
基于时空维度变量的杭州市轨道交通站点聚类研究
2022-09-28 03:17张海燕杜希旺
北京交通大学学报 2022年4期
李 亮,赵 星,张海燕,杜希旺
(河海大学土木与交通学院,南京 210098)
城市轨道交通以其速度快、运量大、频次高和能耗低的优点而被视为提高市民出行效率、缓解城市交通拥堵的有效途径.轨道交通站点作为城市轨道交通网络的关键节点,其客流时空分布模式与站点自身特性、周边土地利用及接驳设施配置等存在互动关系.因此,基于不同维度所选特征进行轨道交通站点聚类研究,对探索站点类型与其客流出行模式互动机理具有重要意义.
轨道交通站点客流是站点周边用地形态所产生的出行需求的体现,亦是站点设施使用情况的直接反映[1].随着自动收费系统(Automated Fare Collection,AFC)的广泛应用以及大数据技术的不断发展,基于地铁刷卡数据构造客流时间序列并进行特征选择已成为站点聚类研究的有效途径.Mahrsi等[2]利用地铁刷卡数据探索客流时变规律与OD 分布,提出一种基于最大期望(Expectation Maximization,EM)算法的聚类模型并用于实例研究.Kim等[3]根据首尔地铁进出站客流时间序列提取聚类因子,采用主成分分析与K-means 算法将站点划分为5 类.尹芹等[4]基于工作日地铁刷卡数据构造客流矩阵,应用引入客流特征的时间序列聚类方法对北京市地铁站点进行分类研究.
基于站点聚类结果,通过对各类别站点的客流时空分布特性与周边土地利用性质进行融合分析,能够进一步识别不同聚类站点客流出行模式的异质性,进而探索站点布局与乘客出行需求之间的互动关系[5-6].Shen等[7]基于进出站客流时序特征对地铁站点进行分类,并结合站点周边用地形态归纳分析不同站点类型的客流出行模式.Gan等[8]应用Kmeans 算法将南京市地铁站点分为7 类,并构建多项Logit 模型深入剖析建成环境属性对站点客流的影响机理.马晓磊等[9]采用K-means 算法与交叉分类组合模型将北京地铁站点分为5 类,并应用地理加权回归模型量化分析站点客流特征与土地利用之间的相关关系.
既有研究关于聚类变量的选取多集中于客流时间序列分析,聚类变量构成较为单一且未能考虑空间属性对站点类别的影响.因此,本文以地铁刷卡数据与站点周边兴趣点数据(Point of Interest,POI)为基础,从时空维度出发进行聚类变量选择,应用K-means++聚类算法对杭州地铁站点进行聚类分析,并结合不同站点类型周边建成环境探讨客流出行模式的异质性.
1 基础数据与研究方法
1.1 研究区域与数据概况
杭州坐落于长江三角洲地区,是浙江省的省会和经济、文化、科教中心.本文以杭州市主城区为研究区域,包括余杭区、拱墅区、西湖区等行政区划.2012 年杭州地铁1 号线一期正式开通试运营,杭州成为浙江省首个开通地铁的城市.截至2020 年12 月,杭州地铁已有7 条运营线路,车站167 座,线网里程共计约306 千米[10].杭州地铁站点空间分布如图1 所示.
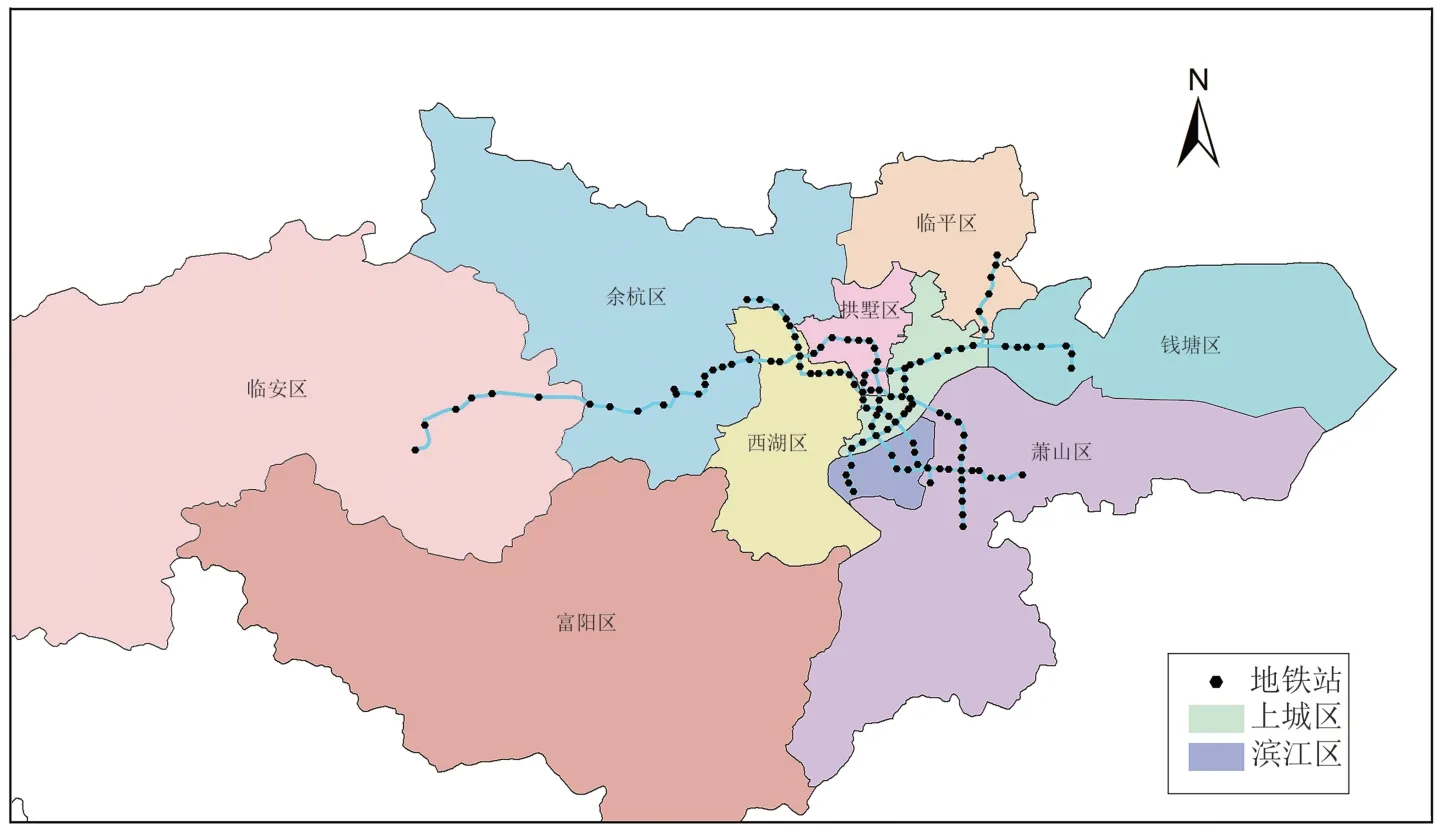
图1 研究区域与地铁站点分布Fig.1 Distribution of research area and metro station
本文所用数据包括杭州地铁刷卡数据和站点周边兴趣点数据.地铁刷卡数据包含2019 年1 月1 日~2019 年1 月25 日乘客进出站刷卡记录,涵盖1、2、4 号线3 条线路80 个站点,总计约7 000 万条数据,并通过用户IC 卡号、刷卡日期、刷卡时间、所属线路、站点编号、进出站状态等字段记录乘客出行行为及交易信息.其中进出站状态为布尔型数据类型,即通过数值1、0 分别表示进站与出站行为.杭州市地铁刷卡数据样例见表1.
