
结合gazetteers和句法依存树的中文命名实体识别
2022-09-21 05:38冯一铂
计算机工程与应用 2022年18期
方 红,苏 铭,冯一铂,张 澜
1.上海第二工业大学 文理学部,上海201209
2.上海第二工业大学 工学部,上海201209
3.喀什大学 数学与统计学院,新疆 喀什844000
命名实体识别对下游的信息提取、问答系统、机器翻译等应用领域起着非常重要的作用,是自然语言处理技术落实到工业生产实践中的基础环节;中文命名实体识别相较于英文来说,其词的划分较为困难,因此如何去丰富地表示字符信息成为近些年来研究的重点。
中文命名实体识别最初是基于字符的NER和基于词的NER,He 等人[1]、Li 等人[2]的研究表明基于字符的NER不能很好地应用词的信息,由于中文单个字所能表示的信息要比单个英文单词欠缺很多,从而无法更好地完成后续的预测标注;基于词的NER 由于无法很好地获得实体边界,因而会产生很多错误信息,导致效果比基于字符的更差。后续大量工作将中文的字符和词信息结合起来进行序列标注,丰富输入表示层的信息。刘小安等人[3]提出了通过CNN进行局部特征提取的CNNBiLSTM-CRF模型,对词汇的局部特征提取起到了一定的效果;谢腾等人[4]使用了预训练模型Bert 来进行词汇表示学习,提出了Bert-BiLSTM-CRF 模型,提升了上下文语义表示学习的效果;以上提出的模型都没有借助外部词典信息,因此对于特殊名词较多的数据集分词错误造成的误差传递问题比较严重。后续Zhang等人[5]提出了一个将词的信息融入到这个词的开始和结束字符中的Lattice 模型,很好地增强了词的嵌入表示效果,但是对于词中间的字符却无法融合词的信息,会造成一定的信息缺失。Liu 等人[6]、Zhang 等人[7]提出了使用词典信息来提升字符向量表示,利用词典来进行匹配,使得能够很好地确定词汇边界信息,降低分词误差导致的错误率,但是对于一个词对应多个类型的问题无法得到解决。MultiDigraph[8]模型提出了使用多重图来解决gazetteers的不同类型引起的多种表示信息的问题,使用了融合多个gazetteers类型信息的方式解决了之前工作中词汇的多义性问题,对于中文句子中的歧义性得到了一定的解决,但是仅仅依靠gazetteers获取的词的匹配关系,不能很好地融入不相邻的词之间的依赖关系。