
知识图谱在商业银行风控领域的研究与应用综述
2022-10-18 01:04刘国柱梁宏涛罗清彩
计算机工程与应用 2022年19期
袁 俊,刘国柱,梁宏涛,罗清彩
1.青岛科技大学 信息科学技术学院,山东 青岛 266061
2.山东浪潮科学研究院有限公司,济南 250101
近年来,新冠肺炎疫情的突发在引发全球范围内不确定风险加剧的同时,不仅造成金融市场的恐慌和极端波动[1],也深深影响商业银行的经营和发展。国内外经济形势动荡不止,金融市场反应剧烈,银行业在风险管理过程中的难度也不断加大。在此背景下,传统风控模式下的潜在风险将加速暴露。
传统风控模式存在的局限性如下:
(1)缺乏对数据有效的整合和利用。金融领域实现信息化后,历时数十年已经积累了庞大的数据,但在商业银行内部,客户信息、账户信息、交易信息等数据通常散落在各个独立的业务系统之中,利用效率和分析能力不足。行内往往存在着一个个“烟囱式”信息孤岛,缺乏有效的信息整合,许多有价值的非结构化数据被埋没在高熵无序的信息汪洋之中。
(2)缺乏高效识别和监控风险的手段。对于授信客户的风险管理,无法在风险预警、监控等管理层面提供高效科技手段,对实际触发数据的筛查和前期风险特征识别预警的手段不多。对于客户洞察,通常以单个客户为分析对象,根据客户的行为与特征分析其风险状况,对客户关系网络的探索较少。
(3)缺乏与时俱进的风险管控模式。近年来商业银行接连推陈出新,新的业务和产品层出不穷,业务模式由柜台服务向手机APP、微银行、网络银行、自助终端、智能柜台等线上渠道及平台全面延伸。而欺诈行为也变得隐蔽和多样化,只依靠过去传统的规章制度、手工台帐报表、人工审批和事后检查等方式来发现潜在风险、解决违规已显得力不从心,原有的风险管控模式亟需随着业务改变而调整。
随着不断地经营发展,授信企业跨业经营、股权并购、融资结构日益复杂化、隐蔽化,这对商业银行信用监测、风险评估等工作带来了巨大的挑战。在金融数字化议程加速的背景下,为解决传统风控模式的弊端,商业银行亟需推进风险管理工作中的科技创新,加快数字化转型建设步伐。在风控领域中,风险往往不会孤立发生。对于自然人客户,盗卡盗刷、非法套现等欺诈行为常常是团伙作案。对于企业客户,随着资金链、供应链、担保链以及集团化的不断发展,容易发生火烧连营般的连锁反应。传统的风控体系难以应对此类关联性风险,基于图数据结构构建的知识图谱(knowledge graph,KG)[2]是解决此类问题的有效途径。知识图谱技术可以关联不同数据源系统的孤立数据,提供客户风险的统一视图,打破信息壁垒,有效解决信息不对称问题;能够实现针对客户关系网络的洞察,有效防控关联性风险,提升风控效能;能够实现风险数据的自动化采集、分析和预警,并深入挖掘金融实体之间的隐蔽关系。
为此,本文将对风控领域知识图谱的构建方法进行系统性综述。
1 风控领域知识图谱的概念与架构
1.1 风控领域知识图谱的概念
想要理解风控领域知识图谱的概念,首先要了解什么是知识图谱。1989 年,Bemers-Lee[3]发明了基于网页之间相互链接的万维网(world wide web,WWW),并在之后提出了新的网络系统,在万维网基础上将其转换为基于实体链接的语义网络——语义网(semantic web,SW)。语义网能够帮助计算机理解蕴含在自然语言中的知识以及它们之间存在的关联关系。在语义网的铺垫下,Google 公司于2012 年首次提出了知识图谱的概念,并将其用于理解搜索关键词的语义信息,为搜索结果提供关键词相关的人物、地点、事件等补充内容。随后知识图谱逐渐在学术界与工业界得到深入研究,并在搜索服务、智能问答、情报分析等多个领域中大放异彩。但直到如今,知识图谱的概念一直未有统一的定义,现借鉴文献[4]对知识图谱做出定义:“知识图谱是一种采集信息并将信息集成到本体中、应用推理机以获取新知识的的系统。”具体来说,知识图谱是将物理世界的事物建模成相互关联的知识网络,它将实体抽象为一个个具备属性的节点,而将两实体间的语义关系抽象为连接这一对节点的边,并以三元组的形式存储这些实体、关系以及属性。例如三元组“担保(客户A,客户B)”描述了两客户间的担保关系,三元组“行业类型(客户,金融业)”描述了客户的行业类型属性。
从知识的适用范围出发,可将知识划分为常识知识和领域知识。相应的,知识图谱也可分为通用知识图谱与垂直领域知识图谱。通用知识图谱覆盖多领域、多场景,具备相当大的知识广度,如DBpedia[5]、Yago[6]、Wikidata[7]、Knowledge Vault[8]等。与之相比,垂直领域知识图谱对知识的深度与粒度要求更为严格,其结构更为复杂,知识的应用形式也并不限于搜索、问答、推荐,可提供更为广泛的知识服务。由于面向的业务场景不同,二者侧重也不同,其构建流程及关键技术存在一定的差异。在表1中,对通用知识图谱与垂直领域知识图谱在知识图谱的构建技术方面作了比较与分析。目前在金融行业中,已有商业银行将知识图谱技术应用在金融问答、智能风控、精准营销、智能决策等领域中。面向商业银行的风控领域知识图谱指的是将知识的覆盖范围和应用目标聚焦于风控领域,图谱中管理着客户信息、业务信息、风险信息等多方面的知识,能够结合规则指标或算法模型自动执行对风险的识别和预警。

表1 通用知识图谱与垂直领域知识图谱构建技术的比较Table 1 Comparison of construction technology of general knowledge graph and vertical domain knowledge graph
1.2 风控领域知识图谱的架构
风控领域知识图谱的架构主要包括其逻辑结构与体系架构。
(1)逻辑架构。从逻辑上看,风控领域知识图谱可以分为描述抽象概念的模式层与描述具体事实的实例层。模式层中的知识是经过整合和概括的,冗余较少,一般用构建本体库的方式对这一层次的知识进行管理,并对领域术语及它们之间的关系进行形式化表达。本体的概念源于哲学领域,早在上世纪80 年代就被引入人工智能领域中,用于在语义层次上对知识进行分类和描述。而实例层中的知识可以看作是有具体指向对象的本体实例。
