
视觉可供性研究综述
2022-09-21 05:37李云龙卿粼波韩龙玫王昱晨
计算机工程与应用 2022年18期
李云龙,卿粼波,韩龙玫,王昱晨
1.四川大学 电子信息学院,成都610065
2.成都市规划设计研究院,成都610041
可供性这一概念由生态心理学家Gibson在1966年[1]首次提出,他在1979 年[2]将可供性定义为“The affordances of the environment are what it offers the animal,what it provides or furnishes,either for good or ill.The word affordance implies the complementarity of the animal and the environment.”即环境的可供性描述其可为动物行为活动提供的或正向或负向的支持,反映动物与环境之间的互补性。Norman[3]将可供性进一步解释为“决定如何使用该事物的基本属性”,其认为可供性为暗示事物的相关操作提供了充分的线索。比如,旋钮可以旋拧,按钮可以按下以及球可以投掷或拍打等。
可供性理论一经提出即受到了广泛关注,相继被引入环境心理学[4-5]、城市规划[6]等相关领域,开展结合可供性基础理论的研究。近年来,随着视觉数据逐渐增加,利用计算机视觉直观地研究可供性渐成趋势。Gibson认为计算机视觉中应该注重物与人的交互,而不是单纯地对物体进行识别。基于此,大量学者和机构开始关注物体与个人的交互,利用计算机视觉领域的技术识别物体的视觉可供性。视觉可供性一方面可以推进机器人领域的发展,促进机器人实现自我控制并完成与人或目标之间的进一步交互。另一方面,对计算机视觉领域而言,视觉可供性的引入可以打破传统物体检测任务中的桎梏,利用物体的属性进一步挖掘其潜在的各类可供性,为物体提供新的使用思路与应用场景。
早期的视觉可供性研究基于传统的机器学习算法,而随着深度学习的发展,卷积神经网络[7](convolutional neural networks,CNN)、条件随机场[8](conditional random field,CRF)等各类神经网络在视觉可供性研究中得到越来越多的应用。伴随传统机器学习的不断改进和深度学习的不断深入,能够识别的范围也从简单的目标识别扩展到对于行为以及物体之间关系的识别研究,在识别的精度上也有大幅的提升。
1 视觉可供性概述
视觉可供性的分类方式很多,本文与目前已有的综述[9-12]不同的是首次对于可供性不同分类进行定义,并分别总结检测方法。本文根据识别方法的不同,将可供性分为功能可供性、行为可供性、社交可供性三大类:
(1)功能可供性是基于物体自身性质判断的可供性。例如利用物体的外形材质判断。
(2)行为可供性是基于物体的使用方法判断的可供性。例如利用人或机器人使用物体的行为判断。
(3)社交可供性是基于目标间关系判断的可供性。例如利用环境各要素之间或个体之间的关系判断。
图1展示了可供性的分类关系。

图1 视觉可供性分类Fig.1 Visual affordances classification
1.1 功能可供性
视觉可供性最基础的类别为功能可供性,即通过识别物体的外形、形状、材质等判断物体的可供性。
功能可供性关注物体的自身属性,可以根据判断方式将其分为显性功能可供性和隐性功能可供性。显性功能可供性即可以通过物体某一自身属性直接推测的功能可供性,而隐性功能可供性则需要在获取物体自身属性的基础之上,结合已有的先验知识判断对于该物体而言并不常见的功能可供性。
1.1.1 显性功能可供性
显性功能可供性通过物体的单个性质或形状等直接判断。基于显性可供性的性质,大多研究人员将视觉显性可供性判断任务同等化为目标检测任务,使用方法与目标检测任务的方法相同,包含且不仅限于KNN、CNN、集成的ResNet或Yolo[13]等框架。例如,Ye将可供性理解为目标检测问题,研究了认知机器人的场景功能理解问题,实现对室内场景中可供性区域的高效识别[14],(如图2所示)“抓”作为可供性意为可以被抓取,图2展示了图片中检测出存在“抓”这类可供性的区域。

图2 场景中“抓”的显性可供性检测Fig.2 Affordance detection for“grasp”in pictures
1.1.2 隐性功能可供性
隐性功能可供性需要通过已知的可供性与物体的性质推断。例如,石头自身具有可以抓取的可供性,如果进一步判断其有质地坚硬、尺寸合适的物理属性,即可推断出该石头具备与工具锤子类似的敲击能力,具有“敲打”这个可供性。这些潜在的可供性都不易直接通过物体的特性判断,而是需要结合先验知识推断。SchoelerM等人[15]成功推断某工具可能存在的另一种用法,如图3,用石头代替锤子或用头盔代替水杯等。
