
基于多模态融合与多层注意力的视频内容文本表述研究
2022-10-16 12:27赵宏郭岚陈志文郑厚泽
计算机工程 2022年10期
赵宏,郭岚,陈志文,郑厚泽
(兰州理工大学计算机与通信学院,兰州 730050)
0 概述
随着移动互联网的快速发展和智能设备的普及,人类信息化进程进入了新阶段。视频由于包含丰富内容且能够直观表达观点,因此逐渐在互联网上流行。例如,在各种社交平台上由用户生成的共享短视频已成为人们社交的重要手段。当前,如何自动地分析和理解视频内容,并将其转换为文本表达方式,成为视频内容文本表述领域的研究热点。视频内容文本表述研究也一直是计算机和多媒体领域极具挑战性的研究课题[1-2],该研究在回答图像问题[3]、应用图像与视频检索[4-6]、协助视觉障碍的患者理解媒体内容[7]等领域具有广阔的应用前景。
视频内容文本表述的早期研究主要基于固定模板结构[8-10],包括内容识别和根据模板生成句子2 个阶段。其中,内容识别通过对视频中的主要对象进行视觉识别和分类;根据模板生成的句子将内容识别的实体匹配到模板所需的类别,如主语、谓语、宾语和地点。但该方法过于依赖预先设定的模板,导致生成的描述灵活性差,生成的句子过于单一,不能全面覆盖视频内容。受机器翻译方向编码器-解码器框架的启发,目前视频内容文本表述主流方法预先采用在对象识别与检测领域广泛应用的卷积神经网络(Convolutional Neural Networks,CNN)[11-13]获取视觉信息并生成视觉表征向量,然后使用在自然语言处理方面取得巨大进步的循环神经网络(Recurrent Neural Network,RNN)[14-16]作为编码器接收视觉表征向量并进行编码,生成中间隐藏向量,接着将其送到由RNN 组成的解码器,生成序列化的自然语言表达。然而,现实中的视频由不同模态的内容构建而成[17],其不仅包含图像信息,还具有视频中对象的运动、背景中的音频、上下文的时序等信息,且不同模态信息之间具有高度相关性和互补性,这些模态通过相互配合提供完整的信息。
本文基于不同模态信息之间具有高度相关性和互补性的特征,提出一种将多模态融合与多层注意力相结合的视频内容文本表述模型。采用融合互补模态信息训练视频内容文本表述模型,并针对不同的视频模态信息,采用预训练模型提取视频中静态帧和音频表征信息,提升视频内容文本表述的准确率。基于自注意力机制设计嵌入层,对单模态特征向量进行嵌入建模,使不同模态间的互补信息能更好地拟合。最后,采用协作表示进行跨模态特征融合,并通过融合特征有效提升模型对视频内容的描述质量。
1 相关工作
视频内容文本表述研究旨在通过使用自然语言的方式对视频所展示的内容进行分析、理解与表述,目前视频内容文本表述的主流方法以“编码-解码”架构为基础,主要可以分为基于视觉特征均值/最大值、基于视频序列记忆建模和基于三维卷积特征这3 种方法。
基于视觉特征均值/最大值的方法对视觉特征进行提取,并求解特征均值或最大值。其中,文献[18]基于长短期记忆(Long Short-Term Memory,LSTM)网络提出一种LSTM-MY 模型,采用帧特征均值池化的方式对视觉特征进行提取,其性能相较于基于模板的方法有所改善。文献[19]针对生成文本和视频内容关联性不够的问题提出RUC-UVA 模型,通过结合Video tagging 方法提取视频关键词,并将关键词和视频帧特征相结合作为解码器的输入,能有效提高生成文本的准确性。但该类方法难以捕获视频片段内的时序特征,极易造成动态特征的丢失。
在基于视频序列记忆建模的方法中,文献[20]针对视频数据预处理时需要注意时序信息提出时间注意力(Temporal Attention,TA)模型,该模型在时间维度上结合注意力机制,将得到的特征输入解码器生成文本表述,生成的句子适应性较高。文献[21]针对视频不定长的问题将序列到序列模型应用到视频到文本任务上,实现了对视频帧序列输入、文字序列输出的端到端视频描述。虽然该方法可以实现时序特征提取与语言模块的端到端训练,但是CNN 特征经过序列变换之后极易导致视频帧中空间信息的破坏与丢失。
基于三维卷积特征的方法对视频的时空特征进行编码,挖掘视频的静态特征和时序动态特征。文献[22]提出M3-inv3 模型,通过提取视频帧的2D 和3D 特征对视觉信息和语言信息共同建模,较好地解决了LSTM 中多模态信息长期依赖与语义错位的问题。文献[23]提出一种用于图像和视频字幕的具有自适应注意方法的分层LSTM,利用空间或时间注意力选择区域预测相关词。
视频所携带的音频信号对视频具有重要的意义,视频配音能够以声音的形式说明视频的要点和主题,例如掌声、鸣笛、说话与唱歌的区别只能从音频信息中捕获到。如图1 所示为一段视频的3 个画面,对其进行描述的3 个文本如下:

