
使用场景增强的安全帽佩戴检测方法研究
2022-10-18 01:04徐传运袁含香
计算机工程与应用 2022年19期
徐传运,袁含香,李 刚,郑 宇,刘 欢
重庆理工大学 计算机科学与工程学院,重庆 400054
在2019 年,我国建筑工地中物体打击伤亡事故占所有伤亡事故的比例高达15.91%[1]。部分原因是作业人员安全意识薄弱,未按规范佩戴安全帽。企业除了加强宣传、强制要求外,采用智能化技术实现作业人员安全帽佩戴的精确自动化监管,也是降低此类事故发生率的有效手段之一。
随着深度学习方法在安全帽佩戴检测中的深入应用,安全帽佩戴检测精度有较大提升。但是,为了提高检测精度,网络模型在逐渐加深过程中,参数量变大,需要的训练样本数量也随之增多。高昂的训练样本采集和标注成本,阻碍了安全帽佩戴智能检测方法的进一步发展。因此样本扩充和数据增强成为在不增加采集和标注成本的情况下,缓解训练样本不足问题的一种有效解决方案。
数据增强通常可分为有监督增强和无监督增强两类[2]。有监督增强又可分为单样本增强和多样本增强。单样本增强即增强操作围绕着一个样本进行,常见的有图像翻转、剪切、变形、缩放、旋转、添加噪声、图像模糊等。多样本增强则同时使用多个样本产生新的样本,如2017年,Dwibedi等人[3]对室内环境检测,提出Cut-Paste算法实现不同实例目标和场景的组合,从而得到新的合成数据。同年,Zhang 等人[4]提出的Mixup 算法在成对样本及其标签的凸组合上训练神经网络,增强了训练样本之间的线性表达,将CIFAR-10 数据集上的错误率降低了1.5%;2018 年,Inoue 等人[5]提出sample-pairing 算法,从训练集中随机抽取两张图像,分别经过单样本增强处理后经像素取平均值而叠加合成一个新的样本,将CIFAR-10 数据集上的错误率从8.22%降低到6.93%;2019 年,Hussein 等人[6]提出的SMOTE 算法为解决样本类别不平衡问题,对少数类样本进行分析并使用聚类算法根据少数类样本人工合成新样本添加到数据集中,一定程度上增加了少数类的样本数量;张家伟等人[7]同样使用此种方法提高了少数类样本分类的准确性;2020年,Bochkovskiy等人[8]提出的YOLO v4中则使用Mosaic方法将随机生成的四张图片进行拼接,以增加训练数据的多样性。无监督数据增强算法可分为:(1)利用模型学习数据的分布,随机生成与训练数据集分布一致的图像数据,如2020 年,杜卉然等人[9]采用邻域差分滤波器和生成对抗网络(GAN)相融合的方法,对工业产品数据集进行样本重建;同年,孙晓等人[10]利用生成器由某一表情下的面部图像生成同种静态图像数据的增强方法。(2)通过模型学习适合当前任务的数据增强方法,如2019 年,Google 提出的自动选择最优数据增强方案即AutoAugment[11]算法,在CIFAR-10 数据集上误差降低了0.65%。
