
含定性解释变量的Logistic回归模型的实例研究
2022-09-24 10:33刘瑞平苏思奇
北京信息科技大学学报(自然科学版) 2022年4期
刘瑞平,苏思奇
(北京信息科技大学 理学院,北京100192)
0 引言
Logistic回归模型是一种以分类变量作为响应变量的广义线性模型,最初由David Cox 在1958年提出[1],其应用非常广泛,比如生物医学中对疾病状态的划分、经济金融中对信用卡违约用户的识别、社会科学中的文本主题分类等。现有的大量关于Logistic回归模型的研究仍有可改进的地方:1)Logistic回归模型中解释变量仅仅涉及连续型变量(定量变量)[2-4],然而实际问题中往往需考虑将定性变量加入解释变量中;2)有的文献虽然考虑到定性变量,但文中涉及的定性变量均被统一处理为二分类变量,导致细节因素被忽略[5];3)当自变量涉及多分类定性变量时,有的文献直接将多分类定性变量赋值为多个数值,例如在对高校社区老年人养老需求特征及其影响因素的研究[6]中,3种居住类型“独居”、“与配偶同住”、“其他”直接被赋值为1、2、3。为此,本文将从一个实例出发,探讨Logistic回归建模过程中的一些细节问题。
本文关注网络文学知识产权(intellectual property,IP)作品是否能被改编为影视剧的影响因素。网络文学IP是以文学内容为载体、具有开发潜能的优质版权内容,已成为影视剧创作的重要内容来源。并非所有的网络文学作品都适合改编成影视剧。为助力决策网络文学IP作品是否适合影视化及其影视化策略的研究,本文将对网络文学作品被改编的相关因素进行研究。目前国内外对于网络小说影视化的研究多集中于网络文学改编剧的开发运营模式和网络剧的版权价值,较少关注网络文学作品被改编的相关因素,而且尚未结合统计学模型进行实证研究[7-10]。国外IP改编影视较多地集中在明星IP上,对于网络小说的研究屈指可数[11-12]。
本文基于晋江文学城互联网平台数据,从网络文学IP作品是否被改编这一角度出发,对改编影响因素进行研究,从而了解当下大众最喜爱的网络文学IP作品特点,也为运营方关于网络文学作品影视化的决策和对策提供参考。
1 数据来源及变量介绍
