
限定域中文事件抽取研究综述
2022-09-21 05:37李华昱毕经纶
计算机工程与应用 2022年18期
李华昱,毕经纶,闫 阳
中国石油大学(华东)计算机科学与技术学院,山东 青岛266580
近年来,随着互联网技术的迅猛发展,互联网上的信息量正以指数级别的速度进行增长,其中很大一部分信息是以半结构化、非结构化的形式存在的,很难快速地从中获得有用的信息,因此自动化的信息抽取非常关键。信息抽取指的是利用计算机把文本、图像、视频等这些非结构化信息转化为结构化信息的过程,事件抽取是信息抽取领域的一个具有挑战性的任务。
事件抽取可分为限定域的事件抽取与开放域的事件抽取。其中限定域的事件抽取指的是在抽取之前,预先定义好目标事件的类别及每种事件类型包含的事件元素,因此针对某一特定领域,限定域的事件抽取更具有研究价值。
传统的事件抽取研究一般采用基于模式匹配的方法和基于机器学习的方法,前者需要领域专家设计模板,并且可移植性差,后者则涉及复杂的特征工程。随着深度学习理论技术的快速发展,基于深度学习的方法成为了现在的主流方法。本文重点对基于深度学习的方法进行介绍。基于深度学习的方法往往需要大量的训练语料,但是现在事件抽取的数据集往往面临训练数据缺乏的问题,因此本文对少样本条件下的事件抽取关键任务进行归纳总结。中文事件抽取因为中文的语言特性问题,面临较大挑战,因此需要针对中文语言特性进行深入研究。
1 任务定义与面临的挑战
1.1 事件抽取任务定义
事件是发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。根据ACE(automatic content extraction)的评测标准定义,事件是由触发词、事件类型、事件元素及元素角色四个部分组成的。因此事件抽取可以分解为以下四个子任务:触发词识别、事件类型分类、事件元素识别和元素角色分类。其中触发词识别,事件类型分类两个任务可以合并为事件检测任务,事件元素识别、元素角色分类两个任务可以合并为事件元素抽取任务。
本文用ACE术语介绍几个定义:
事件提及:描述事件的短语或者句子,包括触发词以及元素。
事件触发词:最能表达事件发生的词,一般为一个动词或者名词。
事件元素:事件的参与者,主要由实体、时间和值组成。
元素角色:指的是事件元素在某个事件中扮演的角色。
例如在图1中,检测到一个“竞赛行为-胜负”事件类型,其触发词为“打败”,事件元素为“中国女排”“荷兰女排”和“世界杯第九轮”。其元素角色分别为“胜者”“败者”和“赛事名称”。
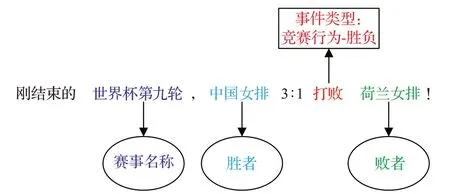
图1 事件抽取样例Fig.1 Event extraction example
1.2 中文事件抽取中面临的挑战
1.2.1 中文词语与触发词不符问题
中文有自己的语言特性。不像英文,在中文的一句话中,词与词之间没有明显的间隔符。如果只是简单的判断一个单词是否为触发词不够准确,如图2 所示,Zeng 等人[1]将分词错误而造成触发词不能正确识别总结为以下两种情况:
(1)触发词由多个词组成
一个触发词是由多个词语组成的。如图2句子(a)中,“比赛结束”这个事件的触发词应该是“落下帷幕”,而不是“落下”或者“帷幕”。
(2)触发词含于一个词
一个词语中包含了多个触发词,或者触发词为这个词语的一部分。如图2 句子(b)中,“射杀”这个词语中包含了两个事件的触发词“射”和“杀”,这两个触发词分别对应“射击”事件和“击杀”事件。图2 句子(c)中,词语“凶杀案”中包含了“谋杀”事件的触发词“凶杀”。

图2 中文词语与触发词不符样例Fig.2 Examples of inconsistency between Chinese words and trigger words
1.2.2 触发词歧义问题
中文事件检测除了在触发词识别阶段的错误,还有在触发词分类时错误的问题,因为中文词语的多义性,存在触发词不能被正确地分类到其所属类别的可能性。例如,这个灯泡报销了。这句话中的报销两个字在这个语境下指的是报废的意思,但是报销这个词汇还有报账的意思。所以鉴于以上问题,如何将触发词正确地从句子中抽取并正确地分类是中文事件抽取的难点。
1.2.3 中文触发词表达多样问题
中文中对于同一个事件类型,触发词的表达方式较多,很多训练集中出现的词语可能不会在测试集中出现。很多学者如Li 等人[2]针对这个问题提出利用中文形态语义组合学进行事件检测。
中文形态语义组合学指的是中文触发词的构成有一定的组成规律,汉语单词的意义在很大程度上取决于其组成字符的意义。并且大多数中文触发器都有一个中心字符来表示其事件类型。例如“受了伤”这个触发词是由一个动词(受)、一个副词(了)、一个名词(伤)组成的,并且“伤”这个中心字符能够表达出一个受伤事件。能够充分利用这些中文特性或许是提高中文事件抽取系统性能的关键。
1.2.4 中文句子元素缺失问题
中文的句子结构较为松散,表达方式较为灵活。很多时候会对句子的主语、宾语进行省略。这会造成事件元素在句子层面的缺失,很多时候需要从文档层面去补全事件元素。而且这种特性也意味着利用依存句法等特征在中文事件抽取的效果不如英文等语言明显。因此需要针对中文特性提取出更适合的特征。
1.2.5 元素重叠问题
Sheng等人[3]将元素重叠问题总结为三种情况:
(1)一个词汇在多个事件中担任触发词,如图3(1)所示,“收购”这个词语不仅是“投资”事件的触发词,而且是“股权转移”事件的触发词。
