
在线多类别逐点式多目标跟踪与分割
2022-10-18 01:02谭锦钢张广慧
计算机工程与应用 2022年19期
毕 鑫,谭锦钢,张广慧
1.中国科学院 上海微系统与信息技术研究所 仿生视觉系统实验室,上海 200050
2.中国科学院大学,北京 100049
视频目标跟踪是计算机视觉领域的一个重要研究任务,在视频监控、人机交互、自动驾驶等领域有着广泛应用。目前绝大多数基于深度学习的目标跟踪算法[1-14]都是联合目标检测与数据关联算法来跟踪目标,利用目标检测得到的边界框识别对象,并估计边界框在后续帧中的位置,将后续帧通过关联算法加入到之前帧的运动轨迹中,实现跟踪的目的,这类算法称为检测-跟踪(tracking-by-detection,TBD)算法。然而,当同一帧里目标过多发生遮挡时,目标之间的边界框很容易产生重叠,很可能包含来自其他目标的信息多于来自其自身的信息,极大地影响了跟踪的结果(见图1)。

图1 分割掩码vs.边界框Fig.1 Segmentations vs. bounding boxes
为了解决这个问题,近两年有研究[15-18]探索了一项新的任务,该任务被称为多目标跟踪与分割(multi-object tracking and segmentation,MOTS),目的是分类、定位、分割、跟踪整个视频序列中出现的特定类别的所有实例。这些工作提出了一种新的跟踪范式,即分割-跟踪(tracking-by-segmentation,TBS)模式。它改变了以往工作基于边界框的跟踪模式,将其细化为基于实例分割掩码的跟踪,从对象级到像素级的过渡极大地提高了跟踪精度。此外,实例分割掩码精确地描绘了可见对象的边界,并自然地分隔了相邻区域,相比于基于边界框的方法,MOTS 通过像素级分割,激励网络学习更具区分性的实例特征,实现了更鲁棒的相似性度量。
TrackR-CNN[15]首次提出MOTS 任务,并设计了一个新颖的基准网络架构和一套完整的评估体系。TrackR-CNN 将3D 卷积集成到MaskR-CNN[19]中,以利用时间上下文信息增强主干网络特征。因此TrackRCNN需要同时输入至少3帧的连续帧,网络难免存在延迟,其速度仅有2 frame/s。同样,MaskTrackR-CNN[16]在MaskR-CNN基础上引入了一个新的跟踪分支,以共同执行检测,分割和跟踪任务。TrackR-CNN和MaskTrackRCNN证明了将MaskR-CNN与跟踪网络及关联算法联合具有重要的研究意义。但是,这些方法均假定MaskRCNN可以有效的生成定位良好的边界框和准确的分割结果。