
基于双流P3D-Resnet 的人体行为识别研究*
2022-09-28 01:40:08缑新科吴宣言
计算机与数字工程 2022年8期
缑新科 王 凯 吴宣言
(1.兰州理工大学 兰州 730050)(2.甘肃省工业过程先进控制重点实验室 兰州 730050)
1 引言
早期的人体行为识别研究通常使用方向梯度直方图HOG(Histogram of Oriented Gradients)[1]计算图像中人体局部外形的方向梯度次数来描述行为特征,使用光流直方图HOF(Histograms of Oriented Optical Flow)[2]以及稠密轨迹特征提取等方法描述相邻视频帧之间的局部时空特征变换。传统行为识别算法之一的稠密轨迹特征采样DT(Dense Trajectories)[3]通过在空间尺度对图像特征进行划分、采样以及跟踪之后形成特征轨迹,然后对特征进行编码和表达,最近采用分类器对行为特征进行分类。改进稠密轨迹采样IDT(Improved Dense Trajectories)[4]在稠密轨迹的基础上对背景区域的光流轨迹进行了优化,以此消除背景带来的干扰,并且将特征归一化方式由L2 改成L1 后再对特征的每个维度开平方,进一步提升了识别准确率,该算法在深度学习出来之前被广泛的应用。
随着深度学习在计算机视觉领域应用逐渐广泛,机器可以自动进行特征学习。应用卷积神经网络CNN(Convolutional Neural Networks)[5~6]在行为识别研究方向上,能够提取图像中行为特征的语义信息,许多识别网络都在CNN 的基础上进行改进,并且在前者的基础上取得了更好的验证效果。为了提升网络对长序列特征的表达能力,文献[7]提出LRCN(Long-term Recurrent Convolutional Networks),首先使用CNN 提取和学习空间域特征信息,然后经过长短期记忆LSTM(Long Short Term Memory)网络对行为特征进行分类。为了提取更多复杂序列的动态时序特征,提高行为识别精度,文献[8]提出了长短期记忆网络LSTM+RNN(Recurrent Neural Networks)模型,经过验证效果显著。文献[9]提出了具有恒等快速连接特征的Resnet(Residue Neural Networks)卷积网络,能够较好地规避在神经网络训练时出现难以训练的问题,对提升识别精度具有重要的作用。为了能够关联更多相邻视频帧之间的特征关系,文献[10]提出双流卷积融合(Two-Stream Neural Networks)模型,旨在学习相邻视频帧之间的光流特征,获得关联特征信息后与RGB 视频帧的特征信息进行融合与分类,进一步提升了行为识别的精度。文献[11]等提出基于TSN(Time Segment Neural Networks)片段的Inception 网络,通过并列延伸不同网络分支达到多尺度特征维度的提取和融合的目的,使得提取到的特征信息更加全面,有利于提升识别效果。文献[12]等提出的注意力机制网络SE-Net(Squeeze and Excitation Neural Networks)能够更好地捕捉到底层行为特征信息。
为了进一步掌握具有连续时空性质的人体行为特征关系,文献[13]系统性的将时间维度与二位空间维度进行融合,以此实现对连续视频帧的特征提取作用,提出了三维卷积神经网络C3D(Three Dimensional Convolutional Neural Networks)。此外,Tran 等在三维卷积的基础上对网络模型进一步进行结构改造和优化,提出了3D-Resnet 网络,再一次提升了网络的识别精度。文献[14]通过维度扩展给卷积核与池化核增加时间维度,并且将其应用到一个新的模型I3D(Three Inception Dimensional Convolutional Neural Networks),使得网络性能得到了巨大提升。但是三维卷积网络的层数加深并不会一直增加识别精度,反而由于参数量的增加容易使得训练网络难以收敛。文献[15]基于3D-Resnet网络提出了先对网络进行维度分解,再合并的P3D(Three Dimensional Pseudo Convolutional Neural Networks)网络模型,通过在空间网络维度上增加时间维度,不仅减少模型的参数计算量,同时也对网络模型的空间表达能力起到了较好的优化作用。
本文采用基于双流P3D-Resnet(Three Dimensional Pseudo Residual Neural Networks)网络的行为识别模型,将RGB视频帧和光流帧分别输入到P3D网络中,并且在网络的底层加入注意力机制。提取更多的人体行为特征,在减少网络模型参数量的情况下,提高网络计算能力。在UCF101 数据集上进行训练与验证,取得较高的识别精度。
2 相关研究
2.1 光流计算
光流(Optical flow)由Horn,Schunck[16]等提出,它是指空间运动物体在观察平面上相对背景产生的像素位移变化。近年来的光流计算方法主要有Lucas-kanade、TV-L1[17]以及基于深度学习的Flownet2.0[18],通常用平均角误差和平均端点误差作为衡量算法性能的标准。本文假设像素点在运动时保持亮度不发生变化的前提下通过光流提取人体运动过程中的动态信息。考虑到用TV-L1 算法计算得到的平均角误差ℓaae和平均端点误差ℓeea所花费的时间较短,且效果理想。本文选用TV-L1算法进行光流帧的计算,其光流模型:
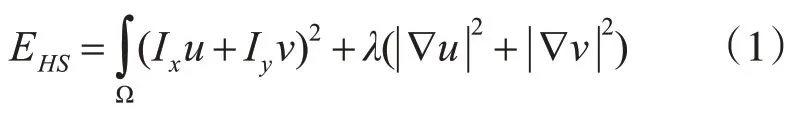
设I(x,y,t)表示图像中的某一个像素点,当其产生位移时,即从时刻t→t+Δt时,产生位移为(x+Δx,y+Δy),假设亮度保持恒定,则有:
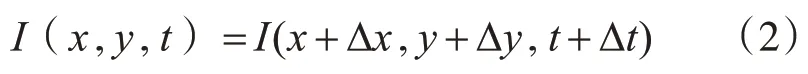
将公式的右边进行泰勒展开,得到式(3):

