
基于改进YOLOv5 的海洋生物检测算法*
2022-09-28 01:40朱伟东何月顺任维民孙一蓬
计算机与数字工程 2022年8期
朱伟东 何月顺 陈 杰 任维民 孙一蓬
(1.东华理工大学信息工程学院 南昌 330013)(2.江西经济管理干部学院 南昌 330088)
1 引言
海洋中的海参、海胆、扇贝、海星等生物含有丰富的蛋白质,且易于被人体吸收。世界上一半以上的人口依赖海洋生物作为蛋白质的主要来源。随着人口在不断增长,海洋生物的需求持续攀升,水下机器人捕捞爆发式增长,如果不加以选择、盲目的捕捞,会误捕很多不是目标的物种,会对其造成伤害甚至死亡,严重破坏了海域资源和海洋生态系统[1]。近年来我国大力发展海洋牧场,将深度学习方法应用在海洋水产业中,推动海洋经济的高质量发展,对保护海洋生态环境具有重要意义[2]。
随着深度学习和计算机视觉的迅速发展,大量学者着手研究水下目标检测任务。洪亮等[3]提出一种基于改进YOLOv3 的海珍品实时检测方法,在数据预处理阶段引入马赛克(Mosaic)数据增强方法,丰富了水下海珍品的背景和数目,提升了图像的检测效果,但原始Mosaic 数据增强最多将4 张图片进行随机裁剪、缩放等操作拼接到一张马赛克图片上,会产生大量无用的灰边,影响模型训练的效率。朱世伟等[4]采用类加权损失方法来提升YOLO算法的水下目标检测性能,但需要根据数据样本的特征,人为地给每一个样本类别设计适当的权重来获得最佳的检测效果,效率较低。李宝奇等[5]将重构SSD算法中的基础网络和附加特征提取网络,通过添加可扩张可选择模块ESK 以提高合成孔径声呐图像水下目标的检测精度,但计算其合适的扩张系数和多尺度系数过程繁琐,计算量较大。林森等[6]提出一种改进YOLOv5 的水下珍品检测方法,通过融合CBAM 注意力机制、添加检测层等方式改进算法结构,来提升模型检测精度,但融合CBAM、添加检测层操作都会给模型引入额外参数量。
基于上述研究,本文提出了一种改进的YOLOv5 海洋生物检测算法,有效地解决了目前海洋生物检测模型在复杂环境下对小目标存在特征提取能力不足、检测精度低的问题。改进思路包含两个方面:一方面是改进Mosaic 数据增强,丰富了小目标数据集的数目,用于提高模型对小目标检测的能力;另一方面在YOLOv5 的主干网络引入SimAM注意力模块,对海洋生物特征图分配3D 注意力权值,在不增加模型参数量的情况下,加强了模型提取特征的能力,进而提高目标的检测精度。
