
COVID-19 疫情下基于YOLOv4 的安全社交距离风险评估
2022-10-16 12:27:00郭克友贺成博王凯迪王苏东李雪张沫
计算机工程 2022年10期
郭克友,贺成博,王凯迪,王苏东,李雪,张沫
(1.北京工商大学 人工智能学院,北京 100048;2.交通运输部公路科学研究院,北京 100088)
0 概述
新型冠状病毒肺炎(Corona Virus Disease 2019,COVID-19)是由SARS-CoV-2 病毒引起的急性呼吸道传染病,自2019 年12 月起,许多国家和地区受到了COVID-19 的侵袭[1]。2020 年5 月,世界卫生组织(World Health Organization,WHO)认定COVID-19为“大流行病”[2]。WTO 于2021 年11 月18 日发布的统计数据证实了200 个国家中有2 亿感染者,死亡人数高达500 万人。目前,仍没有明确的方案或方法消灭新型冠状病毒,全世界都采取了预防措施以限制该病毒的传播[3-4]。由于安全的社交距离是公共预防传染病毒的途径之一,因此在人群密集的区域进行社交距离的安全评估十分重要。
社交距离的测量旨在通过保持个体之间的物理距离和减少相互接触的人群来减缓或阻止病毒传播,在抗击病毒和预防大流感中发挥重要作用[5],但时刻保持安全距离具有一定的难度,特别是在校园、工厂等场所。在这种情况下,将人工智能、深度学习技术集成至安全摄像头,开发智能摄像头技术对行人进行社交距离评估尤为关键。针对疫情防范的要求,现阶段主要采用人工干预和计算机处理技术。人工干预存在人力资源要求高、风险大、时间成本高等缺点,而在计算机处理技术中,引入人工智能对社交安全距离进行安全评估具有良好的效果。吉林大学齐春阳提出基于单目视觉夜间前方车辆检测与距离研究[6],采用two-stage 的检测方式和注意力机制对车辆距离进行安全评估,但该方法的检测率和速度仍有较大的提升空间。BIAN 等提出一种基于可穿戴磁场的接近传感系统用于检测社交距离[7],该系统可达到近100%的准确率,但由于需要极大的资金成本,因此不能很好地进行实际应用。PUNN 等基于微调的YOLOv3 和DeepSort 技术,通过人员检测和跟踪来测控COVID-19 社交距离[8],但由于网络自身具有滞后性,因此该方法存在检测精度低、网络模型冗余等缺点。SATHYAMOORTHY 等提出COVID-Robot[9],在拥挤的场景中利用移动机器人监控社交距离限制,该方法在室内场景下起到了良好的监控作用,但鉴于机器人自身的因素限制,通过地平面的角度图不能及时监控被遮挡的行人。