(2)体系架构。知识图谱的体系架构指其使用何种构建模式,主要有两种方式:自底向上和自顶向下。前者是指直接从底层数据中获取资源,将置信度高的实体、关系及其属性归纳到知识库中,再根据知识库中的知识逐步向上抽象形成概念,以构建顶层的本体模式。后者指的是首先为知识图谱构建出本体和数据模式,再将抽取的对象整合到顶层概念中。一般来说,通用知识图谱中的知识面向通用领域,本体的复杂度不高但数目庞大,可以通过自底向上的方式、以数据为驱动实现自动化创建本体库,节省人力和时间。垂直领域知识图谱中涉及的术语和概念在广度上相对有限,其复杂性表现在知识的深度上,所以可以由业务专家枚举该领域中的重要业务术语,借助本体编辑软件手动创建本体,能够有效保证本体库的质量。在风控领域,基于特定的业务关注点,可以考虑将客户的电话号码、地址等这样的一些属性信息设计为独立实体节点。本体建模不仅需要正确而完整地描述已有的业务,还需要对将来的业务场景有一定的预估,才能设计出高适用性和高稳定性的本体框架。
综上所述,为保证知识质量和准确度的要求,面向商业银行风控领域的知识图谱可以采取自顶向下与自底向上相结合的构建方式刻画客户、账户、合同、押品、机构等实体及其属性、关联关系。如图1所示,其构建流程可归纳为知识抽取、知识融合以及知识推理等步骤。
2 风控领域知识图谱的构建技术
知识图谱是一个横跨多领域、多专业的庞杂学科,想要构建一个大规模的风控领域知识图谱,需要综合自然语言处理、机器学习、深度学习等各类技术[9]。在知识抽取阶段,可从商业银行积累的海量数据中提取出实体、关系以及属性等信息。在知识融合阶段,可以对描述同一实体或概念的多源异构知识进行融合,消除歧义和冗余,有效提升知识质量。知识推理阶段则是在现有的知识图谱基础上,进一步挖掘其中隐式的、包含的知识,对知识图谱进行补充。
2.1 知识抽取
在知识图谱的自动化构建流程中,知识抽取是一项重要环节。知识蕴藏于数据之中,知识抽取技术的关键在于如何从异构数据源中自动提取出高价值信息,并将它们存入知识库中。风控领域知识图谱中的知识主要来自于商业银行的内部数据,一般以结构化的形式存放在关系型数据库中。2012年,著名的标准化组织W3C发布了两种RDB2RDF映射语言:直接映射(direct mapping,DM)[10]与R2RML[11],可以实现将结构化数据转化为OWL本体或RDF数据。商业银行外部数据包括中国人民银行征信报告、银监会披露的风险预警数据、国家工商总局公示的企业信用信息、区域范围内的各级法院公告的裁判文书及执行信息、各级税务机关披露的企业欠税及行政处罚、网络百科及财经新闻等数据,这些也是风控领域知识图谱的重要数据来源。其中如工商信息、裁判文书、网络新闻等主要以半结构化或非结构化的形式存在。对于来源不同、结构不同的数据,抽取过程中所使用的关键技术及其难点也迥乎不同。对于网页中的半结构化数据,通常使用已制定抽取规则的包装器对网站进行解析。对于以文本为代表的非结构化数据,抽取难度较高,需要借助自然语言处理技术,根据抽取对象的不同可以细分为实体抽取、关系抽取、属性抽取等子任务。
2.1.1 实体抽取
实体抽取,即命名实体识别(named entity recognition,NER)[12],旨在从目标文本中界定如账号、组织机构名、人名、货币、金额等命名实体,是风控领域知识抽取过程的关键部分,如图2通过举例对NER任务进行了描述。银行账号通常是一连串的数字,也可能夹杂字母,需要结合银行制定的账号生成规则进行识别和抽取。组织机构称呼通常多种多样,如“阿里巴巴集团控股有限公司”别名有“阿里”“阿里巴巴”“阿里集团”等。货币类型也有多种形式,如“人民币”也可以用“¥”“RMB”“CNY”“Chinese yuan”等符号或文本表示。金额可以是数字,也可能是大写的汉字,如“1 680.50”“壹仟陆佰捌拾元伍角”等。在风控领域,命名实体形式多样、专业术语复杂等因素给NER带来了巨大的挑战。
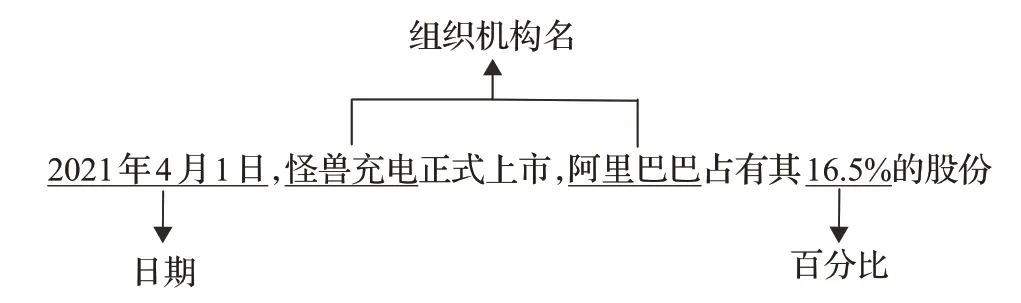
图2 实体抽取示例Fig.2 Example of entity extraction
经过长时间的探索和研究,目前工业界针对实体抽取问题已积累了大量的经验和方法,表2介绍了几种具有代表性的NER方法。这些方法大致可分为基于规则的方法、基于统计模型的方法和基于深度学习的方法。研究初期主要是人工构建规则的方法[13-15],将业务专家手工编写的规则与目标文本进行字符串层面的简单匹配,从而识别出命名实体。但这类方法依赖于规则的准确度和词典的覆盖面,无法识别规则覆盖范围外的新实体,而且在大规模文本数据集上的效果不尽如人意。随着机器学习算法不断深入发展,学术界逐渐将其应用于解决实体抽取问题并取得了不错的效果,如隐马尔科夫模型(hidden Markov model,HMM)[16]、最大熵模型(maximum entropy,ME)[17]、条件随机场(conditional random field,CRF)[18]等。这类基于统计模型的方法实际是将实体抽取作为序列标注问题处理,通过语料标注、特征定义、训练模型等步骤识别出文本中的实体。2015 年,为提升商业银行风控工作效率,Alvarado 等[19]提出了一种基于大量域外数据和少量域内数据相结合的NER 方法,使用CRF 模型从贷款协议文件中提取信用风险信息,对借款人名称、贷款人名称、金额、日期、地点等实体进行抽取,F1 值达到0.798。但对于机器学习模型,人工预先定义的特征在很大程度上决定了实体抽取的准确率,而深度学习方法则可以突破此限制,近年来学者们提出了多种神经网络结构,在NER 任务的应用中获得了较好效果。2020年,为了监控系统性金融风险,Cheng 等[20]基于知识图谱框架对外汇市场参与者进行实时监控,通过BiLSTM-CRF提取新闻文本中的金融实体,在银行间市场参与者相关新闻的数据集上,准确率和Recall 值分别为93.33%、97.68%。2021 年,为防范合规风险,Wang 等[21]提出将BERT 与BiLSTM-CRF 结合,通过BERT预训练词向量并作为BiLSTM-CRF模型的输入,以银行间外汇市场中的海量聊天记录作为数据集,对债券简称、债券类型、发行人等债券信息实体的识别结果在微平均和宏平均指标上比基于规则的方法高出1%~2%。