
多任务交互式学习网络的方面情感分析
2022-10-18 01:48潘理虎陈战伟
计算机工程与应用 2022年19期
宋 婷,潘理虎,陈战伟
1.太原科技大学 计算机科学与技术学院,太原 030024
2.中国移动通信集团山西有限公司,太原 030001
基于方面的情感分析[1](aspect-based sentiment analysis,ABSA)旨在针对文本中特定方面目标获取其情感信息。传统的文本观点获取仅对整篇文档进行情感分析,不针对具体对象[2-3]。基于方面的情感分析分为两个任务,提取方面词[4-6](aspect term analysis,AT),以及分析不同方面的情感极性[7-9](aspect category sentiment analysis,AS)。例如句子:“Good food but dreadful service at that restaurant”,分析语句评论的实体是餐厅,分别对两个方面food和service提取情感信息,分别为积极和消极。
深度学习[10-11]方法在自然语言处理中不断取得新的进展,在机器翻译[12]、句子对建模[13]、情感分析中被广泛应用。常用的深度学习模型[7-9]最大特点是能对批量数据自动学习,利用注意力机制实现对目标内容的特别关注。
在以往的工作中,方面词提取和方面词的情感分类通常分开处理,未充分利用两个任务的联合信息。研究表明[14-15],集成模型对比顺序处理方式,情感获取效果相当,以上工作都将问题表述为具有统一标签的单个序列标注任务,没有明确建模它们之间的相关性,仅从方面级别的实例中学习,这些实例大小通常有限。
基于以上问题,本文提出基于信息传递机制的多任务交互式学习网络(multi-task interactive learning network based on information transmission mechanism,MTIITM),进行方面情感分析,主要贡献如下:
模型采用细粒度属性级和篇章级分类任务联合训练,引入消息传递机制显式的对任务间交互建模,通过共享隐藏变量迭代传递上一轮有用信息,不仅允许共享特征,并且更好的获取不同任务间交互信息,有助于特征学习和推理。
方面级任务引入方面/观点词抽取和方面情感预测两个任务模块,设计词级信息交互机制,及AT-AS 的信息传递通道,实现基于方面的双注意力机制;篇章级任务引入情感预测和类别预测两个任务模块,设计GRUMP网络,利用大规模篇章级语料库的知识,与方面级任务联合训练。
