
基于Mogrifier LSTM 的序列标注关系抽取方法
2022-10-16 12:27方义秋刘飞葛君伟
计算机工程 2022年10期
方义秋,刘飞,葛君伟
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.重庆邮电大学 软件工程学院,重庆 400065)
0 概述
互联网技术的快速发展使得其产生的信息呈爆炸式增长趋势,而非结构化数据在其中占据主体部分,大幅提高了用户获取有价值信息的难度,因此,如何自动地从无结构化文本中抽取结构化信息成为一个热门研究方向。信息抽取技术从无结构化文本中抽取指定类型的实体、关系、事件等事实信息[1],并对其进行结构化处理。关系抽取作为信息抽取领域的核心子任务,能够从非结构化文本中提取关系三元组[2],具体表现形式为
关系抽取可以划分为命名实体识别和关系分类2个子任务,根据2 个子任务之间的完成顺序和依赖关系,可以将关系抽取模型结构分为流水线结构和联合抽取结构。流水线结构将实体和关系的抽取分为2 个先后独立的任务,在实体识别已经完成的基础上进行实体间关系抽取[3],这种方式存在冗余实体推断和子任务间误差传播等问题。联合抽取结构将关系抽取当作一个整体任务,同时完成实体识别和实体间关系分类2 个任务[4],根据实现原理可分为参数共享型和序列标注型。参数共享型结构分别对2 个子任务进行建模,通过共享2 个子任务之间的模型参数来解决误差传播问题。序列标注型结构设计一种包含实体和关系信息的标签,基于该标签方案,实体和关系的联合抽取任务可以被转化为给实体及实体间关系分配对应的标签,然后利用神经网络来建模该任务,从而实现关系抽取,上述过程在一定程度上缓解了上游任务对下游任务产生冗余信息的问题。
目前,常见的关系抽取方法主要分为基于有监督学习、基于半监督学习和基于无监督学习的方法[5]。有监督的学习方法是当前关系抽取领域使用最为普遍的方法,其在人工标注的数据样本上训练模型,然后进行关系分类和抽取。监督学习方法主要分为基于特征向量的方法和基于核函数的方法。KAMBHATL[6]利用最大熵模型将文本的各种词汇、句法和语义特征相结合,通过句法分析树,即使使用很少的词汇特征也可以取得较高的精确度。当含有大量的无标签数据时,有监督学习方法需要耗费大量人力和时间成本进行数据标注,扩展性较差。为了缓解该问题,远程监督关系抽取应运而生。MINTZ等[7]提出一个假设,如果给定文本中的实体对和外部知识库的实体对一致,那么假设它们之间包含相同的关系。HU等[8]根据定量评估结果,通过整合实体优先证明了知识图和注意力机制在引入和选择有用信息方面具有有效性。RIEDEL等[9]设计多示例学习,并提出“至少表达一次”的假设,用来缓解MINTZ 提出的过强远程监督假设问题。在这之后的研究工作主要集中在如何减少对人工标注语料库的依赖以及提高模型的可迁移性方面。
基于半监督的关系抽取方法主要利用少量已标注数据集作为初始种子集[10],通过一种循环机制标注大量的无标注数据,既减少人工标记语料的数量,又能够处理大规模无标注语料库,在一定程度上避免了对人工标注语料的过度依赖。目前,半监督关系抽取方法常用的是Bootstrapping 算法,但该算法易受初始种子集影响以及存在语义漂移等缺点。
基于无监督学习的关系抽取方法没有给定标注样本,不进行模型训练,直接对样本进行建模分析。HASEGAWA等[11]较早利用无监督学习进行关系抽取,其核心思路是利用抽取实体之间的上下文相似性对实体进行聚类。
当前,科学技术的不断进步使得计算能力得到显著提升,深度学习的优势也逐渐体现出来。早期基于机器学习的关系抽取方法受到标注数据高成本的限制,随着深度学习技术的快速发展,这类关系抽取方法的效果得到大幅提升。通过深度学习方法进行关系抽取的主要思路为:利用词向量、位置向量等构建句子的向量化表示,使用深度学习模型对句子特征进行抽取,然后建立关系抽取模型,最后完成实体间的关系抽取。在基于深度学习方法的关系抽取领域,解决重叠关系问题依然具有挑战性。WEI等[12]提出一种新的标记策略,首先识别头实体,然后识别每个指定关系下的尾实体,该联合抽取方法在一定程度上可以解决关系重叠问题。HANG等[13]建立一种端到端的联合关系抽取模型,在命名实体识别阶段引入微调的实体标签模型,并通过参数共享层来捕获实体特征,其可以抽取不同类型的重叠关系三元组。
本文参考文献[12],采用“BISEO”标注策略将关系抽取转化为序列标注任务,建立一种基于Mogrifier LSTM[14]的序列标注关系抽取模型。该模型通过Mogrifier LSTM 提高输入序列的上下文信息交互能力,利用自注意力增强上下文中的重要特征并削弱次要特征,同时结合基于关系的注意力机制缓解重叠关系问题。
1 序列标注关系抽取方法
本文基于Mogrifier LSTM 的序列标注关系抽取方法将关系抽取任务转化为序列标注问题,提取句子的词信息、字符信息和位置信息,利用Mogrifier LSTM 增强上下文之间的交互,结合关系注意力机制改善关系重叠问题。模型结构如图1 所示,该模型主要由嵌入层、Mogrifier LSTM 层、注意力层、关系注意力层和关系分类层5 个部分组成。