上述研究致力于结合人工智能对抗COVID-19疫情,这对于改善和促进民众生活质量具有重要意义[10-11]。本文利用微调的YOLOv4 和DeepSort 算法对行人质点进行提取与跟踪。在此基础上,提出行人质点的运动矢量分析算法搜寻长时间未处于安全社交距离的行人,通过鸟瞰视角计算行人个体之间的距离,从而实现安全社交距离检测。
1 安全社交距离评估模型
1.1 总体框架
面向公众对于安全社交距离的实际要求,本文以公开数据集——牛津城市中心的数据集作为研究对象,基于YOLOv4 网络框架对目标行人进行检测,并提出运动矢量分析算法追溯长时间未处于安全社交距离的行人群体,利用鸟瞰图对违反社交距离的个体进行连线标定。本文模型的总体框架如图1所示。
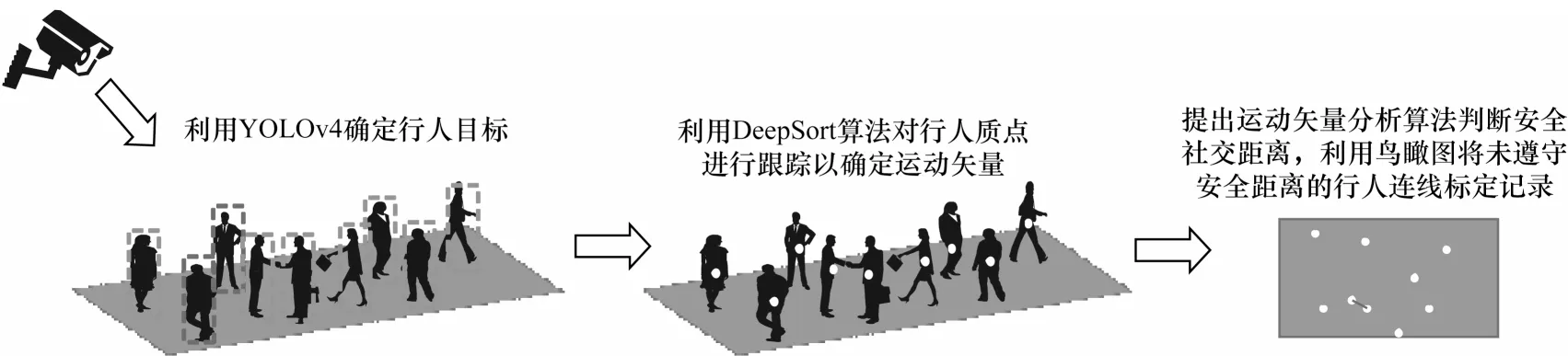
图1 本文安全社交距离评估模型的总体框架Fig.1 Overall framework of the proposed safety social distance assessment model
1.2 基于YOLOv4 的行人检测
YOLOv4[12]使用卷积网络CSPDarknet53 进行特征提取,网络结构模型如图2 所示。在每个Darknet53的残块行加上跨阶段局部结构(Cross-Stage Partial,CSP)[13],将基础层划分为两部分,再通过跨层次结构的特征融合进行合并[14]。同时,采用特征图金字塔网络(Feature Pyramid Network,FPN)[15],通过不同层特征的高分辨率来提取不同尺度特征图进行对象检测。最终网络输出3 个不同尺度的特征图,在3 个不同尺度特征图上分别使用3 个不同的先验框进行预测识别,使得远近大小目标均能被准确检测[16]。
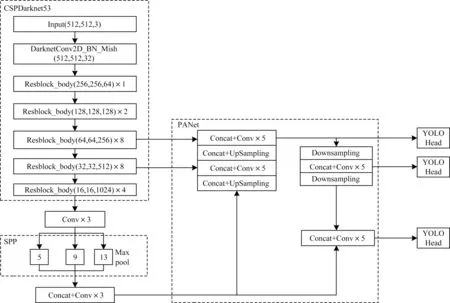
图2 YOLOv4 网络结构模型Fig.2 YOLOv4 network structure model
YOLOv4 的先验框尺寸是考虑PASCALL_VOC、COCO 数据集包含的复杂种类而生成的,并不一定完全适合行人。由于本文旨在研究行人之间的社交距离,因此针对行人目标检测,利用聚类算法对YOLOv4 的先验框进行微调[17]。
首先,将行人数据集F依据相似性分为i个对象,即F={f1,f2,…,fi},其中每个对象都具有m个维度的属性。聚类算法的目的是将i个对象依据相似性聚集到指定的j个类簇,每个对象属于且仅属于一个距离最近的类簇中心。初始化j个聚类中心C={c1,c2,…,cj},计算每个对象到每个聚类中心的欧式距离,如式(1)所示:
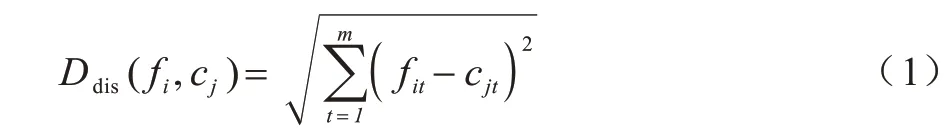
其中:fi表示第i个对象;cj表示第j个聚类中心;fit表示第i个对象的第t个属性;cjt表示第j个聚类中心的第t个属性。
然后,依次比较每个对象到每个聚类中心的距离,将对象分配至距离最近的簇类中心的类簇中,得到l个类簇S={s1,s2,…,sl}。聚类算法中定义了类簇的原型,类簇中心就是类簇内所有对象在各个维度的均值,计算公式如式(2)所示:

其中:sl表示第l个类簇中的对象个数。
本文针对先验框的微调通过Python 语言实现,微调后的先验框更注重对行人的检测。
1.3 基于DeepSort 算法的行人跟踪
YOLOv4 完成行人目标检测后生成边界框(Bounding box,Bbox),Bbox 含有包含最小化行人边框矩形的坐标信息。本文引入DeepSort 算法[18]完成对行人的质点跟踪,目的是为了在运动矢量分析时计算行人的安全社交距离。
首先,对行人进行质点化计算。质点位置计算公式如式(3)所示:

其中:xcenter、ycenter分别为质点的横纵坐标;xtop_left、ytop_left分别表示边界框左上角的横纵坐标;xlower_right、ylower_right分别表示界框右下角的横纵坐标。
在确定行人质点位置后,利用DeepSort 算法实现对多个目标的精确定位与跟踪,核心算法流程如图3 所示。
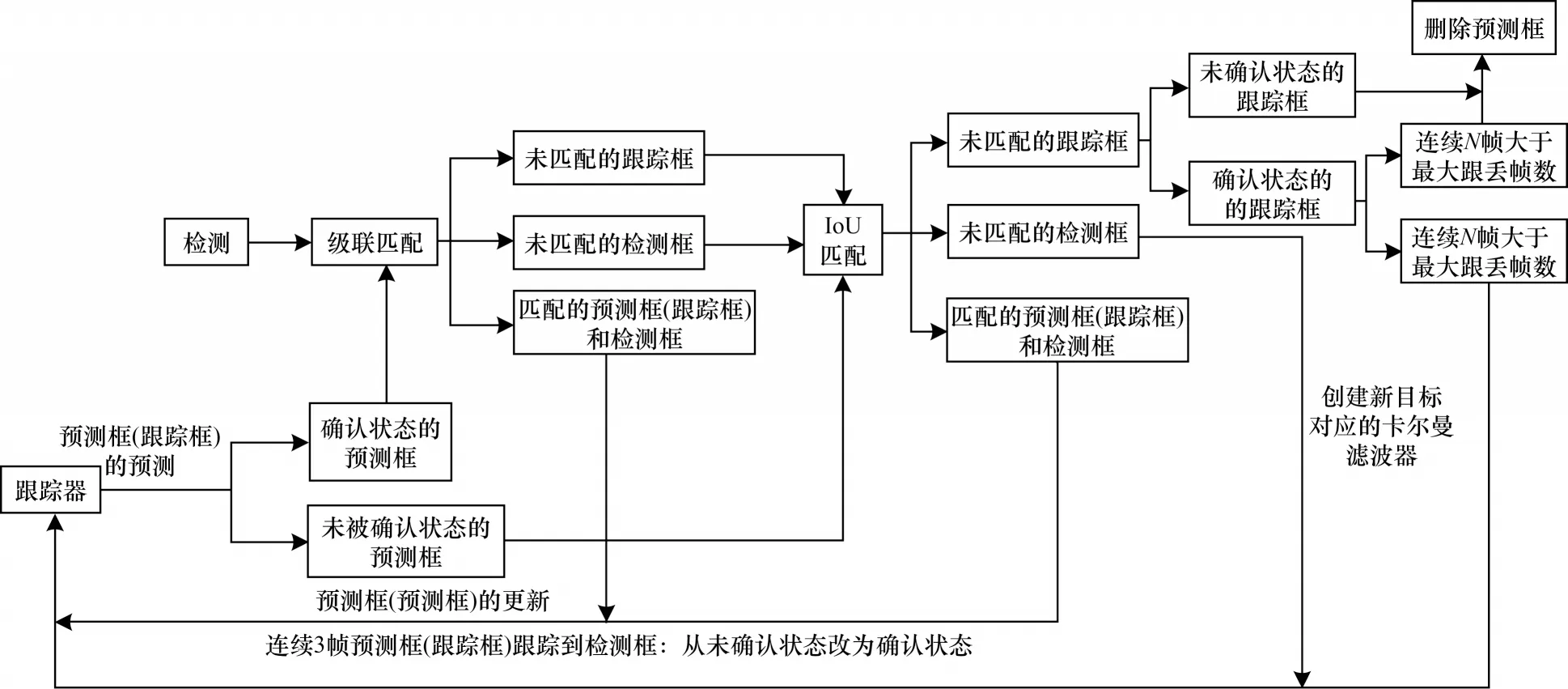
图3 DeepSort 核心算法流程Fig.3 Procedure of DeepSort core algorithm
DeepSort 算法在Sort 算法[19]的基础上增加了级联匹配和新轨迹的确认步骤。首先利用卡尔曼滤波器算法[20]预测行人轨迹Tracks,然后使用匈牙利算法将预测得到的行人轨迹Tracks 和当前帧中检测到的行人进行匹配(级联匹配和IoU 匹配),最后通过卡尔曼滤波进行更新。具体计算公式如下:
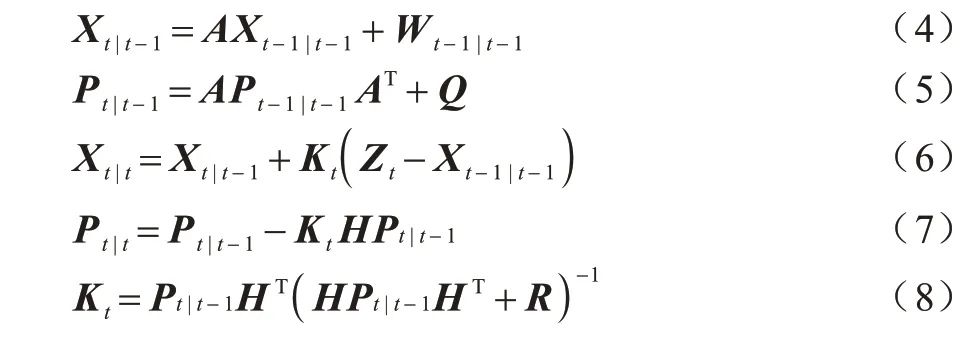
其中:行人质点坐标(x,y)表示为当前状态Xt|t;Xt-1|t-1为上一时刻目标状态;Xt|t-1为上一时刻预测出当前时刻的目标状态;实际检测到的行人质心坐标表示为观测状态Zt;Pt|t-1为当前时刻估计误差协方差;Pt-1|t-1为上一时刻估计误差协方差;Pt|t-1为上一时刻预测出当前时刻的估计误差协方差;A为状态转移矩阵;H为观测矩阵;Kt为卡尔曼滤波的增益矩阵;Wt-1|t-1为上一时刻的激励噪声;Q、R分别为激励噪声和观测声的协方差矩阵。