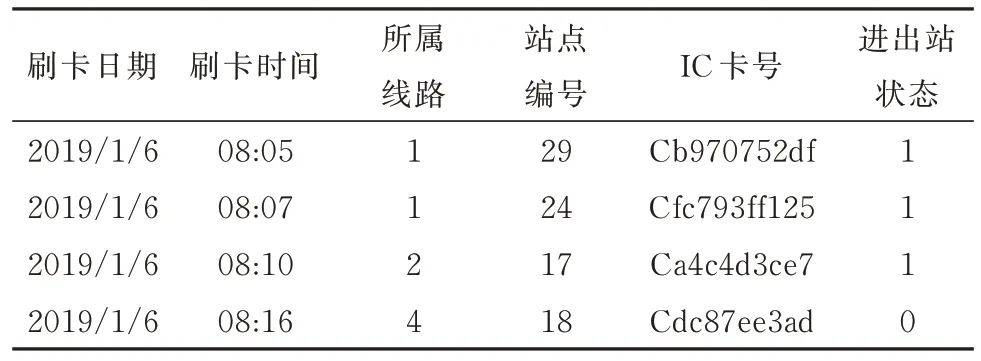
表1 地铁刷卡数据样例Tab.1 Example of metro swip card data
兴趣点数据是表示真实存在地理实体的点状数据,通过名称、类别、经纬度等属性描述空间地理要素信息.为实现特定空间尺度下的兴趣点数据获取与统计分析,以步行可达范围作为站点吸引范围的划定标准,综合考虑前人研究、相关设计规范以及杭州市主城区平均站间距[11-14],本文选择站点周边500 m 半径区域作为吸引范围,并应用高德地图开发平台获取吸引范围内的餐饮服务、购物服务、医疗保健等14 种兴趣点类型来构建土地利用特征数据集.具体兴趣点类型如表2 所示.
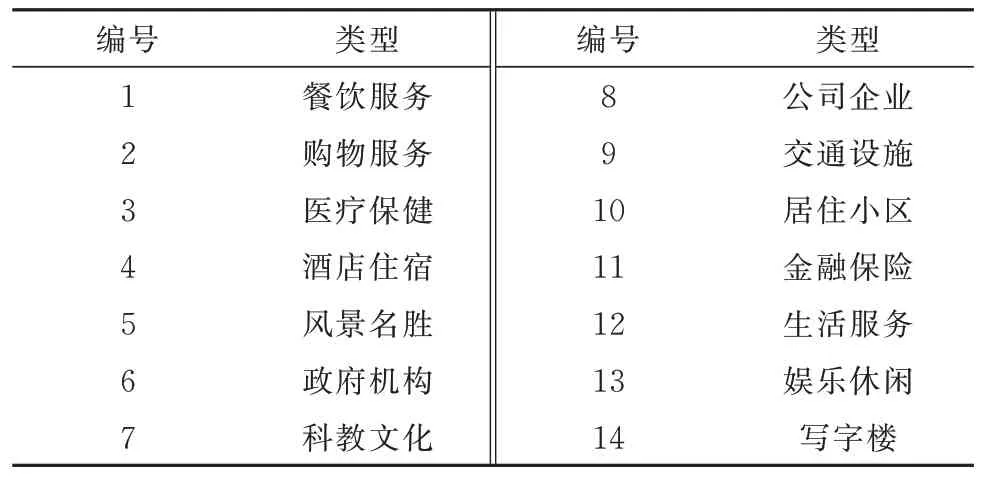
表2 所选兴趣点类型Tab.2 Selected types of POI
1.2 地理加权回归模型
基于普通最小二乘法(Ordinary Least Square,OLS)进行参数估计所建多元线性回归模型是量化分析轨道交通站点客流与其影响因素之间依赖关系的主要研究方法之一.其基本形式为
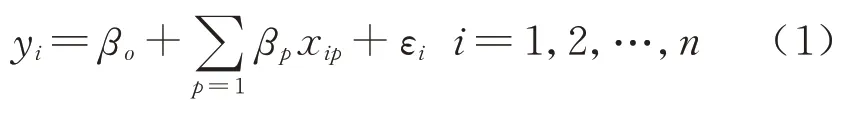
式中:yi为站点i客流量;βp为站点i第p项自变量xip对应回归系数;βo为模型截距;εi为模型误差项并设其服从N(0,σ2)分布.由于OLS 模型所得回归系数仅从平均视角表征解释变量对因变量的影响程度,而未能捕捉变量自身空间异质性对其影响程度的扰动,使得模型回归结果的表达存在一定滞后性.
地理加权回归(Geographical Weighted Regression,GWR)是一种对空间变化关系进行线性回归建模的方法.相对于传统线性回归,地理加权回归模型将空间位置的距离权重函数引入回归方程,并将空间变化纳入模型中解释变量的参数估计[15].因此,地理加权回归模型能够充分考虑数据的空间非平稳性,进而获得更为准确的分析结果.
GWR 模型的表达式为
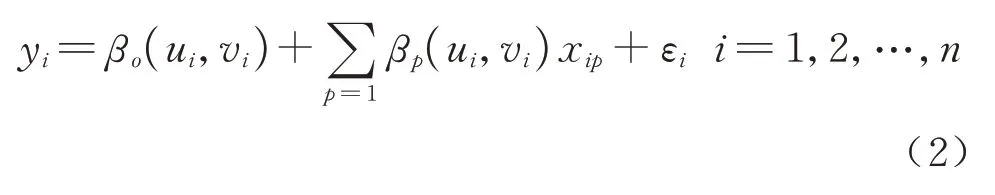
式中:n为所选站点总数;(ui,vi)为站点i的经纬度坐标;βo(ui,vi)为模型截距.在构建GWR 模型前需要对所选自变量进行空间自相关性检验,从而判断其是否适合建模分析.全局Moran’s I 指数常用于检验研究区域内变量是否存在空间自相关性,其公式为
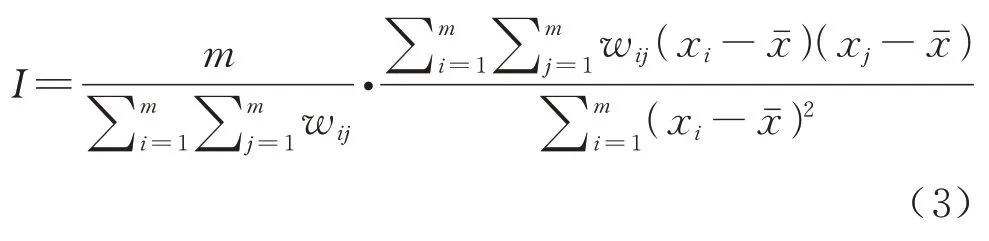
式中:m为区域空间单元总数;xi与xj分别表示变量x在地理单元i和j的属性值;xˉ为区域内变量x的均值;wij为地理单元i与j之间基于欧式距离的空间权重.预设距离阈值为d,当i与j的距离在阈值d内,wij=1;反之wij=0.全局Moran’s I指数值域为[-1,1],其绝对值越接近1,表明变量(正或负的)空间自相关性越强.
GWR 模型的求解核心在于寻找合适的空间权函数和带宽来估计空间权重矩阵.本文采用高斯权函数计算空间权重矩阵,其公式为
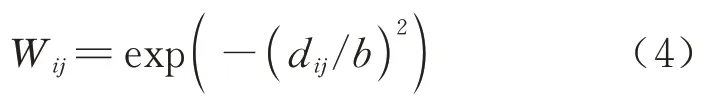
式中:Wij为站点i与j之间的空间权重;dij为站点i、j之间的欧式距离;b为带宽.最优带宽可根据赤池信息准则(Akaike Information Criterion,AICc)获得,当AICc 有最小值时即确定对应的最优带宽b.
1.3 K-means++聚类算法
聚类是按照某种特定标准把数据集划分为由相似子集所组成的若干类或簇的分析过程.聚类分析本质上是一种探索性研究过程,能够根据得到的分类及其内部样本数据分析事物的整体属性与内外特征.K-means 算法是一种被广泛用于实际问题的聚类算法,具有简单高效、算法可解释性强等优点[16].但K-means 算法采用随机化策略选取初始聚类中心而未能考虑彼此之间距离对其聚类结果的影响,这使得其聚类评价指标易收敛于局部最优.Kmeans++算法是对传统K-means 算法的改进,即根据簇类中心距离最远原则确定初始质心,从而克服随机选取方式的影响并改善聚类效果.因此,本文选择K-means++算法用于杭州地铁站点聚类分析,算法步骤如下:
步骤1:从数据集X中随机选取一样本点作为首个初始聚类中心μ1.
步骤2:遍历X中每一个样本点并计算其与当前聚类中心μ1的欧式距离,筛选出最短距离D(x).随后根据计算每个样本被选为下一个聚类中心的概率,并按照轮盘赌法确定新的聚类中心.
步骤3:重复步骤2 直至选择出k个聚类中心μ={μ1,μ2,…,μk},进而得到所划分聚类C={C1,C2,…,Ck}.
步骤4:计算X中所有样本点与μ中各聚类中心的距离,并将其分配到对应最短距离的聚类中心的类中.