2 基础理论
2.1 目标检测算法
基于深度学习的目标检测算法主要分为两类:两阶段检测器(Two-stage detector)和单阶段检测器(One-stage detector)。常见的Two-stage detector 有Faster R-CNN[7],该类算法通常检测精度较高,但检测速度较慢。具有代表性的One-stage detector有SSD[8]、YOLO系列[9~10]等,该类算法通常比Two-stage detector 速度更快、轻量、应用范围更广。结合应用场景,本文选择One-stage detector 中的YOLOv5 算法v6.0 版本作为海洋生物分类检测的模型,将全国水下机器人大赛数据集输入到模型中训练,使用训练好的模型来实现海洋生物的检测。
2.2 YOLOv5算法原理
YOLOv5 算法共有五个网络模型:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x[11],网络模型参数如表1所示。其中,网络深度决定模型C3结构的重复迭代次数,网络宽度决定模型卷积核的通道数,YOLOv5n 是v6.0 版本新提出的模型,相比较YOLOv5s 模型,网络深度维持0.33 不变,但通道数从0.50减少到0.25,检测精度有所损失。综合考量,本文选择YOLOv5s 网络为代表,其网络结构如图1所示。
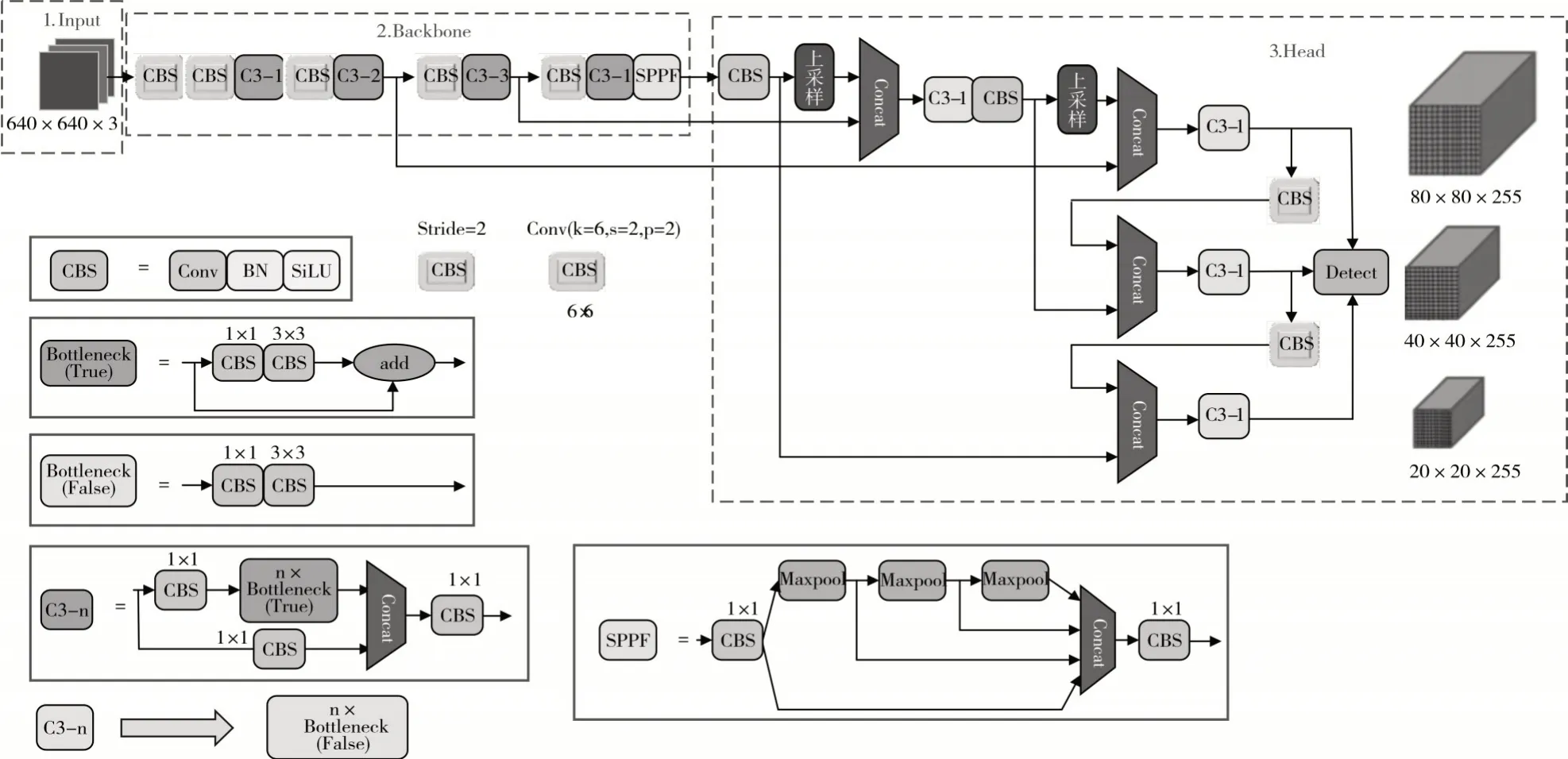
图1 YOLOv5s网络结构图
YOLOv5s 网络结构主要包括输入端(Input)、主干网络(Backbone)和预测分类器(Head)三个部分。
Input 部分,采用Letterbox 自适应图片缩放方法把原图的尺寸等比例缩放到标准尺寸,然后剩下部分采用灰边填充,计算公式如下:
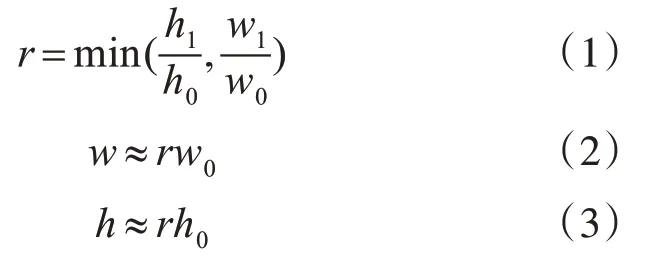
其中,w0和h0分别表示原始图片的宽度和高度,w1和h1分别表示标准尺寸的宽度和高度,本网络模型的标准尺寸为640×640,r为收缩比,w和h分别表示收缩后图片的宽度和高度。使用该方法的目的是为了保持原始图片的宽高比,减少图片的失真率,提高了模型的训练效率。
