个采样块进行向量化,Xi,1,Xi,2,…,Xi,mn∈Rk1k2,从每个窗口中减去窗口均值.对于所有由收集的patch组成的图像,将其矩阵放在一起,得到
假设第i层存在Li滤波器,计算XXT的特征向量,取前L1个最大的特征值对应的特征向量作为下一阶段的滤波器,如
mk1,k2将v∈Rk1k2映射到一个矩阵,ql(XXT)为第l个主特征向量,则每个主特征向量都捕捉到了所有移出的主要变化训练patch.
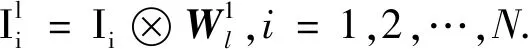

Y=(Y1,Y2,…,YL1)∈Rk1k2L1Nmn,
计算YYT的特征向量,取前L2个最大的特征值对应的特征向量,第2阶段表达式为
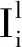
H(g)是一个函数,它可以将一个矩阵转换为另一个矩阵,该矩阵的值对于正元素取为1,否则为0.然后每个输出图像乘以一个权值.这将把输出图像转换为一个范围为[0,2L2-1]的整数.
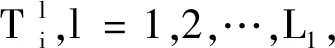
PCANet参数主要包括每个阶段的阶段数、过滤器数、过滤器的大小和局部直方图的块大小.由于PCANet是通过主成分分析而不是梯度下降得到滤波器的,因此,与CNN相比,PCANet在空间和时间复杂度上具有巨大的优势.
2.3.2 SVM分类 SVM分类器是一种有监督的机器学习算法,可用于分类和回归,并在模式识别中表现优异.SVM分类的基本思想是求解能够正确分割训练数据集并且具有最大几何区间的分离超平面;如图9所示,wx+b=0是分离超平面,对于一个线性可分离的数据集来说,存在无限个这样的超平面(即感知机),但是具有最大几何区间的分离超平面却是唯一的.对于输入空间中的非线性分类问题,可以通过非线性变换将它转化为某个维特征空间中的线性分类问题,在高维特征空间中学习线性支持向量机.
非线性SVM的算法过程如下:
1)选取适当的核函数K(x,z)和惩罚参数C>0,构造并求解凸二次规划问题
最终的分类决策函数为
2.4 实验与分析
2.4.1 评价指标 在本文中训练集和测试集分别由60%和40%的样本组成.该技术的实现使用Matlab软件.利用10种不同的训练和测试数据随机组合,研究了上述分类器的性能.
在所有医学图像分类问题中,误分类率是评价分类器性能的重要指标.本文通过衡量敏感性、特异性和准确性来评估该算法的性能.这可根据真阳性率(TP)、假阳性率(FP)、假阴性率(FN)和真阴性率(TN)来计算.灵敏度是检测到的实际渗出物像素的百分比,特异度是正确分类为非渗出物像素的非渗出物像素的百分比.准确率是分类器的总体正确分类的像素率.真阳性率(TP)被定义为正确分类的渗出物像素的百分比,假阳性率(FP)被定义为错误分类为渗出物像素的百分比.假阴性率(FN)为未检测到的渗出物像素的百分比,真阴性率(TN)为正确分类的非渗出物像素的百分比.灵敏度(Se)、特异度(Sp)和准确率(Ac)计算公式分别为
Se=TP/(TP+FN),Sp=TN/(TN+FP),
Ac=(TP+TN)/(TP+FP+FN+TN).
2.4.2 实验结果分析 将图像数据转化为矢量,采用PCANet+SVM算法进行分类(见表2和图10).本文提出的方法对DIARETDB1数据库中的45幅含渗出物图像中有44幅被正确分类.在44幅无渗出物图像中,只有1幅分类错误.对E-Ophtha数据库,所有47幅含渗出物图像都被正确分类,在35幅无渗出物图像中有1幅分类错误.

表2 混淆矩阵
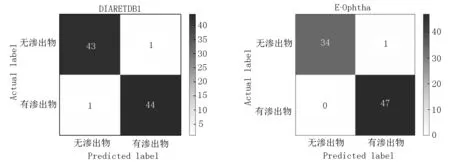
(a)DIARETDB1 (b)E-Ophtha
将PCANet+SVM模型的性能与其他模型进行比较,实验结果如表3和表4所示.

表3 本文模型与其他模型在DIARETDB1上的比较
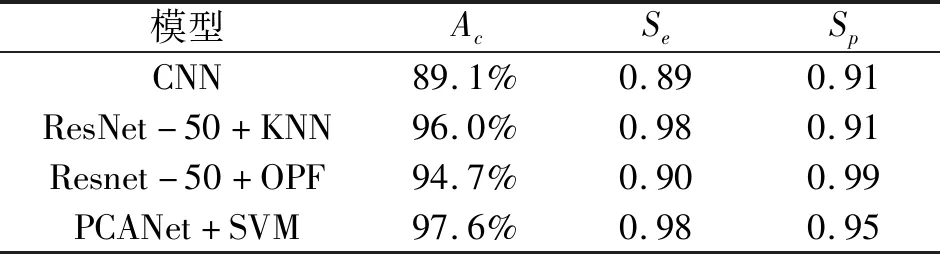
表4 本文模型与其他模型在E-Ophtha上的比较
从表3和表4可以看出:这2个数据库的性能是相似的.对于DIARETDB1数据库,PCANet+SVM的灵敏度和准确率分别为0.99和98.2%,与Resnet-50+OPF、Resent-50+KNN和CNN模型相比,Resnet-50+OPF的特异度最高(0.99),PCANet+SVM、Resent-50+KNN和CNN特异度分别为0.96、0.95和0.91.对于E-Ophtha数据库,在灵敏度、准确率和特异度上,与Resnet-50+OPF、Resent-50+KNN和CNN模型相比,PCANet+SVM的性能也得到了一定的提升.
本文方法的分类性能与现有方法[6-13]的分类性能相比如表5所示.对于DIARETDB1数据库,PCANet+SVM的灵敏度显著高于H.F. Jaafar等[6]研究的方法,这2种方法获得了相似的精度;与M.M. Fraz等[8]的相比,该方法有更高的准确率(98.2%)和特异度(0.96).对于E-Ophtha数据库,本文提出的方法优于E. Imani等[7]的方法,灵敏度提高了0.18,但特异度降低了0.04.

表5 本文模型分类性能与现有方法分类性能比较
3 结论
本文结合PCANet和SVM,对眼底图像进行预处理之后,采用PCANet对眼底渗出物特征提取,以达到检测病变眼底图像的目的,即将其分为正常眼底图像与糖尿病性视网膜病变眼底图像.该算法训练过程更简单,且不需要对大数据集进行训练,能适应不同任务、不同数据类型.与现有的二分类算法相比,本文的算法显著提高了检测准确率,是一种性能比较好的病变眼底图像检测的算法.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
保定学院学报(2022年2期)2022-04-07
中华眼视光学与视觉科学杂志(2022年1期)2022-03-22
临床眼科杂志(2021年2期)2021-05-26
眼科学报(2020年4期)2020-11-14
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
小型微型计算机系统(2019年12期)2020-01-14
摄影之友(影像视觉)(2018年12期)2019-01-28
数学学习与研究(2018年15期)2018-11-12