图1 视频内容文本描述示例Fig.1 Example of video content text description
1)a man giving a speech。
2)a man wearing a suit is giving a speech。
3)a man speech won applause from the audience。
其中,第3 种文字描述最为准确,因为其结合音频特征,提取出了视频中的“掌声”信息。
综上,当前视频内容文本表述模型对提取到的单模态表征信息利用不足,且未利用视频所携带的音频等信息,导致生成的文本对视频内容表述质量不高。因此,本文综合考虑单模态特征参数学习以及视频多模态表征信息之间的互补性,通过提取视频不同模态的表征信息获得每种模态所表达的语义属性,将其进行融合后对视频内容进行表述,从而提高模型对视频内容文本表述的性能。
2 视频内容文本表述模型
2.1 模型结构
图2 所示为多层注意力的跨模态视频内容文本表述模型的结构,包括视频预处理、单模态特征提取、编码(单模态信息嵌入、多模态信息融合)和解码4 部分。

图2 多模态视频内容文本生成模型Fig.2 Multi-modal video content text generation model
在图2 中,视频预处理模块主要提取视频帧、抽取视频的音频信息。单模态特征提取模块利用改进的残差网络(Residual Network,ResNet)网络[24]提取视频的2D 帧特征、FFmpeg 提取音频MFCC 特征。编码器模块由嵌入层与融合层组成,嵌入层包括自注意力机制[25]和两层LSTM 网络[26],融合层由协作表示构成。编码器将帧、音频模态的特征向量作为输入,并分别送入嵌入层进行单模态信息建模,最终编码为单独的隐藏向量{hv,haudio},然后通过协作表征方式将各模态信息映射到统一的多模态向量空间Vmulti。解码器接收Vmulti进行解码,预测当前时间的隐藏状态,依次输出每一时间步的概率分布向量。最后,利用贪心搜索算法取解码时刻每一时间步上概率最大的单词作为预测输出结果。在当前时间步t下各个单词的概率分布表达式如式(1)所示:

其中:ht是当前隐藏状态;Yt-1是上一时间步得到的结果;Vmulti是统一的多模态向量空间;softmax 函数是归一化指数函数。将结果映射到(0,1)之间作为概率值,并当所有概率分布计算结束后,采用贪心搜索算法取解码时刻每一个时间步上概率最大的单词作为预测输出结果,直到输出<eos >,解码完成。
2.2 特征提取
视频数据与图片数据的不同点在于视频是连续的多帧画面,该特性使视频更适合描述连续性动作,且视频附带对应的音频信息可以形象地记录一个事件。相比单张图片,视频不仅包含了空间特征,还具有时序特征、音频、动作等特征[27]。因此,在上下文中确定需要表达的内容并进行准确描述是一项很大的挑战。
本文采用融合视频的多种模态特征进行视频内容文本表述任务。对于视频的静态帧特征提取,在残差网络ResNet152 中加入文献[28]提出的通道注意力(Squeeze and Excitation,SE)模块,以提取帧级2D 特征。对于视频中音频信息的提取,采用FFmpeg 提取语音信号的Mel 频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)。特征提取具体如下。
1)自注意力
自注意力模块对输入的特征图进行自主学习并分配权重,从而获取特征图中的重要信息,减少模型对外部信息的依赖,使网络更注重于捕捉信息内部的相关性。此外,自注意力模块的序列特征提取能力较强,因此采用自注意力模块结构来设计本文模型的嵌入层,其结构如图3 所示。