步骤5:对于i=1,2,…,k,计算并更新样本点所属的聚类中心μi=
步骤6:重复步骤4 和步骤5,直至聚类中心稳定或算法达到最大迭代次数.
K-means++算法属于无监督学习,传统评价指标并不适用于描述其聚类效果.因此,本文选取轮廓系数(Silhouette Coefficient)、Davies-Bouldin 指数和Calinski-Harabaz 指数评估聚类效果.轮廓系数是基于类别内样本点之间的密集度与类别之间的离散度的比率进行聚类评估,值域为[-1,1],其数值越接近1 表明聚类效果越好.计算公式为
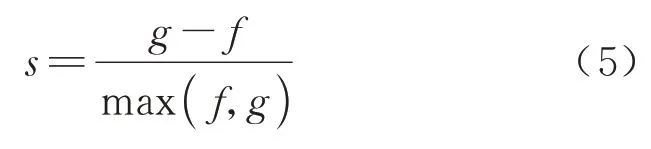
式中:s为单样本的轮廓系数;f为同一聚类内样本点之间的平均距离;g为单样本点与最近邻的类别内各样本点之间的平均距离.Davies-Bouldin 指数又称为分类适确性指标,能够度量各分类之间的相似度,其数值越小表明聚类效果越优.计算公式为
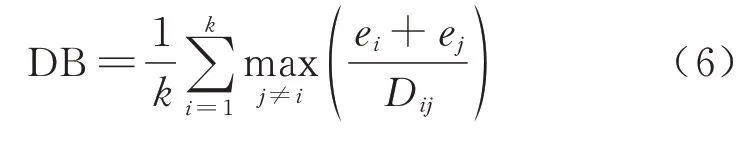
式中:k为聚类 个数;ei、ej分别表示类i和类j内部各样本点到其质心的平均距离;Dij表示类i与类j的质心间距.
Calinski-Harabaz 指数的评估原理与轮廓系数相似,其数值为类别之间协方差与类别内部样本矩阵协方差的比率,数值越大表明聚类效果越优.计算公式为
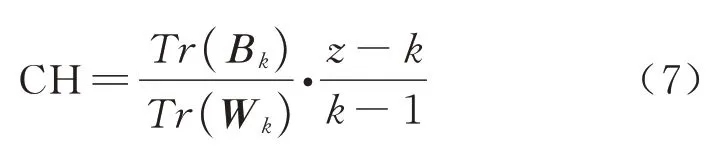
式中:z为样本总数;Bk、Wk分别表示类别之间与类别内部协方差矩阵;Tr为矩阵的迹.
Davies-Bouldin指数与Calinski-Harabaz指数表达式中k具有相同的含义,因而综合衡量该两项指标有助于从直观视角确定最优聚类总数并评价其聚类结果.
2 基于时空维度的聚类变量选择
基于地铁刷卡数据与站点周边兴趣点数据,应用数据挖掘与分析方法从时空维度选取聚类变量有助于深入理解站点类型、客流分布模式与土地利用特征的内在联系,为站点聚类分析提供必要的数据支撑.
2.1 时间维度变量
为优化数据质量并确保分析结果准确性,首先对地铁刷卡数据进行清洗,具体包括缺失值剔除,冗余数据检测以及异常数据处理.基于已清洗的数据,首先按照刷卡日期及时间字段对其进行排序,并以小时为时间间隔统计地铁线网全天总客流.本文选择1 月14 日~1 月20 日一周作为完整周期,全线5:00~23:00 日小时总体客流分布如图2 所示.
从图2 中可看出,周一至周五为工作日,日小时客流量呈现出相似的时间分布模式,休息日亦具有相似的时间分布规律,工作日和休息日的客流时间分布表现出较大的差异性.工作日客流存在明显的早晚高峰,分别是7:00~9:00 和17:00~19:00,早高峰客流峰值相对晚高峰较大,这与人们工作日通勤出行行为高度一致.休息日客流分布相对均衡,并没有表现出明显的聚集效应,推测其原因可能是休息日期间乘客出行时间相对自由,出行目的并不是以通勤为主而是具有就医、休闲娱乐等多种可能性.可以认为,工作日与休息日的客流时间分布差异性反映了人们的生活模式从工作状态到休闲状态的转变.
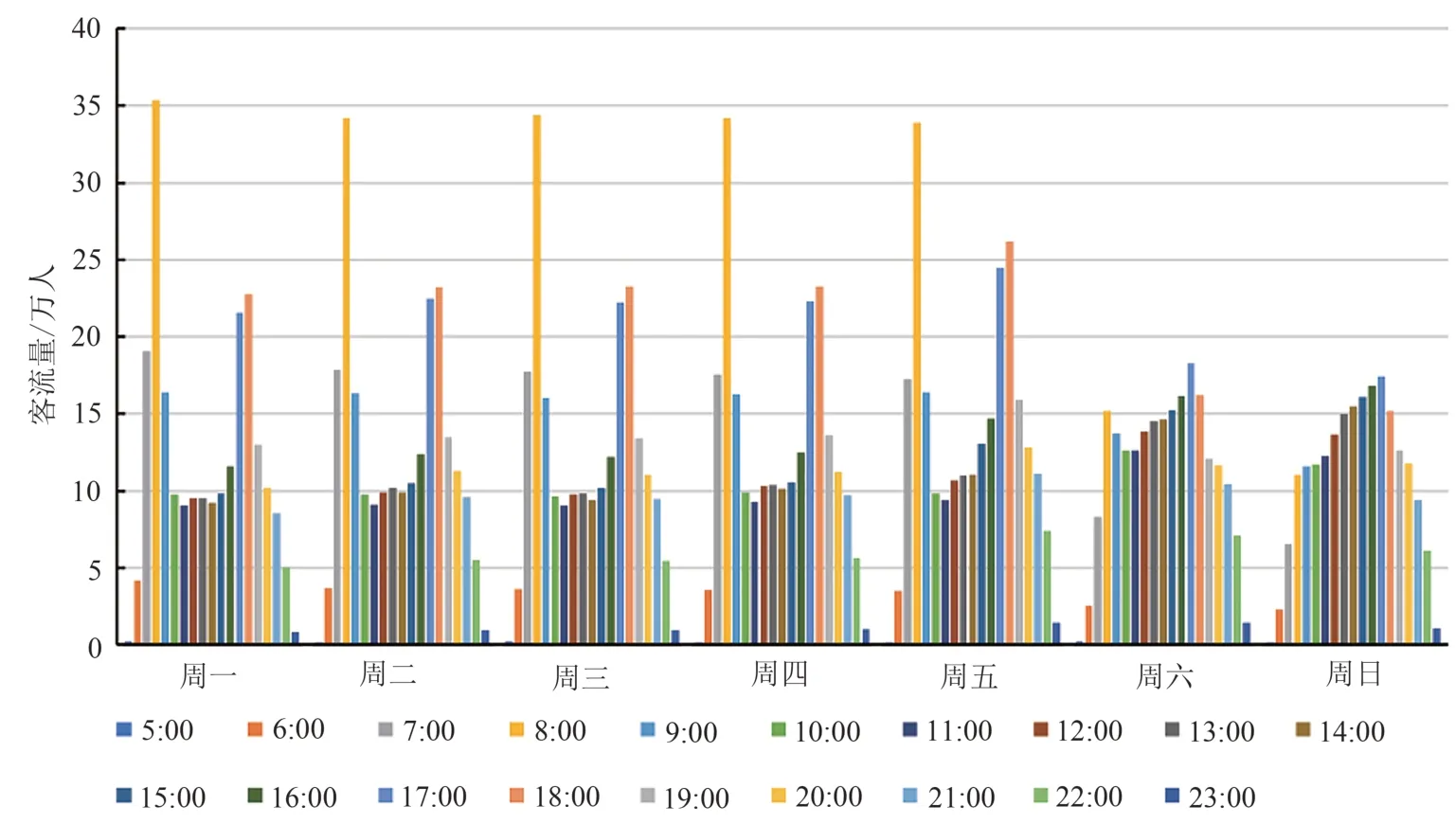
图2 一周日小时地铁总体客流分布图Fig.2 Distribution of daily hour overall passenger flows within a week
基于上述分析,进一步探索站点层面下的客流时间分布模式.基于已完成清洗以及时间序列排序的数据,根据“进出站状态”对进站与出站乘客刷卡记录进行分类存储,以小时为时间间隔分别统计各站点客流量,即可得到分站点分小时的进站客流与出站客流数据.以若干非邻接站点为例,其一周内日小时进出站客流时间分布如图3 所示.

