
基于多级特征融合的伪装目标分割
2022-09-21 05:38付炳阳曹铁勇郑云飞王烨奎
计算机工程与应用 2022年18期
付炳阳,曹铁勇,郑云飞,2,3,方 正,王 杨,王烨奎
1.陆军工程大学 指挥控制工程学院,南京210007
2.陆军炮兵防空兵学院南京校区 火力系,南京211100
3.安徽省偏振成像与探测重点实验室,合肥230031
伪装目标分割(camouflaged object segmentation,COS)是计算机视觉中极具挑战性的任务,其目的是从目标与背景高度相似的环境中分割出伪装物体[1]。由于伪装目标与周围环境对比度较低,相比目标与背景有明显差异的常规分割任务,伪装目标分割更加具有难度。
在早期的传统方法中,研究人员将伪装图案视为特殊的纹理区域,针对颜色、纹理等底层特征,运用三维凸算子、灰度共生矩阵、纹理描述符、数学形态学等方法对伪装目标进行分割[2-6]。随着深度学习技术的发展,从图像中提取的深度特征相比于传统底层特征更加通用和有效。因此,研究人员开始利用深度卷积网络(convolutional neural network,CNN)构建伪装目标分割模型。Li等人通过图像增强算法实现目标与背景特征的区分,再利用区域建议网络实现对特定目标的精确定位[7]。Zheng 等人提出针对分割迷彩伪装目标的密集反卷积网络,并利用超像素优化分割结果[8]。卓刘等人引入多尺度的残差神经网络用于识别伪装迷彩目标[9]。Le 等人引入Anabranch Network 提高分割精度[10]。Fang 等人提出利用强语义膨胀网络(strong semantic dilation network,SSDN)从卷积神经网络中提取伪装目标的语义信息[11]。Fan等人将伪装目标分割建模为搜索和识别两个阶段,搜索阶段负责搜索隐蔽目标,识别阶段采用联级方式准确地检测出隐蔽目标[1]。Yan等人结合实例分割和对抗攻击来分割伪装目标,提高分割精度[12]。Mei 等人设计出一种分心挖掘策略用于分心区域的发现和去除[13]。Zhai 等人将交互学习思想从规则网格空间推广至图域,在图的联合学习框架基础上设计出交互式学习模型用于分割伪装目标以及真实边缘[14]。
上述网络模型在相对简单的场景中分割伪装目标已经具有较好的效果,但面对目标偏小且背景复杂的场景时,模型分割性能显著下降。模型效果下降原因包括当前模型所提取的深度特征多尺度表达能力不足,无法发现图片中尺寸较小且与背景高度相似的伪装目标,导致模型产生漏检情况。其次,模型使用的底层特征包含大量干扰信息,无法准确提取出伪装目标边缘细节;深层特征经过多次下采样后分辨率大大降低,目标细节信息也严重丢失。目前增强特征的常用方式为特征融合,但简单地融合深层特征与低层特征,将导致目标信息淹没在大量干扰信息中,无法准确捕捉伪装目标位置信息以及边缘细节。
