
基于改进粒子群算法的电力系统短期负荷预测
2022-09-30 01:48杨俊义朱殿超
吉林大学学报(信息科学版) 2022年3期
杨俊义,高 骞,洪 宇,朱殿超
(1.国网江苏省电力有限公司 a.发展策划部,南京 210024;b.连云港供电分公司,江苏 连云港 222000; 2.北京国电通网络技术有限公司 规划与计划管理业务事业部,北京 100085)
0 引 言
多分段短期负荷预测技术是稳定电力系统运行安全的重要保障和生产基础。负荷预测的主要作用就是对电力系统短期或长期的未来负荷指标进行估计判断,帮助电力企业人员作出下一阶段的决策。精准的预测报告可最大程度减少电力负荷、降低成本耗用,提高电力系统运行的稳定性,对未来电力行业发展具有重要意义[1]。
目前多分段短期负荷预测采用的主流方法有:时间序列预测法[2]、人工神经网络预测法[3]以及回归分析预测法[4]。这几种方法均采用直接预测,通过预先计算选取电力系统相似日的方式进行负荷预测。但由于相似日的优劣会直接影响预测精度,而这些方法不仅很难把握相似日的选取精度,还容易受外界天气因素的影响,导致对温度或风力变化的敏感性增强,干扰预测效果。负荷预测是一项具有连续性的工作,预测数据之间的关联性较强,一旦某个步骤出现误差,则影响其他步骤从而导致预测效果较差。
综合上述问题,笔者提出一种基于改进粒子群算法,从初始的种群选取到定义预测,均采用归一化统一化的管理模型,提高预测数据之间的连接性和逻辑性。增强数据的收敛性和迭代优化性,可以准确选取短期负荷预测的相似日,有效性和鲁棒性较强。
1 电力系统多分段短期数据预处理
为提高电力系统多分段短期负荷数据预测的准确性和时效性,要对原始的电力负荷数据进行预处理。将选取初始种群数据集中的数据进行归一化管理,去除原始负荷数据中的干扰或冗余量,具体操作步骤如下。
1) 初始种群选取。由于多分段短期数据的初始粒子种群随机性较强,实际状态下分布较为分散,不易获取且容易受干扰攻击。引入粒子群聚合概念,建立一种解空间,在该空间内进行全局最优搜索。通过不断迭代寻找,使负荷粒子均匀分布在整个空间内,不仅能提高初始数据选取的优异性,还能减少外界干扰。解空间的数据定义为

(1)
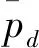
D(t)可概括解空间中全部负荷数据粒子的离散分布状况,D(t)数值越小,解空间中的粒子种群分布越为集中;D(t)数值越大,解空间中的粒子种群分布越为分散[5]。
2) 原始数据归一化处理。对得到的粒子群种群分布的原始负荷数据进行归一化处理,且确保初始的输入样本的数据变动范围在[-1,+1]之间。通过历史数据的迭代计算,得到数据分布在[0,1]范围内时,预测效果最佳,即
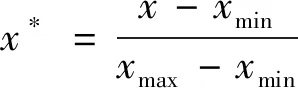
(2)
其中xmin表示历史负荷数据样本中的最小数值;xmax表示历史负荷数据样本中的最大数值;x*表示进行归一化处理后的数值。当xmax=xmin时,取值为中值0.5。
将该中值带入激励函数中,根据电力系统的实时变化情况,对参数进行调节,得到适应度最高的归一化数值[6-7]。
2 改进粒子群算法
在原始的粒子群算法中,为得到粒子群中的最优状态值ξ和ζ,通过最优目标函数计算得出适应度最高值,将该数值引入到粒子群中,以每个粒子的速度和位置判定实现求解[8]。
将ξ和ζ看做粒子群算法中的期望适应粒子[9],设负荷粒子的初始步长为λ,令λ=1,利用该步长生成最新粒子,公式为
Vik(t+1)=wVik(t)+c1r1[Pik(t)-Xik(t)]+c2r2[Pdk(t)-Xid(t)]
(3)
Xik(t+1)=Xik(t)+Vik(t+1)
(4)
其中r1和r2表示服从步骤2)得到的数据变动结论[0,1]内的随机数;c1和c2表示加速度数值;w表示权重值。
根据负荷数据的显著特征,利用线性递减规律提高算法的数据收敛效果[10-11]。用wmax表示加权系数的最大值;用wmin表示加权系数的最小值;u表示迭代次数;umax表示迭代最大次数,则有

(5)
计算得到更新后的负荷粒子Xi(t+1),不断逼近更新后的粒子期望值Xi(t),得到迭代公式为

(6)
以这种迭代更新的方式,得到粒子群优化的位置及速度更新方程
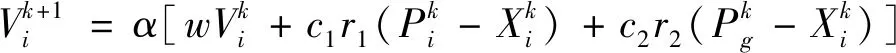
(7)