至此,完成了对行人目标的检测和跟踪。在此基础上,本文按照目前国内疫情情况和政策指导[21]提出运动矢量分析算法,目的在于针对同向行人监控安全距离,避免行人长时间处于非安全的社交距离。
1.4 运动矢量分析算法
三维世界投影至二维透视平面导致对象之间的距离存在不切实际的像素距离,即透视效应。在三维空间中,原始的三个参数(x,y,z)在相机的接收图像中压缩为二维(x,y),深度参数(z)不可用,而在低维空间中,使用欧几里得距离的计算准则进行行人距离估计是错误的。为了应用校准的逆透视变换(Inverse Perspective Mapping,IPM),首先需要设置z=0 来进行相机校准以消除透视效应,此外,需要知道相机的位置、高度、视角以及光学规格[22],以最终确定鸟瞰图下行人的坐标信息[23],从而进一步执行矢量分析算法确定安全距离。可通过OpenCV 库中的“getPerspectiveTransform”方法计算变换矩阵[24]。通过应用IPM,使世界坐标点(XW,YW,ZW)映射为二维像素点(u,v),计算公式如式(9)所示:
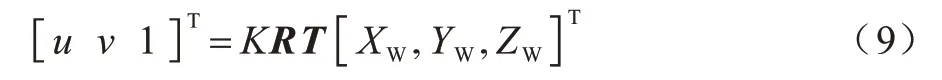
其中:K为相机的固有参数;R为旋转矩阵;T为平移矩阵。
使用齐次坐标,考虑到相机图像平面垂直于世界坐标系中的Z通道(即Z=0),三维点与投影结果图像之间的关系可以表示为:

其中:ni j∈N(N∈R3×4)是变换矩阵,其通过固有矩阵K、旋转矩阵R和平移矩阵T提供。
最终,从透视空间转移到反向透视空间也可以用以下标量形式表示以确定二维坐标:
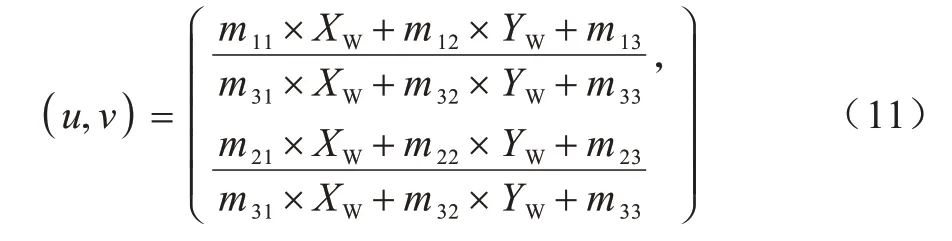
本文提出行人运动矢量分析算法旨在检测同向行人的安全距离。经计算机视觉处理后,依据相机信息得到行人在鸟瞰图下的坐标信息lk=(uk,vk),同理可得行人在k-1 时刻的全局位置坐标lk-1=(uk-1,vk-1)。定义行人的运动矢量为MP,如式(12)所示:
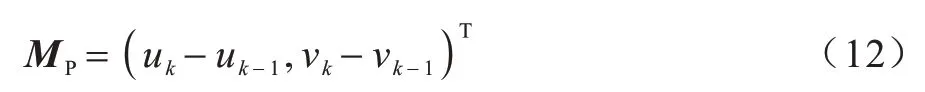
为了获取当前时刻的运动矢量,设当前时刻的行人位置为lk-1,下一帧行人预测区域的中心位置为lk,由此得到的行人运动矢量如图4 所示。
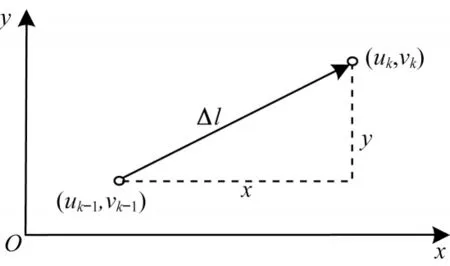
图4 行人运动矢量Fig.4 Pedestrian motion vector
