
时间特征互补的无监督视频行人重识别
2022-10-16 12:28王福银韩华黄丽陈益平
计算机工程 2022年10期
王福银,韩华,黄丽,陈益平
(上海工程技术大学电子电气工程学院,上海 201620)
0 概述
随着科学技术的进步,视频行人重识别在人们生活中越来越重要,旨在从非重叠视觉域多摄像头下检索特定的行人,同时在与监控相关的应用中起到较大辅助作用。近年来,随着大型视频基准的出现和计算资源的增长,视频行人重识别受到研究人员的极大关注[1]。与基于图像的行人重识别数据相比,视频数据包含了丰富的空间信息和时间线索,有利于缓解基于外观特征的局限性。在视频行人重识别的技术研究方面,主要有基于图像集的方法和基于时间序列的方法[2]。基于图像集的方法将视频视为一组无序图像,独立地提取每帧的特征,使用特定的时间池化策略来聚合帧级别的特征,但这种方法缺乏对视频时间关系的建模[3-4]。
在视频片段特征提取方面,常用的方法是利用强大的深度网络和大规模标记基准使视频行人重识别获得较高的性能和效率,如通过循环层和时间注意层。尽管视频行人重识别取得了明显进步,但大多数现有方法仍未充分利用视频中丰富的时空线索[5-7]。具体而言,由于视频的行人帧非常相似,并且现有方法在每帧上执行相同的操作,因此这些方法通常会使视频帧产生高度冗余的特征,而多余的特征通常出现在相同的局部突出部分上,导致很难区分外观相似的行人,并且增加损失函数的计算量[8-10]。在无监督自适应研究方面,利用生成式对抗网络(Generative Adversarial Networks,GAN)将源域图像的风格转换为目标域的风格,保持标签不变,然后对生成的标签图像进行训练,虽然源域与目标域的数据进行交换产生许多可靠的数据,但高度依靠生成图像的质量[11]。而最近在无监督领域提出无监督的自底向上聚类(Bottom-Up Clustering,BUC)方法不使用人工标记的数据集,取得了较好的识别效果,然而在聚类合并时BUC 无法解决在样本相似度较高的情况下伪标签所带来的无法优化模型的问题[12]。
本文提出一种时间特征互补的无监督视频行人重识别方法。通过设计时间特征擦除网络模块,根据视频帧与帧之间的时间关系与每帧的空间信息进行图像特征的擦除提取,利用加入多样性约束和离散度参数的层次聚类算法提高生成的伪标签质量,并运用PK 抽样困难样本三元组方法对模型进行更新训练,以降低不同身份相似样本聚集的概率。
1 本文方法
本文无监督视频行人重识别方法的整体框架流程如图1 所示。首先将无标签的视频序列输入网络,利用时间特征擦除方法提取视频特征,然后利用约束性无监督层次聚类,对提取的样本特征进行从底向上的离散度分层聚类,生成高质量的伪标签,最后通过PK 抽样法产生新数据,困难样本三元组对其重新训练,微调模型,更新聚类信息。

图1 本文方法整体框架流程Fig.1 Procedure of overall framework of this method
1.1 时间特征擦除模块
视频帧与帧之间包含着丰富的时间和空间信息,充分利用这些信息可以实现更可靠的特征表示。但是,大多数现有方法在每帧上执行相同的操作,导致不同帧的特征高度冗余,仅突出在局部,并且多余的特征很大程度上使损失函数计算量增加。为此,本文设计如图2所示的时间特征擦除模块(TFE),目的是从视频的连续帧中挖掘互补特征部分,以形成目标行人的整体特征。如图2(a)所示,特征擦除模块对每个帧迭代执行两个操作:1)使用擦除操作(Erasing Operation,EO)对抗性擦除先前帧发现的部分;2)利用特定的学习器发现新的显著部分以提取互补特征。输入的视频段是经CNN Backbone网络后的一组帧级特征图其中:视频段包含N个连续帧;n是视频帧的索引;H、W和D分别表示特征图的高度、宽度和通道号。首先TFE使用学习者L1发现第一帧最显著的区域,然后对整体帧的全局平均池化(Global Average Pooling,GAP)层求平均,提取I1的最显著特征,表示为:

图2 时间特征擦除模块Fig.2 Temporal feature erasing module

在帧I2中利用EO 删除特征图F2的f1挖掘判别部分,将删除的特征图馈送到学习者L2中。由于学习者L1所参与的部分已被删除,因此学习者L2自然被驱动发现新的显著部分,以识别目标行人最新判别特征。递归地,对于帧In的特征图Fn(n>1),时间特征擦除模块首先应用EO 擦除先前帧发现的所有部分,以形成擦除的特征图,然后使用特定的学习者LN挖掘新的特征部分并获得特征向量fn,表示为:

显著性擦除操作和学习者对输入视频段的N个连续帧重复执行,最后聚合每次得到的擦除特征,得到整个目标行人的特征。
擦除操作主要包括以下3 个部分:
1)擦除操作相关层。式(2)的实现如图2(b)所示,对于要擦除帧In的特征图Fn,需要设计擦除操作的相关层以获得前一帧特征向量fk(k<n)与Fn之间的相关图。首先计算出Fn的每个空间位置(i,j)的特征向量记作。然后相关层通过点运算符相似性计算fk与Fn的所有局部描述符之间的语义相关性,以得到相应的相关图Rnk∈ℝH×W,表示为:

2)擦除操作二值化层。该层将相关图生成二进制掩码以标识要擦除的区域。目前最好的方法是在相关图上进行阈值处理,但这通常会产生不连续的区域,由于卷积特征单元在空间上是连续的,因此当不连续地擦除特征单元时,被擦除单元的信息仍有少部分可以被传送到下一层[13]。因此,本文设计一个块二值化层来生成擦除特征图连续区域的二进制掩码。如图2(b)所示,本文使用滑块搜索标记相关图中最突出的连续区域。在大小为H×W的相关图上使用大小为he×we的滑动块,当分别移动水平步幅sw和垂直步幅sh时,块位置总数计算的公式如式(4)所示:
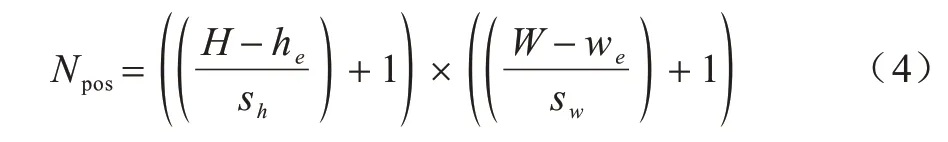
经过式(4)的计算可以为每个相关图获得Npos个候选块。此外,定义一个块的相关值为该块各项的相关值之和,选择具有最高相关值的候选块作为要擦除的块,即:相关图Rnk的二进制掩码Bnk∈ℝH×W是通过将所选块中的单位值设为0,其他单位值设为1而生成的。然后将掩码合并融合为掩码Bn用于特征映射Fn,计算表达式为:

其中:⊙是逐元素乘积运算。
3)时间特征擦除操作。本文采用门控机制来擦除特征图Fn,特别地,将softmax 层应用到融合相关图中,以获得门图Gn∈ℝH×W,表示为:

基于Bn和Gn擦除特征图Fn,生成擦除后的特征图同时为了一致性,本文也对F1进行填充为1的二进制掩码擦除操作,这样可以使梯度传播到EO参数w中,并且时间特征擦除也可以进行反向传播训练。
1.2 约束层次聚类
为了生成高质量的伪标签,监督目标数据集模型训练,本文采用一种从底向上的层次聚类方法。该方法通过加入约束性条件计算类内与类间的距离,之后将相距最近的两类合并,建立一个新类,重复此操作直到满足停止条件,以提高聚类的准确性。
1)类内之间的距离计算。类内之间的距离反映的是类与类之间的离散程度,定义一个类为C,类内平均样本离散度表示为:

其中:n表示为类别C的样本个数;D(·)表示欧氏距离。在类内计算类与类之间的距离时,距离数值较小的两个类被优先合并在一起,该计算方法起到防止类与类之间聚类离散度过高,同时提高层次聚类的作用。
2)类与类之间的距离计算。类与类之间的距离越小,表示两个类之间的离散度越小,则被聚合在一起的概率越大。针对类间的差异性,类间离散度表示为:

其中:Ca与Cb分别表示两种类别;na和nb为两个类别的个数;为类Ca的样本;为类Cb的样本。
3)类内间离散度聚类计算。该聚类表达式为:

其中:dab表示类Ca和Cb之间的距离;α1为计算类与类之间距离时的离散度参数因子;da和db分别为Ca类中类与类之间的距离和Cb类中类与类之间的距离。在聚类过程中,相同身份的特征在特征空间中的距离较近,类别被聚合在一起的概率较大。
随着层次聚类的迭代,数据中的类别数不断变少,类内的样本数量变多。虽然对于每个类别的样本数量不清楚,但可以假设样本数量平均分布在每个类别中,因此达到每个类别的样本数量差别不会太多,这称为多样性。而本文引入多样性参数起到降低极度相似样本被合并在一起的概率,表示为:

其中:|a|为类Ca的样本数量;|b|为类Cb的样本数量。
当一些类与类之间的距离差别不明显时,引入多样性参数因子,使其起到先合并样本数量少的类,其次合并样本数量多的类的作用,因此最终的类内间距离表达式为:

其中:α2为多样性约束参数因子。
1.3 损失函数
本文使用PK 抽样困难样本三元组挖掘正样本锚和负样本锚之间的关系,拉近正样本与正样本之间的距离,增加负样本与负样本之间的距离。在训练过程中,本文从一个批次中随机抽取P个行人身份,然后从每个行人身份中抽取K个视频片段。因此,每个批次中包含P×K个片段,损失函数定义为:

1.4 模型更新
如算法1 所示,本文模型在ResNet50 网络上迭代训练。对于每个迭代,在分层聚类开始时,本文将N个样本视为N个不同的身份,并初始化所有伪标签。设置超参数mp来控制合并速度,设置s为分层聚类的总合并步骤,m=n×mp表示每个步骤中合并的聚类数。根据式(11)生成c×c距离矩阵D,c表示当前簇数。在每个步骤中合并m对最近的簇类,直到第s步,并根据聚类结果生成伪标签。然后,使用PK 抽样生成一个新的数据集作为时间特征擦除网络的输入。通过新数据集进行微调训练,评估模型性能。本文将分层聚类、PK 抽样、微调训练和模型评估进行不断迭代,直到性能不再改善。
算法1模型更新算法


2 实验结果与分析
2.1 数据集设置与评价指标
本文方法是在两个数据集上进行实验和评估,其数据集的具体设置如表1 所示。

表1 视频数据集信息Table 1 Statistics of video datasets
本文使用累积匹配特性(Cumulative Match Characteristic,CMC)作为Rank-k 的概率曲线,表示为检索精度值的前k个数值正确匹配概率。CCMC的表达式为:

其中:在匹配候选集中有N个行人;k为前k个候选目标;pi为要查找的目标行人在匹配候选集中的位置序号。
平均精度(Average Precision,AP)是对单个类别的精度计算,平均精度均值(mean Average Precision,mAP)是预测目标位置以及类别的性能度量标准,为所有类别精度的平均值,表达式分别为:

其中:i为图像要查询的序号;p(i)为图像序号在视频序列图像中的比例;r(i)表示每帧视频序列的图像是否与要搜索的目标图像匹配,如果匹配则取值为1,不匹配则取值为0;g表示目标视频序列中需要进行匹配的序列数;Q为数据集中视频序列数。
2.2 实验方法
在本文实验中,实验平台采用Ubuntu16.04 操作系统,NVIDIA RTX3090 显卡的硬件环境。实验网络采用在ImageNet 上预训练好的ResNet50 模型作为网络骨干,并加入时间特征擦除模块对视频序列进行特征提取[14-15]。使用PyTorch 框架实现,在训练时,从每个视频序列中随机采样4 帧作为输入,并将每帧的大小调整为256×128,同时仅采用随机翻转进行数据扩充。最初学习速率为0.000 3,每经过15 个周期衰减因子为0.1,Adam优化器的最小批量大小为32,用于150个epoch的训练。在合并聚类期间合并参数mp为0.05,式(11)中α1为0.06,α2为0.002。
2.3 时间特征擦除模块有效性分析
本文在MARS 数据集上进行一系列研究来验证时间特征擦除模块的有效性,ResNet50 上用时间平均池作为基线[16]。在ResNet50 有4 个连续的阶段组成[17]:即阶段1~阶段4,每个阶段分别包含3、4、6、3个残差块。本文将前3 个阶段作为主干网络,TFE 可以插入主干网络的任何阶段。而对于时间特征擦除模块的实验验证,本文对所有模型只采用自底向上的层次聚类和三元组损失进行训练,不加入离散度和多样性约束参数及PK抽样法。
1)首先用TFE(base.+TFE)替换基线层来评估TFE 模块的效果。如表2 所示,与基线相比,采用TFE 模块使mAP、Rank-1 分别提高了2.9、1.4 个百分点,这是由于TFE 的学习者协同擦除功能挖掘特征互补部分,从而生成目标行人的整体特征,使模型对具有相似特征的不同行人获得更强的识别能力。为了进一步验证TFE 中的擦除操作提取特征的有效性,本文设计了一种变体,即TFE-wo-EO,采用增加大量的有序学习者,而不进行擦除操作。TFE-wo-EO相对于基线仅取得了很小的改进效果,表明在不进行擦除操作的情况下,不同的学习者捕获的视觉特征几乎相同,可以得出擦除操作的强大功能,迫使不同的学习者专注于不同的图像部分,以发现不可或缺的视觉特征,而不在于学习者数量的增加。

表2 MARS 上不同设置的性能比较Table 2 Performance comparison of different settings on MARS
2)在TFE 模块中学习者的数量不断增加或减少都对本文所提模型产生影响,如表3 所示。TFE 包含N个有序学习者,其中N=1 为基线,它们为N个连续帧挖掘互补特征。随着增加更多的学习者去挖掘互补特征,模型的性能会提高,但是当N达到4时性能会大幅下降。在这种情况下,大多数判别部分已在输入段的最后一帧中删除,第4 学习者必须激活非区别区域,这会破环背景区域。考虑到模型的复杂度,本文将N设置为2。

表3 MARS 中学习者数量对TFE 参数的影响Table 3 Impact of number of learners on TFE parameters in MARS
3)擦除块的大小改变也会影响模型的性能,如表4 所示。本文TFE 模块处理尺寸为16×18 的帧级特征图,由于行人图像的空间结构不同,本文将擦除后的宽度固定为特征图的宽度,以擦除特征图的整个行。可以看出,当擦除块高度he为3 时模型的性能最佳,而当擦除块的高度较大或较小时,性能都会变差。因此,擦除块太小不能有效激励当前学习者发现特征互补部分;擦除块太大会迫使当前学习者激活如背景等非区别区域。

