
面向语义分割模型的外接多尺度投票网络
2022-10-16 12:27朱杰龚声蓉周立凡徐少杰钟珊
计算机工程 2022年10期
朱杰,龚声蓉,周立凡,徐少杰,钟珊
(1.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318;2.常熟理工学院 计算机科学与工程学院,江苏 苏州 215000)
0 概述
语义分割是计算机视觉领域的重要课题之一,其目的是为图像中的每一像素分配类别标签。得益于卷积神经网络(Convolutional Neural Networks,CNN)能够提取高层语义信息的独特优势,基于CNN 的语义分割算法[1-3]取得了巨大成功,在精度、速度上均超越了传统图像语义分割算法。然而,语义分割网络在提取高层语义信息时需不断下采样,容易丢失部分空间细节信息,导致网络在目标边缘、长条状目标,尤其是小目标处的分割效果不佳。
目前,主流语义分割网络[4-6]在训练时通常采用批处理方式提高内存利用率、减少迭代次数、协同批量归一化[7],同时减少内部协变量偏移,加速深度网络训练。梯度下降的方向越准确,引起的训练震荡越小,分割精度提升越明显。但此类方法严重依赖高性能显卡(如GPU 集群)才能设置较大的批处理参数,达到较高的分割精度。低端显卡由于显存有限,仅能设置较小的批处理参数,有时甚至无法进行训练。此外,需要通过选取合适的预训练权重,在高性能显卡中不断更换训练策略、调参、验证才能获得具有较高精度的模型,且在修改网络后,还需重新进行上述步骤,运行周期长,占用计算资源过多。
本文提出面向语义分割模型的外接多尺度投票网络,将共享网络中的分割网络与各尺度注意力头剥离开,仅训练各尺度注意力头,以方便网络收敛。将各尺度注意力头在最佳分割模型下的预测结果按投票权值进行加权融合,通过融入混合池化模块,聚合权值图中的近程与远程整体背景,为整个网络提供全局信息,扩大感受野,从而缓解权值图中长条状目标拟合间断与缺失的问题。引入类内、类间投票注意力模块,并嵌入1×3、3×1 卷积块,以获取类内投票权值与类间投票权值关系,改善投票权值图的边缘拟合效果。
1 相关研究
近年来,基于CNN 的图像语义分割方法取得了重大进展。本节将讨论针对目标边缘、长条状目标、尤其是小目标分割效果不佳的3 类相关改进方法,即上下文信息采集、多尺度特征图融合、多尺度图像共享网络方法。
1.1 上下文信息采集
获取图像上下文信息是扩大卷积网络感受野的有效方法,ZHAO等[3]提出金字塔 池化模块(Pyramid Pooling Module,PPM)融入多尺度上下文信息,可增强不明显的小目标、条状目标(例如与周围环境颜色相近的路杆、行人)的捕获能力。CHEN等[8]提出空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP),将空洞卷积与金字塔池化方法相结合,从而铺抓更充分的上下文信息。CHEN等[4]在此基础上提出利用编码器-解码器结构逐步重构空间信息,可更好地捕捉目标边缘。FU[9]等提出双注意力网络获取像素间、通道间的特征依赖关系信息,改善了类内混淆、目标边缘缺失等问题。HOU等[10]提出条状池化方法,更易于捕获远程特征依赖关系,改善了长条状目标的分割效果。但上述方法在下采样过程中容易丢失细节信息,导致较细的长条状目标难以成功分割,在长条状目标的边缘处存在分割模糊的问题。
1.2 多尺度特征图融合
