
网络攻击检测技术综述
2022-09-26 10:09缪祥华张如雪张宣琦蒲鹳雄张家临
化工自动化及仪表 2022年5期
缪祥华 张如雪 张宣琦 蒲鹳雄 王 攀 李 响 张家临
(昆明理工大学a.信息工程与自动化学院;b.云南省计算机技术应用重点实验室)
近年来,互联网及其基础设施逐渐在人们的日常生活中扮演着重要角色。 互联网在连接不同应用程序(如医疗保健、工业和商业)中的数十亿台机器方面发挥着积极的作用。 它提供了一个全球网络基础设施来连接大量的虚拟和物理事物,如通信设备、网络物理系统和社交网络。 然而它的好处在某种程度上被日趋严重的网络攻击所抵消。2020年国家技术安全联盟(NTSC)的安全报告指出,网络安全问题每个月都在恶化。 2019年,大约有6.2亿账户信息被黑客窃取,并在暗网上出售。 COVID-19大流行加剧了这种威胁,因为许多人不得不在家工作,导致网络流量显著增加。 而网络攻击检测作为一种跟踪网络流量的有效安全机制,可防止恶意请求。
现有的攻击检测系统根据检测的数据可以分为两类:基于已知数据集的检测和基于未知数据集的检测。 而基于已知数据集的检测方法又可以分为基于统计方法的检测和基于机器学习的检测。 笔者从多个角度进行分析,研究了预处理技术,如数据清理、特征选择及特征转换等,为数据准备提供建议, 还讨论了网络攻击检测技术,并按技术类别分析了它们的原理和相关应用。
1 预处理技术
在任何数据分析过程中,数据的表示和质量都是最重要的。 原始数据通常包含噪声和不可靠的数据,会影响训练、分析。 此外,网络攻击检测中使用的数据集具有高维的特点,使得在训练过程中更难发现知识。 要构建高性能的探测器需要进行有效的预处理。 网络攻击检测中最常用的数据预处理方法有数据清洗、数据转换、特征选择、特征提取。
1.1 数据清洗
数据清洗可以纠正损坏或不准确的记录。 质量标准包括以下内容:
a. 有效性。 数据可能必须是某种类型,比如布尔型或数值型。
b. 准确性。数据必须符合实际情况,例如,由于记录过程可能存在异常值,通过数据清洗很难保证准确性,因为验证需要真实的数据源。
c. 完整性。 一些数据可能有未知的或缺失的值。 完整性问题通常通过默认值、设置零或删除来解决。
d. 一致性。 当数据集中有冲突时,就会发生不一致。例如,两个接收器的源IP可能不同。解决这类问题需要确定哪个数据是最可靠的。
基于平均值、标准差或聚类算法的数据分析可以揭示错误,这些错误的值有时可以设置为平均值或其他统计度量。
1.2 数据转换
在将训练数据输入到模型之前,通常必须进行转换和映射来适应需求,以提高检测速度和准确性。 这将影响IDS数据集中的两种数据类型。
非数值数据。 以UNSW-NB15数据集为例,名义形式的特征包括传输协议类型、状态、服务类型和攻击类型,以字符串形式存储,这是大多数机器学习算法不支持的。 最直接的方法是给特性下的值编号并映射它们,但这将导致错误。 比如,在均方误差的计算中, 将一个被标记为0的类误标记为9, 其均方误差是将该类误标记为1的81倍,这是不合理的。 处理这种问题最常用的方法是独热编码。 该方法为了完成对n个状态的编码,采用了对应的n位状态寄存器。 当给定状态生效时,唯一一个与其对应的寄存器位就会生效。
数值数据。 数据值的范围因特性而异。 深度学习框架通过引入偏差来避免它对模型精度的影响, 但当两个特征值的取值范围相差过大时,仍可能影响模型学习时间。 在训练前,特征的取值范围通常通过数据缩放来统一,例如通过下式将特性的每个值都映射到0~1之间:
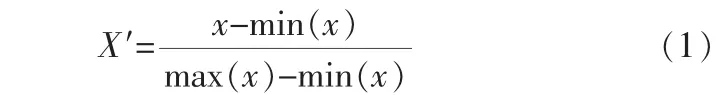
但是,这个方法不能处理异常值。 例如,如果有9个值介于0~1之间,一个离群值等于100,那么这9个较小的值将被映射到0~0.01之间。这种情况可以通过z分数标准化来避免:

其中,μ和σ分别表示特征的均值和标准差。这可以在保持特征分布的情况下将值扩大到接近0,但特征可能不完全在相同的规模上。
1.3 特征选择