表4 MARS 中擦除块高度对TFE 参数的影响Table 4 Impact of erasing block height on TFE parameter in MARS
4)对于复杂度方面的比较,本文除了对在MARS数据集上所提出的网络进行成分分析外,还对输入的视频片段的浮点运算数量(GFLOPs)及模型的参数数量(Params)进行了分析对比。FLOPs 表示训练模型时GPU 的计算量(1GFPLOs=109FLOPs),用来衡量模型的复杂度(时间长短)。参数数量为网络模型中需要训练的参数总数(显存大小)。模型中浮点运算和参数数量采用python 的第三方库thop 中的profile()方法进行计算。
从表2 可以得出,在基线上对数据集进行测试时需要14.144 的GFLOPs,而在TFE(base.+TFE)上进行测试时需要14.149 的GFLOPs,与原始模型(基准)相比仅相对增加了0.005GFLOPs。而增加的成本主要是由TFE 的相关图所造成的,不过这种问题可以通过矩阵乘法进行解决,因此,在运算时占用GPU 的时间很少。在参数数量方面,TFE 相对基线参数数量增加了6.4×106,占用显存的增加主要是由TFE 的一系列有序学习者所造成的。重要的是仅通过使用一系列学习器来扩展基线所带来模型准确率上的提高,表明TFE 的改进不仅仅是因为增加了参数设置。
2.4 约束性层次聚类有效性分析
如表5 所示,分别为加入类内间离散度参数和多样性约束参数以及两者结合对模型结果所带来的影响。在模型中仅考虑类间离散度时(基准),MARS 和DukeMTMC-VideoReID 上的Rank-1 分别为66.9%和75.9%,mAP 分别为44.3%和68.7%。加入类内离散度后,Rank-1 在MARS 和DukeMTMC-VideoReID 上分别提升了0.9 和0.6 个百分点,起到了防止高离散度类被聚合的作用,保证了类别平衡。加入多样性约束后Rank-1分别达到了69.3%和80.5%,mAP 分别达到了46.4%和72.5%。表明在模型中加入类内间离散度参数和多样性约束参数能够提高层次聚类的准确性以及提升图像匹配的准确率。

表5 在MARS 和DukeMTMC-VideoReID 上不同设置的性能比较Table 5 Performance comparison of different settings on MARS and DukeMTMC-VideoReID %
本文对整个迭代过程进行对比分析。如图3 所示,在两个数据集上进行聚类迭代实验,Rank-1 和mAP 的性能百分数随着迭代次数的增加不断增加,但迭代次数达到一定程度时,两个性能指标趋于稳定,同时数据集的类别数目越来越少,最后得出数据集的伪标签。

图3 在MARS 和DukeMTMC-VideoReID 上Rank-1 和mAP 随聚类迭代次数的变化Fig.3 Change of Rank-1 and mAP with the number of clustering iterations on MARS and DukeMTMC-VideoReID
2.5 参数分析
本文对类内间平衡参数α1和多样性约束参数α2进行了实验分析。如图4 所示,在式(11)中保持α2值不变,改变α1的值,计算性能指标的数值。当α1=0.06 时,图4 上纵轴上的指标取得最大值,而随着实验不断进行,横轴上的取值过大或过小,纵轴上的值都会下降。在图5 中,类内间平衡参数α1设置为0.06,对α2取不同的值。从图5 可以看出,当α2=0.002 时效果最好。在MARS 数据集上Rank-1 精度提升到了69.3%,mAP 提升到了46.4%;在DukeMTMC-VideoReID 上随着参数的数值改变,Rank-1 的精度提升到了80.5%,mAP 提升到了72.5%。在实验中α2的值无论小于或大于0.002,性能指标的取值都会下降,因此α2的取值为0.002。

图4 Rank-1 和mAP随α1的不同取值在MARS 和DukeMTMC-VideoReID 上的变化Fig.4 Change of Rank-1 and mAP with different values of α1 on MARS and DukeMTMC-VideoReID