图1 基于Mogrifier LSTM 的序列标注关系抽取模型结构Fig.1 Sequence tagging relationship extraction model structure based on Mogrifier LSTM
1.1 嵌入层
词嵌入表示是将句子中的词映射为稠密的向量。在本文中,一个含有m个单词的句子表示为X=w1,w2,…,wm,每个单词wi均转换为实数向量,由词嵌入矩阵转换而成,其中,V表示词汇表的大小,dw表示词嵌入的维度。
将句子中的单词作为一个序列,每个字符用向量表示并输入到卷积神经网络中,即得到字符嵌入表示。
在关系抽取任务中,每个单词拥有2 个相对距离,分别为该单词到头实体以及该单词到尾实体的距离,靠近目标实体的词通常可以为确定实体之间的关系提供更多的信息。因此,本文采用文献[15]所提方法,在模型中加入位置向量特征,即将词位置嵌入拼接到句子向量表示中,将得到的新句子向量表示输入到模型的下一层。
1.2 Mogrifier LSTM层
长短期记忆(Long Short-Term Memory,LSTM)网络是一种改进的循环神经网络,因为LSTM 在训练过程中可以学习记忆与遗忘信息,所以可以更好地捕捉长距离依赖关系[16],这在一定程度上能够缓解较长序列训练过程中的梯度爆炸和梯度消失问题。LSTM 模型结构主要由遗忘门、输入门、记忆门和输出门4 个部分组成:
1)遗忘门将上一时刻隐藏层的输出结果ht-1和当前时刻的输入xt作为输入,从而决定上一时刻的细胞状态ct-1有多少保留到细胞状态ct,计算如下:

2)输入门将上一时刻隐藏层的输出结果ht-1和当前时刻的输入xt作为输入,从而决定当前时刻的输入xt有多少保存到细胞状态ct,计算如下:

3)记忆门确定将哪些新信息存储在细胞状态中,计算如下:

4)输出门控制记忆细胞ct到下一时间步隐藏状态ht的信息流动,计算如下:

其中:xt表示t时刻的输入内 容;ht-1表示t时刻的输出内容;Ct-1表示t-1 时刻的细胞状态;ft表示遗忘门的输出内容;σ和tanh 分别表示sigmoid 和tanh 激活函数;Wf、Wi、Wc、Wo分别表示权重参数;bf、bi、bc、bo分别表示偏置参数。
然而,LSTM 各个门的输入和隐藏状态之间是完全独立的,它们只在门之间进行交互,这在一定程度上会存在丢失上下文信息的问题。为此,本文采用Mogrifier LSTM,在不改变LSTM 本身结构的前提下,在普通的LSTM 计算之前交替地让输入x和隐藏状态hprev进行交互,从而加强上下文信息的建模能力。将当前时刻的输入和隐藏状态经过指定轮次的运算,从而实现两者之间的信息交互。在交互运算过程中,每一轮的当前输入都是由前一轮输入与前一轮隐藏状态进行交互运算所得来,同时每一轮的隐藏状态都是由前一轮隐藏状态与前一轮输入进行交互运算所得来。在经过交互之后,会获得新的输入和隐藏状态,此时两者之间已经存在信息交互,将两者输入到传统的LSTM 中以改善LSTM 输入的上下文不相关的问题。交互运算过程如下:

其中:Qi、Ri是随机初始化矩阵,在具体实现中,通过将Qi、Ri分别分解为低维矩阵以在一定程度上减少模型参数。在Mogrifier LSTM 交互运算[14]过程中,当轮次为奇数时,交互运算如式(7)所示,当轮次为偶数时,交互运算如式(8)所示。因为sigmoid 函数运算结果的取值范围为(0,1),为避免经过多次乘运算后结果越来越小,式(7)和式(8)通过乘以一个数值2 来保证其数值的稳定性。经过r轮交互运算后,将得到新的x、ht用于后续的LSTM 运算,交互过程如图2 所示。

图2 5 轮交互更新过程Fig.2 5 rounds of interactive update process
1.3 注意力层
注意力机制起源于计算机视觉相关研究,其目的是使人们忽略图像中的无关信息,更加关注重点信息。为了获取句子中词语的上下文语义信息,本文采用自注意力机制。自注意力机制通过计算句子中任意2 个词之间的相似性,从而将这2 个词联系起来,以捕获句子中任意2 个词之间的关系,最终在一定程度上缓解长距离依赖问题[17]。通过自注意力计算之后,将得到新的句子向量表示,自注意力机制的计算公式如下:

其中:KT表示K的转置;dk是用于调节内积的矩阵;Q、K、V是可训练的参数矩阵。
1.4 关系注意力层
句子中的词汇在不同关系下会发挥不同的作用,例如,“在电影《中国乒乓》中,邓超既是导演又是主演”,在该句中,邓超与《中国乒乓》存在导演以及主演的关系,在不同关系下对实体三元组抽取有不同的影响。因此,本文采取基于关系的注意力机制[18]为每个关系下的上下文单词分配对应的权重,计算如下:

其中:rk表示第k个关系的向量表示;v、Wr、Wg、Wh分别是可训练的参数矩阵;avg 表示平均池化操作;sg表示句子的全局表示。通过上述过程可知,注意力分数不仅表明单词对关系抽取的重要性,而且体现其对句子表示的贡献程度。最终,根据句子中所有单词的加权和得到特定关系下的句子表示,如下:

在获得特定关系下的句子表示之后,本文采取一种门控机制[18],目的是过滤掉不相关的关系,从而提升后续解码过程的正确性以及关系抽取的准确性。门控机制具体计算如下:

1.5 关系分类层
本文利用序列标注方法来完成关系抽取任务。在序列标注阶段,对句子中的每个词汇都设置对应的标签,根据标签抽取出相应的实体。对于实体位置标签,本文采取“BIESO”标注策略来表示每个词汇在实体中的位置信息:“B”表示实体开始;“I”表示实体中间;“E”表示实体结尾;“S”表示单个词汇;“O”表示其他词汇,用于标注不相关词汇。
在关系抽取任务中,常存在关系重叠问题,即多个关系三元组共享同一个实体,如图3 所示,关系重叠主要分为正常(Normal)、单实体重叠(Single Entity Overlap,SEO)和实体对重叠(Entity Pair Overlap,EPO)3 种类型。本文根据关系类型进行相应地实体抽取,标注处于不同关系下的实体,该方法能够在一定程度上解决关系重叠问题。

图3 关系重叠类型Fig.3 Relationship overlap types
关系分类模块利用双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络进行序列标注,将句子中的每个词汇映射为相应的标签。本文将隐藏层状态作为输入,利用softmax 分类器从给定句子的关系类别集合中预测其对应的标签:

2 实验结果与分析
2.1 实验数据集
本文采用关系抽取领域使用较广泛的NYT10数据集进行实验,该数据集由RIEDEL 等利用纽约时报中的语料库并结合Freebase 知识库进行对齐标注而生成[19]。其中,训练集由2005—2006 年的新闻语料组成,测试集由2007 年以后的句子组成。该数据集共包含53 类关系,其中,“NA”表示2 个实体之间没有任何关系。数据集详细信息如表1 所示。