Backbone 部分的核心为CBS、C3、SPPF 结构。CBS 结构由二维卷积Conv2d、批量归一化处理BatchNorm2d 和激活函数SiLU 串联组成。C3 结构分为两条支路,上支路通过标准卷积和Bottleneck模块,下支路连接标准卷积再和上支路进行拼接,随后连接一个标准卷积。v6.0 版本使用SPPF 结构替换了v5.0 版本中使用的空间金字塔池化SPP 结构,并放到Backbone 部分的结尾以提升检测性能。SPPF 结构是先通过一个标准卷积将输入特征的通道数减半再分为两条支路,上支路采用三个5×5 的最大池化层串联,剩下一条支路未进行池化操作再和上支路三个池化层进行拼接,最后连接一个标准卷积从而实现不同特征图之间的优势互补的效果。
Head 部分的关键是路径聚合网络[12](PANet),PANet是基于特征金字塔[13](FPN)基础上引入了自底向上的特征融合,使得底层信息更容易传递到高层顶部,获取了更加丰富的特征信息。特征图通过Head部分进行预测并生成预测边界框和预测类别。
3 改进YOLOv5算法
3.1 改进Mosaic数据增强
YOLOv5 算法在数据预处理阶段采用Mosaic数据增强来丰富数据集,其处理过程最多将4 张图片进行随机裁剪、缩放等操作拼接到一张马赛克图片上,随后余下的部分采用灰边填充。原始Mosaic数据增强如图2(a)所示,但过多的灰边会导致模型学习到无关的特征信息,降低模型训练的效率。为了尽可能减少模型从训练数据中学习到无关的特征信息,本文将改进Mosaic数据增强模块。改为最多将9 张图片拼接在一张马赛克图像中,拼接顺序如图2(b)所示。使用改进后的Mosaic 数据增强有三点好处:一是提高了批训练大小;二是尽可能减少灰边填充的面积,提高模型训练效率;三是由于图片经过缩放后在尺寸上会更接近小目标的尺寸,扩充了小目标数据集,增强了模型的鲁棒性,能有效提高模型在海洋环境中对小目标的检测能力。
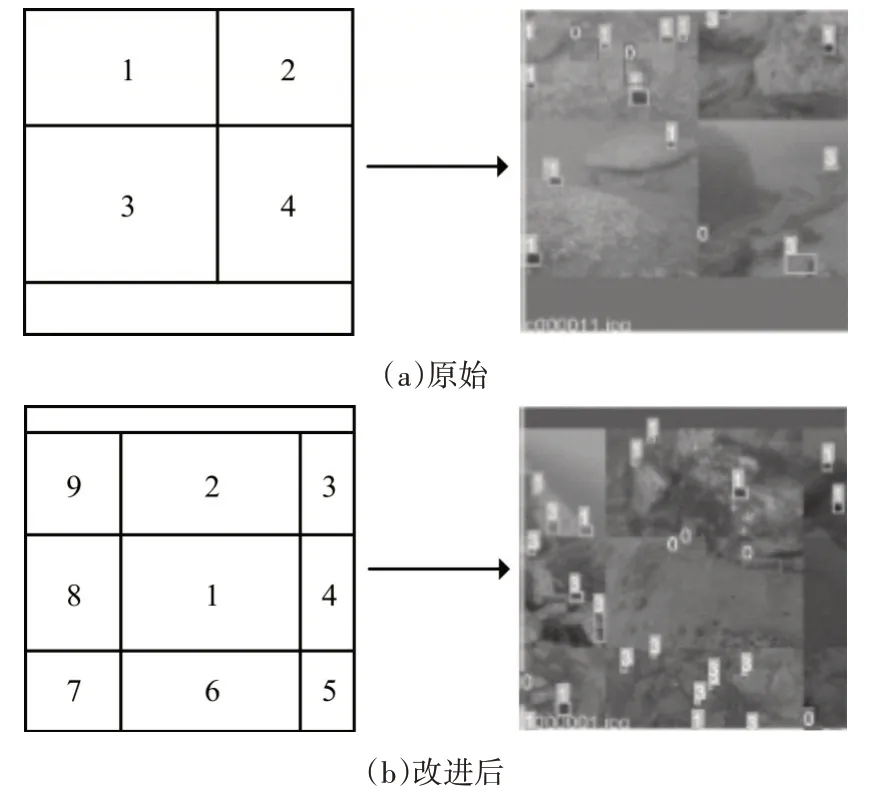
图2 改进Mosaic数据增强效果对比
3.2 SimAM无参注意力机制