在图4 中,Δl的大小即为向量MP的模,物理意义为行人在两个时刻间的移动距离。由于连续两帧图像间的时间间隔很短,因此本文将行人移动的平均移动速率作为当前时刻的行人运动速率vP,其方向即为沿着Δl的方向,夹角θ表示行人相对于自身当前位置的移动方向,由此可以得到速率vP在x轴和y轴方向的投影值,分别为vxk和vyk。至此,可以连续得到行人在当前时刻的移动速率大小以及行人相对于当前位置的移动方向,可用语言描述为行人在(uk,vK)位置以速率vP沿着与x轴呈θ角的射线方向移动。
设定一个行人间安全社交距离的阈值dP,对于安全社交距离的识别,判断公式如下:

其中:i、j为整数;Vpipj为行人i与行人j之间的位置向量;参数dP取值为1,小于阈值表示行人间距离小于1 m,为非安全社交距离。在安全社交距离风险评估算法中,对每个行人,以当前的空间位置坐标为圆心、dP为半径的范围内进行搜索,其运算复杂度与for 的循环控制变量呈一次线性关系,即O(n)。如果含有行人,则再对行人的运动矢量进行分析。成群行走的行人通常具有相似的移动方向和相近的移动速率,运动矢量判断的计算公式如下:
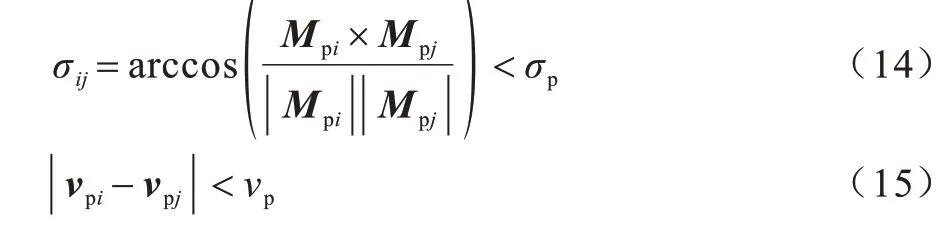
其中:i、j为整数;σij为行人i与行人j运动矢量的夹角;设定一个阈值σp为π18,小于阈值表示行人间具有相同的移动方向。
2 实验结果及分析
本文实验的软件环境使用Ubuntu 16.04 LTS 操作系统及Pytorch 深度学习框架。在硬件配置中,CPU 使用英特尔酷睿i7-7900X,GPU 使用英伟达GTX Titan X 16 GB 显存。
2.1 实验数据集
实验使用Caltech 行人数据库[25]和戴姆勒行人检测标准数据库[26]这两个采用车载摄像头的公开数据集,将“person”子集作为YOLOv4 行人检测模型的训练集,在标准通用测试集Oxford Town Centre Dataset 上进行验证检测。
Caltech行人数据库是目前规模较大的行人数据库,包含10 h 左右的视频,视频的分辨率为640×480 像素,30 frame/s。标注约250 000 帧,总计时长约为137 min,对350 000 个矩形框和2 300 个行人进行标注,此外,还对矩形框之间的时间对应关系及遮挡的情况进行标注。Caltech 数据库图像示例如图5 所示。

图5 Caltech 行人数据库图像示例Fig.5 Example of image in Caltech pedestrian database
