
基于自编码器的深度聚类算法综述
2022-09-21 05:37陶文彬钱育蓉张伊扬马恒志冷洪勇马梦楠
计算机工程与应用 2022年18期
陶文彬,钱育蓉,张伊扬,马恒志,冷洪勇,马梦楠
1.新疆大学 软件学院,乌鲁木齐830046
2.新疆大学 软件学院 重点实验室,乌鲁木齐830046
3.新疆维吾尔自治区 信号检测与处理重点实验室,乌鲁木齐830046
4.北京理工大学 计算机学院,北京100081
聚类是从现有数据中挖掘潜在信息,将其划分为多个簇的过程[1]。聚类算法作为传统机器学习中常用的算法之一[2],得到了广泛的关注与研究。目前虽然已有大量的数据聚类方法[3-6]已经被提出,但是在面对海量图像、视频等高维数据的应用场景时,传统聚类算法运算量过大,且难以从中提取到有效的信息,存在着自身的局限性。
深度聚类由于能借助深度学习技术的特征提取能力提升聚类效果,因此成为了当前业界研究的热点。深度聚类[7-8]方法的核心思想就是使用各种神经网络从高维数据中提取到有用的特征,再进行聚类。
自编码器[9](autoencoder,AE)作为基础的神经网络模型之一,通过编码解码的过程,期望将网络的输出等同于输入,实现对样本的抽象特征学习,适合与聚类任务结合。因此,目前研究最多,泛用性最广的就是基于自编码器的深度聚类算法。
深度聚类算法近几年发展迅速,在2016年Xie等人提出了基于自动编码器的深度聚类模型DEC[10](deep embedded clustering),相比传统聚类算法有了较大提升。Guo等人于2017年提出了基于此的改进算法IDEC[11](improved deep clustering),改进了DEC破坏了部分局部特征的缺陷,进一步提升了效果。之后研究人员们基于自编码器相继提出了很多改进模型,如:使用了卷积自编码器的DCEC[12](deep convolutional embedded clustering),在自编码器中增加了稀疏约束的DSSEC[13](deep stacked sparse embedded clustering),基于变分自编码器的VaDE[14](variational deep embedding)和以及基于多个自编码器结合的MIXAE[15](MIXture of autoencoders)等。
本文主要总结了现有的基于自编码器的典型深度聚类算法及其评估标准,分析了各个模型的特点、优势以及存在的问题,并对以后的研究提供帮助。本文的贡献可归纳如下:
(1)以自编码器的结构作为分类依据,对相关深度聚类算法进行了合理的分析与概述。
(2)对基于自编码器的深度聚类算法常用的数据集与评价指标进行介绍,并根据算法在MNIST、USPS、Fashion-MNIST数据集上的实验结果,作出总结分析。
(3)分析总结了基于自编码器的深度聚类算法目前所存在的问题以及未来可能的方向,为后期研究提供参考。
1 深度聚类算法
深度聚类算法是一种利用深度学习的非线性表达和特征提取的能力进行聚类的算法模型[16],相比传统聚类算法更适合应用于拥有海量、高维的数据场景下。通过对这种方法的基本原理和优缺点的分析,可以加深对其作用机理的认识。
1.1 深度聚类算法概述
聚类算法的核心在于分辨数据之间的差异与共性。高维数据由于信息过多,导致传统聚类算法难以辨别数据之间的差异。例如经典的K-means[17]、谱聚类等算法在图像数据上往往得不到理想的结果。而深度聚类算法通过深度学习技术,使得提取的低维特征可以很好地保留原数据的信息与结构,减少了计算量的同时让数据的差异表现得更加明显,实现了更好的聚类效果。