图3 自注意力模块的结构Fig.3 Structure of self attention module
由图3 可知,自注意力模块首先创建3 个向量Q、K和V,并在训练过程中对向量进行调整优化,通过向量Q与向量K的点积计算得到QKT向量,将结果除以维度平方根使梯度更加稳定,再通过softmax函数归一化计算得到权重信息。最后将计算得出的权重信息与向量V相乘,放大重点关注信息,弱化不重要的特征信号。具体计算式如式(2)所示:

2)视频帧特征提取
在ResNet152 网络中嵌入SE 模块,并将其作为视频帧特征提取网络,如图4 所示为ResNet 模块的原始结构与嵌入SE 模块的SE-ResNet 结构。通过嵌入SE 模块对ResNet 网络提取的特征进行重调,并利用提取的全局信息衡量每一特征的重要性,使其得到各通道间的相关性,协助完成特征的重新标定。此处,为简化模型参数的复杂性,在SE 模块的ReLU激活函数两端依次采用1×1 的全连接层[29],从而使网络具有更多的非线性,能够拟合通道间的相关性,同时提升重要特征的权重并抑制非重要特征的权重。

图4 ResNet 模块与SE-ResNet 模块的结构对比Fig.4 Structure comparison of ResNet module and SE-ResNet module
将数据集中每条视频预处理成固定帧,每条视频等间隔取40 个关键样本帧,然后送入经过ImageNet 数据集预训练的SE-ResNet 模型中提取帧的特征信息,得到40×2 048 的高维特征向量。
3)音频MFCC 特征提取
目前语音特征提取方法有线性预测倒谱系数(Linear Predictive Cepstral Coefficient,LPCC)提 取法[30]和MFCC 提取法[31]。其中,MFCC 提取法主要基于人的非线性听觉机理,模仿人耳的功能分析语音的频率,能够更好地提取语音信号特征[32]。其中,Mel 是感知音调或音调频率的度量单位,1 Mel 为1 000 Hz 的音调感知程度的1/1 000,其具体定义如式(3)所示:

其中:fmel为Mel 频标;fHz为实际线性频率。
Mel 滤波器倒谱参数特征在语音特征提取中占有重要的地位,且计算简单、区分能力较突出。MFCC 的特征参数提取原理如图5 所示。

图5 MFCC 特征参数提取Fig.5 MFCC feature parameter extraction
由图5 可知,MFCC 特征参数提取过程首先对抽取出来的音频信号进行预加重、分帧、加窗等预处理操作,并对分帧之后的单帧信号进行离散傅里叶变换,最终得到频域数据,如式(4)所示:

其中:xi(k)是第i帧的数据;k表示频域中第k条谱线。
其次,将频域数据通过w个Mel 频率滤波器进行滤波,提取频谱、Mel 滤波器组和频率包络,滤波器的频域响应Hw(k)表达式如式(5)所示:

然后,对处理过的能量频谱取对数,使傅里叶变换中幅度乘法转换为加法,得到对数能量Si(w),该过程的计算式如式(6)所示:

其中:i为第i帧:k为频域中第k条谱线。
最后,将对数能量代入离散余弦变换(Discrete Cosine Transform,DCT),得到MFCC 系数,计算式如式(7)所示:

其中:w指第w个Mel 滤波器;i指第i帧;n为DCT 之后得到的谱线。
将数据集中每条视频抽取的音频分成1 120 帧,并从每一帧中提取20 维的MFCC 信号,将其存储为1 120×20 的高维音频特征矩阵。
2.3 特征融合
采用联合表示以及协作表示2 种多模态特征融合方法[33]。其中,联合表示方法的示意图如图6 所示,其通过将多个模态的信息统一映射到一个多模态向量空间中,获得多个模态特征,拼接融合得到表征,并在拼接向量维度较高时进行主成分分析(Principal Component Analysis,PCA)降维操作,形成多维特征向量空间。协作表示方法的示意图如图7 所示,该策略并不寻求融合而是通过建模多种模态数据之间的相关性,将多个模态信息映射到协作空间,映射关系为f(x1)~f(xm),其中“~”表示一种协作关系。网络的优化目标就是优化协作关系。