设计迭代算法在方面级和篇章级任务间交替训练,通过准确率、F1 分数在模型整体及分量性能、篇章级网络性能方面的对比实验,验证了模型的有效性和可行性。
1 相关工作
本章从方面情感分析方法、多任务学习方法、消息传递机制三方面讨论。
基于方面的情感分析属于细粒度分类任务,早期的机器学习结合语言学特征得到的是浅层特征。现使用较多的是神经网络模型,文献[16]基于卷积神经网络实现自然语言处理领域中的任务分析。循环神经网络更适用于序列数据的处理;文献[17-18]基于LSTM和GRU实现目标实体和上下文间的交互,通过引入注意力机制,减少对次要及无关信息的关注度。模型构建集成解决方案中;文献[19]提出将问题建模为具有统一标记方案的序列标记任务,但是效果不佳;文献[20]沿着这个方向提出了具有更复杂网络结构的模型,子任务间的交互并没有明确建模。
多任务学习方法中传统学习框架在各种自然语言处理任务中取得较好效果[19-20]。通过使用共享表示并行学习语义相关任务,并在某些情况下提高模型泛化能力,通过与篇章级情感分类任务的联合建模,明显改善方面级情感分类效果。然而传统的多任务学习方法并没有明确地对任务之间的交互进行建模,AT和AS这两个任务会通过错误反向传播之间的交互获取学习特征,这种隐式交互是不可控的。
消息传递机制已经在计算机视觉和自然语言处理中进行研究,若将这些消息传递算法建模成网络,消息传递过程可以看作是一个循环神经网络,此类架构方法适用于解决多任务学习问题。基于以上提出的问题,需要一个更好的网络结构,实现进一步的任务交互。
2 基于信息传递的多任务交互式学习网络
本章介绍基于信息传递机制的多任务交互式学习网络(MTIITM),通过消息传递机制对不同任务建模,实现细粒度属性级分类任务和篇章级分类任务间信息交互。
MTIITM架构如图1所示,具体功能如下:
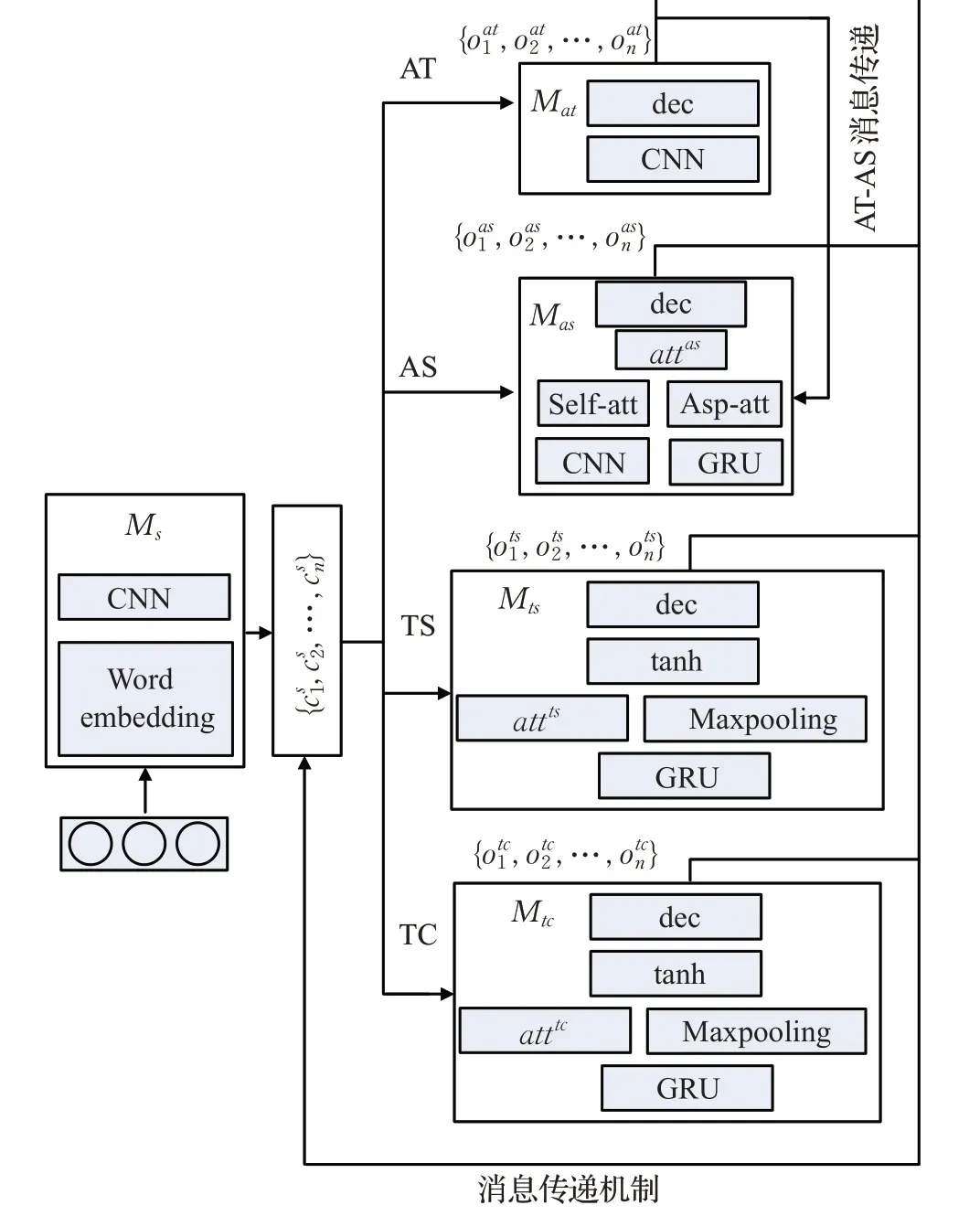
图1 多任务交互式学习网络Fig.1 Multi-task interactive learning network
(1)方面级分类任务。引入方面/观点词抽取和方面目标情感预测两个任务模块,添加AT向AS的信息传递通道实现自注意力机制,并设计词级信息交互机制,实现基于方面的双注意力机制。