在前期实验中,本文尝试采用以上算法对安全帽数据进行扩充。其中,基于Mosaic 的增强方法未能提高安全帽佩戴的检测精度;基于GAN 的增强方法需要大量数据来拟合样本的分布,且不能任意改变图像中目标的数量、大小和位置,因此不适合用于安全帽佩戴检测任务;基于Cut-Paste[3]的增强方法需要把训练集中的目标进行精细分割,标注成本太高;基于sample-pairing的增强方法能提高安全帽佩戴的检测精度,但效果并不理想,精度还需进一步提升,相关结果也在实验部分进行了阐述。
因此本文针对安全帽数据集样本偏少而导致网络检测精度较低的问题,采用有监督的多样本增强方法,提出一种基于场景增强(scene-augment,SA)的样本扩充算法。该算法将从训练集中随机提取前景图像,对其中小目标进行剪切、随机缩放后,粘贴到随机选择的另一源场景图像的任意位置,以较小的成本扩展出大量的可训练数据。另外,本文还将SA算法添加到YOLO v4网络模型(该组合称为YOLO v4(SA))中,对HelmetWear[12]数据集(HW)进行安全帽佩戴检测。实验表明,该方法相比其他学者在HW数据集上的测试结果,检测精度得到了进一步提升。
1 场景增强
场景增强是指把训练数据中的前景和背景抽取出来,将二者随机组合以构建出数据集中原本不存在的场景,可以应用于训练样本不足或训练样本分布不均匀的情况。
本文使用HW数据集进行安全帽佩戴检测实验,训练集有2 272 张图像,参照MS COCO[13]数据集中按面积大小对不同尺度目标的定义见表1,统计出HW 数据集内的小、中、大目标的数量分别为285 例、2 736 例、4 134例,其中目标分为不戴安全帽和戴安全帽两类,分别使用0、1标注。

表1 HW数据集中目标数量统计Table 1 Statistics of number of targets in HW dataset
本文针对上述两种问题提出了一种简单有效的解决方案,即将随机抽取的前景图像内的中小目标剪切、随机缩放后,粘贴到另一源场景图像的任意位置上,构建出新的增强场景,如图1所示。粗略估算,HW数据集增强后的场景图像可以多达500万张,能极大丰富训练样本的多样性。实验结果表明,该算法结合YOLO v4网络模型能够稳定提升安全帽佩戴检测模型的精度。

图1 场景增强Fig.1 Scene augment