深度聚类算法的具体流程与它所使用的深度学习模型相关。基于自编码器的深度聚类算法其主要思想如下:
步骤1 优化自编码器,降低重建损失。
步骤2 预聚类,参数初始化,得到聚类损失。
步骤3 使用聚类损失和重建损失联合优化自编码器中的编码器,循环步骤2、步骤3。
步骤4 最终聚类,输出结果。
其基本结构如图1所示。
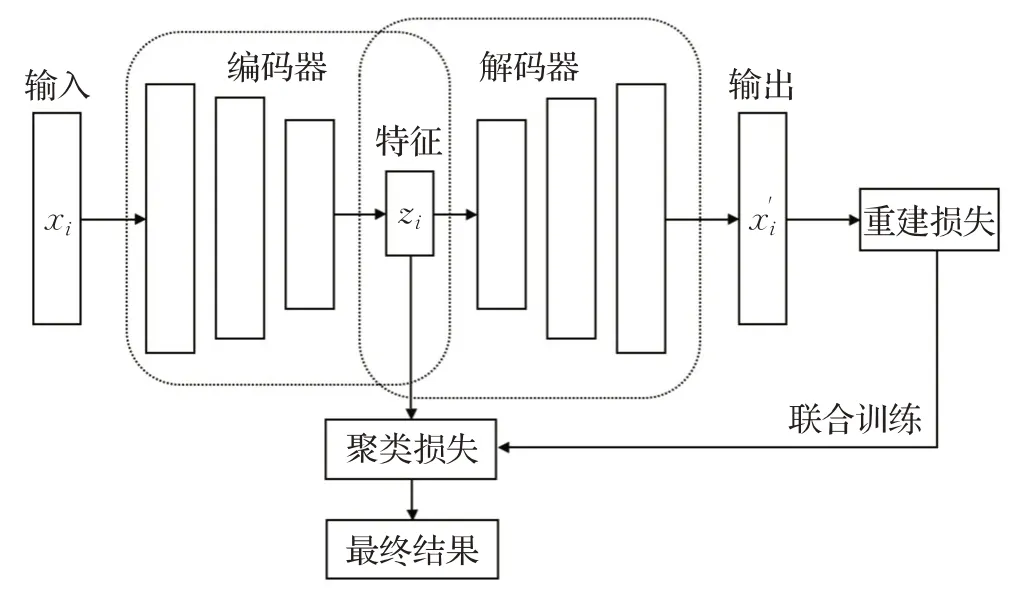
图1 深度聚类算法基本结构Fig.1 Basic structure of deep clustering algorithm
1.2 损失函数
目前深度聚类算法的损失函数一般是由重建损失函数和聚类损失函数两方面组成,定义如下:

其中,Lrec为重建损失函数,Lc为聚类损失函数。
1.2.1 重建损失
自编码器作为无监督的神经网络,目标是使输出的数据尽量接近输入的数据。自编码器可以视为由两部分组成:将原始数据x编码为提取特征z的编码器函数z=fϕ(x),以及将所提取特征z解码为输出数据R的解码器函数r=gθ(z) 。重建损失函数用于衡量这两部分的差异。它的目的是使提取后的特征尽可能地保留原有数据的信息。具体定义如下:
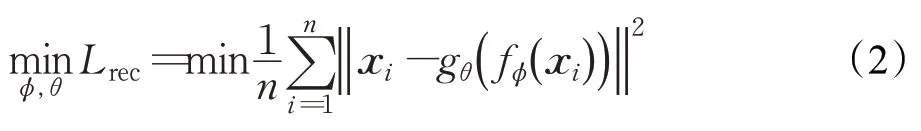
其中,ϕ和θ分别表示编码器和解码器的参数,n为样本数量,xi为输入样本。
1.2.2 聚类损失
聚类损失函数主要用来衡量聚类结果与输入数据之间的关系,一般与样本划分出的簇和质心有关。不同的模型由于所侧重的方面不同,设计的聚类损失函数也各有不同。例如K-means聚类损失[18]、类别硬化损失[19]、层次聚类损失[20]等。
1.3 深度聚类优缺点分析
得益于神经网络的特征提取能力,深度聚类算法可以更好地将高维数据转换为低维特征。这样的结构克服了传统聚类算法面对高维数据计算量大、效果差的局限性,相比主成分分析(PCA)[21]、核方法[22-23]、谱方法[24-25]等传统的数据降维方法,神经网络强大的非线性表达能力也使得数据的结构得到了更好的保留。
基于深度学习的聚类算法也有着自身的局限性,它提取到低维特征的目标是尽可能地保留原有信息,无法剔除无关信息,影响了聚类结果。同时,在使用聚类损失Lc对神经网络调整的过程中,所提取的特征对输入样本信息的保留能力也受到了影响,一定程度上对最终聚类结果起到了反效果。
2 基于自编码器的深度聚类算法
自编码器作为典型的无监督深度学习模型,目的是通过尽可能地让输出接近输入,实现对输入数据的抽象特征学习。Rumelhart等人[26]于1986年最早提出了自编码器的概念,Bourlard等人[27]于1988年对其进行了进一步地完善与阐述。作为深度学习的典型模型之一,AE得到了广泛的研究与改进[9],具体与深度聚类进行了结合、应用的有基础自编码器[26]、卷积自编码器[28]、稀疏自编码器[29]、变分自编码器[30]4大类型。
以自编码器模型结构的分类为依据,基于自编码器的深度聚类算法可分为基于基础自编码器的深度聚类算法、基于卷积自编码器的深度聚类算法、基于稀疏自编码器的深度聚类算法、基于变分自编码器的深度聚类算法、基于混合自编码器的深度聚类算法五类。
2.1 基于基础自编码器的深度聚类算法
基础自编码器[26]的结构如图2 所示,主要分为编码器和解码器两部分。编码器h(x) 将输入样本xi编码为zi,解码器则将zi解码为,网络目标是让输出尽可能地与输入xi相似。