图6 联合表示方法的示意图Fig.6 Schematic diagram of joint representation method

图7 协作表示方法的示意图Fig.7 Schematic diagram of collaborative representation method
将预训练模型提取到的模态特征作为自注意力机制嵌入层的输入,并进行单模态参数学习,然后在特征融合阶段分别利用联合表示和协作表示对提取的单模态特征进行融合实验。实验结果表明,联合表示方法保留了多个模态各自独立的表示空间,而协作表示方法注重捕捉多个模态的互补性,通过融合多个输入模态x1,x2,…,xm获得多模态表征X=f(x1,x2,…,xm)。因此,本文选择协作表示方法对多种模态数据之间的相关性进行建模。
3 实验结果与分析
3.1 实验硬件平台
实验服务器配置为48 核Intel®Xeon®Gold 5118 CPU,内存128 GB,显存为32 GB 的NVIDIA Tesla V100 GPU,操作系统为Ubuntu18.04,加速库为NVIDIA CUDA 11.3 和cuDNN v8.2.1,模型建立与训练框架为PyTorch。
3.2 数据集
本文选用MSR-VTT 数据集和大型电影描述挑战赛(LSMDC)数据集,具体描述如下。
1)MSR-VTT 数据集
MSR-VTT[34]是微软发布的视频生成文本的大规模公共数据集。本文实验采用2017 年更新版MSR-VTT 数据集,该数据集包含10 000 个训练视频片段和3 000 个测试视频片段,总时长达41.2 h,平均每个片段包含20个自然语言标注语句,共计200 000个语句。该数据集包含20 个代表性类别(包括烹饪和电影)的257 个热门门类视频片段,是当前较全面和具有代表性的经典数据集。数据集内容分布如图8所示,其中,X轴为视频类别,共20 类,Y轴为各类别下的视频总数。

图8 MSR-VTT 数据集的内容分布Fig.8 Content distribution of MSR-VTT dataset
2)LSMDC 数据集
LSMDC 数据集由MPII 电影描述数据集(MPII-MD)[35]和蒙特利尔视频注释数据集(M-VAD)[36]两组分组成。包含大约128 000 个句子片段和158 h 的视频,其中训练、验证、公共、盲测试集分别有101 079、7 408、10 053、9 578 个视频片段。由于用来描述动作片的词汇可能与喜剧电影中使用的词汇差异较大,因此该划分方式可以平衡每一组电影中的电影类型,使数据分布更合理。
3.3 评价指标
为验证模型的有效性,采用当前主流的视频内容文本表述评价指标,包括CIDEr[37]、METEOR[38]、ROUGEL[39]和BLEU[40],具体介绍如下。
1)CIDEr 指标是专门为图像或视频描述领域设定的评估指标,将模型生成的描述和真实描述表示为词频和逆向词频的向量形式,通过求其余弦相似度为生成的描述评分,在视频描述领域该评价指标具有较高的参考性。
2)METEOR 指标的计算基于单精度的加权调和平均数和单字召回率,其评价结果与人工评判结果具有一定相关性。
3)ROUGEL 指标在评价描述时考虑句子中单词的顺序,能够评价句子层级的意义。
4)BLEU 指标通过定义4 元词的个数来度量生成结果和目标语句之间的语义相似度。
以上4 种标准评价指标值越高,均表明所生成的描述语义越接近真实描述,准确率越高。
3.4 实验结果
3.4.1 实验参数设置
在模型读取每一帧图像之前,先将提取到的原始帧大小缩放至256×256 像素,对每帧图像进行15°随机旋转后再进行随机裁剪,得到224×224 像素大小的图像,最后对分词之后的文本词汇进行汇总统计,将大于低频阈值的词形成词汇表,剔除低于低频阈值的词汇。本文将词汇阈值设定为5,最终得到16 860 个词汇。
在模型训练阶段,参数优化采用Adam[41]算法,优化器参数α=0.9,β=0.999,ε=10-8,模型初始学习率为0.001,学习衰减速率为0.8,设定连续50 轮训练损失没有下降时的学习率衰减为0.8。采用负对数似然损失函数度量数据集标注语句与模型生成语句间的距离,迭代轮次为3 000 次,批处理大小设置为128。单模态嵌入层网络结构采用2 层LSTM 网络,将融合特征编码器以及解码器部分LSTM 层数分别设置为1、2、3 层进行实验。
3.4.2 结果分析
在模型训练过程中,每隔50 轮保存一次平均损失值,损失值下降曲线如图9 所示。可以看到,刚开始时损失值下降较明显,在2 200 轮以后,损失值整体趋于稳定。