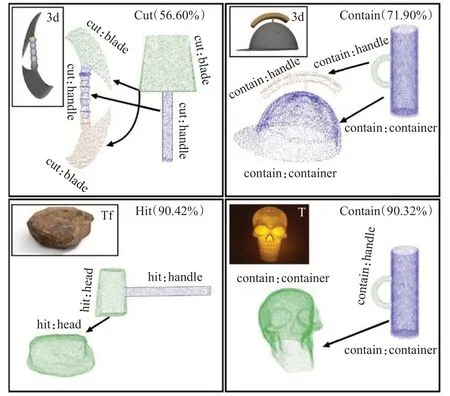
图3 隐性功能可供性的推断Fig.3 Recessive affordance inference
1.2 行为可供性
行为可供性不直接从物体的物理属性中推断,而是需要结合图像中人类或自身的行为,即使用者的行为进一步进行推理。例如一扇无把手的门,其物理属性可以描述为“一块平整的竖立放置的木板”,难以直接推断出其具备的可供性。而如果结合人推门这一连续的行为动作,则可以直观地判断其具有“推”的可供性。现有的行为可供性分析方法主要通过学习包含人物交互的行为图像或视频,预测物体所支持的人类活动,进而分析物体的可供性。早期Fitzpatrick等人[16]提出机器人不应该是只对外部刺激产生反应的系统,而应该探索和理解环境。通过学习人类的行为学习与物体互动应当是它们像人类一样行事和互动的第一步。
如图4 所示,Pieropan 等人[17]认为人类演示视频中包含大量人物交互性信息,可以辅助机器人更好地完成针对物体的可供性理解,因此在可供性理解框架中加入了人手与物体交互的RGBD视频,以便更好地理解人类的活动。

图4 通过物体使用视频学习物体可供性Fig.4 Learn object affordances by how objects are used
1.3 社交可供性
社交可供性是指在会被环境中其他个体与交互目标的关系所影响的可供性,该类可供性需要基于环境各要素或个体相互间的关系判断。
例如在图5中所示,抓取一个人身旁的包是不合适的,因为这个包是属于那个人,并且操作执行者会违反法律。一把被占用的椅子仍然被认为是一把椅子,人却不能坐在它上面[18-19],这是因为这把椅子被已经被坐在它上面的人或物体所占用,故它用来坐的可供性不存在了,因此一个物体的某些可供性需要结合它身处的环境来判定。

图5 社交可供性与环境中的元素联系相关Fig.5 Social affordances are related to connection of elements in environment
另一方面,社会可供性也与观察者自身的属性存在关系,例如给残疾人提供的专属座位,对于一个健康的人来说,一般情况下这个座位是不合适去使用的,则可以称残疾人专属座位的可供性对于健康人而言是消极的[19]。
1.4 可供性检测框架
可供性检测的流程如图6所示,先对输入的文件进行预处理,包括目标检测或目标分割,这样有利于进一步的可供性检测。其中预处理不是必须的,但经过预处理后,后续对图像的处理效率更高。

图6 可供性检测流程Fig.6 Affordance detection process
可供性检测的核心部分如图7所示,主要分为传统机器学习的方法和深度学习的方法。其中基于机器学习的方法包括K最邻近[20](K-nearest neighbor,KNN)、支持向量机[21](support vector machine,SVM)等,而基于深度学习的方法则利用CNN[7]、CRF[8]等网络进行可供性检测。

图7 可供性检测方法Fig.7 Affordance detection method
2 功能可供性检测
功能可供性由目标的物理特性等性质直接体现,对视觉功能可供性的检测旨在通过视觉信息对物体直接显现的可供性进行判断。可供性概念提出后,早期研究仅考虑了显性可供性,大多数方法为目标检测,与图像处理中的目标检测算法相似,使用KNN[20]、CNN[7]等基础方法即可实现。如今对于隐性可供性的检测,需要在检测到物体显性可供性的基础上,对不易直接检测出的潜在可供性进行推断,需要结合物体性质、显性可供性和先验经验综合推断,故隐性可供性检测方法框架更加复杂。在表1 中呈现了有关功能可供性的检测方法发展,展示了部分代表性和部分较新的研究。

表1 功能可供性检测研究Table 1 Functional affordance detection research
2.1 基于传统机器学习的功能可供性检测
在早期可供性理论的定义还未统一时,传统机器学习方法已经被用来检测物体的功能可供性,其方法是成功检测到物体后,通过该物体对应的标签来确定其可供性。伴随机器学习理论的发展,越来越多的学者使用SVM、KNN、贝叶斯网络等机器学习方法检测更加广泛的可供性种类。Stark和Bowyer[22]最初构建了基于形式和函数的通用识别系统,根据对象的功能来识别对象,而不是使用分配给多个函数基元来进行基于函数的识别,此研究作为对于可供性识别的开端。早期,Piyathilaka等人[23]使用SVM对可供性的检测研究用于实现更好的人机交互,提出了通过查看环境几何特征来绘制可供性地图。最后使用SVM分类器作为映射可供性的二进制分类器解决多标签分类问题,以完成可供性识别。