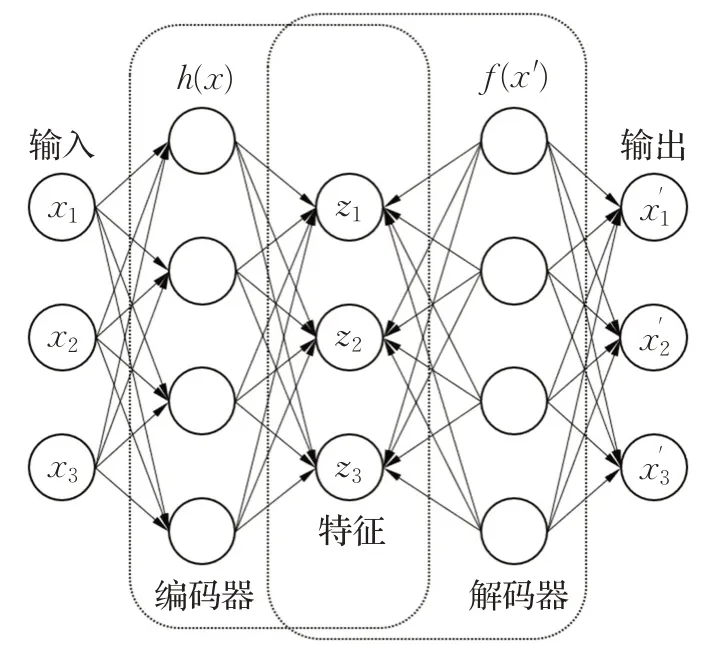
图2 自编码器结构Fig.2 Autoencoder structure
基础自编码器通过训练,用低维的特征尽可能地保留高维数据的信息。对于聚类来说,这不仅减少了无效特征对聚类精度的影响,也提高了聚类的速度。自动编码器可以自动提取数据特征,减少了人力的消耗,更适合聚类这种无监督学习任务。
DEC(deep embedding cluster)[10]是代表性的基础自编码器深度聚类算法之一,由Xie 等人于2016 年提出,它的优势在于从t-SNE 中受到启发,定义了一个基于质心的概率分布,通过将最小化此分布的KL 散度作为聚类损失函数用来同时改善聚类分配以及特征提取,在聚类效果上取得了显著进步,成为了深度聚类效果评价的基线之一。DEC的聚类损失函数Lc具体为公式(3),用来衡量两个目标分布P和Q之间的差异,其中P为真实分布,Q为拟合分布:
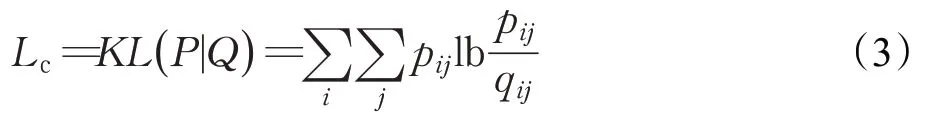
其中,qij表示提取特征得到的点zi与聚类中心ui的相似程度,用t分布[31]进行衡量,其计算公式如式(4)所示。式(4)中α代表t分布的自由度。
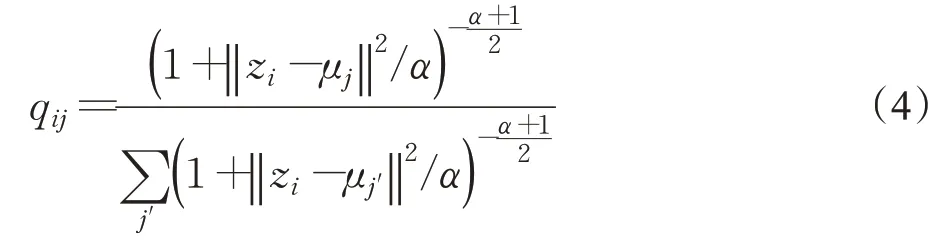
真实分布P的具体定义如下:

DEC的训练过程分为两步,首先用Lrec训练自动编码器,再用Lc训练自动编码器。而第二步训练时对第一步训练的参数产生一定的负影响,影响了聚类效果。
IDEC(improved deep embedded clustering)[11]是DEC的改进算法之一,它认为DEC 在后续训练阶段因为舍弃了解码层会导致编码层扭曲嵌入空间,削弱所提取特征对于原数据局部特征的保留,从而影响聚类效果。它通过联合重建损失与聚类损失联合训练,以求最大程度保留原样本的局部特征,从而提升了聚类效果。它的联合损失函数定义如下:

IDEC 作为DEC 算法的改进版,则通过联合重建损失与聚类损失训练的方式,让数据的局部特征更好地保留,从而提升了聚类效果。
DynAE[32](dynamic autoencoder)则通过动态损失函数,根据提取特征的置信度分别采取重建或者聚类的方式,更好地平衡了重建损失与聚类损失,让损失函数的变化更加平滑,最终取得了更好的效果。
基于基础自编码器的深度聚类算法相比传统聚类算法效果提升明显,但是在自编码器的结构上创新不多,因此并不完全适合聚类任务,没有考虑提取特征的鲁棒性、稀疏性。也因此基于基础自编码器的深度聚类算法应用场景最广,无论是文字数据还是图像数据,都可以达到不错的聚类效果。
2.2 基于卷积自编码器的深度聚类算法
卷积自编码器[28](convolutional autoencoder,CAE)基于卷积神经网络,结构上与基础自编码器相似,区别是通过将网络中的全连接层改为卷积层,可以更好地保留图像信息的空间信息。其中编码器具体由卷积层组成,解码器由反卷积层组成。
DCEC[12](deep convolutional embedded clustering)于2017 年由Guo 等人提出,首次使用卷积自编码器构造深度聚类算法,以端到端的方式学习特征,更好地保留了数据的局部结构,避免了提取特征的失真,最后利用小批量随机梯度下降和反向传播方法,有效地提高了聚类的表现。