针对上述问题,本文提出一种基于多级特征融合的伪装目标分割模型。模型分为编码和解码两个阶段:在编码阶段采用Res2Net-50作为主干网络[15],构建门控融合模块(gated fusion module,GFM)对主干网络提取的各级中间层特征进行选择性融合,过滤特征中包含的干扰信息,同时丰富特征的语义和细节信息;在解码阶段,利用自交互残差模块(self-interaction residual module,SIRM),解决模型对多尺度特征表达能力不足的问题。SIRM 将输入特征转换成不同通道数的高、低分辨率特征,再进行充分融合,从而挖掘出更多有效的特征信息。最后,为增强损失函数对图像中不同尺寸目标的监督效果,本文在训练阶段采用Dice损失(Dice loss,DL)与交叉熵损失的联合损失函数,使模型能更精准地分割伪装目标。本文方法在一个迷彩伪装数据集CPD和三个自然伪装数据集CHAMELEON、CAMO、COD10K 上与典型方法进行对比实验。结果表明,在四个常用评价指标上本文均优于其他方法,由此证明本文方法在各类伪装目标分割任务上具备有效性。
1 本文方法
如图1 所示,本文分割模型基于全卷积架构(fully convolutional networks,FCN)[16]。首先,采用Res2Net-50作为特征提取网络[15]。对于Res2Net-50 输出的不同尺度特征,一起输入门控融合模块(GFM)。GFM 运用门控机制过滤掉各层特征中背景信息干扰,有选择性地融合各级特征图。然后,在解码阶段加入自交互残差模块(SIRM),挖掘出更多当前特征的多尺度信息,增强伪装目标特征信息。最后,模型通过各级特征逐层聚合得出最终的伪装目标分割图。
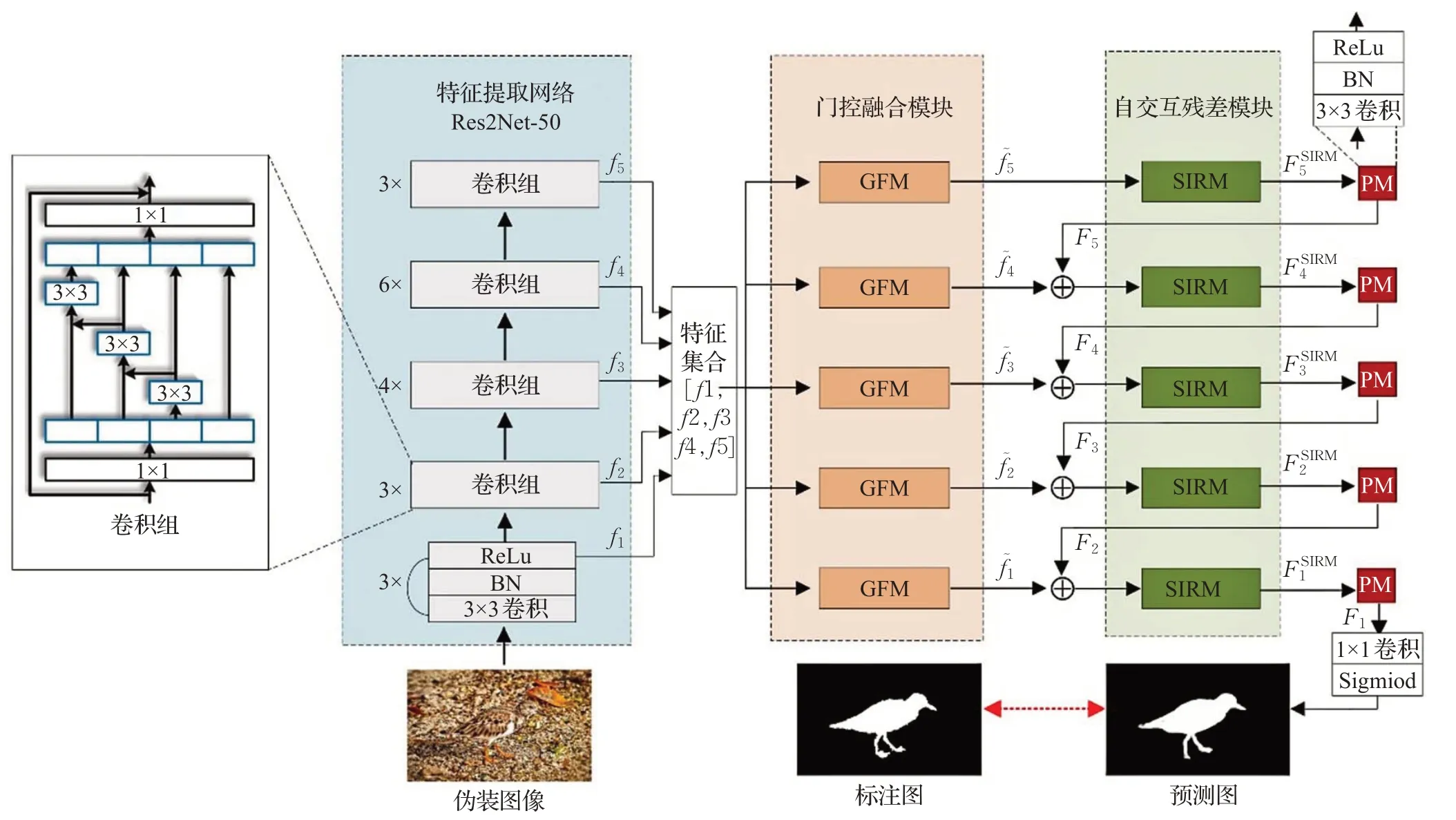
图1 网络结构框架图Fig.1 Network structure block diagram
1.1 门控融合模块
在特征提取网络中,不同深度的卷积层提取出不同表示水平的特征。其中,浅层特征图分辨率高,且包含目标的大量细节信息,但语义表达能力不强;深层特征包含丰富的语义信息,但分辨率低且目标细节信息较少[17-18]。如何结合各级特征的优势提取出具有高分辨率且丰富语义信息的特征图是伪装目标分割模型构建的关键。

本文将门控机制引入多级特征融合过程[19],提出门控融合模块选择性地融合各级特征。在深层特征语义信息的指导下,计算出各级特征对应的门控矩阵以此区分特征中的有用信息与干扰信息。其中,门控系数的大小是多级融合中选择特征的重要依据。各级特征中门控系数较大的部分被保留,门控系数较小的部分被其余各级特征对应信息所补充。采用这种选择性门控机制可以有效过滤各级特征中背景信息,从包含大量噪声信息的原始特征图中抽取目标信息并将其聚合,增强不同分辨率特征的表示能力。