然而,在高度多样化和非结构化的视频中,一方面,跟踪目标通常会遭受部分甚至完全的遮挡、变形以及姿势变化;另一方面,在许多情况下目标的外观相似且难以与凌乱的背景分隔开来。因此,目标检测很可能没有正确初始化,从而降低了后续边界框内预测的分割掩码的精确度以及链接掩码产生的跟踪结果的准确性。PointTrack[17]在无候选框的实例分割网络SpatialEmbedding[20]的基础上,提出逐点跟踪的模式,很好地解决了上述问题。然而它只能跟踪单个语义类别,比如车或者人,这在诸如自动驾驶的实际应用中非常受限。
为了实现快速的多类别多目标跟踪与分割,本文提出了一种能够以近实时的速度同时跟踪多个类别的跟踪与分割方法。本文的贡献点总结为:(1)针对MOTS任务,提出了一种新的在线多类别逐点式多目标跟踪与分割算法(category-free point-wise multi-object tracking and segmentation,CPMOTS),该算法能够在不影响速度的情况下并行处理多个语义类别,比如人和车,在实际场景中更加实用;(2)引入了一个直观且有效的注意力模块来显式建模通道间的相互依赖关系,进行基于通道的特征重标定,来促进神经网络自适应地选择最显著的特征进行跟踪;(3)在KITTI MOTS 数据集上的定性和定量实验表明,所提出的CPMOTS 优于现有的许多相关算法。
1 相关工作
1.1 TBD方法
现有的大部分基于TBD 的算法[1-14,21-22]基本都采用以下四个步骤:(1)目标检测;(2)特征提取和运动预测;(3)相似度计算;(4)数据关联。算法性能在很大程度上受限于目标检测的结果。很多基于图的方法使用运动信息[5]、多重切割[6]、边缘提升[7]或可训练图神经网络[8]等来提升网络性能,这些方法需要昂贵的资源和时间开销,限制了在线跟踪的实际应用范围。还有一类基于外观驱动的方法,这类方法最常用的是孪生网络架构[23],它具有先天的相似度计算优势。可学习的重识别特征[13]、亲和度估计[14]等算法也经常用来提升跟踪精度。但基于外观驱动的方法在许多物体互相遮挡的拥挤场景中进行重识别较为困难。
1.2 TBS方法
最近,少量研究开始尝试用TBS 方法来做跟踪,TBS方法利用像素级的分割结果能更精确地定位目标,极大地缓解了拥挤场景和模糊背景区域引起的常见外观问题。文献[18]提出了一种无模型的多目标跟踪方法,该方法使用与类别无关的图像分割方法来跟踪目标。TrackR-CNN在MaskR-CNN的基础上添加3D卷积来关联不同时间的对象身份(ID)。MOTSFusion[24]提出了一种融合2D边界框检测、3D边界框检测和实例分割结果的MOTS 方法。