场景增强能构建出新的场景,但是会带来以下三个新的问题:(1)粘贴目标可能会遮挡源场景图像中的目标;(2)随机粘贴可能导致粘贴位置周围像素梯度差较大,目标不能无痕的融入到背景中;(3)过多的复制样本可能导致模型过拟合。
针对第一个问题,本文分析了四大类共14 种不同的遮挡情况,并对每种遮挡情况进行处理。如图2 所示,其中B 为前景图像中的目标,A 源场景图像中的目标。第一类遮挡情况中,B在A的4个角的位置上遮挡,为了保持边界框的完整性,此标注框不予以处理;在第二及第三类遮挡情况中,B 对A 的4 条边分别产生了部分及全部遮挡,为保留这两者中较大目标的个体完整性,因此删除较小目标被遮挡的部分;第4 类遮挡情况中,B 完全遮挡了A,A 在增强的场景中没有任何显示,因此舍弃目标B;当B 的面积较A 目标较小时,能够模拟现实中目标正常遮挡情况,因此保留B目标。
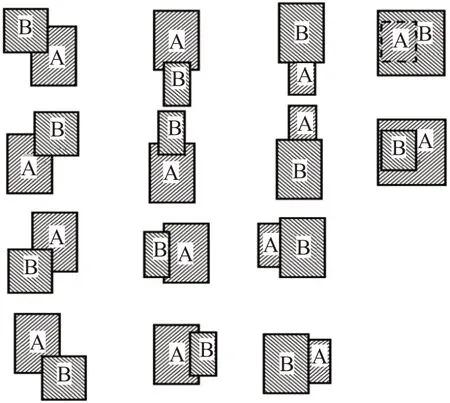
图2 4类共14种不同的遮挡情况Fig.2 Four types of 14 different occlusion situations
针对第二个问题,文献[3]证明了目前的检测器相对于全局场景布局更加关注局部区域的特征,例如安全帽检测器主要关注工作人员的视觉外观及与背景的融合,而不是在场景中出现的位置(如天上或地面)。同样,文献[8]中提出的Mosaic方法,对于拼接处像素梯度突变的情况并未做任何处理,且在MS COCO数据集上检测精度提升了0.5个百分点。像素突变对检测模型的训练是个不利因素,但现有的研究成果和本文的实验结果表明,像素突变对模型检测精度的影响是有限的,场景增强对检测精度的提升足以抵消其不利影响。
针对第三个问题,在使用场景增强时需要控制增强的强度,以保证模型在不发生过拟合的情况下,提高网络的检测精度。不同增强强度的对比实验分析将在第3章中详细阐述。
在安全帽佩戴检测应用中,目标可以出现在施工场景中的任意位置,即不对目标的位置施加约束,不仅能扩大安全帽佩戴检测技术的应用范围,也能提升检测方法的鲁棒性。在提出的场景增强方法中,我们假设检测目标可以以任意大小的形态出现在任意场景中的任意位置。以上假设使得增强场景和真实的安全帽佩戴检测场景更加一致,从而提高检测模型在真实应用场景中的检测精度,也能提高模型的鲁棒性。
2 场景增强算法
目标检测模型需要具有平移不变、旋转不变、缩放不变等基本特性,为了训练检测模型具有这些特性,需要使用不同位置、不同大小、不同倾斜角度的训练数据。场景增强SA(scene-augment)算法对安全帽佩戴数据集中抽取的检测目标和抽取的背景进行组合,以最小的代价生成大量拥有不同位置、不同大小、不同倾斜角度的检测目标的场景图像。