其中,每个门控系数Gl=sigmoid(wl⋅fl)由一个参数为wl∈的卷积层计算得出,门控总数为主干网络提取出的特征图数量。由上式可知,只有当Gi(x,y)的数值较大并且Gl(x,y)的数值较小时,Gl(x,y)对应特征才选择Gi(x,y)处特征信息进行融合,补充特征信息。
1.2 自交互残差模块
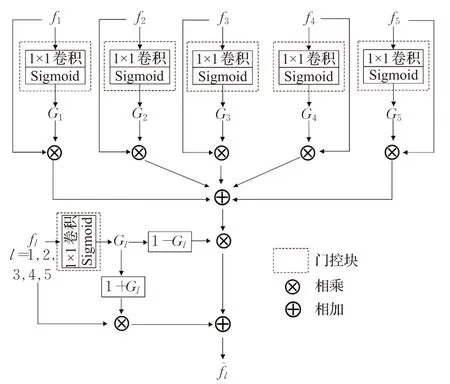
图2 门控融合模块Fig.2 Gated fusion module
在不同深度的高分辨率特征和低分辨率特征之间进行交互融合,可以丰富特征的尺度信息[20]。基于这种思想,本文在解码阶段设计自交互残差模块(SIRM)。SIRM 通过当前特征挖掘尺度信息,增强各级特征图表达能力,便于模型分割出更加准确的伪装目标,整个过程的数学表达式为:
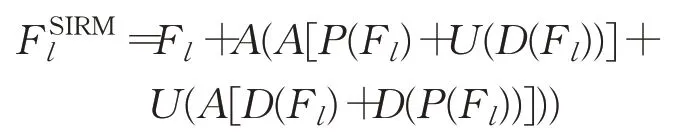

1.3 损失函数
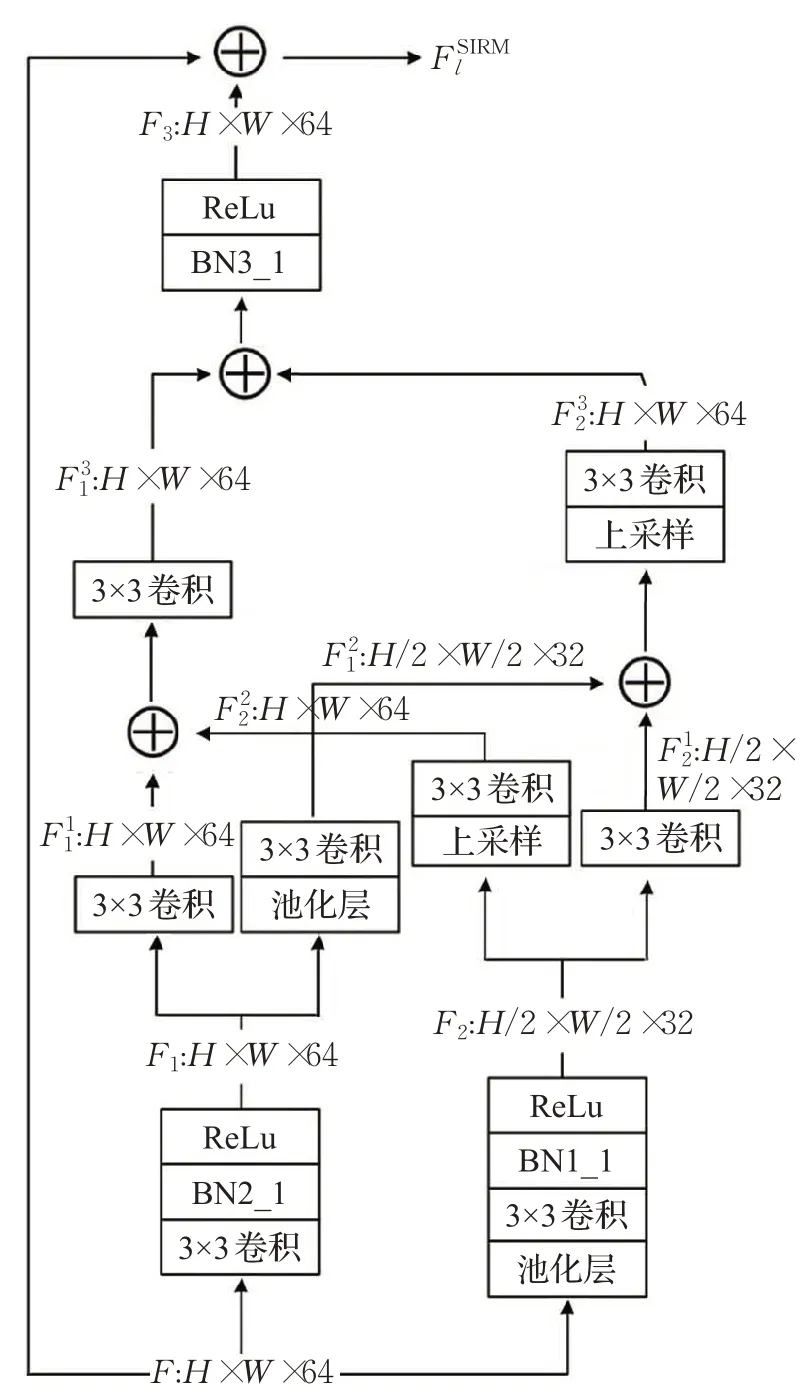
图3 自交互残差模块Fig.3 Self interaction residual module
在伪装目标分割算法中,广泛使用交叉熵函数作为损失函数。交叉熵函数独立地计算每一个像素的损失,然后在整个批次中累积每个像素的损失。但这种方法忽略整体的结构,尤其针对伪装目标较小的图片,目标像素的损失会被背景像素稀释。并且交叉熵损失函数是平等对待各区域像素点,然而在实际情况中,伪装目标的边缘给分割提供更多有价值的信息,应给予目标边缘更多关注[21]。
本文将语义分割中常用的Dice 损失[22]引入伪装目标分割任务,从区域整体的角度进行模型学习,弥补加权交叉熵损失的不足。同样为体现像素之间的差异,每个像素点加不同的权重以强调它们在分割过程中不同的重要程度。加权Dice损失计算公式如下:
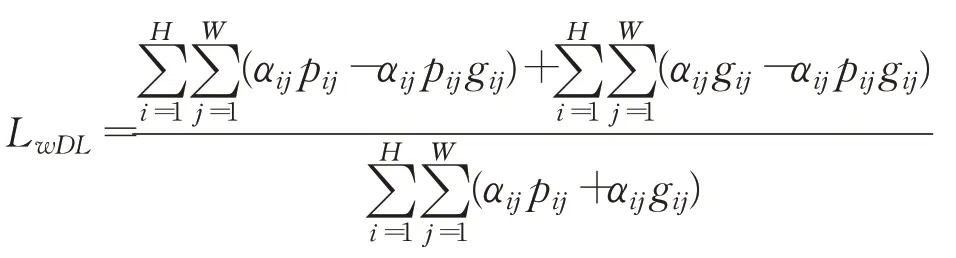
其中,p∈ℝH×W表示预测图的每一个像素点的概率值,g∈{0,1}H×W表示人工标注图。αij表示伪装图像中每个像素点的权重,计算公式如下:上式中Aij表示像素(i,j)周围的区域,γ为可以调节的权重系数。本方法可以找出与其周围环境不同像素点给与更多关注。
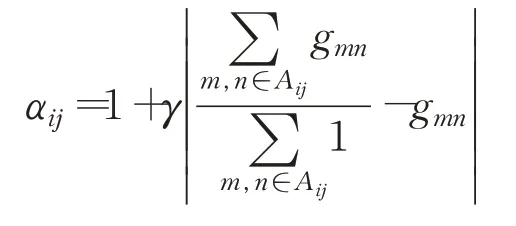
基于上述分析,本文采用加权交叉熵(Lwbce)与加权Dice 损失(LwDL)联合的方式来增强图片中各尺度目标的监督效果。该联合损失函数更多地关注伪装目标的边缘部分,对于目标尺度上的差异也不会造成计算损失的较大波动。该总损失函数为:
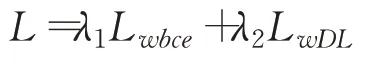
其中λ1和λ2是平衡两个损失贡献的超参数,具体取值分析见表1。
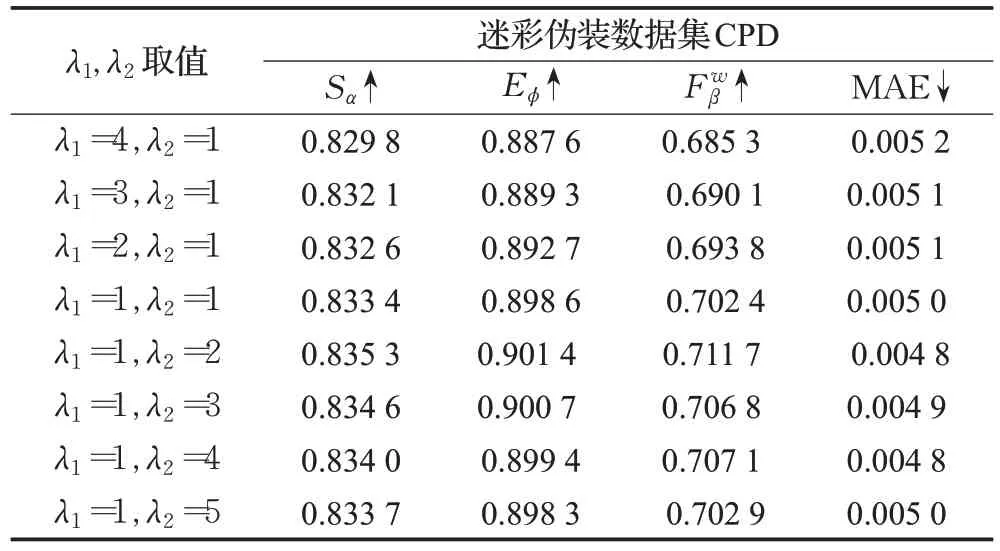
表1 参数λ1 和λ2 对算法的影响Table 1 Influence of parameters λ1 and λ2 on algorithm