Ruiz 等人[25]联合弱监督实例分割与多目标跟踪,在不需要掩码标注的情况下实现多目标跟踪与分割。基于MaskR-CNN,MOTSNet[26]添加了一个掩码池化层,以提升对象关联算法的准确度。GMPHD[27]利用分层数据关联算法和一个简单的亲和度融合模型扩展了高斯混合概率假设密度滤波器。Lin等人[28]提出了一种基于MaskR-CNN的改进变分自编码器(VAE)结构,一个共享编码器和三个并行解码器,产生三个独立的分支,分别用于预测未来帧、目标检测框和实例分割掩码。PointTrack建立了一个新的MOTS数据集,并提出了一个新的跟踪框架。与先前的工作不同,该方法的实例分割部分使用一阶段的SpatialEmbedding方法,避免了常规两阶段方式实现的边界框预测不准带来的分割精度低的问题,并且速度上显著优于MaskRCNN。
2 CPMOTS算法描述
CPMOTS 算法的整体框架如图2 所示,受Point-Track[8]启发也采用逐点跟踪的范式,但与之不同的是,CPMOTS可以并行跟踪与分割多个语义类别,且保持近实时的速度。此外,CPMOTS采用通道注意力机制实现特征重定向,使网络能学习到更显著的特征,提升算法的性能。具体地,CPMOTS首先将单帧图片输入到实例分割网络(spatial embedding)[8]中得到实例分割掩码。然后,从平面的实例分割掩码中采样得到无序的2D 点集合及其初始特征。接着通过多层感知机得到实例嵌入向量,嵌入向量经过通道注意力模块获取更具辨别性的特征。最后,通过关联实例嵌入向量生成MOTS结果。
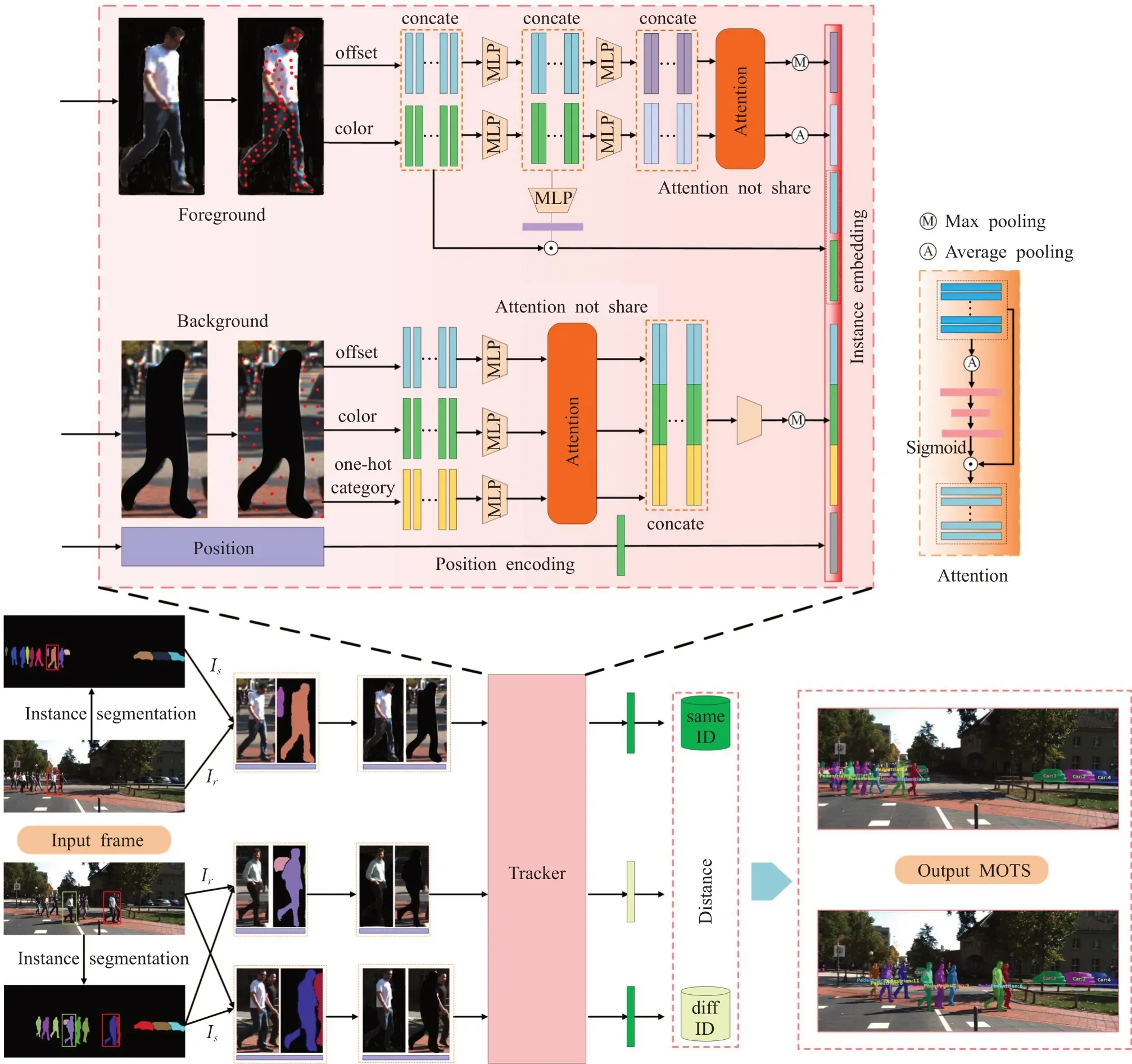
图2 CPMOTS网络架构Fig.2 Network architect of CPMOTS
2.1 多类别逐点式跟踪网络
CPMOTS是一个不限类别的跟踪网络,从图3的多类别分割网络可以看到,整体网络结构是多分支并行结构,可以同时分割与跟踪多个类别的目标。每一个类别分支在分割与跟踪网络的编码阶段特征共享,在解码阶段拆分成类别独立的并行分支,因此网络整体速度很快。在本文中,由于当前数据集只提供车和人两个语义类别的标注,因此CPMOTS 只能同时跟踪车和人两个语义类别。
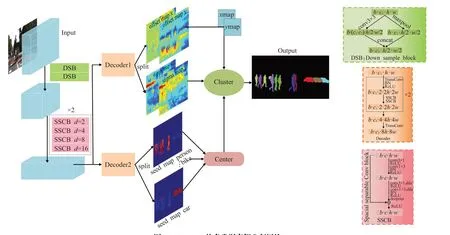
图3 CPMOTS的多类别实例分割网络Fig.3 Multi-category instance segmentation network of CPMOTS