KNN 作为一个理论上比较成熟的方法,也是最简单的机器学习算法之一,常常被用在可供性检测之中。近来对于KNN算法的使用往往结合其他的算法以提高KNN 的精度或简化运算。Hermans 等人[24]引入一种依赖于物理和视觉特征的方法,如材料、形状、大小和重量,来学习可供性标签。基于这些特征,同时使用SVM和KNN分类器来测试方法。这种方法强调了结合物理和视觉特征可以增强可供性理解的概念。
Hjelm等人[25]将物体的RGBD 图片转化为2 维图像和点云,并将物体的特征分为全局特征和局部特征。使用large margin component analysis(LMCM)的正则化版本LMCA-R,将输入空间的每类结点的K阶最邻近结点聚集,同时将非同类成员分散,损失函数使用梯度下降法。可供性类别分类中,为每个可供性类别学习一个特定的值L,将问题理解为二元决策问题,对L使用kNN对可供性进行分类,最终达到可以定位对象的重要部分以分类到可供性。
由于隐性可供性起步较晚,且需要对已有的信息进行综合判断,大部分传统机器学习方法无法高效完成此问题,故传统机器学习只有对于显性功能可供性的检测。同时伴随近十年深度学习的提出和改进,深度神经网络已经实现了远远超过传统机器学习方法的精确度,并且由于传统机器学习不能在获得更多数据的情况下准确率继续稳步提升,因此近期使用深度学习进行显性功能可供性检测的研究也更多。
2.2 基于深度学习的功能可供性检测
和传统机器学习算法相比,深度学习的一个主要优势是它能够从训练集中包含的有限特征集合中推断出新的特征,准确率更高、适用性更强。近几年,深度学习在图像、声音、视频方面的处理都取得了较为出色的成果,同样伴随CNN、RNN 等发展,深度学习在物体可供性检测方面也有着较为显著的成果。
2.2.1 显性功能可供性检测
CNN是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一,在功能可供性的识别中也是常被使用的方法之一。Roy等人[37]使用四个多规模的CNN进行可供性分割:三个多尺度CNN独立应用于图像,以提取三个线索——深度图、表面法线和场景中粗层表面的语义分割;另一个多尺度CNN用于融合这些中级线索,以进行像素可供性预测。Nguyen等人[38]提出了一种从RGBD 图像中检测对象可供性的实时方法训练一个深度卷积神经网络,以端到端的方式从输入数据中学习深度功能。在之后Nguyen 等人提出了[27]一种使用深度卷积神经网络、目标检测器和密集条件随机场检测现实场景中对象可供性的新方法,并成功应用于全尺寸人形机器人。此方法第一阶段,通过在文献[39]中提出的R-FCN 方法作为目标检测器预测输入图像的边界框和对象类别,以完全卷积的方式训练一个非常深的网络。第二阶段,从语义分割网络中获得提供分割结果,为了能够生成对于每个像素可供性预测的热图,将VGG-16网络最后一层替换为1×1的10维的卷积层来预测数据集中每个类的分数,之后将其所有全连接层转换为卷积层。下一步,使用基于CRF的后处理模块来进一步提高提供分割的准确性。
在目前已有的很多成熟图像检测算法的基础上,对其进行针对于功能可供性检测的改进,也可得到较好的效果。Luddecke 等人[28]提出了改进版ResNet 架构[40]的残差卷积神经网络,并且获得了较好的效果。Ko 等人[41]也使用Yolo进行目标检测,下一步进行主成分分析以判断可供性,并达到理想的效果。
但直接使用目标检测的方法会面临一个目标中存在多个区域与人交互等目标检测原本不存在的问题,故Abdalwhab 等人[42]引入了一个单阶段可供性检测框架,利用特征融合来提高视觉可供性检测性能。将已知性能良好的分割模型SegNet[43]开始作为模型主干,通过在每次采样步骤后将可供性与编码器学习的相应可供性合并到下一层之前来增强此架构。下一步,通过将低分辨率、加强语义的功能与高分辨率功能相结合,实现更好的特征表示。Wu 等人44]提出一个可供性检测框架ASPN(affordance space perception network),ASPN 是一个完全卷积的拓扑,用于用RGB 图像输入近似可供性映射,该网络以图像为输入并输出可供性地图。与推断图像空间像素概率可供性地图的现有作品不同,此处的可供性是在现实世界中定义的,消除了人工校准的必要性。Yin等人[29]使用SEAnet作为主要框架,加入空间梯度融合模块与共享梯度注意力模块,对于可供性检测与可供性语义边缘检测更加一致。
综上所述,常见的方法是使用两个独立的深度神经网络模型分别执行可供性分割和对象检测任务。然而,这种常见方法的缺陷是大大降低了整个系统的处理速度,并且网络模型的计算复杂性大大提高。另一种可行的方法是使用多任务网络模型同时执行两项任务,但多任务网络的设计比单任务网络更困难。
2.2.2 隐性功能可供性检测