DEPICT[33](deep embedded regularized clustering)融合了子空间聚类的思想,引入端到端的联合学习方法,将卷积自编码器多层堆叠,采用统一训练自编码器所有网络而不是逐层预训练的方式,在高维和大规模数据集上取得了具有竞争力的聚类结果,并且不需要进行超参数调整,更加便于训练。
RDEC[34](deep embedded clustering with ResNets)通过在卷积层中引入残差连接的方式,降低了堆叠网络层数带来的性能退化问题,相比DEC算法,在层数逐渐增加时,RDEC的性能退化减少了56%。
DCEC方法仅仅替换了自编码器的全连接层,相比DEPICT方法,没有引入子空间聚类的思想,自编码器堆叠层数也较少,所以复杂度较低,最终效果弱于DEPICT算法。而RDEC对于残差网络的引入,虽然对聚类效果的提升并不明显,但是展示了未来通过堆叠网络层数提高效果的可能性。
相比于其他类型的自编码器深度聚类算法,基于卷积神经网络的深度聚类算法对于图像特征提取的效果一般更好,可以有效保留原数据的空间特征。但由于卷积层的引入,导致卷积自编码器对于非图像类的数据处理领域处于劣势,适用性遭到了一定的限制。并不适用于文字等数据处理场景。
2.3 基于稀疏自编码器的深度聚类算法
稀疏自编码器[29](sparse autoencoder,SAE)的主要思想是在基础自编码器的损失函数中增加了稀疏性限制,使大部分网络节点处于非激活状态,迫使网络压缩数据从而达到对特定结构特征的提取。它的具体实现是通过添加惩罚项,对神经元的激活度进行惩罚,从而降低隐含层节点激活比例,惩罚项通常采用L1、L2范数或者KL 散度,用来衡量神经元的期望激活度ρ与实际激活度之间的差异。例如,KL散度的惩罚项公式如下:

基于稀疏自编码器的深度聚类算法通过添加约束使得提取的特征表示更加稀疏,使得数据之间的区分度更高,为接下来的聚类任务降低了难度,从而间接提升了最终的聚类效果。
DEN[35](deep embedding network)是一个比较经典的稀疏自编码器深度聚类模型,它为了使自编码器提取到的特征更适合聚类,首先添加了一个约束以保持原数据的局部性特征,然后对提取到的特征应用了组稀疏约束,目的是学习对应于它的簇的非零组的块对角表示,从而提升了最后的聚类效果。
DSSEC[13](deep stacked sparse embedded clustering)为了综合考虑数据的局部特征与稀疏性,提出了一种深层稀疏自编码聚类算法,在聚类损失和重建损失的联合指导下训练提取输入数据的特征表示。其中重构损失避免了特征空间的破坏,并保持了局部结构。而在编码器中加入稀疏约束则避免了对不重要特征的学习。通过同时最小化重构和聚类损失,该方法能够联合学习面向聚类的特征并优化聚类标签的分配。
基于稀疏自编码器的深度聚类算法所提取的特征分离度较高,更适合于聚类任务,相比基于CAE的深度聚类算法适用场景更广。但由于引入惩罚项,导致算法结果波动性较大。同时,SAE无法将激活与否指定到具体的神经网络节点,稀疏性的超参数设置也没有通用的规则,使网络训练更加困难。
2.4 基于变分自编码器的深度聚类算法
变分自编码器[30](variational autoencoder,VAE)是一个生成式网络模型。目的是通过对样本分布的学习,用预设的估计分布逼近真实样本分布,从而通过估计分布生成类似于原始样本的生成样本。变分自编码器的结构如图3所示。
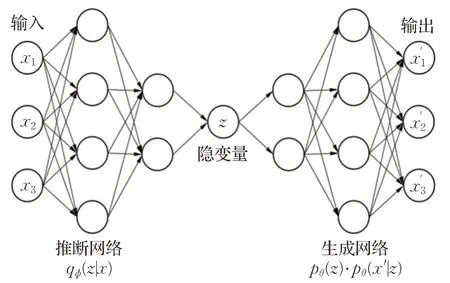
图3 变分自编码器结构Fig.3 Variational autoencoder structure