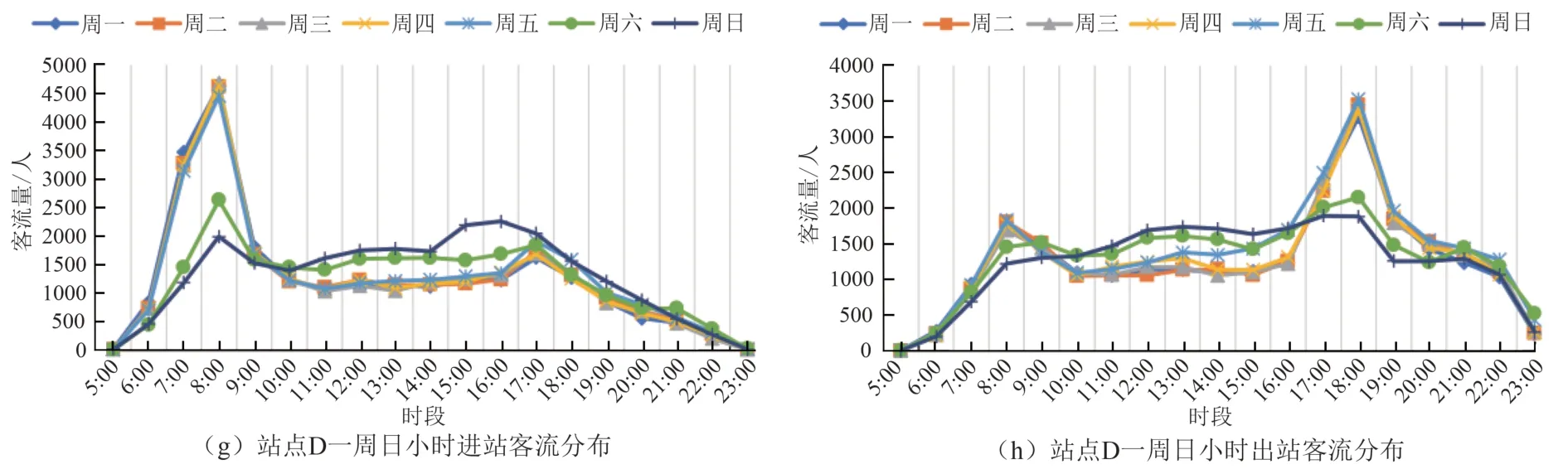
图3 不同站点日小时进出站客流分布Fig.3 Daily hour inbound and outbound passenger flows distribution in different stations within a week
从图3 中可以看出,不同站点的进出站客流时间分布模式在工作日与休息日期间均呈现特定的相似性.充分考虑不同类型客流随时间变化特点,本文以小时为时间尺度分别统计各站点5:00~23:00 工作日进站/出站客流、休息日进站/出站客流,并计算日小时客流比例以减少不同站点客流量分布的绝对差异,更加突出其时间序列变化趋势.将上述四项时序数据进行横向组合从而构建二维矩阵,其中纵向为所选80 个站点编号的正向递增序列.每个站点均包含72 项变量(工作日进出站/休息日进出站×18h),并以之作为时间维度聚类变量,其矩阵布局如图4 所示.
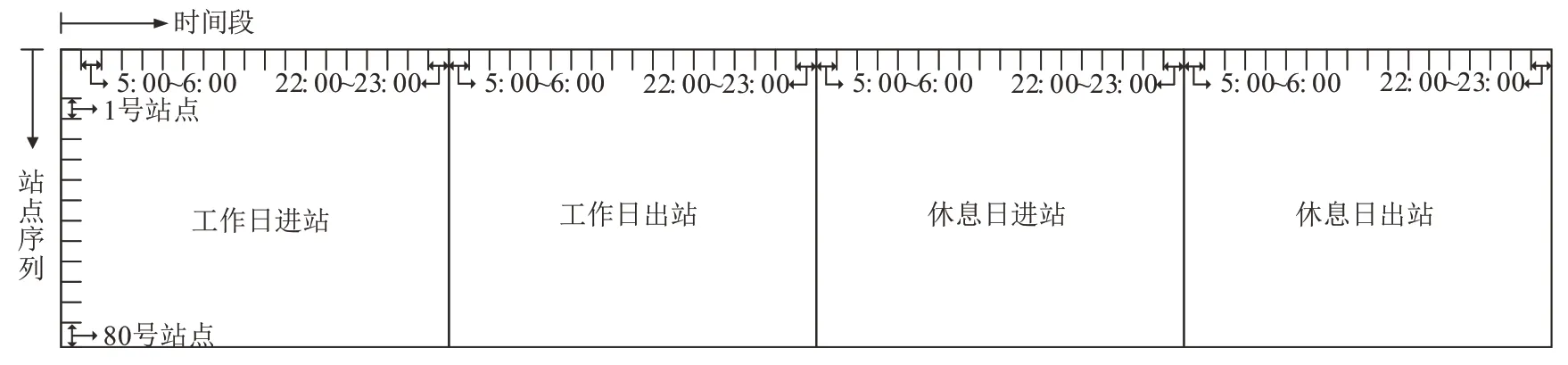
图4 客流时间序列矩阵Fig.4 Time series matrix of passenger flow
2.2 空间维度变量
作为描述真实存在地理实体的基本组成单元,兴趣点数据能够实现基于空间位置的土地利用特征识别与分析,进而可用于表征一定空间尺度下的城市建成环境[17-18].因此本文认为轨道交通站点500 m半径吸引范围内兴趣点数据具备空间属性,以之构建解释变量集并通过回归建模量化分析土地利用特征与站点客流的依赖关系,同时选取判定系数(R2)、调整后的判定系数(AdjustedR2)以及AICc 作为模型性能评估指标,其中前两项指标能够度量回归方程对观测数据的拟合程度,而AICc 则兼顾模型复杂度与拟合优度,进而综合反映模型的性能表现.
首先构建普通最小二乘回归模型(Ordinary Least Square,OLS),从全局视角对站点客流空间影响因素进行初步分析.在变量选择方面,本文选取餐饮服务、购物服务、医疗保健等14 项兴趣点类型的数量作为自变量,综合考虑客流通勤特性与时间分布差异,选择工作日早高峰进站/出站客流、晚高峰进站/出站客流以及休息日全天客流作为因变量,并对其进行对数转换以符合回归建模对于因变量呈正态分布的假设.所选变量组合及其描述统计如表3所示.
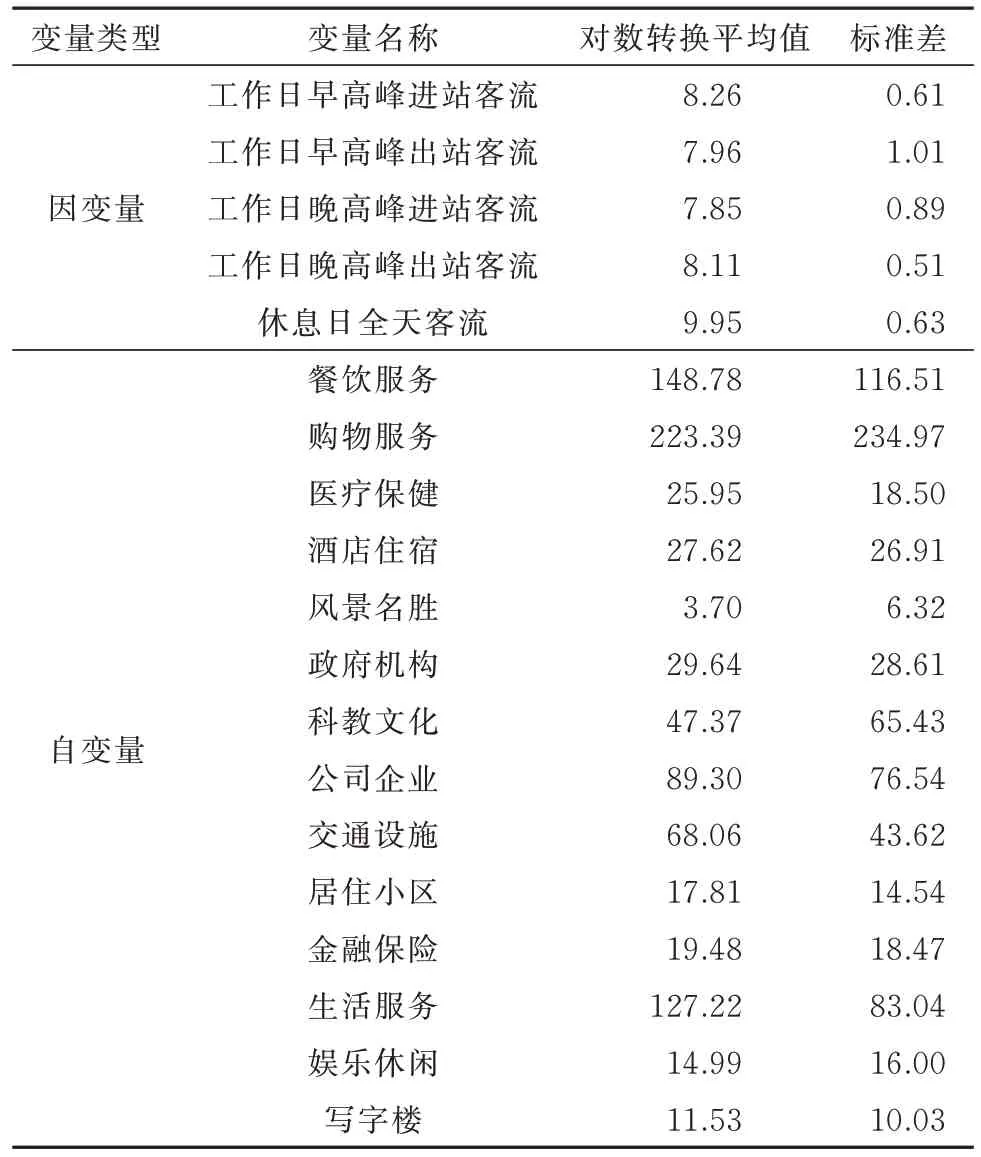
表3 所选变量及其描述统计Tab.3 Summary and descriptive statistics of selected variables
为克服自变量之间多重共线性对模型参数估计的影响,本文应用向后逐步回归法对模型输入变量进行筛选.表4 为5 种客流类型的OLS 回归结果.