通道注意力机制(SENet)通常会使模型沿着通道维度分配权值来提升模型的性能,但基于它们的结构会给模型带来额外参数[14~15]。SimAM[16]可以为特征图灵活地分配3D 注意力权值,从而增强模型提取特征的能力,进而提高目标的检测精度,且不会引入额外参数,同时也是一个即插即用的模块,分配3D 注意力权值示意图如图3 所示。SimAM 模块通过设计能量函数来评估每个神经元的重要性,避免了过多的结构调整。
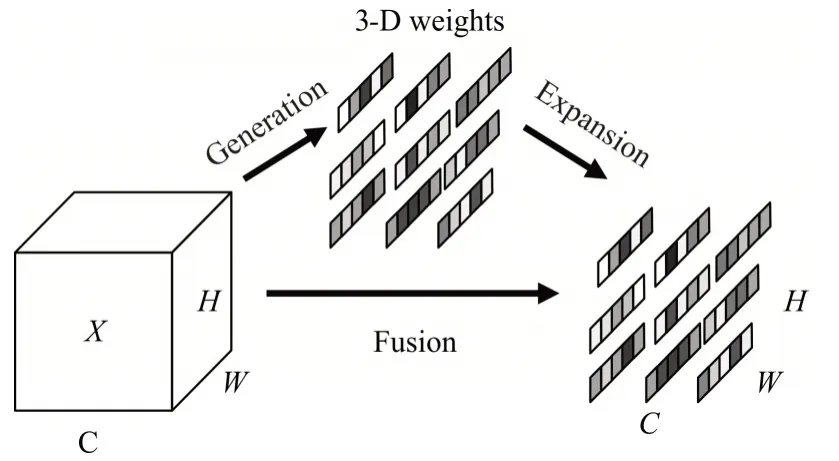
图3 分配3D注意力权值示意图
能量函数的设计主要是利用SVM 算法的特征。具体来说,离决策边界远的点是容易样本(Easy Sample),离决策边界近的点是困难样本(Hard Sample),很好地契合了神经学的理论。能量函数定义为
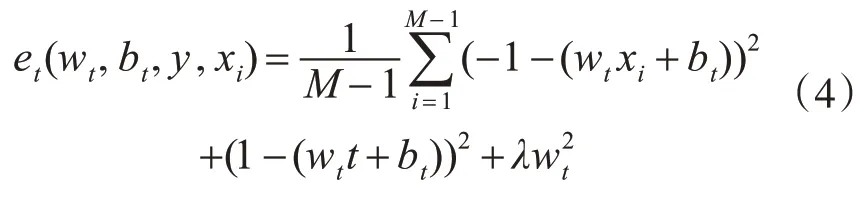
其中,t表示单通道中输入特征的目标神经元,xi表示除了目标神经元以外的其他神经元,wt和bt分别为t,xi线性变换的权重和偏置,i为空间维度上的索引,M=H×W为单通道上所有神经元的数目。通过计算wt和bt的闭式解,加速了注意力权值的计算。通过对wt和bt求偏导代入原能量函数,获取最小能量公式为

从式(5)可以看出,能量函数值越小,神经元t与其他神经元的线性可分性越大,重要程度越高。最终SimAM模块优化为

其中,E是将所有通道和空间维度中的能量函数进行分类。如图4 所示,本文在YOLOv5 的主干网络中的Bottleneck 结构引入SimAM 无参注意力机制,在不增加原始网络参数的情况下,帮助模型在检测过程中能更有效地提取目标的特征信息。

图4 引入SimAM无参注意力机制示意图
4 实验结果与分析
4.1 数据集
本文采用全国水下机器人大赛数据集,该数据集包含海参、海胆、扇贝、海星四种海洋生物图片,共计1415 张图片。海洋生物图片是由水下机器人在复杂海洋环境的海底下进行采集的,这些图片之间不存在帧间连续性。使用labelImg 图像标注工具对采集到的图片进行标注,图片的尺寸以及目标框参数信息存储在XML 文件格式中。将数据集按照7∶3 比例随机划分为训练集和测试集,送入到网络模型中训练。部分数据集如图5所示。


图5 部分数据集样本
4.2 实验环境和参数设置
本文实验环境为Windows10 操作系统,I5-11400F CPU@2.60GHz 六核,RTX 3060 Ti(8G)GPU,16GRAM,Python3.9.7 编程语言,CUDA-Toolkit11.3,CuDNN8.2.1 加速库,Pytorch1.10.0 深度学习框架。训练阶段采用Warmup 训练预热和余弦退火衰减策略[17]来对学习率进行动态调整。实验参数设置如表2所示。