随着互联网的发展,负面舆情能够在极大程度上影响企业的经营,近年来客户舆情风险成为商业银行风控落脚点之一,但舆论文本中往往存在多个实体而只有少数的关键实体。针对传统NER方法无法检测关键实体的问题,Zheng 等[22]提出了一个端到端的分层多任务学习框架HMFF,可增强关键实体识别的特征学习,在2019 CCF BDCI“金融信息负面及主体判定”数据集上,关键实体识别任务的F1值达到0.950。对于同一任务、同一数据集,Zhao等[23]采取了不同的方法,通过基于RoBERTa的舆情分析以及关键金融实体检测的方法,在抽取所有实体后通过句子匹配任务进一步确认关键实体,模型的F1值达到了0.952,略优于Zheng等人[22]的方法。除舆情风险外,企业的司法风险也是商业银行风控工作的重要关注点,文献[24]针对司法案件文本中存在的难点,将词语以及词性关系的拼接向量输入到双向LSTM神经网络中提取特征,通过2个多层感知器再编码得到词向量与词性关系向量,将所有词向量拼接,并将所有词性关系向量与1个单位向量进行拼接,随后利用中间矩阵对拼接向量进行仿射变化,得到分数矩阵对实体头尾、类别进行判断,有效解决嵌套实体问题与原被告角色反转问题。

表2 知识抽取方法的比较Table 2 Comparison of knowledge extraction methods
NER 一直以来都是工业界和学术界研究的热点问题,根据实体抽取的定义可以将其分解为实体边界识别和实体类型识别两个步骤[25],提高实体边界检测的效果能够直接有效地提高NER的准确率与召回率。
2.1.2 关系抽取
关系抽取(relation extraction,RE)的目的是为了获取多个目标实体之间的关联关系,例如从“百度集团董事长李彦宏的夫人是马东敏女士”这句话中,可以抽取出两个实体关系三元组“董事长(百度集团,李彦宏)”、“夫妻(李彦宏,马东敏)”。目前存在着众多RE方法,大体上可以分为基于模板的方法、基于监督学习的方法以及基于弱监督学习的方法。
初期的RE 任务大多借助于模板匹配的方法。Wu等[26]采用基于规则和模板的方法,在2003—2016年中国上市公司财经新闻中提取出诉讼、质押、债务等6 种实体关系,以构建用于金融领域RE任务的大规模语料库,并提出了基于词性标注与BIES 标注的混合方法,经人工验证在测试集上RE 任务平均准确率为88.88%。与基于规则的NER方法的优缺点类似,基于模板的RE方法虽然构建起来简单,在小规模数据集上效果不错,但是覆盖范围有限,可移植性差。与之不同,基于监督学习的方法实际上将RE任务转换为分类问题。Yamamoto等[27]利用马尔科夫逻辑网络从4 661篇网络新闻数据集中提取企业关系,在每种关系的100 个样本上,对于合作类关系与竞争类关系的准确率分别达到67%、81%。机器学习模型虽能取得不错的抽取效果,但严重依赖特征工程,于是无需人工构建特征的深度学习方法受到青睐。在风控领域,企业客户群体之间关系不明确会导致商业银行信用风险加大,具体如给予多头授信以及过度授信等。为有效提升集团客户识别、贷款集中预警等风控工作的效率及准确性,2019年,Yan等[28]提出一种基于ERE-GRU 模型的企业关系自动抽取方法,使用双向门控循环单元BiGRU 搭建神经网络,通过提取词汇特征和句法特征挖掘企业实体之间的关系,在手工标注的金融领域新闻数据集上F1 值可达到0.71,但较多的特征增加了向量维数。在文献[28]的基础之上,Yang等[29]提出了一种SDP-BGRU 模型,采用实体间最短依赖路径(shortest dependency path,SDP)以及句子级注意力机制消除冗余和噪声数据,利用双向门控循环单元BGRU获取特征向量,并通过SVM 分类器将企业关系抽取问题转化为分类问题,在手工标注的财经新闻数据集上的F1值为0.919,可有效识别企业客户关系,增强风险应对策略。在银行风控中,企业关系和自然人关系训练语料来源大不相同且不均衡分布,一起训练会产生较大噪声,针对此问题,李梦霄等[30]提出分开训练企业关系和自然人关系抽取模型,随后利用分开训练的BERT模型对新闻文本中的实体与关系进行管道式抽取,并与银行内部图谱进行融合以支持风控决策。由于关系抽取的效果依赖于实体识别的准确率,学者们发现实体关系联合学习能够比单任务学习取得更优的泛化结果。2022年,田鸥等[31]提出了一种风险传导概率知识图谱生成方法,采用BERT-LSTM-CRF模型抽取企业实体关系对三元组,并引入掩码多头注意力结构提升BERT层提取上下文信息的能力,首先将企业信息输入到BERT层进行编码得到对应文本向量,再经LSTM层得到各字词对应的类型分布概率,由CRF层生成实体关系对,通过计算企业关系对的风险传导概率,有效防控沿客户关系链的风险传播。针对金融领域中的复杂重叠关系,唐晓波等[32]在预训练语言模型BERT 的基础上结合BiGRU 以及CRF,构建端到端的实体关系联合抽取模型,在采集的上市公司资讯信息数据上重叠关系抽取任务的F1值达0.543。2022 年,杨美芳等[33]提出基于知识图谱与文本互注意力机制的实体关系联合抽取模型,通过大规模的风控领域语料与较少的高质量实体关系进行训练,经风控领域专家评估该模型在测试集上的整体误判率为10.7%。基于监督学习的方法离不开训练语料,对深度学习模型的优化尤其依赖大量训练数据。在这一点上,弱监督学习方法具有突出表现,只需要少量标注数据就能进行学习,主要包括远程监督以及Bootstraping 方法。为理清股票发行企业面临的金融风险,刘政昊等[34]在金融知识图谱的构建过程中,使用远程监督方法抽取持股、投资、面临风险、实际控制人等13类关系,通过利用种子知识图谱获取可用于训练的标注数据,可有效节省标注成本,随后使用PCNN+Attention模型进行训练,平均F1 值为0.67。Zuo 等[35]使用弱监督策略从金融新闻语料库中提取企业间复杂业务关系,通过少量的初始种子迭代抽取实体关系,在2007 年新闻文章随机挑选的100个样本上,recall值与F1值均优于PCNN模型。