“晋江文学城”是近几年网络剧和影视剧改编IP作品的重要输送平台,因此本文以晋江文学城网站为数据来源。网络文学IP作品的影视化改编可能与多方面因素影响有关,本文以网络IP作品是否被改编作为响应变量,以作者粉丝数、作品背景类型、作品风格、作品题材、付费月榜排名、章节平均点击数、作品被收藏数、作品被评论数、作品评分、参与评分人数作为解释变量。10个解释变量中既含有定量变量,也包括定性变量,所有变量的具体说明如表1所示。
2 Logistic回归模型简介
2.1 传统的Logistic回归模型
Logistic回归模型是二分类问题中的一种常用模型。经典Logistic回归模型设定解释变量为连续型变量,并基于连续型自变量来分析和预测离散型因变量,是一种广义线性模型。二分类逻辑回归(binary logistic)模型中因变量Y只能取两个值,用示性变量1和0来表示。将“事件发生”记为1,“未发生”记为0,事件发生的概率记为π,则变量Y取值为y的概率为P(Y=y)=πy(1-π)1-y,于是E(Y)=π=P(Y=1)。
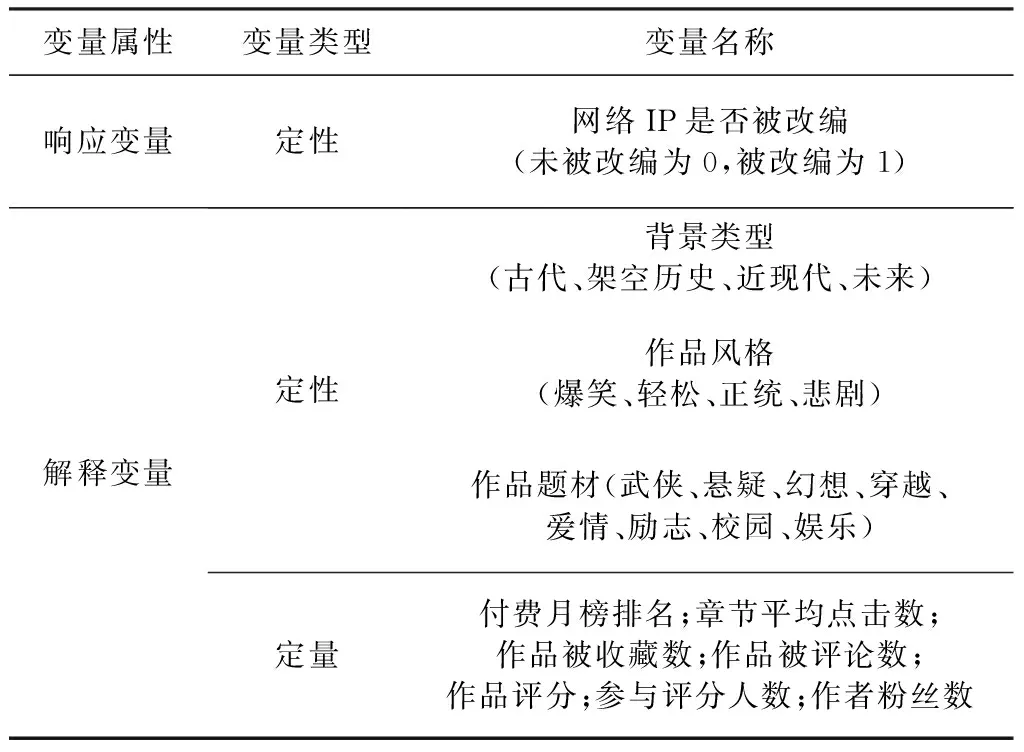
表1 变量说明
传统的Logistic回归模型仅涉及连续型变量。为方便起见,考虑仅含一个连续型自变量X1的情形,则当自变量X1取值为x时因变量Y取1的条件概率为P(Y=1|X1=x)=E(Y|X1=x),记p=P(Y=1|X1=x),为了估计概率p,作logit变换:
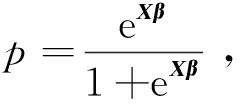
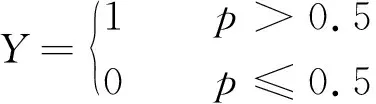
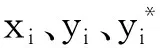
2.2 含定性解释变量的Logistic回归模型
在实际问题中,解释变量往往不只包含连续型变量。离散型或定性变量随处可见,比如含有4个水平(春、夏、秋、冬)的季节变量,此时传统模型已不再适用,需要对定性解释变量作处理。现有文献中有两种处理方式:一是将多分类变量直接赋值为多个水平;二是引入哑变量。事实上,将多分类变量直接赋值为多水平本身暗含了多分类取值之间存在大小差异的假设条件,而引入哑变量相比于直接赋值具有一定的优势,因此后者是常用的处理方法[14-15]。设变量Z为含有m个水平的定性变量,则需设定m-1个哑变量:D1,D2,…,Dm-1。本文将在实证分析过程中,试用不同变量处理方式得到不同的模型并进行探讨。
