基于离子淌度质谱的代谢物碰撞截面积测量方法和数据库研究进展
2022-09-29 04:48李彤洲朱正江
质谱学报 2022年5期
陈 曦,李彤洲,朱正江
(1.中国科学院上海有机化学研究所,生物与化学交叉研究中心,上海 200032; 2.中国科学院大学,北京 100049)
代谢组学旨在系统性地研究复杂生物样本在内部和外界条件影响下,代谢物数目、种类、含量发生的变化及规律[1]。代谢组学处于基因组学、蛋白质组学的下游,与生物表型直接相关。因此,代谢组学能够提供个体分子表型层面的信息,并进一步揭示表型与基因、转录之间的联系[2]。目前,代谢组学被广泛应用于发现与疾病相关生物标志物、研究疾病发病机理等生命科学领域。代谢物具有化学结构复杂多样、浓度分布范围广等特点。因此,对复杂生物样本中的代谢物进行高覆盖、高准确地分析仍然存在挑战[3-4]。
近年来,离子淌度质谱(IM-MS)技术广泛用于代谢组学研究[5-8]。在电场作用下,代谢物离子在淌度池内与惰性气体发生碰撞,从而实现不同结构或构象代谢物的分离[9-11]。离子淌度提供了不同于传统分离策略的新维度分离,能够有效提高分离效率、降低化学噪声、提高信噪比、增加峰容量,并实现对代谢物同分异构体的更好分离[5,11-12]。离子淌度可以提供离子碰撞截面积(CCS),这是基于代谢物结构的物理化学性质,在不同仪器、不同实验室间均具有良好的重现性,可提高代谢物鉴定的可靠性[13-15]。除此之外,CCS可与离子的质荷比(m/z)、保留时间以及二级质谱(MS/MS)图结合使用,进一步提升代谢物鉴定的准确度[5,11,16]。因此,CCS的准确测量及数据库建立对于支持IM-MS在代谢组学中的广泛应用具有重要意义。
目前,根据离子淌度分离类型,可将用于代谢组学研究的商业化离子淌度质谱技术分为时间分离型、空间分离型和选择与释放型等3类[17-18]。具体仪器类型包括漂移管离子淌度(DTIMS)[19]、行波离子淌度(TWIMS)[20]、捕集型离子淌度(TIMS)[21]、差分离子淌度(DMS)[22]和高场非对称波形离子淌度(FAIMS)[23]。上述离子淌度技术的分离原理及CCS测量原理不同。为实现CCS的准确测量,研究者们系统研究了不同类型离子淌度质谱测量CCS值,并对测量结果进行了比较和评估[18]。基于实验测量得到的化学标准品的CCS值,被收集创建为实验CCS值数据库,并应用于代谢组学中代谢物的鉴定[14,24]。为进一步扩大数据库覆盖范围,近年来,基于计算建模和机器学习算法预测CCS值的方法应运而生,能够准确、大规模地计算CCS值并用于代谢物鉴定[25-27]。
本文将首先介绍常用于代谢组学的离子淌度质谱的基本原理,并总结不同类型离子淌度质谱在CCS值测量与校正方面的研究进展。最后,综述用于代谢组学研究的CCS值数据库,包括实验测量、理论计算、机器学习预测等方法建立的数据库。
1 适用于代谢组学的常见离子淌度质谱介绍
1.1 漂移管离子淌度质谱
