
基于新型算子采样优化的交通标志检测网络
2022-10-16 12:28陈春辉马社祥
计算机工程 2022年10期
陈春辉,马社祥
(天津理工大学 集成电路科学与工程学院,天津 300384)
0 概述
交通标志识别是智能交通系统中的重要组成部分。无论是自动驾驶系统还是辅助驾驶系统,交通标志识别为驾驶员提供必要的路况信息、方向指示、交通预警,以确保行车安全。但是,在实际行车环境中,道路情况千变万化。因此,如何在复杂环境下高效、精确地识别小目标、模糊目标及遮挡目标对于交通标志识别具有重要意义[1-3]。
近年来,深度学习飞速发展。卷积算子是组成现代神经网络的核心。由卷积算子构成的卷积神经网络(Convolutional Neural Network,CNN)在目标检测领域中取得显著进展。检测网络主要分为一阶段检测器和两阶段检测器。一阶段检测器直接回归物体的类别概率和位置信息,具有检测速度快、准确率低的特点,代表性算法有YOLO[4]、SSD[5]、YOLOv2[6]、RetinaNet[7]、YOLOv3[8]等。两阶段检测器需要先进行候选区域算法,再通过网络进行分类,与一阶段检测器相比速度较慢,但是准确率较高,代表性算法有SPPNet[9]、RCNN[10]、Fast R-CNN[11]、Faster R-CNN[12]等。
传统机器学习根据颜色和形状的区别进行交通标志检测[13-15]。与传统机器学习方法相比,深度学习在检测交通标志过程中更加高效、精确。研究人员提出一种引入深度可分离卷积(Depthwise Separable Convolution,DSC)[16]和改进正负样本处理算法,以YOLOv3 检测精度,但是检测所需时间较长。文献[17]介绍一种通过精简主干网络,以增加特征提取尺度,从而加快YOLOv4 算法的检测速度,但是对交通标志的检测精度还有待提升。YOLOv5 算法同时兼顾速度和精度等优点获得广泛应用,但是当面对交通标志这类小目标较多的任务时,采用堆叠大量卷积核进行下采样的方式,使得采样特征失去表达能力[18],难以灵活地调整内部参数,从而丢失图像的细节信息,导致检测算法对小目标、遮挡目标的检测能力降低。
本文提出基于YOLOv5 的端到端改进网络。以新型算子[19]作为采样架构,通过自卷积方式减少通道冗余,同时采用控制变量的实验方式分析网络深度与采样信息的关系,结合注意力机制,构建跨阶段注意力机制(AMCSP)模块,增加通道的重要性权值。利用优化的通道聚合网络(Path Aggregation Network,PAN)[20]进行特征融合,采用K-means 聚类算法重新定义适合交通标志的先验框,在保证检测精度的同时大幅减少模型计算量。在此基础上,通过引入距离交并比(Distance Intersection Over Union,DIOU)[21]函数进行非极大值抑制,采用加入惩罚项的方式,使得目标框之间的距离最小化,从而提升检测精度和回归效率。
1 新型算子
传统卷积核的设计主要有2 个重要性质:1)空间无关性,采用一个卷积核处理一张特征图,不会因为图像内空间变换而改变卷积核的权值,即全部滑窗共享权值;2)通道特异性,输入图像通道数量等于卷积核通道数量,即每个图像通道独享其对应的卷积核。卷积运算流程如图1 所示。
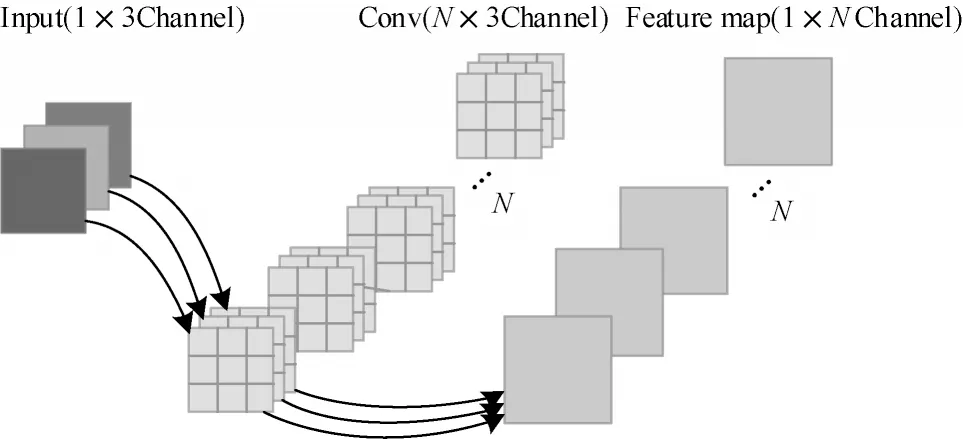
图1 卷积运算流程Fig.1 Convolution calculation procedure
空间无关性可以有效减少网络的参数量,但由于卷积核提取的特征单一,因此无法根据应用场景灵活地调整参数。而通道特异性无法使得通道参数共享,导致网络模型通道参数冗余。为了解决以上问题,具有空间特异性和通道无关性的Involution 算子(Inv)被提出。与卷积核设计理念相反,Inv 算子的通道无关性是在更高的维度上,即整个输入通道范围共享G(G≪C)个Inv 核参数;空间特异性表示Inv 在同一通道不同空间位置上独享Inv 核参数。每个Inv 核由输入图像本身生成,如式(1)所示:

其中:Hij∈RH×W×K×K×G表示Inv 核;XΔij表示在特征图上一个坐标为(i,j)的邻域集合。为了更好地契合YOLOv5 模型框架,减少模型参数量,本文使用SiLU作为Φ的非线性激活函数,如式(2)和式(3)所示:

Inv 采样计算可以认为是一种自注意机制的应用,基于PyTorch 框架的伪代码实现。Involution 算子采样计算流程如图2 所示。本文通过Unfold 滑窗函数将数据打包压缩,数据通过Φ步骤产生核函数,调整两者维度为(B,G,C//G,K×K,H,W);将数据与核函数相乘叠加,调整维度为(B,C,H,W)输出。其中,B表示数据批量大小,C表示通道数量,K表示Inv 核大小,H、W表示特征图的高和宽,Ci、Co表示输入与输出通道维度。

图2 Involution 算子采样计算流程Fig.2 Sampling calculation procedure of Involution operator
2 交通标志检测网络
2.1 改进的特征提取网络
跨阶段注意力机制(AMCSP)模块结构如图3所示。

图3 跨阶段注意力机制模块结构Fig.3 Structure of cross stage attention mechanism module
图中虚线框所示为YOLOv5 使用的跨阶段局部(Cross Stage Partial,CSP)模块,其中,n表示结构中Bottleneck 模块的重复次数。这种残差结构通过将梯度信息分别集中到特征图中,在保证精度的同时提高算术单元利用率。但是CSP 模块对于检测交通标志这样的小目标仍存在不足,分辨率为640×640 像素的图像经过下采样之后最小仅为20×20 像素,相当于每个像素点对应的视野为32×32 像素的图像块,特征被严重削弱,对于所占空间小的目标很容易消失,而AMCSP 模块能够有效解决该问题。
结合混合域注意力机制[22]的思想,在原有CSP模块上增加通道注意力机制,特征图经过平均池化后,大小为C×1×1,第1 个全连接层通过一个比例因子r进行降维,第2 个全连接层再将通道升维到C,使网络获得更多非线性组合,经过Sigmoid 函数后得到各通道的重要性权值,最后与原输入张量权值相乘,使网络在训练中提高对小目标的学习能力。
特征提取网络作为目标检测的主干网络,其采样特性将直接决定预测网络的精确率。在小目标检测任务中,下采样率与网络深度能够显著影响目标语义信息的提取效果。对此,本文结合Inv 核结构的特性,对YOLOv5 特征提取网络的采样层进行改进,并进行多组拆分组合实验。
改进后的特征提取网络参数如表1 所示。网络中第2、4、6、8 层分别利用Inv 核进行4、8、16、32 倍下采样。但是,由于浅层和深层所含的语义信息有很大区别,因此本文结合Conv 与Inv 的特性,最大程度地提高网络性能。输入网络的图像尺寸为640×640像素,Focus 模块通过堆叠3×3 的卷积结构对 图像进行等间隔切片采样,再将采样后的信息拼接,使信息集中到通道域。Inv 模块随着采样倍率和网络层数的不断加深,比Conv 模块挖掘到更加丰富的语义信息。
