
基于改进PageRank算法的文献相关度排序方法
2022-09-30 01:48聂永丹
吉林大学学报(信息科学版) 2022年3期
聂永丹,王 斌,张 岩
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
随着当前专业的学科划分越来越细致,知识信息量爆发式增长导致了文献激增,因此使科研工作者高效地检索与专业研究领域相关的科研文献非常必要。文献检索引擎是通过检索关键词查找相关文献后,再依据相关度排序算法对检索结果进行排序,将排序结果按相关度展示给科研工作者,辅助其快速找到与研究领域最相关的科研文献。
在文献检索相关度排序算法中,PageRank[1]算法应用最为广泛。PageRank最初被用于搜索引擎链接分析相关度排序算法在20世纪90年代提出,并应用于谷歌搜索引擎的网页排序。PageRank算法的基本思想是在有向图上定义一个随机游走模型,形成一个一阶马尔可夫链,描述随机游走者沿有向图随机访问各个节点的行为。通过计算每个网页所具有的PageRank值(PR值)决定其重要程度,PR值越高,表明网页越重要,在搜索结果中该网页的排序就越靠前。文献的相似度排名与网页具有一定的相似性,目前研究者大多借鉴传统网页相关度算法,对文献内容与检索词进行相似度评估并依据相似程度对检索结果进行相关度排名,进而提升文献检索效果。王丹[2]将Lucene排序机制[3]应用于PageRank算法中,但仅提高了文献检索速度,并未提高检索文献的相关匹配程度。张勇等[4]通过PageRank算法与TF-IDF(Term Frequency-Inverse Document Frequency)相结合,提高算法在文献检索上的效果。其缺点在于TF-IDF算法仅能提取出文献中的主要特征词,而对语义相同的词语却无法进行相关匹配检索。华一雄等[5]将WMD(Word Mover’s Distance)算法[6]与PageRank算法相结合,提出一种基于文献相似度和出入比的文献搜索方法,但WMD算法本身存在着丢失语序信息,以及对WMD算法未处理过的词语无法解决词向量OOV(Out Of Vocabulary)的问题。以上学者均从相似度角度对方法做出改进,也有研究学者对PageRank的价值分配问题进行了改进。李瑞等[7]引入马尔科夫链的思想,采用嵌入转移概率因素分配PR值的方式,以达到不平均分配权重的目的,但此方式为随机分配,并不能将PR值分配给相关度更高的文献。王冬等[8]结合互联网的实际情况,并考虑到网页的引用因素,提出NPR(Non-average distribution PageRank)算法,由于算法中PageRank在将节点的PR值分配给当前节点所指向的节点时,仅考虑了连接的引用数量而未考虑引用质量,所以计算结果有偏差。
文献引文网络分析与网页链接分析存在较为明显的差异,主要差异包括以下3个方面:1) 文献在发表后,所引用的参考文献已经确定,因此引文网络表现为静态的有向图,而网页在被发布到网上后,网页中所包含的链接有可能被修改,因此表现为动态结构;2) 文献不存在自引现象,而在网页中则会存在自引现象,而引文网络中则不存在自引现象;3) 在引文网络中,文献与引文之间必然存在着相关性,而网页中则不具有这种必然的相关性。上述将PageRank应用于引文网络的方法,忽略了文献与网页的主要差异,导致其应用于引文网络分析时存在局限性。值得注意的是,由于文献与引文具有相关性,所以将PageRank算法用于文献的引文网络分析时,不能合理地将文献的PR值传给引文,因此找到一种可靠的PR值分配方式,是将此算法应用于引文分析的一个重要问题。
在深度学习领域中,BERT(Bidirectional Encoder Representation from Transformers)[9]是自然语言处理领域内在众多模型中性能突出的算法,其采用迁移学习方式,通过将模型在通用语料库中训练得到预训练模型,其不仅能保留文本的语序信息,而且在经过语料库预训练后,可以通过该模型将文本转化为词向量,因此有效解决了OOV问题。研究者可通过使用文本标注数据对该模型进行微调,得到特定任务模型。该模型在多个自然语言任务测试集上均取得优异结果。
笔者针对传统PageRank算法在引文网络分析中出现相关度排序结果不够合理和可靠的问题,提出具有注意池化方法的孪生BERT深度学习网络模型,以评估文献与引文间的相似度,然后将模型与PageRank结合,以模型计算后的相似度作为给各节点分配PR值的权重,从而使改进后的PageRank算法更适合应用于引文网络分析中。
1 PageRank算法原理
PageRank的一般定义为,给定一个含有n个结点的任意有向图,在有向图上定义一个一般的随机游走模型,即一阶马尔科夫链[10]。该模型的转移矩阵由两部分的线性组合构成:一部分是有向图的基本转移矩阵M,表示一个节点到连出的所有结点的转移概率相等;另一部分是完全随机的转移矩阵,表示从任意一个结点到其他结点的转移概率都是1/n,线性组合系数为阻尼因子d(0≤d≤1)。这个一般随机游走的马尔可夫链存在平稳分布,记作R。定义平稳分布向量R为有向图的一般PageRank,如下