(2)一个元素在多个事件中充当不同的角色。如图3(1)所示,“世纪华通”这个元素不仅是“投资”事件的“主体”角色,还是“股份股权转移”事件的“股权收购者”角色。
(3)一个元素在一个事件中充当多个角色。如图3(2)所示,“富达实业”这个元素同时是“股权减少”事件中的“主体”角色和“股权减少者”角色。
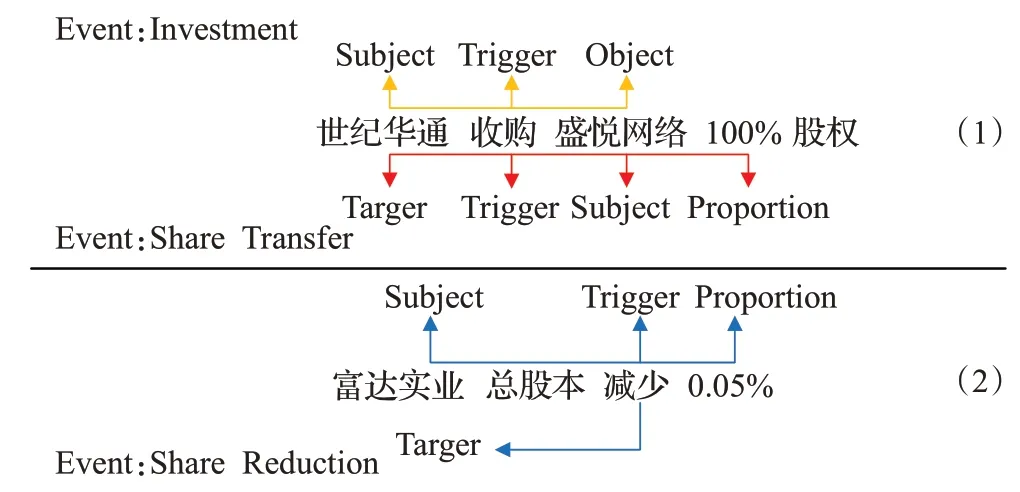
图3 元素重叠样例Fig.3 Element overlap example
2 主要研究方法
在早期,事件抽取主要通过模式匹配的方法进行抽取,这种方法能在特定领域下取得很好的效果,但是却需要专家来编写模板,并且泛化能力较差。基于机器学习的事件抽取方法将模型建立在统计学基础上,将事件抽取任务视作分类或者序列标注等方法,这种方法的关键在于根据数据的分布情况选择恰当的方法提取出合适的特征。
基于深度学习的事件抽取方法根据四个子任务是否联合建模可分为管道式抽取和联合抽取,管道式抽取先抽取触发词,然后根据抽取结果抽取事件元素,例如DMCNN[4]模型。这种方法对触发词的抽取要求较高,触发词的抽取结果直接影响到事件元素的抽取,容易造成错误传播,因此很多学者对联合抽取进行研究。联合抽取将四个子任务建模为一个联合学习框架,这种方法能利用触发词与元素之间的潜在关系,从而相互促进触发词和事件元素的两者之间的抽取效果,例如JRNN[5]模型,下面对这些方法进行详细介绍。
2.1 基于模式匹配的事件抽取
基于模式匹配的事件抽取方法指的是在模式的指导下进行事件抽取,主要分为两个步骤,模板的构建和事件抽取。最先,模板的设计是由领域专家手动设计的。第一个基于模式的抽取系统是1993 年Riloff 构建的用于恐怖事件的抽取系统AutoSlog[6]。AutoSlog依赖句法分析器和预定义的13种语言模式对人工标注的语料库进行模式提取,然后根据提取的模式对文本进行预测。此方法在特定语料库上取得了不错的效果,随后很多方法都借鉴了这种思想在很多领域取得成功。
但是这种方法需要专家消耗大量的精力来设计复杂的模板,而且模板构建的好坏直接影响抽取的结果。因此后续很多方法采用机器学习的方法自动设计模板,姜吉发在博士学位论文中提出了一种领域无关的模式自动学习方法GenPAM[7]。GenPAM 整个过程是在WordNet等外部知识库的支持下完成的,用户只需要对信息抽取任务进行定义,系统就能自动从未标注的语料中学习模式,这种方法很大程度上减轻了对人力的消耗。梁晗等人[8]提出了一种基于框架的事件抽取方法,利用框架的继承方法对某些框架的构建过程进行了简化,并完成了对灾难性事件的抽取。
总体来说,基于模式匹配的方法虽然在特定领域上表现较好,但是可移植性以及灵活性较差,而且模板的制作过程费时费力。所以现在对事件抽取的研究主要集中在基于机器学习的方法和基于深度学习的方法上。
2.2 基于机器学习的事件抽取
基于机器学习的方法将事件抽取任务转化为分类或者序列标注任务,其中两个关键步骤包括分类器的设计以及特征的提取。在特征的提取方面主要是依赖底层的NLP 技术,用NLP 工具从文本中提取语法级别特征、词汇级别特征、实体类型特征等特征,然后利用最大熵模型、隐马尔可夫模型、支持向量机等机器学习模型进行分类。
最早将机器学习方法引入事件抽取的是Chieu 等人[9],他们在事件抽取任务中引入了最大熵分类器,用于事件元素的分类,在讲座通告、人事事件管理两个数据集中取得了不错的效果。Ahn[10]用了两种机器学习算法实现了一个事件抽取系统,先后使用MegaM 算法和Tim bl算法实现对触发词的识别和事件分类,然后针对每个事件类型训练一个分类器抽取事件元素,这种方法在ACE 2005 数据集中取得了很高的F1 值。但是此方法判别触发词时对句子中的每个单词都进行判别,这样会引用大量的反例,使得正反例很不平衡。因此,赵妍妍[11]提出了一种自动扩展事件触发词的方法,使用《同义词词林》自动对训练集中的触发词进行扩展,根据触发词获取候选事件。然后结合底层特征通过最大熵分类器对触发词进行二元分类,对事件类型进行判别。这种方法减少了反例的个数。
Li等人[2]引用了中文的形态结构来更好地表示隐含在中文触发词内部的组合语义,并且提出了一个自动识别触发词中的支配义原的核心词素的机制。例如,信任和担任虽然有相同的BV(“任”),但是却有不同的含义。而出任和担任虽然词性不同,但是却指得是同一个事件。
因为中文词与词之间没有间隔符,因此Chen 等人[12]提出了一种基于字符级别的事件抽取。提取出词汇等特征使用隐马尔可夫模型以字符级别对触发词进行检测。侯立斌等人[13]在Chen等人[12]的基础上,使用了条件随机场(conditional random fields,CRF)解决了隐马尔可夫模型的标记偏置问题。
为了避免管道式抽取的错误传播问题,Chen等人[14]提出了一种联合抽取的方法,将事件抽取任务转化为两个联合抽取任务,并研究了很多从字符到篇章层面的特征,运用了丰富的语言学特征对中文进行事件抽取。李培峰等人[15]针对中文句法多省略的特点,提出了核心元素和辅助元素抽取方法,对触发词的抽取效果进一步提升。贺瑞芳等人[16]提出了一种基于CRF 的联合抽取模型,采用一种分类训练策略解决事件元素的多标签问题。并且针对ACE数据集中同一大类中某子类数据量较少的问题,采用多任务学习的方法对子类进行互增强的联合学习,解决了数据稀疏问题。
