
基于XGBoost 算法的学业成绩预警模型研究*
2022-09-28 01:40:08崔佳杉
计算机与数字工程 2022年8期
崔佳杉 年 梅 张 俊,2
(1.新疆师范大学计算机科学技术学院 乌鲁木齐 830054)(2.中国科学院新疆理化技术研究所 乌鲁木齐 830011)
1 引言
学业成绩预测是帮助学生规避学业风险的重要手段。在高校教学中,学生课程成绩是衡量学生知识掌握程度和教师教学结果的重要尺度,对学生学业成绩进行预测,能够为学生提供课程提供指引,帮助学生规避学业风险[1~4]。但是学校现有教务管理系统无法有效实现学业预警等功能,这也限制了新一轮人才培养方案的调整与制定。针对以上问题,本文提出一种基于XGBoost 回归算法的学业成绩预警模型。XGBoost 作为开源机器学习项目,高效地实现了GBDT 算法并进行了改进,将之运用到学业成绩预警上具有很重要的理论意义。
随着学分制改革的发展,基于学分制改革思维基础上的全过程教务管理系统应该能够满足学生选课、学分查询及学业预警、个性化人才培养方案订制。王斌等[5]使用Pearson 相关系数、随机森林算法和Apriori 算法,评价学生不及格的状态,建立预警规则,但是通过分类特征预测出学生不及格准确率情况有待提高。刘丽娟等[6]基于随机森林算法构建学生学业预警预测模型,但在预测结果中只有“被预警”和“不被预警”两类,一定程度上限制了研究结论的应用范围。刘姣等[7]利用模糊决策树算法确定了模型属性指标,通过改进决策树算法和建立模糊矩阵对学生学业成绩进行分析,但是并未对模糊决策树模型进行实验精度的准确评估。喻铁朔等[8]在SVR 回归在成绩预测预警中的应用研究中,在微观经济学和数理统计课程的预测正确率分别为15.79%和96.87%,正确率差异十分明显,但相应的成绩和学业预警能满足部分教学管理和改善学生学业的需求。Kotsiantis等[9]应用了几种DM算法来根据大学远程学习计划预测计算机科学专业学生的表现,对于每个学生,将几个人口统计学(例如性别、年龄、婚姻状况)和表现属性(例如给定作业中的分数)用作二进制合格/不合格分类器的输入,通过朴素贝叶斯方法获得准确度为74%,准确率有待进一步提高。
2 XGBoost算法模型
2.1 XGBoost算法
2.1.1 梯度提升数(GBDT)
XGBoost 本质上是一个GBDT,属于boosting 方法。2001 年Friedman 等提出一种通过迭代产生的决策树算法,即梯度提升树(GBDT)。该算法由多棵决策树组合而成,最终预测结果是把所有决策树得出的结论相加[10~11]。利用传统的回归决策树进行训练,得到图1所示结果。
图1 传统回归决策树
利用GBDT 方法进行训练时,得到图2 所示结果。

图2 GBDT模型
第一棵树分枝中的结果与图1 一样,由于A 和B的年龄差距不大,C和D 年龄相差也不大,因此将平均年龄作为预测值被分为两类。计算残差时,需要用实际值减去预测值,此时A 的残差为15-16=-1,B 的残差为1,C 的残差为-1,D 的残差为1。在下一棵树的学习中,ABCD 的原值用残差代替,若预测值=残差,则需要把结果累加。第二棵树上被分成两个节点的1 和-1,此时残差结果为0,即预测值真实。
2.1.2 XGBoost算法原理
XGBoost 是在GBDT 的基础上进行改进,引入了树模型的复杂度,避免过拟合,在学习效果和训练速度上有很大提高。其核心算法思想为:利用每次特征分裂后的树去拟合预测残差,最后该样本的预测值为每棵树对应的样本特征相加。
XGBoost的实现过程:
设xgboost模型的第t轮的目标函数为公式:

l为第t 轮的损失项,Ω为模型中决策树的正则项,即:
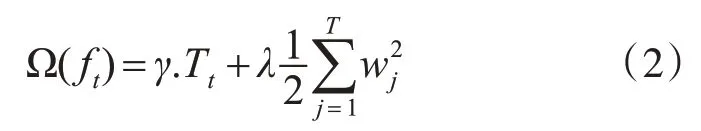
根据泰勒展开公式得到,得到最优系数和目标函数最优值:

2.2 模型评价指标
1)SSE(和方差)
该参数计算的是拟合数据和原始数据对应点的误差的平方和[12],计算公式为

其中yi是真实数据是拟合的数据,wi>0。数据预测结果的准确性与SSE 的值相关,模型的拟合程度越好时,其SSE值越接近0。
2)MSE(均方误差)
该参数是预测数据和原始数据对应点误差的平方和的均值,也就是[13],计算公式为
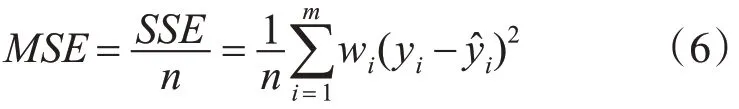
其中n为样本的个数。
3)MAE(平均绝对值误差)
为了更好地反映预测误差的情况,引入绝对误差平均值的概念。
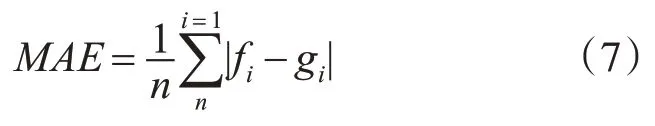
其中,fi表示预测值,gi表示真实值。
4)拟合优度(GOF)
回归直线对观测值的拟合程度称为拟合优度(Goodness of Fit)。可决系数(也叫作确定系数)r2是度量拟合优度的统计量[14~16]。r2的取值范围是[0,1]。r2的值越接近1,说明回归直线对观测值的拟合程度越好;反之r2的值越接近0,说明回归直线对观测值的拟合程度越差。
设y为待拟合数值,其均值为,拟合值为,记为
总平方和:

回归平方和:
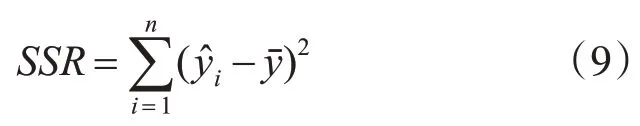
则有:

得到决定系数:

3 实验仿真与分析
3.1 数据集
实验数据集,采用UCI 公开的数据集:Student Performance Data Set[7]。该数据包括了两所葡萄牙中学学校的学生学业成绩情况。数据属性包括学生成绩,学习时间,家庭人员受教育程度,课外学习时间,身体健康等相关特征。数据集中G1 和G2 分别对应第1 阶段成绩和第2 阶段成绩,G3 的成绩是在第3阶段发布,所以G3与G2和G1之间具有很强的相关性。
3.2 数据预处理
使用XGBoost 算法时,要进行稀疏数据的处理。XGBoost 模型内部建模成一个回归预测问题,要将输入数据转化为数值型。数据处理过程中要将string 类型的列放到list 中,建立字典,将类别转化成对应的序号。
3.3 实验参数设置与模型建立
在python3.7 中导入相关的库,然后导入数据集用做模型训练和预测,并在训练集和测试集中随机选择80%的数据量作为训练集数据,测试集为20%,训练集与测试集的比例为4∶1。利用xgboost.XGBRegressor 建立XGB 模型,其中,叶子节点是最大深度的10 倍,模型结果显示训练的回归指标为99.9%。
3.4 模型评估
基于mat 数据集中的396 个训练数据,采用XGBoost 算法建立的学生成绩预警模型,准确率达到了85.8%,如表1 所示。采用por 数据集中的650个数据样本,准确率也达到了83.2%,如表2 所示,因此该模型是有效的。

表1 mat数据集下的实验预测结果

表2 por数据集下的实验结果
由预测模型表明,学生成绩表现与一些其他因素相关,例如,与学校相关(例如缺勤人数,额外教育资助等),受众特征(例如,学生的年龄,父母的工作和受教育程度等。)基于XGBoost 算法的学生学业成绩预警模型,因其不错的学习效果和训练速度,应用教育数据挖掘,有很好的理论意义。
4 算法模型在高校学生成绩预测应用
采集计算机科学技术学院本科生2018 学年~2019 学年上下学期学生学习状态信息,包括学生考勤、学生作业、上学期期末成绩、下学期期末成绩。数据预处理的过程中,剔除空白数据和无效数据,将数据集保存成csv 格式,同样是在二进制/五级分类和回归任务下建模,如表3 所示。学生成绩数据集包含458 条有效数据,训练集与测试集的数据分别为368条和92条。

表3 学生成绩分类等级
对于表4 的预测结果进行分析,使用XGBoost算法模型进行实际应用,准确率达到75.2%。通过对学生学业成绩的预测结果分析,可以得出,作业差的学生成绩预测结果较差,考勤成绩较好的同学对期末成绩影响不大。
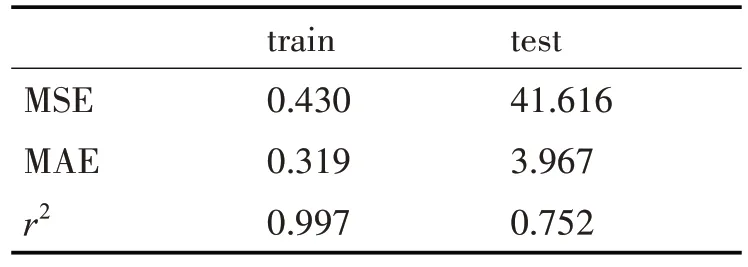
表4 模型应用结果
5 结语
文章讲述了XGBoost 算法的基本理论,采用XGBoost 算法回归模型对学生学业成绩预警问题进行了分析。通过公开样本数据集对算法模型进行学业成绩预测分析,准确率可以达到85.8%。结合相关文献中的实验结论,可以看出XGBoost 相较于传统的机器学习方法有更好的分类效果。在实际应用中,使用XGBoost 算法模型进行学院学生的成绩预测,实验准确率达到了75.2%,为学生的学业预警提供了理论依据。
猜你喜欢
无线互联科技(2022年8期)2022-06-23 06:09:10
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
中国教育信息化(2015年10期)2015-08-23 11:43:44
河南科技(2015年8期)2015-03-11 16:23:52