特征选择是选择原始数据集的子集作为模型输入,这样可以避免维数灾难,增强概化[1]。 在进行特征选择时,需要数据中包含冗余或不相关的特征,以避免过多的信息丢失。 特征选择可以通过几种方式来完成:
a. 手动选择。用户手动决定是否删除某个特性。 例如,文献[2]。
b. 详尽的搜索。对每个特征组合的子集进行验证,寻找效果最优的特征子集,因此需要大量的计算。
c. 嵌入方法。 在模型构建过程中进行特征选择。Bolasso算法通过构造一个线性模型[3],结合岭回归的L1惩罚和L2惩罚, 将许多回归系数降为零。FeaLect算法基于回归系数的组合分析对特征进行评分和选择[4]。
d. 包装方法。 用每个子集训练预测模型,并对一个保留集进行测试。 一个子集的得分由模型检验的错误率得到。 这种方式是计算密集型,通常只用于寻找特征的最佳子集。
e. 过滤方法。 可以使用互信息、Pearson相关系数和显著性评分(如类间或类内距离)等方法对特征子集进行评分,这些方法可以对特征进行排序,但不能产生最佳子集。
1.4 特征提取
与特征选择不同[5],特征提取即创建新的特征以促进学习, 被认为是构建模型的关键因素,可以由以下算法执行。
主成分分析(PCA)。 主成分分析是一种被频繁使用的线性降维方法,它改变了基本成分的数据, 主成分实质上是数据协方差矩阵的特征向量。 XIAO Y H等将PCA与自动编码器相结合,将高维特征压缩输入到卷积神经网络(CNN)中[6]。主成分分析包含以下几种方式:
a. 概率主成分分析(PPCA),利用概率分布进行降维;
b. 核主成分分析[6],先利用核函数将低维空间映射到高维空间,然后利用主成分分析进行降维;
c. 独立分量分析(ICA),不要求隐藏变量服从高斯分布。
线性判别分析(LDA)。 LDA是一种经典的尺度缩减方法,它通过特征的线性组合来描述多类对象。 作为一种有监督的学习算法,它在低维空间中搜索最能区分数据类的向量,以低维投影数据, 使类内距离最小化, 类间距离最大化。ELKHADIR Z和MOHAMMED B提出了一种基于广义均值的鲁棒中值神经网络LDA, 在处理离群点效应方面,该方法利用了散点矩阵内和散点矩阵之间的广义均值, 并证明了所提出的方法比其他许多LDA方法执行得更好[7]。
自编码器(AutoEncoder)。该方法使用隐藏层进行无监督学习,通过非线性变换[8]映射高维特征,以产生尽可能接近原始输入的表示[9]。正则化自动编码器(稀疏、降噪和缩小)通常用于学习表示。 周珮等将AutoEncoder和ResNet相结合,并利用自编码器学习数据特征使实验结果达到较高的准确率和较低的误报率[10]。 HAN F X等利用自适应遗传算法的迭代方法对组合核稀疏自编码器的目标函数进行了优化,通过结合核的稀疏自编码器获得降维后的特征矩阵,解决了网络攻击的非线性特征和稀疏特征的降维问题[11]。
2 已知攻击的检测技术
根据网络检测策略,网络攻击检测方法主要分为基于统计的方法和基于机器学习的方法。 笔者查阅文献对各类方法进行了分类(图1)。

图1 已知网络攻击检测方法的分类
2.1 基于统计方法的检测技术
统计方法通过分析统计数据来理解知识和规则。 统计方法具有客观性、准确性及可测试性等特点,已成为网络攻击检测的重要方法。
2.1.1 协方差矩阵分析(CMA)

所有的协方差系数构成协方差矩阵,然后通过矩阵分解,可以检测到一些潜在的攻击,协方差矩阵分析如图2所示。

图2 协方差矩阵分析
首先用原始网络数据构造协方差矩阵,然后通过矩阵分解提取数据规则。 针对云环境,ISMAIL M N等提出一种用于泛洪DoS攻击检测的协方差矩阵分析模型[12]。 该模型包括3个阶段:第1阶段是对正常交通模式进行建模的基线分析;第2阶段是基于协方差矩阵分析的网络攻击检测;第3阶段是预防阶段。
与上述研究不同的是,TAN Z Y等使用了DoS检测方法, 提取网络流量特征之间的几何相关性,构造协方差矩阵来检测DoS攻击[13]。 该方法的优点是可以通过学习几何特征有效地检测未知DoS攻击。