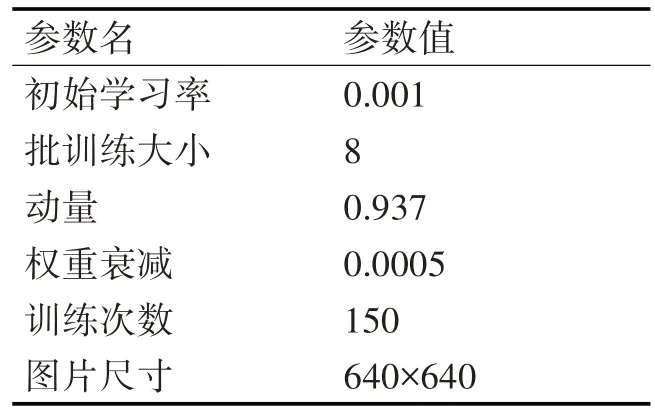
表2 实验参数设置
4.3 评价指标
本文使用查准率(P)、查全率(R)、参数量(Parameters)、平均检测精度(mAP)、每秒传输帧数(FPS)作为评价指标。
查准率为真正例率与真正例率及假正例率和之比。查全率为真正例率与真正例率及假负例率和之比。参数量是模型中的参数总数。平均检测精度为IoU=0.5 时,所有类别的平均精度(AP)的均值[18],计算公式如下:

式(7)和式(8)中的TP、FP、FN分别表示真正例、假正例、假负例,三者之间的关系依赖于表3 混淆矩阵。式(9)中的classes表示所有类别数和,本文所有类别数和为4。
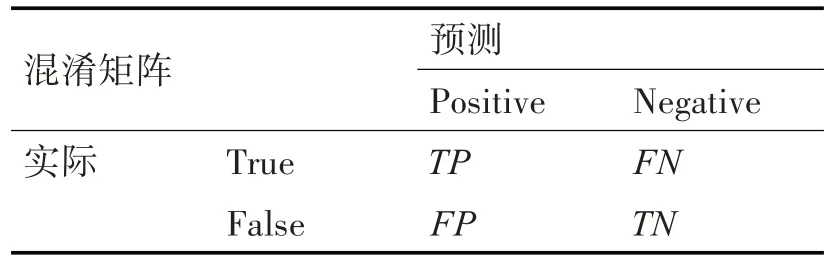
表3 混淆矩阵
4.4 模型训练结果
本文使用改进后的算法与原始YOLOv5 算法进行对比,图6 为训练过程中平均检测精度对比曲线,其中,横坐标代表训练次数,纵坐标代表平均检测精度。从图中可以看出,两种模型在80 轮左右趋于平缓,达到收敛,且均未出现欠拟合和过拟合的问题。相比于原始YOLOv5 算法,改进后的算法的平均检测精度得到一定程度的提升,具有一定的可行性。
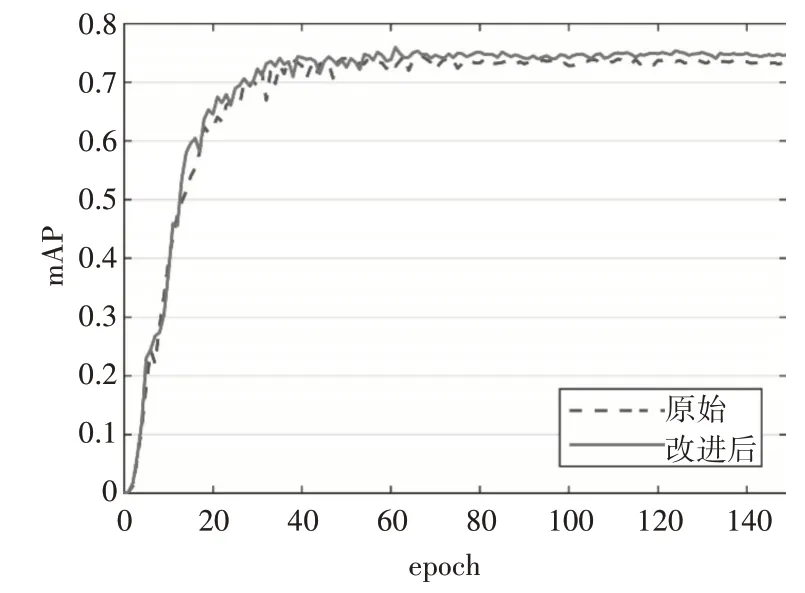
图6 平均检测精度对比曲线
4.5 实验对比分析
为了更加全面地验证本文提出的改进方法对海洋生物检测的影响,本文还使用SENet 作为对比方法,检测性能对比如表4 所示,改进1 使用改进Mosaic 数据增强,改进2 引入SENet 模块,改进3 引入SimAM 模块,改进4 将改进Mosaic 数据增强与SENet 混合使用,且各注意力机制添加的位置固定,表中“√”表示使用相应方法。
在表4 中,通过YOLOv5 算法、改进1、改进2、改进3 相对比,改进Mosaic 数据增强、SENet 以及SimAM 都能提高网络的检测性能,SENet 会使参数量增加15488,SimAM不会引入额外参数;通过YOLOv5算法与改进点4相对比,将改进Mosaic数据增强与SENet 混合使用会微略降低查准率、查全率以及平均检测精度;本文算法与YOLOv5 算法相对比,查准率提高了2.8%,查全率提高了1.7%,平均检测精度提高了1.6%。实验结果表明,本文算法对海洋生物检测精度最高,能有效地增强网络的检测性能并保持模型参数量不变。