漂移管离子淌度质谱(DTIMS-MS)是一种时间分离型离子淌度质谱技术,其结构示意图示于图1a。DTIMS主体部分是由一系列堆积电极组成的漂移管。漂移管的电极在水平方向上产生均匀电场,受到电场力推动作用的离子在漂移管内运动。漂移管中填充了惰性气体(如氮气、氦气等),在电场力驱动下的离子与漂移管内的惰性气体发生碰撞,并阻碍离子运动。对于具有相同电荷数的离子,其受到电场力的推动作用相同。但由于化学结构不同,离子与缓冲气体发生碰撞时受到的阻力不同。离子结构越紧凑,其发生碰撞的机会越少,具有更快的漂移速度和更少的漂移时间,从而实现不同离子的分离[10]。在施加较低电场时,漂移时间与漂移率之间存在较好的相关性,可以通过漂移时间实现CCS的测量和计算。DTIMS-MS的代表性商业化仪器主要是Agilent公司生产的6560 DTIMS-QTOF系统。目前,该仪器的离子淌度分辨率约为60[28],在使用最新的多路复用技术(HRdm)时,离子淌度分辨率可提高至200左右[71]。
1.2 行波离子淌度质谱
行波离子淌度质谱(TWIMS-MS)是一种时间分离型离子淌度质谱技术,其淌度池由一系列环形堆叠电极构成,其结构示意图示于图1b。与DTIMS不同,TWIMS不仅在水平方向施加直流电压使离子沿轴向运动,而且在环形电极的垂直方向施加周期性的射频电压,限制了离子的径向运动。因此,离子在淌度池内形成了类似形波的运动轨迹。由于淌度池内惰性气体的存在,结构较紧凑的离子受到更小的阻力作用,在淌度池内的行波运动轨迹总长度较短、运动时间较短,反之亦然,从而实现不同结构离子的分离[29-30]。由于施加了径向电压,漂移率和漂移时间的相关性被破坏,需要使用校准物来实现CCS的测量和计算。TWIMS-MS的商业化仪器主要包括Waters Synapt系列质谱仪、Waters Vion系列质谱仪和Waters SELECT Cyclic IMS质谱仪。其中,Synapt系列仪器的淌度分辨率约为40~60,Cyclic IMS仪器的淌度分辨率可达400[20,31]。
1.3 捕集型离子淌度质谱
捕集型离子淌度质谱(TIMS-MS)属于选择与释放型离子淌度质谱技术。TIMS同样是在气体和电场共同作用下实现不同结构离子的分离,但与DTIMS和TWIMS使用静态气体不同,TIMS使用惰性气体(如N2)作为推力,将离子推向出口漏斗,同时施加相反的电场力将离子拖回到入口漏斗[32-33],示于图1c。电荷相同但化学结构或构象不同的离子受到的电场力相同,但气流推力不同,从而实现离子分离。随着电场力的下降,结构较松散的离子首先被释放;电场力进一步下降,结构较紧凑的离子较晚被释放出来。Bruker公司将TIMS-MS商业化,以TIMS TOF Pro仪器为例,其离子淌度分辨率可以达到约200[28]。
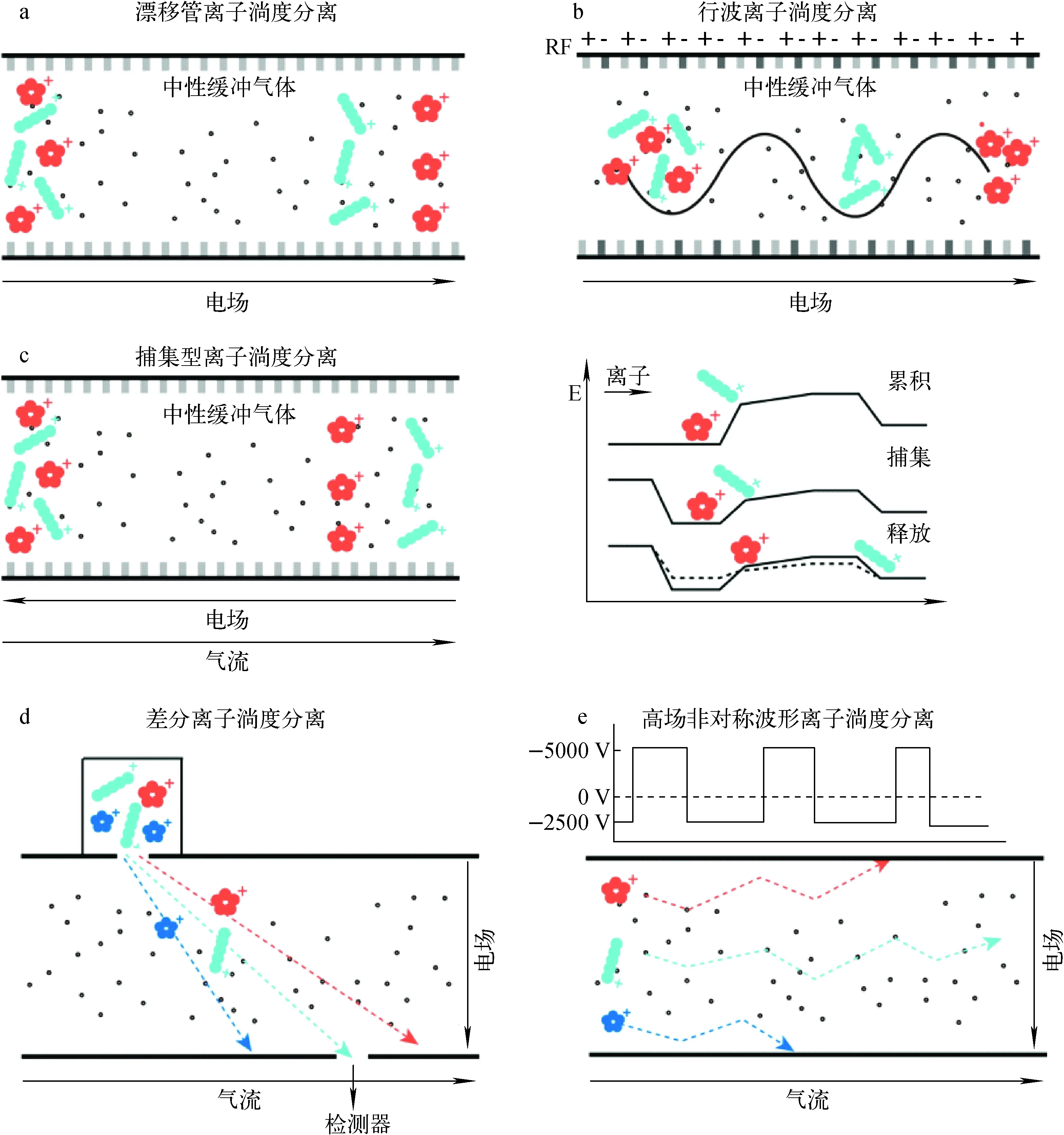
注:a.漂移管离子淌度;b.行波离子淌度;c.捕集型离子淌度;d.差分离子淌度;e.高场非对称波形离子淌度图1 适用于代谢组学的常见离子淌度原理示意图Fig.1 Schematic illustrations of common commercial ion mobility instruments for metabolomics
1.4 差分离子淌度质谱和高场非对称波形离子淌度质谱