(1)
其中1为n维1列,并且每个分量大小为1的向量,t为算法的迭代次数。
相比网页链接分析网络,文献的引文网络中更具静态结构,单项无自引用,无引文为零的结点,相邻引用内容具有关联性[11]。因此在将PageRank用于引文网络中时,也需根据引文网络的特点进行适当的改进。
2 基于注意力池化的孪生BERT相似度评估网络
BERT模型采用多头注意力机制,其目的是为了使模型关注于重要区域,减少噪声的负面影响。孪生BERT网络通过最后一层的池化层,将两个子网的输出结果变为相同维度,以进行两向量的相似度计算,同时在保留重要信息的前提下,减少计算量。原本网络采用的池化方式为最大池化(max pooling)和平均池化(mean pooling),这是为了使用最为突出的一个特征作为最后整个文献的特征表示,但文献本身不仅有专业的理论基础知识,还涉及相关交叉学科的理论知识,导致两文献间相似度需要由多个重要程度不同的特征才能进行完整表达,而不能仅用最为突出的特征对文献间的相似度进行度量,因此需要考虑每个特征对文献间相似度的贡献。采用注意力池化作为本文模型的池化层,则可以通过使用注意力机制池化方式将文献中的多个重要特征进行保留。
针对上述问题,将注意力的思想引入孪生BERT网络模型中,采用注意力池化作为模型的池化层,进行重要特征抽取。网络整体结构如图1所示。

图1 改进的相似度度量网络结构Fig.1 Improved similarity measure network structure
在文献特征经过BERT词嵌入层和BertEncoder层后,整体特征的表示变为XCLS=[x1,x2,…,xi,…,xN],文献中单个字符特征的表示变为Etoken=[e1,e2,…,ei,…,eN],xi,ei∈d,d为词向量的维度。将XCLS和Etoken进行比较,以计算注意力权重,整体特征表示与每个局部表示之间的相似性越高,分配给该局部表示的注意力权重就越大,其计算方法为
αi=Softmax(sim(xi·ei))
(2)
其中αi为注意力权重,函数sim为用于度量其两个输入之间的相似性。笔者提出的模型中分别使用内积相似度和余弦相似度两种相似度评估函数进行计算,最终注意力池化特征提取式为