(2)篇章级分类任务。引入篇章级文本情感预测和类别预测两个任务模块,设计GRU-MP 网络获取预测结果。
(3)消息传递机制。显式地对任务间交互进行建模,通过共享隐藏变量在不同任务间迭代传递信息。
(4)参数学习。设计迭代算法,在方面级和篇章级任务间交替训练,利用大规模文档级语料库的知识,与方面级任务AT和AS联合训练。
2.1 通用特征模块
给定句子表示s={w1,w2,…,wl,…,wl+m-1,…,wn},作为基础特征抽取模块Ms的输入,包含n个单词,其中wi是句子s的第i个元素。方面词表示asp={wl,…,wl+m-1},包含m个单词,以方面词为界,左边称为上文aspL,长度(l+m-1),右边称为下文aspR,长度(n-l+1)。模块Ms由一个词嵌入层和几个特征提取层组成,特征提取层采用ns层卷积神经网络。

共享隐藏向量进入特定任务模块,每个特定子任务模块有自己内部的一组隐藏变量和输出变量,输出变量相当于序列标记任务中的标签序列。在方面/观点词提取任务(AT)中,针对每个字符对应一个标签,表示字符是否属于某一方面/观点;在方面级情感分类任务(AS)中,针对每个标记过的方面目标,确定其情感分类标签。在篇章级文本分类任务中,输出对应整体文本的情感标签和类别标签。
2.2 方面级情感分类任务
2.2.1 基础模块映射表示
AT 任务模块Mat和AS 任务模块Mas旨在抽取方面/观点目标和预测情感分类,建立方面/观点词抽取任务模块和方面情感预测任务模块间的信息传递通道,信息由AT传递到AS,实现二者信息交互。
AT看作一个序列标记问题,采用BIO标记方案,定义五个类标签:oat={BA,IA,BP,IP,O},分别表示属于方面词的主要、次要位置词语,属于观点词的主要、次要位置词语,以及其他词。文中将任务模块AS 也定义为一个序列标记问题,形式为oas={pos,neg,neu},分别表示方面词的正向、负向和中性情感。



2.2.3 基于词级交互的方面注意力机制
AS编码器中实现了结合模块间交互信息的基础映射,设计了结合词级交互信息的方面注意力机制。两种不同的注意力机制意味着提取的高层次特征更加丰富,合并两个输出得到各种角度的文本权重。
分别计算句子上文、下文以及方面词的词向量aspL∈R(l+m-1)、aspR∈R(n-l+1)和asp∈Rm,通过GRU 网络提取各自语义信息,分别得到三部分的隐层向量表示hAL、hAR、hA。词级交互注意力实现如下:
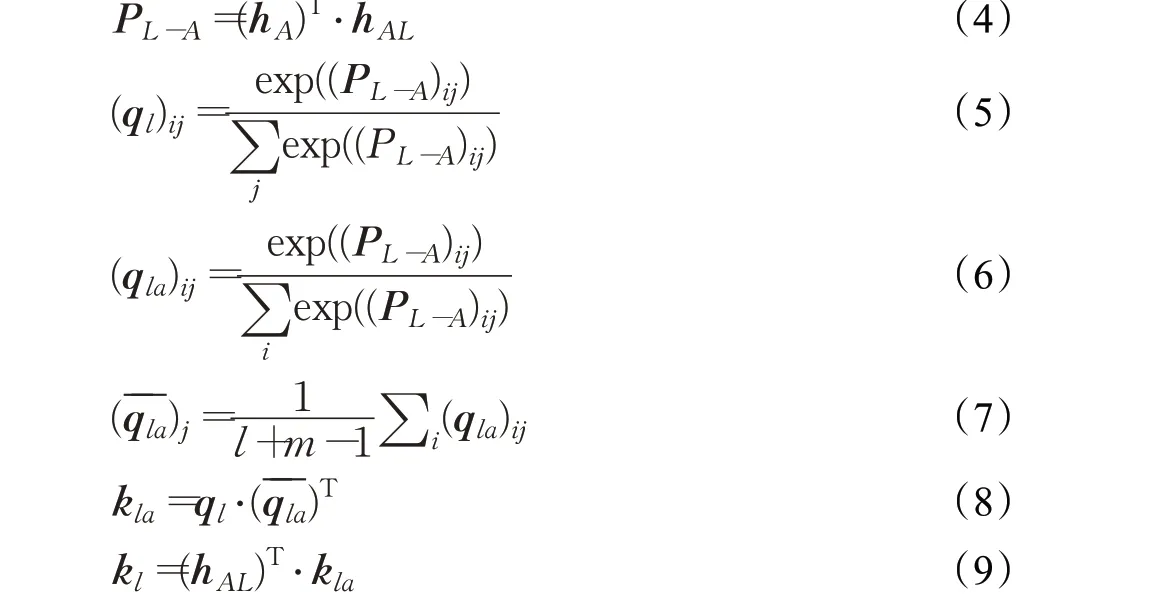
式(4)计算hAL和hA的成对交互矩阵PL-A,获取上文文本和方面词的交互信息;式(5)通过计算PL-A的列式softmax值,获得方面词对左边文本的相关性权重向量ql,抽取左边文本的关键情感特征;式(6)计算PL-A的行式softmax值,获得左边文本对方面词的相关性权重向量qla,在qla的列方向计算均值qˉla,抽取方面词的关键情感特征,如式(7);式(8)和(9)通过两部分注意力向量计算方面词和左边文本的交互特征向量kla,与hAL加权求和,求得基于方面的左边文本表示kl。
按照上述步骤实现方面词和右边文本的词级交互注意力机制,最终得到基于方面的右边文本表示kr。通过上文和下文的拼接操作,得到基于方面的向量表示attk,与自注意力机制合并得到双注意力输出:


2.3 篇章级分类任务
为了解决方面级文本训练数据不足的问题,引入两个篇章级分类任务,分别是篇章级情感预测(TS)和篇章级类别预测(TC),与AT 和AS 联合训练。本节通过篇章级情感预测及类别预测的语料库获取有用信息。
篇章级情感模块Mts和类别模块Mtc在GRU 网络的基础上采用一个类似多层感知机结构的网络,并结合池化操作(GRU-MP),结构如图2所示。
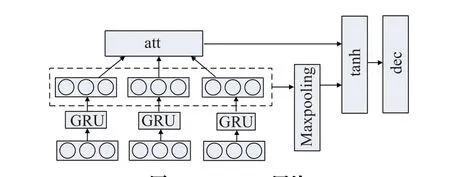
图2 GRU-MP网络Fig.2 GRU-MP network

同时采用池化操作提取位置不变特征和关键信息,将语义矩阵转为语义向量。这里采用最大池化操作,对比平均池化能更好的保留位置信息。最后将文本情感权重状态和文本语义表达相结合,过程如下:
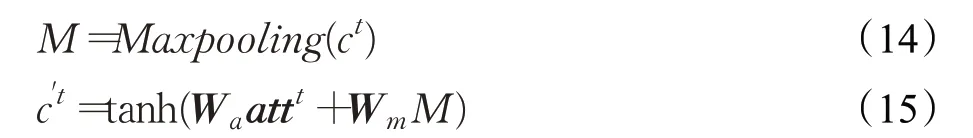
最后使用带softmax函数的全连接层作为解码层。
2.4 消息传递机制
采用消息传递机制显式地对任务间交互进行建模,过程中聚合了上一轮迭代中不同任务的预测信息,以此来更新当轮迭代中的共享隐藏表示。与大多数通过学习共同特征表示来共享信息的多任务学习方案相比,本文不仅允许使用共享特征,而且还获取不同任务间的交互信息,有助于特征学习和推理。这个操作是迭代执行的,随着迭代次数的增加,允许在多个链接修改和传播信息。
在消息传递过程中,第t轮迭代聚合了上一轮隐藏
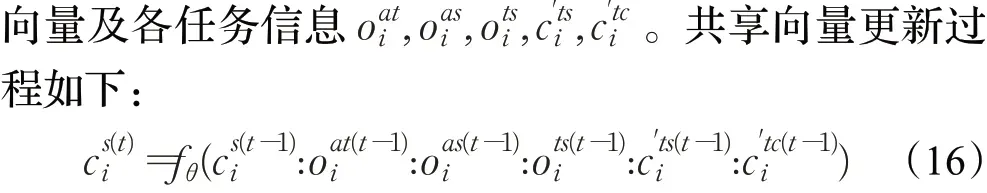