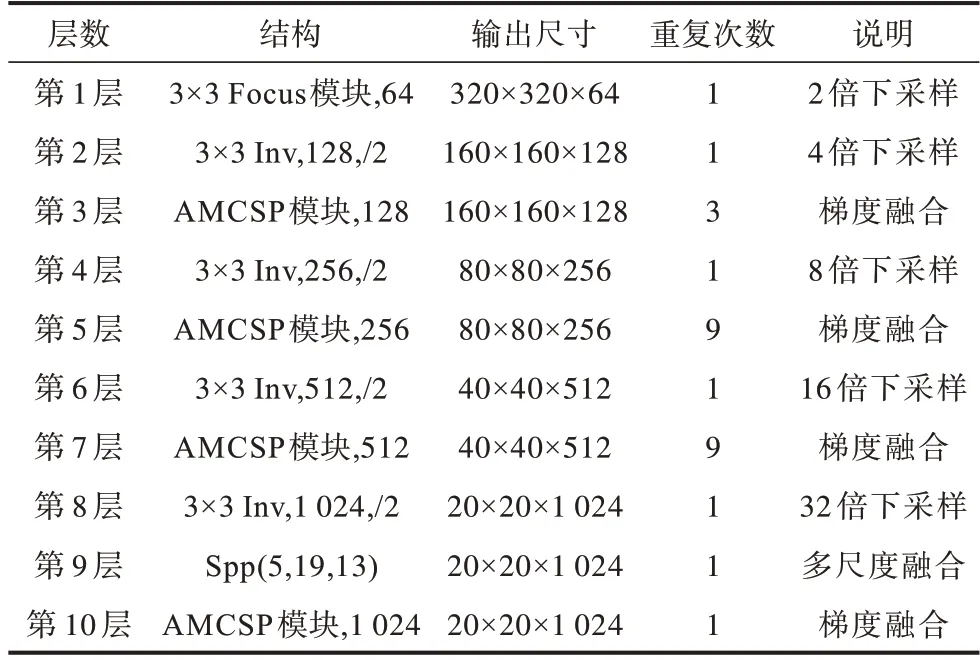
表1 改进的特征提取网络参数Table 1 Parameters of improved feature extraction network
2.2 改进的特征融合网络
提取后的特征信息(第5、7、10 层)先经过特征金字塔网络(Feature Pyramid Network,FPN)[23],将来自第10 层和第7 层的高层特征信息采用自顶向下的上采样方式,与第5 层底层特征进行3 个尺度的传递融合。改进的特征融合网络结构如图4 所示。本文对PAN 进行优化设计,去掉Concat 连接方式,改为Add 连接,然后通过1×1 的卷积将3 个融合层调整为相同的张量维度送入检测输出层。

图4 改进的特征融合网络结构Fig.4 Structure of improved feature fusion network
Concat 连接方式是将通道数相叠加,本身特征所含的信息量没变。Add 连接方式是将描述特征的信息量相叠加,却并不增加图像通道数。相比Concat 连接方式,Add 连接方式大幅减小所需的计算量与参数量。
2.3 目标的检测输出
特征融合后的3 个尺度张量信息如式(4)所示:
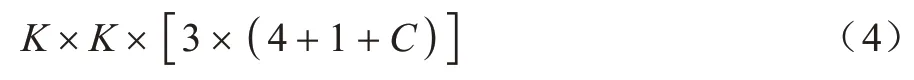
其中:K×K表示特征图的尺寸;3 表示特征图的每个网格会生成3 个边界框;C表示类别个数;1 表示该边界框的置信度得分;4 表示预先设置的先验框和最终生成预测框之间的4 个偏移量坐标(tx,ty,tw,th)。最终预测框的生成计算过程如式(5)所示:
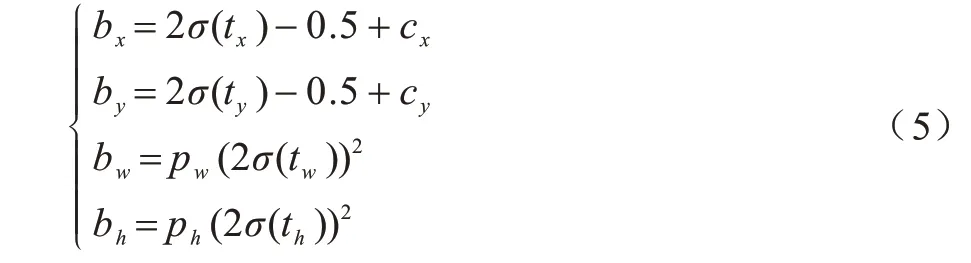
其中:(bx,by,bw,bh)表示预测框的中心点坐标及宽高度信息;(cx,cy,pw,ph)表示先验框网格的左上角坐标及宽高度信息;σ表示Sigmoid 激活函数。
针对交通标志检测应用场景,本文使用K-means聚类算法生成更合适的9个先验框尺寸,分别为(15,16)、(24,24)、(23,52)、(36,34)、(57,55)、(58,116)、(110,90)、(390,341)、(575,545)。
YOLOv5的损失函数由分类损失和回归损失组成,分别使用二值交叉熵(Binary Cross Entropy,BCE)函数和CIOU_Loss 计算。在交通标志检测网络的预测框生成后,需要对预测框进行筛选。YOLOv5 采用非极大值抑制(Non-Maximum Suppression,NMS)方式进行后处理,普通NMS 只考虑重叠面积,如果遇到遮挡情况,经常会将相近的目标错误剔除掉。本文对此不足进行改进,采用DIOU_NMS 进行后处理。DIOU 的计算如式(6)所示:

其中:IIOU为两框交集与并集比值;d为两框中心点距离;c为两框最小外接矩形的对角线长度。DIOU_NMS 的剔除机制如式(7)所示:

其中:si表示分类得分;ε表示NMS阈值。DIOU_NMS 除了考虑重叠面积外,还考虑了预测框之间的中心点距离,可以更加准确地对预测框进行筛选。
本文网络整体架构如图5 所示。本文网络结构分为特征提取、特征融合以及检测输出3 个部分,网络会对输入图像中的目标进行边界框、置信度以及类别的预测回归。
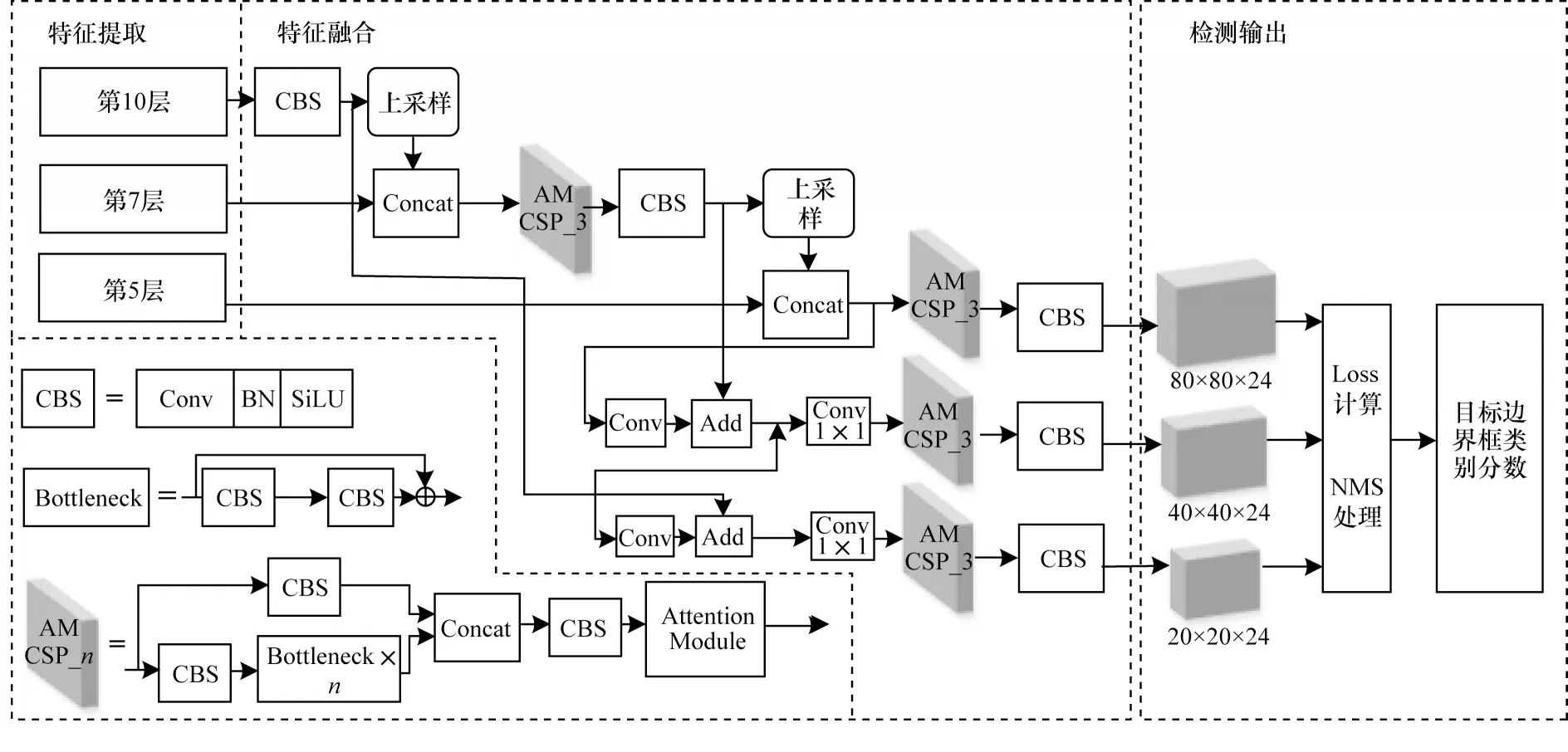
图5 本文网络整体架构Fig.5 Overall architecture of the proposed network
3 实验与结果分析
实验平台为Ubuntu 18.04 操作系统,采用3 路Xeon E5-2678 v3 CPU,NVIDIA Tesla k80 GPU,显存12 GB。运行环境为Python 3.8,深度学习框架为PyTorch 1.7。数据集为中国交通标志检测数据集[24](CCTSDB)。该数据集是在中国高速公路和城市道路上采集的图片,包含15 734 张。本文对数据集进行筛选,将变化小和标注不明显的图片剔除后,从中选取10 000 张包含不同角度以及不同光照变化的图片,每张图片分辨率为1 024×720 像素,共分为Prohibitory、Mandatory、Warning 3 个类别,其中9 000 张为训练集,1 000 张为测试集。
交通标志检测网络在训练之前,先对数据集进行等比例缩放,使图片满足输入分辨率后采用Mosaic 数据增强进行处理[25],批量大小为16。Mosaic 算法每次通过随机缩放、裁剪、排布对4 张图片进行拼接,不但扩充了数据集,还增强了对小目标的检测能力,加快了推理速度。表2 为网络训练相关超参数配置。Mosaic 数据增强样例如图6 所示(彩色效果见《计算机工程》官网HTML 版)。

图6 Mosaic 数据增强样例Fig.6 Examples of Mosaic data enhancement

表2 相关超参数设置Table 2 Related hyperparameter settings
由于本文对YOLOv5 的底层网络架构进行改进,因此无法使用迁移学习进行加速训练,总迭代次数为200。检测网络的学习率设置分为两个阶段,预热阶段采用线性插值对学习率进行更新,预热阶段后采用余弦退火算法来调整学习率。
3.1 评价指标
检测精度和检测速度是用于衡量目标检测网络性能的两个指标。检测速度是指目标检测网络每秒能够检测的图片数量(帧数),用FPS(Frames Per Second)表示。本文采用平均精度均值(mean Average Precision,mAP)评估网络的检测精度。精确率(P)如式(8)所示:

其中:TTP表示正样本被预测为正样本的数量;FFP表示负样本被预测为正样本的数量。精确率表示模型预测的所有正样本,预测正确所占的比例。召回率(R)如式(9)所示:

其中:FFN表示正样本被预测为负样本的数量。召回率表示在所有正样本中,模型预测正确的正样本所占比例。精度(AAP)可以近似看作P-R曲线下的面积,采用定积分的方式计算最终AAP值。精度(AAP)如式(10)所示:

其中:Psmooth表示将P-R曲线平滑处理;i表示类别索引,每个类别对应一个AAP。本文采用以下2 个mAP指 标:1)mAP(IOU=0.5),即交并比(Intersection Over Union,IOU)阈值为0.5 时,各个类别的精度取平均值;2)mAP(IOU∈0.50~0.95),即IOU 阈值以0.05 为步长,取0.50~0.95 精度的平均值。
3.2 实验对比
3.2.1 有效性分析
本文设计7 组对比分析实验,以验证Inv、AMCSP 和DIOU_NMS 模块对基础网络YOLOv5 性能的影响,以及结合Conv 与Inv 特性,最大程度地提高检测网络性能。不同实验的性能分析如表3 所示,组与组之间采用控制变量的方式进行对比,并在CCTSDB 数据集上采用2 个mAP 指标进行评估。其中√表示采用Inv 构造4、8、16、32 倍下采样,×表示没有进行下采样。
从表3 可以看出,在实验1、实验2 和实验3 中,AMCSP、DIOU_NMS 对检测网络的性能均有提升。在AMCSP、DIOU_NMS 两种模块都使用的情况下,与实验1、实验2 和实验3 相比,实验4 的mAP(IOU∈0.50~0.95)提升了约3%,在交通标志检测这种小目标众多、容易出现遮挡的应用场景中,AMCSP 和DIOU_NMS 模块能够有效提升网络的检测性能。

表3 不同实验的性能分析Table 3 Performance analysis among different experiments
本文对比表3 中实验4 和实验5 的结果可知,将特征提取网络中浅层的采样层替换为Inv 结构,检测性能几乎没有改变。本文进行实验6,将提取网络中深层的采样层替换为Inv 结构,与实验4 相比mAP 提升约2%。