2.1.2 基于熵的方法
熵与随机性有关,当网络攻击发生时,被攻击主机的IP地址出现的频率会增加, 这就会导致熵值下降。 根据这种思想,提出了多种基于熵的网络攻击检测方法。 SAHOO K S等在SDN环境下基于流量的特性,提出一种广义熵度量(GE)来检测控制层的低速DDoS攻击[14]。王楠采用了一种基于多维熵的DDoS检测方法[15]。江峰等采用了一种基于粗糙熵的离群点检测方法,该方法依据粗糙集中的粗糙熵对离群点进行检测[16]。
2.1.3 隐马尔科夫模型(HMM)
隐马尔可夫模型是一种统计模型, 它由5个部分组成:
a. 初始概率(PI),表示初始时刻隐藏状态出现的概率;
b. 状态序列(H),隐藏状态的序列;
c. 观察序列(O),由隐藏状态生成的可观察序列;
d. 转移矩阵(A),描述状态转移;
e. 发射矩阵(B),描述隐藏状态和观测状态之间的概率分布。
隐马尔可夫模型如图3所示。

图3 隐马尔可夫模型
针对特殊问题,研究人员提出了一些改进的隐马尔可夫模型。例如,为了检测L-DDoS(低速率DDoS),WANG W T等提出一种改进的隐马尔可夫模型HMM-R, 该方法利用数据包的IP来计算Renyi熵, 再结合隐马尔可夫模型来完成低速率DDoS检测[17]。为了解决网络环境中的攻击检测问题,韩红光和周改云提出一种基于概率模型的网络攻击检测方法,该方法主要利用马尔可夫链完成网络环境行为概率建模,以此实现预测和识别攻击行为[18]。
2.2 机器学习的检测技术
2.2.1 K最近邻(KNN)算法
K最近邻是一种典型的聚类方法, 在网络攻击检测中得到了广泛的应用。 例如,为了实现网络攻击检测的实时性和精确性,付子爔等将支持向量机和KNN进行组合, 提出Il-SVM-KNN分类器,其数据结构使用平衡k维树,减少了训练和测试时间[19]。 ZHU L等提出利用KNN对软件定义网络(SDN)进行隐私保护的Predis系统[20]。 具体来说,Predis首先使用扰动加密保护数据的隐私性,然后使用KNN对加密数据进行网络攻击事件的聚类。 该方法既保护了网络安全,又保护了用户隐私。
2.2.2 混合聚类算法
为了提高检测效率,一些研究者提出了混合聚类的网络攻击检测方法。 王文蔚等将熵理论与支持向量机、K-means相结合来检测SDN网络中的DDoS攻击[21]。为了进一步提高网络异常检测的准确率, 徐雪丽等提出一种基于CNN和SVM的网络报文网络攻击检测方法[22]。 刘国强提出一个将深度置信网络与SVM结合起来的网络攻击检测模型[23]。
针对不同领域中的网络攻击检测,混合聚类算法也表现较好。 例如,陈万志等针对工业控制系统单次检测的传统算法对不同类型攻击的检测 率 和 速 度 较 差 的 问 题[24],建 立 了SVM 和Kmeans++检测模型,并集成了辅助工具。
2.2.3 Boosting算法
Boosting作为一种集成学习算法,其强分类器F(x)由多个弱分类器fi(x)组合而成,这些弱分类器之间存在依赖关系。 Boosting算法包括Adaboost算法、GBDT算法及XGBoost算法等。
Boosting算法在网络攻击检测中得到了广泛的应用, 它比传统的检测方法更加智能和准确。周杰英等提出一种基于随机森林模型和GBDT模型的RF-GBDT网络攻击检测模型[25],该模型分为函数的选择、函数的转换和分类器3个部分。 将该模型应用于现有的数据集,并将它与同一领域的其他3种算法进行比较, 有较高的准确率和较低的误报率。
在物联网环境中,数据来源多、特征多且数据量大,导致特征和数据量分布不均匀,影响检测结果。 为了提高网络攻击检测的准确性,乔楠等提出一种两阶段网络攻击检测模型,该模型通过对特征进行分类和选择,减少了各种特征给系统带来的额外开销[26]。 通过在改进的随机森林中引入权重优化,对密集和稀疏数据的权重进行优化,提高了分类精度,有效降低了数据分布不平衡导致的精度降低问题。