目前,RE 方法经过长时间的发展已经取得了一定成果,但在风控领域的实际应用中仍存在着一些挑战。相比较通用领域,风控领域中的实体关系类型并不复杂,如图3所示。一般不需要从知识图谱中拓展新的关系类型,但风控领域知识图谱往往存在关联关系十分隐蔽的情况,需要结合知识推理技术进行深度挖掘。
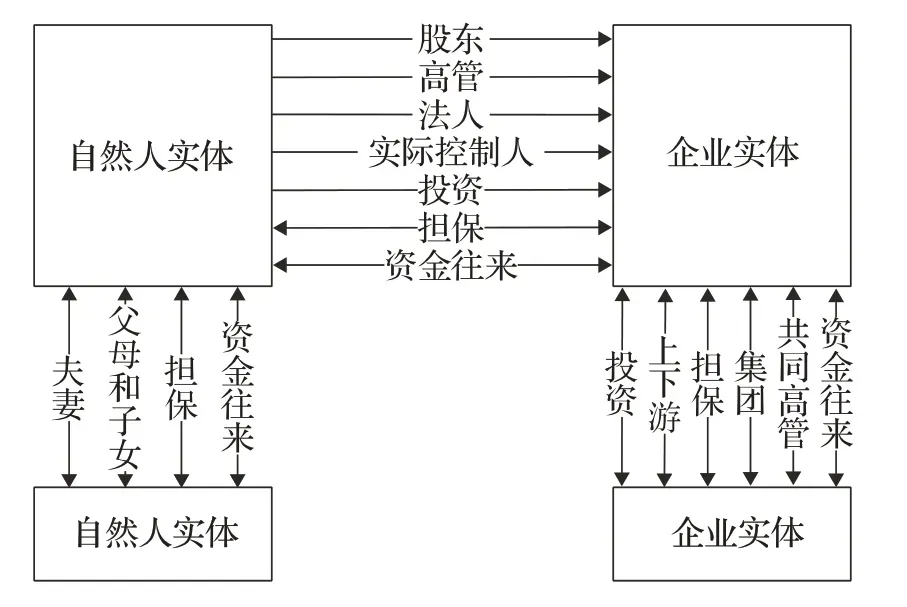
图3 实体关系类型Fig.3 Relation types of entities
2.1.3 属性抽取
属性抽取(attribute extraction,AE)的目的是为了从文本中抽取出“属性(实体,属性值)”形式的三元组,以助于对实体充分理解。风控领域中,存在属性值为日期、金额、企业名或人名等,如“阿里巴巴(中国)网络技术有限公司”注册日期属性为“1999-09-09”,法定代表人属性为人名“戴珊”,可使用NER 方法解决属性抽取问题,将属性看成实体与属性值之间的关系。2021年,文献[36]提出了一种基于金融知识图谱的信贷风险识别方法,采集银行客户的信贷风险数据,利用BERT 将文本中的词语转化为词向量的形式,输入到LSTM-CRF神经网络模型中,以获取信贷风险实体及属性信息。针对授信企业涉及的舆情风险,文献[37]提出了一种风险事件分级方法,通过BERT-BiLSTM-CRF模型对公司名称、注册资本、经营范围、注册地址、金融产品等实体属性进行抽取,并通过Albert模型对损失金额、处罚金额、涉诉金额、死亡人数等事件属性进行抽取,随后对风险事件等级进行评定,以提升商业银行在金融交易中的决策能力。文献[38]采取BERT-BiLSTM-CRF模型对爬取的舆情信息进行舆情主体及对应属性的提取,将AE 问题转化为NER任务,并利用舆情主体、属性和预警模型确定舆情评分,通过知识图谱实现舆情信息的预警级别判定与预警信息推送。文献[39]提出了一种基于扩充三元组的远程监督方法对产品文本数据进行标注,将属性抽取转化成序列标注问题,并通过实验证明了预训练语言模型对属性抽取性能的有效帮助。
目前在面向商业银行风控领域的知识抽取实践中,应用较为普遍仍是基于规则和机器学习的方法。针对关系和属性抽取的性能在很大程度上取决于实体抽取结果,为保证所获知识的质量和可用性,目前人工干预的情况较多,总体上自动化程度还不高。随着商业银行数字化建设的不断深入,风控领域积累的数据体量呈现高速增长态势,对知识抽取精度的要求也不断提升。如何在保证知识质量的情况下提升风控领域自动化知识抽取水平和效率,还需要继续深入研究。
2.2 知识融合
由于知识获取的不确定性,通过知识抽取技术获得的知识通常会存在重复、冲突、质量参差不齐等情况,因此需要对知识进行转换、清洗、消歧等操作,提升知识质量后,方可将其用于知识推理和知识应用。知识融合技术根据融合对象的不同,可分为面向模式层的融合方法和面向实例层的融合方法。其中实例层的异构问题是风控领域知识融合面临的主要问题,包括实体链接、实体对齐、冲突消解等主要任务。实例层客户实体的融合是风控领域知识融合任务的主要目标。由于知识规模巨大而质量参差不齐,多源异构实例数据的匹配面临时间复杂度和空间复杂度的双重挑战。
2.2.1 实体链接
实体链接(entity linking,EL)旨在识别和提取文本中的新实体,将其与知识库中的对应实体链接起来,并加入现有的知识库中,消除知识的不一致性。现有的相关工作可以总结为基于实体属性、基于实体流行度、基于上下文或基于外部证据的实体链接方法。机器学习模型在实体链接任务中有着广泛应用,2019 年,Miao等[40]在构建金融领域动态知识图谱的过程中,利用SVM模型基于相似性特征与先验知识进行金融实体链接,在测试集上的精度可达0.78。Song 等[41]在企业知识图谱的构建过程中,使用代理学习技术训练SVM 模型并计算给定实体与每个候选实体间的相似性分数,在高于预定义的阈值时将给定实体链接到具有最高相似性得分的候选实体,在企业实体和自然人实体数据集上的F1值分别为0.90、0.81。Wang等[42]在股票市场知识图谱的知识融合环节中,利用VSM模型进行实体链接,生成一组候选实体后通过计算实体间的相似度来确定是否需要消歧。近年来,深度学习作为研究热点,也被广泛应用于实体链接任务。2021年,Ding等[43]提出了一种基于端到端神经网络模型JEL的方法,该模型利用少量的上下文信息和Margin 损失来生成实体的向量表示,并通过联合训练Wide线性模型和深度神经网络模型分别匹配字符和语义信息,在摩根大通内部数据以及金融新闻数据集上的实体链接任务中取得不错表现。
2.2.2 实体对齐
实体对齐(entity alignment,EA)也称为实体解析、实体匹配,指判断相同或不同来源的两个实体是否描述的是物理世界中的同一对象,以消除知识的异构性。目前EA 任务中的方法可分为成对实体对齐方法,以及集体实体对齐方法。
成对实体对齐方法是基于实体及其属性的相似度进行对齐。2019年,对于同一客户在多家商业银行同时拥有账户的情况,Suzumura等[44]在对金融犯罪检测任务的研究中,使用基于简单规则的EA方法,针对关系图谱中的自然人客户通过“全名+出生日期+国籍”或“身份证件类型+身份证件号码+国籍”的属性组合进行对齐,针对企业客户通过“公司全称+注册日期+注册地”或“注册类型+注册号+注册地”的属性组合进行对齐,以识别不同数据来源中的同一客户实体。 此类方法简单而高效,但在实践中,由于客户信息录入时打字错误、文档质量不高、OCR过程出错等问题,给基于规则匹配的实体对齐带来了许多挑战。而基于概率的方法具备一定的容错性,早期有Fellegi-Sunter模型[45]为参与相似度计算的每个属性评价其重要程度,对它们分配不同权重以提高相似度计算的可靠性,通过组合这些属性就可以得到两个实体之间的相似度概率。例如,企业客户的实体对齐中,注册地址、法人代表、注册日期等属性对于两实体间相似度概率的影响要显著大于经营范围、企业性质、企业规模等属性。集体实体对齐方法是在成对实体对齐方法的基础上,将实体间相互关系也纳入相似度计算中。2019 年,Trisedya 等[46]提出了一种融合实体结构向量和属性字符向量的实体对齐模型,利用TransE生成实体结构向量并隐式地学习了关系传递信息,通过属性三元组生成属性的字符向量,从而计算实体之间的相似度,在真实知识图谱的实验中比基线模型的性能提高了50%以上。2020 年,Yang 等[47]针对之前EA 任务中对属性信息的利用中所存在的不足,提出了一种融合实体结构和属性信息的协同训练模型COTSAE,模型的属性嵌入组件基于伪孪生神经网络对字符级属性信息进行编码,并提出了联合注意方法以确保属性的类型及属性值能够共享注意力权重,该模型在实验中优于所有基线模型。