靶向OPN基因shRNA慢病毒载体的构建及其对人肺腺癌细胞A549侵袭能力的影响 ………………………………………………………………………… 罗 猛,等(9):1012

为保证训练的安全帽佩戴检测模型具有较高的泛化能力和鲁棒性,在训练模型时,场景增强的数据与未增强的数据需要混合使用。实验结果表明,过少的增强数据不能起到提升检测精度的目的,过多的增强数据反而会降低模型的精度。为了控制场景增强的强度,在模型训练的每个Mini-Batch 中以概率p选择部分图片作为源场景图像,经场景增强后替换原始图片,场景增强后图片数量的计算公式如下:

其中,SUM为使用SA 增强后的图片数量,D为训练迭代次数,BS为每次迭代的batch size大小,p为增强强度。本文中,D为8 000,BS为64,如果p为0.3,那么扩充的图片数量为153 600张。
综合以上论述,设计出SA 数据增强算法。具体实现如下:

如图3展示了把SA数据增强算法与目标检测网络模型结合的安全帽检测框架,训练集中样本数据经SA增强后得到新的训练图片及标签,对其进行基础变换后再将其送入YOLO v4网络模型中进行训练。
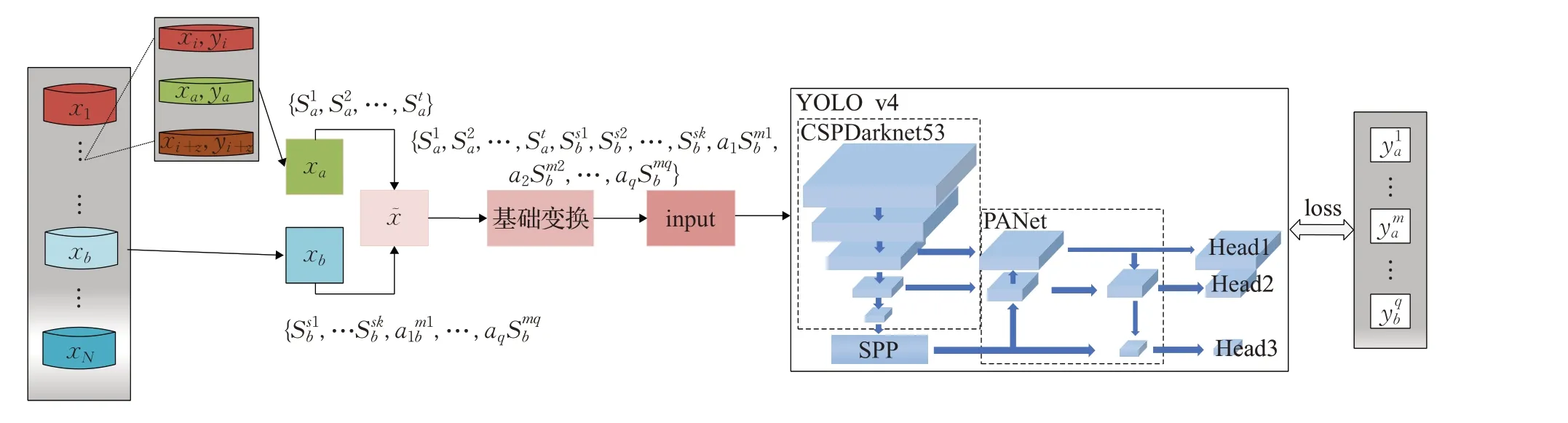
图3 基于场景增强的安全帽佩戴检测过程Fig.3 Safety helmet wearing detection process based on scene augment
3 实验结果与分析
3.1 数据预处理
在实验中发现HW数据集中有部分目标没有标注,这无疑会影响安全帽佩戴检测模型的性能,为了提高HW数据集的质量,使用LabelImg工具对部分遗漏的目标进行了补充标注。经过标注后的HW 数据集标识为HW+,其中,HW+训练集中图像数量总和不变,检测目标增加了570 例,其中小目标395 例、中目标157 例、大目标18 例,测试集增加了检测目标102 例,其中小目标66例、中目标29例、大目标7例,如表2所示。表中Δt、Δc分别代表训练集、测试集中新增的小、中、大目标的数量。图4 中展示了补充标注前后的对比图,其中图(a)、(b)、(c)各列分别为原图、原始标注情况、补充标注后的情况。
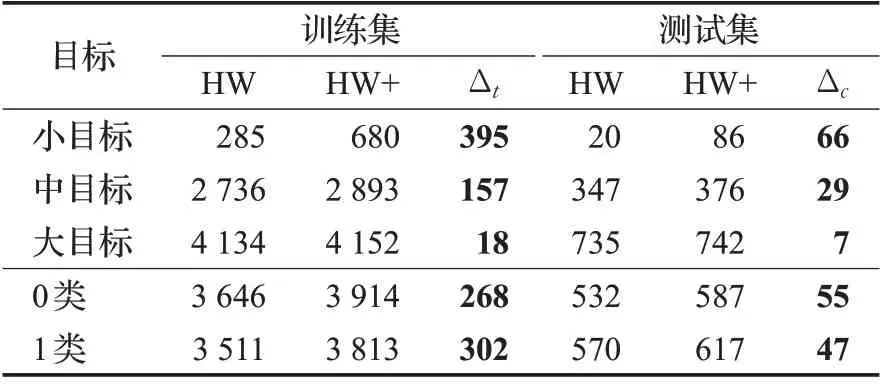
表2 HW数据集补充标注后的目标数量Table 2 Number of targets after supplementary annotation in HW

图4 补充标注前后对比Fig.4 Comparing before and after supplementary annotation