戴姆勒行人检测标准数据库分为检测和分类两个数据集。其中:正样本包含18×36 像素和48×96 像素的图片15 560 张,行人的最小高度为72 个像素;负样本共计6 744 张,分辩率为640×480 像素或者360×288 像素。测试集为一段27 min 左右的视频,分辨率为640×480 像素,共计21 790 张图片,包含56 492 个行人。分类数据库有3 个训练集和2 个测试集,每个数据集有4 800 张行人图片和5 000 张非行人图片,另外还有3 个辅助的非行人图片集,各有1 200 张图片。戴姆勒行人检测标准数据库图像示例如图6 所示。

图6 戴姆勒行人检测标准数据库图像示例Fig.6 Example of image in Daimler pedestrian detection standard database
2.2 检测跟踪实验
重新设计锚点框,采用K-means 聚类算法对数据集进行维度聚类,得到大、中、小3种尺度共计9个锚框,大小分别为(320,180)、(200,136)、(155,81)、(103,55)、(69,44)、(63,140)、(46,33)、(28,26)、(25,63)。依次分配大、中、小的检测单元,之后对网络进行训练,采用SGD 优化器,初始学习率0.000 1,衰竭系数0.000 5,批大小设置为16,其余参数为默认参数,经过2 500 次迭代后进行测试,丢失率接近10%。对YOLOv4 模型进行微调后,在NVIDIA Geforce GTX TITAN 上分别运行微调后YOLOv4 算法和原YOLOv4 算法,检测结果如图7 和图8 所示。

图7 微调后YOLOv4 算法的行人检测结果Fig.7 Pedestrian detection result of fine-tuned YOLOv4 algorithm

图8 原YOLOv4 算法的行人检测结果Fig.8 Pedestrian detection result of original YOLOv4 algorithm
在图7、图8 中,行人年龄分布方面包含小孩、年轻人和老人,状态方面包括骑自行车的人、被部分建筑物遮挡的人、推婴儿车的人等各类行人。YOLOv4 在检测婴儿以及被遮挡的行人方面效果不佳,如图8 中被遮挡的行人、婴儿和特征相似的行人存在较高的漏检率。但是微调后的YOLOv4 算法在检测遮挡的行人以及婴儿等目标时可获得良好的效果,并且有较强的置信度,同时误检和漏检情况较少。