图5 Rank-1 和mAP随α2的不同取值在MARS 和DukeMTMC-VideoReID 上的变化Fig.5 Change of Rank-1 and mAP with different values of α2 on MARS and DukeMTMC-VideoReID
2.6 不同方法的对比
如表6 所示,本文方法在MARS 数据集和DukeMTMC-VideoReID 数据集上实验得出的结果与利用目前最新方法得出的结果进行比较,可以看出,本文方法具有较大的优越性。
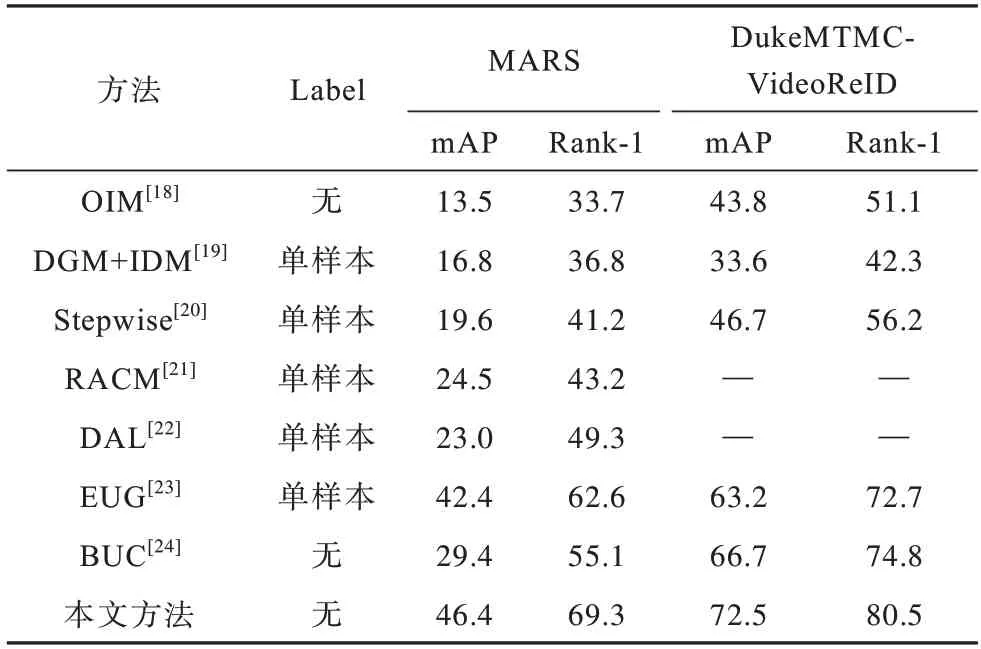
表6 不同方法性能比较Table 6 Performance comparison of different methods %
在表6 中,第2 列显示“单样本”的标签为训练模型时一部分数据采用身份伪标签,不是真正的完全无监督,而在其列中显示“无”的标签,为完全无监督。对MARS 数据集上的实验结果与利用传统方法RACM 和DAL 得出的实验结果进行比较,可以看出,本文方法Rank-1 分别提高26.1%和20%,mAP 分别提高21.9%和23.4%;与完全无监督BUC 进行比较,Rank-1 和mAP 分别提高14.2%、15%;与单样本的深度学习方法EUG 相比,本文方法也具有很大的竞争力。在数据集DukeMTMC-VideoReID 上的实验结果与利用BUC 方法得出的实验结果进行比较,本文方法Rank-1 和mAP分别提高5.7%、5.8%,与利用EUG 方法得出的结果进行比较,Rank-1 和mAP 分别提高7.8%、9.3%。
3 结束语
本文通过研究视频行人重识别的每帧特征提取和标签,提出一种时间特征互补的无监督视频行人重识别方法。使用时间特征擦除网络模块提取具有强力的判别性特征,解决特征的冗余问题,减少后续类别分类的计算量,在层次聚类进行合并时加入离散度参数因子和多样性参数因子,生成高质量的伪标签,解决手工标签带来的巨大代价问题,并通过PK 抽样困难样本三元组损失优化模型,减少不同身份的相似样本被合并的概率。实验结果表明,与RACM 和DAL 等方法相比,本文方法性能指标得到较大提升。下一步将改进时间特征提取建模方法,消除噪声帧的影响,以获得更强的特征表示,并继续研究无监督算法在数据标签上的应用。
猜你喜欢
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
舰船电子对抗(2017年6期)2018-01-11
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
互联网天地(2016年1期)2016-05-04