比如:“张三在上海人民广场”,通过gazetters 的信息嵌入可以很好地将“上海”“人民广场”“上海人”等信息融合进来,但是对于各个词之间的依赖关系没有提取出来,整个句子的句法结构也没有很好融入。这样会导致:如果“人民广场”这个词不在词典中,而“上海人”在词典中,会使得整个句子的词信息融入错误,会降低识别准确率。霍振朗[9]提出了基于句法依存树和图神经网络的模型,证实了融入句法关系对序列标注具有一定的效果提升。针对上述问题,提出了通过将句子中词的依赖关系即句子的句法依存树融入到每个字符信息中的方式来缓解由于gazetteers匹配错误或缺失而造成的词汇信息融入错误问题,给出一种基于gazetteers 和句法依存树的中文命名实体识别方法。该方法首先通过匹配gazetteers词典信息,找到句子含有的词,获取词的开始与结束位置信息,形成两个结点,再根据当前词所对照的词典属性将边赋予词的类别信息;随后将所有词形成的三元组信息拼接成图结构,之后将句子的句法依存结构关系,即句子中各个词为结点,词与词之间的句法依赖关系为边,构成三元组,进一步将所有三元组整合为图结构。将词信息图与句法依赖关系图进行整合,提取其邻接矩阵信息与字符信息共同输入到图神经网络中进行字符表示信息的学习,从而将gazetteers 信息与句法结构信息融入每个字符信息中,最终使得形成的词向量包含了句子的结构和词边界信息。最后通过BiLSTM-CRF 模型进行序列标注,实现最终的实体识别。新的方法使得实体识别过程中每个字符的信息更加丰富,为后续的序列标注提供更好的支撑,减少分词错误和句子结构信息造成的误差传递,从而进一步提升了实体识别的准确率。通过在Ecommerce、Resume、QI 等数据集的验证,新的方法可以使得中文实体识别的准确率得到较大提升。
1 模型架构
基于gazetteers和句法依存树的中文命名实体识别模型的总体思路是通过将句子中字符顺序结构与句子包含的gazetteers 词结构组成的主体结构图、句法结构图进行融合,之后再将融合句法依赖结构的主体结构图与通过bigram 融合后的词向量信息一起通过自适应门控图神经网络进行字符嵌入学习,最终得到每个字符的向量表示信息;通过自适应门控图神经网络融合后的向量信息再经过传统的BiLSTM-CRF进行序列标注,最终得到每个字符的标签信息。模型的框架设计如图1 所示,为表述清楚,框架中以“上海人民广场”为输入句子进行描述,通过对gazetteers 进行匹配,将“上海人”“上海”“广场”“人民广场”等匹配到的词分别与句子的顺序结构图进行融合,形成基于gazetteers的多个图信息,之后将多个图的邻接矩阵信息和句子本身的词向量信息通过自适应门控图神经网络进行表示学习。形成最终的表示向量作为后续序列标注模型的输入。