VAE 使用两个概率分布密度模型作为编码器与解码器,图3中变量qϕ(z|x)是编码器,为推断网络,用于生成隐变量z的变分概率分布,pθ(z)是隐变量z的先验,pθ(z)⋅pθ(x′|z)是解码器,通过z还原原始数据的近似概率分布,为生成网络。它的重构损失衡量的是原数据的概率分布与解码器输出的近似概率分布之间的差异。其目标函数公式最终化简为:
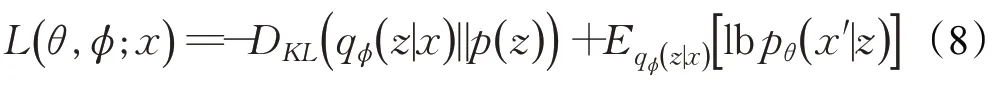
基于变分自编码器的深度聚类算法优势在于结合了变分贝叶斯方法与神经网络,高度灵活,便于扩展,并借助变分下界使得可以直接使用随机梯度下降[36]、标准反向传播[26]对网络进行优化,减小了优化难度。
VaDE[14](variational deep embedding)基于变分自编码器,结合了高斯混合模型,是用混合高斯先验替代单一的高斯先验后的VAE。其生成观测样本x的定义如下:
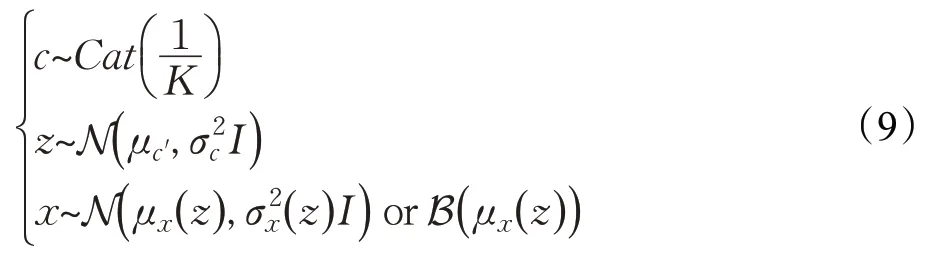
其中,Cat(⋅)表示类别分布,K是设定的聚类簇数,μ和σ是基于蔟中心c高斯分布的均值和方差,N(⋅)和B(⋅)则是用μ和σ表示的多元高斯分布和伯努利分布。
GMVAE[37](Gaussian mixture variational autoencoder)与VaDE的基本思想相像,主要的不同就是生成观测样本x的过程,具体定义如下:
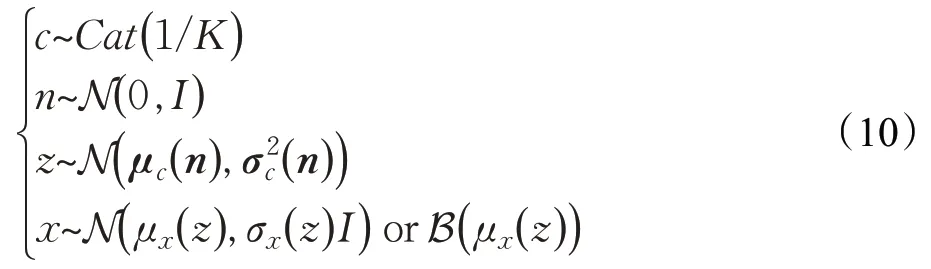
GMVAE 为了改善VAE 过度正则化影响聚类效果的弊端,在算法中加入了最小信息约束[38],缓解了这一问题。
VaDE和GMVAE作为基于变分自动编码器的深度聚类算法,主要的改进方向都是提升观察样本生成的结果,进而提升聚类效果。具体方法有修改网络结构,改进相应约束等。基于VAE的深度聚类算法优势主要在于可以生成伪样本,以及借助高斯混合模型,保证了理论的可解释性。但是生成式网络的引入不但提升了对计算资源的要求,也大大增加了对样本的数量需求。
2.5 基于混合自编码器的深度聚类算法
不同自编码器对特征的提取各有侧重,为了更好地利用各个自编码器的优势,诞生了基于混合自编码器优势的深度聚类算法。通过对多种自编码器的有效结合,实现了对特征更好的提取,提升了最终聚类的效果。
MIXAE[15](MIXture of autoencoders)是一种基于混合自动编码器的深度聚类算法,对于聚类样本假设最终会聚类出K个簇,它使用K个自动编码器对应聚类结果的每个簇,期望每个编码器分别对提取某一个簇的样本特征最有效。对于属于不同簇的样本,将从K个自动编码器中挑选其中某一个进行特征提取。这样提取出来的特征分离度也会更高,从而使得最终聚类效果得到改善。但该算法由于K个自编码器均衡对应K个簇的基本思想,导致面对不平衡样本时则会处于劣势。
DASC[39](dual autoencoder spectral clustering)作为另一种混合自动编码器的深度聚类算法,则是同时使用两个自编码器所提取的特征,其中一个自编码器加入了噪声。通过使用有噪声和无噪声的编码器重构损失,使所提取到的特征具有更好的鲁棒性。同时该方法的新意在于没有使用常见的K-means方法,而是使用谱聚类方法进行最后的聚类步骤。但不论是两个多层的卷积自编码器还是谱聚类算法,相比其他的自编码器深度聚类算法,计算量都大大增加,因此对于资源要求较高,较为耗时。