商业银行中一般存在着多个业务系统,如核心银行系统、信贷管理系统、客户交易信息服务系统等,大型国有商业银行具有多至上百个系统。在这些系统中,对于同一客户的相关数据可能存在着一定差异,如表结构不同、字段值不一致、数据粒度不一致等。除了实体链接、实体对齐外,知识融合还需要解决不同来源的实例数据间的冲突。例如,来自不同数据源的同一企业的规模描述不同,可能这两部分信息都是正确的,只是两个数据源存在时间差,期间企业规模发生了变化,对于这种情况保留最新的信息即可。也有可能是因为知识抽取的过程中产生了错误,针对此类情况可采取基于投票或是基于质量评估的方法进行冲突消解,基于投票的方法是对不同知识出现的频率进行投票和统计,出现次数较多的知识可视为可信度较高。基于质量评估的方法是通过考量数据来源、数据日期等因素对知识的置信度进行量化计算,保留置信度较高的知识。
2.3 知识推理
知识推理旨在从现有知识的基础上深入挖掘出新的知识,从而对知识图谱进行完善和拓展,有效应用知识推理技术可以辅助决策。在风控领域知识图谱中,推理主要用于知识图谱补全(knowledge graph completion,KGC)、三元组分类(triple classification,TC)等任务,其中知识图谱补全是对三元组中缺失或隐含的实体、关系进行补全,即链接预测任务。而三元组分类则是确定三元组所描述的事实是否正确,进行二分类。知识推理方法大致上可以归纳为以下几类:基于规则的推理方法、基于图结构的推理方法、基于表示学习的推理方法、基于强化学习的推理方法以及基于时序性的推理方法。
2.3.1 基于规则的推理方法
基于规则的方法在早期的知识推理任务中应用广泛,风控领域的规则来自于商业银行内的业务规定以及专家依据经验从已发生的风险事件中提取的特征信息。通过预设的经过验证的规则,根据规则与事实的匹配与否给出推理结果。如判定贷款资金是否受托支付的推理规则为:贷款发放时,收款人与借款人不一致。对于与规则匹配的某笔贷款,其支付方式可被判定为受托支付。2019 年,为预测企业破产风险,唐晓波等[48]通过CART 算法从训练集中抽取用于破产预测的9 条规则,并将其转化为对应的SWRL 规则,随后利用Drools推理引擎进行可解释的知识推理,在2008—2017 年美国破产上市公司数据上预测破产企业的准确率达到84.13%。除此之外,还可以对实体间隐含的关系进行推理。表3 中列举了几种隐含关系及其推理规则,可在风控领域知识图谱中对客户实体间的关联关系进行深化。

表3 关系推理规则举例Table 3 Example of reasoning rules of relations
为便于书写规则,面向数据库及知识库的逻辑语言Datalog[49]得到开发,在其基础上,牛津大学推出了Vadalog[50],以平衡知识推理的计算复杂度和表达能力。2020 年,Atzeni 等[51]提出了基于Vadalog 和多层次聚类的Vada-Link框架,将KGC任务化分为聚类与多分类这两个子任务,并在为意大利中央银行构建企业股权知识图谱的实践中取得不错效果,在20 个集群上的召回率为99.4%,在50 个集群上的召回率为98.6%。基于规则的推理方法较为精确且具有可解释性,但学习能力不足,人工提供规则的效率较低。为弥补此缺陷,有学者提出了自动化的规则学习方法,如AMIE[52]通过迭代地在规则中增加悬挂边、实例边以及闭合边,引入剪枝策略以高效地探索搜索空间,并在规则学习的过程中评估规则的质量,可以有效应用在大规模知识图谱上。为对知识图谱缺失的关系进行推理,2020年,Zhang等[53]提出集成全局信息与关联规则的概率模型FGEM,首先挖掘简单规则并生成大量知识,以构造因子图表示推理空间,然后通过开发EM算法,E步骤中使用置信度传播算法计算候选边的边缘分布,M步骤中通过广义迭代比例拟合框架学习软规则的可信度,最终在关系补全任务中的表现优于AMIE、TransH。自动化的规则学习方法将挖掘到的置信度高的规则添加进规则库中,可以节省人力,大幅度提升工作效率。
2.3.2 基于图结构的推理方法
由于知识图谱特有的图属性,基于图结构的方法尤其适于知识图谱的推理任务。在知识图谱技术面世之前,Lao等[54]已提出将基于随机游走的PRA算法用于大规模知识库中的推理和学习,将节点间的路径作为特征预测潜在路径,具有较好的可解释性,但计算量大。Gardner等[55]其PRA基础上提出表达能力更强的子图特征提取模型SFE,舍去路径特征的概率计算,直接保留二值特征,以有效降低计算复杂度。2022年,Wu等[56]将SFE方法应用在金融欺诈风险分析中,构建基于SFE的知识图推理框架,通过搜索已知诈骗公司以挖掘潜在的诈骗公司,有助于监管机构防范欺诈风险。除欺诈风险外,企业供应链的风险传导也不容忽视,传统的供应链风险分析方法只针对链中大型核心企业,授信时以其非流动资产作为担保,而中小企业依靠核心企业的信用担保,传统风控模式无法捕捉其日常交易中流动资产形式的转换。针对这一问题,Zhang 等[57]提出了基于图挖掘的企业供应链推理方法,利用企业间交易合同与企业基本信息搭建知识图谱,随后通过基于图的社区检测方法发现潜在的企业供应链,从而对供应链中的企业进行风险评估,以支持商业银行授信决策。针对股权网络中的关联查询问题,Ouyang等[58]提出了基于金融领域知识图谱的双节点关联查询DAQ 算法以及多节点关联查询MAQ 算法,以挖掘两顶点之间最大股权链的k度关系路径,为金融风险防控提供强有力的技术支撑。2020年,黄炜等[59]基于浦发银行全行级企业关联关系知识图谱,利用随机游走以及Fraud Rank 算法模拟了以舆情数据、借贷信息为起点的风险传播过程,并对风险值进行计算。吕华揆等[60]通过深度优先遍历以及Tarjan算法对金融实体间持股关系、持股比例进行穿透式分析,并结合网络中心度指标判断实体对象风险水平,为风险识别和预测提供了新方法。
