
一种基于主题划分及TF-IDF 的文本摘要提取方法*
2022-09-28 01:40朱小虎周艳平陈显利
计算机与数字工程 2022年8期
朱小虎 周艳平 姜 涛 陈显利
(青岛科技大学信息科学技术学院 青岛 266061)
1 引言
随着社会发展和技术进步,人们的日常生活和互联网技术越来越密切,每天产生海量的信息[1]。一些文本信息篇幅较长,长篇文章的叙述会导致用户阅读理解效率低下[2]。在问答系统中,答案过于冗长[3]会大大降低答案质量,影响用户体验[4~5]。如何从文本信息中提取摘要信息,使人们在短时间内快速了解文本核心内容[6]是自然语言处理领域中一个极为重要的课题[7]。
文本摘要提取技术兴起于20 世纪50 年代,最初是依靠统计学为基础,依据词频、位置等信息为格式较为规范的文章生成摘要[8~9]。随着机器学习在自然语言处理方面的应用,20世纪90年代开始,文本摘要提取融入了人工智能的元素[10~11]。近些年,随着深度学习的流行,文本摘要提取与深度学习结合[12~13]也取得了一定的进展。文本摘要提取根据生成方式不同,分为抽取式和生成式[14~15],根据处理文档的数量不同,分为单文本提取和多文本提取[16]。
研究发现,文本信息中的文本内容大多包含多个主题,传统的文本摘要提取方法忽视了各个主题的作用[17],不仅导致摘要提取结果不全面,也造成了算法发挥效果不好。本文针对这一问题,借鉴英文文本摘要提取方法、TF-IDF 算法[18]和大量的对比实验,提出一种中文的段落摘要提取方法。该方法首先对依据段落表达的主题进行分割,其次对分割的段落提取中心思想,最后将中心思想连贯成摘要,进而表达整个段落的完整意思。该方法不仅能解决传统摘要提取算法中对主题类别区别不强的缺点,还能有效提升摘要提取的结果质量。
2 文本主题划分
在日常接触的文章当中,我们取出其中的一段,此段落往往表达了一个中心思想,而这个中心思想往往由许多片段的主题思想结合而成,片段的主题思想又由中文的汉字、词语等合成。一般来说同一主题中的段落关联性高,而不同主题的段落关联性相对较低。因此将关联性强的段落划分到同一个主题中,更容易抓住文本主题,提高文本包含的信息质量。
传统的主题划分是统计两个段落所含的特征词的共现次数多少,共现次数越多说明这两个段落具有较高的重复性和关联度,甚至可以认定表达同样的中心思想。但在实验中发现,不仅共现词能作为两个句子表达意思的依据,核心重点词汇也能表达两个句子之间的关联性。
一个段落中现有两个句子:D1=“疫情期间,学生参加学校组织的线上课程学习和考试”。D2=“老师制定相应的教学计划,确定学生考核要求”。D1、D2均出现词语“学生”,但实际上D1、D2表达的是与“教学”有关的话题,D1、D2 中的词语“考核”、“教学”之间具有关联,为了直观了解文本各个段落之间的联系性和相关性,对全文所有段落与其他所有段落进行段落相似度计算,然后以矩阵的形式列出文本每个段落之间的相似度,通过评价机制对段落矩阵表进行分析,从而达到段落划分的目的。
假设文本共有m 段,记为D1,D2,…,Dm,每段提取特征词有n个,记为T1,T2,…,Tn,用Word2vec[19]将特征词转换为词向量,计算两个特征词之间的相似度S(Ti,Tj),两个段落所有特征词相似度计算后,将其平均值作为两个段落之间的相似度Sim(D1,D2),计算公示如下:
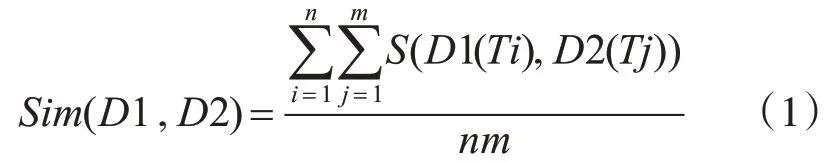