DMNEC[40](deep multi-network embedded clustering)则提出了一种基于SAE、VAE、CAE 三种网络机构的多网络深度聚类算法。它以不同网络结构作为分支,得到不同的特征,再进行拼接融合,从而得到了互补的最终特征,基于此再进行聚类。网络微调阶段则是通过引入软分配的思想,同时借助辅助目标分配,实现多网络解码器与簇心的联合学习。
MVC-MAE[41](multiple auto-encoder-based multi-view clustering)是一种多模态深度聚类算法。它通过使用多个自编码器,在多个模态的数据中提取具有一致和互补信息的特征,最后在统一框架中进行聚类。该算法在目标函数中引入了一种新的基于交叉熵和正则图的约束,保证了不同模态数据特征的一致性和互补性。由于充分利用了不同模态数据之间的互补优势,提升了最终聚类效果。
混合模型的深度聚类算法最终效果都比较优秀,但由于多个神经网络的存在,导致训练对资源要求较高,神经网络中相关超参数的调整也比较耗时。
2.6 小结
基于不同自编码器的深度聚类算法侧重点各有不同,依据上文分析结果,表1 从自编码器类型、创新、优势和局限性对这几类自编码器深度聚类算法做了对比分析。
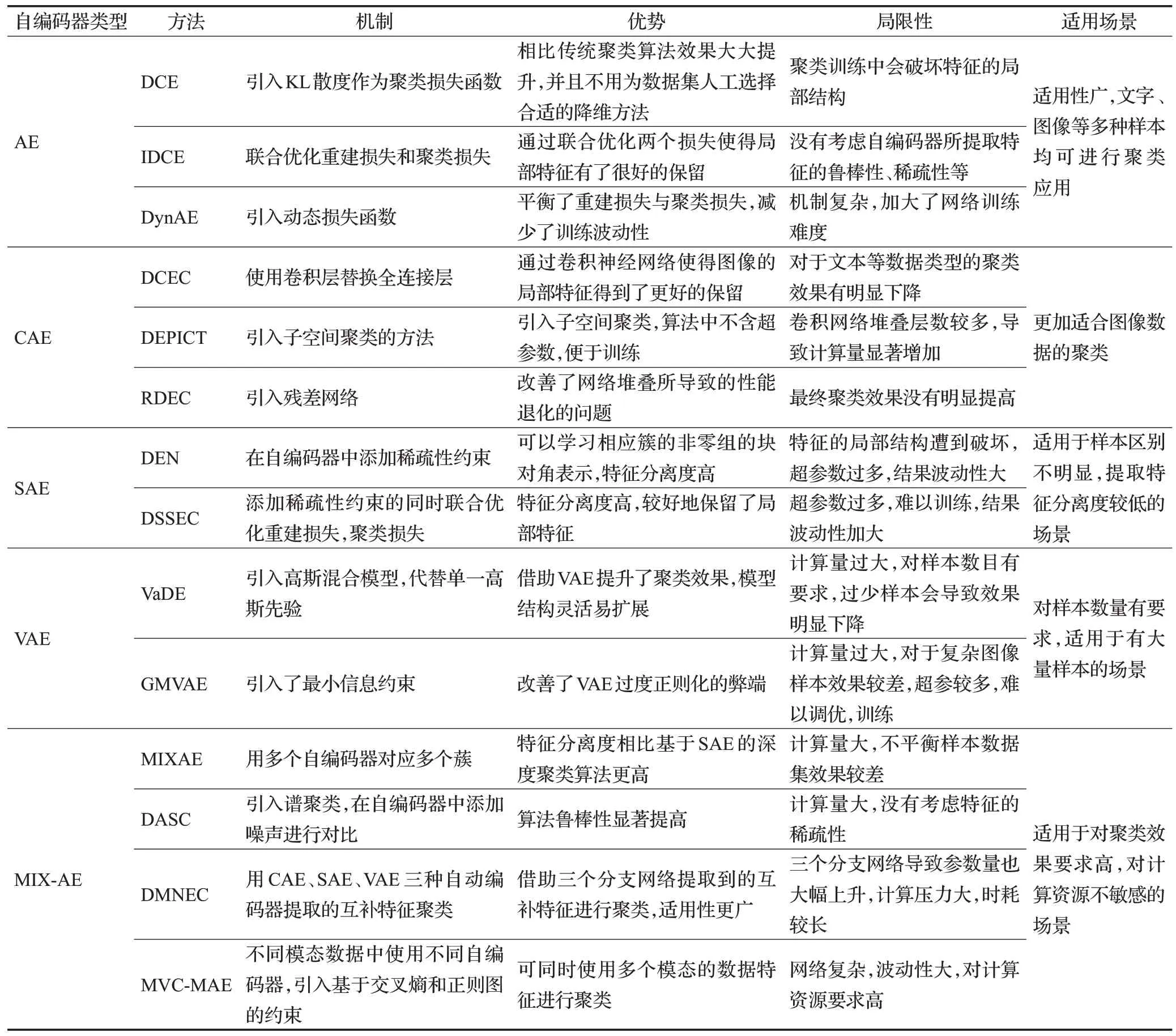
表1 自编码器深度聚类算法对比Table 1 Comparison of autoencoder deep clustering algorithms
3 实验分析
首先介绍三个实验所用的公开数据集的基本情况,然后分析阐述深度聚类算法的两个评价指标,最后则通过经典聚类方法与基于自编码器的深度聚类方法在三个数据集上的实验结果进行对比分析。
3.1 数据集
本次实验采用的三个数据集为MNIST数据集、USPS数据集、Fashion-MNIST数据集,主要信息如表2所示。
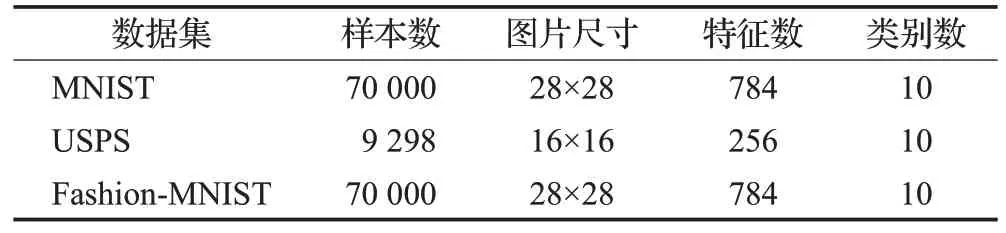
表2 数据集属性Table 2 Dataset properties
其中MNIST 数据集和USPS 数据集均为灰度手写体数字图像数据集,主要区别为样本数目。通过二者的对比,可以看出各个聚类算法对于样本量的需求。而Fashion-MNIST 数据集则是由裙子、外套、运动鞋等灰度图像组成,与MNIST 数据集的区别是图片的复杂程度,相互对比可以展示聚类算法面对复杂图像的聚类效果。
3.2 评价指标
本次算法实验采取两个广泛使用的评价指标来评价相关深度聚类算法的性能,分别是准确率ACC(accuracy)和标准互信息指数NMI(normalized mutual information)。
ACC 指数可以直观地看出正确分配的样本占全部样本的比例,相关公式如下:
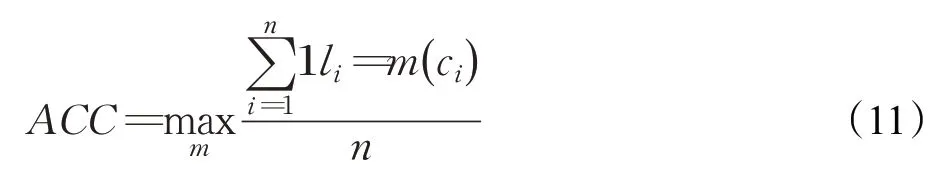
其中,n是样本总数,li为真实簇标签,ci为算法所输出的预测簇标签,m(ci)作为映射函数,表示真实标签与预测标签之间所有可能的一一映射,一般使用匈牙利算法[42]进行实现。
NMI基于信息熵的思想,用于衡量两个数据分布的吻合程度,也经常用来评价聚类效果。相关公式如下:
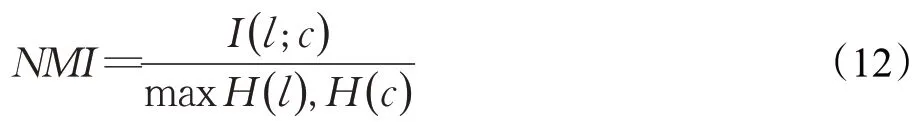
其中,I(l;c)表示真实标签与预测标签之间的互信息程度,H(l)表示真实标签的熵值,H(c)表示预测标签的熵值。
ACC、NMI 指数的值均位于区间0 和1 之间,值越高,性能越好。
3.3 实验设置