为了验证补充后是否提高了模型的检测精度,分别使用HW、HW+训练YOLO v4,并在两个数据集的测试集上交叉测试,结果见表3。使用HW 训练出的模型的测试mAP 分别为92.29%、89.21%,使用HW+训练出的模型的测试mAP 分别为92.86%、91.29%。纵向对比两组结果可知,HW+数据集对每个测试集都有相应的提高,说明添加标签能够一定程度上提高模型的检测精度。
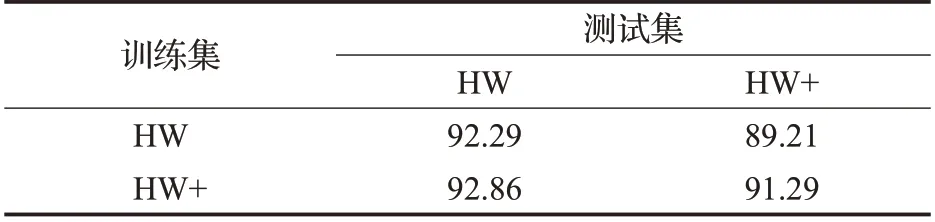
表3 补充标注前后的模型检测精度对比Table 3 Comparison of model detection accuracy before and after supplementary annotation单位:%
3.2 网络训练
实验基于PyTorch 框架实现,硬件配置为:两张NVIDIA RTX 2080Ti,配备22 GB 图形缓存,32 GB 系统内存,Intel I9 9900K CPU;软件配置为ubuntu16.04,64 位操作系统。实验测试评价指标为平均准确率(average precision,AP),描述了每个类别准确率的平均值,其中mAP、APs、APm、APl分别表示AP 的均值和小、中、大3种不同尺度物体的AP 值。
训练样本采用补充标注后的HW+数据集,并利用VOC2007数据集处理方法将其输入到YOLO v4网络模型中分两阶段训练[8]:第一阶段冻结网络预训练权重只更新检测头的参数;第二阶段更新整个网络的参数。batch size分别为64、16,训练及测试图像大小均为416×416,每个实验训练迭代8 000次。表4的结果展示了分别使用余弦退火(cosine annealingLR)[14]、自适应调整(reduce LROnPlateau)[15]学习率下降策略及标签平滑(label smoothing)[16]训练技巧对安全帽检测精度的影响。结果表明余弦退火、标签平滑对安全帽佩戴的检测精度起到了削弱作用,自适应调整能够有效提高模型检测精度,因此以下实验将采用自适应学习率下降策略,且取消标签平滑操作。

表4 模型调优Table 4 Model tuning单位:%
为消除YOLO v4 自带Mosaic 数据增强算法的干扰,接下来的实验选择将其剔除,另外为和其他学者在HW数据集上的测试结果进行对比,以下将使用HW测试集验证测试。
本文还在同样的实验环境下替换多种数据增强算法对HW+训练集进行训练从而得到对应的检测模型,以便于在HW测试集上与SA的检测结果进行对比。
3.3 面向小目标的场景增强实验