图9 训练损失值曲线Fig.9 Training loss value curve
为验证本文模型的有效性以及具体参数对模型的影响,在相同实验环境下对视频的静态帧特征Vf、视频所携带音频的MFCC 特征Vaudio分别在模态Vf、双模态Vf+Vaudio下进行视频内容文本表述的训练,并在各模态组合的基础上,将单模态嵌入模块及编码器模块的LSTM 网络层数分别设置为1、2、3 层进行模型训练。模型在MSR-VTT 数据集上的实验结果如表1 所示。可以看出,本文模型通过学习单模态信息的参数及融合互补模态的表征信息,各类指标均有所提升,这验证了不同模态信息间具有高度的相关性以及互补性。由表1 还可以看出,在固定LSTM 层数时,在融合2D 帧特征、音频的MFCC 特征两种互补模态信息时模型评价得分最高。在固定模态时,当嵌入层、编码器2 个模块中的LSTM 层数为2 时,实验效果最佳。在固定模态以及LSTM 网络层数情况下,多模态融合方案采用协作表示方法训练得到的模型相较于采用协作表示方法得到的模型测试得分较高,这表明在视频内容文本表述中,采用协作表示方法进行模态信息融合效果较好。此外,表1 也验证了联合表示方法能够保留多个模态各自独立的表示空间,更适合仅有一个模态作为输入的应用,如跨模态检索、翻译等任务。而协作表示方法较注重捕捉多模态的互补性,通过融合多个输入模态x1,x2,…,xm获得多模态表征X=f(x1,x2,…,xm),更适合多模态作为输入的情况。
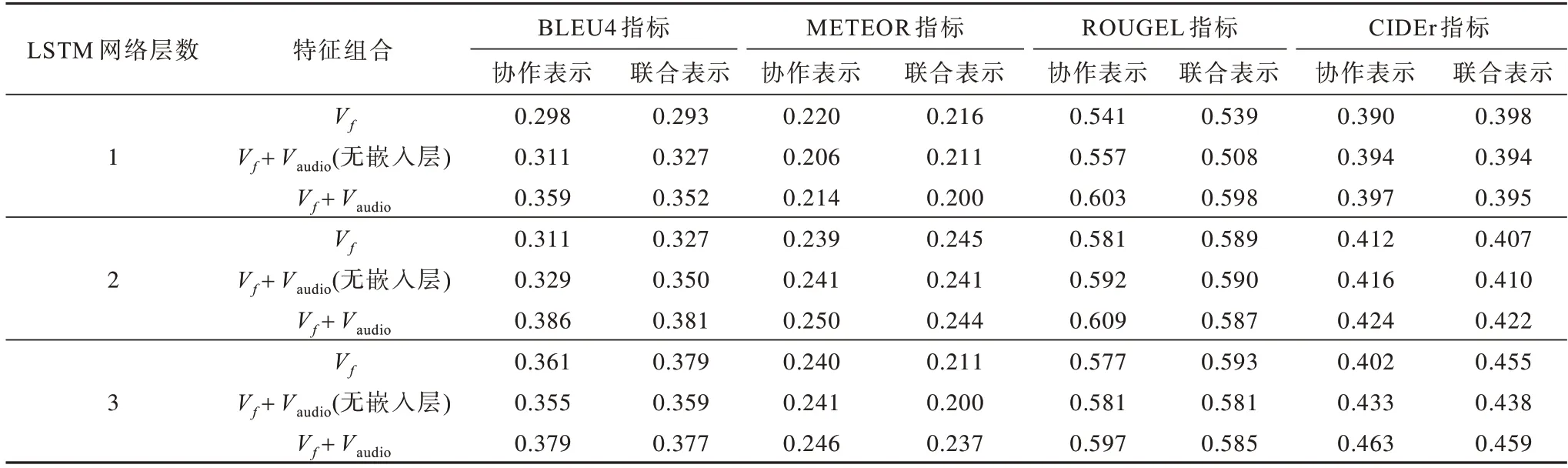
表1 消融实验的结果对比Table 1 Comparison of results of ablation experiments
本文模型首先对基于自注意力结构的嵌入层进行单模态相关参数学习,然后再通过协作表示方法进行多模态信息融合,融合后将其送入解码器。通过表1 的消融实验结果对比可以看出,相较于单模态及无嵌入层结构时的双模态情况,本文模型能够提升模型的性能,其评价指标相较于单模态模型的BLEU4、METEOR、ROUGEL 和CIDEr分别提升了0.088、0.030、0.068、0.073。
本文分别与第2 届MSR-VTT 挑战赛中排名前5的模型,即参赛组织RUC&CMU、TJU、NII、Tongji University 以及IIT DeIhi 所发布模型,以及当前主流视频内容文本表述模型MPool、S2VT、TA、M3-Inv3、Shared Enc 进行对比,结果分别如表2 和表3 所示。由表2 和表3 可知,本文模型相较于MSR-VTT 挑战赛中IIT DeIhi 发布的模型,评价指标BLEU4、METEOR、ROUGEL、CIDEr分别提升了0.082、0.037、0.115、0.257,相较于主流模型TA 分别提升了0.101、0.034、0.135、0.113,这证明多种互补模态相互融合对视频内容文本表述性能的提升具有积极作用。