消除I(x,y,t),并且忽略高阶项Θ(Δt2)。式(3)两边同时对Δt求导,得到光流的约束方程,其中:

上式(u,v)即为I(x,y,t)的光流。
2.2 三维卷积神经网络算法
在卷积计算过程中,卷积层中连续层之间的特征map结合多组相邻的视频帧之后,对其连续的运动特征信息进行表达[19]。三维卷积的运算模块被描述为C(n,m,d),可表示成输入尺寸n×n×n的卷积层与d个尺寸为m×m×m的特征图。三维卷积计算公式如式(1)所示,计算第i个卷积层里面第j个特征图中(α,β,γ)位置处的输出形式:
无论是PBL教学法、TBL教学法、虚拟现实教学法还是标准化病人教学法,都有着优势与不足。但是即使教学模式产生了巨大变化,它的根本目的也不会改变,就是让学生在最少的时间里最大程度的掌握医学知识和临床实践技能。为了达到这种目的,教师在课堂上也可以尝试将几种教学方法相结合,实现优势互补。

式中,f表示在第i-1层与第i层第j张特征图相连的特征图数量。是第(p,q,r)个特征内核的权重,bij为对应特征映射图的偏置,tanh 为卷积网络的激活函数,通过网络训练可得到网络权重以及偏置。
2.3 P3D-Resnet三维残差网络
在三维残差网络结构的基础上,将残差网络维度先分解为空间维度,后与时间维度相合并,即P3D(Three Dimensional Pseudo Convolutional Neural Networks)网络,P3D 网络不仅能够减少模型参数计算量,同时能够提升网络的优化能力。如图1所示的三种网络结构P3D-A、P3D-B、P3D-C。在训练网络时,将这三种结构进行串联连接。
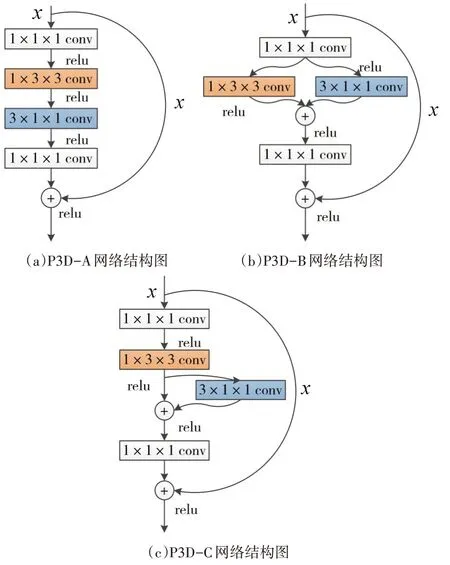
图1 P3D-Resnet三种网络结构图
2.4 注意力机制(SE-net)网络
为了表达建模特征通道间的关系,通过自主学习的方式获知每个特征通道的重要程度。本文将注意力机制引入到卷积神经网络中。SE-Net(Squeeze and Excitation Neural Networks)嵌 入Resnet网络的结构中,如图2所示。