通过计算段落之间的相似度,即可得到相似度矩阵,矩阵中第i 行第j 列上的值代表Sim(Di,Dj),每个段落与自身的相似度为1。通过计算百度百科中一篇文献所构成的段落的相似度得到相似度矩阵,如表1所示。

表1 段落之间相似度矩阵表
从表1 中可以分析出,D1 与D2 的相似度为0.97,D1 与其他段落的相似度较低,所以D1、D2 划分为同一个主题。D3 与D4、D5、D6 的相似度比较高,与其他段落的相似度较低,因此D3、D4、D5、D6划分为同一个主题。同理D7、D8、D9 划分为同一个主题。经过与原文意思对照,此划分方法准确。
通过矩阵表中的相似度情况能够很容易地划分出属于统一主题的段落,因此可以通过该规律设计相应的算法来划分段落,使同一主题的段落划分在同一集合。不同主题的相邻段落之间的相似度差值一般都较大,因此我们将相邻段落的相似度做差来观察其变化程度,公式如下:
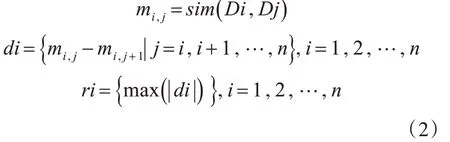
其中di表示矩阵i行中相邻段落之间相似度的差值,ri 表示矩阵i 行中差值绝对值的最大值。对前面例子中的文献,根据式(2)两两相邻段落计算差值后,每行最大差值作标记。计算结果如表2 所示。

表2 各行段落相似度差值结果
相似度的最大差值代表了段落之间联系程度的变化,若差值大,如果变化明显,两个段落极大可能不是一个主题,如果变化不剧烈,说明两个段落很大可能是一个主题。
据此提出三个主题划分的原则:
1)相似度最大差值原则。从矩阵表中可以直观的看出,D1、D2段落和D3段落的差值最大,因此把D3 段落作为主题划分位置,从而把D1、D2 段落划分到同一主题当中。
2)段落最多区分度原则。如果根据相似度最大差值原则会将D3~D6 分成D3、D4、D5~D6 三个主题,与原文不符。一般而言,同一主题的段落一般是连续的,因此可以依据段落的连续情况对主题进行划分,如D3~D6连续段落,最大差值位置D7出现了3 次(D3、D5、D6),而D8 位置出现一次(D4),因此选择区分度最多的位置D7段落为主题段落划分位置,从而D3、D4、D5、D6 段落会被划入一个主题中。
3)特殊结尾划分原则。研究发现,一个段落作为一个主题的情况非常少,因此最后结尾划分主题时,不能少于两个段落,并且结尾段落最大差值不能低于前面段落划分所有最大差值的最小值,例如D1~D6 的所有最大差值的最小值为0.37,而D7、D8、D9 的最大差值分别为0.08、0.14、0.00 都小于0.37,因此都不足以单独成为主题,故将D7、D8、D9划分为同一主题。
3 主题摘要提取
从实用性方面讲,简短的信息往往更容易被人接受。当我们对文本进行主题划分后,有一定的几率会发生多数段落同时存在于一个主题中的情况,因此,迫切需要一种方法将主体的中心句取出并作为摘要,其既能减少无效信息的扰乱、烘托出该主题的作用,又能使摘要通俗易懂、简洁明了。通过计算得出不同主题中不同句子的权重,按照权重大小进行排序,找出主题句中的中心句并生成摘要是本文使用的TF-IDF算法的主要功能。
TF-IDF 实际上是TF(Term Frequency)×IDF(Inverse Document Frequency),假设某个词语或者短句在一篇特定的文章中出现的频率较高,但是在其他的文本中出现的频率很低,那么我们就可以认为这个词语或短句的类别区分能力很好、代表性很强,甚至能够代表该文章,这就是TF-IDF的中心思想。计算公式如下:

TF 表示一个给定的词语在整篇文章中的出现次数,其计算公式如下,其中cout(w)表示文章中词条w 的出现次数,|Di|表示文章Di 中所有词条的个数:
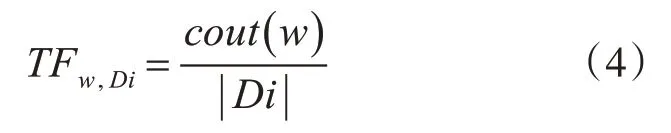
IDF 表示逆向文档频率,其计算公式如下,其中N 表示语料库的文档总数,I(w,Di)表示文档Di是否包含关键词,包含为1,不包含为0:
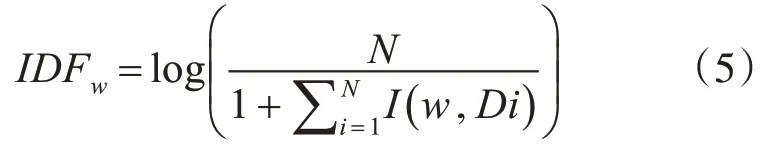
可想而知,当通过TF 进行词频统计,出现最多的是“的、在、是”这一类停留词,因此我们在主题中的段落进行分词操作之后,将停留词和标点符号过滤去除,留下特征词,再针对不同的词语,分别计算TF-IDF 的结果,再对结果取平均值来表示当前句子在当前主题内的权重,计算公式如下:
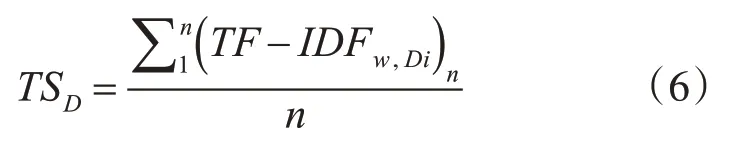
其中n代表句子中词语的个数,对得到的TS进行排序,优先选择权重高的作为当前主题的中心句。
例如某一主题段落中有三个句子分别如下:
D1:疫情期间,学生参加学校组织的线上课程学习和考试。
D2:老师制定相应的教学计划,确定学生考核要求。
D3:同学们要主动适应全新教学模式,积极配合任课老师。
三个句子依次用D1、D2、D3 表示,分别对三个句子进行分词、去标点符号、去停留词操作,D1、D2、D变为:
D1:疫情期间学生参加学校组织线上课程学习考试
D2:老师制定教学计划确定学生考核要求
D3:同学们主动适应全新教学模式积极配合任课老师
然后根据式(3)、(4)、(5)、(6)计算权重:
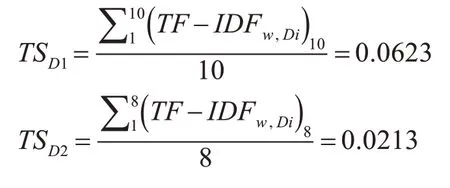

D1 权重最高,将选择D1 对应的句子作为该主题的中心句,因此将其作为文本主题摘要。
在实际抽取中心句的过程中,主题划分之后的各个主题段落包含句子数量各不相等,包含一个至两个句子的可以直接将所有句子作为当前主题的摘要,包含三个及以上的句子,提取多少中心句作为摘要是一个需要解决的问题。经过人工实验经验,选取阈值σ=0.05,当句子TS 值大于等于σ,提取当前句子为中心句,当句子TS 值小于σ,舍弃当前句子。最后将每个主题段落提取的中心句合并成为当前主题的摘要,再将文本各个主题段落的摘要组合形成文本摘要。
4 基于主题划分及TF-IDF 的文本摘要提取方法流程
根据前面的分析和设计,本文提出一种基于主题划分及TF-IDF 的文本摘要提取方法(Text topic division and TD-IDF abstract extraction,TDTAE),该方法具体流程为
1)设待处理文本有m 个段落为D1,D2,…,Dm,将每个段落处理,保留特征词。
2)为得到段落相似度矩阵表,首先将不同段落之间的特征词进行相似度计算,可使用Word2vec方法,在依据上述式(1)计算获得不同段落的相似度值。
3)最大差值按照式(2)将每行两个相邻的段落带入来计算。
4)根据上述所阐述的主题划分思想,按照顺序选择出不同段落的主题。
5)根据式(3)、(4)、(5)、(6)计算每个主题段落中句子的TS值。
6)若句子数量小于等于2,则选取全部句子作为当前主题摘要,句子数量大于2,则根据阈值σ来选取中心句作为主题摘要。
7)将文本所有主题摘要按顺序合成文本摘要。