表1 数据集信息Table 1 Dataset information
2.2 评价指标
在关系抽取任务中,通常采用精确率(Precision,P)、召回率(Recall,R)和F1 值作为评价指标,三者的计算公式分别如下:

其中:真正例(TTP)表示将正类预测为正类的个数;假正例(FFP)表示将负类预测为正类的个数;真反例(TTN)表示将负类预测为负类的个数;假反例(FFN)表示将正类预测为负类的个数;F1 值是将精确率和召回率进行加权调和的结果。在关系抽取领域,将关系三元组中的头实体、尾实体和关系都预测正确才判定该关系三元组正确。
2.3 实验环境和超参数设置
本文采用交叉验证方法对实验进行调优,首先在训练集上训练模型,然后在测试集上测试已经训练好的模型。本文的初始实验参数参考文献[18]的最优值进行设置,然后根据实验结果微调参数。
表2 和表3 所示分别为本文实验所使用的超参数及实验环境。实验选取Adam 作为优化器,该优化器结合AdaGrad 与RMSProp 这2 种算法的优点,可以根据历史梯度的震荡情况和过滤震荡后的真实历史梯度对变量进行更新。在Bi-LSTM 模块中,隐藏层的维度与单词嵌入的维度均设置为300,丢弃率为0.5,Mogrifier LSTM 的交互轮次为5。

表2 超参数设置Table 2 Hyper parameters setting
表3 实验环境Table 3 Experimental environment
2.4 结果分析
为了验证本文模型的关系抽取性能,进行以下对比实验:
1)不同轮次r对关系抽取结果的影响
选择文献[14]中的参数r作为本文实验的基础参数,为了得到最佳的实验结果,分别选取4、5、6、7作为实验参数r的不同取值,4 轮实验中除参数r以外其余参数全部保持一致。从表4 可以看出,F1 值随着r的增大先提高后降低,当r值为5 时,F1 值获得了最高值。

表4 不同轮次下的实验效果Table 4 Experimental results under different rounds
2)3 种模型的精确率对比
关系抽取任务的数据集语料均为句子或文本段,循环神经网络结构适用于处理具有连续性的序列形式数据(如句子、语音等)。为了验证引入Mogrifier LSTM 对关系抽取性能具有提升效果,本次实验将Mogrifier LSTM 分别与循环神经网络中2 种经典模型,即LSTM 模型和门控循环单元(Gated Recurrent Unit,GRU)模型进行对比。LSTM 主要利用门机制,能够控制每个细胞单元保留的信息以及记忆当前输入的信息,通过学习获得权重从而控制依赖的长度,并缓解梯度消失问题。相对LSTM 而言,GRU 内部实现上少一个门控,同时参数也较少,在实验过程中更易收敛,但LSTM 和GRU 都存在缺少上下文交互的问题。
在本次实验的5 轮交互运算中,Mogrifier LSTM每轮的当前输入和隐藏状态都进行交互运算。从表5 可以看出:相较传统的LSTM,Mogrifier LSTM的精确率提升4 个百分点,证明在LSTM 普通计算之前增强上下文信息交互有利于提升关系抽取性能;相较GRU,Mogrifier LSTM 的精确率提升1.7 个百分点。实验结果表明,本文Mogrifier LSTM 的关系抽取性能优于LSTM 和GRU。

表5 3 种模型的精确率对比Table 5 Comparison of precision of three models
3)重叠关系实验分析
关系抽取领域存在重叠关系问题,主要分为Normal、EPO、SEO 这3 种类型。本文将近年来所提的几种经典模型与本文模型进行对比,结果如图4~图6 所示。从图6 可以看出,本文模型在SEO 类型下F1 值明显高于其他模型,F1 值较ETL-Span 模型提升14.4 个百分点,证明本文模型在一定程度上能够缓解SEO 类型的重叠关系问题。
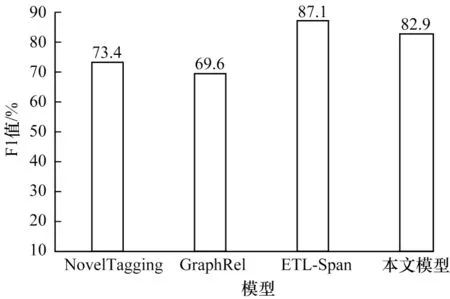
图4 存在Normal 类型关系重叠时的关系抽取性能对比Fig.4 Comparison of relationship extraction performance in case of Normal type relationship overlap