小目标检测是计算机视觉中最具挑战性和重要的问题之一,为了验证场景增强在小目标检测上的有效性,设计了面向小目标的场景增强实验。实验只选择(xb,yb) 中的小目标粘贴到源场景(xa,ya) 中,测试了Mini-Batch中图像进行SA增强的概率p对检测精度的影响,表5展示了实验结果。当p=0.3 时,即10张图像中有3张进行SA增强,在测试集上检测的mAP由93.02%提高到93.41%,其中,小目标检测的mAP 由33.65%提高到35.09%,由结果可知,当p=0.3 时,SA增强算法能够提高模型的检测精度,且在小目标检测上的表现尤为明显。
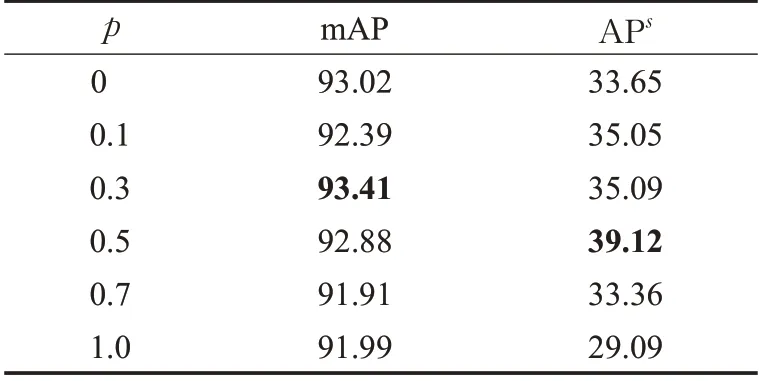
表5 小目标增强的对比实验结果Table 5 Contrastive experimental results of small target enhancement单位:%
为了验证算法的鲁棒性,训练了10 组p=0.3 时的检测模型,并测试其检测精度,实验结果参见表6,可知,10 组实验检测精度的平均值为93.42%,标准差为0.07%。从结果可以看出,场景增强算法能稳定提升安全帽佩戴检测模型的检测精度。
3.4 基于中小目标的场景增强实验
为增强中小目标的样本数量,尝试在小目标与场景融合的同时,对中目标采用剪切缩放并融合的方法。实验结果见表7,当p=0.1 及p=0.3 时模型检测精度均有提升,但随着p的增大,扩充样本增多,模型过拟合的概率越大,模型检测精度逐渐下降。当p≤0.3 时,能够在保证模型不发生过拟合的前提下,有效提高模型的检测精度,且这种设置比只融合小尺度目标效果更好。
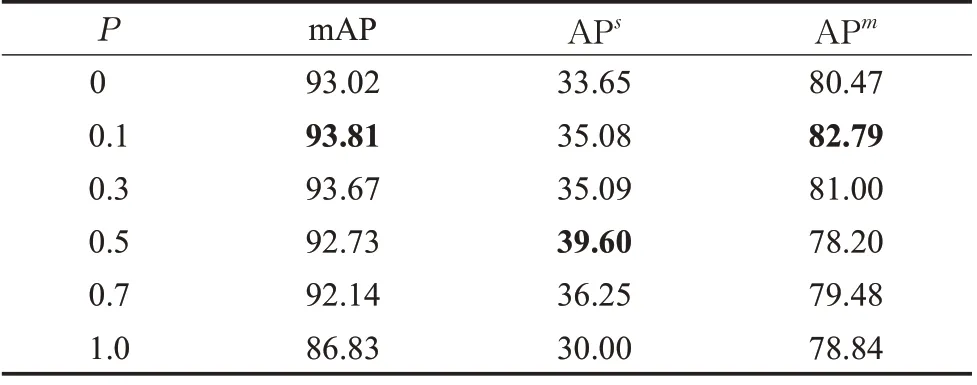
表7 不同概率对中小目标增强的实验对比Table 7 Experimental comparison of enhancement of small and medium targets with different probabilities单位:%
图5 展示了不同安全帽佩戴检测方法的检测结果对比,其中图(a)、(b)、(c)各列分别为原始测试图像、YOLO v4原始模型检测结果、YOLO v4(SA)的检测结果。可以看出,相对于添加Mosaic的YOLO v4模型检测结果,YOLO v4(SA)模型能更加准确地检测出小目标的位置。

图5 SA算法检测结果对比Fig.5 Comparison of detection results of SA algorithm
3.5 数据增强方法对比实验
面向目标检测的数据增强方法有多种,为了验证这些方法对安全帽佩戴检测的有效性,本文将其分别添加到YOLO v4 网络模型中对HW+数据集进行训练并对实验结果对比分析,结果如表8。从实验结果可见,Mosaic增强[8]、random erasing[17]增强没有提高安全帽佩戴检测的精度,sample pairing[5]增强能提高安全帽佩戴检测的精度,但是实验精度要低于SA增强,进一步说明SA算法相比目前主流数据增强算法在提升安全帽检测精度上具有一定的优势。