为了更有效地检测网络攻击,ZHOU Y等提出一种基于改进的曲线下面积自适应增强(MAdaBoost-A)算法的集成系统,利用粒子群优化等多种策略, 将多个基于M-Adaboost的分类器组合成一个整体[27]。
由于当前网络攻击检测系统面对的是海量流量,因此误报警率较高,同时由于模型泛化能力低,若只采用一种机器学习算法不能很好地进行多种攻击类型的检测。 针对上述问题,池亚平等提出一种基于支持向量和Adaboost算法的网络攻击检测系统[28]。在Snort环境下,采用PCA方法减小采集到的流量特征的维数, 最后采用SVMAdaboost算法对流量进行分类。
3 未知攻击的检测技术
物联网的快速发展导致了一系列安全和隐私问题。 现有的网络攻击检测技术虽然能够识别异常流量, 但大多集中在封闭的检测集合上,对于真实的开放网络环境, 当发生未知的攻击时,现有的检测系统无法正确识别,这将严重威胁网络安全。
ZHANG Y等为了解决这一问题,研究了将极值理论(EVT)应用于未知网络攻击检测系统,提出一种基于开放集识别的网络攻击检测方法[29]。该方法通过将已知类的后识别激活量拟合到威布尔分布上,建立Open-CNN模型,在倒数第2级重新计算每个激活量,然后根据已知类的激活分数估计出未知类的伪概率,实现对未知攻击检测的目的。 对不同类型和特征分布的多个数据集进行的实验结果证明, 该方法具有较高的分类准确率,同时证明了该方法的有效性和鲁棒性。
在现实场景中,数据往往是不充足的,这将会导致模型预测和真实数据之间产生各种偏差。因此,针对这类问题,LIU A等提出了一种新的基于嵌入空间内类别生成的未知攻击检测方法[30],即SFE-GACN,该文献首先提出用会话特征嵌 入(Session Feature-ture Embedding,SFE)来 总结网络流量基本粒度的背景,将不足的数据引入到预先训练好的嵌入空间中,这样就实现了在少量数据情况下初步扩展信息的目标。 其次,进一步提出了生成式对抗合作网络(Generative Adversarial Cooperative Network,GACN), 通过监督生成的样本避免落入相似的类别,从而使样本能够生成内部类别。
4 结束语
对网络攻击检测在网络安全中的研究工作进行了全面的概述和分析。 现有情况表明,在不同的目标网络下,网络异常检测的研究是不平衡的。 在信息中心网络(ICN)领域,由于工业网络数据的敏感性和保密性,研究人员往往不公开他们的数据集。 现有数据集的缺乏限制了ICN领域的网络安全研究。 数据集的缺乏也是限制SDN领域研究的一个关键因素。 在进行安全研究之前,研究者往往需要建立SDN网络环境来模拟数据。 就目前所使用的网络攻击检测技术而言,有监督学习仍然是主流的方向。 然而,这些研究需要建立在已经标记的数据之上。 在实际应用时,所获得的数据是未标记的。 对数据进行标记是一项耗时且乏味的任务。 因此笔者认为以后的研究方向应为:
a. 无监督学习和半监督学习是网络异常检测的发展方向,网络数据的自动标记也是一个值得深入研究的方向。
b. 对抗环境已被证明会影响基于机器学习的网络异常检测算法。 因此,对抗环境下的抗扰动异常检测也有待更多的研究。
c. 现实中还有许多未知的攻击未被发现,所提到的基于未知攻击的网络攻击检测技术相对较少,这也是一个值得深入研究的方向。
猜你喜欢
南京理工大学学报(2021年4期)2021-09-15
计算机应用与软件(2019年2期)2019-04-01
经济研究导刊(2018年19期)2018-07-24
小型微型计算机系统(2018年5期)2018-07-04
读与写·教育教学版(2017年10期)2017-11-10
计算机应用(2017年3期)2017-05-24
电子制作(2017年23期)2017-02-02
考试周刊(2016年54期)2016-07-18
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