LONG等[1]提出全卷积神经网络进行图像语义分割,在实验中观察到不同深度的卷积层分割结果存在较大差异,提出使用跳跃连接方法将浅层获取到的细节信息与高层语义信息进行融合。RONNEBERGER等[2]在LONG 等的基础上提出类U型的编码器-解码器结构,将更多浅层细节、纹路特征与深层语义特征进行融合,改善了小目标与目标边缘处的分割效果。ZHANG等[11]针对语义层和浅层的差异较大,浅级特征噪音较多,简单地融合浅层和深层的效果不佳问题,在浅层特征中引入语义信息,并在深层特征中引入高分辨率细节,以有效融合浅层与深层的特征。FAN等[12]提出短期密集连接模块,提取具有可伸缩感受野和多尺度信息的融合特征。但上述方法只能提取单一尺度图像特征,细节信息的提取能力有限。
1.3 多尺度图像共享网络
在同一网络下,不同尺度图像的分割结果存在部分差异,基于此,CHEN等[13]将多个调整尺度的图像输入注意力网络,加大各尺度权重。YANG等[14]在CHEN 等的基础上提出多尺度网络分支方法,并在预测阶段融合特征。TAO等[15]针对上述方法依赖固定放缩比例与数量的尺度组合提出多层次多尺度注意力机制,以拟合相邻尺度间的注意力权重,同时在预测分割结果时灵活扩展更多尺度,使网络获得更高的分割精度。但网络需承担额外尺度的输入,训练复杂度高。
为利用网络在不同尺度下的分割优势,DAI等[16]与PAPANDREOU等[17]分别使用平均池化、最大池化融合各尺度的分割结果。但由于网络对各尺度的分割优势不同,因此武断地取最大值或平均值容易导致正确分割的像素被其他尺度干扰,精度提升效果不佳,甚至下降。受共享网络[15]启发,本文将分割网络与各尺度注意力头融为一体。但在训练时,除了在原尺度上的训练开销,网络需额外承担其他尺度的输入,这成倍增加了训练复杂度。此外,尺度间的差异难以界定,以致网络较难收敛,且当修改网络后需重新训练,原模型的价值丧失。
针对上述训练成本过高的问题,本文期望复用具有最高精度的模型,并在其基础上改善模型在小目标、长条状目标、目标边缘处的分割效果。得益于现有的语义分割网络通过采用随机尺度缩放进行数据增强,使图像放缩后也能保持较高分割精度的方法,本文定量分析图像缩放后的不同分割效果,将放缩后的各尺度图像输入同一已训练的分割网络中,以达到提高分割精度的目的。
2 外接多尺度投票网络
2.1 投票网络总体结构
图1 所示为投票网络结构,其中每个模块已用虚线框出。其中:通道数C1为分割类别数;通道数C2为网络层数,设为64;H 为高度,值为1 024;W为宽度,值为2 048;α为位置注意力权重;β为通道注意力权重;可视化指使用三线性插值(2 倍),各通道逐点相加,将各像素点归一为0~255。当只使用TAO 网络时,发现提升效果不明显,通过分析发现该网络主要存在以下问题:未利用每一类的投票权值偏好;未获取较全面的上下文信息;未挖掘类内投票权值与类间投票权值关系;投票权值图在目标边缘处有一定概率会发生拟合间断。针对上述问题,本文分别构建4个相应的模块进行改进。
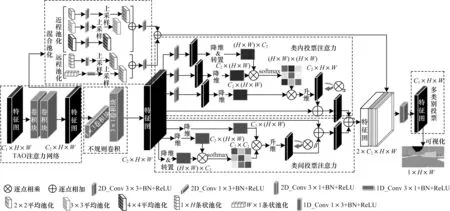
图1 外接投票网络结构Fig.1 Structure of external voting network
2.1.1 多类别投票模块
由于TAO 网络仅输出通道数为1 的注意力图,忽视了每一分割类别存在特有的投票权值偏好。为此,本文提出多类别投票模块,以扩大投票选择空间。以语义分割数据集Cityscapes[18]为例,该数据集包含19 个类别,多类别投票模块在此数据集上分割所得的结果特征图含19 个通道,得到19 个类别的投票权值图,由于改方法在每一个类上分别进行投票,因此扩大了19 倍的投票选择空间。
2.1.2 混合池化模块