差分离子淌度质谱(DMS-MS)和高场非对称波形离子淌度质谱(FAIMS-MS)均属于空间分离型离子淌度质谱技术,其结构示意图分别示于图1d,1e。它们的原理相似,在2个电极之间施加1个高不对称电场,同时增加1个反向的补偿电压,交替施加2个电压,使不同离子在漂移管中具有不同的路径,实现特定离子的分离[23]。由于其具有高选择性,常用于靶向代谢组学的研究。然而,在动态变化电场作用下,离子的运动轨迹与CCS之间的相关性构建仍然是一项挑战。目前,商业化的DMS/FAIMS代表仪器主要有Sciex公司的SelexION技术和Thermo Fisher公司的FAIMS技术,它们都可以与高分辨质谱(如飞行时间质谱、静电场轨道阱质谱)联用。
2 各类离子淌度质谱CCS测量原理及校正
不同类型离子淌度质谱的基本原理存在差异,相对应的CCS测量方法也不同[16-17]。对于目前常见的商业化离子淌度质谱,CCS的测量通常可以分为校准物非依赖型方法(calibrant-independent approach)和校准物依赖型方法(calibrant-dependent approach)。最近,为解决DMS不能有效测量CCS的问题,Hopkins课题组[34]提出机器学习依赖的校正方法(machine learning-based calibration)。不同类型离子淌度质谱的特点以及CCS测量方法的情况列于表1。

表1 常见离子淌度质谱仪特点和碰撞截面积的测量方法Table 1 Characteristics of common IM-MS instruments and CCS measurements
2.1 漂移管离子淌度质谱CCS测量
2.1.1多漂移电场法 目前,DTIMS-MS中的多漂移电场法(stepped-field method)是唯一的校准物非依赖型CCS测量方法。对于漂移管离子淌度,当施加较低电场时,漂移率和漂移时间存在良好的相关性。在不同的漂移电场下,通过测量离子的漂移时间,并依据Mason-Schamp方程(式1)可以直接计算化合物的CCS值[19,35]。
(1)
式中,kb为波兹曼常数,T为漂移管内温度,z为离子的电荷数,e为电荷量,mI为离子的质量数,mB为缓冲气体的质量数,tA为测量到达时间,E为电场强度,L为漂移管长度,P为漂移管内缓冲气体压力,N为标准气压与温度下缓冲气体的数密度。
该方法首先测量了多个电场条件下(至少5个)的漂移时间,通过建立漂移时间与其相对应电场电压倒数的线性回归方程,得到方程的斜率,进一步计算CCS值。多漂移电场法具有较高的测量可重复性,Stow等[35]对该方法进行了系统评估,在4个不同实验室测量CCS值的相对标准偏差仅为0.29%,示于图2a。该方法是校准物非依赖型,被认为是CCS值测量的金标准。但由于需要在至少5个不同电场条件下对同一样本进行测量,使测量时间增加,同时限制了与其他分离技术(如液相色谱)的兼容。
2.1.2单漂移电场法 单漂移电场法(single-field method)是基于DTIMS-MS的另一种CCS测量方法,属于校准物依赖型。单漂移电场法需要在固定的电场条件下进行实验,首先使用已知CCS值的标准校准物(如Agilent ESI-L low concentration tune mix)测量校准物的漂移时间,并建立漂移时间与CCS值的线性关系方程(式2)[35-36]。通过式(2),可以得到与CCS值计算有关的2个系数:漂移管外的飞行时间(tfix)和仪器依赖型的比例系数(β)。最后依据式(2)和式(3)计算离子的CCS值。