其中[:] 表示级联操作,采用带有ReLU激活函数的全连接层实现重新编码功能fθ。式中融合了方面/观点抽取和方面情感预测模块的输出,以及篇章级文本情感预测的输出,它代表的是整个文本的情感表达。此外,还融合了来自篇章级两个任务中的映射表示,它分别反映了某一元素的情感相关度和类别相关度,相关度越高,则预测为方面词或观点词的概率越大。由于任务模块AT和AS是最终任务,因此,在迭代过程中主要使用两者的输出进行信息传递,篇章级文本分类任务主要用于数据训练。
2.5 参数学习算法
模型在方面级和篇章级实例间交替训练,设计的算法类似于一个循环神经网络,因为每次迭代都使用相同网络来更新共享隐藏变量。方面级训练实例的损失函数定义如下:


Da、Dts、Dtc分别为方面级预测和篇章级情感及类别预测的训练数据,Da、Dts来自同一领域类别,Dtc包含至少两个领域类别的评论文本,其中一个领域类别和方面级相似,由此使模块间语义相近,有价值的语义信息从篇章级任务传递到方面级任务。因此首先在篇章级任务上训练,得到合理的预测,再在方面级和篇章级间交替训练,利用比率参数p使损失值最小化,p采用交叉验证方法获取。算法的时间复杂度与maxepochs和batchsize相关,若用m、n分别代表它们,则上述算法时间复杂度为O(m×n)。
3 实验
3.1 数据集
方面级情感分类任务采用数据集SemEval2014 和SemEval2015 中的3 个基准数据,如表1 所示,显示了3个数据集在方面词和观点词预测的训练集和测试集数量。
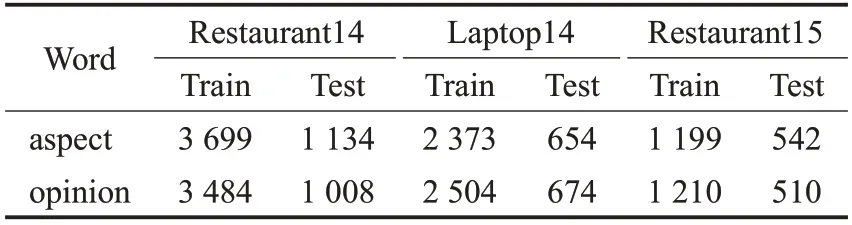
表1 数据集信息Table 1 Dataset information
篇章级分类任务采用两个不同领域的数据集Yelp restaurant 和Amazon electronics,类别预测连接两个数据集一起训练;情感预测采用其中一个数据集,与方面级任务采用的数据集类别一致。例如方面级情感预测采用表2中的餐饮类,则篇章级情感预测选择篇章级训练数据中的餐饮类,方面级情感预测采用表2中的电器类,则篇章级情感预测选择篇章级训练数据中的电器类。
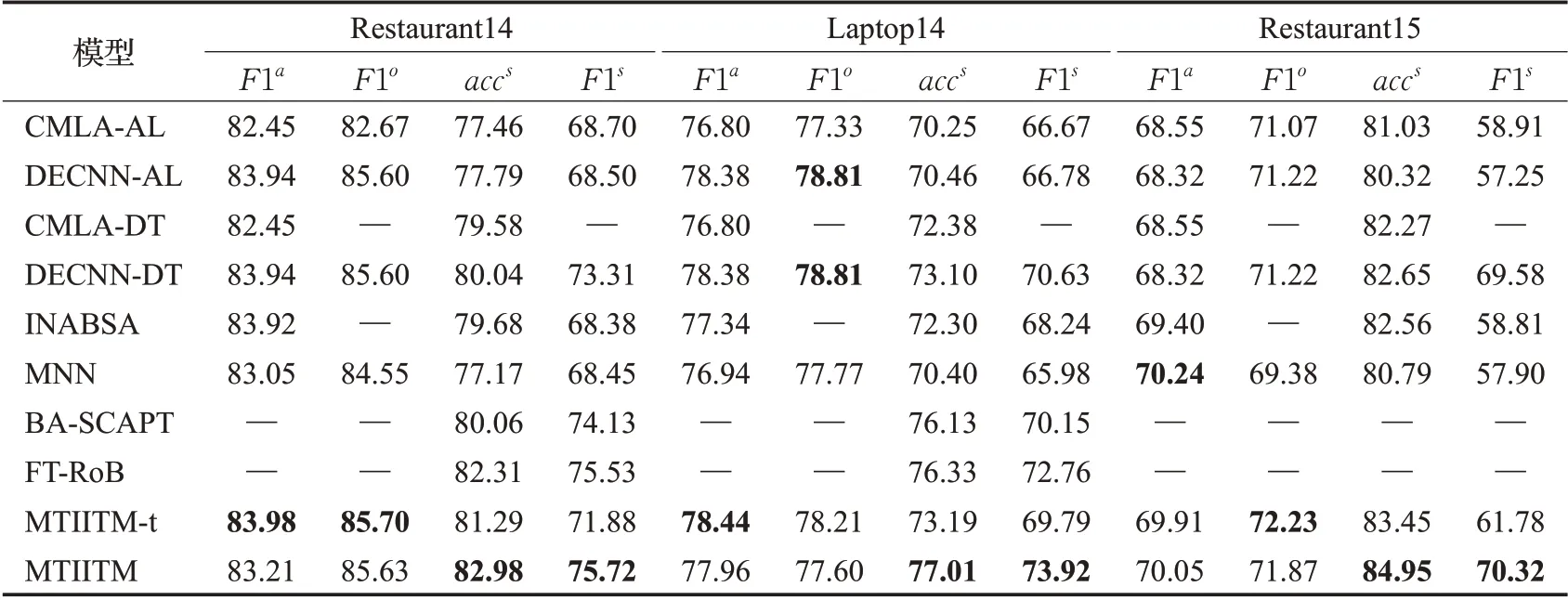
表2 不同模型在3个数据集上的性能指标Table 2 Performance indicators of different models on three datasets 单位:%
