
基于知信图卷积神经网络的开放域知识图谱自动构建模型
2022-10-16 12:27孙亚茹杨莹王永剑
计算机工程 2022年10期
孙亚茹,杨莹,王永剑
(公安部第三研究所,上海 201204)
0 概述
知识图谱[1-3]可以理解为知识关联网络,主要通过实体、实体属性及实体间的关系来刻画。通过知识关联网络,可以完成知识智能查询、知识智能分析、知识智能问答等重要的自然语言处理任务。以医疗领域数据为例,医疗知识图谱[4-6]是实现医疗人工智能的基石,构建完善的医疗知识图谱,可以为人们提供更高效精准的医疗服务。在开放数据域中挖掘医疗知识,自动构建或补充现有的医疗知识图谱,更是现代化医疗人工智能的体现。
完善的医疗知识图谱应不受限于特定的医疗数据域以及特定的实体和关系,但现有的知识图谱在增加新的知识时会面临实体和关系无法对齐的问题,从而产生知识冗余[7-8]。简单罗列实体和实体所属关系以及无逻辑支撑,是造成医疗知识图谱效率低、限制多、拓展性差的主要原因。
图卷积神经网络(Graph Convolutional Neural Network,GCN)具有强大的图结构建模表达能力,是结构化输入的通用逼近器。因开放域中的数据无类别界限,若要达到精准识别的效果,需要结合先验知识。这种以知识驱动参与神经网络模型的训练方式,被称为知信学习[9]。将先验知识与深度学习相结合,对于模型在开放域中达到精准识别起到至关重要的作用。文献[10]对先验知识与神经网络结合的初步尝试,表明该方式可以达到与现代神经网络相似的数据拟合能力。
本文采用知信学习的设计思想,在先验知识与GCN 之间建立关联,提出自适应医疗知识图谱构建方法Ad-MKG,实现在开放域中自适应地进行实体对齐和关系消歧。在此基础上,从关系抽取、实体对齐、三元组抽取3 个方面评估Ad-MKG 的有效性。
1 相关工作
现有的医疗知识图谱多采用半自动构建方法,主要依赖人工定义实体与关系的规范、人工知识降重和知识消歧[11-12]。中医药学语言系统的语义网络框架在中医药术语系统的质量保证和国际推广工作中发挥重要的作用,但其中包含复杂、庞大的语义概念,这为知识的构建和扩增增加了难度。虽然之后128 种语义类型被去掉了设置不合理的类型,精简成58 种,但是其抽象形式仍不利于知识的动态扩增。对此,韩普等[12]将医疗知识重新划分为6 类14 种实体关系,通过多源医疗实体链接融合促进了医疗知识的融合。
针对知识间表象关联、无实质性逻辑支撑等问题,各种不同的实体对齐和关系抽取方法相继被提出,如文献[13-14]采用分析文本依赖树的方法来挖掘文本中的非局部语法关系,文献[15-16]在完整树中实体间的最短依赖路径上应用神经网络,文献[17]将完整依赖树裁剪为实体间的最低公共祖先作为模型的输入,以降低完整树中的无关信息对模型噪声的影响,文献[18]则在修剪过的依赖树上应用GCN。然而,基于规则的裁剪策略会忽略文本中的一些重要信息,如在跨句子关系抽取任务中,裁剪后的依赖树可能会丢失关键的依赖路径和中间载体。获取的实体信息与关系信息的丰富程度严重影响知识融合的准确率,是知识图谱自动构建性能优化的关键点。因此,如何使模型在完整树中学习有用的信息而剔除无关的信息,是完成实体和关系抽取任务的关键问题。
2 知信图卷积神经网络
本文提出的Ad-MKG 模型主要由3 个模块组成,即知识库构建、数据预处理和知信图卷积语义分析,其中,知信图卷积语义分析模块包含图编码层、注意力引导层、知信牵引层和三元组判别层。Ad-MKG 模型框架如图1 所示,具体步骤如下:

图1 Ad-MKG 模型框架Fig.1 Framework of Ad-MKG model
1)通过爬虫技术从多源获取所需数据:获取实体与别名实体对作为先验知识存放在知识库中,以及获取模型所需训练的医疗数据。训练数据详情将在下文实验部分详述。
2)对整理好的训练数据样本,通过数据预处理模块将文本转换为模型可处理的数据:先通过依存句法分析把文本转换成关联矩阵,再将文本关联矩阵和实体作为知信图卷积语义分析的输入。
3)在知信图卷积语义分析模块的处理过程中:首先通过GCN 编码对结构化数据进行初步信息挖掘;然后结合多头注意力机制捕获实体间的关联依赖信息,通过将先验知识与锚点相结合的方式,使得模型计算输出的实体特征在空间域中不偏移;最后对GCN 输出的实体和关系的特征信息进行分析判别:若判别是相同实体,则输出三元组存储知识图谱;若判别不是相同实体,则输出不同三元组存储知识图谱。
Ad-MKG 模型的核心部分为知信图卷积语义分析模块,下文将结合具体的输入和输出,具体描述该模块各层的计算过程。
2.1 图编码层
图编码层用于将数据预处理模块输出的文本依存信息编码成图结构数据,以支持模型从图结构数据中有效捕获实体关联信息。
数据预处理模块将输入的文本{s1,s2,…,sn}处理成输出(S,e1,e2,e3),其中,S表示文本的依存信息,e1、e2和e3表示不同实体。S包含文本的token 以及关联矩阵。关联矩阵刻画了文本中词与词之间的关联,若词间有关联则元素值为1,若无关联则为0。在图编码层,词变成了图中的节点,词间的关系表示图中的边。若文本中有n个词,则图中有n个节点,可将该图表示成一个n×n的邻接矩阵A,其中Aij和Aji表示节点i和j之间存在一条边,初始值为0 或1。GCN 通过邻接节点来表征本节点,在L层的GCN 中,给定输入集合第l层节点i的输出向量由第l-1 层节点i及其相邻节点表示如下:

其中:W(l)是做线性变换的权重矩阵;b(l)是偏差向量;是初始输入的单词向量x(ixi∈Rd,d是输入特征的维度)。
经过L层GCN 对每个节点向量的处理,得到节点的隐藏表示,利用这些词表征可以得到一个句子的特征表示:

其中:h(L)∈Rn×d,表示L层所有的隐藏表示(L是超参数);函数f:Rn×d→Rd将n个向量转变成一个句子向量。同理,第i个实体hei的计算公式如下:

2.2 注意力引导层
注意力机制是一种有效计算数据中哪些重要部分影响结果的方法,其中多头注意力机制可以从数据的多个层次挖掘影响结果的重要信息。本文采用多头注意力机制对文本全局信息特征进行把控,将图编码层中的邻接矩阵通过注意力机制转换成边-权连接图,使得边-权连接图能够深度刻画节点和节点之间的信息交互。
邻接矩阵通过注意力矩阵转化成边-权连接图。在图1中表示节点i到节点j的边的权重,描述了单个序列2 个任意位置之间的相互作用。注意力矩阵的计算公式如下:

相应地,初始输入的原始图转换成了全连接的边-权图,第l层节点i的输出向量计算公式如下:

2.3 知信牵引层
知信牵引层以先验知识引导模型学习拟合数据的规律,实现文本中的实体对齐。本文以医药实体别名对作为先验知识,将成对的医药实体作为医药特征的锚点。在实体特征输出时,设置一个惩罚项γ来奖励或惩罚模型对实体对齐和关系抽取学习的行为。在注意力引导层输出实体特征和句子特征时,首先会判别句子中是否含有锚点,若有则增加锚点在实体特征和句子特征中的权重,否则惩罚该实体和句子整体的表示。以第l层第i个词的信息特征为例,计算公式如下:

实体对齐是指不同名字的实体在语义表征空间中具有相同的信息。本文通过直接计算实体特征向量在特征空间的表示,找出文本中与实体he表征最相似的实体表征,计算公式如下:

其中:He表示实体特征的集合。通过式(7)可得到潜在的实体对齐对
2.4 三元组判别层
三元组的提取依赖实体对和实体间关系的确定。知信牵引层确定了实体对齐对,对去除掉别名实体的实体对判别关系,构成三元组。本层通过一个维度变换函数计算GCN 编码后的句子的整体表达,如式(8)所示:

关系抽取任务可看作是对描述文本中实体对的关系进行分类。实体hei与实体hej的关系rij通过一层前馈神经网络FFNN(·)计算得到:

本文通过Softmax 函数对rij进行关系类别的预测,计算公式如下:

对三元组的提取,笔者期望模型对于给定的实体集合{he1,he2,…,hen}可以判别出哪些是相同实体,并输出不同实体hei和hej之间的关系rij,然后组成三元组的形式。因此,目标函数定义为:

其中:m为关系标签的个数。可采用梯度下降法对目标函数求参,并采用超参数学习率α更新参数,计算公式如下:

3 实验与分析
3.1 数据集
实验将从关系抽取、实体对齐和三元组抽取3 个方面测试和评估本文提出的Ad-MKG 模型。为便于对比现有的任务模型,采用SemEval 2010 Task 8 作为关系抽取评估数据集,采用FB15k 作为三元组抽取评估数据集。同时,为验证知识图谱自动构建的流程,采用收集整理得到的数据集Medical Dataset(MD)进行实体对齐和三元组抽取。数据集介绍具体如下:SemEval 2010 Task 8[19]训练集包含8 000个样本,测试集包含717 个样本;FB15k 数据集是从Facebook 中抽取出的数据集,训练集包含480 000 个样本,测试集包含59 000 个样本;MD 数据集中的训练文本依据爬取到的实体别名对清洗得到。根据医疗领域中行文的语义网络结构,定义5 种实体、5 种关系和7种属性,整理训练得到的数据集包含10 000个样本,其中训练集有80 000个样本,测试集有20 000个样本。
3.2 对比模型
在关系抽取实验中,选取以下4 个具有代表性的模型进行对比:支持向量机(Support Vector Machine,SVM)[20],最短路径LSTM(Shortest Path LSTM,SDPLSTM)[21],注意力引导的图卷积神经网络(Attention Guided GCN,AGGCN)[22],基于BERT 的关系抽取模型R-BERT[23]。
在实体对齐和三元组抽取实验中,选择BERTSoftmax、TransE[24]和TransR[24]作为对比模型。
3.3 实验设置
实验中主要涉及的超参数有GCN 层数L、多头注意力头数N和单词向量维度d。从L={2,3,4}中选择GCN 层数,从N={1,2,3,4,5}中选择多头注意力头数,从d={100,200,300}中选择单词维度,进行10 次独立运行的实验,选择具有中间验证结果的F1 值模型,并报告其测试的F1 值。通过测试集上的实验结果可以发现,(L=2,N=2,d=300)的组合设置在MK 数据集上取得了最好的效果。该模型是在NVIDIA GeForce GTX 1050 下采用CUDA10.2训练的,包含100 个训练周期,每个周期时长约为209 s,初始词典大小为5 000,dropout 率设置为0.1。同时,采用Adam 优化器训练参数,初始化的学习率为0.001,选择带指数衰减的学习率设置,衰减率为0.9。
3.4 实验结果
3.4.1 关系抽取任务
在SemEval 数据集上进行关系抽取任务的实验,实验结果如表1 所示,其中加粗数据表示最优值。由表1 可以看出:深度学习模型性能优于基于特征的模型,基于图结构的深度学习模型性能优于基于序列学习的模型,这说明基于图结构的深度学习方法可以更深层次地捕获实体之间的信息;基于实体信息挖掘完成关系抽取的R-BERT 模型较AGGCN 的Macro-F1 值提升了3.5 个百分点,这是因为C-BERT 依赖性能较稳定的预训练模型BERT;本文所提出的Ad-MKG 模型取得了最好的性能,表明先验知识的参与可以有效提升模型挖掘实体间关联信息的能力。

表1 SemEval 数据集中关系抽取任务的实验结果Table 1 Experimental results for relational extraction task in SemEval dataset %
3.4.2 实体对齐任务
在MK 数据集上进行实体对齐任务的实验,实验结果如表2 所示,其中加粗数据表示最优值。由表2 可以看出,Ad-MKG 模型依然取得了较好的结果,其F1值较BERT-Softmax 模型提升了2.4 个百分点。

表2 MK 数据集中实体对齐任务的实验结果Table 2 Experimental results for entity alignment task in MK dataset %
进一步地,从数据规模对模型性能的影响出发进行评估和分析。将MK 数据集中的训练集比例划分为20%、40%、60%、80%、100%,实验结果如图2 所示。由图2 可以看出:数据规模对Ad-MKG 有大影响,随着数据规模不断增加,Ad-MKG 的学习效果越来越好,但是对基于强大预训练模型的BERT-Softmax 影响较小,这说明BERT-Softmax对数据规模有较好的扰动性,而Ad-MKG 对样本数据有较强的依赖性。
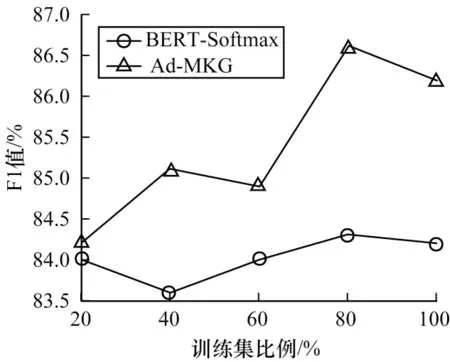
图2 不同数据集规模下实体对齐任务的实验结果Fig.2 Experimental results for entity alignment task under different dataset sizes
3.4.3 三元组抽取任务
三元组抽取任务是指从文本中识别出成对的实体和实体间的关系。对三元组抽取结果进行对比,实验结果如表3 所示,其中加粗数据表示最优值。由表3可以看出,Ad-MKG 依然取得了较好的结果,这说明Ad-MKG 更关注于文本中关键的节点关联信息。但同时从表中发现,Ad-MKG 精确率高但召回率低,而BERT-Softmax 相对稳定,这可能与文本中存在多个实体有关,并且文本的倾向性也会误导模型对实体关系的表征计算。