表4 检测性能对比
为了进一步验证本文算法的检测性能,将本文算法与其他目标检测算法SSD、Faster R-CNN、YOLOv3、YOLOv4 进行对比,采用mAP、FPS 作为评价指标,如表5所示。

表5 不同算法下的实验结果对比
从表5 可以看出,本文算法在检测精度方面优于其他目标检测算法,且本文算法的检测速度比Faster R-CNN、SSD、YOLOv3、YOLOv4 算法更快。本文算法相较于YOLOv5 算法,检测速度仅慢5FPS,在一定程度上不影响海洋生物实时检测任务的同时提升检测精度。本文算法部分效果检测图如图7所示。

图7 部分效果检测图
5 结语
针对海洋生物检测任务,本文提出一种基于改进YOLOv5 的海洋生物检测算法,通过改进Mosaic数据增强,提高对小目标的检测精度;同时在YOLOv5 的主干提取网络引入无参注意力机制,增强检测网络提取特征的能力。实验结果表明,本文算法在不增加模型参数量的情况下,获得了更高的检测精度,且几乎不影响检测速度,最终得到模型的权重大小仅13.7MB,为水下机器人进行精准识别和捕捞提供了技术支持。在下一步工作计划中,进一步优化模型结构,将优化后模型植入到嵌入式设备,以实现海洋生物更轻量、更高效的检测。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小雪花·成长指南(2022年1期)2022-04-09
学苑创造·A版(2022年3期)2022-03-29
百科探秘·海底世界(2021年2期)2021-03-18
小天使·一年级语数英综合(2020年6期)2020-12-16
小猕猴智力画刊(2018年4期)2018-06-09
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
电子技术与软件工程(2016年24期)2017-02-23
第二课堂(课外活动版)(2016年2期)2016-10-21
职业·中旬(2009年12期)2009-06-01