5 仿真实验及结果分析
文本摘要抽取分为两个实验,选取不同数据集进行测试,并和传统文本摘要处理方法对比。
1)实验1
从知网中抽取400 篇不同领域的论文,构建知网论文数据集,使用本节提出方法提取正文摘要,并与论文摘要进行cos 余弦相似度计算,余弦值大于0.6的记为提取的摘要合格。该实验使用“结巴”进行分词处理,使用Word2vec 训练词向量模型,使用准确率(Precision)、召回率(Recall)和F值(F-Measure)三个指标来评估本章算法的性能。
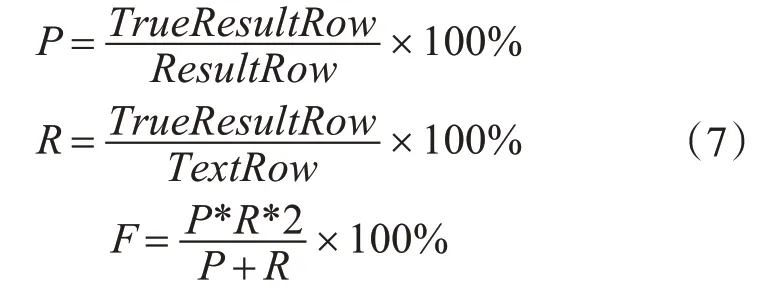
其中TrueResultRow为返回结果中属于文本摘要内容的行数,ResultRow为算法返回结果的总行数,TextRow为文章摘要的总行数,将本文提出的基于文本主题划分与TD-IDF的文本摘要抽取方法(TDTAE)与TF-IDF 提取方法、TextRank 提取方法进行实验对比,实验结果见表3。

表3 TDTAE与TF-IDF、TextRank对比结果
通过表3 可以看出,在知网论文数据集摘要抽取方面,TDTAE方法相比TF-IDF、TextRank方法准确率召回率都有提高,这说明TDTAE 方法是可行有效的。
2)实验2
此部分实验采用DUC 数据集及其摘要评价方法来相对客观、真实、有说服力的突出TDTAE 方法的可靠性、高效性、准确性等性能优势,其采用Rouge-N 和Rouge-L 方法作为内部评价指标,该评价方法是国际通用且相对客观的评价方法。从维基百科的英文语料库中选取本实验所要用到的Word2vec 词向量模型,Word2vec 模型占用约1.26G的存储空间,为从多方面突出TDTAE 方法的性能,将其与MDT方法进行实验对比,实验结果见表4。
从表4 可以得出结论,TDTAE 方法与MDT 方法相比,其他因素相同的条件下,TDTAE 方法在任务Rouge2、Rouge3、Rouge4 中得到的结果更优,这也从侧面反映出由TDTAE 方法生成的摘要与文献中真正的摘要在词顺序和结构上相似性更好、一致性更强,因此得到的语句可读性更强,更加易懂、通俗、顺畅。尽管准确率、F 值这两个指标在Rouge1、RougeL 两个通道中TDTAE 方法要稍微逊色于MDT方法,但是显而易见,表中TDTAE方法的召回率数据更优于MDT 方法,因此我们可以就重避轻,尽可能地去放大其优点、弱化其缺点,更多地去注意获取文本主题的中心内容。段落之间的关联、依赖关系是导致TDTAE 方法产生这一性质的主要因素。

表4 TDTAE与MDT对比结果
6 结语
本文提出一种基于文本主题划分及TF-IDF的单文本抽取式摘要提取方法,该算法无论是在知网论文数据集还是在DUC 公共数据集中准确率、召回率、F 值均比传统算法要好,并且该方法适用范围广。后续研究中,将进一步简化该方法的计算复杂度,提升算法效率。
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
高中时代(2017年7期)2018-02-24
读与写·教育教学版(2017年10期)2017-11-10
南方农业·下旬(2017年8期)2017-10-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
科技与创新(2014年8期)2014-07-17