表3 MK 数据集中三元组抽取任务的实验结果Table 3 Experimental results for triple tuple extraction task in MK dataset %
为直观分析影响模型性能的因素,可视化Ad-MKG 和BERT-Softmax 在5 种关系类别上的准确率,同时给出每种关系在数据集中的个数,实验结果如图3 所示。由图3可以看出:在样本数量最多的drugs_of 关系下模型性能最差,说明实体的模糊含义对模型准确率的影响最大;而在样本数量最少的belongs_to 关系下模型性能最好,说明明确的特征表征使得模型在判别时对处理的数据有清晰的判别界限。

图3 不同关系样本数量下三元组抽取任务的实验结果Fig.3 Experimental results for triple pull task under different relationship sample sizes
在FB15k 数据集中进行三元组抽取任务的实验,将本文提出的Ad-MKG 模型与TransE 和TransR模型进行对比,实验结果如表4 所示,其中加粗数据表示最优值。由表4可以看出,Ad-MKG 模型依然取得了最优的结果。

表4 FB15k 数据集中三元组抽取任务的实验结果Table 4 Experimental results for triple tuple extraction task in FB15k dataset %
3.4.4 消融实验
对模型的各模块进行消融实验,以分析Ad-MKG知信图卷积语义分析模块中各层对模型整体性能的影响。评测依据三元组提取性能,实验结果如表5所示。由表5 可以看出,注意力引导层与知信牵引层对模型性能的影响较大。在去除图编码层后,本文利用多层感知机对数据信息进行处理,F1 值下降了3.1 个百分点,说明图编码层对模型提取的特征信息质量起到了重要的保障作用。目前,注意力机制在很多模型[18-19]中已被证明是有效的,在Ad-MKG 模型中,注意力机制也同样发挥了重要作用。在去除注意力引导层后,F1 值下降了1.5 个百分点。在同时去除注意力引导层和知信牵引层后时,模型性能明显下降,说明注意力引导层发挥了提升模型捕获信息特征的作用。同时由消融实验结果也可以看出,将先验知识与深度学习模型相结合,有利于减小模型在特征域中的位置偏移。

表5 消融实验结果Table 5 Ablation experiment results %
3.4.5 实体特征质量评估
为直观地评估模型所得到的实体特征质量,对各模型进行样例测试,二维可视化模型输出的特征。选取可以对齐的实体和不同的实体进行实验,测试样例如表6 所示。