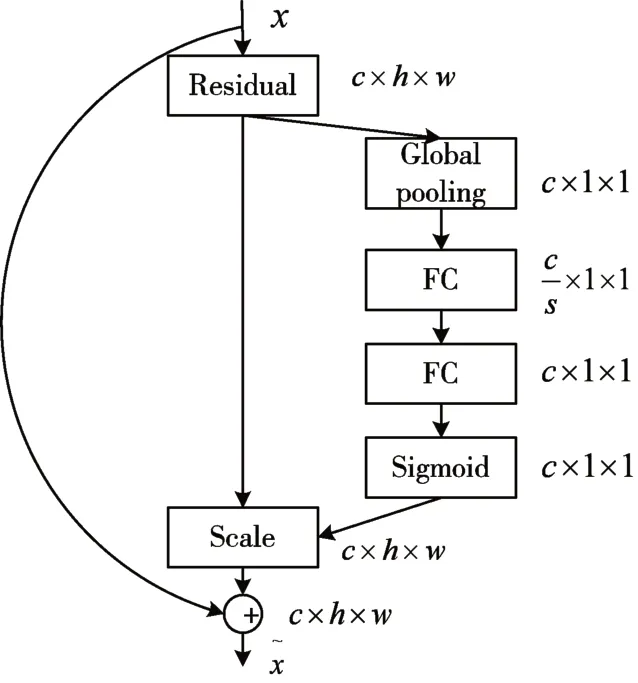
图2 SE-Net注意力机制网络结构图
在残差模块之后建立分支,使用global average pooling 对特征通道进行Squeeze 操作提取全局信息,然后将两个全连接层组成一个Bottleneck 结构去建模通道间的相关性,保持输出特征权重的数目与输入相同[12]。对网络进行特征降维,将特征维度降低到输入的,c表示该网络层特征维度,s表示该网络层的降低倍数。

式(7)中,H、W分别代表图像的高和宽,uc(i,j)代表在(i,j)处的特征。同理我们可以得出在三维卷积神经网络中的Squeeze操作表达式:

式(8)中,H、W、L分别代表图像的高和宽以及时间维度,uc(i,j,k)则代表在(i,j,k)处的特征。网络经过Relu 激活后通过一个全连接层进行特征升维,升回到网络的原维度,并通过一个Sigmoid的门操作获得0-1 之间归一化权重,具体公式如式(9)所示,σ和δ分别表示Relu和Sigmoid激活函数。
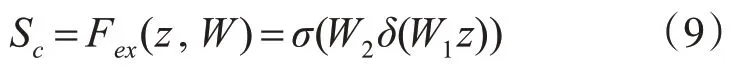
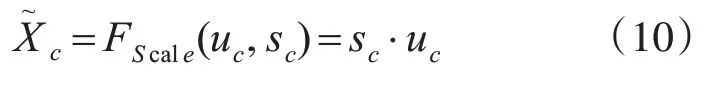
3 本文算法
3.1 算法框架
本文采用基于双流P3D-Resnet 网络的人体行为识别框架。整体网络结构如图3所示,将RGB视频帧与Flow 光流帧作为输入,分别输入到P3D-Resnet 网络中训练,将P3D 网络与注意力机制在底层相结合,获取更多的底层空间维度的特征信息。以Resnet50 残差网络为网络基础,包括5 个卷积层,1 个全连接层,以及一个对视频中行为进行分类的Softmax 层,卷积层后面有一个归一化层和Relu 激活层。本文采用最大值池化方法,其卷积核大小为3×3×3,步数为2。在网络的前30 层加入注意力机制。将双流网络分类的结果进行Softmax 融合,并使用交叉熵函数计算模型的损失函数。