在TAO 网络中,由于网络层数较少,导致感受野过小,无法获取较远距离的投票信息与整体投票信息,以致较大目标与长条状目标的投票权值拟合效果不佳。在语义分割任务中构建上下文信息采集模块[3,6,10]是改善该问题的常见方法。HOU等[10]提出混合池化方法,有效改善了长条状目标与较大目标的分割效果,且计算开销不大。为改善投票权值图在大目标与长条状目标处的拟合效果,受HOU等[10]启发,本文利用混合池化模块聚合近程与远程的相关投票权值信息。图1 左上角所示为混合池化模块,其中近程池化融合了3 种不同尺度的标准空间池化模块,且引入标准2D 卷积块进行拟合,因此更容易捕捉近程投票信息,能够改善较大目标的投票拟合效果。远程池化通过水平与垂直池化方法将水平与垂直的信息分别压缩到1D,并引入1D 卷积块进行拟合,从而更容易捕获到远程投票信息,改善长条状目标的投票拟合效果。
2.1.3 类内、类间投票注意力模块
在语义分割任务中,金字塔池化仅能获取全局的上下文信息,却无法利用全局视图中像素、类别间的关系。文献[9]提出一种位置注意力机制捕获特征图中任意2 个通道间的空间依赖关系。由于投票网络无法学习到类内、边缘权重的相邻关系,导致类内混淆,边缘间断。类内注意力模块通过所有位置特征的加权,选择性地聚合每个位置的特征,使网络学习相邻位置关系。类间投票注意力模块能学习到更多类间关系,并能选择性地强调相互依赖的通道映射。此外,令注意力图分别乘以初始为0的α、β可学习参数,若某一注意力方法无法提升精度,参数便会趋近于0,能够避免精度下降。
2.1.4 不规则卷积模块
针对常规卷积核长宽相同,较难学习线条状特征的问题,MOU等[19]提出1×3 与3×1 的非对称卷积,可更好地捕捉线条状特征。由于投票网络亟需拟合线条状的目标边缘信息,如图1 中不规则卷积模块所示,因此本文参考文献[19]引入1×3、3×1 卷积,后接一个批量归一化(Batch Normalization,BN)与激活函数ReLU,改善投票权值图中目标边缘的拟合效果。
为增加本文方法的可解释性,将投票权值图各通道逐点相加,归一化到0~255 之间,并将其进行可视化,结果如图1 右下黑白图像所示。本文将在3.4 节对投票权值图的可视化图进行具体分析。
2.2 各尺度分割结果对比
为验证本文方法的前提条件,即不同尺度的相同图像在同一已训练分割网络下的分割结果不同,本文采用在开源框架OpenMMLab[20]训练的最佳DeepLabv3+[4]语义分割网络模型,并在无人驾驶标杆数据集Cityscapes[18]上进行实验。
图2 所示为不同尺度图像的预测流程,其中小尺度图像为长宽缩小1 倍,原尺度为原图,大尺度图像的长宽放大1 倍,将其分别输入到已在Citysca-pes数据集下训练的DeepLabv3+模型中,得到各自的分割结果。如某像素归类为车辆,则用对应颜色掩膜掩盖,最后将掩膜与原图叠加。为便于观察,将图2中小尺度图像上采样2 倍、原尺度图像不变、大尺度图像下采样2 倍,各尺度保持同样长宽大小,并将预测的分割掩码叠加在原图上,分割结果如图3 所示(彩色效果见《计算机工程》官网HTML 版),其中小目标用白圈标出,长条状目标用黑圈标出。

图2 不同尺度图像的预测流程Fig.2 Prediction process of different scale images

图3 不同尺度图像的分割结果对比Fig.3 Results comparison of different scale segmentation
为方便叙述,按每组虚线框出现的顺序对虚线框进行标号,从左至右分别为左1、左2、左3、左4,从左至右观察图3 可以发现以下现象:
1)在左1 虚线框中,在分割目标边缘时,大尺度图像相较于原尺度图像、小尺度图像,分割结果愈加精细。
2)在左2 虚线框中,原、大尺度图像的分割结果过于追求细节,导致目标内部分割间断。小尺度图像在边缘处分割得不平整,在目标内部不过分追求细节,更注重目标整体信息,目标内部分割效果较好。
3)在左3 虚线框中,在分割小目标时,大尺度图像能够正确分割出骑手小目标,而原尺度、小尺度图像将骑手误识别成行人,且边缘分割效果明显弱于大尺度图像。
4)在左4 虚线框中,在分割长条状目标时,大尺度图像的分割效果相较于原尺度图像、小尺度图像,捕捉的长条状目标信息依次增多,漏检概率逐渐降低。
以上实验数据将在第3 章节中给出,并测试各尺度总体及不同类的分割精度。总体上,原尺度图像的总精度最高,小尺度图像的总精度最低。而在某些类别中,如行人、骑手(小目标),栅栏、路杆(长条状目标),大尺度图像的分割精度高于原图。但由于目标内部分割效果不佳,限制了大尺度图像的分割精度。
根据上述实验,各尺度图像的分割结果都有独特的优势,本文旨在结合各尺度图像优势,提升分割精度。
2.3 训练方式
与一般语义分割网络的训练方式不同,投票网络不改变分割网络模型,仅训练投票网络。在网络训练方式上,本文沿用TAO等[15]的方法,仅训练相邻尺度间的相对关系,并灵活增加其他尺度,不再针对某一尺度额外训练。将给定的输入图像按因子r进行缩放,其中r=0.5 表示按因子2 下采样,r=2 表示按因子2 进行上采样,r=1 代表原图。由上文多尺度预测的实验结果可知,下采样2 倍的图像与原图的分割精度相差较大,更能突出尺度间的相对差异,因此本文采用小尺度图像和原图进行训练。
如图4 所示,将原尺度图像和下采样2 倍的图像分别输入已经过训练的DeepLabv3+网络中,得到各尺度预测特征图F。为保持相同尺度,将小尺度预测的特征图上采样(三线性插值)2 倍后,输入需训练的投票网络中,拟合小尺度的投票权值图Wr=0.5,并用1 减去小尺度的投票权值结果,作为原尺度的投票权值图(1-Wr=0.5)。即若小尺度某一像素投票权值为0.2,那原图对应像素的投票权值为0.8。最后将小尺度和原尺度的投票权值图分别与对应尺度预测的特征图相乘后相加,经过Softmax 函数得到投票后的预测结果,其表达式如式(1)所示:

图4 投票网络的训练结构Fig.4 Training structure of voting network

其中:U代表将特征图上采样2 倍;D代表下采样2 倍。
2.4 预测方式
在训练得到相邻尺度间的投票网络后,在预测时分层次灵活地应用此网络,并将若干相邻尺度的预测结果进行整合。采用下采样2 倍、原尺度、上采样2 倍的图像进行举例,如图5 所示。
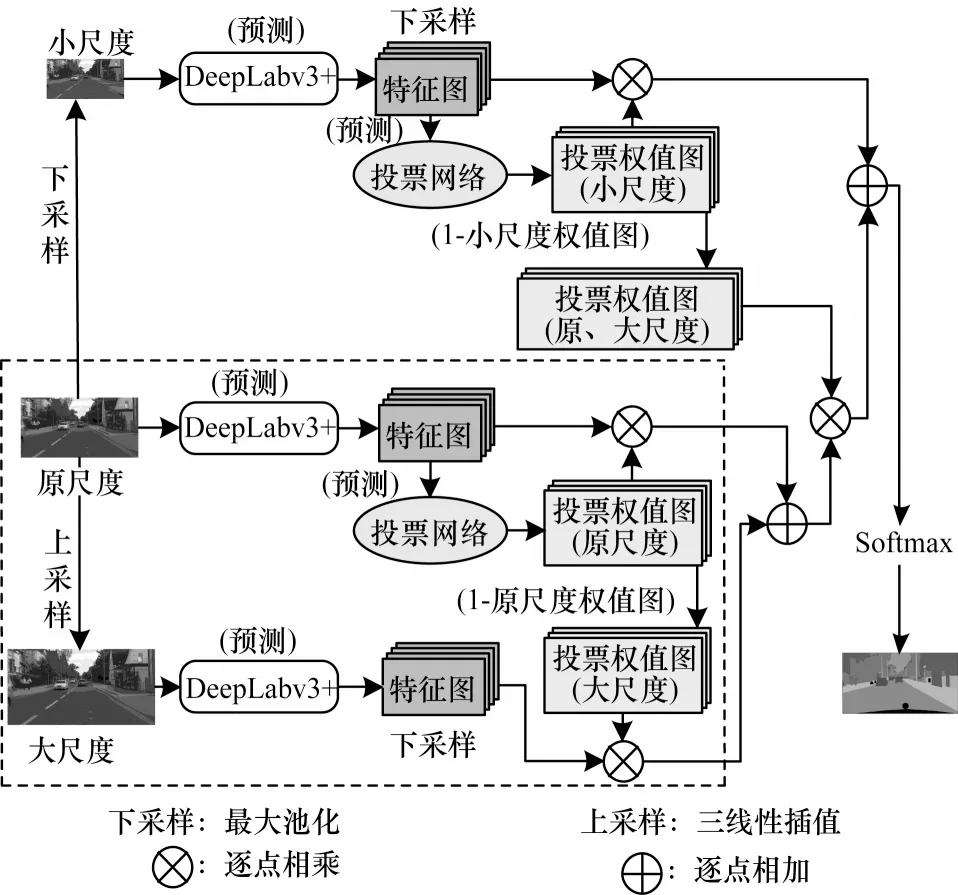
图5 投票网络的预测结构Fig.5 Prediction structure of voting network
将原图分别进行上、下采样,其中,图5 虚线框内为大尺度图像和原图的成对预测结构(与训练结构相同),并得到大尺度图像和原图投票的预测结果,如式(2)所示:
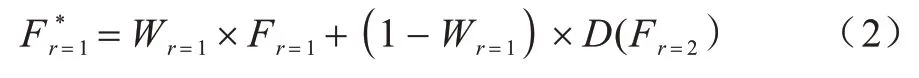
将图5 中虚线框圈出的部分作为一个整体,与小尺度分割结果以相同方式结合,得到最终的分割结果,表达式如式(3)所示:
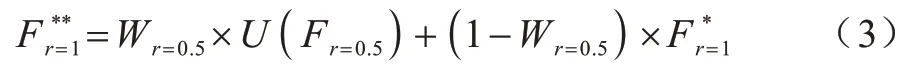
3 实验结果与分析
3.1 实验环境