物体检测及其可供性的推理是视觉智能的一个基本问题。大多数工作将这个问题转换为分类任务,训练单独的分类器来标记对象、识别属性或分配赋值。Zhu等人[30]使用知识库(knowledge base,KB)表示进行对象提供推理的问题。对象的多样化信息首先从图像和其他元数据来源中获取,使知识库包含广泛的异构信息,包括对象属性、可供性、人体姿势等,之后使用马尔科夫逻辑网络[45](Markov logic network,MLN)通过学习关系来构建知识库,即一般规则的权重,通过加权的一阶逻辑知识库指定马尔可夫随机场,以构建知识库。最后无需训练单独的分类器就可完成一套不同的视觉推理任务,包括对人类姿势的预测和对象识别。例如苹果在知识图中,一些描述其视觉属性的节点与可供性连接,如形状、颜色、质地等节点与可食用连接。
在此之后,Zhu等人[46]再次提出面向任务的建模、学习和识别,旨在了解将对象用作“工具”的基本功能、物理和因果关系,提出物体识别。不仅仅是记住每个类别的典型外观示例,而是推理各种任务中的物理机制,以实现概括。在此基础上,Schoeler 等人[15]成功推断工具的任何可能用法,证明了可以识别各种工具甚至不常见的工具类型,系统“理解”对象可以用作临时替代品。例如,头盔或空心颅骨可用于运输水,是因为都存在一个空间可以储存水。但是这个框架忽视了对象的大小,并且未考虑目标属性,仅仅通过形状判断。近期Nair 等人[31]讨论了任务规划背景下的工具构建问题,引入了一种名为可供性引导搜索的方法,使机器人能够在无法获得执行任务所需的工具的情况下有效地构建和使用工具。在此之后,Fitzgerald等人[32]在工具的替代问题进行了更深一步的研究,表明交互式校正中学习的模型可以推广到为新工具有类似可供性的其他任务。
综上,在隐性可供性探索的前期,主要方法为通过找到目标的各部件和各部件的关系,并且学习其中的联系进行隐性可供性检测。随着时间的发展,隐性可供性的研究集中到了目标物体的功能可供性扩展,其中包含三个关键步骤:探索、评估以及将隐性可供性运用到任务。
3 行为可供性检测
行为可供性通过物体被使用的一系列行为动作判断,其需要检测视频或图像中正在发生的行为,或者类人机器人对于自己正在执行的行为或正在交互的物体进行理解。以动作倒水为例,Mottaghi 等人[47]认为机器人在完成该动作时需要估计杯子的体积,近似水罐中的水量,并预测倾斜水罐时的水的行为,容器的角度等。在表2中呈现了有关行为可供性的检测方法发展,展示了部分代表性和部分较新的研究。

表2 行为可供性检测研究Table 2 Behavioral affordance detection research
行为可供性检测作为实现人与机器人的无缝交互关键的一步,与机器人技术、人机交互、认知科学、人工智能、动作识别等多个学科共同实现。行为可供性在机器人理解环境并与之交互中起到了关键的作用。
3.1 基于传统机器学习的行为可供性检测
在早期,研究可供性运用了SVM分类器的学者中,Ugur等人[48]提出了一个两步学习过程,引导阶段和好奇心驱动(curiosity-driven learning)的学习阶段。在引导阶段,使用初始交互数据来查找可供性的相关感知特征,并训练SVM分类器。在好奇心驱动学习阶段,使用SVM决策超平面的好奇心决定给定的互动机会是否值得探索。
Akgun 等人[49]使用SVM 分析机器人与一组不同类型和大小的对象进行交互,以学习其环境中的可供性关系。首先控制机器人对物体进行敲击,物体由初始特征变为最终特征,从最终特征中减去初始特征得到所有物体的效应特征;下一步,使用1D 邻域的Kohonen selforganizing maps(SOM)[58]进行聚类;再通过ReliefF 算法[59],将相关性强的效应特征整合为相关特征;最后使用分类标签和相关特征共同训练SVM,最终将初始特征与动作联系,机器人由此可以执行特定动作并预测它对物体产生的效果。此研究证实了SVM分类器可以使用相关特征成功地学习效应类别。
Koppula 等人[60]通过给定一个RGBD 视频,将人类活动和对象可供性联合建模为马尔可夫随机场,之后选择使用结构支持向量机(SSVM)方法来进行机器学习以判断行为可供性。
贝叶斯网络又称信度网络,是贝叶斯方法的扩展,是目前不确定知识表达和推理领域最有效的理论模型之一。Hassan等人[61]为了实现对行为可供性的检测,分别运用SVM、KNN和贝叶斯网络构成检测模型,对正在进行的操作图像进行图像检测,经过对比结果,使用基于贝叶斯网络的方法构建最终可供性模型准确率最高。
3.2 基于深度学习的行为可供性检测