为了使目标定位更加准确,在跟踪阶段,CPMOTS不仅考虑前景特征,也会考虑背景特征。对于一个实例I,它的分割掩码为Is,最小外切矩形框为Ir。将这个矩形框从上下左右4 个方向用一个尺度缩放参数α(α=0.2) 扩展得到Îr,如图2 中左下角分割掩码外侧的红色和绿色矩形框所示。从Is中采样得到的点集合看作是前景,定义为F。从扩展矩形框Îr中除Is以外的区域采样得到的点集合看作是背景,定义为B。
中包含背景信息及周围实例的信息,更有助于网络辨别假阳性实例,精准跟踪当前实例。因为有前景背景之分,CPMOTS 在训练分割网络时对前景赋予权重wf来提升前景特征提取的能力,并且针对不同的语义类别wf有不同的取值。点集合F和B中每一个点都由6个数据维度组成(x,y,C,R,G,B),其中(x,y)表示该点在二维图像中的位置。C指该点所属的语义类别,本文用独热编码来处理语义类别标签。(R,G,B)表示该点的颜色信息。
对于每个实例I,CPMOTS 分别从前景点集合F和背景点集合B中随机均匀地采样NF(NF=1 500)和NB(NB=750 )个点。通过对图像平面中NF个点的坐标求平均值可以得到一个实例中心点Q(xcF,ycF),进而可以计算出每个点相对于Q的偏移量。网络通过对这些点的位置、类别、颜色以及偏移量四种数据特征进行编码,生成实例嵌入向量。
2.2 通道注意力模块
如图2上半部分所示,当采样点的各个初始特征分别进行编码后,为了促使神经网络自适应地选择最显著的特征进行跟踪,本文使用一个简单却高效的注意力模块来显式建模特征通道间的依赖关系。与其他大部分在图像层面操作的注意力模块不同,本文采用的注意力模块是对点特征进行操作。考虑到通道层面的信息足以提取显著性特征以满足后续的跟踪,同时鉴于跟踪任务对于网络运行效率的要求更高,本文和需要用到空间依赖关系的注意力模块也不一样,仅利用通道信息,采用特征重标定的策略,用学习的方式来自动获取每个特征通道的重要程度,以达到强化有用特征的目的。
具体来说,对于NF个采样点,特征为P=[p1,p2,…,pNF],P∈ℝNF×c。为了获得一个全局接收域,注意力模块首先使用沿空间维度的全局平均池化来生成通道统计信息,此时输出为oc∈ℝ1×c:


该过程能够强化重要程度较高的特征通道,抑制重要程度较低的特征通道。这个过程被称为通道层面的原始特征重标定。
2.3 跟踪网络损失函数
CPMOTS 的目标输出包含实例分割掩码和相应的跟踪ID。本文对于每一个待跟踪的实例,不是像其他方法一样都是从连续帧中选择,而是从其轨迹中随机选择一帧作为中间帧,然后从其前后10 帧的范围内各随机选择一帧作为前后帧。这样引入随机的方法可以增加每个实例轨迹内的差异性,得到更泛化的跟踪结果。本文通过基于距离阈值δ的Triplet Loss[29]来训练跟踪网络,跟踪的损失函数定义为:
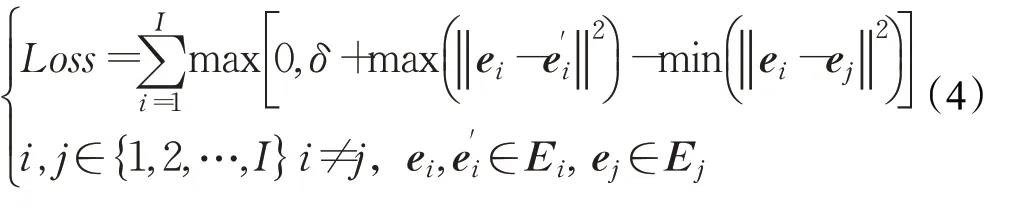
其中,Ei表示第i个实例的嵌入向量集合(一共三帧),ei、e′i分别表示其中任意不同两帧的嵌入向量;I表示当前批次训练数据中待跟踪的所有实例;δ是为了防止过拟合而引入的阈值,默认值为0.2。从上式可以看出,该损失函数的目标是最小化相同实例对应的嵌入向量间的距离,同时最大化不同实例的嵌入向量之间的距离。最终,在嵌入空间中同一实例的嵌入向量会更相似,在后续实例关联时的匹配度更高。而不同实例的嵌入向量会更不同,在实例关联时可以降低匹配错误率。CPMOTS采用常用的匈牙利算法[30]做实例匹配,基于相似度做关联输出最终的跟踪结果。
3 实验结果及分析
3.1 数据集
KITTI MOTS 是最常用的用于多目标跟踪与分割的基准数据集。该数据集中的视频均来自于车载相机,训练集总共包含21 个视频序列,对应21 个不同的真实场景,分为12个训练序列和9个验证序列,一共有8 008帧图像,其中标注了26 899 辆车和11 420 个行人,目标在帧间有一致的ID和实例标签。测试集一共包含29个视频序列,对应29 个不同的真实场景。本文在KITTI MOTS[8]数据集上对提出的CPMOTS算法进行了大量的实验来验证算法的有效性。
3.2 评价标准
MOTS的评价标准是由TrackR-CNN基于多目标跟踪系统的标准评价措施CLEAR MOT[31]扩展得到的,主要是用多目标跟踪与分割准确度(multi-object tracking and segmentation accuracy,MOTSA)及其soft 版本(soft multi-object tracking and segmentation accuracy,sMOTSA),以及多目标跟踪与分割精度(multi-object tracking and segmentation precision,MOTSP)来评估。
形式上,具有T个时间帧,高度h和宽度w的视频的标注真值由N个标注的分割掩码M={m1,m2,…,mN}组成,其中mi∈{0,1}h×w,每个掩码对应一个唯一的实例ID,但每个实例ID可能对应多个掩码。对应地,网络的输出结果是K个预测掩码H={h1,h2,…,hK} ,其中hi∈{0,1}h×w,每个预测掩码也分配给一个实例ID。每个前景像素被唯一地分配给标注掩码中某一个实例,而在预测掩码中至多分配给一个实例。因此,对于给定的标注掩码,至多存在一个预测掩码与之交并比(intersection-over-union,IoU)大于0.5。于是,从预测掩码到标注掩码的映射c:H→M∪{∅ } 可以简单地使用基于掩码的IoU定义为:

sMOTSA 累计的是TP͂(正确预测的掩码的IoU 值之和),而不是TP(正确预测的掩码数量),因此它能同时衡量分割检测和跟踪的质量。
3.3 实验环境和参数设置
本文算法使用Python语言在Ubuntu16.04系统上用Pytorch框架进行实验,实验环境如表1所示。尽管本实验所用设备显存为24 GB,但在推理时分割阶段只需要0.9 GB,跟踪阶段只需要1.5 GB 的显存大小,对硬件的要求不高。

表1 实验环境Table 1 Experimental environment
和之前的工作[15,17]一样,由于KITTI MOTS 中训练数据集有限,CPMOTS 先在KINS 数据集上预训练实例分割网络,一共训练180 轮,此时的输入是被裁剪之后的图,车和人的前景权重wf分别设置为10 和20。随后,分割网络在KITTIMOTS 上微调,以5×10-6的学习率再训练100 轮,由于此时输入的是未被裁剪的原图,车和人的前景权重wf分别设置为230和250,跟踪阶段以2×10-3的学习率训练50 轮,损失函数中距离阈值δ设置为0.2。
3.4 KITTI MOTS数据集结果
如表2 所示,本文在KITTI MOTS 验证集上与MOTS 之前的一些相关工作进行了对比:TrackRCNN[15]、MaskTrack R-CNN[16]、CAMOT[18]、MOTSNet[26]、GMPHD[27]、VAE[28]、CIWT[32]、BePixels[33]以及根据作者提供的代码和方法训练的PointTrack[17](表中PointTrack-U)。本文着重关注sMOTSA 和IDS 两个指标,因为它们能直接反映出跟踪和分割的精度与算法的鲁棒性。表2数据显示,本文提出的CPMOTS算法性能优于之前发表的工作中同时跟踪人和车的大多数算法,比如TrackR-CNN 和MOTSNet。从表中可以发现,GMPHD和PointTrack 等算法在性能上优于本文方法,究其原因是因为这些方法只同时跟踪一个语义类别,可以使得网络聚焦于学习该类别的专属特征,因此其性能理论上会优于本文提出的多类别算法CPMOTS。
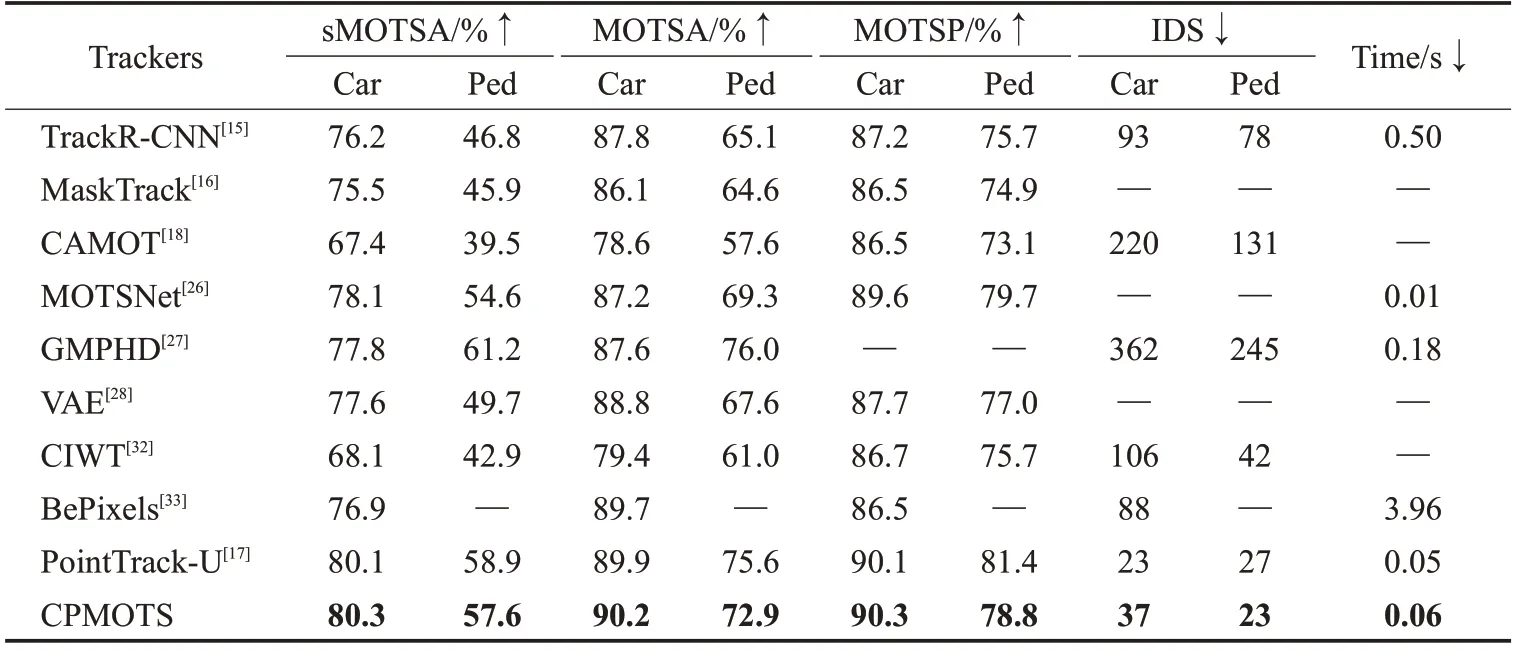
表2 KITTI MOTS验证集不同网络对比结果Table 2 Comparison results of different networks in KITTI MOTS validation set