使用深度学习框架Pytorch[21]实现投票网络,本文实验的硬件和软件环境如表1 所示。将本文网络在Cityscapes[18]大型街景数据集上进行验证。该数据集是目前公认的具有较强权威性、专业性的图像语义分割评测数据集,包含了50 个城市不同场景、背景、季节的街景,提供了5 000 张精细标注图像、20 000 张粗略标注图像,分别对应精细和粗略两套评价标准。本文采用精细标注的5 000 张高分辨率图像进行实验,其标注了19 个语义类,并以精细评价标准验证本文方法。
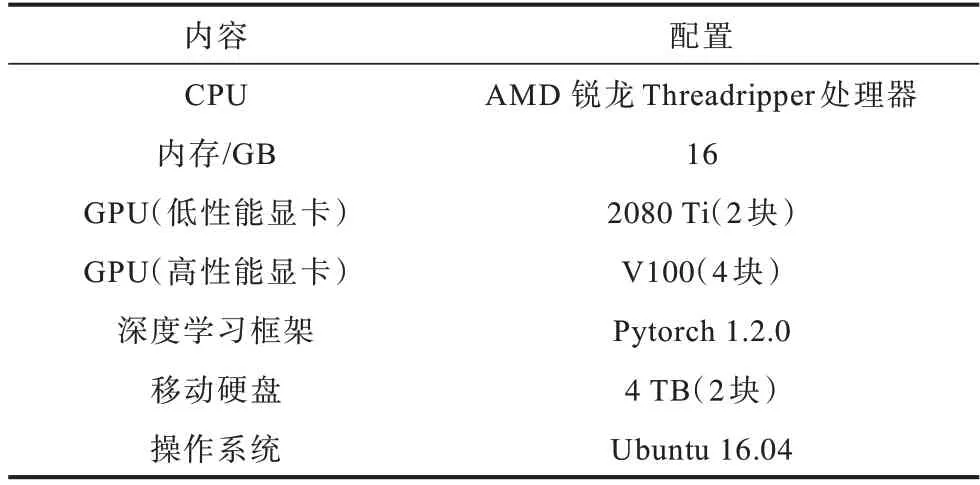
表1 实验硬件与软件配置Table 1 Experimental hardware and software configuration
本文在训练投票网络时与一般分割网络不同,并不直接将图像输入网络,而是保留不同尺度图像的分割结果,再输入投票网络进行训练。采用开源框架OpenMMLab[20]共享的不同分割网络模型进行实验,以保证实验的可靠性与公平性。为保证实验的一致性,实验均选用在高性能显卡、相同训练策略下得到的模型,并将其定义为最佳模型。具体训练细节如下:采用4 块V100 显卡训练,骨干网络选取ResNet50-B[22],以随机梯度下降算法优化模型,交叉熵为损失函数,动量设为0.9,学习率为0.01,权重衰减为0.000 5,随机尺度缩放比例为0.5~2 倍,随机裁剪大小为769×769 像素,批处理参数设为8,迭代训练80 000 次。根据以上规则在不同分割网络上训练模型。
以DeepLabv3+网络为例,在网络中输入不同尺度的图像,得到不同尺度的分割结果,再将其经过上、下采样操作变回原图的大小,转换成NumPy 格式保存。其中,通道数为分割类别数,长宽与原图相同,每张图像各尺度分割结果的文件大小为155 648 KB。
在训练投票网络时,由于无需再重新训练分割网络,仅需训练投票网络,因此仅采用2 块低性能显卡2080 Ti 训练,并以随机梯度下降算法优化模型,将批处理参数设为2,动量设为0.9,学习率为0.001,学习率衰减乘数因子为0.1。由于目标边缘占图像比例较小,因此采用Focal Loss[23]作为损失函数,从而缓解边缘和整体图像比例严重失衡的问题。在Cityscapes 数据集[18]中,投票网络进行80 000 次迭代训练后,通过结合各尺度分割结果,达到对比网络中较高分割精度。
3.2 评价指标
本文采用语义分割中通用的评价指标平均交并比(mean Intersection over Union,mIoU)评价本文方法,通过计算各类预测值和真实值2 个集合的交并集之比,再取其平均值,mIoU 的表达式如式(4)所示:
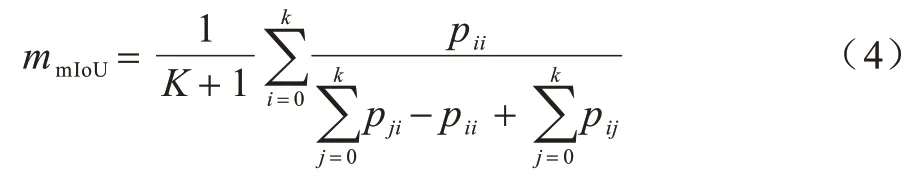
设存在K+1 个类别,存在一个背景类,pij代表i类被错误预测成j类的像素数量;pii代表预测正确的像素数量,通过计算预测结果与真值的重合程度判断分割效果。mIoU 的值域为0~1,数值越大,代表分割精度越高。
3.3 投票网络有效性验证