由表4 可知,交通设施在上述模型中均呈现正相关且回归系数值较高,表明交通设施对所有站点客流类型均具有较强的积极影响.酒店住宿与科教文化在所有模型中均不显著.餐饮服务、风景名胜、生活服务与休息日出行客流均为正相关,而购物服务、休闲娱乐以及金融保险则表现为负相关,表明商业-服务业用地对非通勤客流具有显著影响,且影响程度存在一定差异性.进一步观察可知,工作日早高峰进站客流与晚高峰出站客流的显著变量相似,但后者的变量回归系数相对较高,表明其与出站客流相关性程度更强.同时,工作日早高峰出站客流与晚高峰进站客流显著变量及其系数分布亦具有相似性,可认为其是全局视角下以通勤出行为主的工作日客流与空间用地属性互馈作用的效果.

表4 OLS 回归模型系数估计结果Tab.4 Parameter estimation results of OLS regression models
基于OLS 全局回归分析结果,进一步应用GWR 模型进行后续分析.在GWR 建模前需要对候选解释变量进行Moran’s I 指数检验,以判断其分布是否存在空间自相关性[19].检验结果见表5.所有自变量的Moran’s I 指数均为正值且通过95%置信度检验,表明候选自变量的空间分布具有明显的聚集特性,符合GWR 建模要求.

表5 Moran’s I 检验结果Tab.5 Results of Moran’s I test
以OLS 回归分析所得显著变量为输入变量,构建GWR 模型探索空间视角下的站点客流影响因素并统计其回归系数的均值如表6 所示.
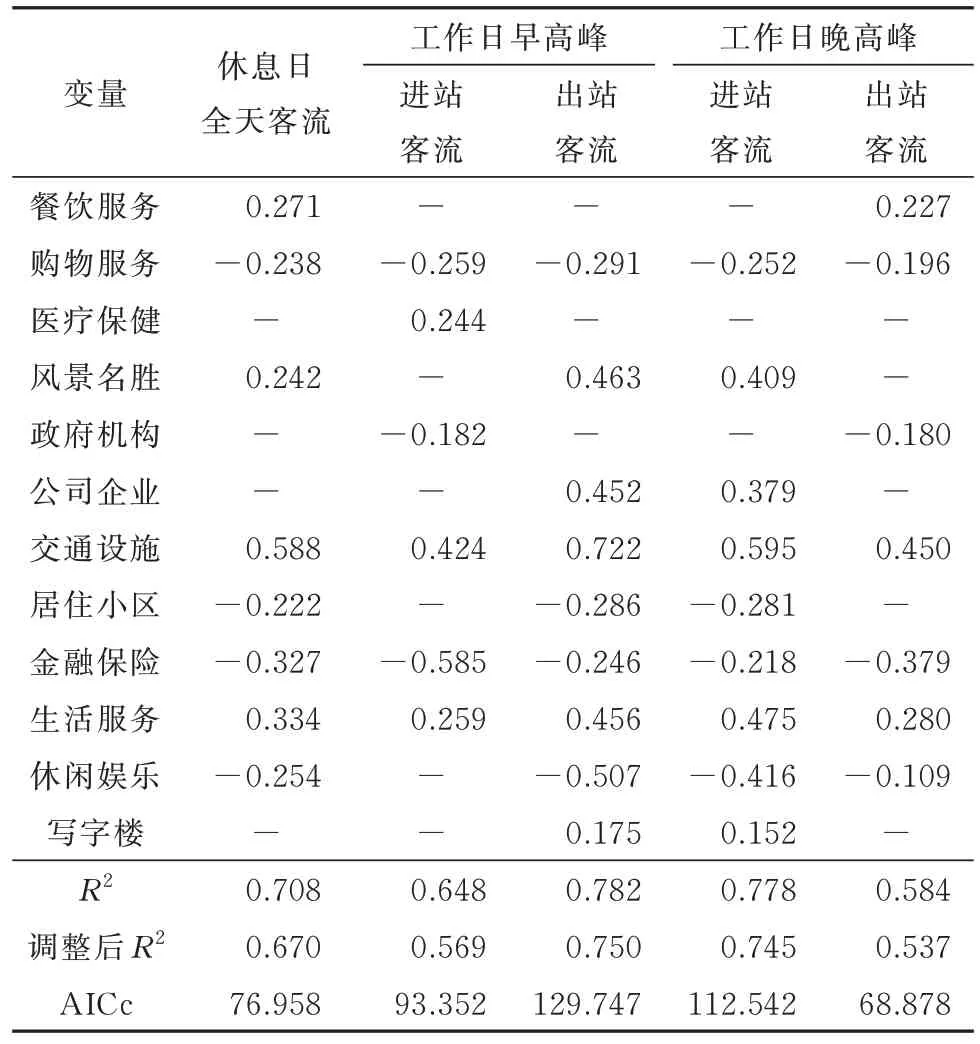
表6 GWR 模型系数估计结果Tab.6 Parameter estimation results of GWR models
由表6 可知,生活服务、交通设施与所有站点客流类型均为正相关且具有较高的系数值,这与OLS回归分析结果相一致,表明地铁站出入口、公交站点等交通设施数量的增长以及周边生活配套设施的完善能够有效吸引地铁出行客流.休息日全天客流反映了人们非通勤的出行特性,餐饮、风景名胜与休息日客流呈正相关,而购物、休闲娱乐则为负相关,表明人们的出行目的偏向于餐饮消费与闲暇出游.早高峰进站客流与晚高峰出站客流反映居住区域的通勤出行特性,因而两者的显著变量及其系数分布相似,且生活服务设施对客流有较强的积极影响.早高峰出站客流与晚高峰进站客流反映工作区域的通勤出行特性,两者的变量构成及其系数分布亦具有相似性,其中以就业功能为主的公司企业、写字楼与客流呈显著正相关.同时风景名胜回归系数为正值,可认为杭州市内众多旅游景点是人们通勤出行的重要途径或目的地,因而对客流具有一定的积极影响.购物服务、金融保险及休闲娱乐与客流为显著负相关,表明商业-服务业用地类型对于工作日从工作地到居住地的通勤客流并不具备较强吸引力.
对比表4 和表6 所得结果可知,GWR 模型的三项评价指标均优于OLS 模型,表明在描述用地特征的空间非平稳性对站点客流的影响程度时,GWR模型具有更好的数据拟合效果和性能表现.因此,本文以GWR 模型中的自变量作为空间维度变量,即各站点吸引范围内除酒店住宿和科教文化之外的12 项POI 变量用于站点聚类研究.