为检验微调后YOLOv4 在检测数据集上的检测效果,将其与Fast R-CNN、Faster R-CNN、SDD、YOLOv3等算法进行对比,以平均精度均值(mean Average Precision,mAP)和帧率(FPS)作为评价指标。mAP 的值越高,说明算法对目标的检测效果越好;FPS 越高,代表每秒输出的画面越多,说明实时检测效果越好。实验结果如表1 所示,从中可以看出:微调后YOLOv4相较于其他算法mAP 值和FPS 有所提高,为之后的社交距离风险评估提供了保障;由于本文采用是YOLO系列算法,参数量和FLOPS 均大幅降低,因此提升了速度。
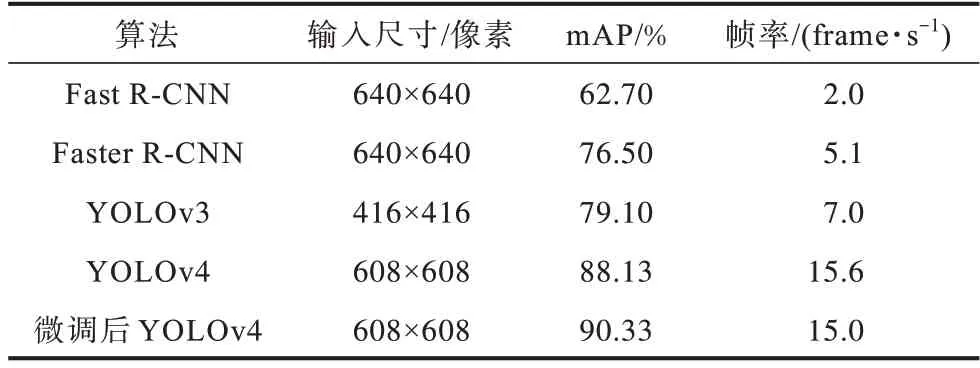
表1 微调后YOLOv4 算法与其他算法的性能对比Table 1 Performance comparison of fine-tuned YOLOv4 algorithm with other algorithms
在完成对视域内行人的检测后,通过筛选出特征点将人抽象为质点,利用DeepSort算法中的卡尔曼滤波和匈牙利算法即可得到该行人的移动路径。微调后YOLOv4 与原YOLOv4 算法的行人跟踪结果分别如图9 和图10 所示。实验结果表明,原YOLOv4算法对于行人的跟踪有较强的鲁棒性,但是对婴儿等小目标的识别存在一定的漏检率,而微调后YOLOv4 算法在小目标识别方面性能得到了大幅提升,提高了小目标的检测效果。

图9 微调后YOLOv4 算法的行人目标跟踪结果Fig.9 Pedestrian target tracking result of fine-tuned YOLOv4 algorithm

图10 原YOLOv4 算法的行人目标跟踪结果Fig.10 Pedestrian target tracking result of original YOLOv4 algorithm
2.3 运动矢量分析及安全距离评估
在逆变换空间,利用线性距离表示每个人的位置,依据视域内各行人运动矢量间的关系对行人进行安全距离评估,最终算法结果如图11 所示,嵌入式系统将识别出违反安全社交距离的行人并用直线进行连接以作警示。

图11 安全距离检测评估结果Fig.11 Safety distance detection and evaluation result