为验证本文网络的有效性,选用经过开源框架OpenMMLab 训练的 DeepLabv3+最佳网络(DeepLabv3+*网络)作为基线网络与其他网络进行对比,测试不同网络对不同尺度图像的分割精度。此外,将文献[16]所提网络和文献[17]所提网络在不同图像尺度(图像放缩为原尺度后,对应像素求平均值)上进行实验。结果如表2 所示,其中:1.0 代表图像原尺度,2.0 代表图像的长宽各放大2 倍,0.5 代表图像的长宽各缩小2 倍,0.25 代表图像的长宽各缩小4 倍;分割网络采用4 块V100 显卡训练,投票网络仅采用2 块2080Ti显卡训练,由于训练投票网络需在分割网络模型基础上进行,为进行区分,将本文方法的训练显卡用+2*2080Ti表示(下同)。由表2 可知,实验结果与前文所述相同,mIoU 的提升效果不佳,但本文网络的精度提升幅度最大。与DeepLabv3+*网络在尺度为1.0的图像下的mIoU值相比,本文网络在组合原尺度和大尺度图像时,mIoU提升0.76个百分点,在组合3个尺度时,mIoU提升0.89个百分点,在组合4 个尺度时,可提升0.92 个百分点。由表2 还可以得知,投票网络在最佳网络模型基础上可达到的较高分割精度为80.30%。

表2 不同网络的实验结果对比Table 2 Comparison of experimental results of different networks
为验证本文方法的通用性,基于3.1 节下的规则,选用FCN[1]与PSPNet[2]网络训练的最佳模型(分别为FCN 模型*、PSPNet模型*)进行实验,并使用在2*2080Ti显卡上训练出的DeepLabv3+[13]模型(DeepLabv3+(本地))进行对比实验,结果如表3所示。由表3可以看出,本文网络可以在其他经典网络的基础上提高模型的分割精度。且由于FCN 模型边缘分割的效果弱于PSPNet和DeepLabv3+(本地)模型,因此在使用本文网络时精度提升幅度更大。

表3 不同语义分割模型的结果对比Table 3 Comparison of results of different semantic segmentation models
3.4 投票权值可视化
为增加本文方法的可解释性,将投票网络学习到的权值图进行可视化。以相邻尺度的投票权值图为例,分别将原尺度、大尺度的投票权值图各通道合并,并归一化到0~255 之间,得到图6、图7 所示的灰度图。其中某像素越趋近于白色,权值越趋近于255,即投票权重越大;像素越趋近于黑色,权值越趋近于0,即投票权重越小。

图6 原尺度投票权值图可视化Fig.6 Visualization of the original scale voting weight map
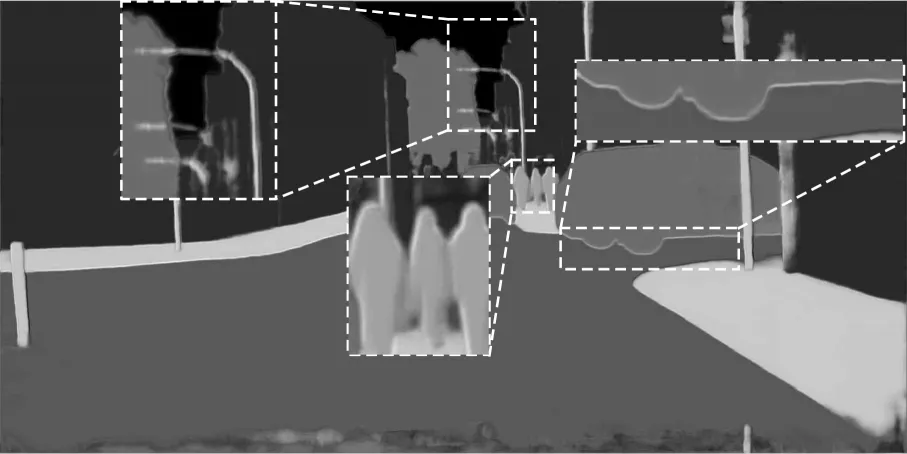
图7 大尺度投票权值图可视化Fig.7 Visualization of the big scale voting weight map
为方便叙述,按每组虚线框出现的顺序对虚线框进行标号,从左至右分别为左1、左2、左3。由图6、图7 可知:
1)在小目标、长条状目标处,如在左1、左2 虚线放大框中,路杆(长条状目标)与行人(小目标)内部在大尺度权值图中更趋近白色,在原尺度中趋近黑色,即网络更趋向于相信大尺度图像的分割结果。权值图并未完全趋近白色,这说明网络避免了大尺度面临的内部分割间断问题。
2)在目标边缘处,如在左3 虚线放大框中,车辆边缘在大尺度权值图中更趋近白色,在原尺度中趋近黑色,即网络在边缘处更趋向于相信大尺度的分割结果。在左2 虚线放大框中,也可明显发现在边缘处更趋近白色。
3)相较于目标边缘,网络在目标内部稍趋向于相信原尺度的分割结果,而在非小、长条状目标内部,这一趋势更为明显。如图6 中十字形标出的非小、长条状目标内部区域,在原尺度权值图中更趋近白色,在大尺度中趋近黑色,即在非小、长条状目标内部,网络更趋向于相信原尺度的分割结果。
综上,图6、图7 显式地验证了本文网络的有效性。
3.5 消融实验