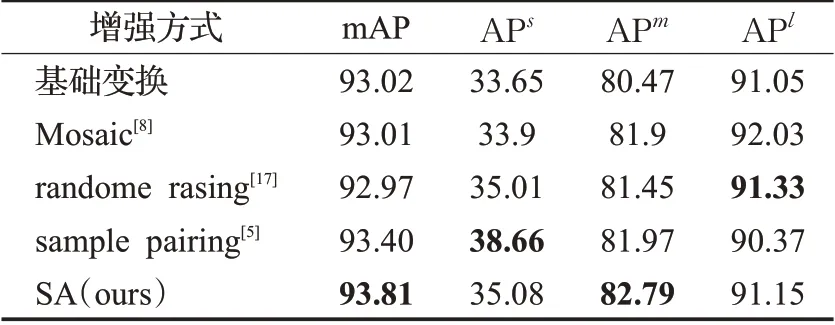
表8 不同数据增强算法实验对比Table 8 Experimental comparison of different data enhancement algorithms单位:%
3.6 不同模型对比实验
图6 分别显示了YOLO v2[18],MD-YOLO v2[12],YOLO v3[19],YOLO v4[8](SA)5 个框架在HW 测试集上的测试结果。其中MD-YOLO v2的实验结果由方明等人[12]提供(是当前公开发布的最好检测结果),其他结果由测试得到。可知,YOLO v4(SA)相比YOLO v2、MD-YOLO v2、YOLO v3 分别提高了7.29 个百分点,6.39个百分点,5.57个百分点。YOLO v4(SA)方法相比YOLO v4,能够在参数量不变的情况下,对安全帽佩戴检测效果有较好的提升。
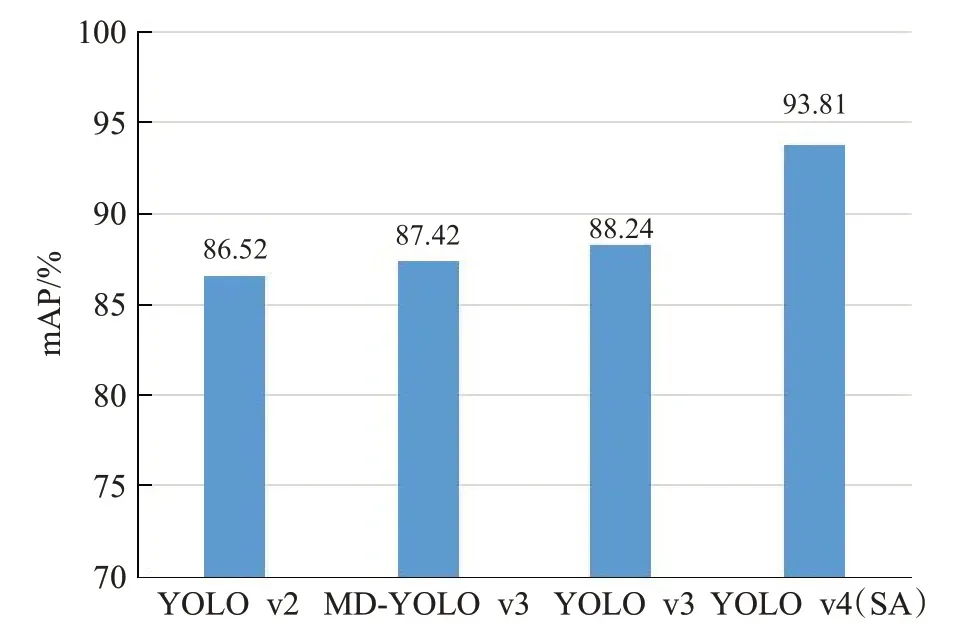
图6 不同模型的测试结果对比Fig.6 Comparative test results of different models
4 结束语
为了解决现有安全帽佩戴数据集样本数量有限而导致模型检测精度较低的问题,本文提出了一种基于场景增强的样本扩充算法并将其应用到YOLO v4 网络模型中对安全帽佩戴情况进行检测,结果表明,合适的场景增强强度结合YOLO v4 网络模型能有效提高检测精度。
但由于在场景增强时,目标被粗暴的粘贴进源场景图像中,目标和背景的拼接处将会有较大的梯度突变,这可能会影响增强数据集的训练效果,在未来的研究中,计划将目标与背景融合成自然的增强场景并提高场景构建的随机性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
课外生活·趣知识(2019年4期)2019-09-10
领导决策信息(2018年16期)2018-09-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
今古传奇·故事版(2017年5期)2017-04-08
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
西南学林(2011年0期)2011-11-12
职业·中旬(2009年12期)2009-06-01