2.3 基于深度学习的事件抽取
2.3.1 句子级别事件抽取
(1)基于卷积神经网络的方法
传统的方法通常需要复杂的特征工程和现有的NLP工具,这样会造成错误传播,并且消耗大量的人力、缺乏通用性。因此人们开始用深度学习的方法[4,17-18]自动提取特征。Nguyen 等人[17]提出使用卷积神经网络(convolutional neural networks,CNN)进行事件检测,和传统方法相比不需要大量的外部资源,并且在跨域能力方面表现优异。Chen等人[4]认为CNN只能捕捉句子中最关键的信息,然而一个句子中可能含有多个事件,并且一个元素在不同事件中扮演不同的角色,因此提出了DMCNN 框架,在CNN 的基础上设计了一个动态多池层,提取一个句子的每个部分中的最关键的信息,对句子中的单词进行分类判别事件触发词,DMCNN结构图如图4所示。
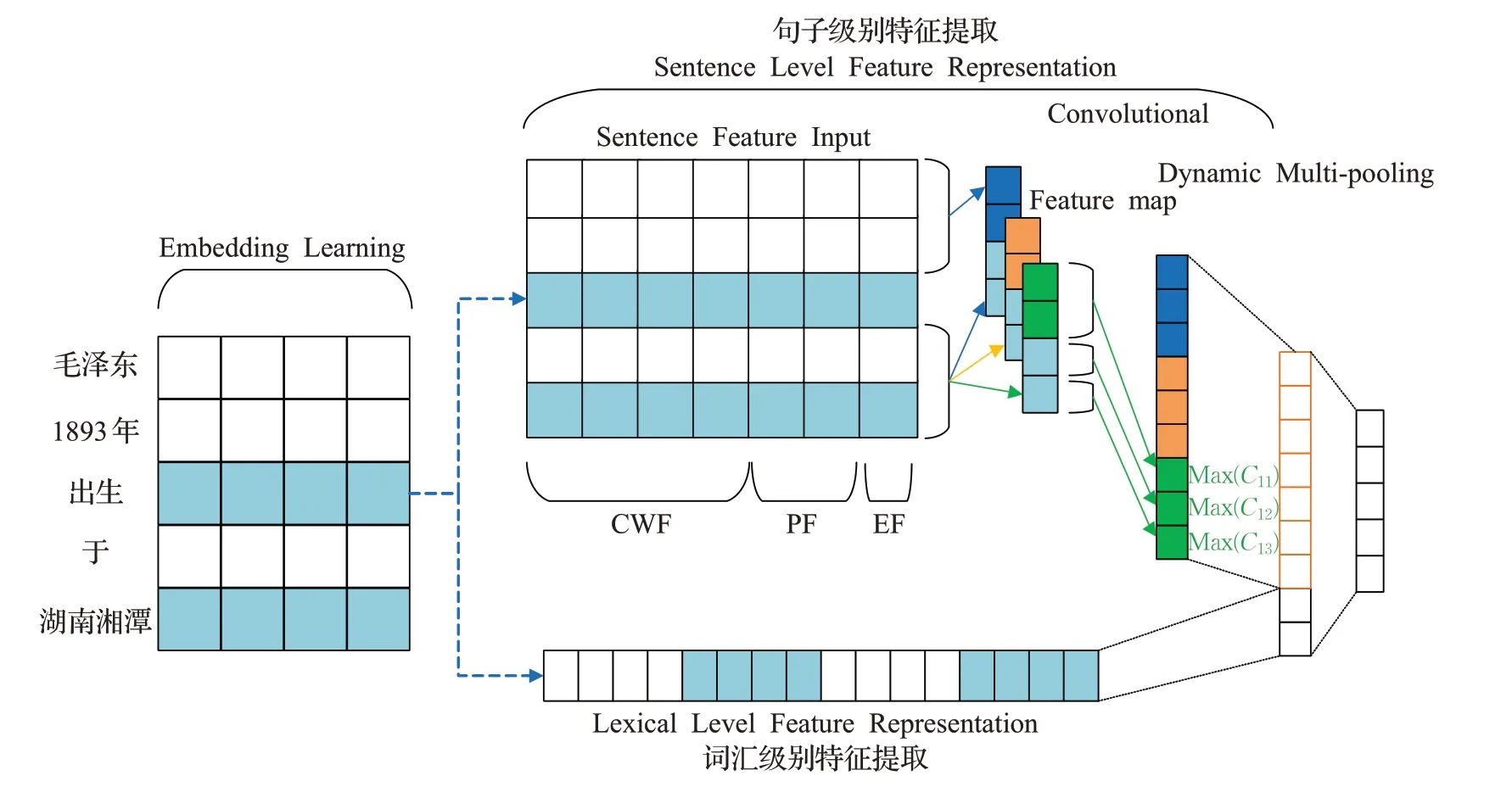
图4 DMCNN模型结构Fig.4 DMCNN model structure
上述方法在事件抽取任务中得到了较好的效果,但是如果单词和触发词不匹配的情况下,特别是在中文中,没有明显的单词分隔符的情况下效果较差。因此Zeng等人[1]将事件检测任务转化为序列标注任务,分别使用Bi-LSTM和CNN捕捉句子级别特征和词汇级别特征,并分别将文本处理成词汇级别和字符级别作为模型的输入,最后输出为BIO格式标注的序列。后面元素角色的判定将其视为触发词和元素配对后进行分类的任务。Lin 等人[18]针对中文触发词组成特点提出了NPNs模型,模型分为触发词识别与分类两个部分,以字符为检测级别,先把词汇级别特征融入到字符特征中,然后将触发词识别为以字符与上下文组成一定长度的块状结构,随后对提出的触发词进行分类。
(2)基于循环神经网络的方法
相比于CNN,循环神经网络(recurrent neural network,RNN)隐藏层之间的节点有连接,隐藏层的输入包含输入层的输出和上一时刻隐藏层的输出,能够更好地处理序列信息,因此RNN被广泛应用于各种NLP的任务中,下面介绍使用RNN[5,19-20]处理事件抽取的方法。
Nguyen等人[5]提出了联合抽取模型JRNN用于事件抽取,相较于pipeline 模型,Joint 模型能减少错误传播。JRNN 分为编码阶段和预测阶段,编码阶段使用双向RNN学习句子的特征表示,在预测阶段,引入记忆矩阵和记忆向量表示触发词类型和元素角色的依赖关系,同时预测事件类型和元素角色,这是第一个在神经网络方法中进行联合抽取的。
Sha等人[19]认为上述方法并没有充分利用句法信息和事件元素之间的关系,因此提出了DBRNN 框架,通过依赖桥把句法信息建模到单词中,在RNN 中同时使用了树结构和顺序结构增强单词的表示,并且设计了一个张量层来捕获事件元素之间的潜在关系。
在中文事件抽取中,针对触发词歧义问题,Ding 等人[21]提出了TLNN 框架用于事件检测,模型结构如图5所示。该模型引用了外部知识库HowNet获得了字符和词汇的多含义特征,然后使用树状LSTM融合三种特征对每个字符进行分类,此方法能够减轻触发词歧义问题。Xi 等人[22]则认为字符级别模型不能表达出触发词内部结构和句子层次的语义关系,因此通过字符级别表示、词汇级别表示、位置表示、语言模型表示四种特征增强中文语义特征表示。
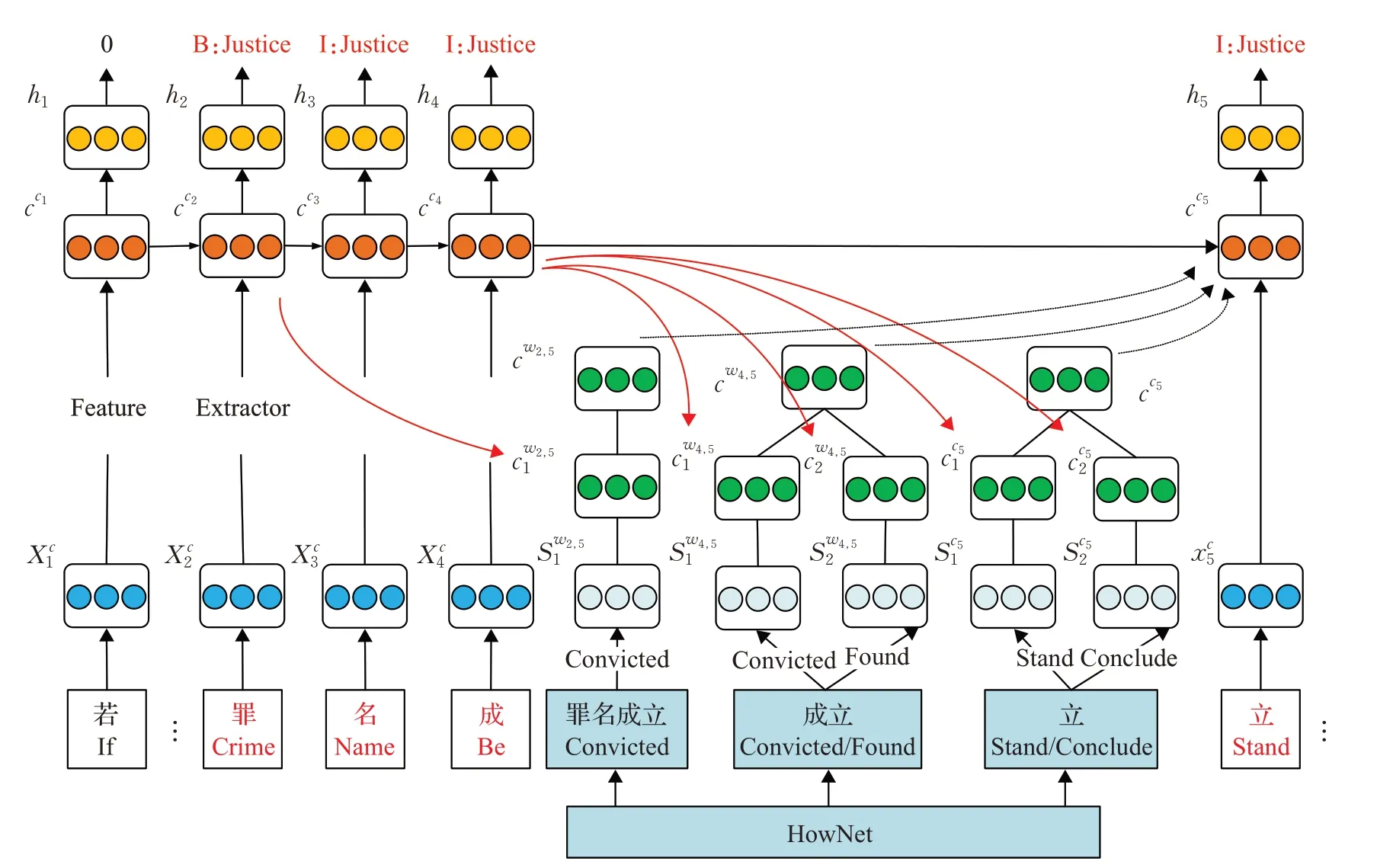
图5 TLNN模型结构Fig.5 TLNN model structure
(3)基于图神经网络的方法
前面很多方法把句子表示为顺序结构,然后通过CNN、RNN等模型对文本序列进行建模,但是这些方法不能很好地捕获具有长依赖距离的单词之间的关系,并且这些关系中很多关系如主谓关系能对事件检测等任务有着较大帮助,因此文献[23-24]利用依存句法树将句子表示为图结构,然后采用图卷积神经网络进行事件检测,这种方法加强了触发词与关键元素之间的联系,对触发词的识别与分类有较大帮助,并且这种方法能够缩短触发词之间的距离,加强了事件之间的信息交互,对多事件识别有很大提升。
但是这种方法随着层数的增加,相邻节点会变得越来越相似,因此为了保证节点的多样性,Yan等人[25]通过注意力机制显性地建模和聚合触发词的多阶句法特征,Lai等人[26]则利用了图和模型之间的一致性增强了候选触发词的特征表示,而且在每层网络引入门控机制过滤了与候选触发词无关的噪音信息。
上述方法没有考虑依存句法树中边的类型,因此Cui 等人[27]将句法树边类型信息引入到图结构中,根据上下文信息不断更新关系表示。Liu 等人[28]则认为文献[27]的方法会带来噪声,因此使用了自注意力机制深入挖掘节点之间潜在关系,并利用图残差网络解决图信息消失问题。
然而中文表达较灵活,经常会有主语或者宾语的省略,因此将句法特征在中文效果并不佳,所以Cui等人[29]利用图结构加强了单词与字符之间的信息交互,并利用事件标签中的语义信息加强触发器的识别,模型结构如图6所示。Wu等人[30]给出了中文字符与依存句法结果相结合的方式,并使用图注意力网络充分捕捉依存句法树中长依赖单词之间的关系。
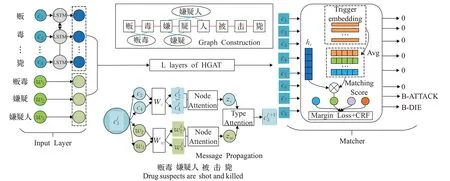
图6 L-HGAT模型结构Fig.6 L-HGAT model structure
(4)基于注意力机制的方法