tA=βγ·CCS+tfix
(2)
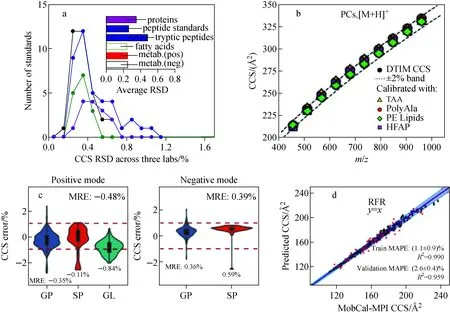
注:a.在DTIMS中使用多漂移电场法测量CCS值的准确性和重复性[35]; b.在TWIMS中使用不同校准物测得脂质标准品CCS值[40]; c.TIMS测得人血浆中脂质CCS实验值与DTIMS测得实验值的相对偏差分布[43]; d.在DMS中基于机器学习校正方法测量的CCS值与MobCal-MPI计算的CCS值比较[34]图2 不同离子淌度质谱CCS值测量准确性Fig.2 Accuracy of CCS values measured with different IM-MS
(3)
式(2)中,γ为校正质量系数,可通过式(3)计算得到。
Kurulugama等[36]报道了使用单漂移电场法测量CCS值的相对标准偏差为0.54%。相比于多漂移电场法,单漂移电场法的测量通量更高,且可与液相色谱联用,在代谢组学分析中有更广泛的应用[37]。
2.2 行波离子淌度质谱CCS测量
在行波离子淌度质谱中,CCS值的测量方法是校准物依赖型。TWIMS-MS使用已知CCS值的校准物构建CCS值与漂移时间的非线性校准曲线。利用该曲线以及实验测量得到的被分析离子的漂移时间,可以计算得到被分析离子的CCS值[30]。目前,使用较广泛的校准物有聚丙氨酸低聚物(polyalanine oligomer)和Agilent ESI-L low concentration tune mix。这些校准物具有较好的化学稳定性,m/z与CCS值的覆盖范围较广,并且与代谢物的结构较接近,因此有较广泛的应用[20,38-39]。然而,Xu等[40]发现,所选取的校准物与被分析物的化学结构相似性显著影响了TWIMS-MS仪器上CCS值测量的准确性。在使用TWIMS-MS分析脂质分子时,如果以胰蛋白酶肽作为CCS校准物,实验测得的脂质CCS值与从DTIMS获得的标准值相比,平均相对偏差高达6.4%。与之相反,如果以脂酰磷酸乙醇胺混合物作为校准物,平均相对偏差可以降至2%以内,示于图2b。因此,在使用TWIMS-MS测量CCS值时,有必要选择与被分析物结构类似的校准物用于校正。
2.3 捕集型离子淌度质谱CCS测量
近几年,捕集型离子淌度质谱发展迅速,基于TIMS-MS仪器的CCS值测量方法同样是校准物依赖型。TIMS-MS使用已知迁移率(K0)的校准物,通过建立迁移率的倒数(1/K0)与电压之间的线性关系得到校正方程。根据校正方程与仪器记录的电压计算得出被分析离子的迁移率。进而根据式(4)计算得到CCS值[33]。
(4)