其原因主要有以下2 个:1)浅层网络包含更多的像素特征信息,即图像细节信息,根据Conv结构的通道特异性使每个通道层独享核函数,可以更加全面地学习细节信息,比Inv 结构更加合适;2)深层网络包含更多的特征抽象信息,即图像语义信息,Inv 结构的空间特异性可以保证每个像素能够更加灵活地学习核函数,而通道不变性又能确保不产生冗余干扰信息。因此,相比Conv 结构,Inv 结构更加适合放在深层网络中。
本文进行实验验证了上述分析的正确性,Conv结构适合浅层网络,Inv 结构适合深层网络。采用性能优异的实验模型对CCTSDB 数据集上每个类别的精确率、召回率以及AP(IOU=0.5)进行统计分析,结果如表4 所示。从表4 可以看出,实验6 的网络模型在各个类别的评价指标均达到最高。因此,本文最终采用实验6 的改进网络模型进行后续实验分析。
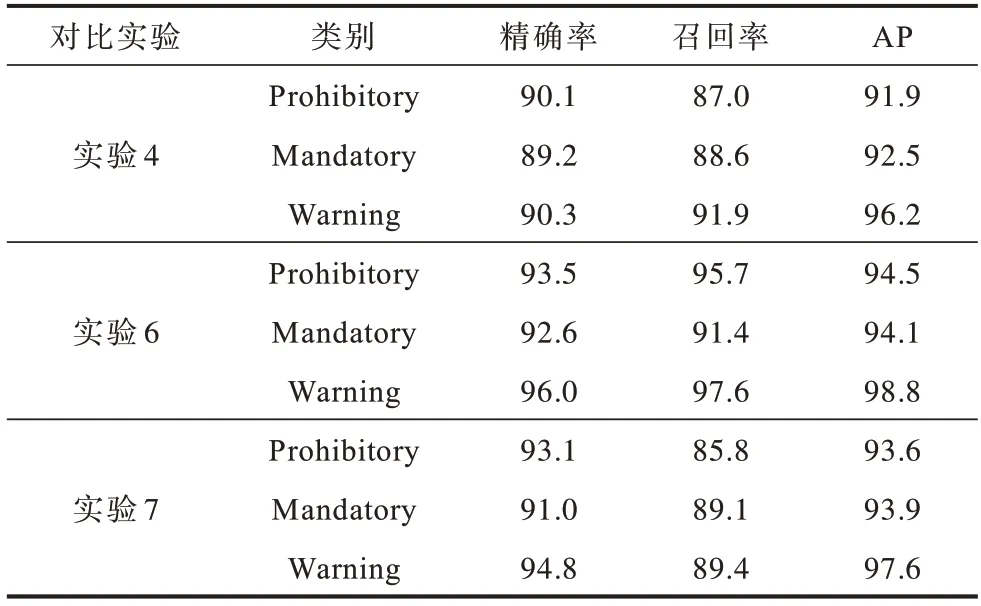
表4 在不同实验中各类别的评价指标对比Table 4 Evaluation indexs comparison of each category on different experiments %
3.2.2 检测网络对比
本文网络与典型检测网络在CCTSDB 数据集上进行各项实验对比,为保证实验的公平性,所有实验基于同一平台测试,包括YOLOv5、Faster R-CNN+FPN、SSD。其中,后两者的特征提取网络均为Resnet50。图7 所示为不同网络最佳IOU 阈值的mAP 分析,相比SSD 检测网络,本文网络的mAP 提高了约10 个百分点。
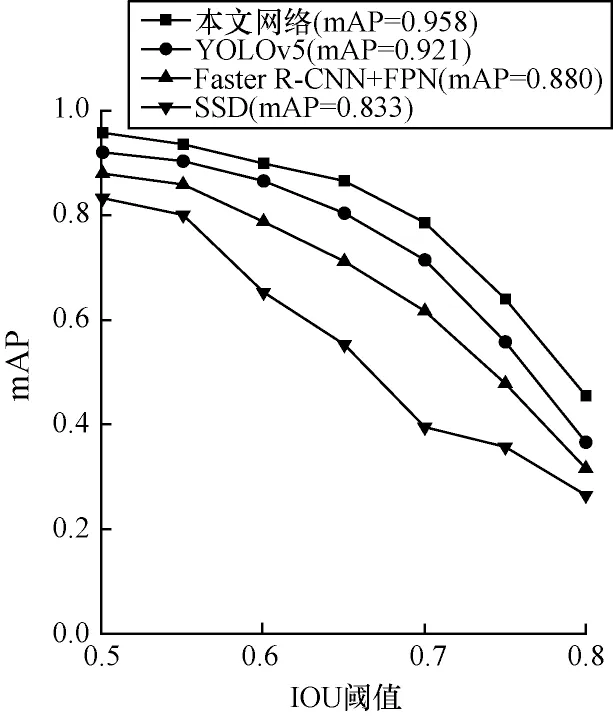
图7 不同网络的mAP 对比Fig.7 mAP comparison among different networks
推理速度决定检测网络是否能满足实时需求,而模型参数量决定网络是否方便部署到小型移动设备上。不同网络的检测速度与参数量对比如表5 所示。