3 基于Logistic回归模型的实证研究
3.1 样本的选取
已获取数据共含41 739部网络文学作品,其中有350部作品被改编,可以看到样本容量很大,同时改编与否两类作品数量存在较大悬殊。因此在做模型拟合之前,先对数据进行抽样。根据已获数据的实际情况,采用欠抽样方法,即通过减少多数类样本来提高少数类的分类性能。最简单的方法是随机去掉某些多数类样本来缩小其规模。因此本文对多数类(即未改编作品)进行欠抽样,按照未被改编作品数量∶被改编作品数量=2∶1的比例进行抽取。
首先针对少数类(即被改编作品),为了尽可能保留总体分布信息,基于作品类型采用分层抽样,将被改编的作品按照作品类型划为4层,并按照1∶1的比例分为训练数据和预测数据。接下来在已获取的未改编与被改编样本中,根据每一层中被改编作品的数量,按2∶1的比例对未改编作品进行抽样。最终将全部样本分为训练集和预测集两部分,其中训练集用于构建与估计Logistic 回归模型,预测集的数据用于检验模型的预测能力。最终所得样本数据规模如表2所示。
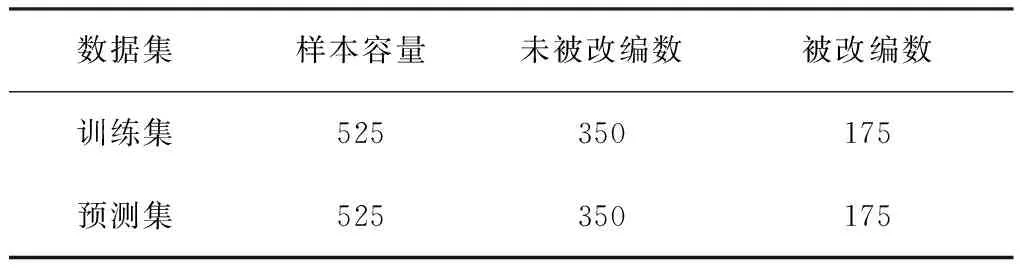
表2 样本规模
3.2 建立Logistic回归模型
本研究中,因变量为网络文学IP作品是否被改编,解释变量共10个。其中包含7个连续型定量变量:付费月榜排名X1,章节平均点击数X2,作品被收藏数X3,作品被评论数X4,作品评分X5,参与评分人数X6,作者粉丝数X7;另外含3个定性变量:作品的背景类型Z1(4类),作品风格Z2(4类),作品题材Z3(8类)。变量具体解释参见表1。为了探讨在应用Logistic回归模型时需注意的细节问题,对多分类定性变量进行不同的设置,得到不同的Logistic回归模型,并对这些模型的估计结果和拟合效果进行比较。
3.2.1 对多分类定性变量进行不同设置
1)将其直接赋值为多个水平
用Z=(Z1,Z2,Z3)表示3个定性变量,然后分别对各定性变量进行直接赋值。例如变量Z1(背景类型)共含4类,则将该变量的4种类型“古代”、“架空历史”、“近现代”、“未来”直接赋值为1、2、3、4。其余两个定性变量Z2(作品风格)、Z3(作品题材)也做相同处理。于是所得模型为