TIMS-MS仪器常用的校准物为Agilent ESI-L low concentration tune mix[21,41-42]。朱正江课题组[43]使用该校准物,在测量人血浆得到的567个脂质中,基于TIMS-MS得到的CCS值与基于DTIMS-MS单场测量得到的CCS值相比,约90%脂质CCS值的相对偏差在1%以内,示于图2c。此外,Cazares课题组[44]比较了使用TIMS-MS在尿液样本中测得362个代谢物的CCS值与其他实验室报道的CCS值,平均相对偏差在1.3%以内。这些研究均表明了TIMS-MS在CCS值测量上的准确性。
2.4 差分离子淌度质谱CCS测量
由于DMS中存在动态变化的电场作用,构建离子的运动轨迹与CCS值之间的相关性一直是难题。2021年,Hopkins课题组[34]使用基于机器学习的校准方法测量离子的CCS值。在正离子条件下,作者利用409个化学小分子作为训练集,使用多种机器学习方法,在氮气环境、分离电压为1 500~4 000 V下建立了CCS值、质荷比与洗脱所需补偿电压的关系。在使用随机森林(random forest)方法时,预测得到CCS值的平均误差为2.6%,示于图2d。使用机器学习的方法实现了DMS仪器对小分子化合物CCS值的测量。但由于训练集中小分子数量以及结构多样性的限制,使用基于机器学习校正测量的CCS值仍有较大偏差。因此,进一步提高训练集覆盖范围将会提升CCS值的预测准确性。
3 代谢物实验CCS值数据库的发展和应用
CCS值作为代谢物小分子的一种物理化学性质,具有高度重现性、稳定性。研究表明[13-15],将CCS值作为新的维度加入代谢物鉴定中,可以有效提高代谢物鉴定的准确性。过去10年,研究者通过采集代谢物标准品的实验CCS值来构建高准确的代谢物CCS值数据库,示于图3a。本文对2014~2022年报道的主要小分子化合物实验CCS值数据库进行总结,列于表2。归纳了25个通过实验获取的CCS值数据库,涉及DTIMS-MS、TWIMS-MS和TIMS-MS这3种类型离子淌度质谱仪,涵盖极性代谢物、脂质、药物和天然产物等多种类型化合物。2016年,朱正江课题组[26]利用DTIMS-MS仪器采集了617个化合物的953个CCS值,构建了综合性的小分子代谢物实验CCS值数据库,对鉴定生物样品内代谢物提供了重要帮助。2019年,Nye等[45]使用TWIMS-MS仪器收集了510个代谢物的942个CCS值。同年,Picache等[46]整合了1个新的代谢物CCS值数据库,收录了1 142个化合物的3 271个实验CCS值,并提供免费下载。近年来,对化合物CCS值的研究逐步拓展到脂质组学领域。Paglia等[14]使用TWIMS-MS构建了脂质代谢物的实验CCS值数据库,包含12类脂质共244个脂质代谢物。2020年,Vasilopoulou等[21]使用TIMS构建了包含1 856个脂质的实验CCS值数据库。除了常规脂质代谢物,特殊脂质分子的研究也有进一步发展。2018年,Hernández-Mesa等[47]构建了类固醇类代谢物的实验CCS值数据库,用于食品安全和兴奋剂检测等领域。药物小分子是病理和临床研究的重要对象,2017年,Hines等[48]对1 425个药物及其类似物进行离子淌度质谱分析,采集了1 440个实验CCS值,建立了药物分子的实验CCS值数据库。2019年,Schroeder等[42]使用TIMS-MS构建了146个植物天然产物的实验CCS值数据库。