本次对比分析选取了多种经典聚类算法以及基于各个自动编码器结构的具有代表性的深度聚类算法,包括有经典的K-means 算法,PCA 降维后的K-means 算法,AE降维后的K-means算法,以及七种具有代表性的基于自编码器的深度聚类算法(DEC、IDEC、DCEC、DSSEC、VADE、DASC、DMNEC),从而可以全面地对比分析传统聚类,降维后的传统聚类以及基于自编码器的深度聚类的最终效果,更好地展示自编码器以及联合优化两方面对最终聚类效果的影响。
由于K-means算法聚类需确定K值,公平起见,均将K设定为相应数据集的类别数。对于PCA+K-means,AE+K-means,SAE+K-means三种组合方法具体是利用降维方法将数据集降到10 维,再运行K-means 算法。对于深度聚类算法,具体结构各不相同,但特征层均设置为10 维,重复的编码器结构使用了一样预训练模型。网络具体训练阶段,学习率0.001,batch_size 设置为128。
为了保证实验的公平性,所有复现的算法都基于相同的环境。具体实验条件如表3所示。
表3 实验条件Table 3 Lab environment
3.4 实验结果与分析
本节展示并分析在MNIST、USPS、Fashion-MNIST数据集上不同算法的结果,各个算法在三个不同数据集上的ACC和NMI指数如表4所示。
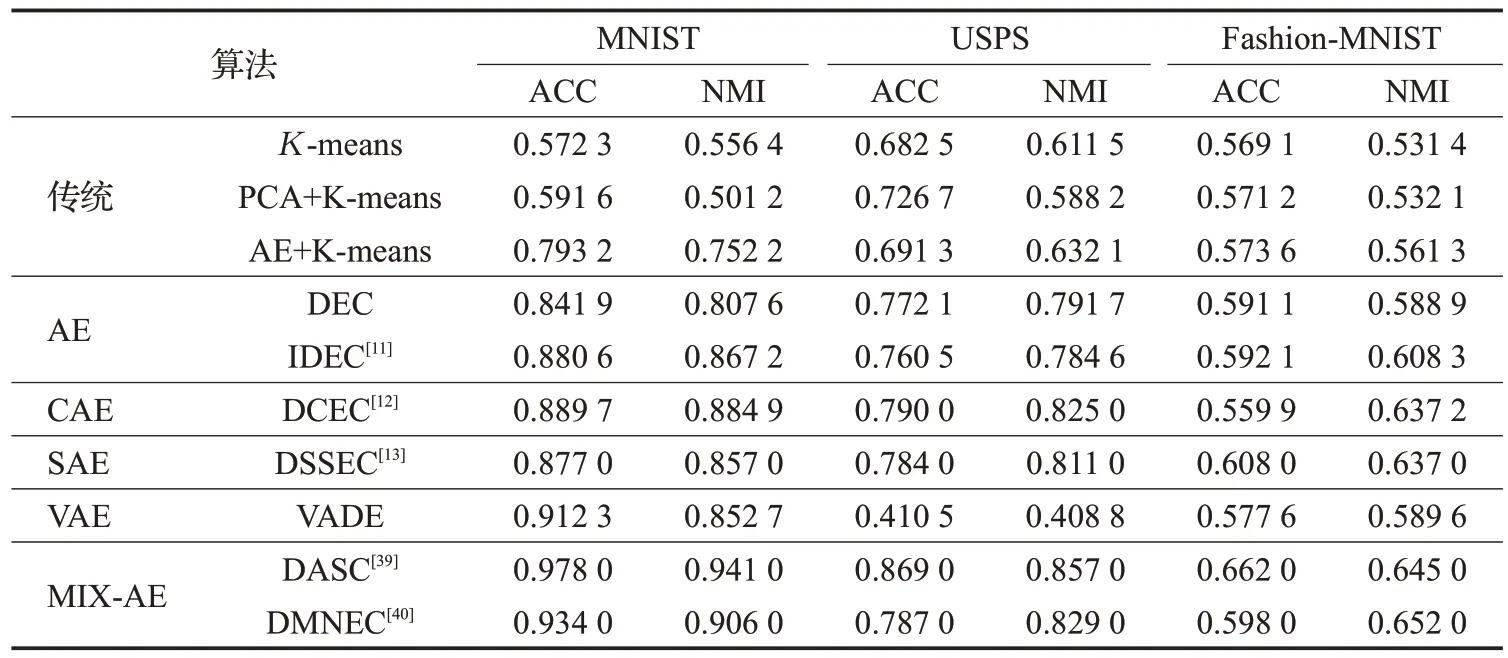
表4 实验结果对比Table 4 Comparison of experimental results
从实验结果可以看出,基于自编码器的深度聚类算法在三个数据集的各个指标均优于K-means聚类算法以及传统的降维方法与K-means聚类算法的结合。
基于AE、CAE、SAE的深度聚类算法中,基于AE的深度聚类算法结构相对简单,最终聚类效果虽然在ACC 指标上与其余算法没有明显差距,但是在NMI 指标上则处于劣势,这说明基于AE 的深度聚类算法划分的各个簇之间的分离度不够高。而基于CAE、SAE的深度聚类算法在NMI指标上处于优势主要是因为卷积网络对图像特征提取的效果优于全连接网络,以及稀疏约束迫使所提取特征分离度更高。
基于VAE的深度聚类算法在MNIST数据集上表现较好。但VADE 在小样本量的USPS 数据集上,表现效果就大幅下降,说明了该算法对于训练数据的数量有着较高的要求。同时,VADE 在图像较为复杂的Fashion-MNIST 数据集上的表现与基于AE、CAE、SAE 的算法并没有拉开差距,某些指标甚至弱于它们。这说明基于VAE 的深度聚类算法在面对复杂图像时的生成效果不佳,依旧有较大的改善空间。同时需要注意的是,基于VAE 的深度聚类算法训练所需要的资源明显高于其他单一结构的自编码器深度聚类算法。
基于混合自编码器结构的深度聚类算法在三个数据集上的各项指标均领先单一自编码器结构的深度聚类算法。这主要是因为通过混合网络结构算法可以提取到不同侧重点的特征,通过互补可以更好地进行聚类。混合自编码器结构的深度聚类算法劣势则是训练需求也是其余单一结构的自编码器深度聚类算法的多倍,对训练资源要求较高。同时,如何设计结合不同分支网络结构所提取的特征也是一个难点。例如实验中的DASC 和DMNEC,其中DASC 是使用谱聚类的思想融合相关特征,DMNEC则是仅仅进行了简单的特征拼接,没有采用神经网络进行特征融合,因此DASC 的最终聚类效果相对DMNEC就有一定提升。
4 总结和展望