基于图结构的推理方法可以很好地挖掘图结构中的路径特征,结合业务规则,可以挖掘出实体间的隐含关系及路径等,但在大规模知识图谱的应用中会面临高复杂度和巨大计算量等问题。
2.3.3 基于表示学习的推理方法
随着知识图谱的向量表示方法不断完善,基于表示学习的推理也取得了新的进展。基于表示学习的推理是将实体和关系映射到连续的向量空间中进行向量表示,再根据这些低维向量进行知识图谱补全、三元组置信度评估等推理任务。其中应用较为广泛的是基于平移距离的方法与基于语义匹配的方法。
(1)基于平移距离的方法。其中较为经典的模型如TransE[61]、TransH[62]、TransR[63]、TransD[64]等。它们的共同特点是得分函数通过计算头、尾实体向量间的距离,以衡量此三元组的置信度。最早的翻译模型TransE 受到词向量中平移不变性的启发,将关系的向量表示解释成头、尾实体向量之间的转移向量,简单而高效。TransA[65]在TransE的基础上,将得分函数中的欧氏距离改为适用性更高的马氏距离,并为实体与关系向量的每一维学习不同的权重以区分其重要程度。TransParse[66]将TransR模型中的稠密矩阵简化为稀疏矩阵,可以有效解决实体与关系的异质性,减少参数数量,并通过对头、尾实体使用不同的投影矩阵解决关系的不平衡性问题。为解决一种关系可能对应多种语义信息的问题,TransG[67]提出使用高斯混合模型及聚类算法生成实体关系的多种表示,不同的语义用不同的高斯分布描述。近年来,翻译模型在风控领域知识推理任务中得到尝试。2021 年,Ma等[68]提出了一种基于知识图谱语义信息的深度学习模型,利用TransR模型将离散符号表示的知识图谱嵌入到向量空间中,以挖掘债券实体之间的隐含关系,并使用融合知识图谱语义信息的DeepFM 模型对债券违约进行预测,取得了不错的效果。
(2)基于语义匹配的方法。比较经典的模型有RESCAL[69]、DistMult[70]、ComplEx[71]等,这些模型的共同特点是借助矩阵、张量或是神经网络挖掘实体向量和关系向量之间的语义联系,其得分函数使用相似度来衡量。在RESCAL、DistMult 的基础上,HolE[72]将二者相结合,引入循环相关运算描述实体之间的关联。ANALOGY[73]将RESCAL中的关系矩阵约束为正规矩阵,以进一步对实体和关系的类比属性进行建模。为学习到更多的特征,ConvE[74]提出使用多层卷积网络进行知识图谱嵌入,但对于实体与关系间的交互仍不充分,于是ConvR[75]提出将关系向量作为卷积核,以获得实体与关系之间交互最大化,而InteractE[76]使用特征置换、交叉排列的特征重塑和循环卷积操作以增加实体与关系间的交互。SACN[77]提出使用加权的图卷积网络解决ConvE中图结构信息未充分利用的不足,并保留了平移特性。2022年,Alam 等[78]将贷款违约预测二分类问题转化为知识图谱推理中的链接预测和三元组分类问题,即对三元组“分类为(申请人,?)”中缺失的尾实体预测为“违约”或“不会违约”,利用ComplEx 捕获语义信息,并作为特征输入到LR、RF 等传统机器学习分类器以提升其性能,增强贷款违约预测模型的准确性和可解释性。
2.3.4 基于强化学习的推理方法
2017 年,强化学习(reinforcement learning,RL)首次被引入知识图谱推理中,经过近几年的探索,目前基于强化学习的推理方法已成为知识推理研究的新方向。开山之作DeepPath[79]旨在推理给定头实体到尾实体之间的路径,并将其建模为马尔科夫序列决策问题,通过TransE将知识图谱映射到连续空间中,利用基于蒙塔卡洛策略梯度的REINFORCE算法求解,在奖励函数的设置中考虑路径的多样性、效率以及准确率,令智能体执行最优动作以拓展路径,但其策略网络需要预训练,且搜索效率较低。紧随其后,Minerva[80]旨在解决已知头实体与关系情况下的查询回答问题,并将其建模为部分可观察的马尔科夫决策过程。与DeepPath 相比,Minerva无需预训练,奖励函数较为简单,且具备更强大的推理能力,但当缺乏高质量路径的训练时,模型易受虚假路径误导。后续工作Multihop-KG[81]改进了Minerva的奖励函数,使用预先训练的ConvE 模型计算软奖励,并在训练过程中随机掩盖部分出边,避免智能体受到历史路径误导,实现对路径的多样化探索。于2019 年提出的AttnPath[82]通过引入基于LSTM与图注意力机制的记忆组件以摆脱对预训练的高度依赖,使用TransD 进行知识图谱表示学习,并通过设定新的强化学习机制以避免智能体在某一节点持续停滞,在实验中显著优于DeepPath。由于基于强化学习的推理方法具有良好的可解释性和学习能力,在量化金融、投资交易等决策问题中已得到有效应用,同时在金融风控领域也进行了初步探索。为识别与防范企业重大风险,熊盛武等[83]提出了一种基于强化学习的区域产业关联效应趋势推理方法,以预测如“中美贸易摩擦”“关税”等风险事件对关联产业的影响趋势,首先在产业知识图谱上通过TransE将事实映射到低维向量空间,并将趋势预测建模为序列决策问题,利用LSTM提取的历史路径特征和自注意力机制提取的邻接实体特征构建策略网络模型,智能体最终抵达的实体即预测结果。
2.3.5 基于时序性的推理方法
目前大部分知识图谱相关研究大多是基于静态知识图谱,即认为图谱结构不随着时间变化而改变,只能反映某一时间点的风险信息。而真实数据通常具有随时间演化的动态性,T+1 时刻的知识图谱结构可能与T时刻的知识图谱结构有着不小的差异,如企业实体的股权结构发生频繁变动。同时新知识的重要程度一般大于旧知识,风控领域中的大部分业务都带有时间窗口的限制,如统计客户自贷款发放日起一个月内进行的借方交易金额。