基于深度学习的方法较传统方法在进行行为可供性检测时对于不同行为的检测更加高效,学习能力更强。Gupta等人[51]提出了一个以人为中心的场景理解范式,用于估计3D场景几何形状,预测以数据驱动的人类互动词汇,以表示的人类“工作空间”。在有着内场景理解和运动捕捉数据方面[62-63]工作的基础上,创建一个人类姿势和场景几何的联合空间。但其只着重于对相互作用的检测,而未强调物体本身的可供性。之后Qi 等人[52]提出一种使用ST-AOG 观测RGBD 视频以预测人类未来的运动的方法,其中使用随机语法模型来捕获事件的组成结构,整合人类行为、物体及其可供性。
行为可供性的研究在对物体的可供性检测之外也包括对于人类活动的理解,Li 等人[64]提出了一种高效、全自动的3D 人姿势合成器,该合成器利用从二维学到的姿势分布和从三维中提取的可供性。其在此之后开发了一个3D 可供性能力预测生成模型,该模型从单个场景图像中生成具有完整3D信息的可信的人类姿势。
行为可供性识别的另一个方向是使用现实或虚拟的机器人进行实际操作。Shu等人[65]使用ST-AOG作为可供性检测方法,从人类交互的RGBD 视频中学习,并输出到类人机器人,以实现实时运动推理人机交互(human-robot interaction,HRI)。Chu 等人[66]通过语义分割预测对象的可供性,并用于真实的机器人操作。Mandikal 等人[67]将以对象为中心的视觉可供性模型嵌入到一个深度强化学习循环中,以学习使用人们更倾向的对象区域。模型由两个阶段组成。首先,训练一个网络,从静态图像预测可供性区域。其次,使用可供性来训练动态抓取规则。Zhao 等人[54]考虑了多可供性之间的共生关系以及可供性和客观之间的组合关系。与现有CNN 的方法不同,所提出的网络以端到端的方式直接从输入图像生成像素提供映射。
静态的视觉观察只能识别物体的一些特征如形状和纹理。如果不了解对象的全部范围而规划动作可能会导致策略失误,Veres等人[53]针对这个问题,主要研究了机器人抓取时所需要考虑的属性,例如物体表面的摩擦力或者物体的刚度都进入可供性一起进行考虑,提出通过机器人手腕上的力和扭矩读数,将CoM 隐含地纳入抓取承受力预测中。其主要是对文献[68]中的框架进行了改进,将引导网络方法扩展到感官反馈的机器人抓取问题。先使用CNN 模型,通过几个卷积加池化操作对RGB对象图像进行编码。此深度学习网络同时由另一个CNN和MLP编码RGB图像和力/扭矩读数的形式展示了k与之前完全相同的物体的抓取尝试的预测抓取成功的概率。
以前的方法通常将移动对象视为主对象,并依靠光流来捕获视频中的运动线索,当嘈杂的运动特征与外观特征相结合时,主对象的定位有几率被误导,此时仅靠流动信息不足以区分主物体和一起移动的背景物体。Luo 等人[55]利用视频中手的位置和行动提供的辅助线索,消除多种可能性,更好地定位对象中的交互区域。此方法在可供性基础方面取得了先进的结果。
Lu等人[69]建立一个循环双边一致性增强网络(cyclic bilateral consistency enhancement network,CBCE-Net),以逐步调整语言和视觉特征。此外,对比实验结果表明,在客观指标和视觉质量方面,此方法在四个相关领域(语义分割、显着性检测、可供性检测和实例分割)都优于九种典型方法,其中包括用于可供性检测的OSADNet[70]和OAFFD[54]。
4 社交可供性检测
社交可供性检测目的是通过研究个体与环境属性或环境属性自身内部的关联性,探索出更加深层次的可供性的可能或限制。各物体互相或与观测个体的相互联系造就的可供性则称之为社交可供性。现实生活中,人类对物体的感知就一部分取决于时空上下文知识[71-72],鉴于人类对环境已有的了解,这种机制有助于识别未知物体及其可供性[73]。总体而言,对于社交可供性的检测,重点在于对于物体上下文信息等的推断,由于社交可供性起步较晚,深度学习已经被熟练运用在此检测中,例如CRF、CNN 等,故使用传统机器学习方法的社交可供性研究较少。在表3 中呈现了有关社交可供性的检测方法发展,展示了部分代表性和部分较新的研究。
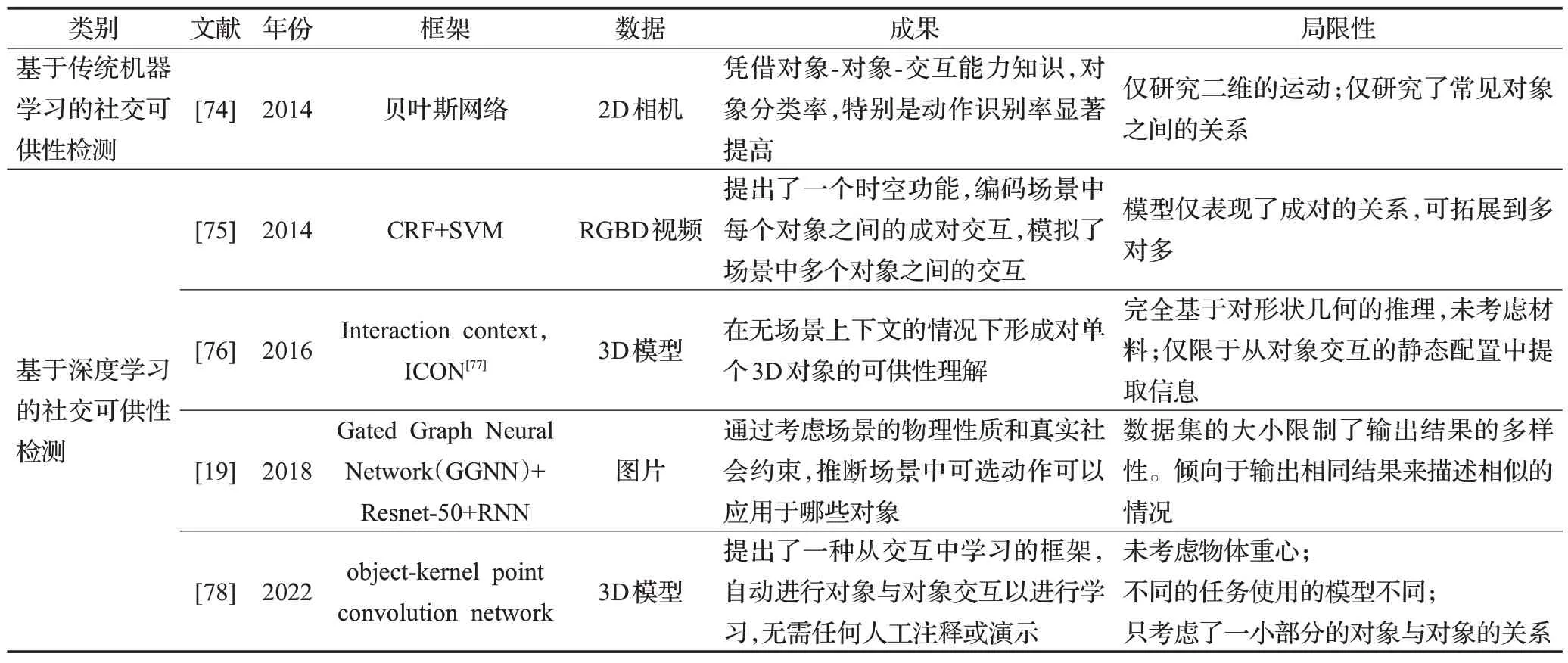
表3 社交可供性检测研究Table 3 Social affordance detection research
4.1 基于传统机器学习的社交可供性检测
Sun等人[74]提出了一种建模目标相互间的可供性的方法,这种可供性关系被用来提高行为识别准确度。其中使用以全监督的方式训练目标分类器、动作分类器和贝叶斯网络。首先获得对目标的操纵和目标的反应的初始可能性,其中目标初始似然度是使用基于方向梯度直方图(HoG)的滑动窗口目标检测器估计的。并且据人类手部运动轨迹的特征估计了人类动作的初始可能性。在训练中,全程跟踪人手,根据速度的不同对手部动作分段。通过分割和可能的目标位置,检测出正在交互的目标,最后利用贝叶斯网络建立人与物体之间的联系。此实验通过观察物体与主动动作之间的联系来解决机器人学中的技能学习问题。