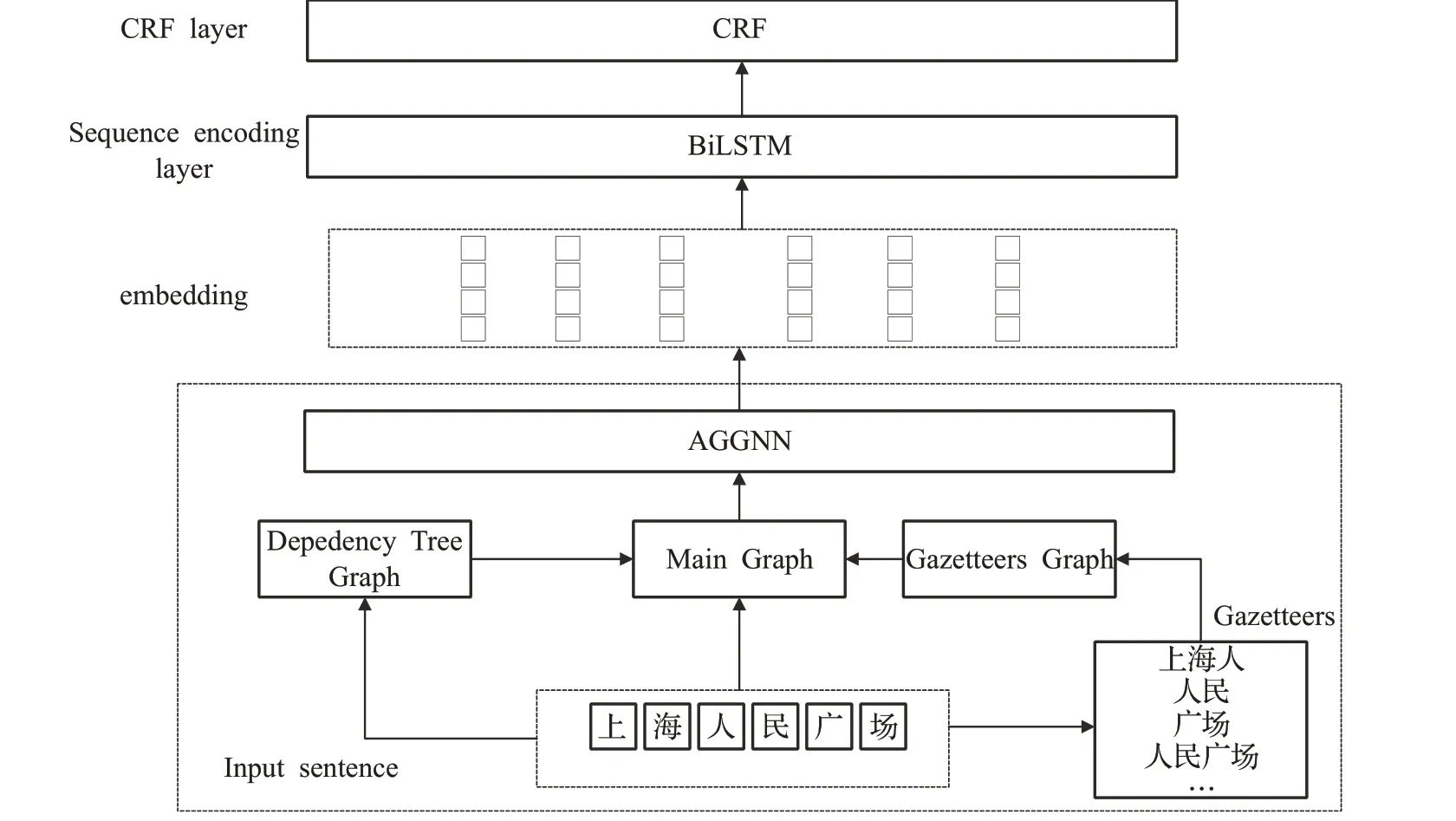
图1 模型架构Fig.1 Model architecture
1.1 图的构建
通过句子所有字符顺序信息、gazetteers 的结构信息、句法依存树信息来构建两个图,分别为主体结构图、依赖关系图,最后将依赖关系图信息融合进主体结构图,将融合后的主体结构图作为后续模块的输入。
1.1.1 主体结构图
主要将所有字符序列化,形成正向、反向两个序列。如:“上海人民广场”,一共有6 个字符,表示为c1、c2、c3、c4、c5、c6,两两之间通过有向边进行连接,形成如下:

Vc表示输入句子的每个字符,E表示由前后字符两两相连的边的组合。
通过匹配gazetteers词典信息来匹配句子中的词,并以作为开始结点,依次使用有向边连接词的各个字符,最终以作为结束结点,gi表示匹配到的gazetteers类型。将所有结点相连构成gazetteers图,表示为:

其中,表示由开始结束的各个gazetteers所包含的字符,E是由各个字符组成的边,Lgaz代表一个gazetteers在不同词典列表中的类型。
1.1.2 依赖关系图
句法依存树[10]是由依存关系构成的一棵树,依存关系是一个中心词与其从属之间的二元非对称关系,其结构是一个加标签的有向图,箭头从head 指向child,以“青岛是一个著名的啤酒品牌”为例,其句法依赖关系如图2 所示,从该依赖树可以看出,每个Token 只有一个Head,依存关系用依存弧表示,方向由从属词指向支配词。每个依存弧上有个标记,称为关系类型,表示该依存对上的两个词之间存在什么样的依存关系[11]。常见的依存关系有主谓关系(SBV)、动宾关系(VOB)和状中关系(ADV)等。通过句法依存树可以进一步降低中文命名实体识别中的歧义性并且可以融入更多的结构关系。
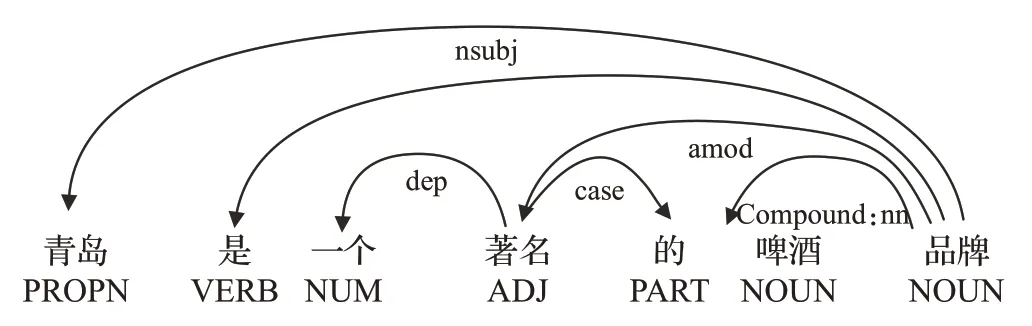
图2 句法依存树结构Fig.2 Syntactic dependency tree structure