近年来,基于时序性的知识推理方法相关文献陆续发表。对于商业银行来说,了解客户行为对降低信用风险以及欺诈风险非常重要。2020 年,Shumovskaia 等[84]使用链接预测方法来挖掘银行客户间的交互,通过一家欧洲的大型银行真实客户交易数据集得到了具有8 600万节点和40 亿条边的时序图谱,按时间段划分为三个部分:前三年、第四年和第五年,分别用于训练、验证和测试,随后采用2-SEAL-RNN 模型进行链接预测,其中RNN 用于构建注意力机制,在提取目标链路周围的闭合子图之后处理关系对应的时间序列,最后将2-SEALRNN 作为GCN 中的注意力模块以提高信用评分的质量。针对担保关系动态变化的担保圈风险,Cheng 等[85]提出了一种基于时序图谱的注意力神经网络模型DGANN用于预测风险担保关系(即借款人违约而其担保人未能偿还担保金额),模型包括具有结构注意力的GCN、具有时序注意力的GRN 以及计算风险概率的预测层这三部分,并在东亚一家主要金融机构2013—2016年期间的真实贷款数据集上对DGANN模型进行评估,对风险担保的预测精度超越了GCN、SEAL、GRNN 等基线模型。随后,Wang 等[86]提出通过时间感知图神经网络TemGNN 对信用风险进行预测,该模型结合了静态特征学习模型、带有特殊图卷积的短期图编码器以及基于LSTM的长期时序模型这三部分,能够同时挖掘短期和长期的时间结构信息,最后在支付宝客户借贷行为时序图谱上进行违约预测,效果优于所有基线模型。2022 年,Yang 等[87]引入时间信息构建企业动态风险知识图谱,在“实体-关系-实体”三元组的基础上增加时序维度,拓展为“实体-关系-日期/时间-实体”形式的四元组,通过基于多关系循环事件的动态知识图谱推理方法Multi-Net 预测缺失实体和关系,并利用多关系邻近聚合器得到每个时间戳下实体邻近信息聚合后的向量表示,随后利用基于LSTM的时序事件编码器捕捉风险事件在多时间、多关系上的依赖性,将链接预测视为多分类问题并通过改进损失平衡函数提升计算精度,最后通过金融数据集验证该模型在链接预测任务中的明显优势。
总的来说,基于表示学习的推理方法虽然可以自动捕捉特征,但可解释性较差,且知识表示过程会产生语义损失。风控领域中决策空间巨大、推理链较长,基于表示学习的推理在复杂的推理任务上存在局限性,很难取得令人满意的效果。Shao 等[88]在新加坡星展银行的真实客户数据上验证了这一点,将TransE、DistMult、ComplEx用于知识图谱补全任务,实验结果表明这些模型在金融数据集上的性能远低于在公共数据集上所能达到的效果。基于强化学习的推理方法是新兴的推理手段,在风控领域有待进一步探索,例如用于风控领域知识图谱中挖掘因果链的风险溯因场景,以生成可解释的风险演化路径。基于时序的推理方法通过引入时序信息以契合真实的风控场景,主要利用RNN、LSTM 等神经网络捕获时序特征,在对于可解释性要求较高的风控领域中难以受到信任。目前在风控领域中应用较多的还是基于规则的推理方法以及基于图结构的推理方法。随着科技的不断发展、人力成本上升,知识推理技术势必要朝着自动化、智能化的方向发展,在这一技术领域中仍存在着许多挑战和机遇。
3 风控领域知识图谱的应用
面向商业银行风控领域的知识图谱有如下几个方面的特点:(1)全面性。利用知识抽取技术以获取全面的风险信息,基于知识图谱描绘客户风险全景图以洞察客户行为,有效防控信用风险、操作风险、欺诈风险。(2)深加工。利用知识推理技术挖掘实体间的潜在关系,以及担保圈链、资金转移链等复杂关系链。(3)浅表达。通过可视化工具进行图形化展示,金融实体间错综复杂的关联关系可以一目了然。近年来知识图谱技术在商业银行已有实际应用,表4中列举了几家商业银行在风控领域中的知识图谱应用成果[43,89-92]。以下从反欺诈、反洗钱、关联风险预警、可视化分析、数字普惠金融等方面介绍知识图谱的应用。

表4 知识图谱在商业银行风控领域的应用成果Table 4 Application results of knowledge graph in field of risk management of commercial banks
(1)反欺诈。欺诈行为包括薅羊毛、电信诈骗、刷单、中介代办、套现等,若未严加防控,可能使商业银行造受巨额损失,所以反欺诈在商业银行的风险管理中起着重要的作用。风控领域知识图谱可抽取和挖掘目标客户的设备信息、交易数据以及行为数据,拓展对欺诈风险的分析维度。在申请阶段,可结合一定指标的预警规则对账号、设备等风险因子进行分析,以支持高效、精准的反欺诈预测,对虚假申请等行为进行有效预警;在交易阶段,结合特征工程和算法模型对目标客户涉及的交易数据进行分析,对非法套现、盗刷等欺诈行为进行实时预警和监控。2019年,金磐石等[93]提出了一种基于企业画像与关联图谱的贷前反欺诈模型,对小微企业客户的欺诈风险进行量化,在测试集上的AUC 值比仅利用企业基本特征建模提升了5%,能够有效检测申贷阶段的欺诈行为。Yang 等[94]提出一种反欺诈检测模型FraudMemory,通过TransE在交易图谱上生成客户实体的向量表示以提取语义特征,在某银行的380万条客户交易数据上欺诈预测效果优于SVM、GRU 等基线模型。2022 年,Mao 等[95]通过构建企业交易知识图谱,提取交易规模、类型与频率等特征,以增强金融欺诈行为检测能力,并在2000—2019 年中国上市公司数据集上取得不错的效果。
(2)反洗钱。洗钱行为是指通过混淆资金来源,使非法获得的金钱财产转变为合法资产的过程。反洗钱是一项全球范围内的艰巨任务,通常涉及多地域、多机构、多部门。商业银行面对的洗钱犯罪一般是团伙作案,利用多身份、多账户进行操作。随着互联网金融和数字货币的发展,洗钱作案方法越发复杂,洗钱作案手段越发隐蔽。仅依靠账户一度关联交易识别洗钱账号通常步履维艰,而利用知识图谱建立账号实体间的资金交易关系网,可以对监管账号的关联账号进行深度追踪挖掘,由浅到深地逐步排查可疑账号,从而大幅度减少调查体量,提升反洗钱能效。2020 年,Bellomarini 等[96]提出基于Vadalog 和知识图谱的反洗钱框架,对最终受益人、控股、夫妻等关系进行挖掘,然后根据综合情况对可疑交易计算怀疑度评分。