(8)
w是粒子群算法改进的决定性因素,通过递减策略得到关键的改进公式
w(ψ)=(wini-wend)(Tmax-ψ)/Tmax+wend
(9)
其中ψ表示优化次数;Tmax表示最大改进值;wini表示初始权重值;wend表示改进过程中决定的权重,该值决定了粒子群改进的优异程度。
3 电力系统多分段短期负荷预测算法实现
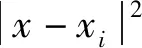
为使局部核函数和全局核函数二者的优点能有效结合,结合优异性的分类能力,并考虑核函数的组合价值,使其负荷预测满足线性变化条件[13],可得
K(x,xi)=αKlocal+βKglocal
(10)
其中α、β表示负荷预测函数的权值系数,令α+β,且α≥0、β≥0,通过改变权值的大小确定局部、全局预测函数的关系。根据该特点推导基于粒子群及局部、全局预测函数[14]。
根据推导原理建立包含N天电力负荷信息的数据矩阵

(11)
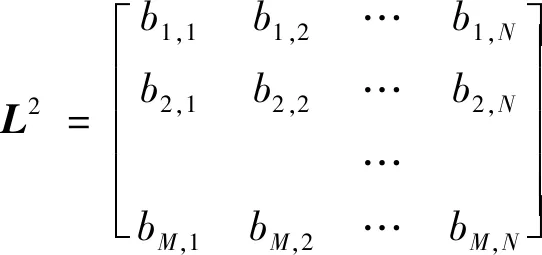
(12)

(13)
其中aM,N、bM,N表示M,N点的负荷数据;ηj表示预测矩阵中第j例数据的预测平均值;μi表示预测矩阵中第i例数据的预测标准差。
4 仿真实验
4.1 实验背景
实验从关系数据库管理系统(RDBMS:Relational Database Management System)中挑选北京市某一化妆品加工厂电力系统,从2021年8月26日-31日6天的电力负荷数据。以这6天的负荷数据作为仿真实验样本,通过监测仪器得到这6天内加工厂用电量和负荷数据如表1所示。

表1 电力加工厂系统6日用电及负荷量Tab.1 Electricity consumption and load of the power processing plant system in 6 days
4.2 多分段短期负荷预测结果
电力系统的总负荷数据量为2 000个,从中挑选500个数据进行预测学习,剩余1 500个进行分段短期负荷预测实验。仿真实验结果如图1所示。

图1 基于改进粒子群算法负荷预测结果Fig.1 The load prediction results based on the improved particle group algorithm
从图1可以看出,笔者对电力系统的预测结果与实测结果曲线吻合度较高,变化范围基本一致,说明笔者方法的预测精准度较高。算法之所以没有出现误差影响,是因为初始数据的粒子种群选取、原始数据归一化管理,再到最后负荷预测,都严格遵循最优函数原理。保证参数负荷中所有数据粒子,都经过最优筛选和改进,通过逐步寻优,不断剔除其中的噪声干扰,从而达到最佳预测状态。
由于笔者使用的改进粒子群算法,属于小样本学习算法,数据收敛量较小。但从实验结果可以看出,无论是学习过程还是测试过程,笔者算法都表现出较好的预测效果,充分体现了算法的
实用价值。
量化评价指标采用平均绝对偏差值(Mean Absolute Percentage Error,MMAPE)和均方根误差(Mean Squared Error,MMSE),计算公式为

(14)
其中ot表示观测值;pt表示预测值。

(15)

基于指标判定的仿真实验结果如图2、图3所示。

图2 基于平均绝对偏差值的预测结果 图3 基于均方根误差的预测结果Fig.2 Predictions based on the mean absolute deviation values Fig.3 Prediction results based on the root mean square error
从图2和图3可以看出,无论是平均绝对偏差值还是均方根误差指标,笔者方法实验结果表现都极为优秀。其中平均绝对偏差值曲线波动范围整体在0.015~-0.015之间,偏差波动不大,属于稳定的正常变动趋势;均方根误差曲线随着预测数量的增加,呈小幅度增长,增长幅度都在可承受范围内,并没有因数据量的骤增而降低预测精准度。从二者指标的评判结果可看出,方法具有较强的适应能力,对电力系统的负荷数据预测精准度较高。经过改进粒子群算法减少了原始算法的盲目性和随机性,增强了负荷粒子的聚集性,方便归一化管理,使预测均值的寻优能力增强,预测结果更为精确。
5 结 语
电力系统负荷属于一种非线性的变化模型,笔者采用较为成熟的改进粒子群算法,更好、更快地解决因外界干扰噪声过多、维度过高、样本数量过小而导致的预测精准度不高等问题。采用改进粒子群算法,通过迭代交叉策略改善了原始算法对多样负荷数据接纳度不高、收敛效果较差现象,使后续数据处理更具有规范性和有效性。仿真实验证明,笔者算法预测精准度较高、对负荷数据的收敛效果较好,可应用到实际电力系统工作中,对电力系统未来的发展与应用具有重要帮助。
猜你喜欢
今日农业(2022年15期)2022-09-20
当代陕西(2020年24期)2020-02-01
小学生学习指导(低年级)(2018年11期)2018-12-03
生物学教学(2018年3期)2018-08-08
中学生物学(2018年8期)2018-03-01
中学生数理化·高一版(2018年1期)2018-02-10
理科考试研究·高中(2016年10期)2017-01-17
安徽农学通报(2016年20期)2016-12-26
太空探索(2016年9期)2016-07-12
科技与创新(2015年2期)2015-02-11