表5 不同网络的检测速度与参数量对比Table 5 Detection speed and parameter quantity comparison among different networks
相比YOLOv5 网络,本文所提网络的推理速度提升1/8(推理速度受GPU 资源所限,因此只比较提升比例),在交通标志检测应用场景中可以做到实时处理。另外,由于Inv 结构实现通道参数共享、PAN结构的优化,因此本文网络模型参数量较YOLOv5减少了15.7%。
在测试集上随机挑选一张实际拍摄的交通标志图像进行测试。不同网络的目标检测结果对比如图8 所示(彩色效果见《计算机工程》官网HTML 版)。图中含有5 处交通标志,包括2 处小目标和1 处遮挡目标。在同一应用场景中,本文网络能够精准检测目标,而YOLOv5 漏检了遮挡目标,Faster R-CNN+FPN 和SSD网络对小目标检测能力还有待加强。

图8 不同网络的目标检测结果对比Fig.8 Target detection results comparison among different networks
4 结束语
在交通标志检测场景中,本文结合优化的新型算子结构与跨阶段注意力机制模块,提出基于YOLOv5 采样优化的检测网络。通过控制变量实验探究新型算子与卷积相结合对网络性能的影响,以减少通道聚合网络的参数运算量。在中国交通标志数据集上的实验结果表明,本文网络具有较少的参数量,在满足实时性的同时具有较优的检测精度。后续将在特征融合部分,结合新型算子方法设计高效的自注意力结构,提高算力资源的利用率和模型精度。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
校园英语·上旬(2020年1期)2020-05-09
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
安徽大学学报(自然科学版)(2018年6期)2018-11-19
北京航空航天大学学报(2018年1期)2018-04-20
卷宗(2017年16期)2017-08-30
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