Y*=β0+β1X1+β2X2+…+β7X7+η1Z1+η2Z2+η3Z3+ε
该模型同时含有定量变量与定性变量,模型可简写为
Y*=β0+Xβ+Zη+ε
(1)
式中:X=(X1,X2,…,X7)代表7个连续型解释变量,β=(β1,β2,…,β7)T为对应的系数;η=(η1,η2,η3)T为3个定性变量的系数。记此模型为模型(1)。
2)对多分类定性变量进行哑变量处理
以“背景类型”这一变量为例,其中包含4个水平,此时引入3个哑变量:D11、D12、D13,当作品类型为“古代”时,(D11,D12,D13)取值为(1,0,0)。类似地,若(D11,D12,D13)取值为 (0,1,0),表示作品类型为“架空历史”。对3个定性变量均作哑变量处理后,模型中变量维数为20,Logistic回归模型为
y*=β0+β1X1+β2X2+…+β7X7+γ11D11+γ12D12+γ13D13+γ21D21+γ22D22+γ23D23+
γ31D31+…+γ37D37+ε,可以简写为
Y*=β0+Xβ+D1γ1+D2γ2+D3γ3+ε
(2)
式中:X=(X1,X2,…,X7)代表7个连续型解释变量;D1=(D11,D12,D13),D2=(D21,D22,D23),D3=(D31,D32,…,D37)分别表示3组哑变量。记此模型为模型(2)。
为了比较对定性解释变量的两种处理方式所得模型的表现,分别考虑模型所得变量显著性情况与模型的拟合效果。表3给出了系数估计值显著性情况(包括系数z值与P(>|z|),均由R语言中glm函数输出),其中P(>|z|)越小表明变量的显著性越高。本文采用Nagelkerke提出的拟合优度[16]来比较不同模型的拟合效果,公式如下:
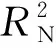
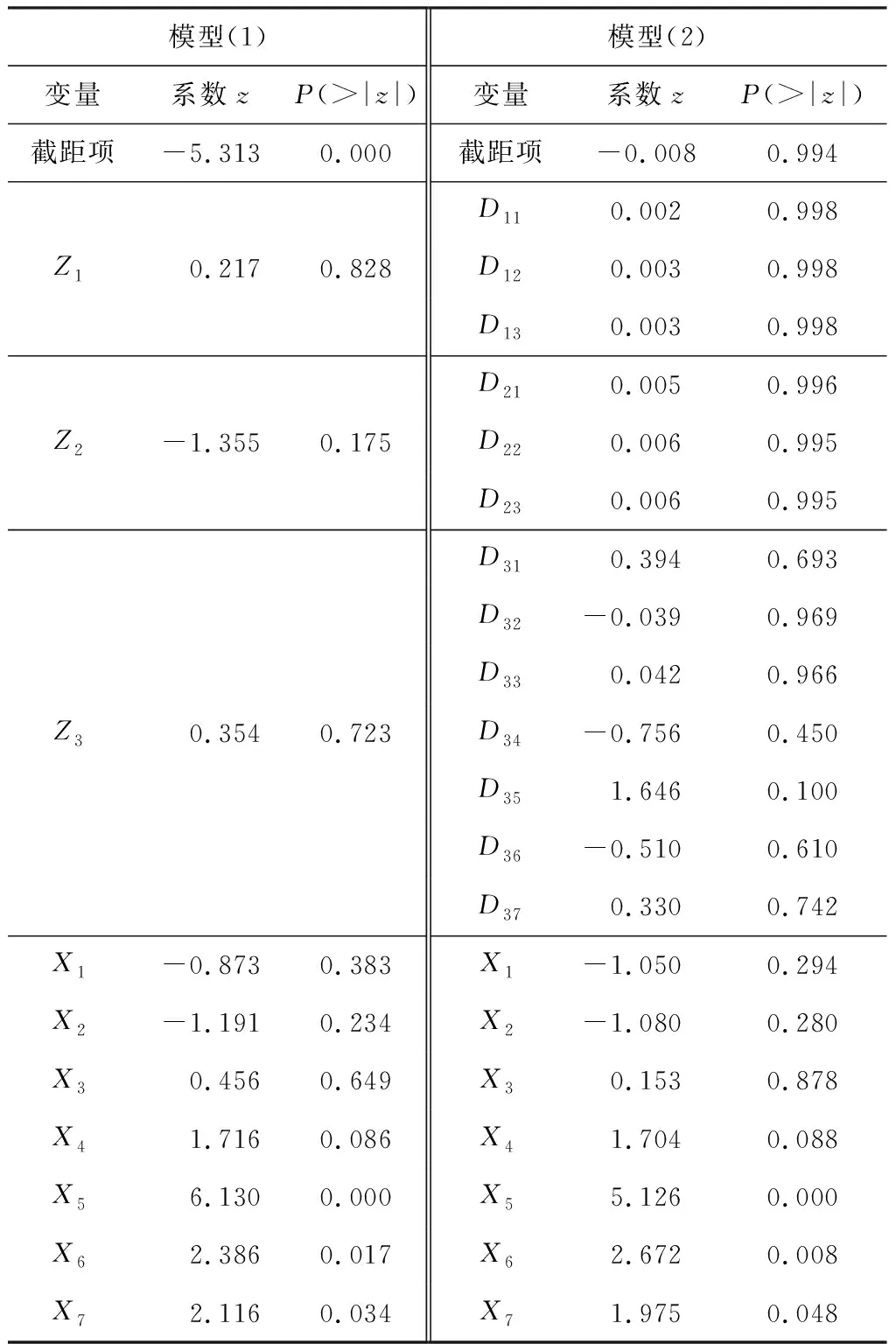
表3 对定性变量不同处理方式下的系数显著性结果
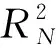
3.2.2 关于“截距项在模型中显著”