注意力机制最先被提出用于计算机视觉,注意力机制的提出是为了使计算机模仿人类的认知功能,使计算机能够更加关注某些信息,现在广泛用于NLP的各个领域中。因此文献[31-33]将注意力机制引入事件抽取中,使模型关注更重要的信息。Liu等人[31]通过注意力机制把事件元素信息引入到事件检测中。使用一种监督学习方法来训练注意力向量,从而使得事件元素在句子中得到更多的权重。Zhang等人[32]认为实体关系和事件类型之间存在潜在关系,因此提出利用实体关系进行事件检测,使用注意力机制对单词分配不同的注意力来捕捉更关键的信息。Ding 等人[33]为了表达单词深层次的语义特征,使用语言模型对单词进行表示而不是词向量表,然后使用一种注意力机制把触发词和候选元素融入到句子特征中。
在中文事件抽取中,由于中文中没有分隔符,因此Wu等人[34]提出一种字符级别注意力机制用于中文事件抽取,把字符特征融合到词语特征中去,考虑到词语的含义与词语中各字符的含义并不一定相同,并且字符的含义与其在词语中的位置也有关系,因此需要考虑各个字符与词语之间的权重,然后对触发词和事件元素联合解码。字符与词语的向量拼接方式如图7所示。
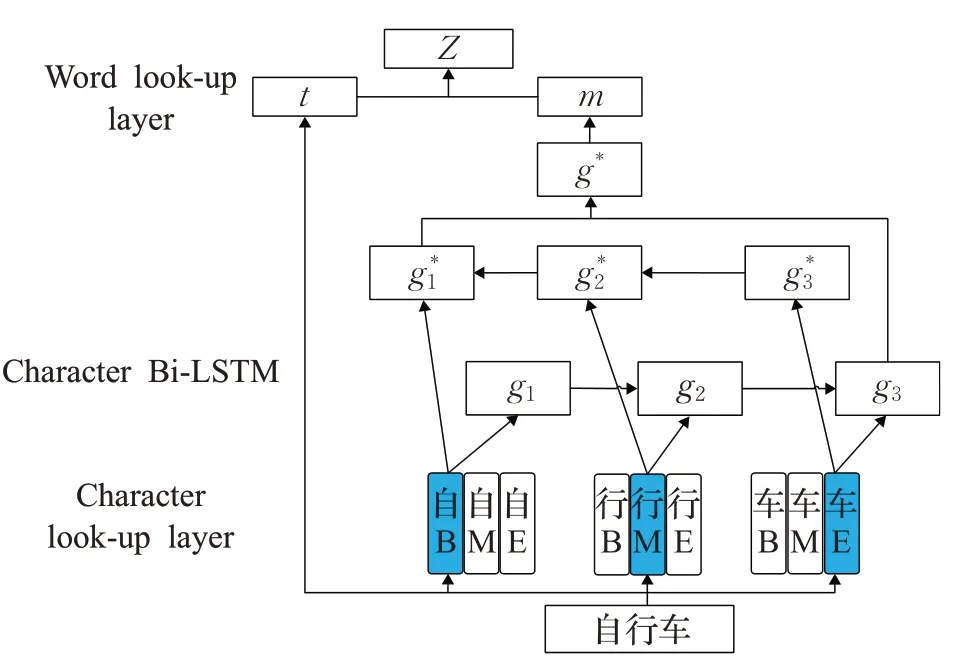
图7 字符向量与词向量结合方式Fig.7 Combination of character vector and word vector
(5)基于Transformer模型的方法
预训练模型可以根据单词的上下文动态地获得单词的语义,在文本分类、信息抽取等多个NLP任务取得了非常好的效果。因此很多学者使用预训练模型解决事件抽取任务。
Yang 等人[35]提出了PLMEE 框架用于事件抽取,首先为了解决训练数据不足的问题,利用预训练模型进行数据生成。然后为了解决元素重叠问题,在元素抽取时根据角色个数设计多组分类器,对每个元素角色分开抽取。最后根据元素角色在事件中的重要性重新加权损失函数。Xu等人[36]将预训练模型应用到中文事件抽取中,把事件抽取任务转化为抽取事件三元组(触发词,元素角色,元素)的任务,在文献[35]的基础上两阶段共享参数,设计多个二分类器中判别中触发词和元素的起始位置与终止位置,模型结构图如图8所示。
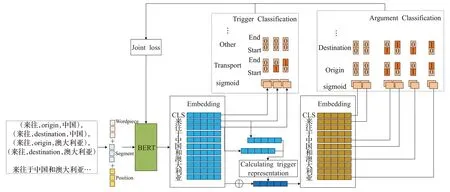
图8 JMCEE模型结构Fig.8 JMCEE model structure
上面的方法通常通过分类或者序列标注的方法进行抽取,这些方法依赖命名实体识别并且需要大量数据。因此文献[37-39]等将事件抽取任务转化为阅读理解任务。把事件中的每一个元素角色表述为相应自然语言描述的问题,通过BERT判断出答案片段的起始位置和终止位置,这种方法更好地利用了元素角色类别的先验信息。Zhou 等人[40]在阅读理解框架的基础上增加新的任务,借助于命名实体识别的结果,通过阅读理解的方法对候选元素进行角色分类,并通过两个过程的结果扩展训练集。
Li 等人[41]认为一个事件的事件元素之间存在着强关系,某个元素的角色的确定可以通过其他元素角色判别出来。因此设计了一个多轮对话引导的事件抽取系统,通过强化学习和增量学习建模事件元素之间的关系,使用已经提取的事件元素来提取难以提取的事件元素,并使用新获得的知识改善之前提取元素的决策,此方法在事件检测和元素抽取两个任务上均取得了较好的效果。
文献[42]将事件抽取任务转化为文本生成任务,将触发词、元素以及它们的标签统一作为自然语言生成,在数据标注方面只需要粗粒度的文本-事件记录,而不需要细粒度令牌级的标注,提出了一种约束解码算法,通过事件模式指导生成过程,并使用课程学习算法加强模型的训练过程。这种方法简化了数据标注过程,在一个模型中统一建模了多个任务,高效地以端到端的形式从文本提取事件。
基于深度学习的方法和基于机器学习的方法相比能自动提取高层次特征,避免了复杂的特征工程,近年来大多数事件抽取方法都基于深度学习,本文对这些方法进行了对比,如表1所示。
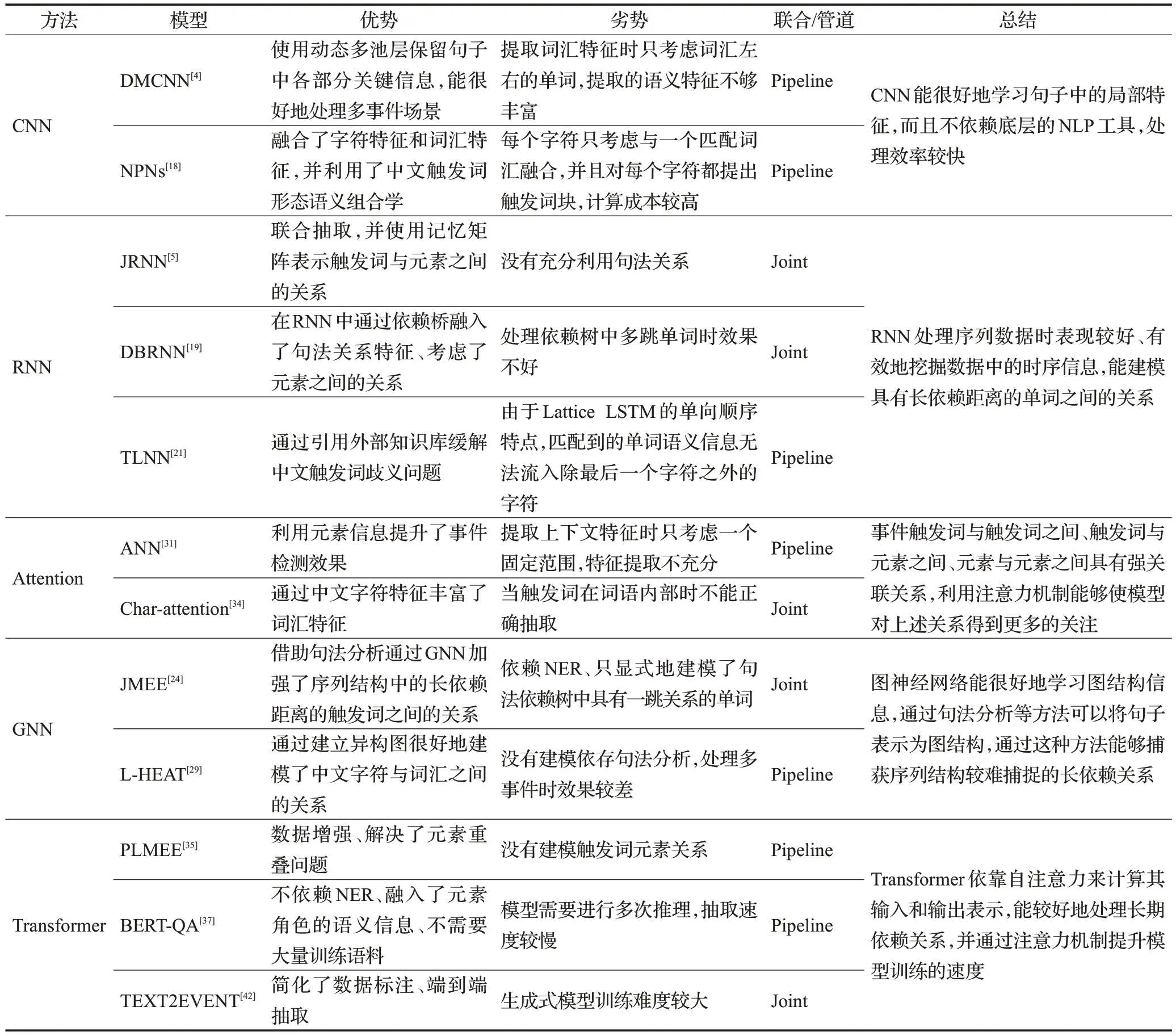
表1 基于深度学习的方法对比Table 1 Comparison of methods based on deep learning
2.3.2 文档级别事件抽取
相较于句子级别事件抽取,文档级别事件抽取任务中,一个事件的事件元素可能分散于一篇文档的多个句子中,因此需要对整篇文档的内容进行全面理解。而且一篇文档可能包含多个事件,这使文档级别事件抽取任务变得更加复杂。
现阶段中文文档级别事件抽取大多集中于金融领域,很多学者对大量金融通告进行了分析,提出了文档级别事件抽取方法。其中文献[43-45]仍在句子级别事件抽取的基础上,增加了一些全局策略,对事件元素进行补全,从而得到篇章级的事件信息。但是这些方法仅在句子范围内对元素角色进行判定,没有考虑到全局上下文信息,忽略了跨句子的事件元素之间的信息交互。
因此,后续的很多方法[46-49]从全局角度出发,对候选元素和句子进行联合建模,并且放弃了句子级别中的对触发词的抽取,从全局的角度检测事件,进而对事件元素进行分类。Zheng等人[47]先通过篇章层面特征获取事件类型,然后定义好元素角色的识别顺序,把元素角色识别任务转化为多个路径扩展的子任务。但是这种顺序识别的方法,前序角色的识别没有考虑后序角色的识别结果,因此文献[48]使用了一种多粒度解码器并行地对元素角色进行判定。