如表3 是CPMOTS 上传到KITTI MOTS 测试集上得到的结果,验证集中大部分方法没有上传到测试集,但与TrackR-CNN和MOTSNet结果对比可以看到,本文提出的CPMOTS 算法在各项指标上都有明显的提升,尤其是sMOTSA 和IDS 两个最重要的指标。相对于TrackR-CNN 算法,sMOTSA 在车和人上分别提升了5.8%和11.2%,而IDS则分别大幅减少了289和272。对比MOTSNet算法,sMOTSA在车和人上分别提升了1.8%和9.8%,而IDS则分别减少了25和64。此外,CPMOTS保持了16 frame/s 的在线速度,充分证明了CPMOTS 算法的鲁棒性和实用性。
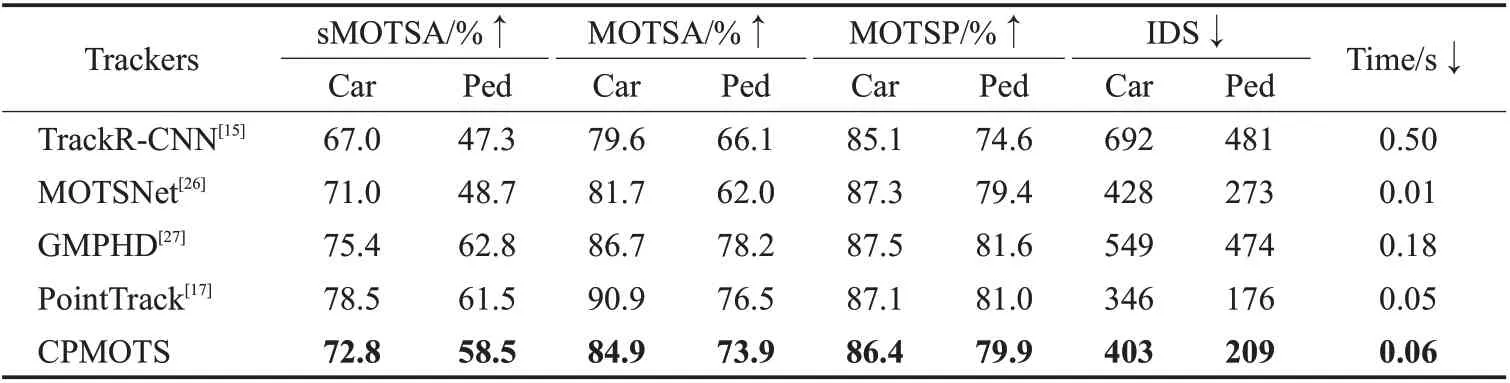
表3 KITTI MOTS测试集不同网络对比结果Table 3 Comparison results of different networks in KITTI MOTS test set
图4 可视化了CPMOTS 和其他两种典型方法在KITTI MOTS数据集上的效果,图中选取了3种不同的问题场景,箭头标注了重点目标,不同方法用不同颜色标出。在光照变化、完全遮挡、尺度变化等不利因素下,对比其他方法,CPMOTS依然可以准确定位目标并保持ID不变,证明了算法的鲁棒性。由于PointTrack是单类别算法,因此每种场景有两行图像:第一行是车,第二行是人。第一个场景显示在数次完全被遮挡的情况下,CPMOTS不仅依然能识别目标,而且全程保持ID不变,而TrackRCNN 在第三帧出现了ID 变换。尽管Point-Track可以准确地跟踪车并保持ID不变,可是从第四行可以看出,它全程将交通指示牌误检成人,误检率较高。第二个场景展示了在光照变化、尺度变化等不利因素下,CPMOTS 依然能准确的跟踪目标,其他两种方法都出现了丢包现象。第三个场景表明在多个语义类别同时存在的拥挤场景中,即使存在完全遮挡、尺度变化、光照变化等不利条件,CPMOTS 依然可以准确跟踪与分割每一个目标,并始终保持ID 不变,而TrackRCNN和PointTrack 不仅无法识别出骑自行车的人,在多次行人遮挡之后,4 辆车的ID 也发生了改变。在KITTI MOTS 数据集上的定性和定量实验充分证明了本文提出的CPMOTS算法具有良好的性能以及对不同场景的适应能力。

图4 不同方法在KITTI MOTS上的可视化结果Fig.4 Visualization results on KITTI MOTS of different methods
3.5 消融实验