社交可供性的概念近几年才开始作为一个明确的研究要点,对于社交可供性这种更加需要探究物体之间的关联性的任务,传统机器学习方法性能并达不到深度学习的效率,基于传统机器学习的社交可供性检测实例不多。
4.2 基于深度学习的社交可供性检测
社交可供性研究的是物体之间的关系,使用深度学习的方法更适合找到各个物体的深层次联系。为了探究物体之间可供性的影响,Pieropan 等人[75]提出利用对象到对象的时空关系来创建“对象上下文”以及功能描述符来预测人类活动。例如,只有杯子的存在不能确定是否会发生饮酒行为,但旁边有酒瓶会增加饮酒行为的可能性。其描述了一个概率框架,为场景中物体及其随时间推移的相互作用建模,但只局限于成对的关系。于是Hu等人[76]提出了一种分析对象间关系和对象内关系的方法,旨在根据对象的功能对其进行分类。他们使用对象的部件上下文、语义和功能来识别它们的可供性。
在过去很少有研究对象-对象交互的任务,而对象交互在机器人操作和规划任务中发挥着重要作用。在日常生活中,有丰富的对象-对象交互场景空间,例如将对象放在凌乱的桌面上,将对象放置在抽屉里,使用工具推动对象等。Chuang 等人[19]提到为了在社会中自然融合,机器人需要像人类一样行事,因此机器人需要了解3D 环境施加的可供性和限制,以及在特定场景中哪些行动是社会可接受的。利用空间网状图神经网络(gated graph neural network,GGNN)来推理给定感兴趣的操作对图像中对象的提供。并且基于实例级语义分割映射构建一个图表,其中节点是图像中的对象。之后通过将相邻对象与边缘连接来编码节点对的空间关系。最后空间GGNN 模型将每个对象的语义特征表示作为其初始节点表示,并通过在图表中的邻近点之间传播消息来迭代更新其隐藏矢量。这能够高效地捕捉图像中的上下文关系。
近期,Mo等人[78]提出了一种对象-内核点卷积网络(object-kernel point convolutional network),以推理两个对象之间的详细交互,以学习各种任务的对象交互。通过构建对象-对象交互任务环境,进行大规模的对象支持学习,无需人工注释或演示。对大规模合成数据和现实世界数据的实验证明了该方法的有效性。
总而言之,在社交可供性研究起步阶段,都是对小规模的对象-对象交互进行了建模,并通过人工注释或演示对模型进行了训练,而近期研究进行了大规模无注释可供性学习,涵盖了具有不同形状和类别的各种对象-对象交互。
5 轻量化策略
目前已经存在的视觉可供性检测方法框架数量很充足,但其中大部分方法并不适合在运算资源受限的系统中使用,如嵌入式平台,它们主要目标是提高准确性,未关注所提出解决方案的计算成本。例如,计算机视觉用于智能假肢等移动平台,在这种情况下,平台能够提供的运算资源是有限的,但需要可供性检测可用于确认物体可供性,此时视觉可供性检测是必要的。
在轻量化检测框架这个方向,Yen-Chen等人[79]发现视觉任务的预训练显著提高了学习操作对象的泛化能力和样本效率。因此,将模型参数从视觉网络直接传输到可供性预测网络,并成功进行零样本适应,意味着机器人可以无训练就能抓取物体。只需少量经验,在拾取新物体方面成功率就能达到约80%。
Tsai 等人[80]提出了一种基于ESPNetv2 的轻量级可供性分割模型,该模型可以有效地提高处理速度,并降低运行时所需的计算需求。采用基于锚点的单级对象检测模型作为与语义分割分支集成的骨干网络。依靠单阶段网络架构的优势,该网络模型可以通过相对简单的架构来实现,在高精确度的同时,大幅度提升运算速度,比AffordanceNet 快五倍。Apicella 等人[81]提出了一种利用对象检测器克服帧问题的可供性检测通道,减少通道在资源受限平台上运行的计算负载,构建了具有轻量级结构和嵌入式重新校准技术的抓取候选评估器。
在此之后,Ragusa等人[82]提出并描述了第一个完整的嵌入式设备可供性检测解决方案即一种基于硬件感知深度学习解决方案的可供性检测策略。这种解决方案可用于大幅改善基于计算机视觉的假肢控制,在计算成本和准确性之间建立了更好的平衡。因此,该模型在实时嵌入式设备上在功耗有限的情况下实现并获得了高FPS速率。
综上所述,轻量化的解决方案应该使用在嵌入式设备上以支持的模型,降低训练模型的整体硬件需求。其次,应仅通过处理RGB 图像实现可供性检测。目前最新的硬件检测可供性模型可以在标准基准上实现与机器人学的最先进解决方案相同的精度。
6 数据集
对于视觉可供性检测,数据集的重要性是不言而喻的。利用合适的数据集,结合与之对应的框架与参数能达到最好的检测可供性的结果。
在本章中,提供了可供性注释的可用数据集。如表1所示,所使用的文件格式也包括图像、视频以及3D 模型。对于视觉可供性,已经提出了许多数据集,以促进从场景中检测可供性对象,即从输入图像中检测具有可供性或功能性的对象。