文献[49-50]则将文档建模为图形结构,这种方法能够加强事件之间的关系。Xu等人[49]通过了图结构加强了候选元素和句子之间的信息交互,促进了相似事件之间的元素角色判定。Huang等人[50]通过实体共现关系把句子建模为图结构,并使用图注意力网络加强了句子之间的关系,将事件表示为其中的子图。
2.4 少样本场景下的事件抽取
上述方法大多遵循监督学习范式,这需要大量的标记数据,如果只是基于少量的标记数据,上述方法表现欠佳,因此很多学者[51-53]研究了少样本事件抽取的一些方法,通过引入外部资源或者多任务学习等方法提高事件抽取的效果,本节对这些方法进行介绍。
2.4.1 训练语料的补充
现有的研究大多基于ACE2005 数据集,数据集规模小、类型分布不均,因此模型训练效果较差。所以,很多学者[51-53]提出利用外部资源库对训练语料进行补充。Liu等人[51]提出了利用FrameNet框架补充训练语料。文中认为FrameNet中定义的框架与ACE定义的事件在结构上非常相似,框架中的词汇单元类似事件中的触发词,框架中的元素类似于事件中的元素。因此,文中通过将FrameNet中的框架映射为事件从而补充了训练语料。
Chen 等人[52]提出利用远程监督的方法对训练语料进行自动标注。文中首先利用Freebase 挑选出每个事件类型的关键元素,然后通过关键元素标记出事件并找出触发词,然后利用FrameNet 过滤噪声触发词并对触发词进行扩展。最后通过一种软远程监督的方法自动标注训练语料。Wang等人[53]使用生成对抗网络进一步提升了生成数据集的质量,首先将候选集分为可靠集和不可靠集,然后把可靠集做为正例,将生成器选择的数据做为负例,同时对判别器和生成器进行训练,使生成器选择容易混淆的实例来“欺骗”判别器。
BERT 等模型在大量语料库上进行预训练,能更好地捕捉上下文信息,因此Yang等人[35]通过预训练模型生成标注样本补充训练语料,通过编辑原型的方法生成训练语料。首先使用masked语言模型任务在ACE2005数据集上进行微调。然后将原型中的元素替换为与其扮演相同角色的相似元素,并通过微调后的BERT 重写adjunct tokens。最后对这种方法生成后的事件进行打分,保证生成事件的高质量。
2.4.2 基于少样本学习的事件抽取
前面的方法[4-5,24]大多在监督学习下进行事件抽取的,但是这种方法却需要大量标注语料,不能快速理解新事件类型,因此文献[54-56]等探究了低资源条件下的事件抽取,包括零样本学习与少样本学习。
文献[54-56]使用了零样本学习的方法用于事件抽取。Huang 等人[54]先使用AMR 解析工具识别触发词和元素,然后将事件本体和事件提及映射到一个语义空间,将事件分类为空间中最接近的事件类型。这种方法能够通过现有事件类型的手动注释数据,来预测无标注数据的新事件类型,并且这种方法抽取性能可以和很多监督方法相媲美。
Deng等人[55]在文献[54]的基础上扩展了事件本体,把事件之间的联系建模到本体中,可以通过建立新事件类型与现有事件类型之间的关联,学习到新的事件类型。Zhang等人[56]将标签语义信息引入到零样本事件抽取中,通过预训练模型计算触发词和元素与其相应标签的语义相似度,从而实现触发词与元素的分类。
少样本学习中往往会采用C-wayK-shot 的数据采样方法,当K的值较小的情况下,可能会出现样本偏差问题。因此Deng等人[57]提出了一个基于动态记忆的原型网络,多次从事件提及中提取上下文信息,从而能在样本较小的情况下更好地学习事件原型的上下文表示。Lai等人[58]则通过建模跨任务之间的关系来减轻样本中异常值的影响。文献[59]考虑了支持集样本之间的关系,进一步提升了抽取效果。
因为考虑到不同事件的触发词差异较大,Cong 等人[60]将触发词识别与分类合并成一个序列标注任务,首先提出了PA-CRF来模拟少样本场景下的标签依赖性,并引入高斯分布缓解了因数据不足而造成的不确定性估计问题。
2.4.3 基于多任务学习的事件抽取
很多事件抽取的方法往往依赖于实体识别,但是大部分方法均将实体当作已知条件,这样不符合一般应用场景,并且如果对多个子任务单独抽取会造成错误传播。因此文献[61-64]使用了全局特征对实体识别、事件抽取等多个子任务联合建模,Nguyen 等人[61]通过双向RNN共享特征表示,对实体识别、事件检测和元素识别三个任务联合预测,通过三个子任务隐藏关系提高事件抽取性能。
文献[62-63]则提出了一种基于全局跨度的方法,将触发词与实体表示为图结构中的节点,将触发词与实体、实体与实体之间的关系表示为边,对实体识别、关系抽取、事件抽取和共指消解四个任务联合建模,根据它们的监督信号通过图传播来捕获全局上下文信息,不断更新跨度表示。Lin等人[64]则认为上述方法对多个子任务使用独立的分类器,没有显式建模了多个子任务之间和实例之间的关系,因此在解码阶段,使用全局信息捕获子任务之间和实例之间的关系,并通过束搜索找到全局最优图。
2.4.4 利用文档层面的事件抽取
大多数事件检测方法只利用了句子层面的信息,但是很多时候句子层面的信息不够丰富,只考虑句子层面的信息不足以推断出事件类型,因此文献[65-67]使用了文档层面信息建模语义信息。这种方法能够考虑文档中事件之间的关系,对消除事件的歧义性有很大帮助。