图3 基于双流P3D-Resnet网络算法框图
3.2 算法结构
对于不同结构的P3D-ResNet,在空间尺寸大小为182×242 的视频帧中随机裁剪大小不重叠的16帧作为输入视频帧,即16×160×160,并且通过随机水平翻转的方式对输入视频帧进行数据增强。如 表1 所 示,将3D-Resnet50、P3D-Resnet50、P3D-Resnet50+SE三种网络结构进行比较。

表1 3D-Resnet50、P3D-Resnet50、P3D-Resnet50+SE三种网络结构
4 实验设置与结果分析
4.1 数据集
本文使用公开数据集UCF101[20],样本来自Youtube 视频网站。此数据集包括有101 种行为类别共13320 个视频样本,每个视频大约有150 个视频帧,视频帧的空间分辨率在320×240。选取样本中70%作为此次实验的训练集,选取剩余30%作为验证集。行为类别可以分为4 种类型:1)人和人互动;2)体育活动;3)演奏乐器;4)人与物体互动。在使用数据集时,将视频帧进行水平翻转、缩放以及整体旋转等操作扩展数据集,防止网络过拟合。
4.2 本文实验平台
1)计算机系统:Windows10 专业版,8G 内存;2)CPU 型号:AMD A8-6500 APU with Radeon HD Graphics;3)GPU 版 本:Nvidia GeForce GTX1080,8G 显存;4)网络框架:Tensorflow,Tensorflow-Gpu版本:1.14.0,Opencv-python版本:3.4.2;5)Cuda版本:10.0.130,Cudnn版本:7.6.4。
4.3 实验训练参数
将视频帧及其x,y方向上的光流帧灰度图像输入训练网络,由于光流帧与视频帧的通道数不同,在训练前分别对卷积网络通道进行调整。网络训练采用SGD 小批量随机梯度下降法,权值衰减率weight decay 为0.0005,dropout 层的丢失率设置为0.5,初始学习率learning rate 为0.001,每训练5 个epoch 后学习下降5 倍,SE-net 注意力机制网络的维度下降倍数S设置为16,epoch设置为25。
4.4 实验结果分析
图4 展示了本文模型在UCF101 数据集上的训练与验证结果,accurary 为本次实验的训练精度,val_accurary 为验证精度。本文验证精度达到了94.3%,能够对人体行为识别起到提高作用。图5展示了本文模型训练的损失函数,损失函数下降比较明显,体现出了本文网络能够有利于进行人体行为识别。
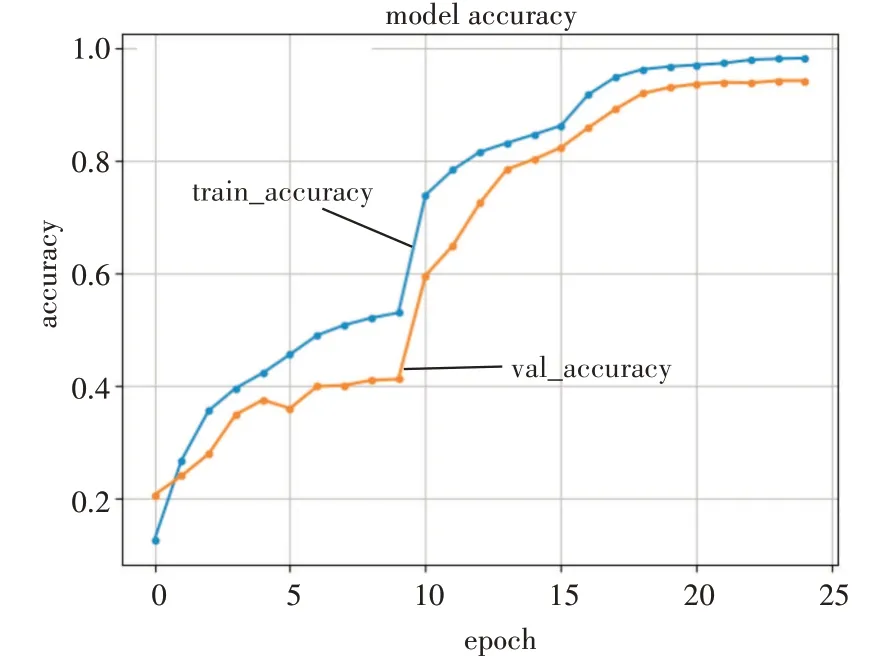
图4 双流P3D-Resnet卷积网络识别结果