3.2 参数设置和评价指标
通用基础特征模块词嵌入初始化,连接通用嵌入矩阵和特定类别的嵌入矩阵,通用嵌入矩阵是具有300维的预训练Glove 向量,类别嵌入矩阵是100 维的餐饮和电器类预训练fastText向量。训练使用Adam优化器,学习率和批量尺寸按常规值设置,无需进行特定调整,分别为10-4和32。
消息传递机制迭代次数及各个模块网络层数直接影响训练开销及预测效果,一般可通过设置阈值类思路避免数值过大造成的开销增加及模型过拟合,以达到较好效果。本文对训练中的一系列参数采用交叉验证的方法计算,得到较优参数的同时控制了重复次数:其中共享编码器和特定任务编码器卷积层的层数,使基础模块和特定任务任一模块卷积层层数之和等于交叉验证产生值,则ns,nat,nas,nts,ntc可设置为{2,2,0,0,0} 或{1,3,1,1,1} ;训练中通过交叉验证在方面级数据集上调整最大迭代次数,设置为2,在方面级数据集和同类别篇章级数据集上调整参数p,使损失最小化,设置为2。
实验中分别采用不同指标评估模型性能,两个用于方面/意见词抽取模块,两个用于方面情感预测性能。方面词和意见词预测结果用F1 分数衡量,表示为F1a和F1o,方面情感预测结果采用准确率和F1 衡量,表示为accs和F1s。
3.3 对比模型
实验对比模型如下所示。
(1)CMLA-AL:基于长短期记忆网络构建模型,通过方面词和观点词间的相互依赖关系建模,获取文本方面词和观点词预测,在注意力机制基础上获取情感预测[6,17]。
(2)DECNN-AL:基于多层卷积神经网络构建模型,结合通用类别和特定领域类别数据,获取文本方面词和观点词预测,基于长短期记忆网络上的注意机制获取情感预测[5,17]。
(3)CMLA-DT:通过方面词和观点词间的相互依赖关系建模,获取文本方面词和观点词预测,结合领域类别数据库的语义知识,获取情感分类[6,18]。
(4)DECNN-DT:基于多层卷积神经网络构建模型,结合领域类别数据库的语义知识,基于注意力机制获取情感分类[5,18]。
(5)INABSA:是一种多任务集成模型,将整个任务建模为序列标记问题,具有统一的标记方案的方面抽取和情感预测模型[19]。
(6)MNN:是一种多任务集成模型,通过神经网络多任务学习实现方面提取和情感分析任务[20]。
(7)FT-RoBERTa:同时比较了分别基于预训练模型和句法解析器生成的依存句法树在ABSA上的性能[21]。