2 实验及分析
2.1 数据集
本文在迷彩伪装数据集和三个自然伪装数据集上进行实验:迷彩伪装数据集CPD[11]、自然伪装数据集CHAMELEON[23]、CAMO[10]以及COD10K[1]。迷彩伪装数据集中包括26 种迷彩种类共计2 600 张迷彩伪装目标图像(其中1 300 张用于训练,1 300 张用于测试),该数据集包含丛林、雨林、雪地、荒漠和开阔地等5种复杂背景,包括卧倒、站立、半蹲等多种姿态[11]。CHAMELEON包含76张通过互联网收集的伪装动物图片,以及相应的人工标注图[23]。CAMO包含1 250张不同类别的伪装图像(其中1 000张用于训练,250张用于测试),涵盖自然伪装目标和人工伪装目标并都有精细的标签标注[10]。COD10K 是目前最大的基准数据集,它包括5 个大类和69 个子类共计5 066 张伪装图片(其中3 040 张用于训练,2 026 张用于测试),该数据集通过多个摄影网站下载并进行人工标注[1]。本文在完成迷彩伪装目标分割时,使用公开迷彩伪装数据集的训练集与测试集进行实验。在自然伪装目标分割实验中,本文实验仿照之前的工作,使用CAMO 和COD10K 的组合作为训练集(4 040张图片),其余自然伪装图片作为测试集[1]。
2.2 评估指标
本中使用结构度量(Sα),自适应E度量(Eϕ),加权F度量()以及平均绝对误差(MAE)作为评价指标。其中结构度量(Sα)着重评估预测图的结构信息,计算公式为:Sα=αSο+(1-α)Sr,这里Sο和Sr分别表示对象感知和区域感知的结构相似性[24]。自适应E 度量(Eϕ)同时评估像素级匹配和图像级统计信息,对结果图的整体和局部的精度有较好的评价[25]。
加权F 度量()是一个综合精确度和召回率的评估指标,计算公式为:
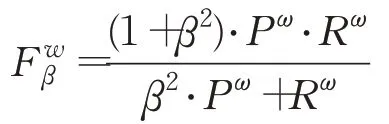
式中,β2是平衡参数,Pω为加权准确率,Rω为加权召回率。在测评中,β2设置为0.3以提高重要的准确率比重[26]。
平均绝对误差(MAE)用于计算预测图和真值之间的像素差异,广泛应用于评价图像分割结果,计算式为:
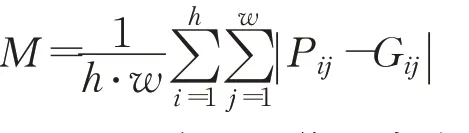
式中,h和w表示图像的高度和宽度,P表示预测图,G表示标注图。
2.3 实验细节
本文通过实验分析出联合损失函数中两个参数λ1和λ2对算法性能的影响,并为选择合适的参数提供依据。
语义分割中采用联合损失函数时,权重参数λ1和λ2一般都取值为1,因此本文在讨论λ1和λ2比例时,设置了八组参数均在1∶1 附近。实验中设置的八组参数在迷彩伪装数据集CPD 上进行定量评价。Sα、Eϕ、和MAE的测试结果如表1所示。