4 CCS计算数据库的发展和应用
虽然实验CCS值数据库发展快速,但由于化合物标准品数目和淌度分辨率的局限性等原因,与已知的代谢物数目相比,实验CCS值数据库化合物种类的覆盖范围有限。解决此类问题的主要方法是发展计算CCS值数据库。目前,构建计算CCS值数据库的方法主要有计算化学方法和机器学习方法这2种策略。本文对2014~2022年报道的12个CCS计算数据库进行总结,列于表3。
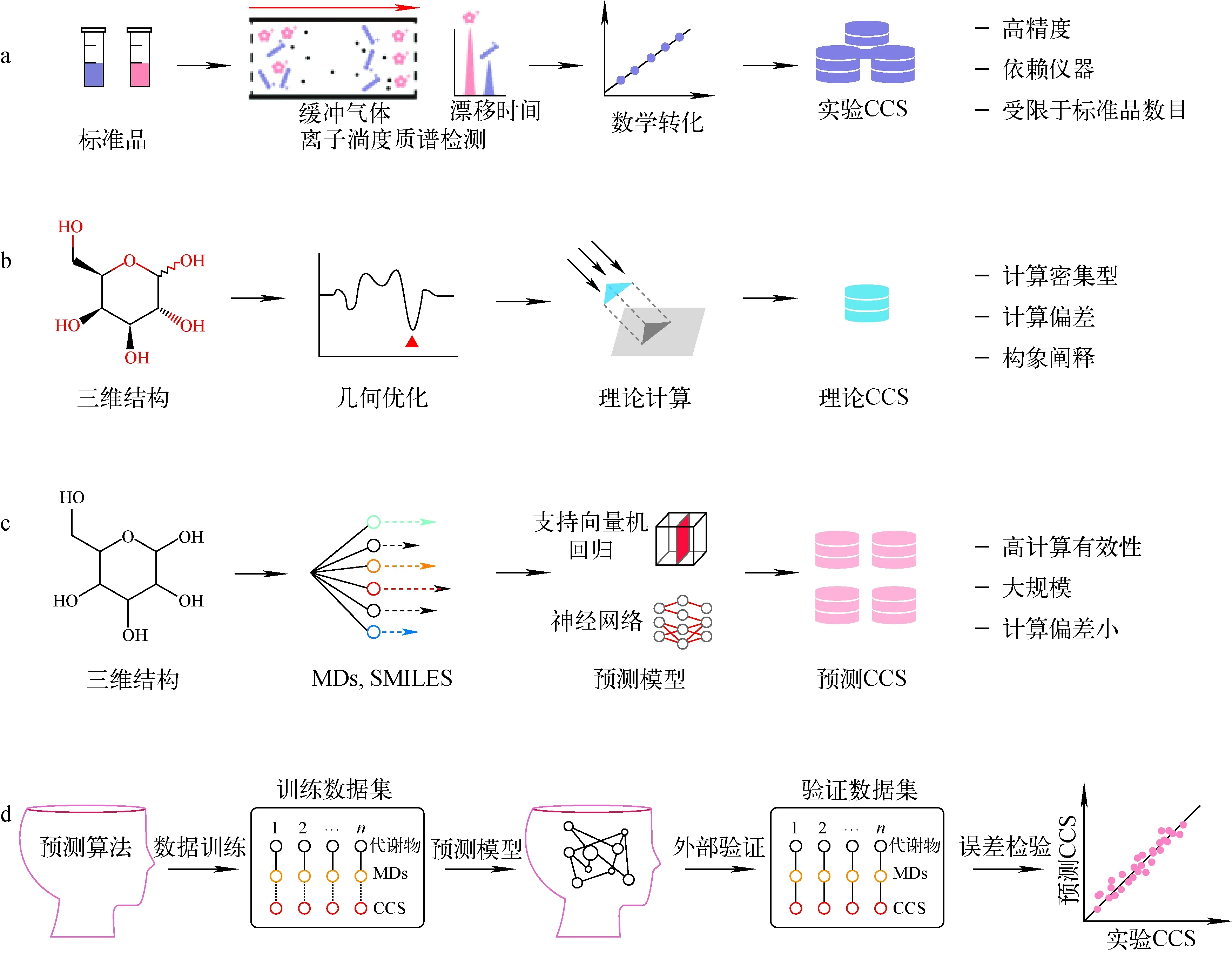
注:a.实验测量方法;b.计算化学方法;c.机器学习方法;d.构建基于机器学习方法的预测CCS值数据库图3 构建小分子代谢物CCS值数据库的主要策略Fig.3 Strategies for the curation of CCS databases for metabolites
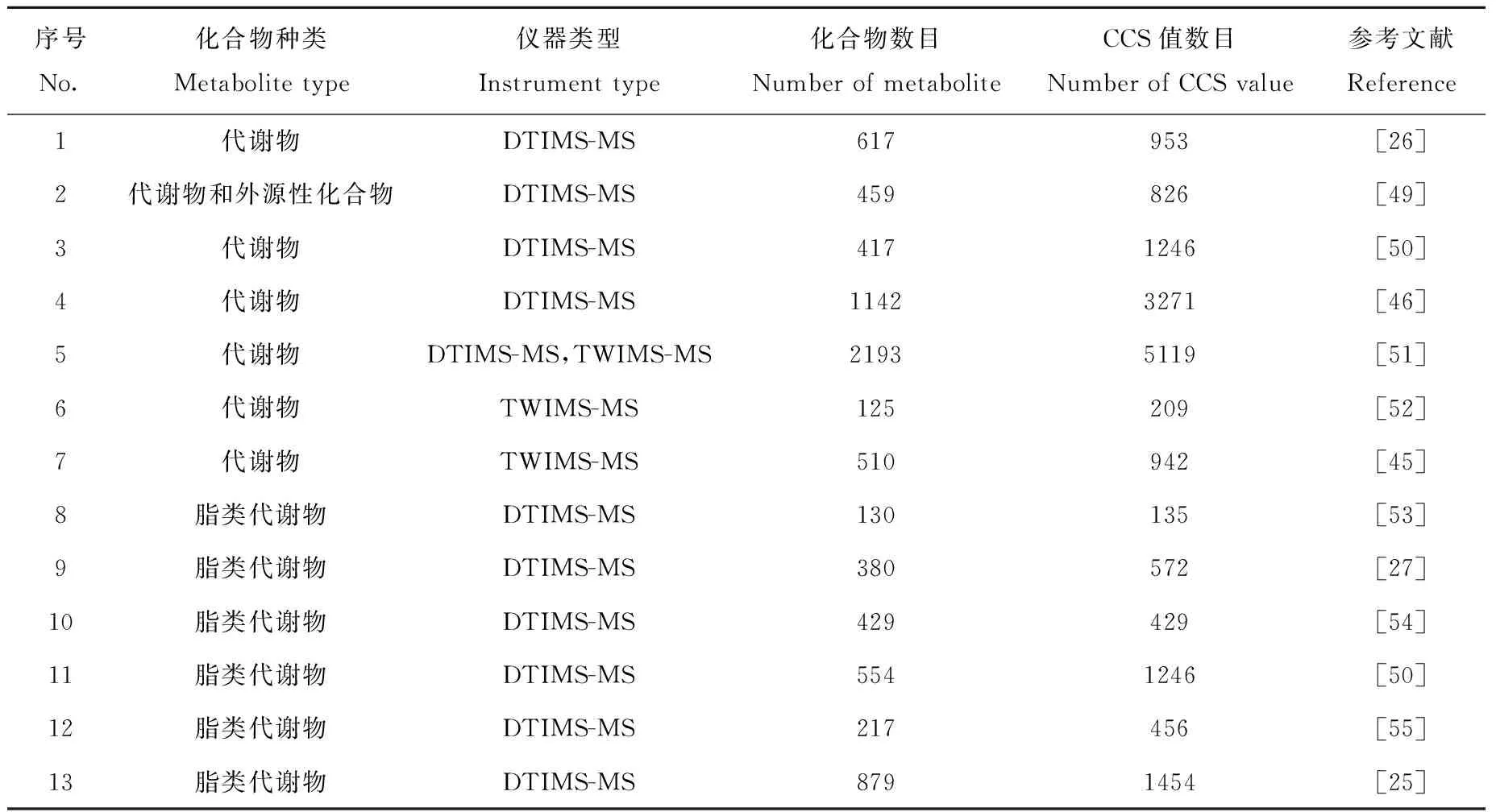
表2 小分子化合物实验CCS值数据库Table 2 Experimental CCS databases for small molecules
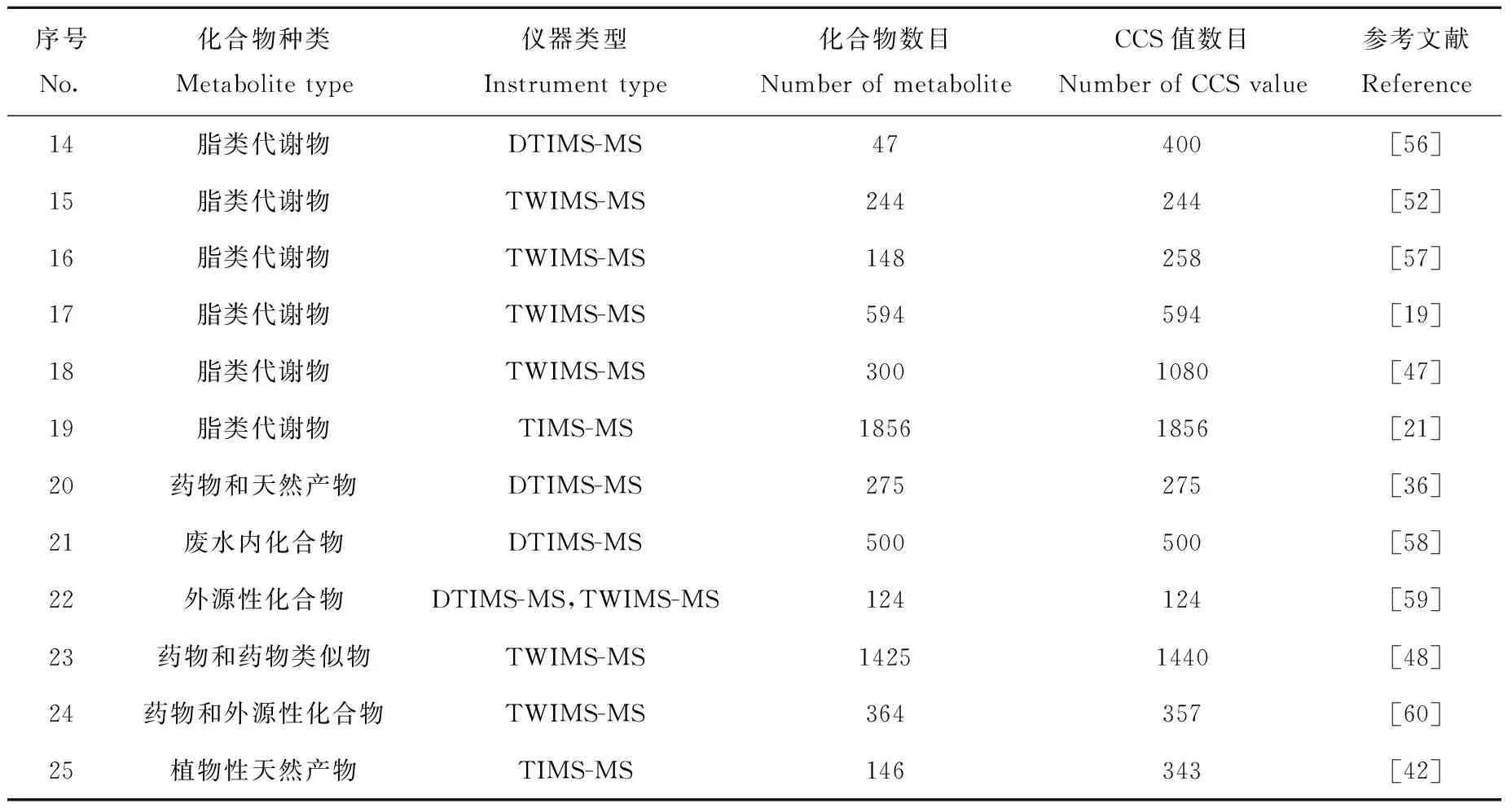
续表2
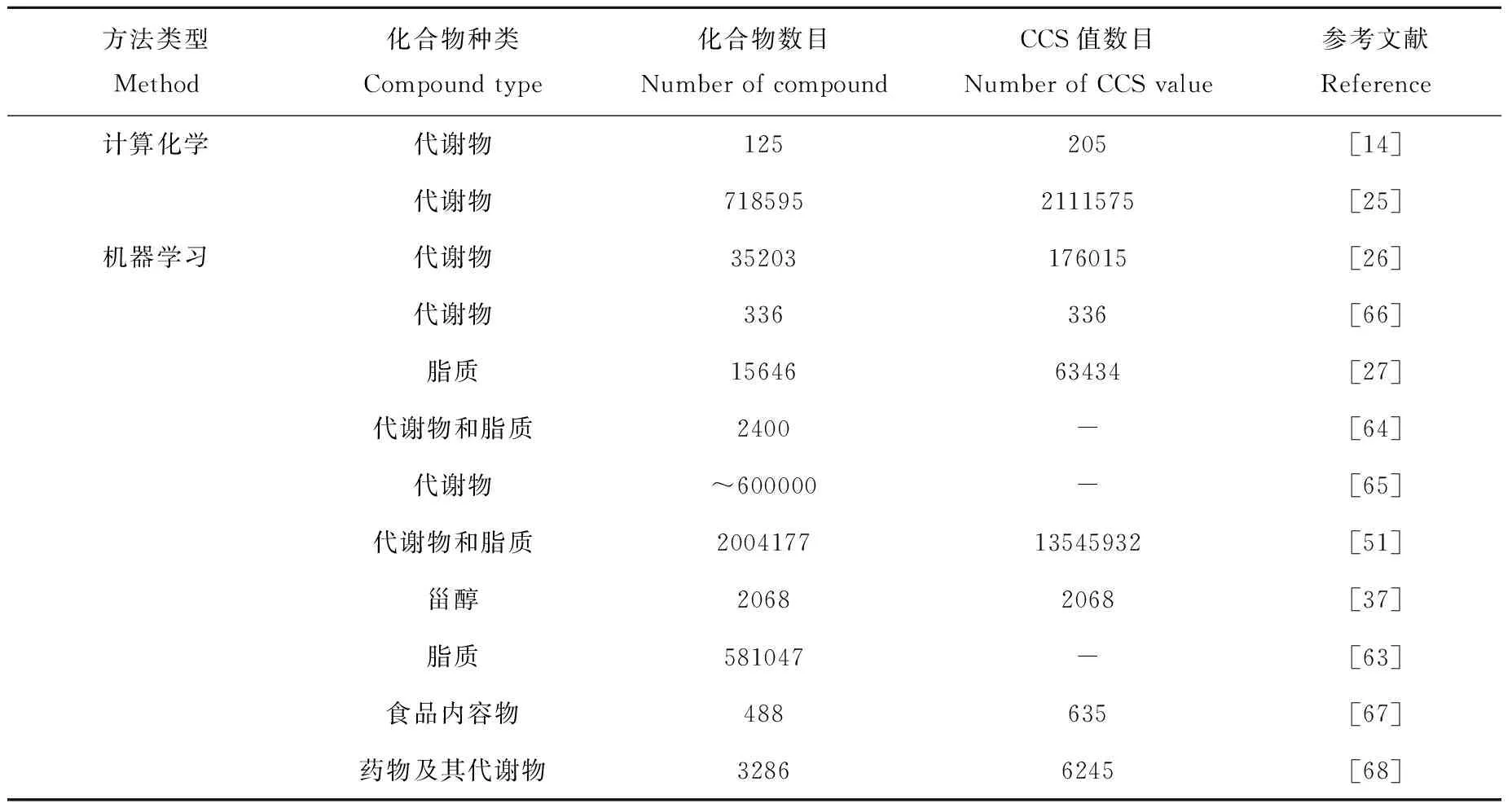
表3 基于计算化学方法和机器学习方法构建的CCS值数据库Table 3 CCS databases obtained from computational chemistry and machine-learning methods
计算化学方法首先将化合物结构转化为三维结构,示于图3b。此时,通常会生成此化合物所有可能的构象形式,利用分子力学、分子动力学和密度泛函法等对构象进行几何优化,然后输出能量最小的1个或者若干个构象,最后导入MOBCAL和Collidoscope等专业软件,选择合适的算法计算化合物的理论CCS值。MOBCAL可提供投影近似(PA)、精确硬球散射(EHSS)和轨迹法(TM)等3种算法计算CCS值[61];Collidoscope是基于轨迹法算法,但其使用并行计算和优化轨迹参数,计算时间显著减少[62]。Paglia等[14]最初使用MOBCAL计算代谢物的CCS值,并构建了含有205个代谢物CCS值的数据库。2019年,Colby等[25]提出了使用优化的MOBCAL核心理论化学库引擎(ISiCLE),它可以使用化学识别符作为三维构象信息进行输入,利用分子动力学、量子化学和离子迁移率计算生成结构和化学性质库,最终输出计算CCS值。目前,计算化学方法有一定局限性,其计算和逻辑判断量大,需要消耗大量CPU资源,计算时长需要几天甚至几周,而且有研究指出[71],此策略对于脂质等柔性化合物的计算偏差较大。