在对多分类定性变量进行哑变量处理后,建模时经常会出现截距项显著的情形。对于模型(2),考虑3个定性变量对应的3组哑变量的不同组合形式。以“背景类型”这一变量为例,其中包含4个类,前文考虑了3个哑变量:(D11,D12,D13),对应(古代,架空历史,近现代)。现在考虑4类中后3个类(架空历史,近现代,未来)对应的哑变量:(D12,D13,D14),即:当作品类型为“古代”时,哑变量取值为(0,0,0),同理(1,0,0)表示“架空历史”,(0,1,0)表示“近现代”,(0,0,1)表示“未来”。可以看到,关于“背景类型”这一定性变量共有4种哑变量取法。同理,关于“作品题材”这一变量,共有8种哑变量取法。
现在考虑实例中3个定性变量的所有哑变量取法并进行建模,可得4×4×8=128个模型。这些模型虽然本质相同,所得Akaike信息准则值相同,但共有42个模型所得截距项为显著。故在实例分析中应用这些模型对实际问题进行解释时,对各个定性变量对应的哑变量的显著性解释结果有所不同。因此,在应用含有定性变量的Logistic回归模型时,需选取截距项不显著的模型形式。
3.3 对模型的进一步优化
模型(2)中包含7个连续型变量,经Bartlett球形检验值,所得显著性p<0.001,表明这些变量之间存在高度相关。因此接下来考虑做主成分分析实现降维,并尽可能多地包含对数据变异的解释。前3个主成分的累积贡献率依次为53.97%、69.81%、83.27%,因前3个成分对总变异的累积贡献率高达83.27%,所以基本可以反映原来的7个连续变量的信息。表4给出了主成分分析载荷计算结果,第1主成分载荷显示出作品被收藏数、章节平均点击数的重要性。
下面根据主成分所得结果进行模型优化,根据方差累积贡献率考虑在模型中选用前3个主成分。优化后的Logistic回归模型包含3组定性变量以及3个主成分:
Y*=β0+Fβ+D1γ1+D2γ2+D3γ3+ε
(3)
式中:F=(F1,F2,F3)代表7个连续型解释变量所得的3个主成分;D1=(D11,D12,D13),D2=(D21,D22,D23),D3=(D31,D32,…,D37)分别表示3组哑变量。记此优化后的模型为模型(3)。
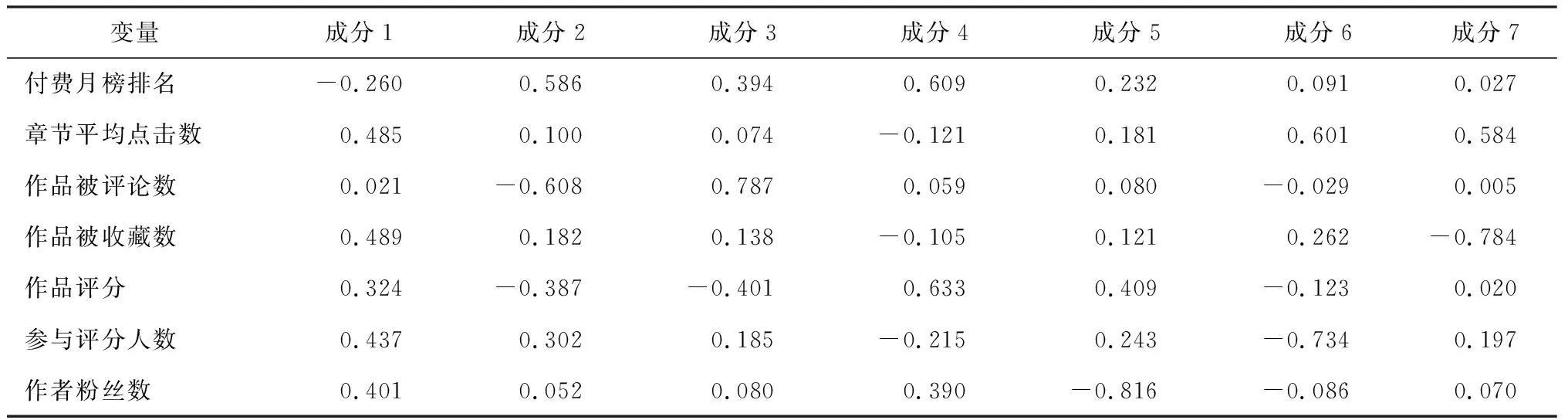
表4 主成分分析所得载荷结果