这里是通过spacy[11]模型来对句子的句法结构进行提取,最终将切分出来词的第一个字符与其有句法关系的另一个词的第一个字符建立有向边,其结构如式(3):

其中,Vdt表示句法依存结构中的各个成分,Edt表示各个成分直接的依赖关系构成的有向边的集合。
1.2 自适应门控图神经网络
这里采用自适应门控图神经网络来对图信息进行嵌入表示学习,图神经网络已经广泛应用于深度学习的各个领域中,对于通过图卷积神经网络(graph neural network,GCN)来融合句法依赖信息在Cetoli 等人[12]提出的模型中已经体现出了很好的作用。后来为了更好地融合长距离信息,Li 等人[13]提出了门控图神经网络,通过加入GRU 来进一步提升句子整体语境的融合度。在门控图神经网络的基础上添加自适应的门控机制,形成最终的自适应门控图神经网络(adapted gated graph neural network,AGGNN)来进行信息融合,它相较于传统的门控图神经网络的优点在于它可以融合多图信息,由于每个词可能属于多个类型,因此一个词可能会形成多张图,而AGGNN 可以更好地进行多重图的嵌入表示。其具体的结构如下所示,bigram已经被Chen等人[14]提出的模型证实在命名实体识别任务中有较好的效果。初始化的向量信息由gazetteers和由bigram表示的词嵌入向量融合表示:

将由主图、gazetteers 图、句法依赖图融合后的图的邻接矩阵表示为Av,这里的Av是通过权重比来计算的最终矩阵,具体实现如下。
将上下文匹配到的gazetteers 类型进行统计,通过sigmoid 函数计算贡献度系数,最终将多个邻接矩阵转化成一个融合多个gazetteers信息的邻接矩阵Av。其权重计算方式如下所示:
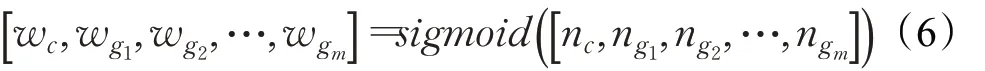
其中,w为权重系数,n为对应gazetteers类型出现的次数。
得到邻接矩阵信息后,通过一个网络层获取融合图信息的隐向量信息:
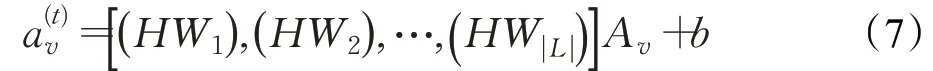
最后输入到GRU[15]中形成最终的字符表示信息。
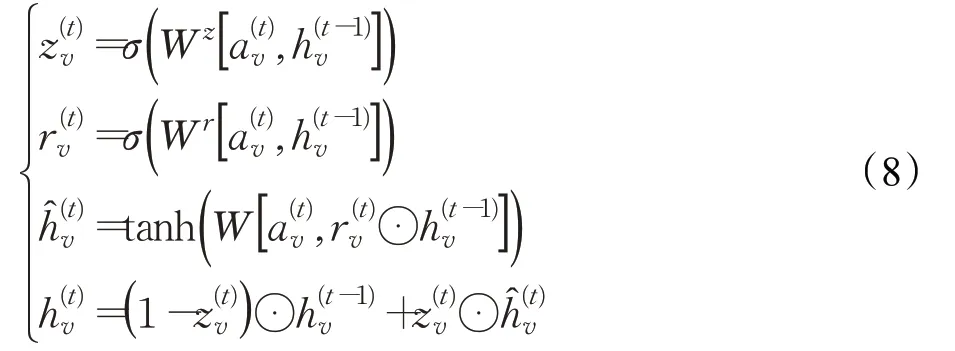
1.3 BiLSTM-CRF
BiLSTM-CRF是一个传统的序列标注预测模型,在Lin等人[16]的研究中,可以看出它能起到比较好的效果,因此这里采用这个基础模型作为序列标注预测模型,将通过AGGNN 形成的字符表示信息输入到BiLSTMCRF中获取最终的预测结果。