第3种建立小分子代谢物CCS值数据库的方法是机器学习,示于图3c、3d。发展以机器学习方法为核心的CCS值计算方法一般需要3个模块:1组训练数据集、1个预测算法和1个验证数据集。该方法的建立一般需要预测模型的构建和预测模型的验证2步。直接使用实验数据作为数据训练,利用机器学习算法学习代谢物化学结构性质与CCS值的联系,并构建二者之间的数理关系,然后使用另一组实验数据验证预测模型,评估预测误差,示于图3d。训练数据集通常为实验CCS值数据集,验证数据集的格式与训练数据集一致,而且是1组不重复于训练数据集的实验数据。因为CCS值在一定程度上反映了代谢物的化学结构性质,所以训练集还包含了可以反映代谢物化学结构理化性质属性的分子描述符(molecular descriptors,MDs),如logP和pKa等。分子描述符可直接从代表代谢物化学结构的简化分子线性输入规范(SMILES),通过计算化学软件包(如rcdk等)获得。机器学习算法主要用于构建代谢物分子描述符与CCS值之间的数理关系。目前,最常用的机器学习包括支持向量回归(SVR)算法和神经网络算法。SVR算法是用核函数将分子描述符映射到1个高维特征空间,并在超几何平面内将分子描述符和CCS值进行高维回归;神经网络算法是通过几个隐藏层的阈值激活函数,在输入值和输出的CCS值之间构建人工神经元连接网络。为获得具有最佳预测能力的模型,预测算法中的参数通常需要进行迭代优化。
使用机器学习方法可以快速(以s为单位)计算小分子化合物的CCS值,且不需要耗费大量的计算资源,预测误差在1%~3%。2016年,朱正江课题组[26]首先发展了基于支持向量回归算法计算CCS值的方法,并创建了首个大规模的代谢物预测CCS值数据库MetCCS。MetCCS含有超30 000个代谢物的超170 000个CCS值,通过将代谢物预测的CCS值与实验值相比,相对偏差中位值约为3%。朱正江课题组[27]继续使用此策略开发了包含15 646种脂质的预测CCS值数据库LipidCCS,在正离子模式下以训练数据集脂质分子的221个分子描述符作为输入值,CCS值作为输出值,阶梯式筛选与CCS值相关性较强的45个MDs作为优势分子描述符。作者利用支持向量回归算法进行数据训练,获得优势分子描述符与CCS值的高维回归关系。最后,再用外部验证数据集对预测CCS值和实验CCS值进行对比,发现相对偏差中位值约为1%[27]。最近,朱正江课题组[37]针对特殊代谢物甾醇,用支持向量回归算法构建了大规模的甾醇预测CCS值数据库,并在软件Sterol4DAnalyzer内用于甾醇的鉴定。基于机器学习的CCS值预测受限于训练数据集的大小,训练集覆盖代谢物数目和种类较少会导致较低的准确性。2020年,朱正江课题组整合并使用来自14个实验数据集的超过5 000个实验CCS 值作为大规模训练集,利用优化的支持向量回归算法,开发了第二代CCS值计算方法AllCCS,并建立了目前世界上最大的小分子化合物CCS值数据库(http:∥allccs.zhulab.cn/)。AllCCS数据库包含了超2 000 000个化合物的超13 500 000个CCS值[51]。对于不同类别的小分子化合物,通过AllCCS计算获得的CCS值相对偏差中位值约为0.5%~2%。最近,Tsugawa等[63]使用含101个脂质亚类的超过3 500个脂质离子的CCS值作为训练集,利用机器学习算法XGBoost预测CCS值,错误发现率约为2%。