为验证本文网络中各子模块的有效性,选用经过开源框架OpenMMLab 训练的DeepLabv3+最佳网络(DeepLabv3+*网络)进行消融实验,并量化分析各模块的作用,即在Deeplabv3+*基础上加入各模块,从而分析本文网络各模块的作用。该实验中模块的添加为逐渐累积的过程,比如在添加多类别投票模块(+多类别投票模块)的基础上,再添加混合池化模块,以此类推,结果如表4 所示,其中,TAO 网络(本地)表示将TAO 网络在本文网络上进行实验。

表4 本文网络各模块的消融实验结果Table 4 Ablation experiments for each module of network in this paper
由表4 可知,与DeepLabv3+*网络相比,TAO 网络(本地)的mIoU 提升效果不明显。通过分析发现,TAO网络由于未考虑每一类的投票权值偏好,因此投票选择空间有限。此外,TAO 网络仅堆叠了2 层卷积,感受野过小,因此通过融入混合池化模块可分别获取近程与远程的相关投票权值信息,尤其改善长条状目标的投票权值拟合效果。为进一步获取类内、类间投票权值关系,本文在投票网络中分别加入类内、类间双投票注意力模块,以获取相邻投票权值关系,选择性地加强相互依赖的类间投票映射。如表4 所示,当加入类间投票注意力模块时,精度相比仅增加多类别投票模块和混合池化模块可提升0.13 个百分点,当加入类内投票注意力模块时,精度在此基础上可提升0.15 个百分点。最后本文通过采用不规则卷积优化投票权值图在目标边缘的处理,从而提升投票权值图的目标边缘拟合效果,但由于边缘所占像素较小,因此在总体精度上仅有较小幅度的提升。
3.6 投票网络与共享网络对比
为量化分析投票网络与共享网络的差异,采用本地2 块2080Ti 显卡对网络进行训练,结果如表5 所示。由于投票网络在模型外部训练,而共享网络的多尺度注意力头在模型内部训练,所以采用内、外分别表示共享网络和投票网络。

表5 投票网络与共享网络的实验结果对比Table 5 Comparion of experimental results between voting network and sharing network
对比表5中TAO 网络(外)与TAO 网络(内)的数据可知,TAO 网络(外)的mIoU 略低于TAO 网络(内),但需训练的模型大小却大幅降低,缩小了413 倍。对比本文网络(内)与本文网络(外)的数据可知,本文网络(外)的mIoU 高于本文网络(内),其训练模型缩小了102 倍。
相较而言,共享网络需拟合的参数多,训练复杂度高,较难收敛。而本文将不同尺度图像的预测结果用于训练外接投票网络,与用于共享网络相比,最佳模型的预测结果比网络内部的特征图更稳定,能够学习更可靠的投票模型,且参数量较小,更易收敛。
为进一步显式分析,将TAO等[15]的大尺度注意力权值图与本节模型外方式拟合出的投票权值图进行对比。如图8 所示,为方便叙述,按每组虚线框出现的顺序对虚线框进行标号,从左至右分别为左1、左2、左3、左4。其中左1 为TAO 等的大尺度权值图,左4 为本文网络的大尺度权值图。对比发现,本文网络对小、长条状目标更敏感。如两图中最左边虚线放大框所示,左4 的行人(小目标)比左1 更清晰,边缘勾勒也更明显。另外,如两图中最右边虚线放大框所示,左1 几乎丢失了路杆信息(长条状目标),而左4 的路杆信息被成功捕获。如两图中的中间虚线放大框所示,车辆边缘被成功勾勒出了边缘,相较左1 而言,左4 图片更清晰。从整体上,左4 的层次感也优于左1 图片,即尺度间的投票权值相差更大,越偏向于正确尺度的分割图。