1.3.1 BiLSTM层
BiLSTM 层是由前向LSTM 和后向LSTM 组成,可以更好地用于提取文本中的上下文特征。Marcheggiani等人[17]的工作指出,图卷积网络的主要问题在于难以捕捉长距离节点之间的依存关系,将其与LSTM结合后可以很好地避免这一问题。因此,将经过图卷积神经网络后的字符信息加入到BiLSTM 中进行编码。其中,LSTM的主要结构可以表示为:
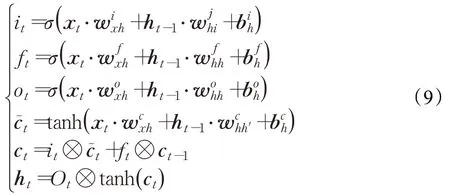
其中,σ是sigmoid 激活函数,i表示输入门,f表示遗忘门,o表示输出门;⊗是点乘运算,w、b代表输入门、忘记门、输出门的权重矩阵和偏置向量。对于句子(x1,x2,…,xn),共有n个单词,每一个都代表一个d维的向量,BiLSTM通过计算每个词包含其在句子中左侧上下文信息表示向量htl和其右侧上下文信息的htr,通过将其整合共同表示这个词的信息为ht=[htl,htt],这种表示可以有效地包含上下文中单词的表示,对于多标记应用十分有效。
1.3.2 CRF层
命名实体识别任务一般可以被认为是序列标注的问题,通常BiLSTM 的输出结果即可进行序列标注,通过在最顶层添加一个softmax 层进行判断,输出概率最大的标签,即可完成输入序列的标注任务。但是BiLSTM虽然解决了上下文联系的问题,却缺乏对输出标签信息的约束。softmax分类器在序列标注任务中没有考虑标签与标签间存在的依赖关系,而条件随机场CRF可以使用对数线性模型来表示整个特征序列的联合概率,能更好地预测序列标注中的标签。
假定句子长度为n,句子序列为X=(x1,x2,…,xn),通过BiLSTM 输出的分数矩阵为P,P的维度为n×k,其中k表示标签种类的数目,Pij表示第i个词预测为第j个标签的概率,对于预测标签序列Y=(y1,y2,…,yn),预测序列最终的总分数为:
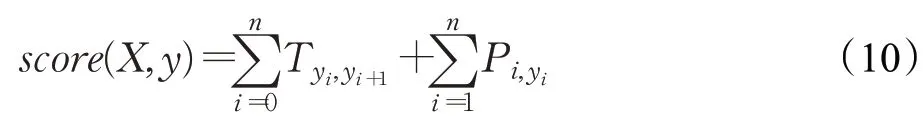
其中,T表示标签间的转移分数,表示每个字到对应yi标签的分数。
由于预测序列有多种可能性,其中只有一种是最正确的,应对所有可能序列做全局归一化,产生原始序列到预测序列的概率,在所有可能的标记序列上的softmax产生序列y的概率:

2 实验结果与分析
2.1 数据集