根据表1,模型在不同的权重参数λ1和λ2下都有较好的表现,但还是存在一定程度的差别。从表1整体来看,参数λ2偏大时效果较好,表明在联合损失中适当增大Dice 损失的权重对模型效果有一定提升。在表1列出的参数设置中,当λ1=1 且λ2=2 时,模型有最好的效果。在后续实验中,设置参数λ1=1 和λ2=2。
本文模型采用PyTorch框架实现。训练和测试均使用一台6核电脑,配备Intel®Xeon®E5-2609 v3 1.9 GHz CPU 和NVIDIA GeForce RTX 2080Ti GPU(11 GB 内存)。网络主干参数由预先在ImageNet 上训练的Res2Net-50 模型初始化,其余参数由PyTorch 的默认设置进行初始化。使用动量SGD优化器,权重衰减为5E-4,初始学习率为1E-3,动量为0.9。此外,批量大小设置为4,并通过因子为0.9 的poly 策略调整学习率,网络训练40轮。训练图像的大小统一调整为352×352。
2.4 实验结果及对比
实验中,将本文模型与近期的6种典型方法进行比较,其中包括医学图像分割方法PraNet[27],显著性目标分割方法F3Net[21]、GCPANet[28]以及MINet[29],自然伪装目标分割方法SINet[1]以及PFNet[13]和军事伪装目标分割方法SSDN[11]。为客观公正地进行对比,上述方法的预测图都通过运行官方开源代码,在相同数据集训练模型生成。其中,输入图像大小、batch数量、学习率、权重衰减系数等训练参数与本文模型所做实验相同,此外,所有的预测图都使用相同的代码进行评估。表2 报告本文与其他6 种典型方法在迷彩伪装数据集CPD 上的定量结果。图4展示出不同模型的目标分割结果图。
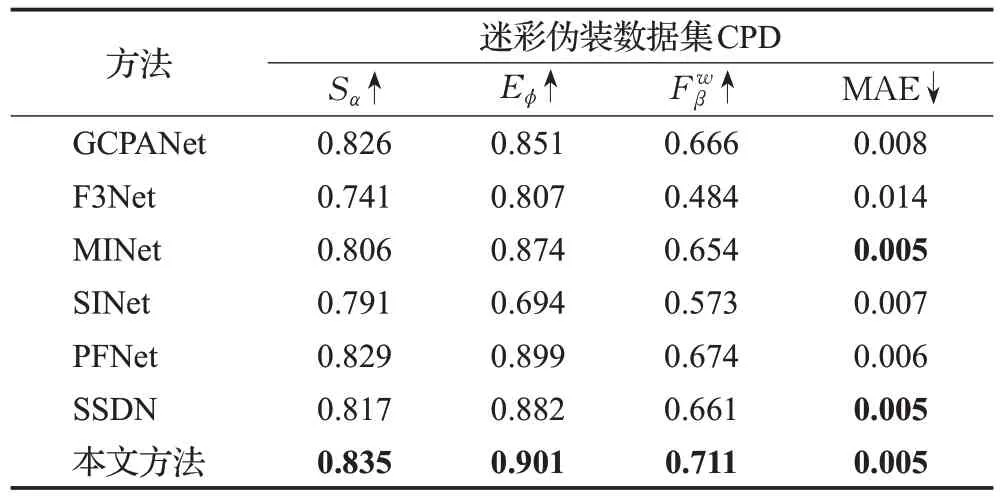
表2 本文方法与其他方法在迷彩伪装数据集对比Table 2 Comparison between other and proposed methods on camouflaged people dataset
从表2可以发现,本文的方法在各项标准评估指标下都优于其他比较模型,说明本文方法较其他方法更适合军事迷彩伪装分割任务。图4 也可以直观看出本文方法能更好地在各种复杂环境下分割出多姿态小目标伪装人员。因此本文方法相比于其他方法更加充分利用图片各层特征中的语义信息以及细节信息,在小目标分割中生成更加精确和完整的伪装物体预测图,并且减少误判和漏检的情况。
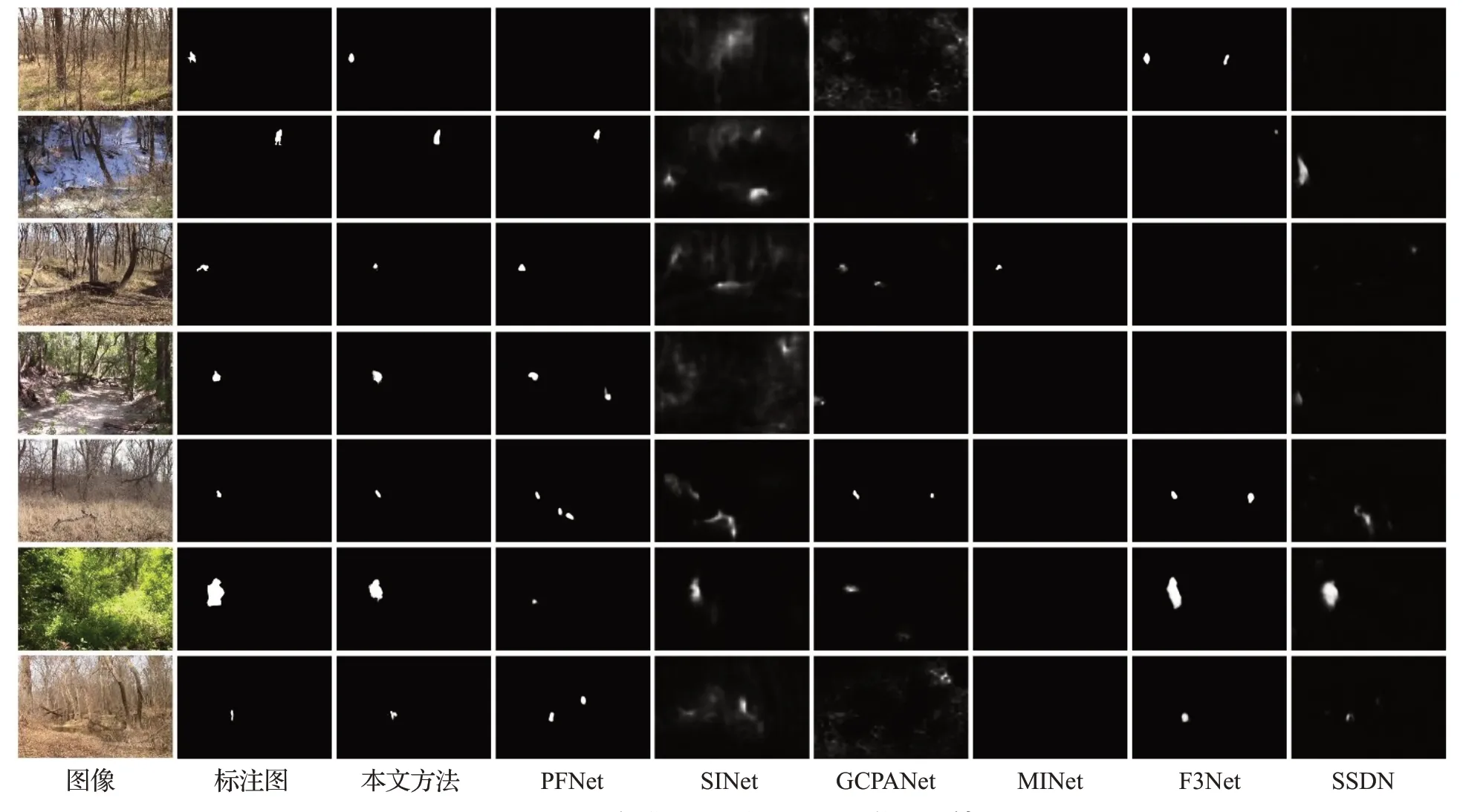
图4 CPD数据集上不同模型的视觉比较结果Fig.4 Visual comparison results based on different models on camouflaged people datasets