3 聚类分析
3.1 聚类结果
K-means++算法需预先设定聚类个数k,且k值的选取对其聚类效果影响较大.本文根据轮廓系数、Davies-Bouldin指数以及Calinski-Harabaz指数选择最优k值,同时引入传统K-means 算法进行对比分析.两种聚类算法对应评价指标随不同k值的变化曲线如图5 所示.

图5 不同k 值对应聚类评价指标Fig.5 Clustering indices for different values of k
由图5 可以看出,在所设聚类个数相同的情况下,K-means++算法相关评价指标相对于传统Kmeans 算法较优,表明前者具有更好的性能表现.进一步对比观察可知,k=2 时三项指标均达到最优,但仅基于指标值将地铁站点分为两类;易忽略由城市轨道交通与周边建成环境互馈关系所产生的站点类型差异.结合相关研究[20]与杭州市轨道交通站点实际分布可知,相对于其他取值,当k=4 时轮廓系数处于拐点位置且Davies-Bouldin 指数与Calinski-Harabaz 指数均达到较优水平,三项指标改善幅度相对于经典K-means 算法分别为30.43%、10.51%、9.02%,因而能够更为准确地反映地铁站点与周边建成环境的互动及空间组织关系.因此,本文确定最优聚类数k=4.基于前文所得时空维度聚类变量,应用K-means++算法将杭州地铁1、2、4 号线站点分为4 类,聚类结果见表7.

表7 站点聚类结果Tab.7 Results of station clustering
对聚类结果进行可视化处理得到各类站点的空间分布,如图6 所示.
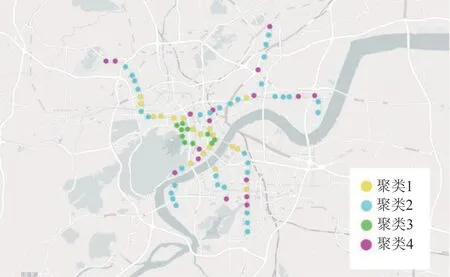
图6 各聚类站点空间分布Fig.6 Spatial distribution of stations in each cluster
聚类1 站点主要分布于2 号线途经主城区沿线地段,毗邻文教区商圈与钱江世纪城中央商务区(Central Business District,CBD).聚类2 站点呈链状分布于1、2、4 号线所经城市外围区,该区域内居住用地分布较为密集.聚类3 站点呈团状分布于市中心区与钱江新城,邻近西湖风景区、武林广场以及湖滨商圈,站点周边资源配置水平和土地开发程度较高.聚类4 站点分布较为离散,并呈现出从主城区内部逐步扩散至城市郊区的变化趋势.
由聚类分析的概念可知,同一聚类内部所含站点具有相似的数据属性,具体表现为站点客流时间分布特征与变化规律的同质性.因此,本文分别计算各聚类站点日小时进出站客流比率并筛选其上下限分布范围,进而分析站点客流时间分布模式.图7为聚类1 站点工作日与休息日的小时进出站客流比率上下限分布曲线.在工作日,客流具有明显的晚高峰进站与早高峰出站聚集特征,两者客流比例分别为30.37%~61.07%、31.62%~65.68%,反映了人们下班返程的通勤特征.在休息日,进站客流表现出一定的晚高峰聚集特征,所占比例为20.19%~36.64%,且非高峰时段客流比例相对于工作日同时段进站客流较高;出站客流亦呈双峰型分布,其比例分别为12.64%~26.49%、12.68%~26.23%,表明站点周边用地综合化水平较高,能够吸引较多弹性出行客流.
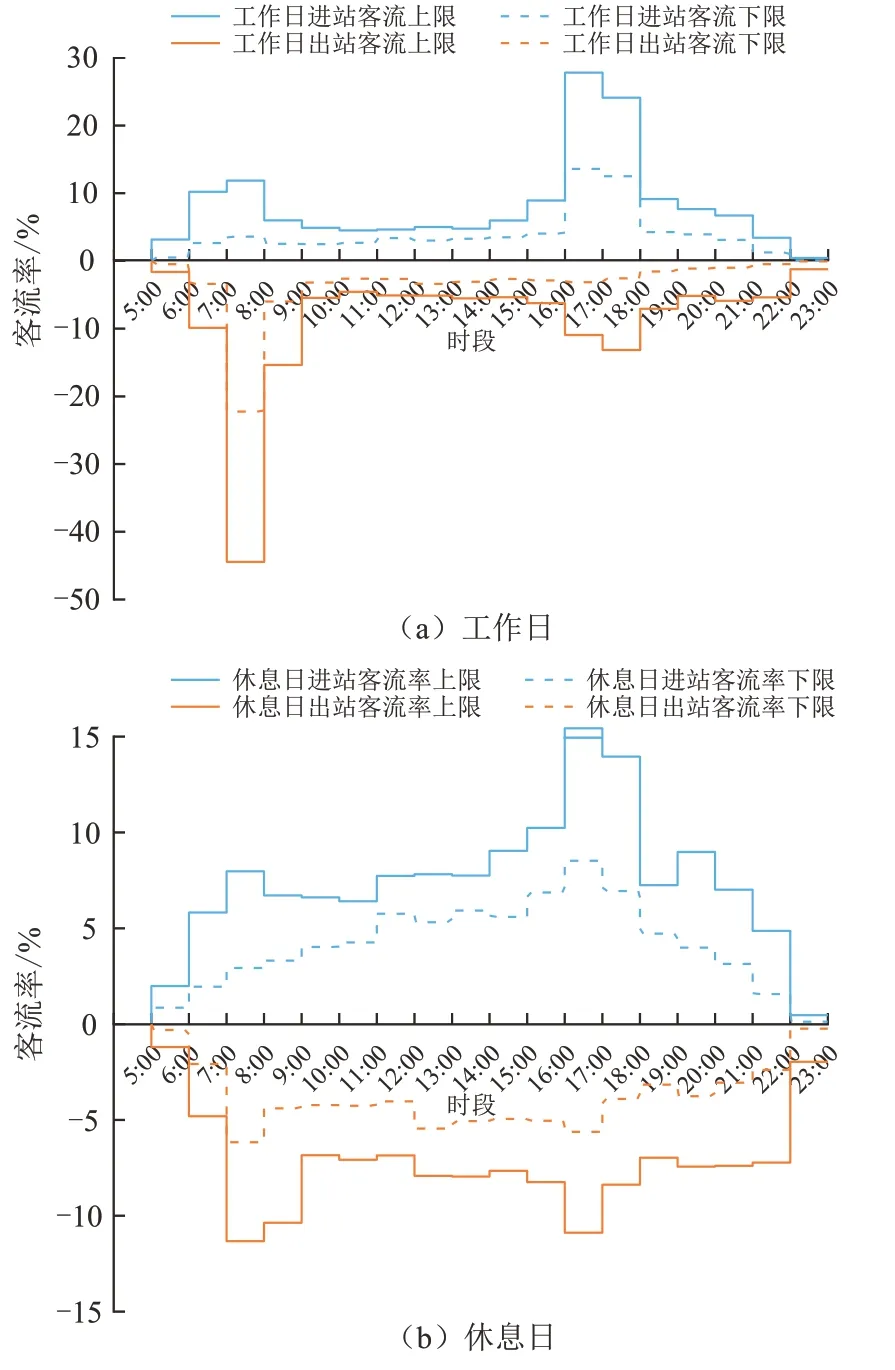
图7 聚类1 站点日小时进出站客流比率阶梯图Fig.7 Staircase curves of daily-hour percentage inbound and outbound passenger flows at Cluster 1 stations
图8 为聚类2 站点工作日与休息日的小时进出站客流比率上下限分布曲线.由图8 可知,工作日客流分布模式与聚类1 相反,具有明显的早高峰进站与晚高峰出站聚集特征,其客流比例分别为34.73%~66.27%、28.66%~60.60%,反映了人们以上班出行为主的通勤特征.休息日进站客流比例在7:00~8:00 时段达到最大值,为6.86%~12.10%,并随时间逐步递减;出站客流比例在8:00~18:00时段呈缓慢递增态势,随后在晚间逐步下降,表明站点周边区域用地类型较为单一,休息日客流出行强度较小且时间分布相对分散.