采用了Ecommerce、Resume、QI 三个数据集来作为模型的实验数据集。Ecommerce是由Ding等人在文献[8]中提出的一个电商领域的命名实体识别数据集,Resume是Zhang 等人[5]最初提出的一个简历数据集,它是一个公共数据集,在多篇文章中已经得到了使用与验证。QI是由本文标注的商品质量检测领域的数据集,主要分为9个实体类型,用来进行产品实体的标注,如表1。
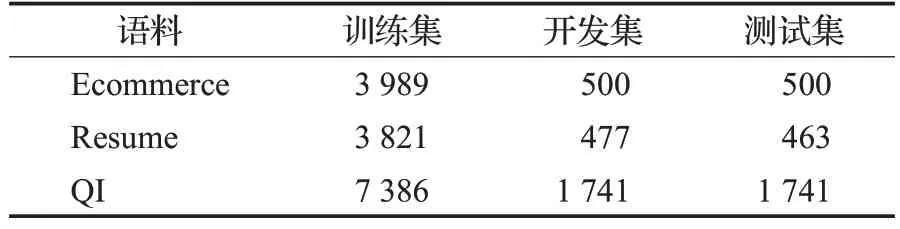
表1 语料规模Table 1 Corpus size 句
对于使用到的词典信息通过在搜狗词库、百度词库中获取,将其中的词按照行进行分割,最终形成一个综合的词典库信息,如表2。
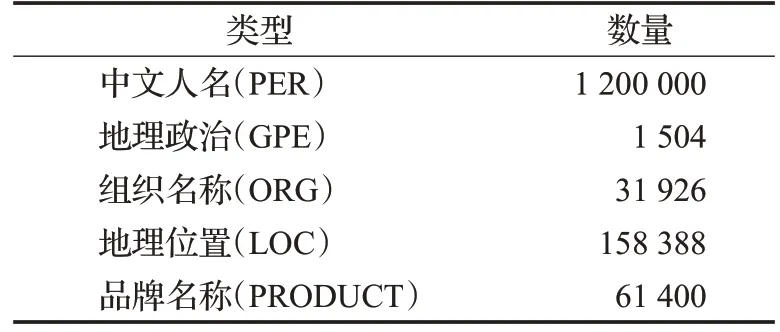
表2 词典信息Table 2 Dictionary information 个
2.2 数据集标注及评价标准
采用的标注格式是BIEO 的标注形式,如对于位置信息,使用“B-LOC”“I-LOC”“E-LOC”“O”。采用的评价标准与以往相关论文所使用的标准一样,即使用精确率P、召回率R和F1 值来进行模型的效果评估。其中各个评价指标的计算公式如下:
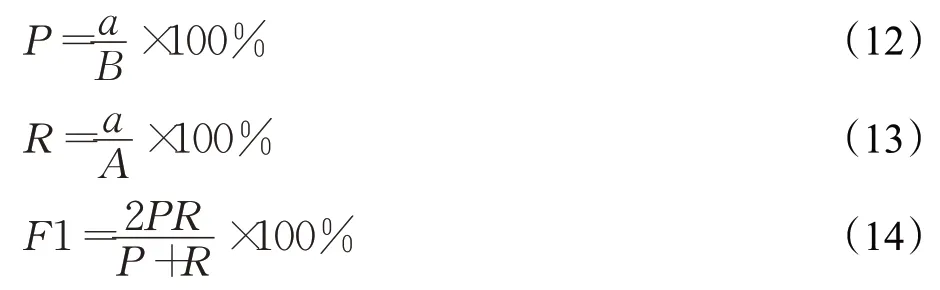
其中,a表示识别正确的实体数,A表示全部实体的个数,B表示被识别出的实体数。
2.3 参照对比模型
这里对比模型选取BiLSTM(2-gram)、BiLSTM(3-gram)、BiLSTM(4-gram)、Lattice、Multigraph。使用BiLSTM(2-gram)、BiLSTM(3-gram)、BiLSTM(4-gram)主要是为了将所提出模型与依靠N-gram进行分词并与字符进行组合的模型进行对比,从而进一步体现出在数据集不使用gazetteers和句法结构信息时的效果,Lattice和MultiGraph 模型都是使用了gazetteers 的中文命名实体识别模型,前者是基于LSTM 实现的修改,在LSTM的神经元接收字符信息的同时也会接收通过词典匹配的词信息,后者是基于词向量表示层的改进,将词典信息通过图神经网络融合进字符表示中,之后再将其输入到下一层的BiSLTM 中。通过与以上两种模型的对比可以体现出新模型的以下两个方面的效果:(1)对比基于LSTM 层融入词信息模型的效果;(2)对比基于表示层融入词信息而没有使用句法结构信息的效果。通过以上模型对比,从而更好地体现出所提出模型的效果。