(3)
其中S表示注意力池化层输出结果。
通过两孪生子网注意力池化层的输出结果u,v,计算两向量的余弦相似度

(4)
计算文献与引文间的相似度流程如下。
1) 对文献的文本特征进行提取,主要包括3部分:对文献的标题采用去除停用词的方式进行处理;文献的摘要使用Textrank[12]算法对摘要的关键词进行特征提取;文献关键词表现文献的核心主题,可直接作为文献的特征使用。
2) 对文献文本特征进行处理。特征首先通过模型的输入层,使文献特征文本转化为向量的形式,然后通过词嵌入层,将输入层中的字向量、文本向量、位置向量进行合并,得到每个词的词嵌入表示,词嵌入表示通过注意力机制的编码层对特征做进一步提取,最后通过注意力池化层再对特征作进一步提取,得到最终的文献和引文特征。
3) 对利用模型得到的文献与引文特征,计算两者的余弦相似度,结果作为两篇文献间的相似度。
3 改进的文献相关度排序方法
从PageRank的原理可以看出,当前节点会将自身的PR值以平均分配的方式分给当前节点所指向的节点。在引文网络中,一篇文献往往需要引用交叉学科的文献作为参考。由于作者对自身研究领域中的研究侧重点不同,导致每篇参考文献的参考程度不同,造成文献与引文间的相关度不同。所以传统的PageRank算法应用于引文网络分析时,其采用平均分配权重的方式作为当前文献PR值,即将文献对引用文献的相关度视为相同,不能将文献当前的PR值合理地分配给引文。因此,找到一种更为合理可靠的文献PR值分配方式,是使算法更加适用于引文网络分析的主要目标。针对此问题,笔者采用具有注意力池化方法的孪生BERT网络相似度评估模型,对文献与引文进行相似性估计,进而利用模型计算得到的相似性作为分配文献PR值的权重。算法结构如图2所示。
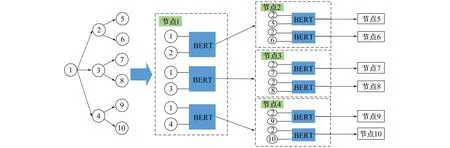
图2 算法结构改进示意图Fig.2 Schematic diagram of algorithm structure improvement
该算法采用孪生网络的方式同时读取文献与引文,首先通过BERT词嵌入层,将文本转化为向量;然后经过BERTEncoder层,从众多信息中找到与自身最相关的部分达到特征提取的目的;最后通过池化层对提取的特征进行降维,获得整体特征表示,将两文献的整体特征进行相似性计算,并将得出相似度评分用于PR值分配权重。
改进后的算法流程如下。
1) 使用孪生BERT网络模型,对文献和文献引用的每个引文计算相似度。
2) 计算文献指向的所有引文的相似度所占总体的比例,计算公式如下

(5)
其中Si为该文献与第i个参考文献的相似度,N为文献包含的参考文献总数,Wi为该文献的第i个参考文献的相似度占参考文献的总相似度的比重。
3) 利用式(5)计算得到的相似度占比W代替算法中原本由平均分配方式的转移矩阵M,计算公式如下
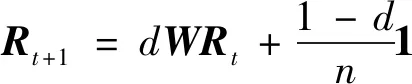
(6)
4) 执行PageRank算法若干次,直到前一次迭代得到的PR值与此次的PR值的差别小于预设的阈值,视为结果稳定。
5) 输出结果。
4 实验结果与分析
笔者以石油钻井方面文献为例,采用scrapy爬虫框架开发数据采集程序,以“石油钻井”为检索关键词,对石油钻井文献进行采集,经过筛选并过滤掉具有干扰性的文章后,获得544篇文献,并且以这些文献为源头对文献的引用文献进行拓展采集和整理。对文献进行编号,数据样例如表1所示。

表1 文献数据样例Tab.1 Literature data sample
表1中给出的相似度主要依据以下5个指标:
1) 文献研究背景所涉及的理论基础和交叉学科是否相同;
2) 文献要解决的问题是否相近;
3) 文献所采用的方法是否类似;
4) 文献同时被另一文献所引用的数量(文献共引);
5) 文献都引用同一文献的数量(文献共耦)。
依据上述5个指标用于文献相似度的评估,并依据指标相关程度的强弱对两文献间的相似度进行评分。
针对石油钻井的研究领域,选取了10个检索词,即“钻头”、“钻井液”、“钻进”、“应力”、“地层”、“牙轮”、“钻压”、“井壁”、“机械钻速”,“钻井”对笔者算法进行验证,采用文献[8]使用的评估方法对文献进行评估,由7位专家组成相关度评估小组,对检索结果的相关度进行判断,选取人数认同最多的相关度作为评估结果,采用以下相关度等级函数进行评估