针对图11 中标记部分,在不同时间段内对两人至多人的行人行走状态进行判断分析。可以看出:在行人密度正常的情况下,本文算法具有一定的可行性。图11(a)、图11(b)结果表明,两人安全距离检测评估判断具有较高的准确性;图11(c)结果表明,由于行人群体在前几秒有相似的位移和速度,因此将其归为违反安全社交距离人群的一部分,在之后的判断中根据算法结果将其排出被选范围;图11(d)结果表明,在长椅的遮挡下,本文算法在噪音处理后以及背景与行人较为相似的状态下存在漏检,但对于其他情况具有一定的可实施性。最终利用OpenCV绘制成鸟瞰图,如图12所示,在虚线框图中,利用鸟瞰图对行人质点进行连线警示。

图12 测试集的鸟瞰图Fig.12 Aerial view of the test set
采用人工安全社交距离标定,将违反安全距离规定的人群视为“群组”,统计前1 000 帧的行人总数、实际群组和判断群组绘出三维统计图,如图13所示。可以看出,本文算法的“群组”识别准确率达到88.23%,视频的帧率为15 frame/s,可满足校园、工厂等封闭环境的防疫需求。
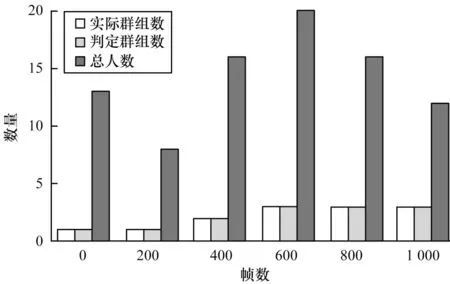
图13 每帧的总人数及群组的判断Fig.13 Judgment of total number of people and groups per frame
3 结束语
本文结合目前COVID-19 疫情状态,在文献[8]方法的基础上进行改进,利用鸟瞰视角开发一个基于CNN 的深度社交距离监控模型,结合CSPDarknet53主干网络、SPP 空间金字塔池化层以及PANet 颈部、Mish 激活函数和聚类算法构建行人检测网络框架,基于DeepSort 算法进行行人跟踪,最后提出运动矢量算法并利用OpenCV 库函数构建鸟瞰图。实验结果表明,该算法能够实现对社交距离风险的有效评估,可满足校园、广场、工厂等环境的防疫需求。后续将对YOLOv4 在智能移动平台上的部署做进一步优化,提高图像的像素大小、mAP 和帧率,同时减少视频流传输过程中的视频帧损失。
猜你喜欢
中学生数理化·高一版(2021年11期)2021-09-05 12:21:24
意林(2021年5期)2021-04-18 12:21:17
扬子江(2019年1期)2019-03-08 02:52:34
电子测试(2017年15期)2017-12-18 07:19:27
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
现代防御技术(2016年1期)2016-06-01 12:13:28
新高考·高一物理(2016年1期)2016-03-05 22:47:39
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