模型(3)系数估计结果及显著性结果如表5所示。表5显示了3个主成分在模型中的显著性,其中第1个主成分F1显著性最强,说明作品被改编与否的主要相关因素为作品被收藏数、章节平均点击数(可概括为用户粘性);第2、3成分对应的系数显著性也极高,结合系数值以及表4中第2、3成分的载荷系数,表明作品被评论数和评分值与作品改编与否的相关性强,间接反映了作品讨论热度以及作品本身质量与作品是否被改编的相关性较强。另外,作品题材(对应的文学作品题材为爱情类)也具有较高的显著性,说明爱情题材类作品更容易被改编。
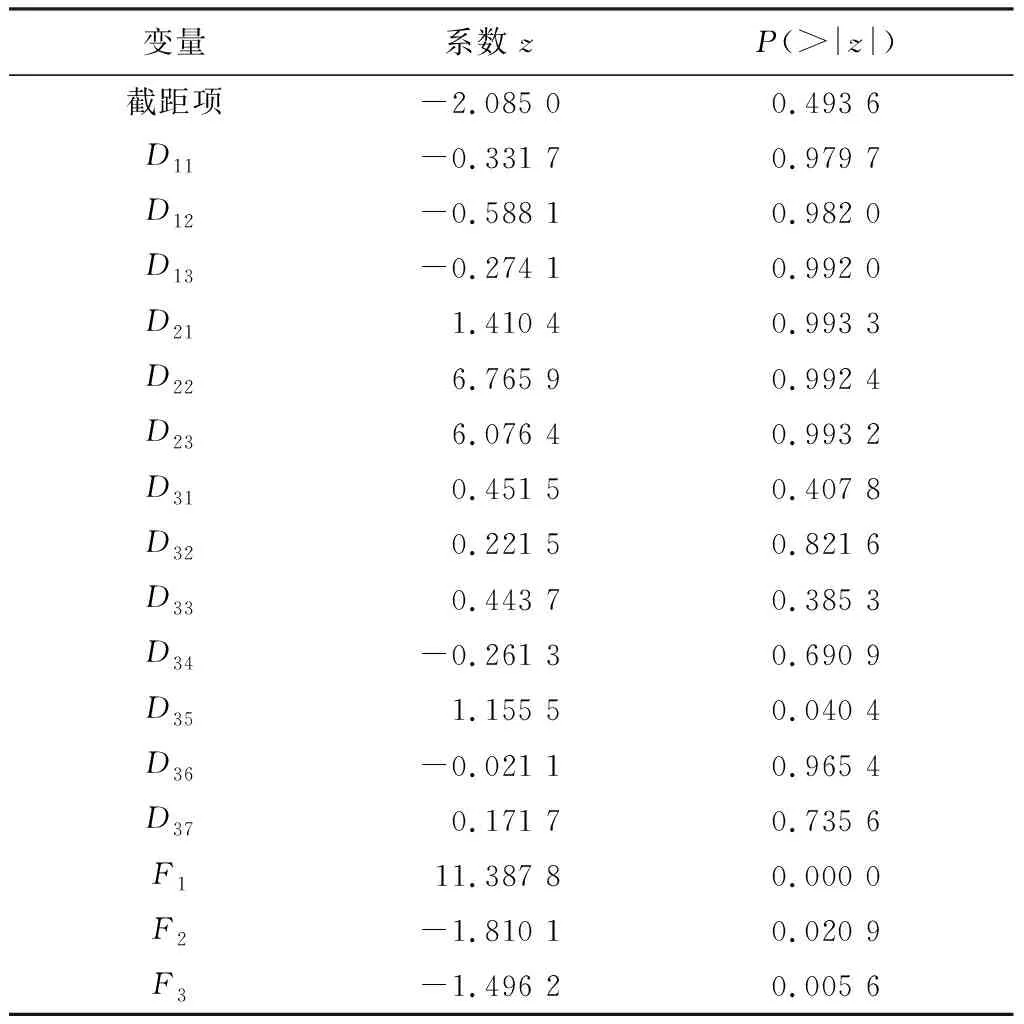
表5 模型(3)估计结果
下面将模型用于预测集,即观察模型在新数据集上的预测效果。记样本总数为n,真实改编个数为nP,未改编个数为nN,正确预测为改编的个数为nTP,正确预测为未改编的个数为nTN,误预测为改编的个数为nFP,误预测为未改编的个数为nFN。考虑如下指标:总体正确预测率RT=nP/n;正确预测改编比率RTP=nTP/nP;正确预测未改编比率RTN=nTN/nN;误预测为改编比率RFP=nFP/nN;误预测为未改编比率RFN=nFN/nP,易知:RTP+RFN=1,RTN+RFP=1。表6给出了原始模型以及优化模型的预测率结果。可以看出优化后模型对网络文学IP改编与否的总体预测率较高(85.52%),与优化前相比总预测能力得到了显著提升。特别是对“适于改编”的错误预测率显著降低,同时对“未被选作改编作品”结果的正确预测率显著提升,结果高达92.29%。在实际应用中可表现为,对于“不适于改编”作品的预测更加准确。
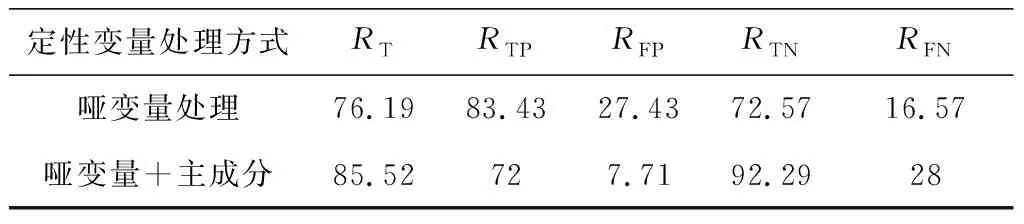
表6 模型预测结果 %
3.4 结果分析
基于数据分析结果,可以发现网络文学IP作品被改编的主要相关因素为:用户粘性、作品讨论热度以及作品题材风格。其中,用户粘性及用户感受与是否被改编的相关程度更大,在实际生活中可以直观地体现为网络文学IP作品具有的粉丝基础及受众人群对改编影视剧的接受程度;作品的讨论度在实际生活中可以体现为改编剧播出前在微博等媒体平台上的讨论热度。由作品背景类型、风格以及作品题材变量和3个主成分构建的回归模型正确预测率达到85.52%,其中对未被改编的IP作品预测准确率为92.29%,对被改编的IP作品的预测准确率达到72%。说明模型(3)对网络文学IP影视剧改编的选择具有较好的预测能力。