图5 双流P3D-Resnet卷积网络损失函数
通过表1,可得到三种网络性能的对比,并得到模型大小。如表2 所示,P3D-Resnet+SE 网络的参数量较3D-Resnet 网络的参数量小,较P3D-Resnet 网络的参数多。在实际训练中,P3D-Resnet+SE 网络能够提取到更多的底层特征,提高卷积神经网络的识别能力,其实验结果较3D-Resnet、P3D-Resnet好,有较好的识别能力。
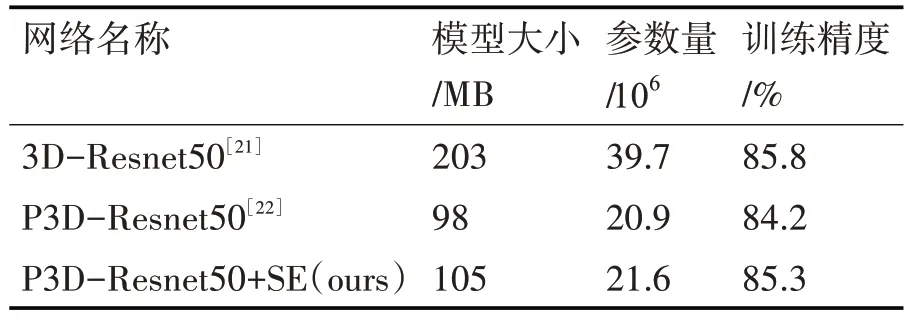
表2 3D-Resnet、P3D-Resnet以及P3D-Resnet+SE三种网络性能对比
表3 显示本文网络与当前一些主流网络进行对比。本文结合Two-stream P3D Resnet实验,将注意力机制加入到Resnet50 网络的底层网络。获得了较好的实验效果。下一步将会将注意力机制与整个Resnet神经网络进行结合,在扩充网络结构的基础上,避免网络产生更多的模型参数。不断进行实验,得到更高效的识别结果。

表3 本文模型与其他主流网络识别结果对比 单位:%
5 结语
本文提出的对双流P3D-Resnet 网络进行网络改进并在UCF101 数据上进行训练,旨在学习深度网络的时空特征表示。将三维残差卷积神经网络用一个二维卷积网络和一个一维卷积网络替换,并且在网络中加入注意力机制,使网络能够学习到更多的底层特征,提高网络的准确率。本文分别将RGB 视频帧与Optical flow 光流帧输入到网络进行学习,将双流网络识别结果进行融合后得到更好的结果。通过与其他的网络模型进行对比得出结论,将注意力机制与P3D-Resnet 网络结合对卷积网络人体行为识别效率有提高作用。下一步,将在更深层的卷积神经网络中进行实验。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
中小学校长(2022年7期)2022-08-19 01:36:36
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
冶金设备(2020年2期)2020-12-28 00:15:22
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
电子制作(2019年11期)2019-07-04 00:34:38
电光与控制(2018年10期)2018-10-13 08:19:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国铁道科学(2014年6期)2014-06-21 06:35:32