另一方面,为证明本文方法对于自然伪装目标分割任务同样有效。本文方法与其他6个典型方法进行比较,其中包括PraNet[27]、F3Net[21]、MINet[29]、CPD[30]、SINet[1]、PFNet[13]以及MGL[14]。同样为客观公正地进行对比,上述所有模型采用官方提供的开源代码,并设置同样的训练参数。此外,所有的预测图都使用相同的代码进行评估。表3报告本文方法与其他6种典型方法在3个自然伪装数据集上的对比结果。可以发现,本文的方法在所有4个标准评估指标下都优于所有其他方法。
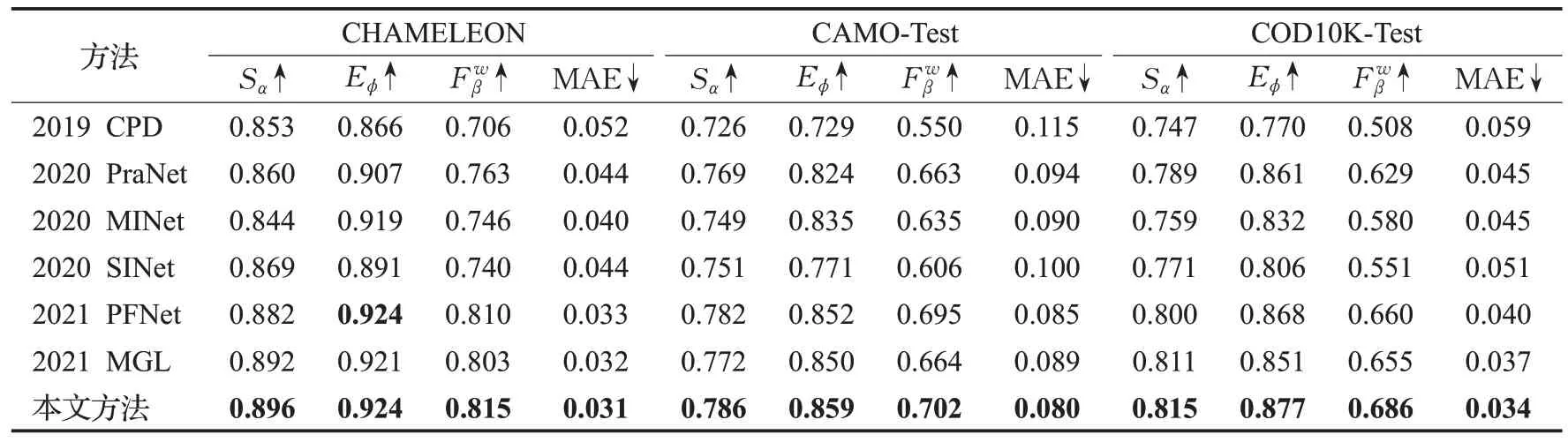
表3 本文方法与其他方法在自然伪装数据集上对比Table 3 Comparison between other and proposed methods on natural camouflage dataset
此外,图5 展示本文方法与其他方法的比较结果。可以看出,在各种尺寸的自然伪装目标分割(小伪装目标(1)行和(2)行、大伪装目标(3)行和(4)行)中都生成更加精确和完整的伪装目标分割图,并且具有清晰的边界和连贯的细节。在分割目标被物体遮挡((5)行和(6)行)情况下,该方法也可以成功地推断出真实的伪装物体区域。因此,本文方法相比于其他方法在复杂场景下的自然伪装分割任务具有更好的表现。
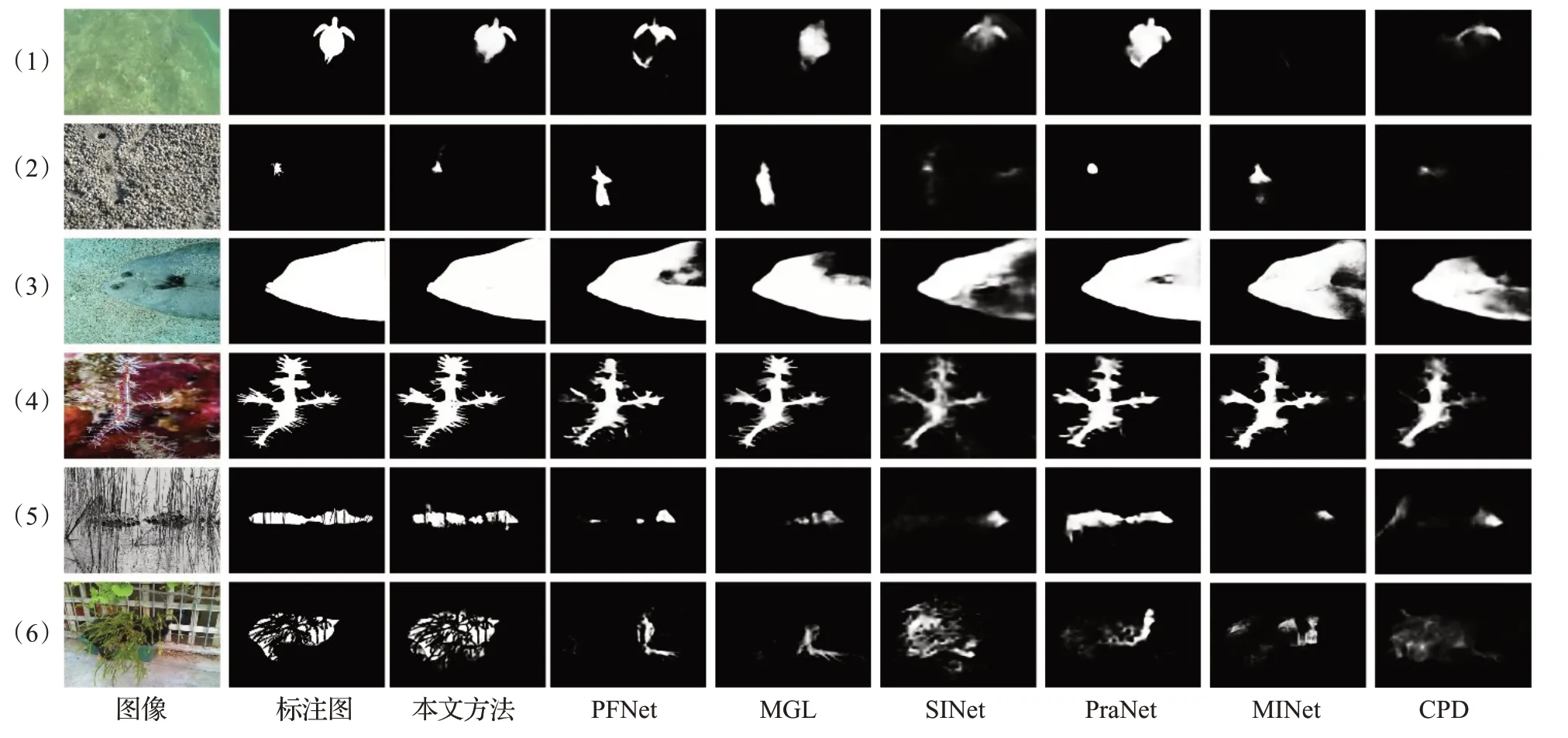
图5 自然伪装数据集上不同方法的视觉比较Fig.5 Visual comparison results based on different models on natural camouflage dataset
本文方法与其他方法在实时性方面也进行了对比。所有算法在相同的实验环境下(RTX 2080Ti显卡)推理相同大小的测试图片,对比结果如表4所示。本文方法对每张图片的处理速度约为0.012 s左右,即帧率在单张GPU上的FPS约为83。根据表4可知,本文方法实时性方面明显优于其他方法。

表4 不同方法的实时性比较Table 4 Real time comparison of different methods
2.5 消融实验
为验证每个提出模块的有效性,本节对多级门控融合模块(GFM)、自交互残差模块(SIRM)以及联合加权损失函数进行详细的消融实验分析,结果报告在表5中。
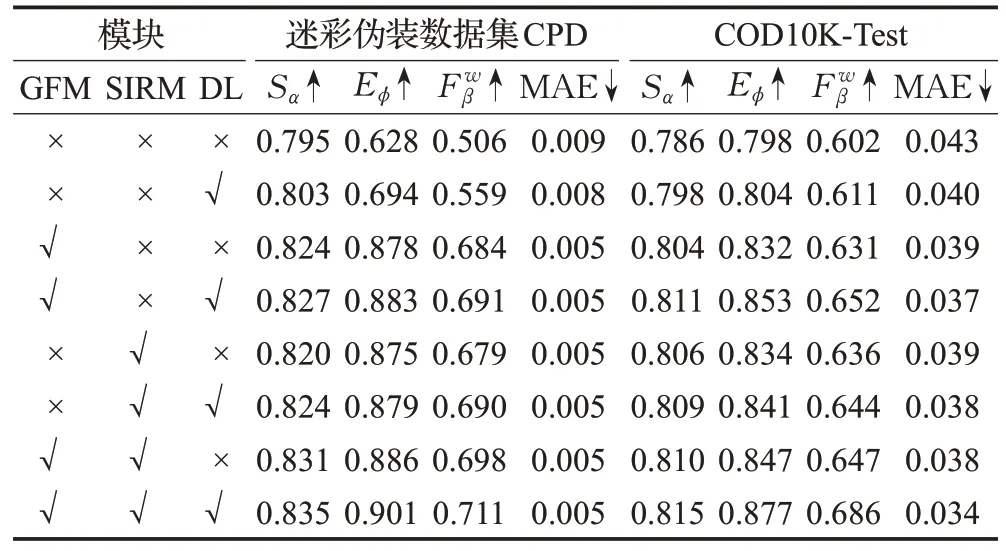
表5 不同模块的性能评价比较Table 5 Comparison of different approaches using different integration module
本文的基线模型是一个类似FCN 的网络,它使用横向连接将最浅层的通道数量减少到32 个,其他层的信道数量减少到64 个,再逐层连接融合最终得出预测图。对比实验是分别在基线模型上加入GFM 和SIRM进行训练,并评估它们的性能,以验证这两个关键模块的有效性,结果如表5所示。