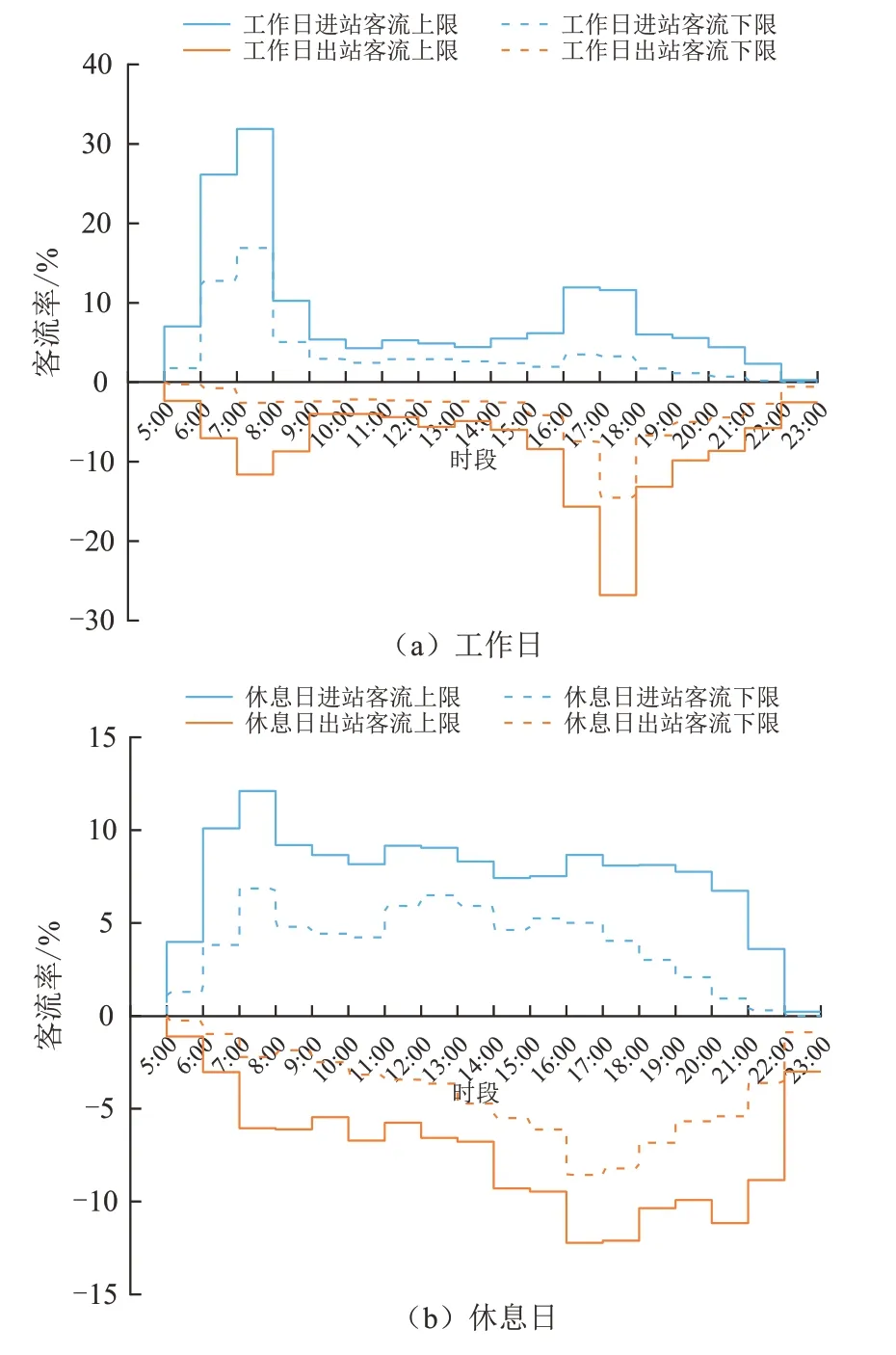
图8 聚类2 站点日小时进出站客流比率阶梯图Fig.8 Staircase curves of daily-hour percentage inbound and outbound passenger flows at Cluster 2 stations
图9 为聚类3 站点工作日与休息日的小时进出站客流比率上下限分布曲线.在工作日,客流分布模式与聚类1 相似,呈现明显的晚高峰进站与早高峰出站特征,其客流比例分别为27.01%~56.65%、33.37%~65.67%,高峰时段客流聚集性相对聚类1较弱.休息日进出站客流整体强度增大,其中进站客流在下午15:00~17:00 以及19:00~20:00 时段表现出一定的聚集效应,其所占比例分别为16.37%~27.18%、7.41%~23.48%;出站客流在8:00~9:00、12:00~14:00 以及16:00~17:00 时段呈现小高峰,客流比例在夜间时段趋减,表明站点周边土地利用程度较高,商业业态成熟,乘客弹性出行需求更为频繁且行为模式与商铺营业时间一致.
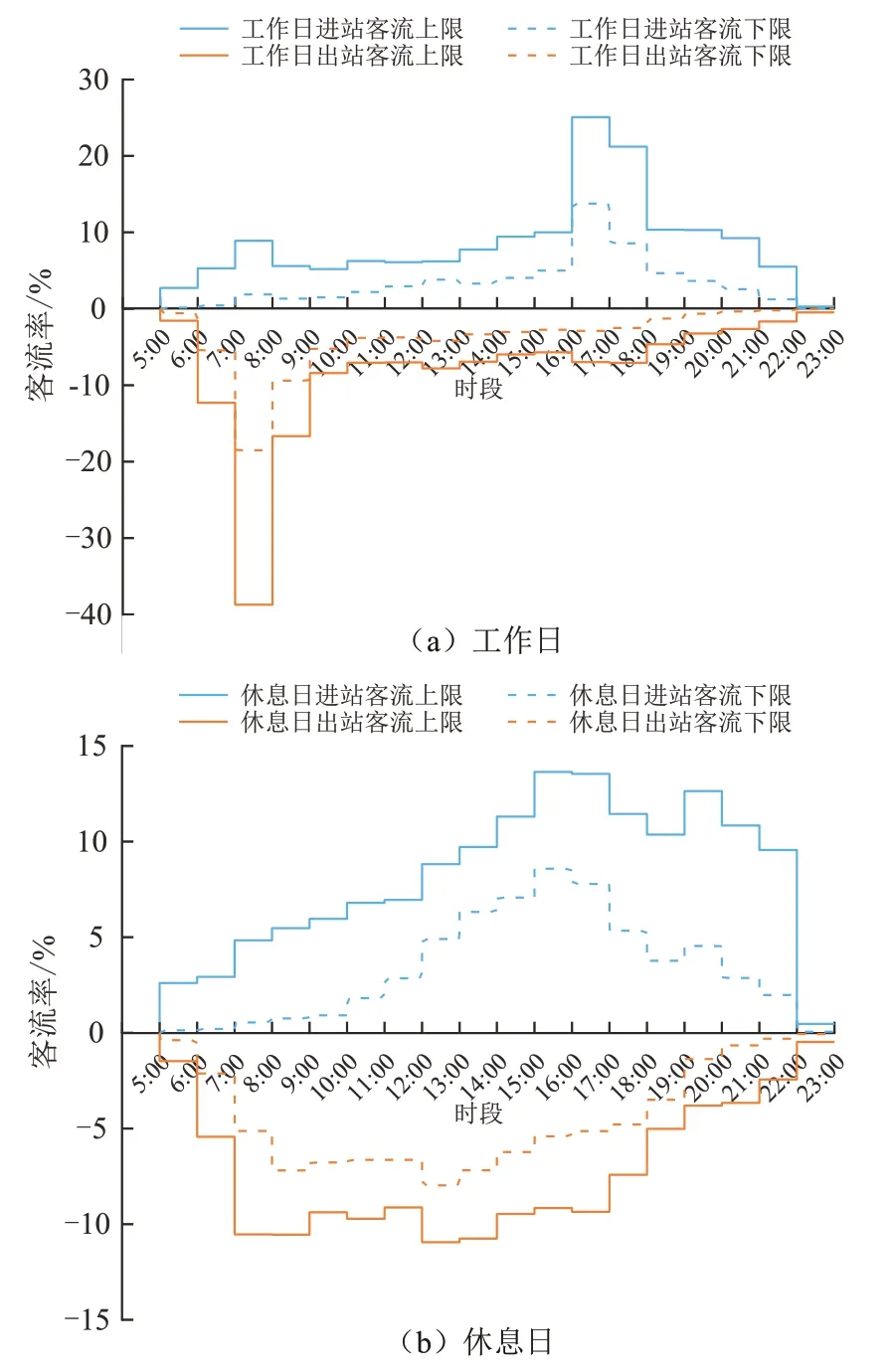
图9 聚类3 站点日小时进出站客流比率阶梯图Fig.9 Staircase curves of daily-hour percentage inbound and outbound passenger flows of Cluster 3 stations
图10 为聚类4 站点工作日与休息日的小时进出站客流比率上下限分布曲线.与其他聚类不同,工作日进出站客流均呈双峰型分布,其中进站客流早晚高峰比例分别为26.51%~57.55% 与8.53%~29.53%,早高峰客流聚集程度相对晚高峰较高;出站客流早晚高峰占比相近,分别为12.11%~34.23%与17.20%~39.41%.休息日进出站客流时间变化规律相似,整体分布较为均衡.因此,可认为聚类4 站点周边用地形态为职住混合型,兼具居住区域站点与工作区域站点对客流的吸引特性.