如表4所示,对于适用于功能可供性的数据集需要有各类不同的物体与其对应的可供性标签,此时物体种类越多,则此数据集的应用范围则越大;对于适用于行为可供性的数据集需要包含动作数据或人物使用物体过程;对于适用于社交可供性的数据集不仅需要有功能可供性数据集的要求,并且需要存在多个有联系的物体出现在同一图中,由此也可发现对于社交可供性的数据集制作是有一定困难的。这也是为何近期可供性的数据集主要集中于功能可供性与行为可供性,而极少包含社交可供性。

表4 近期主要可供性数据集Table 4 Recent and primary affordance datasets
有的数据集经过对较早数据集的修正、补充与筛选等更新,使得新数据集更加适合某些特定类型的可供性检测,或能够覆盖更多的场景使得应用面扩大。
7 视觉可供性的应用、挑战及未来方向
7.1 应用方向
视觉可供性是依靠摄像头理解世界的一个重要途径,用于判断环境或物体的交互方式。对于视觉可供性的检测的两大应用主体则分别是真人与机器人。
7.1.1 视觉可供性对于真人的应用
可供性识别可以代替人去感受,包括且不限于环境、产品等。使用可供性识别以真人的视角去评估事物,相比于真人的评估更准确与标准:
(1)城市规划领域:通过以真人视角检测可供性之后,可以对于一个区域的环境与设施的合理性作出建议[83],比如以小孩或老人视角评估设施环境[84],进而提升环境的儿童友好性或适老性,例如公园环境和设备所包含的可供性能给予儿童直接的感官体验,包括自然环境、标识以及游戏设备的适宜性等能够增加儿童的体验舒适度。
(2)产品设计:通过运用可供性检测的方式优化产品使得用户有更舒适的使用体验,Zhu 等人[85]通过坐在椅子上时不同身体部位的压力来判断舒适区间。
7.1.2 视觉可供性对于机器人的应用
可供性识别可以使机器人理解其所处的环境,理解工具的用法,达到一定程度的智能:
(1)操作目标对象:经过视觉可供性识别,机器人可以了解物体的性质与可供性,以便于操作对象。例如对于城市垃圾的处理分类[86],亦或者对于超市自主机器人[87]的加强。
(2)理解目标运动:结合行为可供性的运动检测,将会帮助机器人理解观测目标的运动,以便于后续的预测或交互更加合理。
(3)预测目标运动:以机器人视角进行视觉可供性检测,帮助机器人更加高效预测人的活动[60,88-90],在环境存在指定可供性的情况下,可判断为目标做特定行为的可能性会变高。Corona 等人[91]根据一个或多个物体的单个RGB 图像,预测人类将如何抓住这些物体。预测人的活动可以有助于机器人充分理解和响应人的行为。
(4)场景理解:机器人需要掌握使用工具的方法,比如Myers等人[92]提到在厨房的机器人应该要充分理解各种工具的可供性,才能更好地代替人类工作[93]或与人交互,使得它们与人或物体的交互更加合理,使机器人更好理解其所处的环境,也可以运用到AI 使其更加智能。例如加强自动驾驶[94]的可靠性。
(5)发掘工具隐藏功能:隐性可供性检测可发现工具之间的可替代性,例如当前任务为“开快递”,在环境中利用隐性可供性检测达成钥匙来完成此任务。
7.2 目前的挑战
(1)目前的视觉可供性识别,主要框架与计算机视觉目标检测所使用的框架类似,存在的挑战与目标检测部分相同:
①视角的多样性:同一个物体在不同的视角下的外形大多是不同的,所以需要在不同角度下都能识别出物体的可供性。
②物体的形变:现在对于可供性的检测全部都是刚性物体,也就意味着不包含例如绳子之类的可形变物体,这对于视觉可供性是一个缺失的部分。
③遮挡:遮挡是实际对象可供性估计任务中的常见挑战。Liu等人[100]制作了用于研究被遮挡物体的可供性的数据集。但是这个问题对于可供性检测的影响依旧存在。
(2)同时,也存在很多在进行目标检测时并不会显现,而是只有在可供性检测时才会显现的问题:
①多区域可供性:一个对象中可能存在多个可能的区域可以与人交互,也就意味着,不能将物体看作一个整体,而是对物体自身也要有拆分。
②可供性多样性:与物体检测不同,同一对象区域存在多个可能的可供性。
7.3 未来发展方向
目前视觉可供性检测主要集中在这三种类型,即功能可供性、行为可供性、社交可供性。而对于未来的发展方向主要分为应用的方向与研究的方向。
7.3.1 未来应用方向
(1)未来可供性识别应用方向广阔,其中机器人智能设计将为重要的应用领域,通过视觉可供性与机械相结合,可以达到如下成果:
①智能机器人与机械手:对于视觉可供性检测,最显而易见的应用为机器人与机械手,将可供性检测运用到机器人上后,其可以更加智能的服务人类。
②社会辅助机器人:全球人口需求的变化和增加,需要社会辅助机器人为最需要帮助的个人提供更舒适、更安全的环境[109]。
③专用视觉:与日常生活相对应的为专业使用场景,结合视觉可供性,可以比人手更加精准的操作。例如,使用机械臂完成手术时,不会出现人为意外。
(2)不依赖机械实物作为载体,可供性识别可以在其他相关领域创造成果和创新:
①虚拟现实与建模:在虚拟现实中,重要的一点是人与建模出的物体的交互。结合可供性检测,可以在虚拟现实中更加便捷地对于各类物体进行分类与运用。同时,在直接使用现实物体扫描进行建模的方法相比于直接建模将会更加便捷。
②5G-云端计算:与轻量化设计相对应的是,如果将所有的运算通过5G 放置云端,那么无论是运算速度或是框架的尺度都可以与在本地运算不在同量级。
7.3.2 未来研究方向
(1)目前的挑战之一,视角的多样性使物体在不同角度所观察到的外形不同,对此在未来可以进行如下研究:
①数据集的创建与更新:数据集是对深度学习结果有着重要影响的因素之一。可供性研究的一个重要工作是可供性数据集的制作与优化,目前已经有很多优质的数据集可以使用,不过跟现实世界的复杂性相比,已有的数据集在标签的种类方面依旧存在局限。同一个物体不同视角下的数据越多,则此问题更易解决。
②多视角兼容性与可迁移:在第一人称视角下的可供性检测与第三人称视角下的可供性检测是不同的。易于发现的是,第三人称视角的数据更容易获得,而机器人使用第一人称观察对象,故而在不同角度下对可供性检测的兼容性是必要的。
(2)目前只能做到对于刚性物体的可供性检测,而对于绳子一类可变形物体的可供性检测技术尚不成熟,即物体的形变是现在尚未有明确解决方案的研究方向,可从如下方面进行实现:
①对已有可供性检测框架改进:对于可形变物体需要更精准地识别与控制,对检测框架的改进实现对非刚性物体的模拟和操控。
②多传感器结合:在未来伴随硬件品质的发展,以及更多种传感器的出现,将视觉与其他传感器相结合。例如,将视觉与压力传感器相结合共同检测可供性,那么可以更加准确地判断物体的硬度可供性。
(3)物体被遮挡条件下的可供性识别目前已有进展且有研究人员制作相关数据库,在未来这个问题仍可以继续深入研究:
①对于数据库的创建与更新。
②对已有计算机视觉框架转化:目前存在基于深度学习技术,对视觉可供性提出新的研究框架,但对还未运用到可供性方向的图像识别等框架的改造适配,将最新的研究成果适配于可供性检测有几率获得更好的成果。
(4)物体的不同区域可供性不同和同一区域可供性的多样性使得可供性检测与目标检测有着显著的差距,未来可能的研究方向如下:
①对于数据库的创建与更新:目前研究使用的数据库大都是专供可供性或在原始数据库技术上为可供性更新的新数据库。在未来可创建更多适配可供性检测的数据库。
②创建新的可供性检测框架:可供性检测与目标检测不同在于可供性除外形等特征外,还可通过使用者的行为或与其他物体的关系来确定,在未来可以创造出更适配可供性检测的算法框架。
(5)目前已有研究方向的加深同样是未来可供性检测研究的重要一环:
①轻量化设计:可见对于视觉可供性检测的轻量化设计发展才开始被重视,将视觉可供性检测框架做小,放在嵌入式设备或将整体做快,运算速度更快,则机器人可以有更多的反应时间。
②知识图谱的更新与创建:在有先验知识或知识图谱的情况下,可以更好地去理解图像或者视频,基于图或图谱的方法和视觉可供性结合将会帮助可供性检测。目前对于知识图谱的可供性研究依旧处于缺失状态,目前Zhu等人[30]使用知识库表示进行对象提供推理的问题来完成对于隐性可供性的检测。利用知识图谱,将物体与可供性的联系组合,并且通过知识图谱相互联系,使得AI应用更智能。
③对已有可供性检测框架改进;目前基于可供性的机器人行为控制仅能实现简单动作(例如移动、抓取等一次性动作),而对需要多重可供性共同控制的复杂动作(例如开锁等复杂性更高的行为)目前仍未能实现。
(6)除以上所述,目前还有如下部分可供性检测未有显著成果的研究方向:
①主动视觉检测:将感知与运动、控制结合,将视觉上升到有意识的、可控制的一个过程。作为生物的视觉可以通过实时调整,能够在能量消耗和三维感知,分辨率等达到平衡。如果将主动视觉加入可供性检测,机器人可以通过在新环境中的主动探索,实现智能等提升。
②动态特性:目前仅仅有行为可供性进行对于人的动态检测,然而目前对于机器人的自我运动依旧是固定场景,未考虑到摄像头自身运动导致动态场景的情况。
8 结语
本文对视觉可供性的概念、分类与识别的相关方法对可供性理论诞生以来的文献进行了综述。首先将可供性划分为三种类型,按传统的机器学习方法和深度学习的方法出发分别进行了阐述和讨论;并且梳理了可供性数据集;最后对视觉可供性的应用方向、未来可能的研究方向及潜在的应用领域进行了讨论。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
中学生数理化·中考版(2020年10期)2020-11-27
中学生数理化·高一版(2020年1期)2020-02-20
意林(2018年3期)2018-03-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