表5显示,伪装目标分割任务中加入GFM或SIRM模块都比基线模型在评价指标上有显著提升。面对军事伪装目标分割任务,本文采用公开迷彩伪装数据集CPD作为数据集,进行对比实验。该数据集中伪装目标普遍较小、形态多样,背景环境复杂。多级门控融合模块在深层特征图的指导下对底层特征背景信息进行过滤,增强各级特征图的表达能力使得网络模型比基础模型的Sα、Eϕ和分别提升2.9%、25%和17.8%,证明门控融合模块能够帮助模型更好地分割军事伪装目标;单独引入SIRM增强特征多尺度表达能力,使得Sα、Eϕ和分别提升2.5%、24.7%和17.3%,实验证明自交互融合模块在军事伪装目标分割任务中具备有效性。此外,GFM和SIRM同时放入模型中,分割性能较单独引入有进一步提高。但注意到几种模型的MAE 差别不大,这是由于数据集中含有大量较小的或被障碍物所遮挡的目标(即只包含伪装人员部分身体的图像,约占数据集60%),在这种情况下,无论是否正确检测,都不会引起MAE值的剧烈变化。
针对自然伪装目标分割任务,本文采用COD10K作为数据集,进行对比实验。结果显示,单独引入GFM的网络结构较基线模型结构度量提高2%,自适应E 度量提高3.6%,加权F 度量提高3.4%并且平均绝对误差从0.043降低到0.039,证明门控融合模块选择性地融合多级特征对于提高伪装目标分割精度有一定帮助。加入SIRM 的网络结构较基线模型Sα、Eϕ和分别提升1.6%、3.4%和2.98%并且平均绝对误差从0.043 降低到0.039,证明SIRM深度挖掘出的多尺度信息可以有效提升模型分割性能。此外,GFM和SIRM的结合帮助模型进一步提高模型分割性。
图6 为各级特征经过GFM 模块后的可视化比较。第一行为Res2Net-50主干网络提取的各级特征,第二行为多级融合后的各级特征。依次为输入图像从浅到深的中间层特征图。可以清楚地发现浅层的提取特征和中伪装目标被背景信息严重干扰,经过门控机制后特征图中背景信息得到有效抑制,目标细节信息更为明显,底层特征图可以清晰地分辨出目标所在位置。门控融合过程中,只要存在某一特征图能准确描述伪装目标位置,其余各级特征选择性融合后都可以发现目标位置,并有效过滤各级特征中干扰信息。图6 中第一行的特征图f5突显出伪装目标所在位置,因此其他各级特征在门控融合中都可以判断出背景位置,对干扰信息加以过滤,增强各级特征表达能力。多级门控融合的前提是深层特征中包含较强语义信息,可以准确寻找出目标位置。但如果提取网络中各级特征都无法定位出目标位置,门控融合模块就无法达到增强各级特征表达能力的效果。
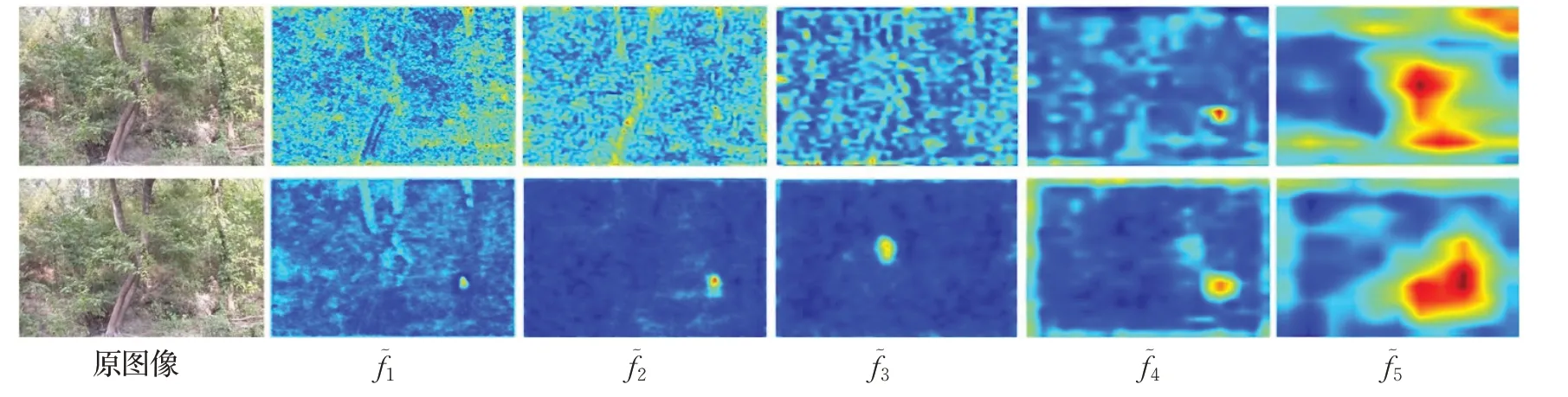
图6 经过GFM后特征图的可视化比较Fig.6 Visualization comparison of feature maps after GFM