(8)BERTAsp+SCAPT:从域内检索的大规模情感标注语料库进行了有监督的对比性预训练,预训练过程可以更好地捕捉评论中隐性和显性情绪倾向[22]。
3.4 模型有效性分析
除6 种对比模型,还对比了MTIITM-t 即未嵌入篇章级文本语料库的网络,分析表2数据,在3个数据集上数据走向基本一致,MTIITM 和MTIITM-t 模型优于对比模型。
针对方面词和观点词抽取模块的实验数据,可以看出MTIITM-t 模型结果最优,由此可得未嵌入篇章级文本语料库的模型在这一部分优于其他模型;针对方面情感预测模块部分,方面词是语料库中已标注过的正确标签,在此基础上,MTIITM模型最优,即加入基于词级交互和AT-AS 信息交互的双注意力机制的模型在方面级情感预测中优于单独运行两个模块的模型。从多任务整体性能的角度看,实验中嵌入文档级语料分析或句法分析的几种模型,均有效提高了分类准确率和F1 分数,未加入篇章级语料库嵌入的MTIITM-t也优于其他大部分对比模型。由此可得通过模块间交互信息的获取和篇章级大型文本语料库的利用有效的提高了模型准确率,模型适用性更强。

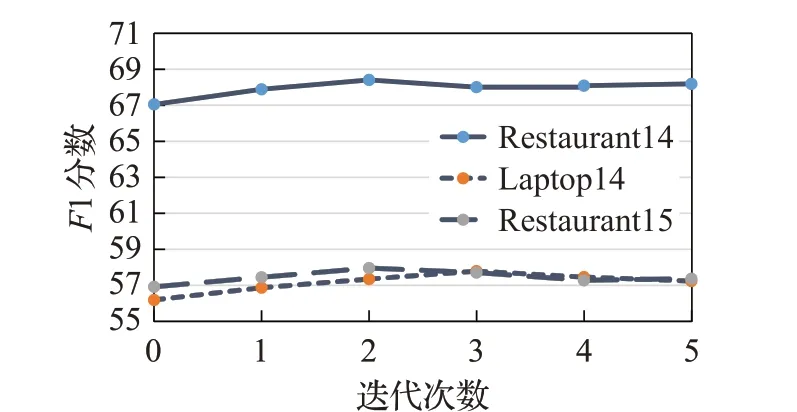
图3 不同迭代次数的F1分数Fig.3 F1 scores for different iterations
模型采用不同领域的数据集以配合联合训练中的篇章级类别预测模块,模型适用范围较广,对于包含跨领域文本的方面情感分析同样适用。因此可以作为预训练模型利用迁移学习的思路应用到多种任务中,以减少耗时,提高模型精确度,进一步获得性能提升。针对提出模型层数及功能模块丰富的特点,复用时可采用一些微调方法,例如:利用预训练模型体系在大量计算资源上进行训练,较低层适用的是通用特征,而较高层适用的是特殊特征,因此可选择冻结部分层或模块,只训练所需要的部分。若数据集较小并拥有大量参数,则需要冻结更多的层避免过度拟合,若数据集较大并参数数量很少,则通过对新任务训练更多层来完善模型。
3.5 分量贡献比较
通用基础特征模块、方面词抽取模块和方面词情感预测模块组成模型的原始状态,在原始模型基础上分别加入某一分量,验证模型效果。