随着数据维度和数量的迅速增长,线性降维之后再进行聚类的方法已经无法满足当今社会的需求,深度学习作为非线性降维的有效方法,逐渐得到了国内外研究学者的关注。尤其是将深度学习方法引入聚类领域后所诞生的深度聚类,相比传统聚类方法取得了明显的优势,已经广泛应用于目标检测[43-46]、图像处理[47-48]、事件分析[49-51]、网络优化[52-53]等各个领域。本文总结了各类基于自编码器的深度聚类算法,分析了相关算法的优势与不足,并对深度聚类算法作出如下展望。
(1)理论探索
目前通过联合网络损失与聚类损失的方法显著提高了深度聚类性能,但对于如何定性地分析特征提取与聚类损失对最终聚类的影响,以及引入聚类损失对特征提取的影响依旧没有可靠的理论分析。因此,探索深度聚类优化的理论基础,对于指导该领域的进一步研究具有重要意义。
(2)多模态数据融合
现实的应用场景中,需要聚类的往往不是单一的图像信息,经常同时有可以利用的文本、语音信息。而目前的深度聚类算法大多只能利用到其中一类信息,不能很好地利用已有的各种信息。后续的研究可以考虑充分融合两种及两种以上模态的信息,充分利用不同模态数据之间的互补性,提高聚类效果。
(3)半监督学习
深度聚类算法作为无监督学习,并不能使用有标记的数据进行训练。但是在实际的应用场景中,更多的时候数据并不是完全无标签,而是少量具有标签的数据和大量无标签数据的场景。现有的深度聚类算法却无法利用这些少量的有标签数据。半监督学习技术作为一类可以同时有效利用有标签数据和无标签数据的学习范式,与深度聚类结合可以更好地提升最终聚类效果。
(4)聚类方法单一
目前的深度聚类算法基本均使用K-means 算法进行最后的聚类步骤,只有少数算法利用了其余的聚类算法,并没有充分利用到之前研究传统聚类算法的积累。实际上DASC 算法在最后的聚类步骤采用了谱聚类的方法,就使得聚类效果有所提升。如何改进K-means算法让它更加适用于深度聚类算法这一结构,或者利用其余优秀的传统聚类算法进行最终聚类,提升效果,是一个值得研究的方向。
(5)模型过拟合与效率
限制深度聚类模型实际应用的因素主要有以下两点:模型过拟合和模型计算效率[54]。
深度聚类算法需要大量样本进行训练。因此在小样本数据集上,深度聚类容易出现过拟合,导致聚类效果下降,降低了模型的泛化性能。因此引入样本扩充技术,减弱深度聚类算法对于样本量的需求了,对于深度聚类的实际应用至关重要。
另一方面,深度聚类算法计算复杂度较高,可以从两方面着手。首先可以采用模型压缩技术,减少模型的计算量。例如借助剪枝算法对冗余节点或通道进行切除[55],或者效仿DSSEC算法,通过对网络添加稀疏化的约束,抑制部分神经网络节点的激活,有效减少了计算量。其次,可以汲取轻量化模型的思想,譬如借鉴ELMAE算法,通过减少自编码器参数迭代的次数[56],减少了训练所需时间。此外,分布式的思想也可以用来降低模型的复杂度[57],或研究并行计算从而使现有的计算资源得到充分利用。这些方法都有助于轻量化深度聚类的模型,降低计算资源的要求,节省训练时间。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
数学小灵通·3-4年级(2021年5期)2021-07-16
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
铁道通信信号(2019年6期)2019-10-08
今日农业(2019年15期)2019-01-03
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
探测与控制学报(2015年4期)2015-12-15