为了验证通道注意力模块和各个超参数设置对于CPMOTS 算法性能的影响,本文进行了大量的消融实验,如表4所示。依次修改注意力模块(Attention)、损失函数中的距离参数δ(Margin)以及分割网络微调时的前景权重(Weight,第一列项是车第二列项是人),在实验中发现此时的前景权重对于结果的影响比其他时刻大很多。当修改其中一项时,另外两项保持不变。从表4 可以看到,CPMOTS 在搭载注意力模块的基础上,损失函数的距离参数设为0.2,分割网络微调时车和人的前景权重分别设为230 和250 时,性能最佳。当未搭载注意力模块时,算法性能出现大幅度的下降,说明注意力模块对于CPMOTS算法性能的提升有很大作用。
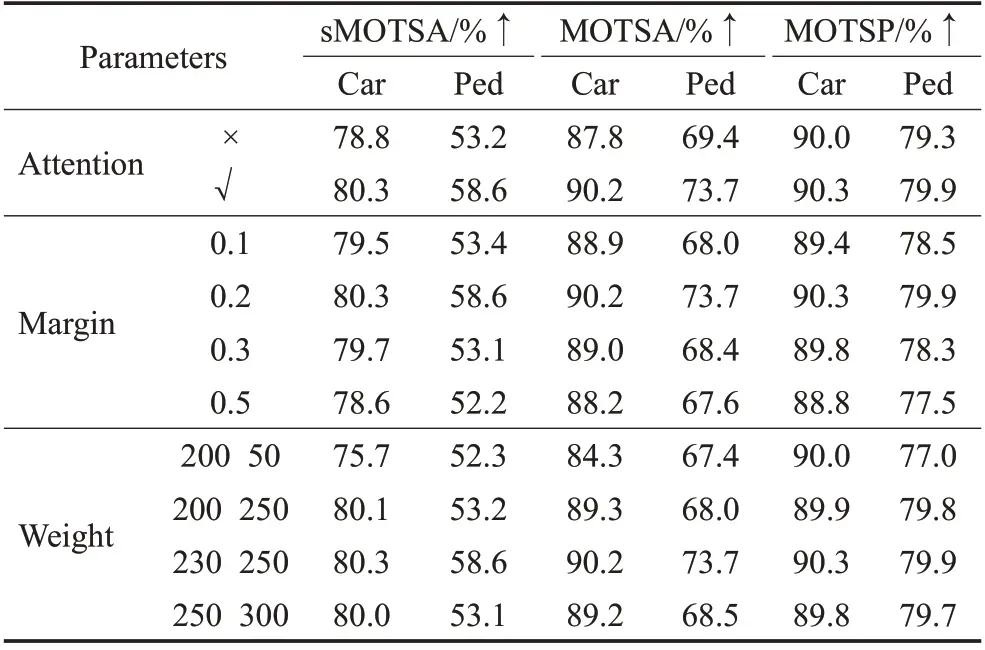
表4 不同参数对性能的影响Table 4 Impact of different parameters on performance
从图5的可视化结果也可看出,本文的注意力模块能够对不同的通道特征进行选择,去强化重要程度较高的特征,抑制重要程度较低的特征。图中越重要的特征通道颜色越亮,越不重要的特征通道颜色越暗,证明了注意力模块的有效性。当选取不同距离参数时,算法表现差异略有下降。相比之下,当改变前景权重时,算法会出现较大的性能下降。这种表现差异表明,CPMOTS更多地关注目标的外观特征和环境特征,对于损失函数中距离边距的依赖较小。

图5 经过注意力模块的通道特征可视化结果Fig.5 Visualization result of channel feature through attention module
为了计算背景特征所需的运算复杂度,本文还做了一个对比实验,对比去掉背景特征前后所需的时间以及显存大小。实验结果表明,去掉背景特征之后,跟踪时每张图片处理速度提升0.006 8 s,而显存仅释放6兆,说明背景特征所需的运算复杂度不太高。
4 结语
本文针对多目标跟踪与分割任务,提出了一个快速的基于注意力模块的多类别逐点式跟踪与分割算法CPMOTS。在KITTI MOTS 数据集的评估结果表明,CPMOTS 算法在速度与精度的综合对比中优于之前的许多算法。尽管本文的算法在部分性能上略低于一些单类别算法,但相对于单类别算法,CPMOTS 能够并行地跟踪与分割多个语义类别,且在1 242×375 的图像上达到近实时(16 frame/s)的速度,更适用于真实场景。未来的研究方向将侧重于提高CPMOTS 的速度,使其达到实时,进而可以应用在更多的实际场景。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
微型计算机(2009年4期)2009-12-23
中学英语之友·高一版(2008年10期)2008-12-11