文献[65-66]通过注意力机制将文档信息融入到句子特征中,但是这种方法不能很好地模拟句子之间的关系,因此Lou 等人[67]通过堆叠多个双向解码器的方式,在句子之间迭代地传播信息。文献[68]为了更好地捕获长距离文档级上下文信息,因此动态地从文档中只选择与目标句子最相关的上下文句子,输入到BERT进行事件检测,这样也解决了BERT输入限制问题。
2.4.5 跨语言事件抽取
由于数据的注释成本较高,很多学者[69-71]提出利用多语言资源来提高事件抽取系统的性能。跨语言方法将多种源语言的知识迁移到目标语言中,以提高事件抽取的抽取性能。His等人[69]提出在多种语言的语料库上进行训练,并通过依赖于语言的特征和不依赖于语言的特征使性能得到提升。Liu等人[70]为了缓解单语中触发词的歧义性,使用了一种门控多语言注意力机制对两种语言的特征进行融合。
很多跨语言方法都依赖机器翻译系统或者通过人工来对齐文档,这需要大量的并行资源,然而现实中可能没有这么多的并行资源。因此Liu等人[71]提出了一种基于最少并行资源的跨语言事件检测方法,针对不同语言的词汇映射问题,提出了一种上下文相关的翻译方法,然后针对不同语言的语序差异问题,提出了一种多语言协同训练的共享句法顺序事件检测器。
Subburathinam 等人[72]和Ahmad 等人[73]将图神经网络应用到跨语言方法中,Subburathinam等人[72]利用语言无关特征,将实体提及、触发词以及上下文表示到一个多语言空间中,然后从资源丰富的源语言训练一个抽取器,将其应用到在资源匮乏的目标语言中去,此方法在多种语言数据集上取得了良好的效果。Ahmad 等人[73]则为了更好地建模长依赖距离关系的单词,引入了自我注意机制,明确地融合结构信息来学习不同句法距离的词与词之间的依赖关系。
前面方法大多只在单语中进行训练,这可能导致单语偏见问题,因此文献[74]利用了无标注的目标语言数据,通过类的语义特征和语言无关特征,更好地跨语言迁移知识。
2.5 领域事件抽取
金融领域、法律领域等具有大量复杂的非结构化信息,这些信息中包含很多有价值的内容,事件抽取可以帮助人们快速地对这些内容进行分析,得到规范化的信息,领域事件抽取方法如表2所示。
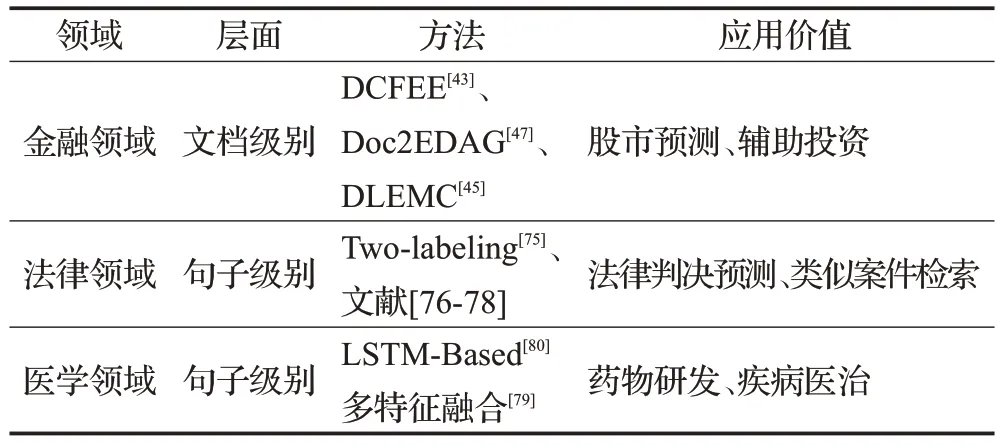
表2 领域事件抽取总结Table 2 Domain event extraction summary
Yang 等人[43]、Zheng 等人[47]对大量金融公告深入研究,给出了金融领域的文档级别事件抽取方法,能帮助金融人员预测股市并做出正确的投资。
为了使法官更方便快捷地了解案情,Li等人[75]提出了法律领域的事件抽取方法,多个事件共享事件元素这一现象,作者定义了焦点事件这一机制,先抽取出预定义的12 个transition label,然后第二步再抽取出事件元素角色。文献[76]在Li等人[75]的基础上,增加了时间线机制,将提取的事件以时间序列的形式显示。Shen 等人[77]为了区分相似法律事件,为事件检测设置了分层的事件特征,并为了解决事件元素共指消解问题,提出了一种踏板注意机制。Feng 等人[78]提出使用事件抽取完成法律判决预测任务,先提出了一种层次化的事件结构,然后通过两种约束联合学习事件抽取与法律判决预测两个任务。
生物医学文本中含有大量事件信息,对生物医学研究对药物研发和疾病医治有很大帮助。Wang等人[79]提出了一种生物医学领域的多特征融合的事件抽取方法,在特征提取方面结合依存句法分析结果获得词汇丰富的语义表示信息,并利用词性特征补充句子结构信息。Yu 等人[80]提出了一个基于LSTM 的端到端框架用于生物医学事件抽取,通过依存句法分析使用Tree-LSTM完成了元素抽取,为了减少级联错误,使用了一个整体的损失函数对模型进行训练。此方法在BioNLP09等数据集取得了很高的F1值。
3 数据集
对中文事件抽取常用的数据集进行介绍,包括句子级别数据集和文档级别数据集,句子级别数据集指的是某个事件的元素仅在一个句子的范围内出现,而文档级别数据集指的是某个事件的元素分散于一篇文档的多个句子中,并且一个文档中可能包含多个事件,而且这些事件之间往往存在着因果、转折等关联关系。数据集规模如表3所示。
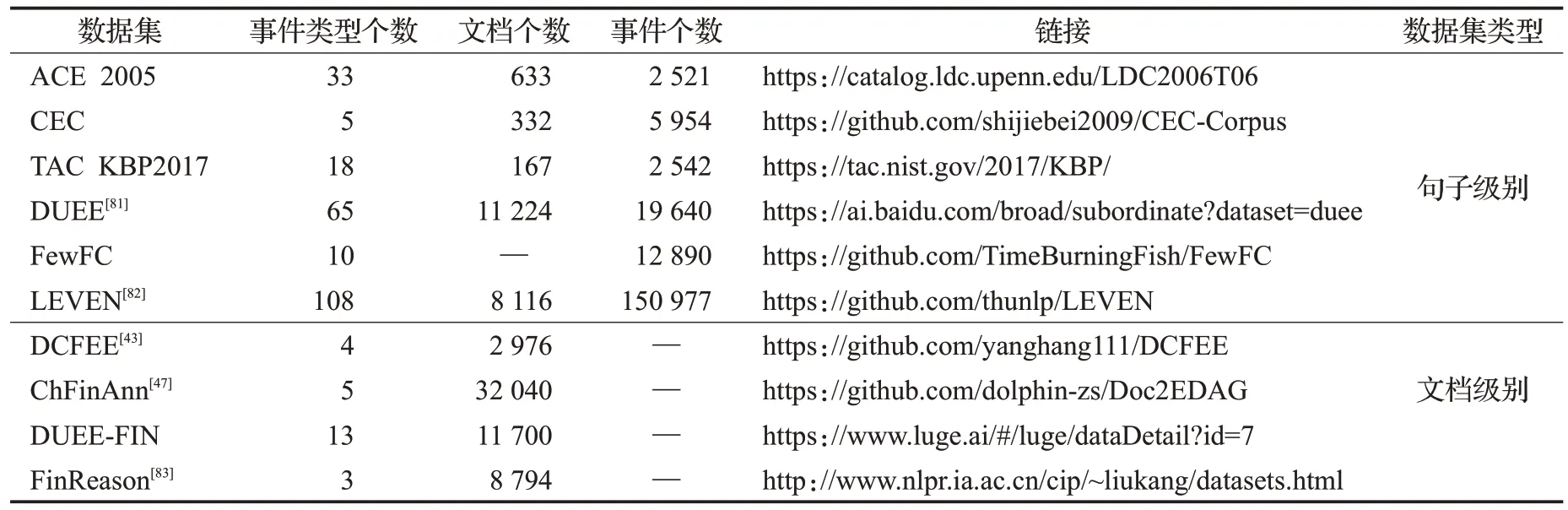
表3 中文事件抽取数据集统计Table 3 Chinese event extraction data set statistics
3.1 句子级别数据集
ACE2005 数据集:ACE 2005 数据集是语言数据联盟(LDC)发布的包含汉语、英语和阿拉伯语三种语言的数据集,被用于2005 年自动内容提取(ACE)的评测。数据集由实体、关系和事件等多种数据类型组成,包含了8 大类事件类型和33 小类事件类型,共计633 篇文档。ACE 数据集是事件抽取领域最具影响力的基准数据集。
上海大学CEC 数据集:CEC 数据集是由上海大学语义智能实验室创建的中文突发事件数据集。实验室从互联网上收集了5种突发事件(地震、火灾等)的新闻报道生成数据集,共计332篇文档。CEC数据集的规模与ACE等数据集相比较小,但是事件要素的标注较为全面。
Text analysis conference knowledge base filling(TAC KBP)数据集:TAC KBP事件跟踪的目标是提取有关事件的信息,并以合适的结构输入到知识库中。TAC KBP事件评测的任务包括检测和链接事件的事件块任务、提取事件参数和链接属于同一事件参数的事件参数任务。其中TAC KBP 2016 和TAC KBP 2017 的数据集中包含了汉语、英语和西班牙语三种语言,共有8种事件类型和18种子事件类型。