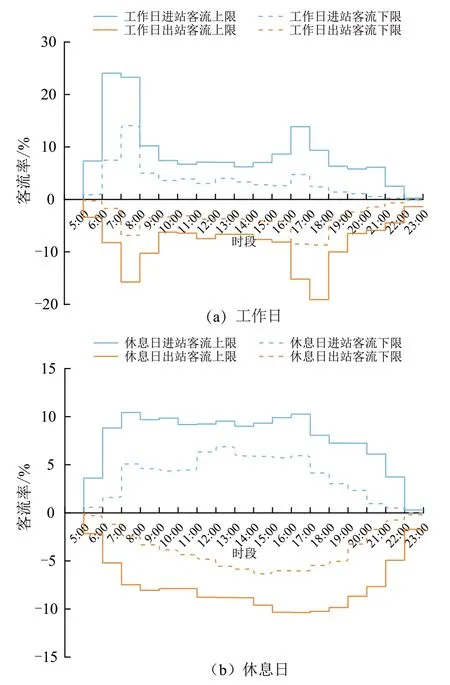
图10 聚类4 站点日小时进出站客流比率阶梯图Fig.10 Staircase curves of daily-hour percentage inbound and outbound passenger flows of Cluster 4 stations
3.2 各站点聚类周边建成环境与客流出行模式
轨道交通站点联系着周边建成环境,两者之间存在一定的互动机制与反馈关系.基于土地利用兴趣点数据,对各聚类周边用地特征进行统计如表8所示.
由表8 可知,不同聚类周边建成环境表现出一定的异质性.聚类1 周边与就业功能要素密切相关的科教文化、公司企业以及金融机构用地比例显著,而餐饮与购物服务用地占比相对其他聚类较低.聚类2 具有最高的居住、餐饮以及生活服务用地比例,同时政府机构与金融保险用地比例最低.聚类3 周边购物、酒店、休闲娱乐以及风景名胜用地比例显著,表明其建成环境以商业服务业设施为主,土地开发程度较高,城市中心功能明显.聚类4 周边用地形态介于聚类1 与聚类2 之间,但其工作用地与居住用地比例更为均衡.基于上述分析,将4 项聚类分别定义为工作导向型、居住导向型、商业型以及工作-居住混合型站点.
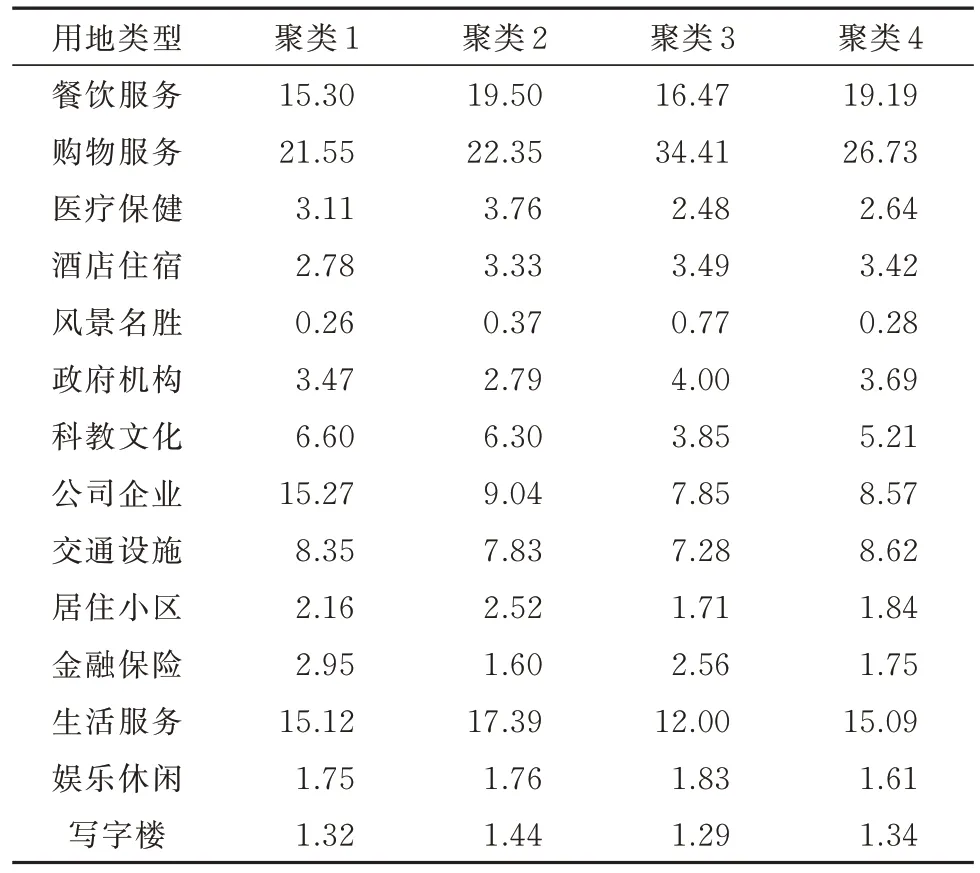
表8 各聚类周边用地形态分布Tab.8 Distribution of land use attributes around the clusters%
结合客流时间分布规律与功能导向,进一步分析各站点类型的客流出行模式.聚类1 为工作导向型站点,其工作日客流呈单峰分布,具有明显的晚高峰进站与早高峰出站潮汐特征.休息日整体客流强度减弱,其出行以弹性需求为主且多发生于上、下午时段.聚类2 为居住导向型站点,工作日客流以通勤出行为主,具有明显的早高峰进站与晚高峰出站潮汐特征.休息日整体客流量较小,但相对于工作日平峰时段较高,其出行目的以就医、购物休闲等弹性需求为主.聚类3 为商业型站点,工作日客流分布形态与工作导向型站点相似,但客流聚集程度较弱,休息日整体客流强度较大且存在多时段客流聚集效应,其出行目的以餐饮、购物以及休闲旅游为主,具有显著的建成环境导向特征.聚类4 为工作-居住混合型站点,工作日双向进出站客流量相近,且均呈双峰形分布,客流主要源于以站点附近居住区、商务区为起始或目的地的错位出行.休息日客流分布较为均衡,其客流量稍高于工作日平峰时段,客流出行目的具有较多自主选择性.
4 结论
1)基于杭州地铁刷卡数据与站点周边兴趣点数据,本文从时空维度进行聚类变量的提取与构建,应用K-means++聚类算法将杭州地铁1、2、4 号线80 个站点分为4 类,根据日小时客流分布特征与周边建成环境属性将其定义为工作导向型、居住导向型、商业型以及工作-居住混合型站点,并进一步探索不同站点类型所对应的出行模式.
2)本文所用轨道交通站点聚类方法操作简便,能够得到有效的聚类结果.通过站点聚类研究,能够深入梳理城市功能分区、轨道交通站点布局以及乘客出行模式之间的互动关系,可为站点客流预测、站城一体化建设等后续研究做出指导.
3)轨道交通客流时空分布特性是其出行需求与站点空间布局、城市用地形态等因素互馈作用的结果.基于地铁智能卡数据与用户画像分析方法,未来可进一步对轨道交通客流进行聚类分析,以期深入探索乘客角色属性与其站点选择的内在逻辑与行为机理.
猜你喜欢
今日农业(2021年8期)2021-07-28
书香两岸(2020年3期)2020-06-29
铁道通信信号(2019年9期)2019-11-25
祖国(2018年6期)2018-06-27
阅读(科学探秘)(2018年8期)2018-05-14
理论观察(2018年1期)2018-03-24
卫星与网络(2016年12期)2016-02-05
铁路通信信号工程技术(2014年6期)2014-02-28
商(2012年14期)2013-01-07
资源导刊(2011年4期)2011-08-15