(7)
针对10个关键词的查询,查询与结果的相关性同样采用<完全相关,部分相关,弱相关>的方式进行表述,查询与结果相关性计算公式为

(8)
其中F为最终的相关度计算结果,Ki为第i个位置的文献与查询的相关度,n为选取的文献总数,选择搜索结果中的前40篇用于计算。两算法排序结果如表2所示。
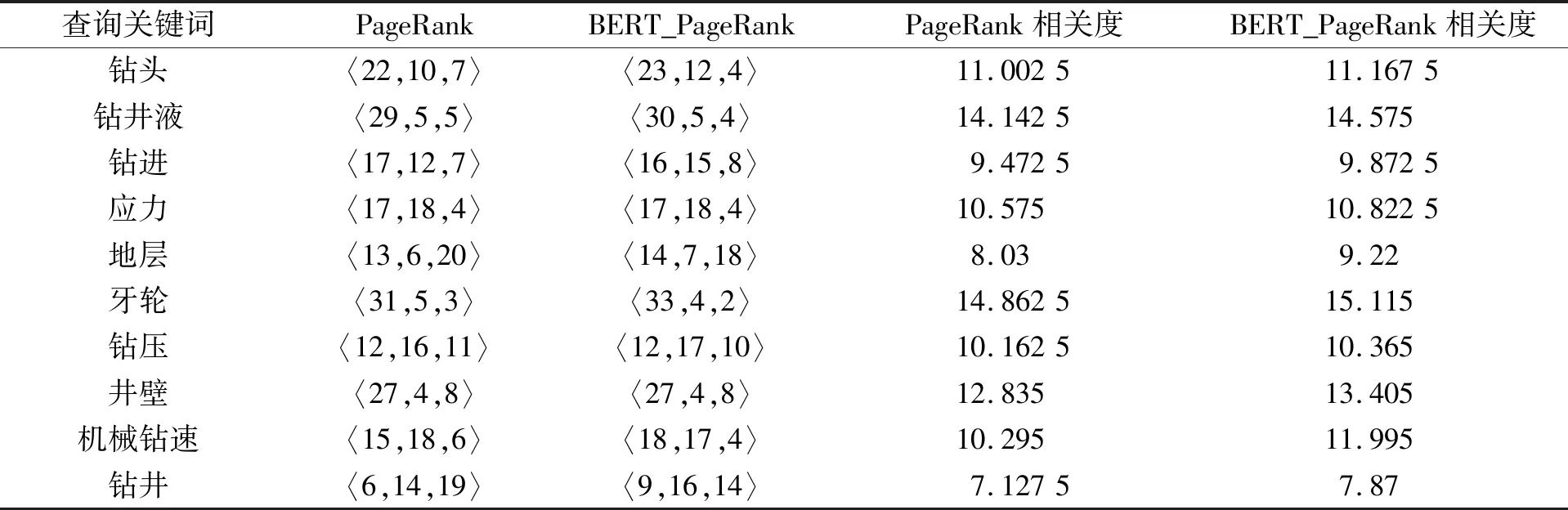
表2 排序结果对比Tab.2 Comparison of sorting results
从表2中可知,改进算法给出的检索结果高于传统的PageRank算法,在10个相关主题的查询条件下,从上至下各个查询项,改进算法比传统算法分别提升1.5%、3%、4.2%、2.3%、14.8%、1.7%、2%、4.4%、16.5%、10.4%,平均提高了6.1%,可见该方法对文献相似度的排序结果更接近专业人员的检索需求,具有一定的实用性。
5 结 语
针对PageRank算法应用于文献相关度排序时,由于引文参考程度不同,检索结果相关度排序不可靠的问题,笔者将具有注意力池化的孪生BERT深度学习网络与PageRank算法相结合,通过深度学习方法计算文献的相似度,使用文献相似度作为分配PR值权重改进算法中原本的平均权重分配方式。通过实验证明,改进后的算法在文献的引文网络分析方面,比传统的PageRank算法具有更高的相似度,排序结果更符合科研人员的检索需求。
由于笔者提出的模型目前只对石油钻井领域的文献进行相似度评估的相关实验,而石油钻井领域的文献具有涉及相关交叉学科,如机械专业、力学等专业的相关理论知识的特点,因此该方法也能适用于此类具备涉及多种交叉学科的科研领域文献的分析。下一步将继续研究该算法对其他科研领域文献的分析效果。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
名家名作(2021年4期)2021-05-12
成都信息工程大学学报(2021年6期)2021-02-12
科普童话·学霸日记(2020年1期)2020-05-08
计算机技术与发展(2019年1期)2019-01-21
小天使·一年级语数英综合(2019年2期)2019-01-10
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
智能计算机与应用(2018年2期)2018-05-23