表6 实体特征测试样例Table 6 Examples of entities features test
首先测试Ad-MKG 和BERT-Softmax 这2 个模型是否能够正确判别出属于疾病和药品的实体(测试1),然后测试同类别中相似实体和不似实体之间的判别结果(测试2),实验结果如图4 所示,其中形状相同的表示是同一种类别。由图4(a)和图4(b)可以看出,Ad-MKG 模型能够正确区分疾病和药品实体,且界限明晰,达到了预期的效果,而BERT-Softmax模型存在少许的错误,如将“黑色素斑”判别为药品。由图4(c)和图4(d)可以看出,在相似实体测试中,BERT-Softmax 模型不能准确区分相似实体“阿奇霉素”和“希舒美”,而Ad-MKG 模型仍达到了预期的效果,但是对别名实体对不能较好区分,如“阿奇霉素”和“希舒美”。
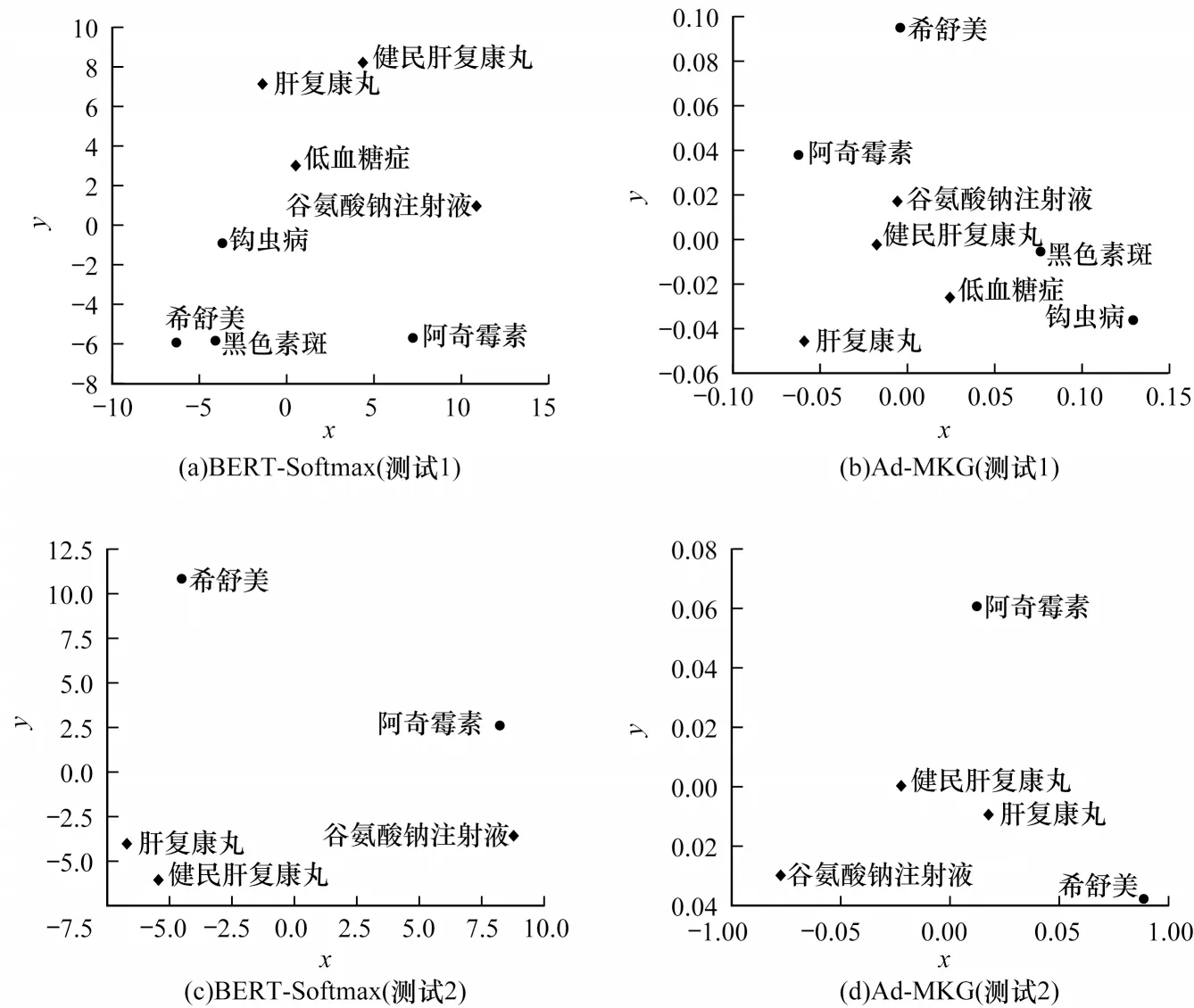
图4 BERT-Softmax 和Ad-MKG 的样例实体特征空间Fig.4 Example entities feature space for BERT-Softmax and Ad-MKG
4 结束语
针对知识间表象关联、无实质性逻辑支撑等问题,本文提出一种自适应的开放域知识图谱自动构建模型。该模型将先验知识与深度学习模型的训练过程相结合,联合语义空间实现知识对齐。以医疗领域数据为例,在关系抽取、实体对齐和三元组抽取3 个任务上的实验结果验证了该模型的可行性和有效性。多源异构信息融合是完善知识图谱自动构建的关键点,后续将研究多源异构知识信息对知识图谱构建的影响,进一步提升本文模型的泛化能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
计算机与生活(2022年3期)2022-03-13
少先队活动(2020年12期)2021-01-14
甘肃教育(2020年22期)2020-04-13
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
新城乡(2018年6期)2018-07-09
计算机系统应用(2017年5期)2017-06-07
第二课堂(课外活动版)(2016年2期)2016-10-21