DUEE[81]数据集:DuEE 数据来源于百家号,其事件类型涵盖了百度搜索中的很多热门话题。DuEE 具有19 640 个事件,包含65 种事件类型,是迄今为止最大的中文事件抽取数据集,被用于2020 语言与智能技术竞赛的事件抽取任务的评测。DUEE 的抽取场景更有挑战性,一个句子可能包含多个事件,并且存在事件元素重叠问题。
FewFC数据集:FewFC数据来源于真实的金融新闻数据,由金融专业人员标注,被用于CCKS 2020金融领域跨类迁移事件抽取评测任务。FewFC 是一个包含质押事件、股份股权转让事件、投资事件等10个事件类别的小样本金融领域数据集。
LEVEN:LEVEN[82]是一个大规模的中文法律领域事件检测数据集。该数据集事件本体涵盖较全面,涉及法律案例中的常见事件如逃逸事件,对法律案例分析有较大帮助。该数据集包含8 116篇法律文档,108个事件类型,超过15万个事件实例。
3.2 文档级别数据集
DCFEE:DCFEE[43]是金融领域的文档级别数据集,其数据来源于搜狐证券网上企业发布的公告,并通过远程监督的方法对数据进行标注的,包含股权冻结事件、股权质押事件、股权回购事件和股权增持事件四种类型,共计2 976个公告。
ChFinAnn:ChFinAnn[47]数据集是实验人员搜集了近10年的金融公告并通过远程监督的方法生成的金融领域数据集。ChFinAnn 包括32 040 份文件,由股权冻结、股权回购、股权减持、股权增持和股权质押5个事件类型组成,其中超30%的文档中包含多个事件。
DUEE-FIN:Duee-Fin 是百度发布的金融领域文档级别数据集,由1.17 万个文档组成,包含13 个事件类型,同时存在一部分非目标文档作为负样本,数据来源于真实金融领域的公告和新闻。被用于2021语言与智能技术竞赛的文档级别事件抽取的评估。
FinReason:文献[83]提出了一个金融领域的用于事件因果关系抽取的数据集FinReason。此数据集总共包含8 794 个文档,由12 861 个金融事件和11 006 个原因片段。数据集包含了多事件、多重原因和隐含原因等多个复杂场景。
4 评价指标与各方法对比
4.1 评价指标
事件抽取常用的指标有精准率、召回率、F1值。事件抽取的四个子任务分别为:
(1)触发词识别:识别出句子中的触发词片段,如果预测的触发词片段与标注中的触发词片段一样,则认为抽取正确。
(2)事件类型分类:对识别后的触发词进行分类,如果与标注中的事件类型一样,则认为是分类正确。
(3)事件元素识别:在获得事件类型后,识别出句子中的事件元素,如果预测的事件元素片段与标注中的事件元素片段一样,则认为抽取正确。
(4)事件元素分类:对抽取后的事件元素进行分类,如果识别的事件元素类型与标注中的类型一样,则认为分类正确。
研究选择使用标准精确度(Precision,P)、召回率(Recall,R)和F测度(F1)作为评价指标来评估结果。计算公式分别如下所示:

其中,TP表示为被模型预测为正类的正样本个数、FP表示为被模型预测为正类的负样本个数、FN表示被模型预测为负类的正样本个数。
除此之外,由于中文识别最小单位为字符,在2020年百度举办的语言与智能技术竞赛的事件抽取任务[74]中,还使用了字级别的评测方法对事件元素的抽取结果进行评价:
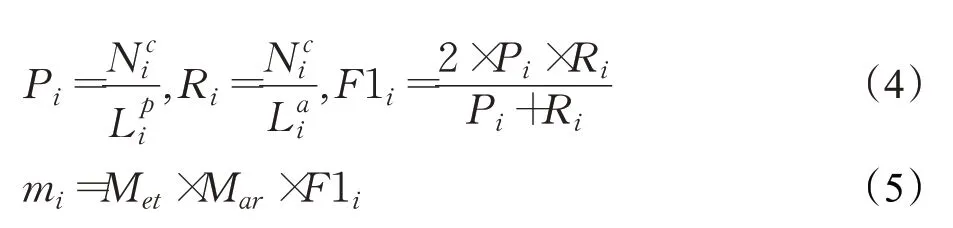
字级别匹配P值:预测出的元素和人工标注的元素共有字的数量/预测元素字数。如式(4)所示,表示第i个预测的元素与对应标注的元素共有的字数,表示标注元素的字数。
字级别匹配R值:预测出的元素和人工标注的元素共有字的数量/人工标注的元素的字数,表示预测元素的字数。
字级别匹配F1值:2×字级别匹配P值×字级别匹配R值/(字级别匹配P值+字级别匹配R值)
预测元素得分=事件类型是否准确×元素角色是否准确×字级别匹配F1 值。如式(5)所示,Met和Mar分别表示事件类型和元素角色是否正确。
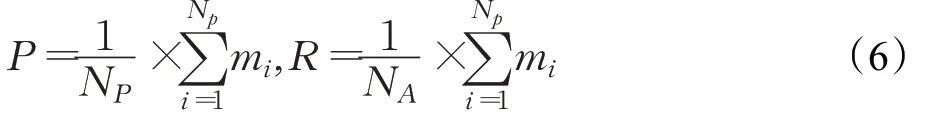
P=预测元素得分总和/所有预测元素的数量。NP表示预测元素个数。
R=预测元素得分总和/所有人工标注元素的数量。NA表示所有定义元素角色个数。

4.2 各方法对比
本节主要总结事件抽取模型优缺点,比较其在基准数据集上的性能,评价指标主要有精确率、召回率和F测度。
4.2.1 事件检测结果对比
目前大多数中文事件抽取的研究集中在事件检测任务上,本文选取ACE 2005 中文数据集与TAC KBP 2017 两个基准数据集进行事件检测效果对比,如表4所示。
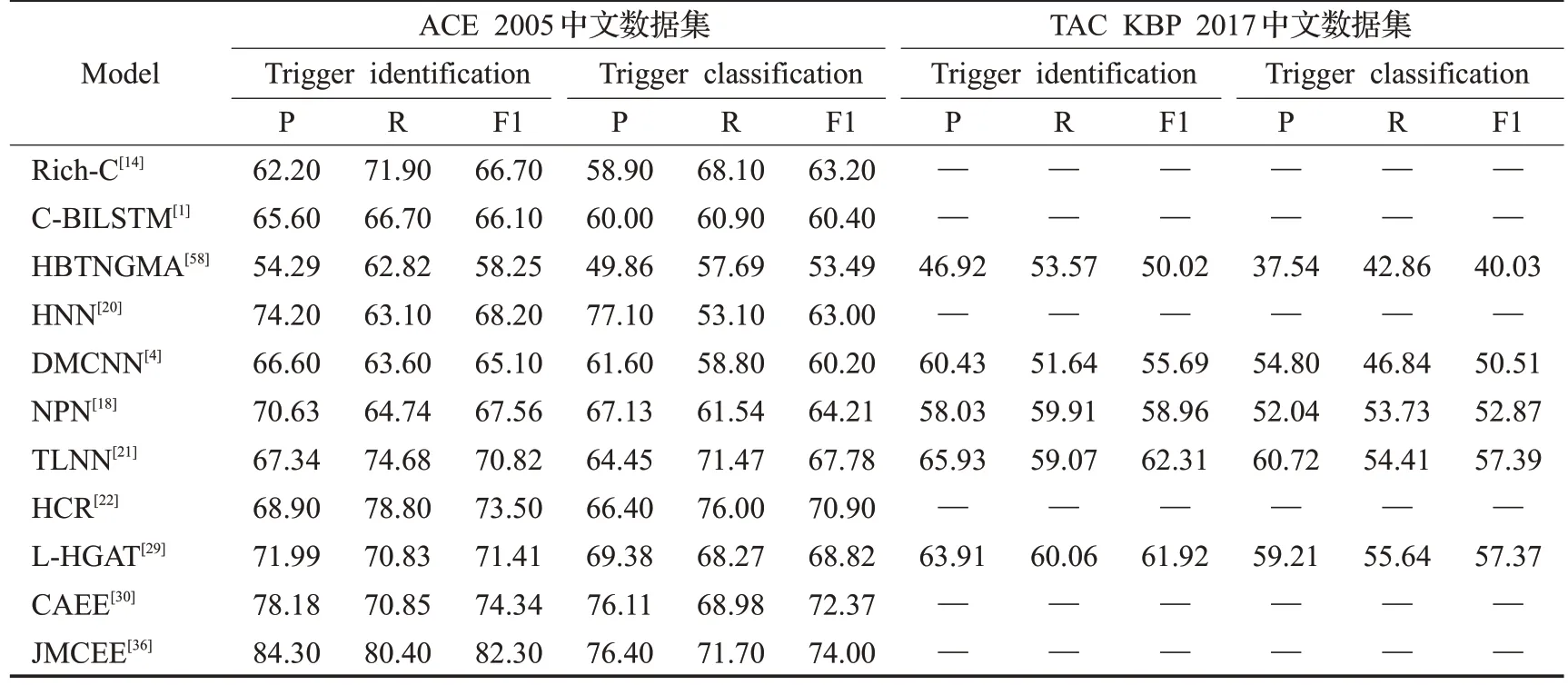
表4 事件检测方法的精确率、召回率、F1值对比Table 4 Comparison of accuracy,recall and F1 value of event detection methods %
从结果上可以看出,基于传统机器学习的方法Rich-C[14]在事件分类任务上有着较高的F1值,能与很多深度学习方法相媲美,但是这种方法需要人工提取特征。由于基于深度学习的方法能自动提取高层特征,近几年的方法[18,21,29]要明显优于基于机器学习[14]的方法。