2.4 实验环境与实验参数配置
2.4.1 实验环境配置
本实验是基于NCRF++框架[18]搭建,其具体的训练环境配置如表3所示。
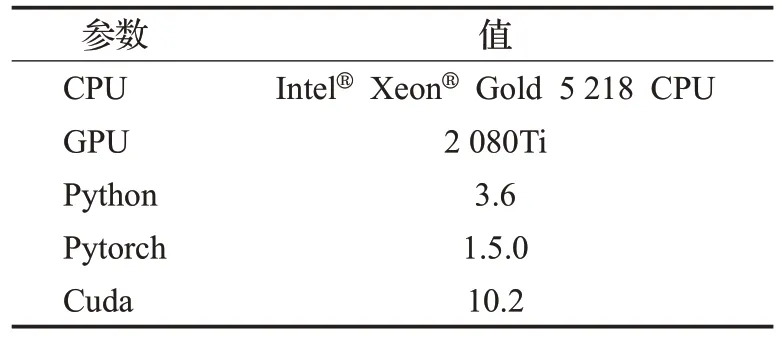
表3 训练环境配置Table 3 Training environment configuration
2.4.2 实验参数配置
在本次实验过程中,采用sgd来作为模型优化器,初始学习率设置为0.01,之后按照0.05的衰减率进行递减。LSTM 隐藏层的特征维度设置为300,训练批次大小为64,在LSTM的输入和输出设置Dropout,值为0.5,GRU的Clip值设置为5。具体的实验参数配置如表4所示。
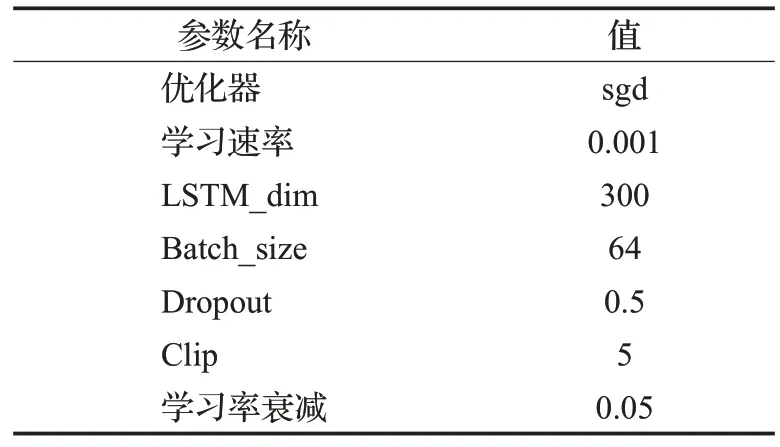
表4 参数设置Table 4 Parameter settings
2.5 实验结果
通过采用文献[19]中的方法,首先在BiLSTM-CRF仅仅基于字符的基础上实验,后续通过添加2-gram、3-gram和4-gram的实验对比,结果如表5所示。
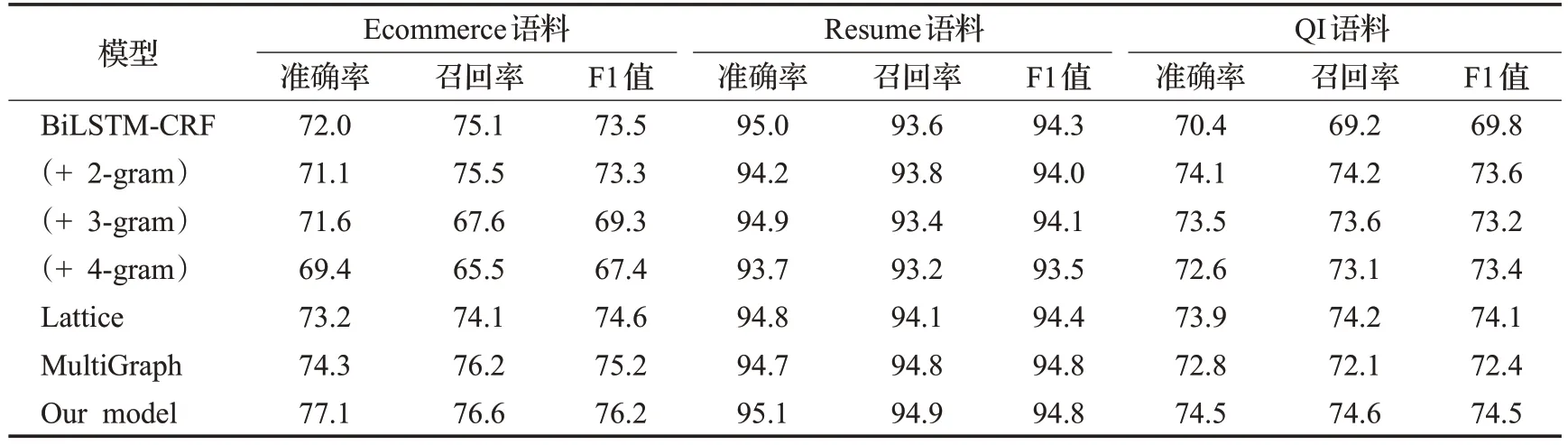
表5 Ecommerce语料、Resume语料和QI语料的实验对比结果Table 5 Experiment comparison results of Ecommerce corpus,Resume corpus and QI corpus %
通过表中数据可以看出2-gram 相对于3-gram、4-gram 有较好的结果。与模型Lattice 和MultiGraph 对比本文的模型效果也有所提升。综上,本文的模型在使用了gazetteers和句法依存树的关系后使得模型效果显著提升。在Ecommerce数据集和QI数据集上的提升比较明显,主要是因为这两个数据集的特殊符号和品牌名称特殊字符较多,相对于Resume 数据集有更多的噪音信息,通过融入gazetteers 和句法结构关系可以缓解词典匹配错误信息的传递,从而使得各项指标都得到了提升。对于Resume 数据集,数据格式和文本结构比较单一且文字信息较为工整,提升效果不是很明显,但是相比于实验中的其他模型,效果也得到了一定的提升。
2.6 消融实验