图5 存在EPO 类型关系重叠时的关系抽取性能对比Fig.5 Comparison of relationship extraction performance in case of EPO type relationship overlap
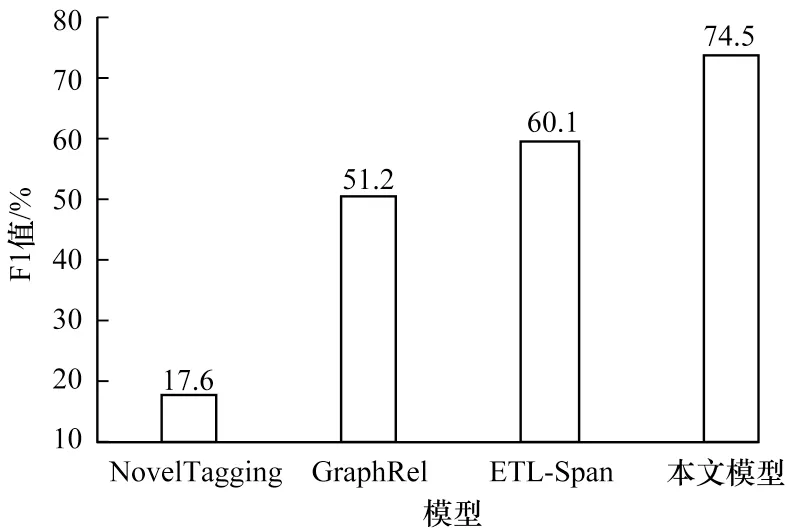
图6 存在SEO 类型关系重叠时的关系抽取性能对比Fig.6 Comparison of relationship extraction performance in case of SEO type relationship overlap
4)基线模型对比分析
为了验证本文模型对于实体关系抽取的有效性,在NYT 数据集上将其与多个模型进行对比。对比模型具体如下:
(1)NovelTagging[20]提出一种新的标注策略,将联合关系抽取任务转换为序列标注问题。该模型通过在解码的过程中增加偏置损失函数,增强实体之间的相互联系,使得模型更加适合特殊标签。
(2)CopyRE[21]提出一种基于复制机制的端到端学习模型,采用一个联合解码器和多个独立解码器这2 种不同的解码策略,在一定程度上解决了重叠关系问题。
(3)MultiHead[22]利用条件随机 场(Conditional Random Field,CRF)将关系抽取任务转换为一个多头选择问题,一次建模所有实体和句子,有助于获得相邻实体和关系之间的信息。
(4)CopyMTL[23]提出由Encoder 和Decoder 组成的模型,Encoder 部分使用Bi-LSTM 建模句子上下文信息,Decoder 部分则结合复制机制生成多对三元组,结合命名实体识别技术来解决无法匹配多字符实体的问题。
(5)OrderRL[24]提出一个序列到序列的模型,并在该模型上应用强化学习,通过强化学习过程来完成三元组的生成,强化学习奖励与生成的三元组有关,允许模型自由生成三元组以获得更高的奖励。
(6)HRL[25]提出一个分层强化学习框架,将实体当作关系的参数来促进实体提取与关系类型交互,通过层级结构来处理重叠关系问题。
(7)ETL-BIES[26]提出一种新的分解策略,第一步为头实体提取,第二步为尾实体和关系提取。与先提取后分类的方法相比,该策略第一步不再提取所有实体,只识别可能参与目标三元组的头实体,从而降低冗余实体对的影响。
从表6 可以看出,在NYT 数据集上,本文模型的精确率、召回率和F1 值分别为0.848、0.834 和0.841。相较对比模型,本文模型在NYT 数据集上取得了更高的精确率和F1 值,且精确率和召回率具有较小的差值,说明模型较为稳定。本文模型的F1 值较ETLBIES 提升6.7 个百分点,证明该模型有利于提升关系抽取性能。