NPN[18]、TLNN[21]和L-HGAT[29]等方法在两个数据集中均表现较好,证明了其方法的鲁棒性。BERT 等预训练模型在庞大的语料库进行预训练,能够更好地捕捉全局信息,因此在所有深度学习的方法中,基于BERT 的方法效果最好。JMCEE[36]和CAEE[30]在一个统一的框架下联合训练,对事件抽取两阶段任务进行联合抽取,避免了错误传播,在抽取的效果上要优于pipeline的方法。
4.2.2 元素抽取结果对比
目前对中文事件元素抽取的研究大多基于ACE 2005中文数据集,本文选取ACE 2005中文数据集作为元素抽取的基准数据集,事件元素抽取结果如表5 所示,从结果可以看出,中文事件元素识别和分类的F1值并不高,还有很大的提升空间。基于深度学习的方法明显优于机器学习的方法,基于联合抽取的方法避免了管道模型方法的错误传播问题,效果要优于管道模型方法。
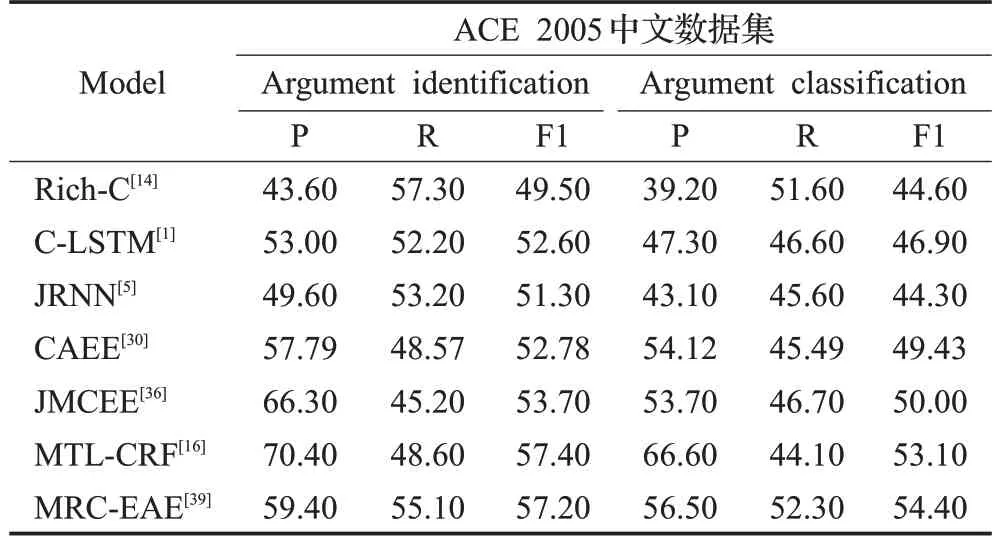
表5 元素角色识别方法的精确率、召回率、F1值对比Table 5 Comparison of accuracy,recall and F1 value of element role recognition methods %
其中MTL-CRF[16]并没有使用深度学习模型,使用了一种基于CRF的多任务学习框架有效挖掘了元素之间的相互关系,在元素的识别和分类上均有较高的精准度。MRC-EAE[39]方法将任务转化为机器阅读理解的任务,在模型中编码了元素角色信息,在召回率和F1值上有着明显提升。
4.2.3 文档级别抽取结果对比
本文选取F1 值作为评价指标,并把ChFinAnn[47]作为文档级别事件抽取方法的评价数据集,此数据集包含股权冻结(EF)、股权回购(ER)、股权减持(EU)、股权增持(EO)和股权质押(EP)五种数据类型。各方法的F1值对比如表6所示。
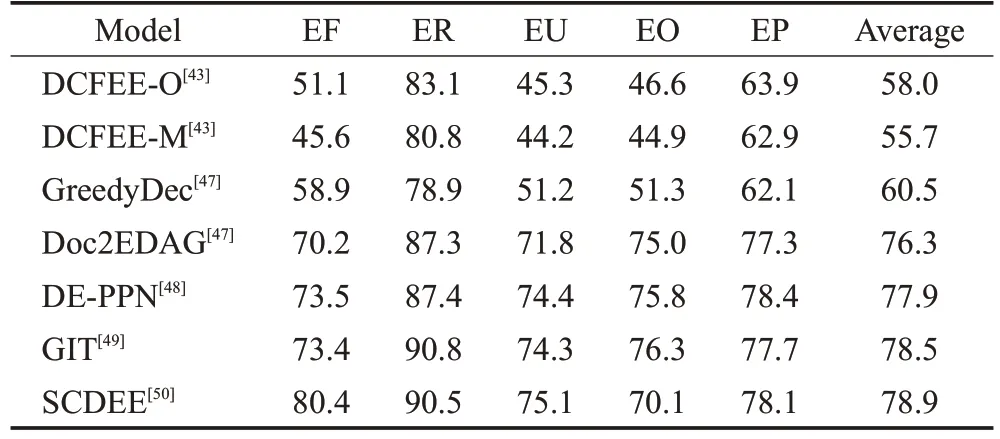
表6 文档级别事件抽取方法F1值对比Table 6 Comparison of F1 values of document level event extraction methods %
DCFEE-O 和DCFEE-M 是DCFEE[43]的两个版本,DCFEE-O只从文档中抽取一个事件,DCFEE-M能抽取多个事件。GreedyDec 是Doc2EDAG[47]的简化版,只贪婪地从文档中抽取单个事件记录。
从结果中可以得出,由于DCFEE[43]对全局信息理解不够充分,因此F1 值要明显低于后面对全局进行建模[47-50]的方法。GIT[49]和SCDEE[50]使用了图神经网络对事件关系进行建模,对文档有着更充分的理解,有着较高的F1值,并在股权回购事件类型上效果最好,明显高于其他方法。
5 未来展望
(1)中文特性挖掘
近年来,对中文事件抽取的研究大多集中在事件检测上,由于中文词语之间没有分隔符并且触发词表达方式较多,因此中文事件检测难度较大。因此需要挖掘如中文触发词组成特点等中文语言特性,与深度学习模型相结合提取出更适合中文的语义特征应用到事件抽取中。
(2)文档级事件抽取
中文是一种篇章驱动的语言,中文语法多省略,某个事件的元素往往需要从篇章层面补全或者共指消解,而且文档级事件抽取更符合现实生活中的应用场景,因此对中文文档级事件抽取有较深的研究意义,如何对文档内事件关系进行建模是对文档整体理解的关键。
(3)零样本事件抽取
现有的事件抽取方法大多需要大量的训练语料,但是无法快速地应对新事件类型,零样本事件抽取方法能快速理解新事件类型,研究价值较大,如何正确地建立事件本体与事件实例的关系从而提升抽取效果值得深入研究。
(4)基于问答的事件抽取
近几年,很多学者使用基于问答的方法进行事件抽取,这种方法能利用元素角色的语义信息,在样本较少的情况下表现较好。问题的设计的好坏及问题与文本特征融合的方式等都会对结果有所影响,需要进一步讨论。
(5)面向开放域的事件抽取
现在很多深度学习的方法都基于限定域的事件抽取,事件本体是预定义的情况下。但是面对新领域,事件类型未知的情况下,开放域的事件抽取能快速帮助人们理解新事件。
(6)面向领域的事件抽取研究
日常生活中人们常常需要对某一领域进行研究,但是领域中有很多专业术语,如何设计更有效的方法,来提取领域文本的深层语义信息和上下文信息[84],使深度学习模型深入理解领域知识很关键。因此需要针对特定领域展开深度研究。
6 结论
本文全面介绍了中文事件抽取的研究现状,对基于模式匹配、基于机器学习、基于深度学习的方法进行归纳总结,其中基于深度学习的方法能自动提取特征,成为了现在的主流方法,因此本文详细介绍了基于深度学习的事件抽取方法。由于中文特性问题,本文对中文事件抽取中面临的挑战进行了总结,并对监督学习方法中样本缺失的条件下,少样本事件抽取方法进行总结,然后介绍了中文事件抽取相关数据集,最后对未来的发展趋势进行了分析和展望。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
当代水产(2019年11期)2019-12-23
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
汽车导报(2017年5期)2017-08-03
电脑爱好者(2017年7期)2017-05-06