为了对融入句法依赖解析所产生影响做出更加客观的评价,将模型设置为四种情况进行消融实验:(1)初始模型(不包含句法依赖结构和词典信息)BiLSTM+bigram;(2)仅仅包含句法依赖信息,表示为BiLSTM+bigram+DT;(3)仅仅融入gazetteers 信息,表示为BiLSTM+bigram+gaz;(4)既包含gazetteers信息也包含句法依赖结构信息即本文的模型,表示为BiLSTM+bigram+gaz+DT,最终实验结果如表6所示。

表6 Ecommerce语料、Resume语料和QI语料消融实验结果Table 6 Ablation experiment results of Ecommerce corpus,Resume corpus and QI corpus %
通过实验结果数据可以看出,在模型去掉gazetteers信息和句法依赖结构关系时,整体评测标准大幅下降,当初始模型加入句法依赖信息后,准确率和F1 值都有一定的提升;仅仅将词典信息融入进去对于recall 值有很大的提升,准确率和F1 值提升幅度与仅仅加入句法依赖关系效果接近。将两者共同融入后,所有的指标都得到了一个明显的提升。由此可以看出句法依赖信息有助于提升词的信息表示,进而提升各项评测信息的值。
3 总结及展望
针对中文命名实体识别任务,通过自适应图神经网络将词信息、句法依赖信息、句子顺序信息融合获得语境化的词向量,再结合传统的神经网络模型BiLSTMCRF,构建成新的实体识别模型。通过在Ecommerce数据集、Resume 数据集和自行标注的QI 数据集分别进行评测,相比于参考的其他模型都获得了不错的效果。所提出模型的最大优势在于通过将句法依赖关系融合进词的信息可以很好地缓解对于词典中不存在的词造成的融合错误信息的问题,从而使得该模型相比于其他模型识别效果得到了很好的提升。文中所研究的这个方法可以应用于其他领域对于中文命名实体识别模型的词的消歧工作。
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
汉字汉语研究(2020年2期)2020-08-13
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
英语文摘(2019年5期)2019-07-13
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