在基于神经网络算法开发CCS值计算方法方面,Plante等[64]开发了使用神经网络算法的CCS预测方法DeepCCS,可直接使用化合物的SMILES和离子类型的信息作为输入值,建立其与CCS值的人工神经网络,预测了2 400个化合物的CCS值,其相对偏差中位值为2.7%。2020年,Colby等[65]提出了一种新的基于神经网络算法的CCS值计算方法DarkChem,该方法的核心是从PubChem数据库内直接学习不同化合物的结构特征,并拓展应用于预测化合物的其他物理化学特征。此方法从大型结构数据集PubChem出发,以SMILES为输入,以m/z输出,进行初始性分子结构表征学习,并建立神经网络。然后,作者利用前期计算化学方法ISiCLE产生的CCS数据集进行中间态的神经网络训练,以SMILES为输入,以CCS和m/z输出。该方法利用神经网络算法,直接从化合物的化学结构出发,预测化合物的多种物理化学性质,包括了近60万个小分子化合物的CCS值。利用机器学习算法构建的CCS值数据库为以IM-MS为中心的代谢组学和脂质组学研究提供了更全面的数据资源。
小分子代谢物CCS值的准确测量以及代谢物CCS值数据库的发展,极大地促进了CCS值在代谢物化学结构鉴定中的应用。CCS值的应用可以降低代谢物鉴定假阳性,提高准确度。相比于液相色谱保留时间的较大波动性和MS/MS谱图较低的覆盖度等缺点,代谢物CCS值数据库具有高覆盖、高准确的优点,为鉴定缺少标准二级质谱图的未知代谢物提供了新途径[6,8,16]。2020年,朱正江课题组[51]详细全面地探讨了CCS值在代谢物鉴定中的用途和优势,CCS值在已知和未知代谢物化学结构注释中均发挥着重要作用。最近,该课题组[43,69]整合了296 663个脂质分子的多维信息(如m/z、保留时间、CCS和二级谱图),开发了脂质组学鉴定分析软件Lipid4DAnalyzer(http:∥lipid4danalyzer.zhulab.cn),实现了脂质的高覆盖、高准确的化学结构鉴定。小分子CCS值数据库在代谢组学和脂质组学领域的应用正在蓬勃发展[16,70]。
5 总结与展望
离子淌度质谱技术的发展为代谢组学研究提供了强大的技术支持。通过离子淌度质谱测量的CCS数值能够有效辅助已知和未知代谢物的化学结构鉴定。随着各类离子淌度质谱仪的发展和广泛应用,需要准确实验测量CCS值,并构建高覆盖、高准确的碰撞截面积数据库。目前,离子淌度质谱技术处于蓬勃发展的阶段,相信随着离子淌度质谱仪的发展,以及对CCS值测量和计算方法的进步,离子淌度质谱技术将会更广泛地应用于代谢组学研究。
猜你喜欢
现代临床医学(2022年4期)2022-09-29
浙江大学学报(农业与生命科学版)(2022年4期)2022-09-07
中山大学学报(自然科学版)(中英文)(2022年4期)2022-08-05
中国油脂(2022年5期)2022-05-31
昆明医科大学学报(2022年3期)2022-04-19
现代临床医学(2021年6期)2021-11-20
昆明医科大学学报(2021年4期)2021-07-23
智慧健康(2021年33期)2021-03-16
昆明医科大学学报(2021年1期)2021-02-07
天津医科大学学报(2021年1期)2021-01-26