图7 为各级特征经过SIRM 模块后的可视化比较。第一行为多级融合后的各级特征,第二行为各级特征经过SIRM 后所有特征的可视化结果。由图F4和F5可视,深层特征经过SIRM 后,可以挖掘出更多有用信和息。在浅层特征(F1、F2和F3)中伪装目标更加突显,对模型准确分割伪装目标起到较大帮助。

图7 经过SIRM后特征图的可视化比较Fig.7 Visualization comparison of feature maps after SIRM
为分析本文中联合损失函数的有效性,本文对基线模型以及单独引入GFM、单独引入SIRM 和同时包含GFM和SIRM的四种模型,在损失函数方面进行对比实验。根据表5可知,采用联合损失函数的模型较比不引入Dice损失的模型,在分割效果上都有所提高。证明加权Dice损失对目标尺度不敏感以及更加关注优化全局结构的特点,可以有效提高模型的分割精确度。在迷彩伪装数据集CPD 上,基线模型中引入Dice 损失,Eϕ和评价指标分别提升6.6%和5.3%。并且在同时包含GFM和SIRM的改进模型中,带有加权Dice损失的模型在迷彩伪装数据集CPD 上Sα、Eϕ和三个标准评价指标都有不同程度的提高。同样在自然伪装数据集COD10K上Eϕ和分别提高3%和3.9%,MAE从0.038降低到0.034。视觉效果如图8 所示,引入加权Dice 损失后模型对于目标边缘分割更加精细,并且整体结构更加完整。
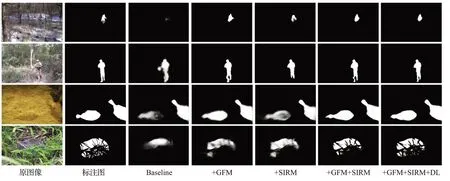
图8 各模块的视觉比较Fig.8 Visual comparison results based on different module
3 结束语
本文提出一种基于多级特征融合的伪装目标分割方法。首先使用门控融合模块有选择性地融合多级特性,有效过滤背景信息干扰,然后利用自交互残差模块从GFM 输出特征中提取更多尺度信息。最后,本文引入Dice损失增强损失函数对图片中各尺寸目标的监督效果,提升伪装目标的准确度。本文的方法在军事迷彩伪装数据集以及三种自然伪装数据集上进行实验,在常用的四种评价指标下优于其他典型方法。在主观视觉上,本文方法分割出的结果图能更好地处理各种复杂情况的伪装图像,较好保留出伪装目标轮廓。实验证明,本文方法对伪装目标分割任务有更好的分割效果。
在未来的研究发展中,进一步考虑融合传统方法与深度学习相结合共同提取目标特征信息,增强特征中目标信息帮助模型更好发现伪装目标。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
数学小灵通·3-4年级(2021年5期)2021-07-16
当代陕西(2019年10期)2019-06-03
今日农业(2019年15期)2019-01-03
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
汽车与新动力(2012年1期)2012-03-25