表2 本文模型与第2 届MSR-VTT 挑战赛排名前5 模型的结果对比Table 2 Comparison between the results of model in this paper and the top 5 models in the 2nd MSR-VTT challenge

表3 不同模型的结果对比Table 3 Comparison of results of different models
此外,为验证本文模型的泛化性能,本文对比了不同模型在LSMDC 数据集下的METEOR 指标得分,结果如表4 所示。

表4 不同模型在LSMDC数据集下的METEOR值对比Table 4 Comparison of METEDR value of different models under LSMDC dataset
由表4 可知,相比当前主流视频内容文本表述模型frcnnBigger 和rakshithShetty,本文模型的METEOR 指标分别提升了0.018 以及0.005,虽然相比最优模型EITanque 得分稍有不足,但差距甚微。表2~表4 的结果验证了本文模型在保持较好性能的基础上,在不同数据集下也具有较好的泛化性能。
综合以上实验结果可知,通过引入视频的多种模态信息,可以获得更互补、更多样化的表征信息,使模型具有更好的鲁棒性。此外,多模态信息对复杂类视频片段的文本生成也同样具有积极作用,究其原因是视频不同模态信息间具有高度的相关性和互补性。
图10 所示为本文模型在MSR-VTT 数据集分割测试集的4 个视频片段示例,本文模型对以上4 个不同类别的视频片段进行文本生成,并挑选每个视频片段的前5 个真实数据(Ground Truth,GT)进行对比,分别用GT0~GT4 表示,结果如表5 所示。其中,本文模型输出的数据为生成数据。由表5 可知,本文模型所生成的视频文本内容丰富,且准确率更高,这验证了多种互补模态可以相互融合,提升模型性能。

图10 视频内容文本生成示例Fig.10 Example of video content text generation

表5 本文模型对视频片段的文本生成结果对比Table 5 Comparison of text generation results of video clips by model in this paper
4 结束语
本文提出一种将多模态融合与多层注意力相结合的视频内容文本表述模型,通过预训练模型提取视频所包含的静态帧及音频信息,利用自注意力模块的嵌入层进行单个模态的特征参数学习,以增强各模态间的互补性,为视频生成文本提供较为丰富、全面的表征信息,使模型生成的自然语言表达更加准确。在MSRVTT 及LSMDC 数据集上的实验结果表明,本文模型相较于MPool、S2VT、TA 等当前主流模型,在BLEU4、METEOR、ROUGEL、CIDEr 这4 个评价指标上的得分均有明显提升,生成的文本准确率更高。下一步将充分利用视频中对象与真实描述之间的对应关系及各种模态信息间的互补性,并结合注意力机制改进模型,使各种模态信息与文本信息对齐,在生成高质量文本的同时保证模型的轻量性。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
家庭影院技术(2021年1期)2021-03-19
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
人间(2015年8期)2016-01-09