图8 投票权值对比Fig.8 Comparison of voting weights
3.7 不同类别的mIoU 对比
为对比不同类别的mIoU,在Cityscapes 数据集中选取有代表性的类,包括交通标志、行人、骑手、摩托车等小目标的类;路杆等长条状目标的类;小汽车、公共汽车等中目标的类;人行道、马路等大目标的类。选用经过开源框架OpenMMLab 训练的DeepLabv3+最佳网络(DeepLabv3+*网络)进行实验,结果如表6 所示。由表6 可知,前3 行分别为不同尺度(0.5、1.0、2.0)图像输入DeepLabv3+*网络的各类分割精度,表6 最后2 行分别为以模型外训练方式的TAO*网络与本文网络在0.5、1.0、2.0 尺度组合下的分割精度。在表6 前3 行中,原图的总精度相对最高,小尺度总精度相对较低。在具体类中,原尺度在大部分类中分割精度最高,小尺度中大目标的类别分割精度与原图的差距小于其他类,大尺度中小、长条状目标的分割精度优于原图。但内部分割间断拉低了整体精度,而本文通过结合小、原尺度的分割结果弥补了该缺陷。

表6 不同网络对不同类别图像的mIoU 值对比Table 6 mIoU value comparison of different types of images by different networks %
表6 第4 行为将TAO*网络以模型外方式训练后测试的分割精度,与原尺度分割结果对比,网络的mIoU 有一定提升,但提升幅度较小。本文在此基础上进行改进后,在大部分类别中提升幅度较大。实验结果也验证了相比于其他类,网络在小目标、长条状目标处的分割精度较低。本文网络可更好地改善小目标、长条状目标的分割效果,但不可忽视的是,在表6 中,使用本文网络分割属于中目标的公共汽车类的分割精度相比于原尺度有小幅下降。而图7已验证了本文网络可在中目标的边缘处进行优化,理论上来说不应有所下降。通过结合分析属于大目标的马路类分割精度提升幅度过小,猜测此时投票网络已经陷入局部最优,还未能充分把握中目标与大目标间正确的尺度关系,导致在目标内部出现像素投票偏差,在一定程度上限制了分割精度的提升幅度。
4 结束语
本文提出一种面向语义分割模型的外接多尺度投票网络,在外接投票网络结构中,分别对多类别投票模块、混合池化模块、类内与类间投票注意力模块及不规则卷积4 个模块进行改进,以更好地拟合投票权值。在消融实验中验证每个模块的有效性,并通过可视化的投票权值图,进一步证明CNN 网络在不同尺度图像中的分割偏好。实验结果表明,相比FCN、PSPNet、DeepLabv3+等分割网络,本文网络的mIoU 分别提升了0.92、0.88、0.80 个百分点,尤其提高了对小目标、长条状目标、目标边缘处的分割精度。下一步将利用不同尺度的分割偏好及引入注意力机制,把握中目标与大目标间更正确的尺度关系,从而提高网络对中目标以及大目标的分割精度。
猜你喜欢
一重技术(2021年5期)2022-01-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
青年与社会(2019年29期)2019-11-29
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
电子制作(2018年11期)2018-08-04
法人(2018年5期)2018-05-09
对外经贸(2017年6期)2017-08-24
太空探索(2016年5期)2016-07-12
华人时刊(2016年16期)2016-04-05