(3)关联风险预警。外部风险是客户发生违约的重要原因之一,因关联企业的风险冲击等外部因素引起的违约案例数不胜数。目前商业银行的客户洞察工作中,主要以客户自身为研究对象,对于多个客户间的风险传导进行评估时通常只能评估与分析对象有直接关联的客户风险,而无法对其间接关联客户进行风险评估。通过搭建客户关联图谱,可以对客户错综复杂的外部关联关系逐级梳理,有效拓展风险预警范围,加强对关联风险客户的重点关注。考虑到同一种关系的紧密程度也存在差异,可根据关系属性划分关系等级,在风险传导概率计算中为不同等级的关系分配不同的权重,例如,资金往来关系可以可根据交易金额的数量级划分权值,“100 RMB”对应关系权值为3,“10 000 RMB”对应关系权值为5。2020 年,Xue[97]利用知识图谱建立企业客户关系网络,挖掘风险传递路径并计算风险传递系数,以帮助商业银行精准定位客户的潜在风险。
(4)可视化分析。风控领域知识图谱将冗杂的信息转化为高度结构化的知识网络,借助可视化技术可以将知识资源映射为图形元素,通过提供多维洞察视角,将实体间复杂关系直观明了地描绘出来,令图谱使用者对客户、关系以及风险传导路径等信息了解得更为透彻。Wang等[98]基于交易数据构造了端到端的风控领域知识图谱,将知识以三元组的形式存储在Neo4j 图数据库,以文本列表和图形可视化相结合的方式展示客户之间的业务关系。
(5)数字普惠金融。近年来,普惠金融受到高度重视,但风险一直是普惠金融发展中的核心问题之一,商业银行在发展传统普惠金融业务时面临信息不对称、贷前审批难、贷中贷后管理难等问题。而数字普惠金融实现金融科技与普惠金融的完美结合,利用知识图谱技术打造数字化风控体系,能够有效提升风控水平与工作效率。由于小微企业大多处于产业链弱势地位,容易受到上下游风险传导,中国农业银行通过构建小微企业知识图谱,划分风险客群,对小微客户风险进行洞察和分析,致力于建设智能中枢,实现风控立体化,为数字普惠金融开辟了新道路[99]。
目前,国内银行对于知识图谱在风控领域中的应用尚浅,数据质量还不完善,面临数据治理能力和数据价值挖掘能力的挑战。欧美对于金融知识图谱的探索较早,构建技术较为成熟。十多年前,英国Garlik 公司就已将语义网用于在线信用监控。由EDM Council 发布的金融业业务本体(financial industry business ontology,FIBO),此标准经过包括美国道富银行、德意志银行在内的多家银行的检验。丰富的语义本体为知识图谱奠定基础,能够准确描述金融实体,显著减少映射工作,并能够通过ETL代码生成和自文档化,降低维护成本。
4 总结与展望
本文在对知识图谱的概念、体系架构等全面阐述的基础上,介绍了风控领域知识图谱构建技术的研究进展,并列举了风控领域知识图谱的实际应用及成果。由于大型商业银行存量客户可达千万量级,在风控知识图谱的构建过程中会生成以亿为量级的节点和边,不仅对图谱存储带来巨大负担,也为知识抽取、知识融合、知识推理等构建技术带来了新的障碍,大型知识图谱的管理和运营也是潜在的挑战[100]。在过去的十年中,知识图谱技术从首次被提出到现在广泛研究,期间虽取得了诸多实践成果,但在风控领域的落地实践中仍存在进一步发展的空间。
(1)进一步提升知识质量与知识抽取效果。商业银行中,各业务条线一般有着各自的管理系统,不同系统或是同一系统的不同模块可能出现重复录入的情况,从而产生冗余或是数据不一致的错误,另外人工录入信息时也可能输入错误信息。在风控领域,对数据的准确性有着极高的要求,错误信息可能还会造成其关联知识产生偏差,严重影响决策和判断。在对结构化数据的抽取时可结合ETL技术提高知识质量,对于非结构化文本数据,可通过人工定义规则过滤掉一部分错误信息,并使用NLP 技术进行预处理。针对商业银行风控领域的专业术语复杂度较高等特点,可以考虑结合融入专家经验的规则库提升深度学习模型的效果。对于罕见词和多义词,结合垂直领域的业务背景加以解释,提升知识抽取效果。
(2)隐私保护下的知识共享。风控的本质是利用数据降低信息不对称程度,所以银行需要全面采集客户信息。而2021年《数据安全法》和《个人信息保护法》接连颁布,昭示着风控工作的前提是保障客户隐私安全以及数据安全。相比较网络爬虫盛行的前几年,当下更为注重个人隐私安全、数据合规性。考虑到客户隐私、商业竞争等因素,银行业未能形成联合风控模式,无法共享数据、算法模型。故而可能出现这种情况:同一授信客户在不同银行的信用评分相差较大。现有的隐私保护机器学习技术如协作学习、联邦学习以及安全机器学习,能够支持多方在隐私保护下的数据使用和机器学习建模。知识图谱中的知识涉及实体间的关联关系,更为复杂。未来可考虑将知识存储、知识表示与同态加密、密钥共享等加密技术相结合,以促进知识共享。
(3)增强知识推理的可解释性。嵌入表示算法能够获得高效的计算效率,但模型越复杂,推理结果就越难被解释,缺乏可解释性的自动化推理与决策可能导致未知的风险。风控领域对算法模型的安全性能要求较高,其可解释性事关商业银行稳健经营和客户权益保障。有相关工作通过稀疏注意力机制、重要性权重等方法增强知识嵌入的可解释性[101-102]。未来可以考虑提高已具备高安全性的基于规则或图结构的推理模型性能,以及提升从黑盒模型中提取可解释性描述的精确性。
“十四五”规划提出“加快数字化发展,建设数字中国”,央行也提出“力争到2025 年实现整体水平与核心竞争力跨越式提升”的金融科技发展愿景,可以预见,商业银行数字化建设仍将不断加强、加深。在深度学习能力的支撑下,知识图谱能够有效提升商业银行知识管理的智能化水平,为智慧金融的建设提供新动力,在银行业的大规模应用已成必然趋势。面向商业银行的风控领域知识图谱以风控业务为重心,通过建立以大数据为支撑的知识网络,对风险进行智能化监控与及时预警。当前知识图谱在银行业的落地仍处于发展阶段的初期,如何使业务和技术深度融合是知识图谱落地的关键。待领域知识图谱构建技术进一步发展,知识图谱将提供更为广泛的知识服务,对于风险识别和分析的准确率也会越来越高。
猜你喜欢
军事文摘(2022年17期)2022-09-24
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
计算机系统应用(2021年11期)2022-01-06
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
创业邦(2017年12期)2017-12-29