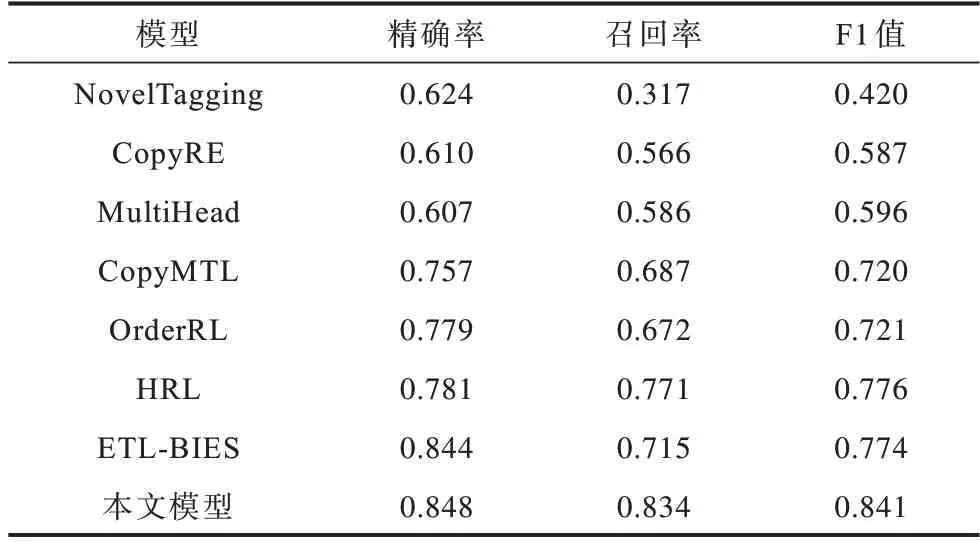
表6 不同模型在NYT 数据集上的性能对比结果Table 6 Performance comparison results of different models on NYT dataset
NovelTagging 模型提出一种标注方法来实现关系抽取,但该模型只考虑单个实体只属于一个三元组的情形,无法识别重叠关系,因此,其召回率较低。CopyRE 是一种序列到序列模型,在一定程度上缓解了重叠关系问题,召回率得到提高,但其区分头实体与尾实体的能力较弱。MultiHead 采用多头关节模型,能够同时识别头实体与尾实体,但其利用LSTM获取字符嵌入特征,存在丢失上下文信息的问题。CopyMTL 模型利用复制机制直接生成关系三元组,使用SeLU 作为激活函数的全连接层改善CopyRE模型存在的问题,使得模型抽取效果得到较大提升。OrderRL 模型结合强化学习,考虑关系事实在句子中的抽取顺序,精确率得到了提升。HRL 利用高级别关系检测和低级别实体抽取的分层框架来增强实体和关系类型之间的交互,从而处理重叠关系问题,该模型的召回率得到显著提升,达到了0.771。ETLBIES 模型将头实体提取和尾实体提取都转化为序列标注问题,减少了冗余实体的干扰,精确率得到了提升。本文模型将关系抽取问题转化为序列标注任务,通过Mogrifier LSTM 增强上下文信息交互,利用注意力机制促进特征提取,并结合基于关系的注意力机制解决重叠关系问题,相较其他模型,F1 值取得大幅提升,证明了模型的有效性。
3 结束语
本文提出一种基于Mogrifier LSTM 的序列标注关系抽取模型,该模型通过增强上下文信息交互来获取更多的有效信息,利用关系注意力抽取特定关系下的实体三元组,同时结合BIESO 序列标注策略获取实体信息。实验结果表明,该模型在NYT 数据集上的关系抽取性能优于对比模型,并能有效改善SEO 类型的重叠关系问题。下一步将通过本文模型捕捉双向语义依赖信息并增强上下文信息之间的交互,从而提升文档级的关系抽取效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
计算机与生活(2022年3期)2022-03-13
甘肃教育(2020年22期)2020-04-13
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
当代陕西(2019年5期)2019-03-21
计算机技术与发展(2018年12期)2018-12-20
计算机系统应用(2017年5期)2017-06-07
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