4 结束语
本文构建的Logistic回归模型给出了网络文学作品改编与否的相关因素,可为影视剧产业对文学IP作品改编提供决策和对策参考,从而降低原创剧本开发成本。相关建议如下:第一,为打造高质量网络文学IP改编影视剧,制片方、投资方应结合现有平台数据资源对优质网络文学IP作品下粉丝用户行为进行深入分析,挖掘用户需求,引领用户文化价值取向;第二,关注网络文学IP作品本身,以保证改编作品质量;第三,丰富网络文学IP作品改编影视剧题材。当前数据分析显示改编作品偏重爱情类题材,建议不拘泥于热点,着眼于更多具有创新点的网络文学作品,提高改编剧的整体价值。
从研究方法来看,应用Logistic回归模型可助力各类应用场景下的决策。在具体应用过程中,当模型中除了定量变量外同时含有定性变量时,采用引入哑变量的处理方式要优于对定性变量直接进行多水平赋值的方式,后者可能会带来信息损失;建模过程中若出现截距项显著的情形,则必有某个哑变量的解释作用被忽略,此时考虑哑变量的多种组合方式可避免截距项的显著,从而找到真正起显著作用的关键变量。在未来研究中,可以进一步考虑高维情形下的Logistic回归模型中对定性变量的变量选择。另外,在该实例研究中可考虑将生命周期分为不同阶段,数据变化与阶段保持一致,例如,将时间维度细化到作品完结或被购买IP的前一个月、前一周等,从而建立动态模型。
猜你喜欢
纺织标准与质量(2022年1期)2022-07-12
成都信息工程大学学报(2021年5期)2021-12-30
口腔护理用品工业(2021年4期)2021-11-02
逻辑学研究(2021年3期)2021-09-29
课程教育研究(2021年27期)2021-04-13
知识文库(2019年10期)2019-10-20
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
当代陕西(2019年8期)2019-05-09
当代陕西(2019年8期)2019-05-09
当代陕西(2019年8期)2019-05-09