如表3所示,分别加入基于词级交互和AT-AS信息传递的双注意力机制;在消息迭代传递中传送方面级任务的输出更新共享变量(M-A);在消息迭代传递中传递篇章级任务的输出更新共享变量(M-T);加入TS/TC 任务进行参数训练。分析表3 数据,每一个分量的加入都有效提高了模型F1 分数,其中消息传递迭代中M-A 和M-T 对模型性能影响最大,可得消息传递机制的有效性,由于通用基础特征模块已嵌入篇章级文本语料库,所以后续TS/TC 任务获取的信息对模型性能影响稍弱。
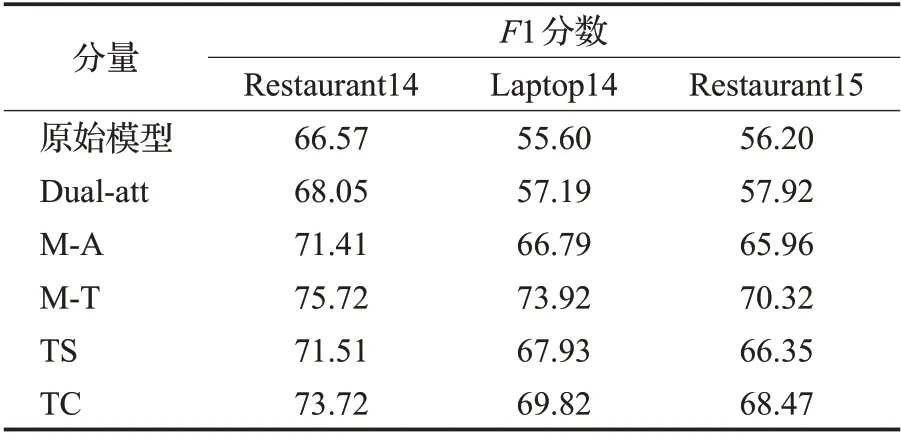
表3 分量对模型性能贡献对比Table 3 Components contribution to model performance comparison
3.6 GRU-MP网络性能
将方面级情感预测模块的基本方法运用到篇章级文本分类模块,对比文中提出的篇章级GRU-MP 网络,基本方法MTIITM-CNN 采用多层CNN 和自注意力计算,去除自注意力层BI 操作。对比结果如图4 所示,GRU-MP 网络通过注意力层得到的情感权重和最大池化操作提取位置不变特征和关键信息,更好地保留文本的语义信息和位置信息,在三个数据集上均比基本方法的F1分数有所提高,有效提高了情感预测性能。
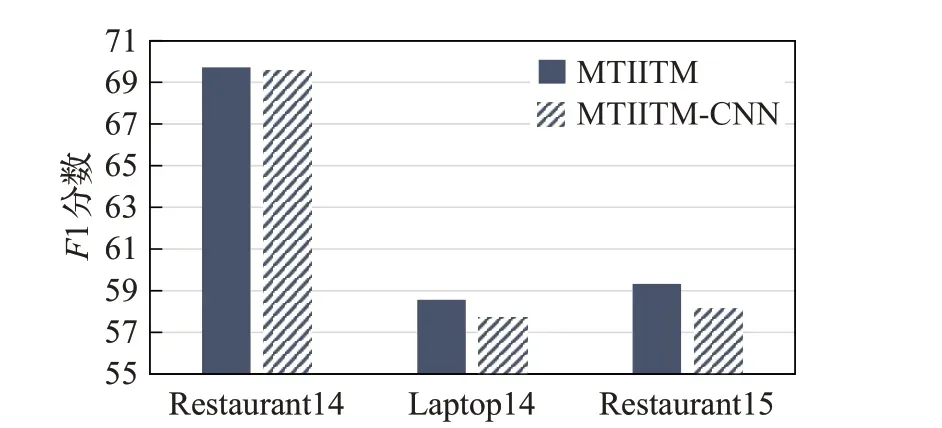
图4 GRU-MP网络性能Fig.4 GRU-MP network performance
4 结语
本文基于方面情感分析,提出基于消息传递机制的多任务交互式学习网络,设计的消息传递机制显式地对任务间交互进行建模,通过共享隐藏变量迭代传递信息,有助于特征学习和推理,并提高了模型性能。方面级任务中实现双注意力信息交互机制,通过GRU-MP网络实现篇章级任务预测,通过迭代算法在方面级和篇章级任务间交替训练,验证了模型的有效性和可行性。模型适用范围广,对于包含跨领域文本的方面情感分析,模型同样适用。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
小天使·三年级语数英综合(2022年4期)2022-04-28
时代英语·高二(2021年4期)2021-07-29
时代英语·高二(2021年4期)2021-07-29
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
中学生数理化·高一版(2016年6期)2016-05-14
金点子生意(2014年4期)2014-04-10
